FTAT(Fully test-time adaptation for tabular data) 적용
FTAT (Fully Test-time Adaptation for Tabular Data) 이란?
- 개념: 표 형식(Tabular) 데이터의 분포 변화(Distribution Shift) 문제를 해결하기 위해 고안된 테스트 시간 적응(TTA) 방법론 (AAAI 2025).
- 목적: 모델을 실제 환경(테스트)에 배포했을 때, 정답(Label) 없이 스트리밍되는 테스트 데이터(배치 단위)만으로 모델 파라미터를 실시간 업데이트(Online Adaptation)하여 성능 저하를 방어함.
- 특징: 이미지 데이터와 달리 데이터 증강(Augmentation)이 불가능한 표 데이터의 특성을 극복하기 위해, 3가지 핵심 모듈(CDO, LCW, DME)이 유기적으로 협력하여 작동함.
1. CDO (Confident Distribution Optimizer) : 거시적 라벨 분포 추정 및 확률 보정
- 목적: 학습 데이터 비율()에 갇힌 소스 모델의 '라벨 편향(Bias)'을 깨고, 현재 테스트 환경의 실제 클래스 비율()을 추정하여 예측 확률을 현실적으로 교정함.
- 동작 방식:
- 필터링: 모델의 원본 예측 확률 중 불확실성(엔트로피)이 낮아 모델이 강하게 확신하는 일부 정상 샘플만 추출함.
- 분포 추정: 추출된 샘플들을 바탕으로 공분산 행렬을 거쳐 편향을 제거한 타겟 라벨 분포 비율 (예: Non 40%, Pre 30%, Post 30%)를 계산함. (이전 배치의 비율과 지수이동평균(EMA)으로 누적 갱신함).
- 확률 보정 (Adjust): 계산된 를 모델의 원본 예측 확률에 곱하여(스케일링), 현실적인 비율로 교정된 확률()을 반환함. (이 단계에서는 모델의 파라미터를 직접 수정하지 않음).
2. LCW (Local Consistent Weighter) : 미시적 데이터 신뢰도 평가 및 샘플 가중치 산출
- 목적: 정답이 없는 상태에서, 어떤 샘플을 믿고 모델 학습에 반영할지 개별 데이터 샘플의 신뢰도 점수(가중치)를 결정함.
- 동작 방식:
- 이웃 탐색: 피처() 공간 상에서 유클리디안() 거리를 계산해, 서로 비슷한 물리량(가까운 거리)을 가지는 데이터들을 '이웃(Neighborhood)'으로 묶음.
- 일관성 검증: 특정 샘플의 예측값이 이웃들의 평균 예측값과 오차가 적다면(일관성을 만족한다면), 이를 노이즈가 아닌 '신뢰할 수 있는 데이터'로 판별함.
- 가중치 부여: 신뢰할 수 있는 샘플에는 예측 마진(Max 확률 - Min 확률)에 비례하는 높은 가중치()를 부여하고, 이웃과 동떨어진 이상치(Outlier)는 가중치를 0으로 처리함.
3. DME (Dynamic Model Ensembler) : 파라미터 업데이트 및 동적 앙상블
- 목적: CDO가 보정해 준 확률과 LCW가 매긴 가중치를 결합하여 모델의 파라미터(LayerNorm)를 실제로 업데이트(Loss 역전파)하고, 최종 예측을 도출함.
- 동작 방식:
- 모델 준비: 서로 다른 학습률(예: 1e-3, 1e-4 등)을 가진 개의 모델을 복제하여 유지함.
- Loss 계산 및 마스킹: 원본 확률이 아닌 CDO가 보정해 준 확률()을 바탕으로 엔트로피 손실(Loss)을 구함. 여기에 LCW가 산출한 개별 샘플 가중치()를 곱함. (이때, 신뢰도가 0인 샘플은 Loss가 0이 되어 학습에서 강제 배제됨).
- 역전파 (Update): 최종 산출된 Loss를 역전파(Backpropagation)하여 각 모델의 파라미터를 실시간으로 업데이트함.
- 최종 앙상블: 업데이트된 모델들 중, 현재 배치에서 오류(엔트로피)가 가장 적은 우수 모델에 가장 큰 비중을 두어 동적으로 가중 합산(Ensemble)한 후 최종 예측을 출력함.
전체 파이프라인 요약 (Data Flow)
정답을 모르는 추론 데이터가 배치(예: 512개) 단위로 들어오면 다음의 사이클이 반복됨.
- [LCW]가 개별 피처 거리를 비교해 모델 학습에 쓸만한 데이터인지 점수()를 매김.
- [CDO]가 정상 샘플만 모아 배치의 거시적 타겟 비율()을 구하고, 모델의 원본 예측을 현실적인 확률()로 교정함.
- [DME]가 CDO의 교정된 확률로 Loss를 구하고, LCW의 점수를 곱해 오답(신뢰도 0)은 버린 채 모델 가중치를 안전하게 수정(학습)하여 최종 앙상블 결과를 내놓음.
FTAT 적용
코드 (모듈별 분리 및 설명)
1. 전역 설정 및 데이터셋
- 모델 추론에 필요한 경로 및 하이퍼파라미터를 설정함.
GalaxyDataset은 TTA 과정에서 정답(Label) 없이 피처(X)와 도메인 지식(P_NOMERGER)만 반환하도록 구성함.
import os
import copy
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
# (경로 설정 및 하이퍼파라미터 생략 - 기존 코드와 동일)
FTAT_CONFIG = {
"batch_size" : 512,
"learning_rates": [1e-3, 1e-4, 5e-4, 1e-5],
"alpha" : 0.10,
"epsilon_p" : 0.70,
"beta" : 0.30,
}
class GalaxyDataset(Dataset):
"""레이블 없이 피처와 도메인 확률(P_NOMERGER)을 반환하는 TTA 전용 데이터셋"""
def __init__(self, X, p_nomerger):
self.X = torch.tensor(X, dtype=torch.float32)
self.p_nomerger = torch.tensor(p_nomerger, dtype=torch.float32)
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.p_nomerger[idx]2. 모델 로드 및 TTA 설정
- TTA 진행 시 모델 전체를 재학습하면 과적합(Collapse)이 발생할 수 있음.
- 따라서
configure_for_tta함수를 통해 전체 파라미터는 동결(Freeze)하고, 데이터의 분포를 맞추는 데 핵심적인 역할을 하는 LayerNorm의 파라미터만 학습되도록 해제함.
def configure_for_tta(model: nn.Module) -> nn.Module:
"""모든 파라미터를 동결하고 LayerNorm의 파라미터만 업데이트 허용"""
model.train()
for param in model.parameters():
param.requires_grad_(False)
for module in model.modules():
if isinstance(module, nn.LayerNorm):
module.train()
for param in module.parameters():
param.requires_grad_(True)
return model
def tta_params(model: nn.Module):
return [p for p in model.parameters() if p.requires_grad]3. 모듈 1: CDO (Confident Distribution Optimizer)
- 배치의 예측 엔트로피를 계산하여 확신도(Confidence)가 높은 샘플만 선별함.
- 이 샘플들을 바탕으로 편향을 제거한 타겟 라벨 분포(
P_hat)를 시간적 EMA(지수 이동 평균) 방식으로 갱신함.
def batch_entropy(probs: torch.Tensor) -> torch.Tensor:
return -(probs * (probs.clamp(min=1e-8)).log()).sum(dim=1)
class ConfidentDistributionOptimizer:
def __init__(self, num_classes, P0, alpha, epsilon_p):
self.K = num_classes
self.P0 = P0.clone()
self.P_hat = P0.clone()
self.alpha = alpha
self.epsilon = -(epsilon_p * np.log(epsilon_p) + (1 - epsilon_p) * np.log(1 - epsilon_p))
def update(self, probs: torch.Tensor) -> None:
ent = batch_entropy(probs)
mask = ent < self.epsilon
if mask.sum() == 0: return
conf = probs[mask]
P_tilde = conf.mean(dim=0)
C_hat = torch.zeros(self.K, self.K, device=probs.device)
pred_cls = probs.argmax(dim=1)
for k in range(self.K):
km = pred_cls == k
C_hat[k] = probs[km].mean(dim=0) if km.sum() > 0 else torch.eye(self.K, device=probs.device)[k]
try: unbiased = torch.linalg.solve(C_hat, P_tilde)
except Exception: unbiased = P_tilde
self.P_hat = (1 - self.alpha) * self.P_hat + self.alpha * unbiased
self.P_hat = torch.softmax(self.P_hat, dim=0)
def adjust(self, probs: torch.Tensor) -> torch.Tensor:
ratio = self.P_hat / (self.P0.to(probs.device) + 1e-8)
adjusted = probs * ratio.unsqueeze(0)
return adjusted / (adjusted.sum(dim=1, keepdim=True) + 1e-8)4. 모듈 2: LCW (Local Consistent Weighter)
- 배치 내 데이터 간의 쌍별(Pair-wise) 거리를 계산하여 이웃을 정의함.
- 특정 샘플의 예측값이 이웃들의 평균 예측값과 유사할 경우(일관성 만족), 해당 샘플의 예측 마진값을 가중치로 반환하여 모델 학습에 적극 반영함.
class LocalConsistentWeighter:
def __init__(self, beta: float = 0.30):
self.beta = beta
def compute_weights(self, X: torch.Tensor, probs: torch.Tensor) -> torch.Tensor:
N = X.shape[0]
diff = X.unsqueeze(1) - X.unsqueeze(0)
dist_mat = diff.pow(2).sum(dim=2).clamp(min=0).sqrt()
triu_idx = torch.triu_indices(N, N, offset=1)
dist_thresh = dist_mat[triu_idx[0], triu_idx[1]].mean()
margin = probs.max(dim=1).values - probs.min(dim=1).values
weights = torch.zeros(N, device=X.device)
for k in range(N):
nbr_mask = (dist_mat[k] < dist_thresh)
nbr_mask[k] = False
if nbr_mask.sum() == 0:
weights[k] = margin[k]
continue
nbr_mean = probs[nbr_mask].mean(dim=0)
consistency = torch.norm(probs[k] - nbr_mean)
is_consistent = (consistency < self.beta).float()
weights[k] = margin[k] * is_consistent
return weights5. 모듈 3: DME (Dynamic Model Ensembler)
- 서로 다른 학습률(
learning_rates)을 가진 기본 모델들을 유지하며 동시에 업데이트함. - 각 배치를 처리할 때 엔트로피 손실이 낮은(성능이 좋은) 모델의 예측값에 더 큰 가중치를 부여해 동적으로 앙상블함.
class DynamicModelEnsembler:
def __init__(self, source_model, learning_rates):
self.M = len(learning_rates)
self.models, self.optims = [], []
for lr in learning_rates:
m = configure_for_tta(copy.deepcopy(source_model))
opt = optim.AdamW(tta_params(m), lr=lr, weight_decay=1e-4)
self.models.append(m)
self.optims.append(opt)
def _model_weights(self, X):
losses = []
with torch.no_grad():
for m in self.models:
m.eval()
losses.append(batch_entropy(torch.softmax(m(X), dim=1)).mean().item())
m.train()
losses = np.array(losses, dtype=np.float64)
span = losses.max() - losses.min()
norm = (losses - losses.min()) / span if span > 1e-8 else np.zeros(self.M)
w = 1.0 - norm
return w / (w.sum() + 1e-8)
def step(self, X, cdo, lcw):
mw = self._model_weights(X)
self.models[0].eval()
with torch.no_grad():
proxy_probs = torch.softmax(self.models[0](X), dim=1)
self.models[0].train()
sample_w = lcw.compute_weights(X.detach(), proxy_probs.detach())
cdo.update(proxy_probs.detach())
all_adj_probs = []
for m, opt in zip(self.models, self.optims):
m.train()
probs = torch.softmax(m(X), dim=1)
adj_probs = cdo.adjust(probs)
ent = batch_entropy(adj_probs)
loss = (sample_w * ent).sum() / sample_w.sum().clamp(min=1e-8)
opt.zero_grad()
loss.backward()
opt.step()
m.eval()
with torch.no_grad():
all_adj_probs.append(cdo.adjust(torch.softmax(m(X), dim=1)))
ensemble = torch.zeros_like(all_adj_probs[0])
for w, p in zip(mw, all_adj_probs):
ensemble += w * p
return ensemble, mwFTAT 적용 전 (Vanilla Inference) 결과
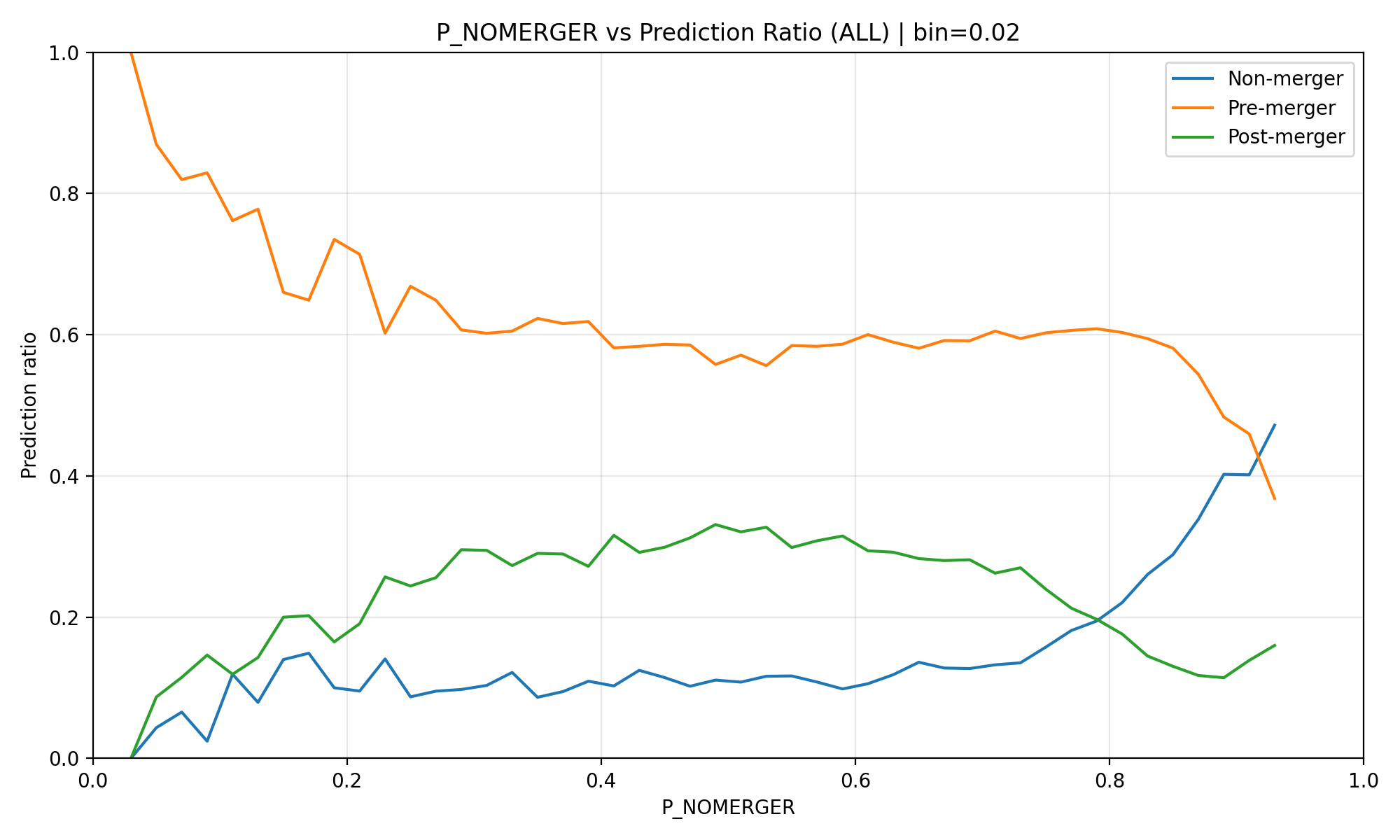
- TTA 적용 전, 전체 데이터 분포 및 확신도(Confidence 0.8) 필터링 결과임.
- conf 전체
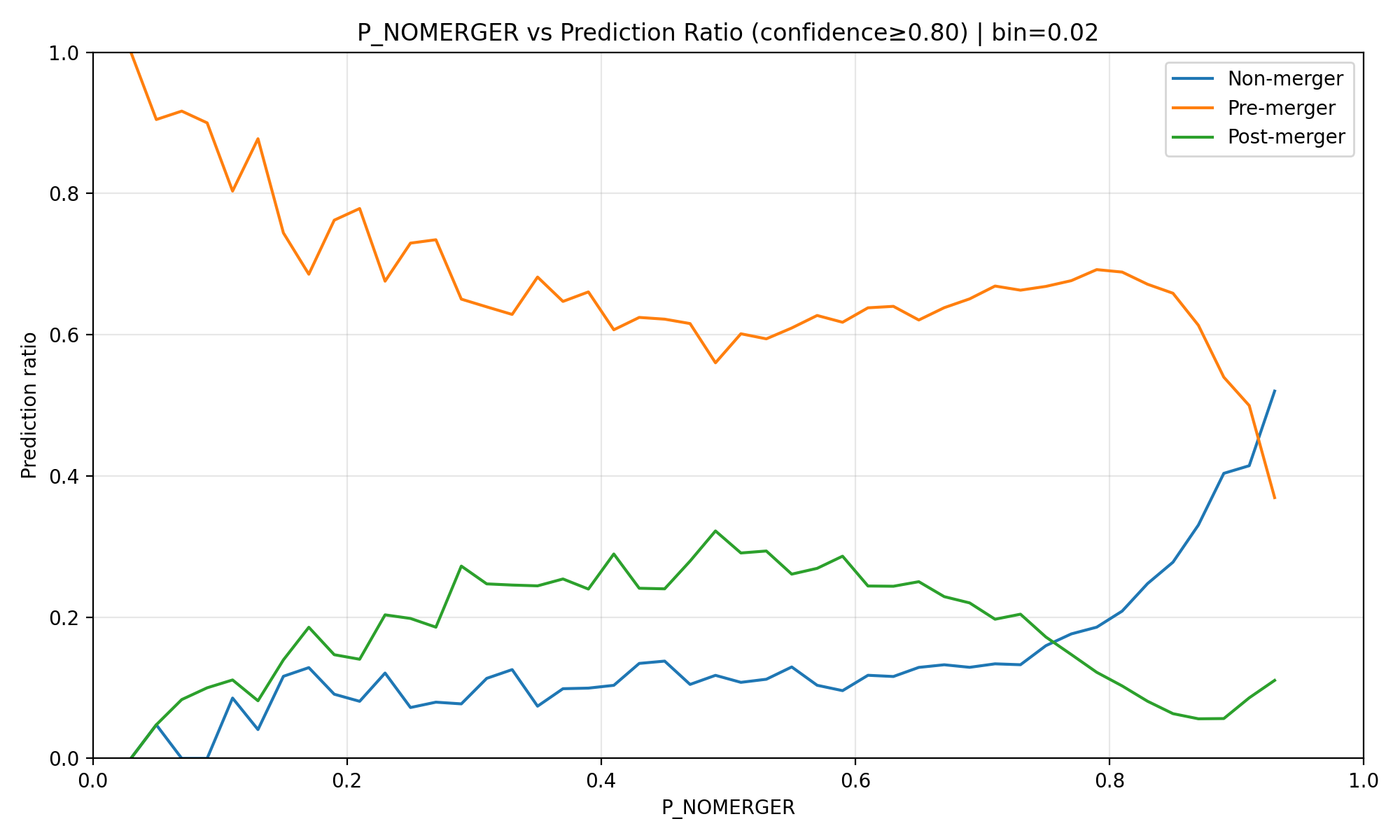
- conf 0.8
FTAT 적용 후 (초기) 결과
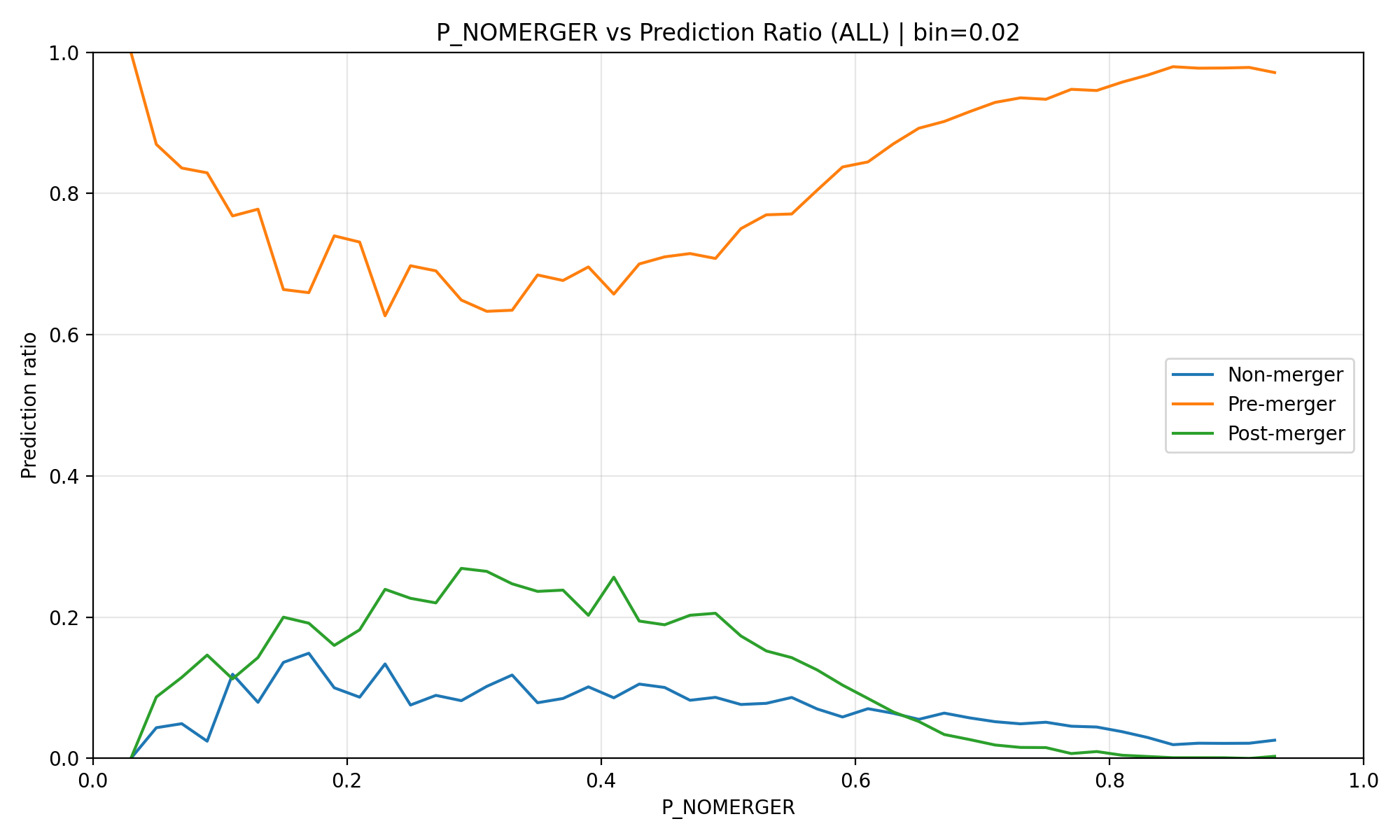
- 결과 분석 (망함): - 기본 추론(Vanilla Inference) 자체가 conf가 높아도 전체 데이터와 비슷하게 좋지 않음
- 결국 모델의 잘못된 확신이 반복되면서 확증 편향(Confirmation Bias)이 발생, 그래프가 완전히 붕괴함.
- 해결 방안: - 모델의 통계적 확신도(
conf)에만 의존하지 않고, 물리적 도메인 지식(P_NOMERGER)을 필터링 조건으로 함께 사용하여 논리적으로 타당한 샘플만 학습에 사용하도록 로직을 수정함.
해결 방안 적용 코드
기존 코드에서 CDO의 라벨 분포 갱신 로직과 DME의 모델 업데이트 로직에 도메인 지식 필터를 추가함.
1. CDO 업데이트 로직 변경 (이중 필터링)
- 단순 엔트로피 조건뿐만 아니라,
P_NOMERGER값이 논리적 기준(Non-merger는 높게, Pre/Post는 낮게)에 부합하는 샘플만 라벨 분포(P_hat) 추정에 사용함.
# ConfidentDistributionOptimizer 모듈 내부
def update(self, probs: torch.Tensor, p_nom_batch: torch.Tensor) -> None:
ent = batch_entropy(probs)
conf_mask = ent < self.epsilon # 1차: 모델 확신도 조건
pred_cls = probs.argmax(dim=1)
logical_mask = torch.zeros_like(conf_mask, dtype=torch.bool)
is_non_merger = (pred_cls == 0)
is_merger = (pred_cls != 0)
# 2차: 도메인 지식(P_NOMERGER) 조건
logical_mask[is_non_merger] = p_nom_batch[is_non_merger] >= self.th_high
logical_mask[is_merger] = p_nom_batch[is_merger] <= self.th_low
final_mask = conf_mask & logical_mask # 이중 필터링 교집합
if final_mask.sum() == 0: return
conf = probs[final_mask]
# ... 이하 기존 C_hat 및 P_hat 갱신 로직 동일2. DME 모델 학습 로직 변경 (Loss 마스킹)
- 물리적으로 말이 안 되는 예측(예: P_NOMERGER가 0.9인데 Pre-merger로 확신)을 하는 샘플은 아예 엔트로피 손실(Loss) 계산에서 배제(
masked_sample_w)시켜, 모델이 꼼수로 학습하는 것을 방어함.
# DynamicModelEnsembler 모듈 내부 step 함수
def step(self, X: torch.Tensor, p_nom_batch: torch.Tensor, cdo, lcw):
# ... (proxy_probs 추출 및 lcw, cdo.update 적용)
is_non_merger = (proxy_pred_cls == 0)
is_merger = (proxy_pred_cls != 0)
# Loss 계산을 위한 도메인 논리 마스크 생성
loss_logical_mask = torch.zeros_like(proxy_pred_cls, dtype=torch.bool)
loss_logical_mask[is_non_merger] = p_nom_batch[is_non_merger] >= cdo.th_high
loss_logical_mask[is_merger] = p_nom_batch[is_merger] <= cdo.th_low
# LCW 가중치에 논리 마스크를 씌워 논리에 안 맞는 샘플 가중치를 0으로 만듦
masked_sample_w = sample_w * loss_logical_mask.float()
# ... (이하 모델별 루프)
ent = batch_entropy(adj_probs)
denom = masked_sample_w.sum().clamp(min=1e-8)
loss = (masked_sample_w * ent).sum() / denom # 마스킹된 샘플로만 학습
if masked_sample_w.sum() > 0:
opt.zero_grad()
loss.backward()
opt.step()
# ... 해결 방안 적용 inference 결과
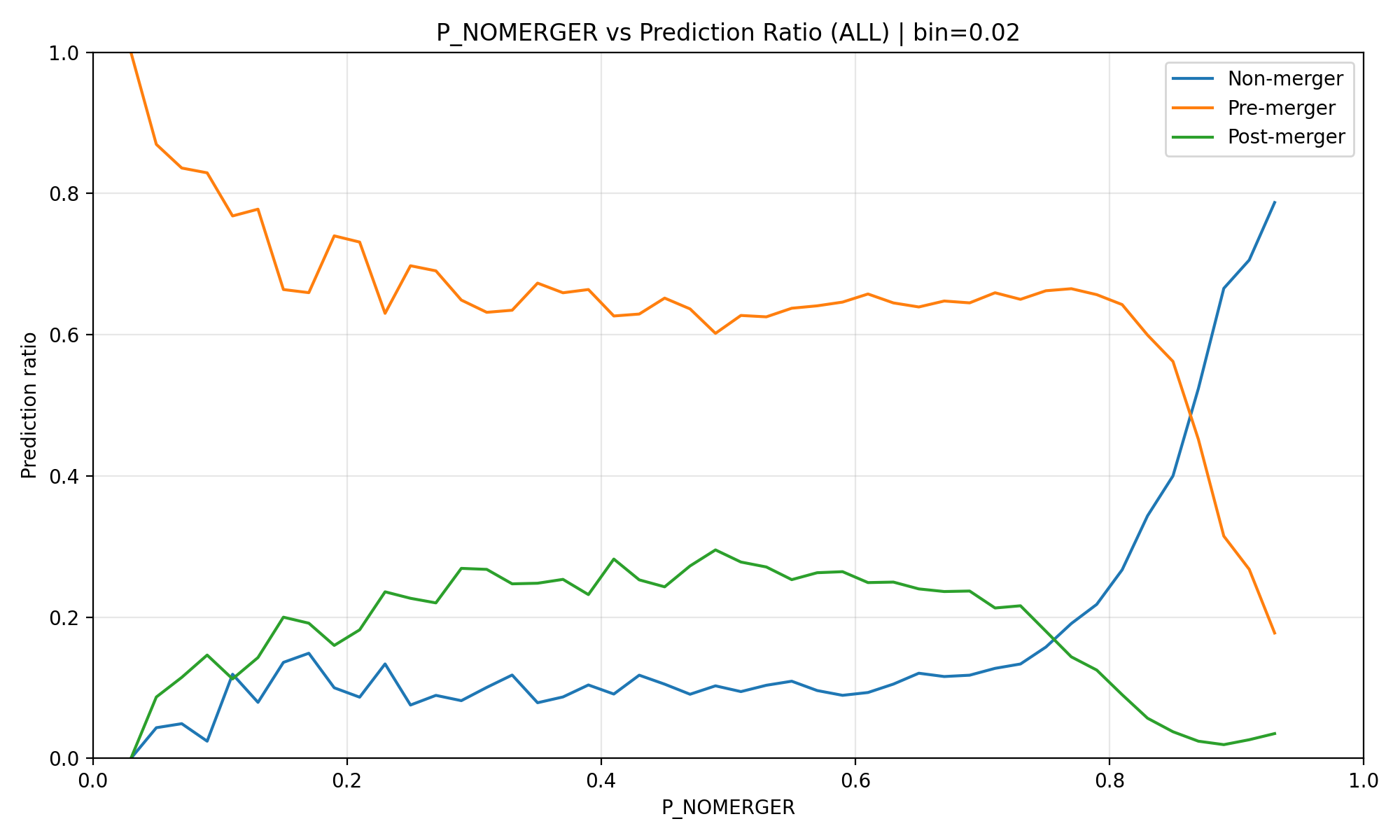
- 도메인 지식 마스킹을 추가한 결과, TTA가 확증 편향에 빠지는 현상을 막아내며 이전보다 훨씬 타당한 예측 분포를 형성함.
- 하지만 여전히 P_NONMERGER가 낮을 때 post merger가 낮음
⚠️ 논의 및 한계점 (주의 사항)
위와 같이 도메인 지식(P_NOMERGER)을 직접 Loss 필터링에 개입시키는 것은 결과적으로 모델의 분류 성능을 크게 높일 수 있으나, 연구 논리를 전개할 때 데이터 누수(Data Leakage) 또는 오라클(Oracle) 개입의 비판을 받을 소지가 있음. 따라서 연구의 '최종 목적'에 따라 두 가지 방향 중 하나로 논리를 디펜스해야 함.
-
방향성 1: 순수 알고리즘 중심 (Unsupervised TTA)
- 외부 힌트 없이 타겟 데이터 분포에 적응하는 순수 TTA 알고리즘의 성능 입증이 목적일 경우.
P_NOMERGER를 활용한 Loss 마스킹을 제거해야 함.- 대신 모델이 다수 클래스로 붕괴하는 현상을 막기 위해, 다양성 손실(Diversity Loss, ex. KL Divergence)과 같은 표준 비지도 정규화 기법을 도입하여 모델 스스로 분포 밸런스를 맞추도록 유도해야 함.
-
방향성 2: 도메인 문제 해결 중심 (Physics-Informed / Weakly-Supervised)
- 시뮬레이션 데이터(IllustrisTNG)와 실제 관측 데이터(DESI) 간의 극심한 도메인 갭(Domain Gap)을 극복하고, 현실에서 작동하는 견고한 분류 파이프라인 구축이 목적일 경우.
- 순수 피처 기반의 비지도 학습이 가지는 태생적 한계를 인정하고, 천문학적 지표(
P_NOMERGER)를 약지도 학습(Weakly-Supervised Learning)의 가이드라인으로 주입하여 모델을 올바른 물리적 공간으로 견인한 '물리 지식 융합 모델링'으로 디펜스함.
