문서 목적
해당 문서는 하둡에 대해 정리하기 위해 작성된 문서이다.
Hadoop
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
공식 문서 : https://hadoop.apache.org/
대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 프리웨어 자바 소프트웨어 프레임워크이다.
크게 아래와 같이 2가지 기능이 있다.
1. 대용량 데이터를 분산 저장
2. 분산 저장된 데이터를 가공/분석 처리하는 기능
MapReduce
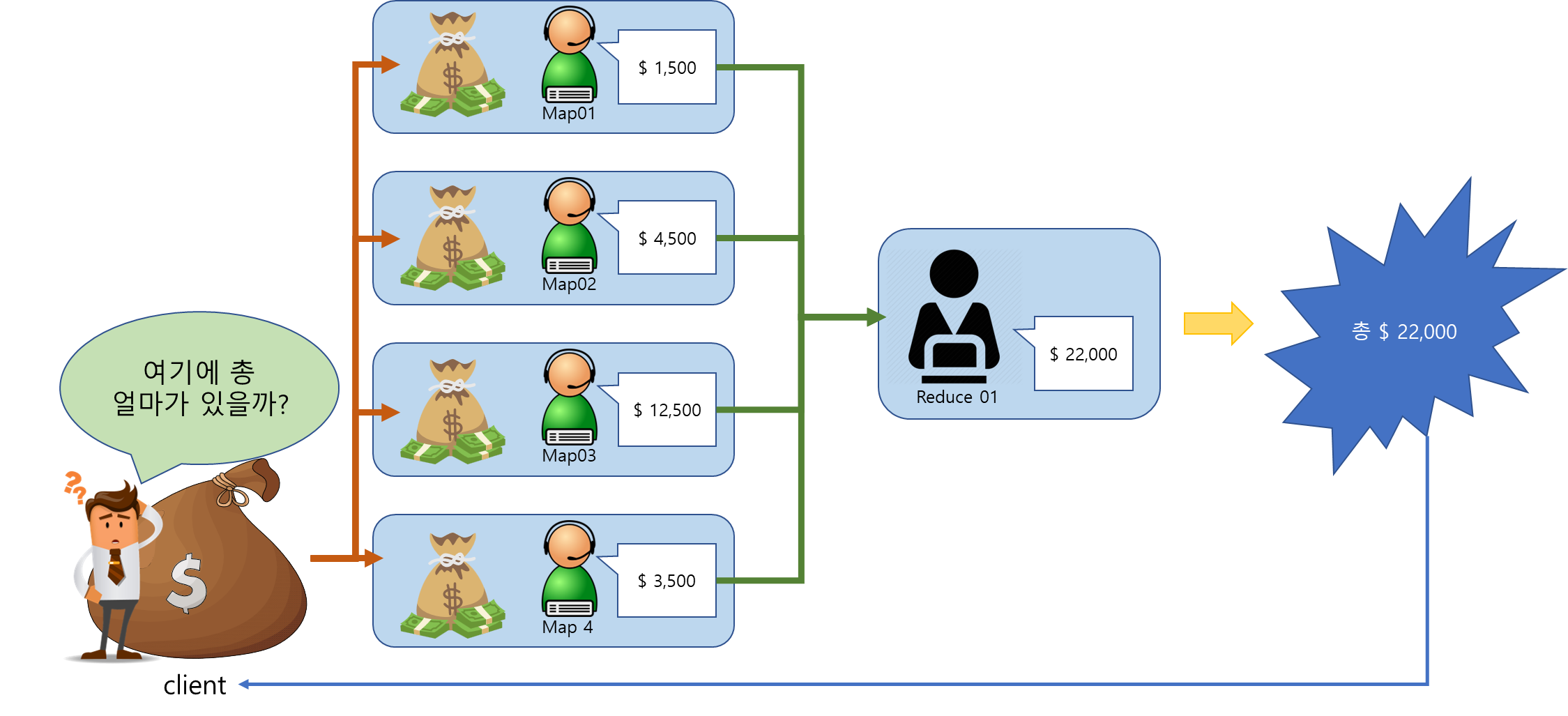
분산 병렬 처리에서 여러 컴퓨터에 분산 저장돼 있는 데이터로부터 어떻게 효율적으로 일을 나눠서(Map) 실행시킬 수 있고, 여러 컴퓨터가 나눠서 실행한 결과들을 어떻게 하나로 합칠 수 있냐(Reduce)가 중요한데 이를 쉽고 편리하게 지원하는 framework가 MapReduce이다.
정리하면 이런 느낌..
1. 전체 돈을 나누어서 각 창구에 나누어서 저장
2. 각 캐셔(Worker) 들은 전체 돈을 구하는 Map 함수 생성
3. 각 캐셔(Worker) 들은 돈 자루(데이터 블록)마다 얼마가 있는지 구하고 이를 매니저(Reducer)에게 명세서(작아진 데이터) 전달
4. 매니저(Reducer)는 이를 모두 취합해서 전체 얼마가 있는지 구하고 이로 명세서 발급(파일로 저장)
5. 고객은 이를 확인하여 얼마가 있는지 확인한다.
주요 구성 요소
Common
- DataNode : 블록(64MB, 128Mb..) 단위로 분할된 대용량 파일들이 DataNode의 디스크에 저장 및 관리
- NameNode : DataNode에 저장된 파일들의 메타 정보를 메모리상에서 로드해서 관리
- EditsLog : 파일들의 변경 이력(수정, 삭제 등) 정보가 저장되는 로그 파일
- FsImage : NameNode의 메모리상에 오랄와 있는 메타 정보를 스냅샷 이미지로 만들어 생성한 파일
Ver 1.x
- SecondaryNameNode : NameNode의 FsImage와 EditsLog 파일을 주기적으로 유지 관리해 주는 checkpoint node
- MapReduce v1 : DataNode에 분산 저장된 파일이 스플릿(Map)되어 다양한 연산(정렬, 그루핑, 집계 등)을 수행한 뒤 그 결과를 다시 병합(reduce)하는 분산 프로그래밍 기법
- JobTracker : 맵리듀스의 잡을 실행하면서 태스크에 할당하고, 전체 잡에 대해 리소스 분배 및 스케줄링
- TaskTracker : JobTracker가 요청한 맵리듀스 프로그램이 실행되는 task이며, 이때 맵 태스크와 리듀스 태스크가 생성
Ver 2.x
- Active / Stand-By NameNode : NameNode를 이중화해서 서비스 중인 ActiveNode와 실패 처리를 대비한 Standby NameNode로 구성
- MapReduce v2 / YARN : 하둡 클러스터 내의 자원을 중앙 관리하고, 그 위에 다양한 애플리케이션을 실행 및 관리가 가능하도록 확장성과 호환성을 높인 하둡 2.x의 플랫폼
- ResourceManager : 하둡 클러스터 내의 자원을 중앙 관리하면서, 작업 요청시 스케줄링 정책에 따라 자원을 분배해서 실행시키고 모니터링
- NodeManager : 하둡 클러스터의 DataNode마다 실행되면서 Container를 실행 시키고 라이프 사이클을 관리
- Container : DataNode의 사용 가능한 리소스(CPU, memory, disk...)를 Container를 단위로 할당해서 구성
- ApplicationMaster : 애플리케이션 실행되면 ApplicationMaster가 생성되며 ApplicationMaster는 NodeManager에게 애플리케이션이 실행될 Container를 요청하고, 그 위에서 애플리케이션을 실행 및 관리
- JournalNode : 3개 이상의 노드를 구성되어 EditsLog를 각 노드에 복제 관리하며 Active NameNode는 EditsLog에 쓰기만을 수행하고 Standby NameNode는 읽기만을 실행
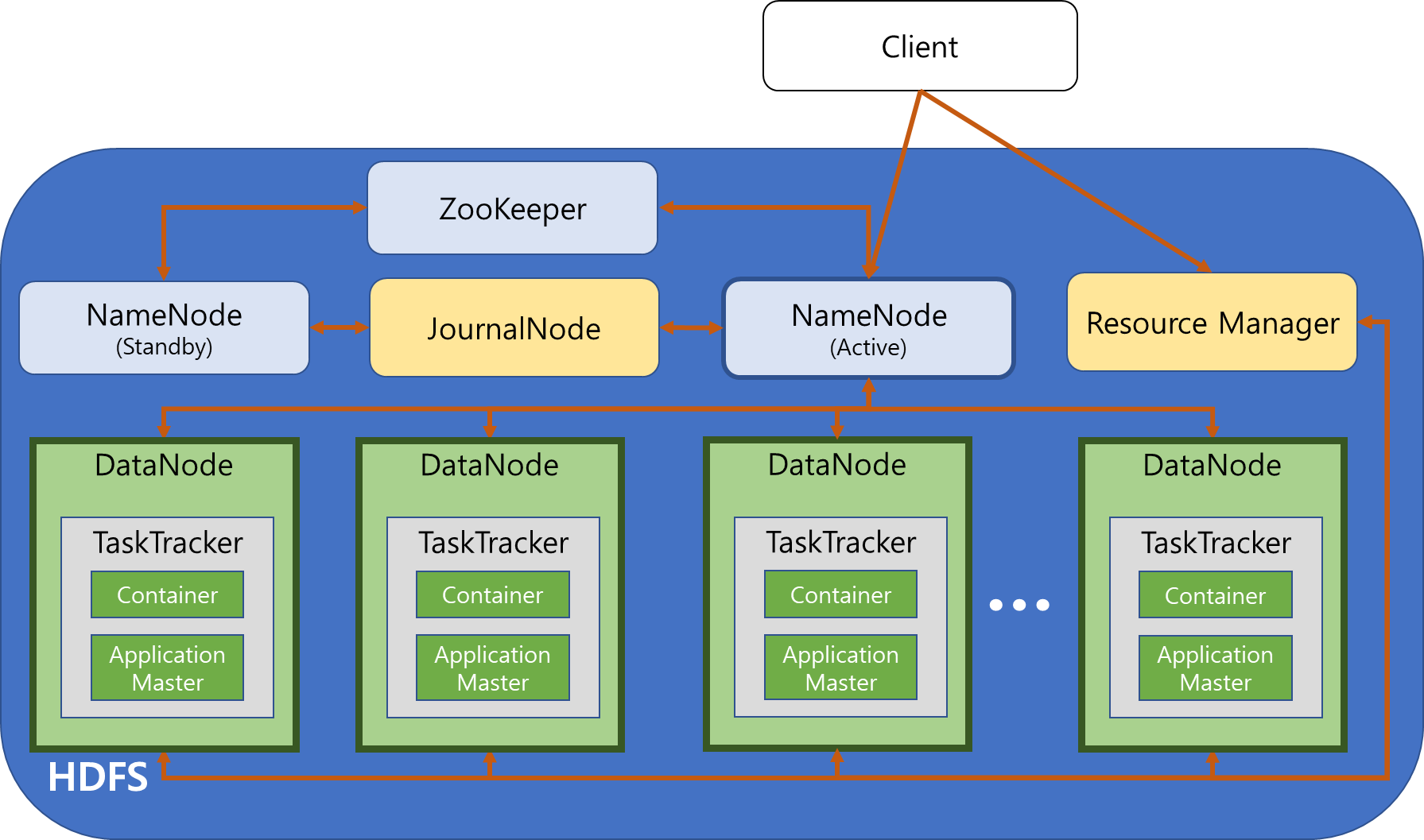
Architecture
Hadoop 1.x

과정
- 클라이언트에서 하둡에 파일을 읽기/쓰기를 할 때, 우선 NameNode를 참조에서 파일을 읽기/쓰기 할 DataNode의 정보를 전달 받는다.
- 클라이언트는 1의 정보를 이용해 DataNode에 직접 연결하여 파일을 읽기 / 쓰기한다.
- 하둡에 적재된 데이터를 분석해야 할 때는, 클라이언트가 JobTracker에게 맵리듀스 실행을 요청하게 되며, JobTracker가 스케줄링 정책에 따라 작업항 DataNode/TaskTracker를 선정한다.
- 선정된 TaskTracker에서 맵리듀스 프로그램이 전달되어 저장된 파일들을 이용해 맵리듀스 작업들이 실행된다.
문제점
- NameNode의 이중화 기능 미지원으로 SPOF(Single Point Of Failure, 단일 장애 접점)가 존재한다.
- NameNode에 문제가 발생하면 Hadoop 클러스터 전체에 장애가 발생하게 됨
- 보완하기 위해, NameNode에 추가적인 HA 작업을 해야 하고 그로 인해 관리의 복잡성과 비용이 증가
- 분산 병렬처리를 위한 맵리듀스를 실행할 때도 잡 스케줄링과 리소스 배분 정책이 효율적이지 못해 병목이 자주 발생
Hadoop 2.x
1.x와의 차이점
- 다양한 컴포넌트가 교체 및 추가
- NameNode가 Active / Standby 이중화
- NameNode의 메모리에서 관리되는 파일들의 네임스페이스 정보를 주기적으로 관리하기 위해 JournalNode, Zookeeper 추가
- JobTracker, TaskTracker ➜ Resource Manager, Node Manager
- Resource Manager는 Node Manager의 리소스 현황들을 종합적으로 수집해가며 작업 실행을 위한 최적의 DataNode를 찾아줘서 효율적인 잡 스케줄링이 가능해 졌으며, DataNode의 리소스 불균형 현상 문제 해결
- NodeManager의 Container, Application Master는 기존 1.x의 맵리듀스 잡외에도 다양한 애플리케이션을 하둡의 DataNode에서 실행 및 관리할 수 있게 확장
- 이렇게 변화된 하둡 2.x 플랫폼을 YARN(Yet Another Resource Negotitator)이라고 함
