
문서 목적
해당 문서는 Kafka에 대해 대략적으로 설명한 문서이다.
Kafka
-
분산 이벤트 스트리밍 플랫폼
-
Event streaming : DB, log, sensor, applicaion과 같은 이벤트 소스에서 이벤트 스트림의 형태로 실시간으로 데이터를 캡쳐하는 방식
-

-
-
기존에는 어플리케이션 끼리 메시지를 날리는 방식이었으나, Kafka는 kafka Cluster와 어플리케이션 끼리 메시지를 날리면서 교환하는 방식으로 기존보다 확장성이 높다
구성 요소
Zookeeper
- 아파치 프로젝트 애플리케이션
- kafka의 metadata 관리 및 broker의 health check를 담당
- https://bcho.tistory.com/1016
Kafka(Kafka cluster)
- 여러대의 broker를 구성한 클러스터
Broker
- Kafka application이 설치된 서버 또는 노드
- Kafka cluster는 여러 대의 Broker로 구성
- 각 broker는 고유한 id로 구분되며 특정 topic partition을 포함함
- Replication factor
Producer
- Kafka로 메시지를 보내는 역할을 하는 클라이언트
Consumer
- Kafka에서 메시지를 꺼내가는 역할을 하는 클라이언트
- 데이터는 각 partition내에서 순서대로 읽어온다
- Consumer group
Topic
- 특정 스트림 데이터이며, kafka cluster에서 데이터를 관리할 시 기준이 됨
- Similar to a table in a database (without all the constraints)
- 원하는 수만큼 topic 생성 가능
- partition으로 나누어서 처리되며 각 partition은 순서가 존재
- 데이터 보존 주기 기본 7일(log.retention.hours)
- 특정 파티션에 데이터가 쓰여지면 절대 변경이 이루어지지 않음
Partition / Offset
- Partition
- 각 topic 당 데이터를 분산 처리하는 단위
- topic안에 partition을 나누어 그 수대로 데이터를 분산처리 함
- replica의 수만큼 partition이 서버에 복제
- Offset
- partition에서만 의미가 있는 순서로 partition내에서만 보장
Segment
- Producer가 전송한 실제 메시지가 broker의 로컬 디스크에 저장되는 파일
Message / Record
- Producer가 broker로 전송하거나 consumer가 읽어가는 데이터
Architecture
-
1대의 카프카 서버만 설치하고, 1개의 broker만 구성한 아키텍처로, 대량의 발행 / 소비 요건이 없고, 업무 도메인이 단순할 때 이용
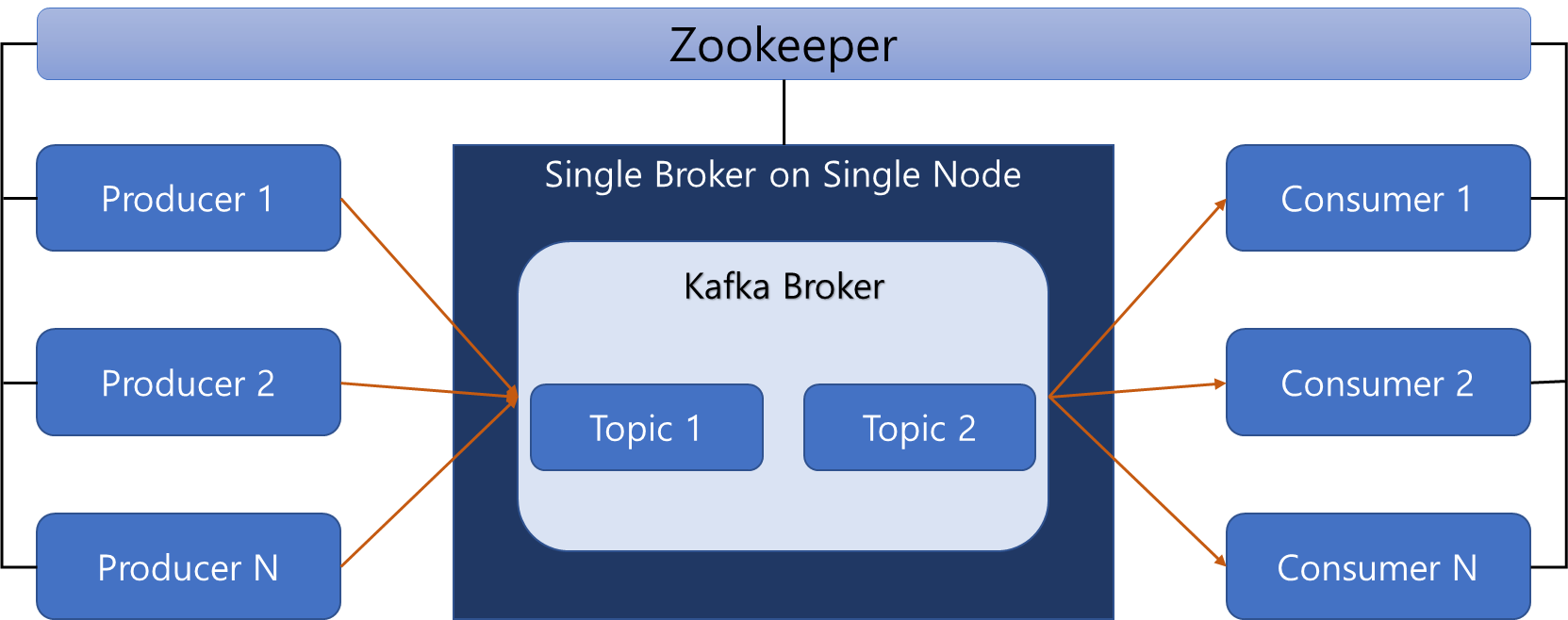
-
kafka 서버 2개에 Broker를 구성
물리적인 카프카 서버는 1대이므로 대량의 발행/ 소비 여건에는 사용하기 어려우나, 업무 도메인이 복잡해서 메시지 처리를 분리 관리해야 할 때 이용
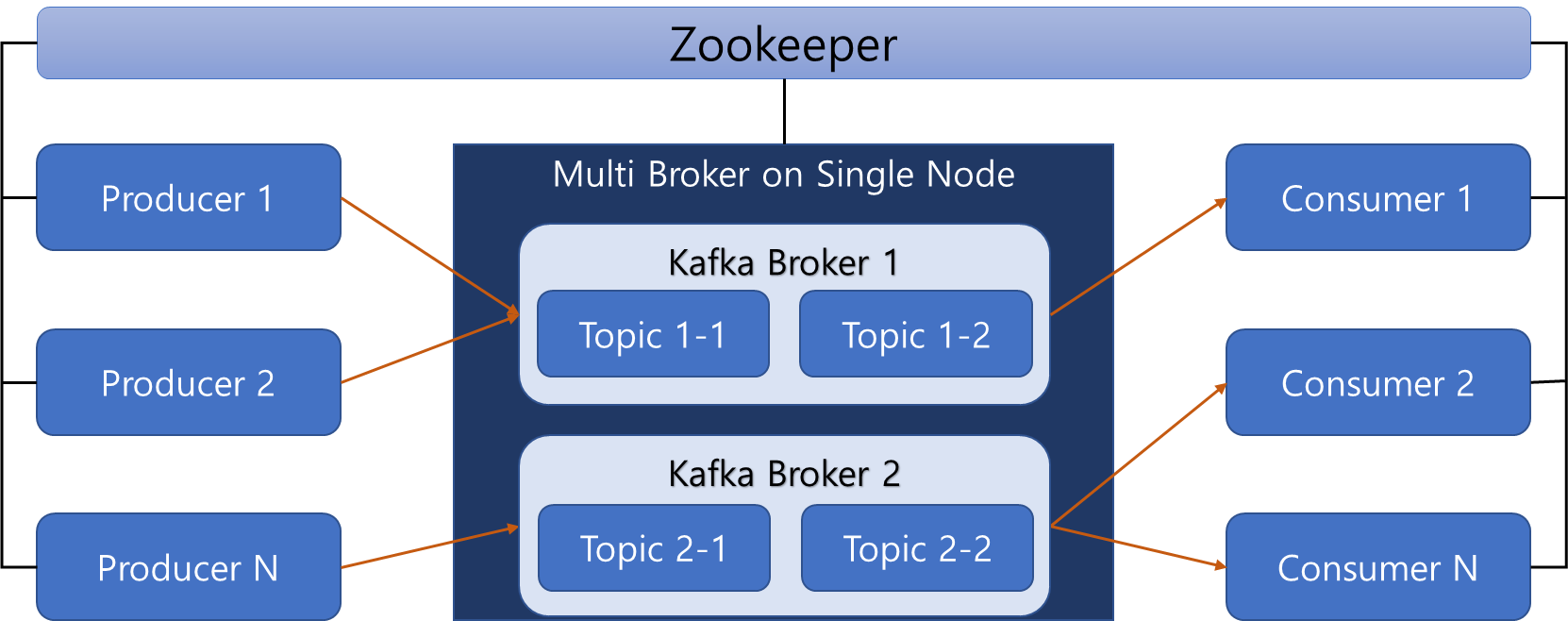
- 2대 이상의 kafka 서버로 멀티 브로커 생성
대규모 발행/소비 데이터 처리에 적합하며, 물리적으로 나눠진 브로커 간의 데이터 복제가 가능해 안정성 높음
업무 도메인별 메시지 그룹을 분류할 수 있어 복잡한 메시지 송/수신에 적합
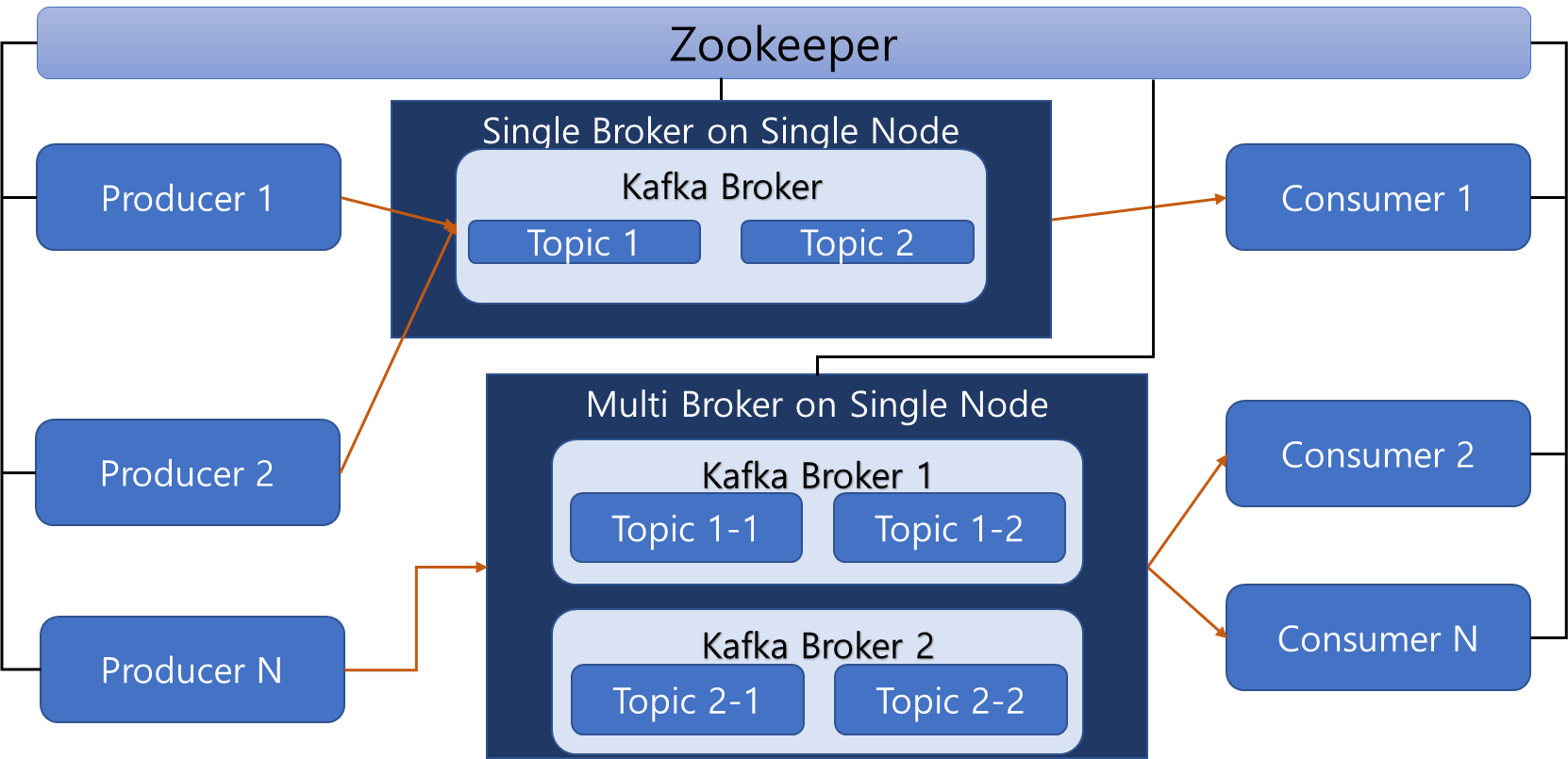
활용
플럼이 데이터를 수집해서 카프카 토픽에 전송받은 데이터를 컨슈머로 가져오는 형식으로 사용할 예정
출처
- https://kafka.apache.org/intro
- https://velog.io/@qlgks1/0장.-카프카Kafka란
- https://velog.io/@king3456/Apache-Kafka-기본개념
- https://blog.naver.com/PostView.naver?blogId=arkdata&logNo=222632637775&parentCategoryNo=&categoryNo=14&viewDate=&isShowPopularPosts=true&from=search
- https://zeroco.tistory.com/105
- https://team-platform.tistory.com/11

열심히 정리하는 습관 기르기..