AI Agent
에이전트란?
에이전트 프레임워크 종류
- crewAI
- Langchain으로 구축된 프레임워크
- Agent, Tool, Task, Process, Crew로 구성되어있음
- Langchain과 결함이 용이하며 멀티에이전트에 최적화
- AutoGen
- MS에서 구축한 멀티 에이전트 대화 시스템 구축 프레임워크
- 사용자를 대신하는 UserProxyAgent, 이를 보조하는 AssistantAgent등 존재
- 여러 에이전트간의 대화 자체에 집중
- Langgraph
- Langchain 생태계에서 구축된 그래프 방식의 프레임워크로, Low-level 접근
- 에이전트-에이전트, 에이전트-도구 간의 흐름을 상세히 정의하므로 controllabilty가 높음
RAG 구현 측면에서 에이전트의 필요성
LLM의 한계
- 환각현상
- 딥러닝 모델은 학습된 데이터 이외의 정보에 취약함
- 기억 불가
- LLM은 사전학습시에 받아들인 정보 외의 것은 배우지 못함
- 토큰 제한
- LLM은 입력값의 길이가 길어지면 계산량이 크게 늘어나 대부분의 모델이 길이를 제한하고 있음
RAG란?
- AI 모델이 외부 데이터베이스에서 관련 정보를 검색하고, 이를 활용하여 더 정확하고 최신의 응답을 생성하는 기술
- 이를 통해 LLM이 가진 한계를 극복할 수 있음
RAG 구성요소
- Retrieval
- 사용자의 질문이나 프롬프트 입력
- 입력 내용 분석 및 관련 키워드나 의미 추출
- 추출된 정보 기반 벡터DB에서 관련성 높은 정보 검색
- 문서, 단락, 또는 관련 데이터 조각 형태의 검색 결과 도출
- 벡터 유사도 검색 등의 기술 활용
- Augmented
- 검색된 정보와 사용자의 원래 질문/프롬프트 결합
- 검색 결과의 관련성 평가 및 필요 정보 선별
- 선별된 정보를 원래 프롬프트에 추가한 증강된 프롬프트 생성
- 컨텍스트 윈도우 조정, 정보 요약 등의 기술 적용
- LLM의 정확하고 관련성 높은 응답 생성 기반 마련
- Generation
- 증강된 프롬프트의 LLM 입력
- LLM의 증강된 프롬프트 기반 응답 생성
- LLM의 사전 학습 지식과 새로 제공된 컨텍스트 정보 활용
- 사용자 질문에 대한 답변, 요약, 분석 등 다양한 형태의 응답 생성
- 최종 생성된 응답의 사용자 제공
RAG의 한계점
- Retrieval 단계
- Pre-Retrieval(Indexing): 문서를 인텍싱하는 과정은, 어떤 문서인지에 따라 전처리, 청킹, 임베딩 모델, 메타데이터 등의 맞춤화 과정이 필요함 -> 맞는 방법을 찾기 위해 시행착오 필요
- Retreival & Post-Retreival: 문서가 적절히 저장되었더라도, 사용자의 질문에 따라 검색 결과가 다르므로(ex, 질문이 모호한 경우), 사용자의 질문을 재구성하거나, 검색된 문서를 재배치하는 등 추가적인 조치 필요
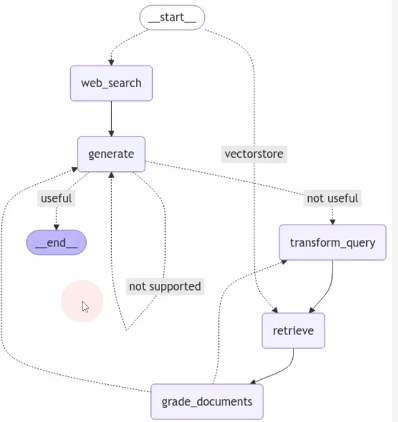
Agent Framework
CrewAI
CrewAI 구조
코드 구성
-
Agent 정의
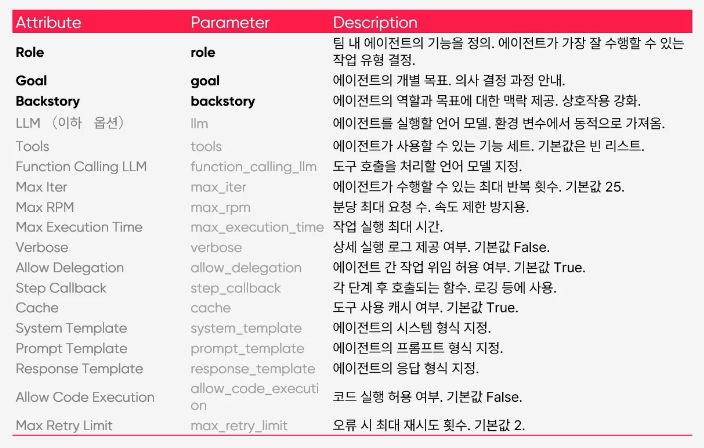
- role: 역할 배정
- gole: 목표 설정 - AI가 해야하는일 정의
- backstory: role과 gole 이외에 추가적인 설명
- allow_delegation: true/false- 주어진 task를 다른 agent에게 맡길 수 있도록 할지 여부 (false로 해야 일을 완벽히 수행해내려고 노력할 가능성 높음)
- llm: 사용하는 모델 종류 - ex. ChatOpenAI(model_name="gpt-3.5", temperature = 0.7))
- tools: 사용할 도구
-
Task 정의
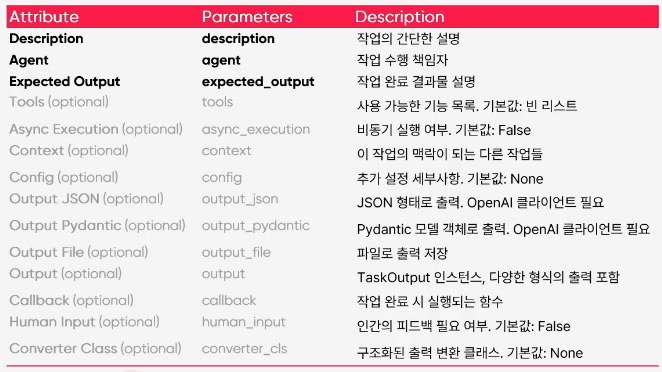
- description: 에이전트들이 행해야하는 테스트 설명
- expected_output: 테스크가 수행된 결과물을 어떤 형식으로 받고싶은지
- agent: 해당 테스크를 수행할 에이전트
-
Tool 정의 (사전정의 툴 사용 가능)
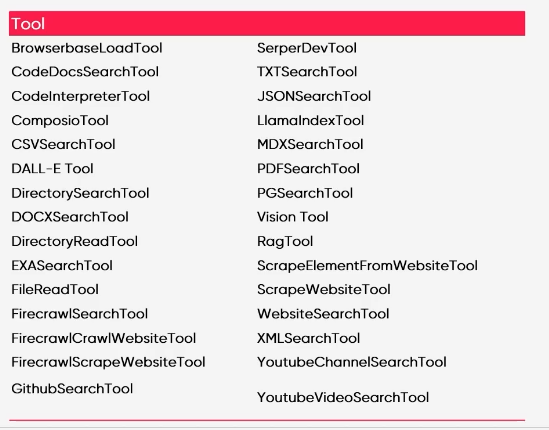
-
Crew, Process 정의
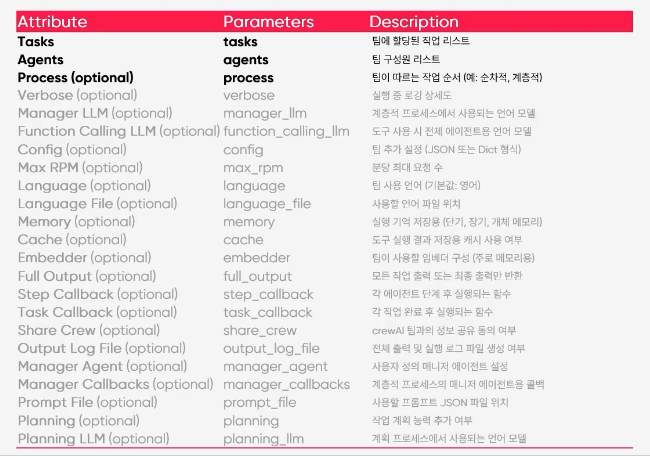
- agents: 크루안에 넣을 에이전트 목록
- task: 크루안에서 해결해야하는 테스크 목록
- verbose: true/false - 크루가 수행하는 작업 과정 출력 여부
Autogen
Autogen 구조
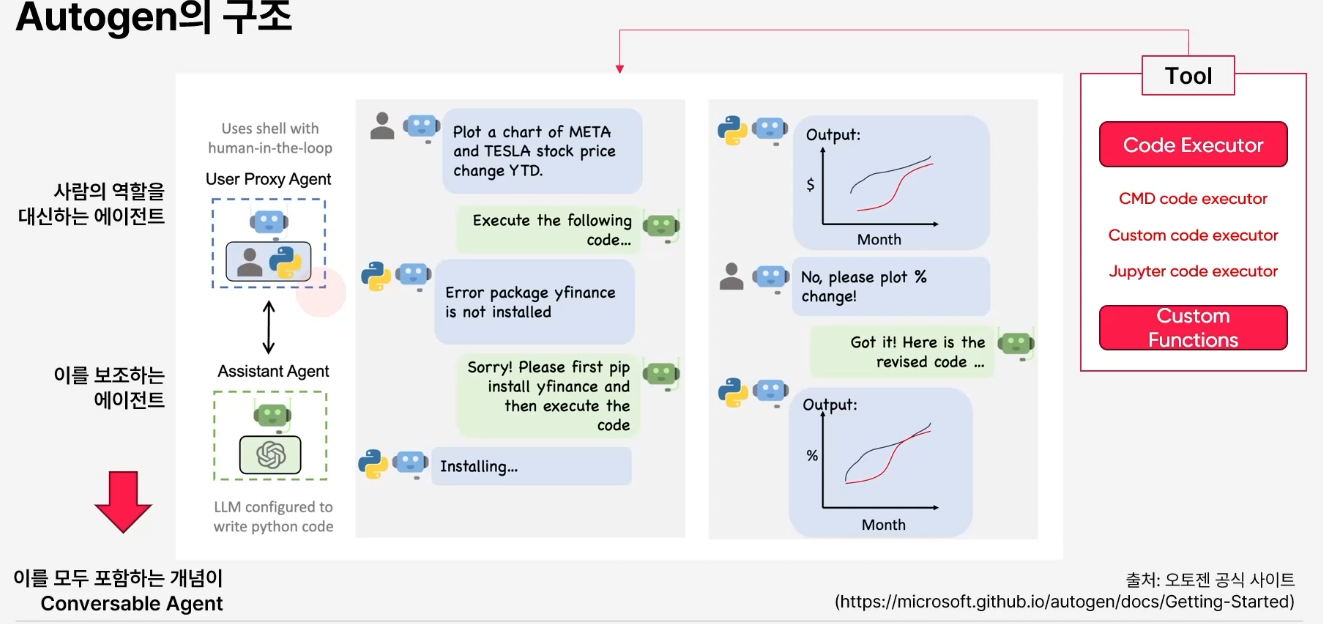
- Agent
- User Proxy Agent: 사람의 역할을 대신하는 에이전트
- Assistant Agent: 이를 보조하는 에이전트
- Tool
- Code Executor: 에이전트가 실제로 주어진 코드를 실행할 수 있도록
- Custom Functions: Autogen은 CrewAI처럼 사전정의된 Tool이 많이 없기에 직접 정의해야함
Autogen 대화 종류
- 2개의 에이전트 대화방식
- 사람이 질문을 하면 두개의 에이전트가 서로 대화를 하고 해당 내용을 요약해서 제공
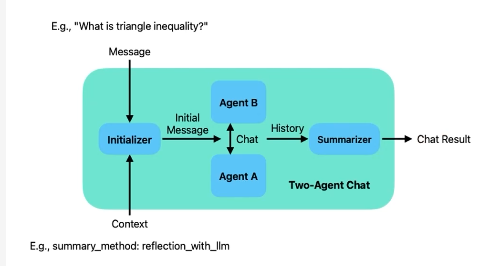
- 사람이 질문을 하면 두개의 에이전트가 서로 대화를 하고 해당 내용을 요약해서 제공
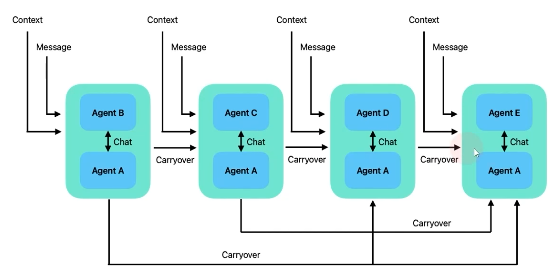
- 순차적 대화 방식
- Group Chat 대화방식
- Group Chat Manager가 speaker 정함
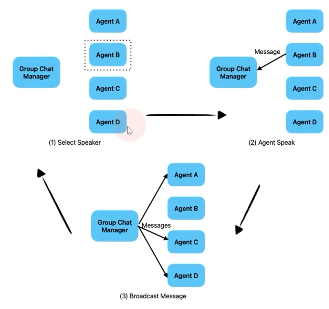
- Group Chat Manager가 speaker 정함
- 중첩된 대화방식
- 특정 조건을 만족하면 Nested Chat에 해당 메시지 보냄. 어떤 대화종류로 할지는 정하기 나름
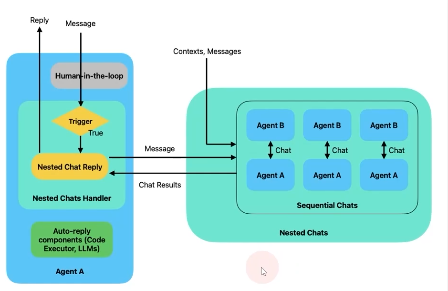
- 특정 조건을 만족하면 Nested Chat에 해당 메시지 보냄. 어떤 대화종류로 할지는 정하기 나름
Langraph
LangGraph 개념
- 핵심 장점: 사이클 지원, 세밀한 제어 가능, 내장 지속성
- 특징: 세밀한 에이전트 워크플로우 생성, 순환 구조 가능, 상태 및 흐름 정밀 제어, 휴먼인더루프/메모리 가능
- Pregel, Apache Beam, NetworkX에서 영감을 받아 만들어짐
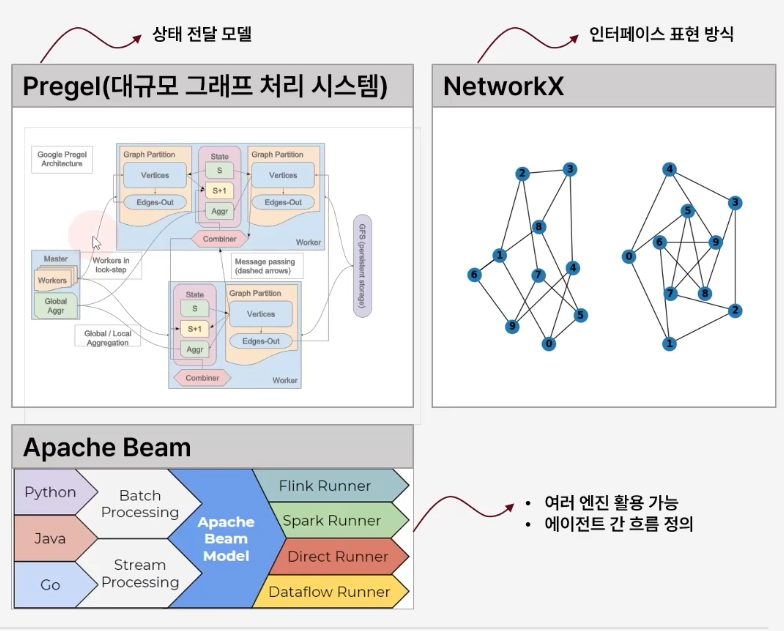
LangGraph 구조
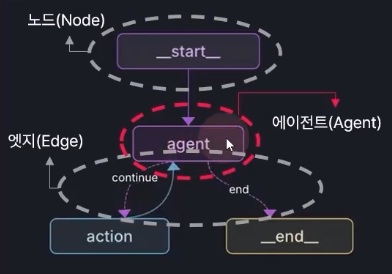
LangGraph 코드 구성
- state(상태) 정의: 에이전트 간에 어떤 정보를 주고받을지 '틀' 정의
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)- node(노드) 선언: 정보를 어떤 식으로 처리할지 함수로 정의
llm = ChatAnthropic(model="claude-3.5-sonnet")
def chatbot(state: State):
return {"messages":[llm.invoke(state(["messages"])]}
graph_builder.add_node("chatbot", chatbot)- edge(엣지) 및 그래프 선언:
graph_builder.add_edge(START, "chatbot") # (State를 전달할 노드, State를 받을 노드)
graph_builder.add_edge("chatbot", END)
graph = graph_builder.complie()RAG
RAG와 Langchain
RAG 구축을 위한 Langchain 구성요소
- Pre-Retrieval(Indexing): 문서 분할 -> 임베딩 -> 벡터DB에 저장
- Retrieval & Post-Retrieval: 질문 임베딩 -> 벡터DB에 검색 -> 검색결과를 활용해 답변 생성
Langgraph로 RAG 보완하기
Agentic RAG
- Agentic RAG가 집중한 기존 RAG 문제점
- 기존 Naive RAG의 경우, 사용자의 질문이 인덱싱된 문서와 관련이 없는 경우에도 Retrieval 단계를 거침.
- 검색된 문서가 사용자의 질문과 관련성이 없는 경우에도 이를 활용해 답변하려고 하기에 환각 현성 크게 증가
- Agentic RAG 개념
- 2개의 분기(검색 필요 여부, 관련성 검토)로 사용자의 질문에 더 제대로 답변할 수 잇음
- 인덱싱되지 않은 문서는 검색을 수행하지 않거나, 관련된 문서를 찾을 수 없는 경우, 쿼리를 재작성하는 등의 과정 수행
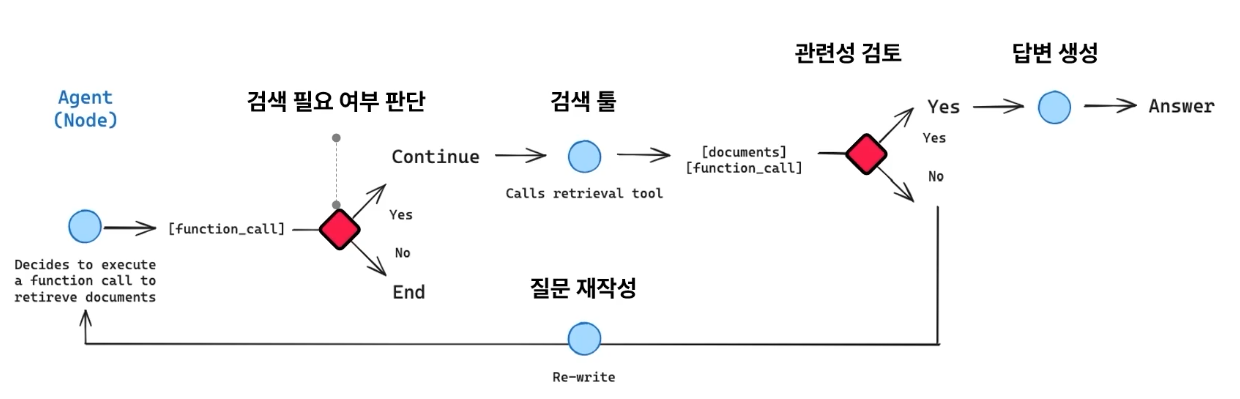
- Agentic RAG 구조
- Agentic RAG State: Messages 키 값에 사용자-AI 간의 대화를 모두 저장하여 그래프 내 상태 유지에 활용. 사용자의 쿼리, 검색된 문서, tool calling의 tool message, AIMessage 등이 저장됨
- Agentic RAG Tool: RAG를 위한 사용자 질문-유사 문서 검색 도구 필요
- Agentic RAG Node(관련성 검토): Retrieval tool로 검색한 문서가 사용자의 질문과 관련있는지 검토하고, 유관하다면 generate / 무관하다면 rewrite 노드로 이동
- Agentic RAG Node(에이전트): 주어진 메시지를 바탕으로 도구를 사용할지 답변을 작성할지 결정
- Agentic RAG Node(질문 재작성): 만약 rewrite노드로 진입한 경우, 사용자의 질문을 재가공하는 과정을 수행. Retriever tool이 더 제대로된 검색을 수행할 수 있도록 보조
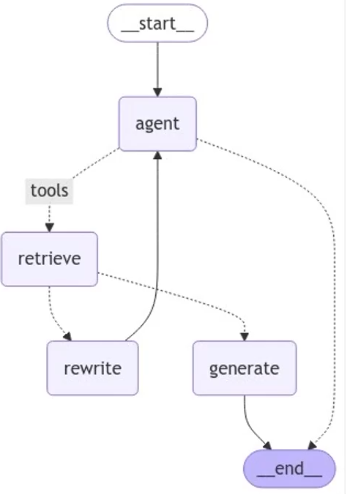
Self RAG
-
Self RAG가 집중한 기존 RAG 문제점
- 검색된 문서가 사용자의 질문과 관련성이 없는 경우에도 이를 활용해 답변하려고 하기에 환각 현성 크게 증가
- RAG 파이프라인의 결과물이 환각을 일으킨 경우, 단방향 파이프라인이므로 LLM에게 재작성을 요구할 수 없음
- 환각 없는 답변이더라도, 사용자의 질문에 적절한 답변이 아닌 경우가 발생
-
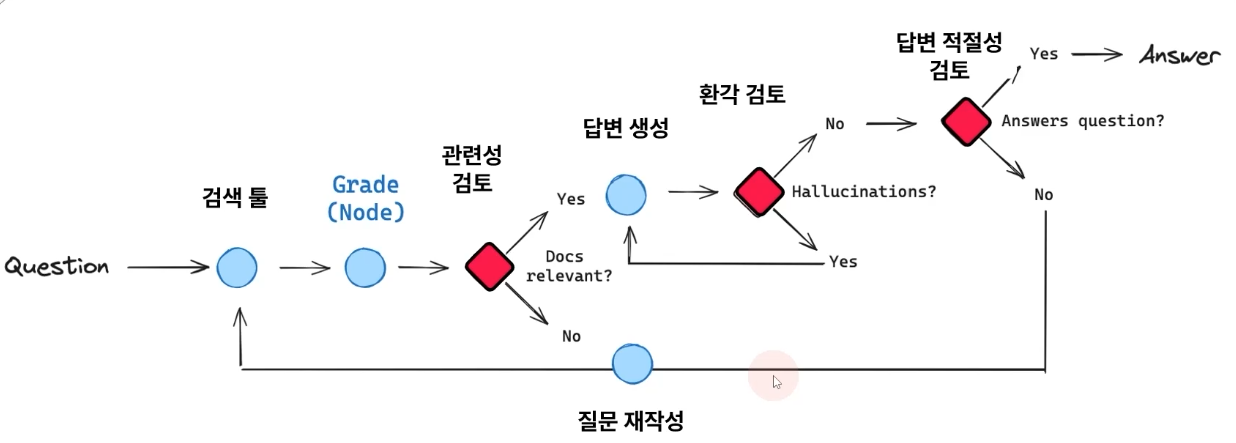
Self RAG 개념
- 3개의 분기(관련성 검토, 환각 검토, 답변 적절성 검토)로 사용자의 질문에 더 제대로된 답변을 할 수 있음
- 관련된 문서를 찾을 수 없거나 답변이 적절치 않은 경우 쿼리를 재작성, 환각이 발생한 경우 LLM 답변 재작성
-
Self RAG 구조
- Self RAG State: 사용자의 질문, 답변 결과, 검색된 문서를 각각 question, generation, documents 키값에 저장하는 틀로 GraphState 설정
- Self RAG Node(검색): 사용자 질문에 답할 수 있는 문서를 검색하는 노드
- Self RAG Node(답변 생성): Retriever에서 검색된 문서를 기반으로 사용자의 질문에 적절한 답변을 생성하는 노드
- Self RAG Node(환각 검토): LLM이 작성한 답변에서 환각현상이 발생했는지 검토하고, 환각 현상이 없는 경우 "useful" / 그렇지 않은 경우 "not useful" 반환. 만약 환각 현상이 없는 경우, 답변 적절성을 검토하여 적절하지 않다고 판단된 경우 질문 재작성 노드로 진입
- Self RAG Node(답변 적절성 검토): LLM이 직성한 답변이 사용자의 질문에 적절히 대응하는지 검토하는 역할을 수행, 만약 적절치 못한 경우 질문 재작성 노드로 진입
- Self RAG Node(질문 재작성): 만약 rewrite 노드로 진입한 경우, 사용자의 질문을 재가공하는 과정을 수행. Retriever tool이 더 제대로 된 검색을 수행할 수 있도록 보조
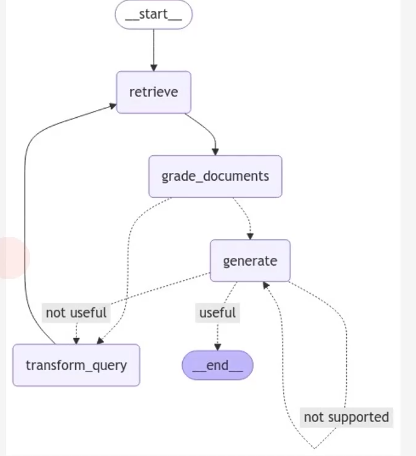
Corrective RAG
-
Corrective RAG가 집중한 기존 RAG 문제점
- 검색된 문서가 사용자의 질문과 관련 없는 경우, 적절한 근거 문서가 없는 것일 수 있음
- 기존 Naive RAG의 경우 이러한 상황을 해결하지 못하는데, Corrective RAG에서는 웹검색 툴을 결합하여 이를 해결
-
Corrective RAG 개념
- 기본적으로 사용자의 질문에 대해 답하기 위해 VectorDB 내 문서 검색
- 만약 검색된 문서 중 몇몇이 사용자 질문과 관련 없는 경우, 사용자의 질문을 재작성하고 이를 기반으로 웹 검색을 활용하여 추가 데이터 확보
-
Corrective RAG 구조
- Corrective RAG State: 사용자의 질문, 답변, 웹검색 결과, VectorDB 검색 결과를 각각 question, geration, web_search, documents 키 값에 저장하는 틀로 GraphState 설정
- Corrective RAG Node(검색): 사용자 질문에 답할 수 있는 문서를 검색하는 노드
- Corrective RAG Node(답변 생성): Retriever에서 검색된 문서를 기반으로 사용자의 질문에 적절한 답변을 생성하는 노드
- Corrective RAG Node(문서 관련성 검토): Retriever를 통해 검색한 문서가 사용자의 질문과 관련있는지 검토하는 노드. 관련 있는 문서만 필터링하여 저장하고, 하나라도 관련 없는 문서가 있는 경우, 질문을 재작성하고 웹 검색 노드 진입
- Corrective RAG Node(질문 재작성): 만약 rewrite 노드로 진입한 경우, 사용자의 질문을 재가공하는 과정을 수행.재작성된 질문을 바탕으로 이후 웹 검색 활용
- Corrective RAG Node(웹 검색):검색된 문서가 하나라도 관련이 없는 경우, 추가 자료 확보를 위해 웹 검색 노드 진입. 이를 documents 키 값에 저장하여 답변 작성 시 활용하도록 보조
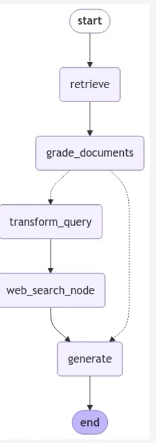
Adaptive RAG
-
Adaptive RAG 개념
- 위 3가지 RAG를 모두 합한 완전체
- 사용자의 질문이 어떤 유형이든지 상관 없이 유효한 답변을 생성하기 위한 적응형 RAG 시스템
- 특히 여러 벡터 DB를 관리하는 시스템이라면, 쿼리 의도 파악 과정에서 적절한 DB를 연결하여 올바른 답변 유도에 효과적
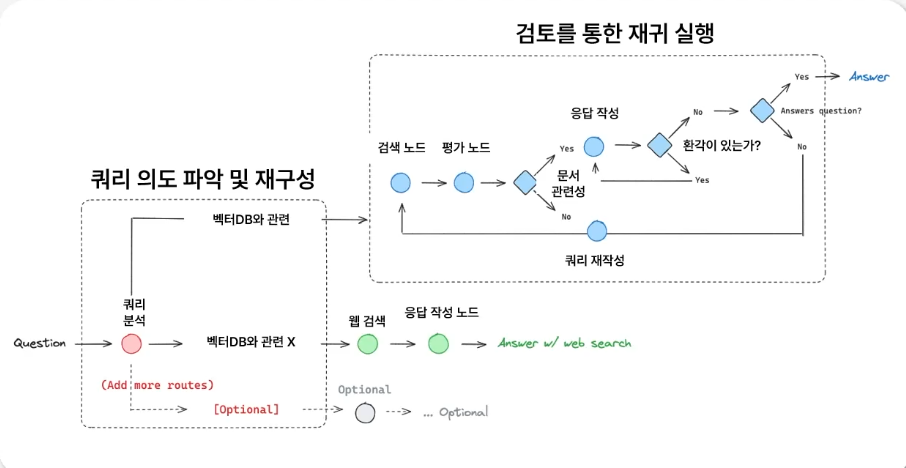
-
Adaptive RAG 구조
- Adaptive RAG State: 사용자의 질문, 답변 결과, 검색된 문서를 각각 question, generation, documents 키 값에 저장하는 틀로 GraphState 설정
- Adaptive RAG Node(검색): 사용자 질문에 답할 수 있는 문서를 검색하는 노드
- Adaptive RAG Node(사용자 질의 분석): 사용자의 질문을 보고 VectorDB와 웹 검색 중 어떤 Data source를 참고해야할지 결정하는 체인 구축. 이를 활용하여 conditional edge 분기 함수에 적용
- Adaptive RAG Node(문성 관련성 검토): Retriever를 통해 검색한 문서가 사용자의 질문과 관련있는지 검토하는 노드. 관련 있는 문서만 필터링하여 저장
- Adaptive RAG Node(답변 생성): Retriever에서 검색된 문서를 기반으로 사용자의 질문에 적절한 답변을 생성하는 노드
- Adaptive RAG Node(환각 검토): LLM이 작성한 답변에서 환각현상이 발생했는지 검토하고, 환각 현상이 없는 경우 "useful" / 그렇지 않은 경우 "not useful" 반환. 만약 환각 현상이 없는 경우, 답변 적절성을 검토하여 적절하지 않다고 판단된 경우 질문 재작성 노드로 진입
- Adaptive RAG Node(답변 적절성 검토): LLM이 직성한 답변이 사용자의 질문에 적절히 대응하는지 검토하는 역할을 수행, 만약 적절치 못한 경우 질문 재작성 노드로 진입
- Adaptive RAG Node(질문 재작성): 만약 rewrite 노드로 진입한 경우, 사용자의 질문을 재가공하는 과정을 수행. Retriever tool이 더 제대로된 검색을 수행할 수 있도록 보조
- Adaptive RAG Node(웹 검색):검색된 문서가 하나라도 관련이 없는 경우, 추가 자료 확보를 위해 웹 검색 노드 진입. 이를 documents 키 값에 저장하여 답변 작성 시 활용하도록 보조