문서 목적
해당 문서는 실무로 배우는 빅데이터 기술 책을 실습하면서 Flume에 대해 정리하기 위해 작성된 문서이다.
Flume
빅데이터를 수집할 때, 다양한 수집 요구사항들을 해결하기 위한 기능으로 구성된 소프트웨어이다.
오픈소스 프로젝트로 개발된 로그 데이터를 수집 기술로, Cloudera에서 2011년 처음으로 소개되었다.
- 공식 홈페이지 : https://flume.apache.org/
- 주요 구성 요소
- Source:
다양한 원천 시스템의 데이터를 수집하기 위해 Avro, Thrift, JMS, Spool Dir, Kafka 등 여러 컴포넌트를 제공하여 수집한 데이터를 Channel로 전달 - Sink :
수집한 데이터를 Channel로 부터 전달받아 최종 목적지에 저장하기 위한 기능으로 HDFS, Hive, Logger, Avro, ElasticSearch, Thrift 등을 제공 - Channel :
Source와 Sink를 연결하며 데이터를 버퍼링하는 컴포넌트로 메모리, 파일, 데이터베이스를 채널의 저장소로 사용 - Interceptor :
Source와 Channel 사이에서 데이터 필터링 및 가공하는 컴포넌트로서 Timestamp, Host, Regex Filtering 등을 기본 제공하며, 필요 시 사용자 정의 Interceptor를 추가 - Agent :
Source → (Interceptor) -> Channel -> Sink 컴포넌트 순으로 구성된 작업 단위로 독립된 인스턴스로 생성
- Source:
- 라이선스 : Apache 2.0
Architecture
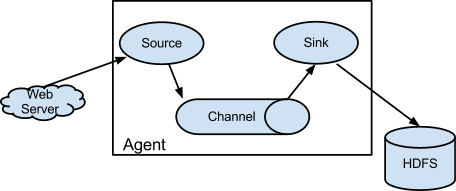
Source에서 데이터를 로드하고 Channel에서 데이터를 임시 저장했다가, Sink를 통해 목적지에 데이터를 최종 적재한다.
대표적으로 4가지의 구성 방안이 있음
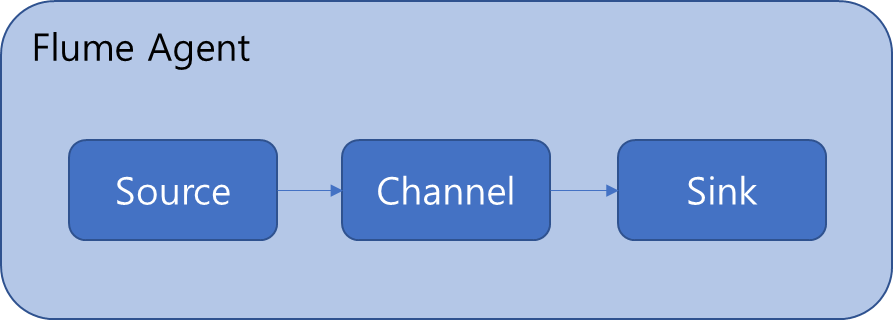
- 원천 데이터를 특별한 처리 없이 단순 수집/ 적재할때 주로 활용(가장 단순한 Agent 구성)
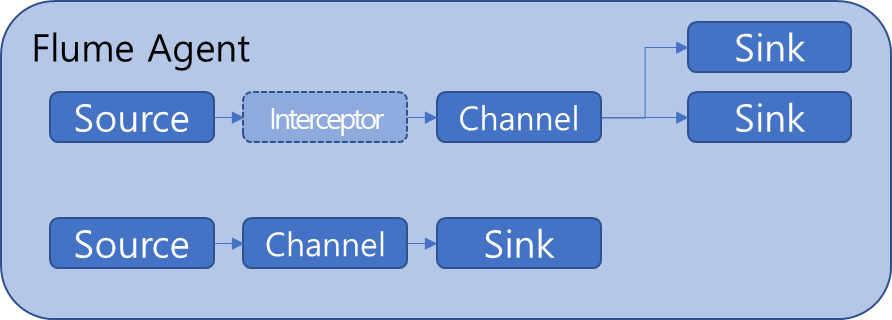
- Interceptor를 추가해 데이터를 가공하고, 데이터의 특성에 따라 Channel에서 다수의 Sink 컴포넌트로 라우팅이 필요할 때 구성
한개의 Flum agent안에서 두 개 이상의 Source Channel Sink 컴포넌트 구성 및 관리도 가능
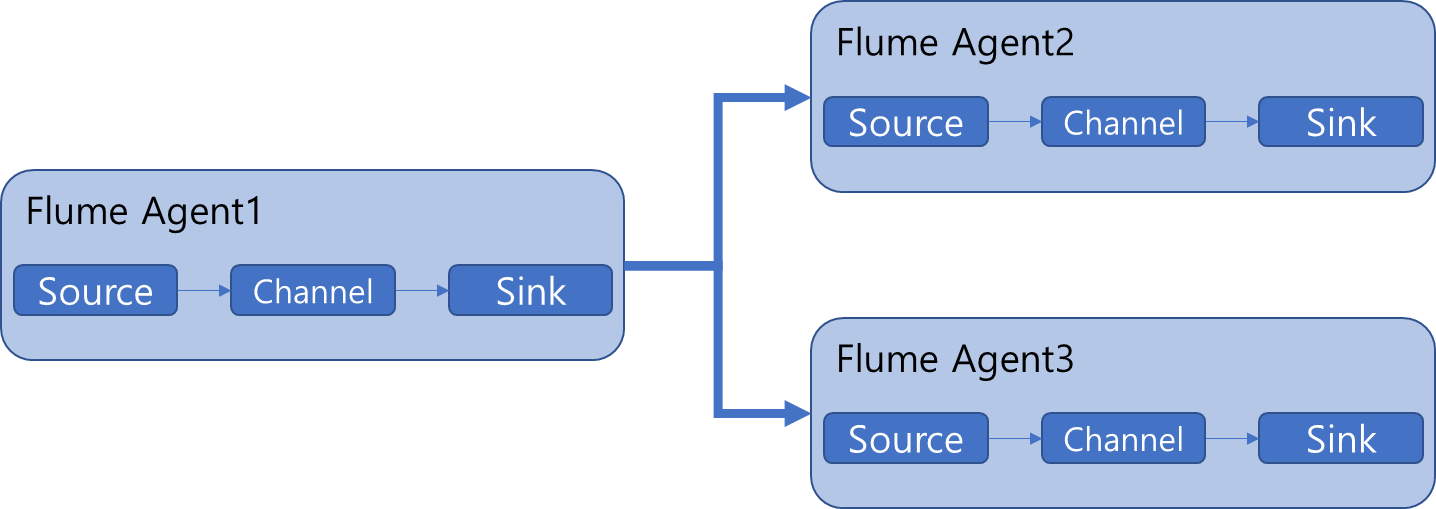
- Flume Agent에서 수집한 데이터를 Agent2, Agent3에 전송할 때 로드 밸런싱, 복제, failover등의 기능을 선택적으로 수행 가능.
수집해야할 원천 시스템은 한 곳이지만 높은 성능이 필요할 때 주로 사용
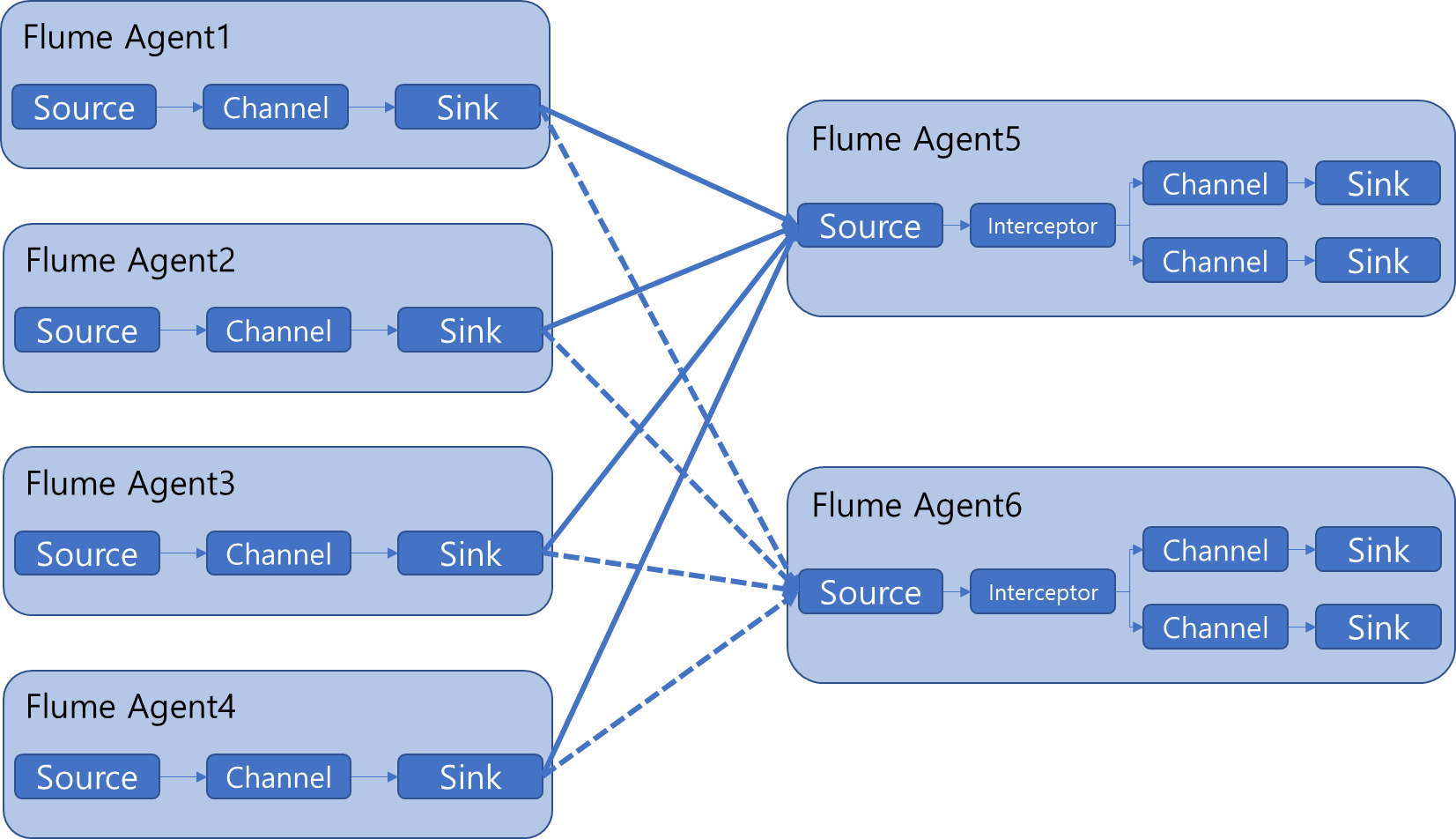
- 수집해야 할 원천 시스템이 다양하고 대규모의 데이터가 유입될 때 사용하는 아키텍쳐
1~4에서 수집한 데이터를 5에서 집계하고, 6으로 이중화해서 성능과 안정성을 보장
활용 방안
- 로그를 직접 수집하는 역할을 담당
- 실시간 스트림과 배치작업 모두에서 사용 가능

열심히 정리하는 습관 기르기..