스택
- Last In, First Out :
LIFO라고도 함
가장 마지막에 삽입된 데이터가 가장 먼저 추출됨(하노이의 탑, 쌓여있는 접시로 비유)
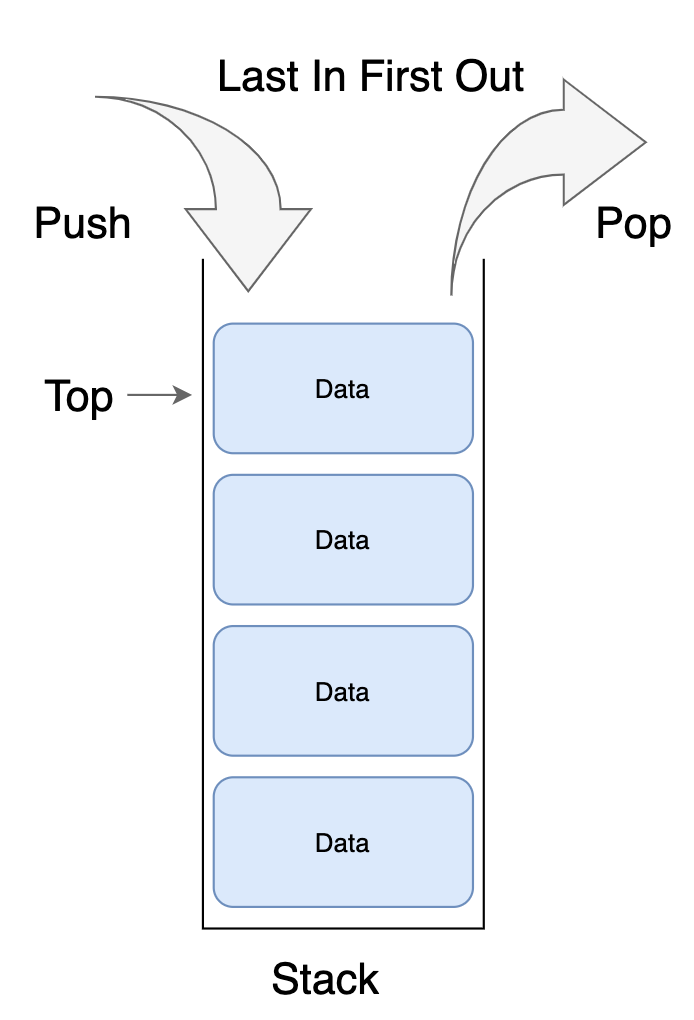
이는 파이썬의 기본 list로 구현 가능
-
값을 삽입(push)할 때는 lst.append() -> 시간복잡도 O(1)
-
값을 삭제할 때는 lst.pop()으로 구현 -> 시간복잡도 O(1)
- 인덱스를 지정해서 값을 삭제할 때는 lst.pop(0)으로 구현 -> 시간복잡도 O(n)
-
값을 탐색할 때는 시간복잡도 O(n)
-
DFS(길이 우선 탐색) 알고리즘
스택 구현
VSCODE에서 위의 내용을 구현해보았다.
INPUTlst = [] lst.append(1) lst.append(2) lst.append(3) lst.append(4) lst.append(5) lst.append(6) print(lst) print(lst.pop()) print(lst)
OUTPUT[1, 2, 3, 4, 5, 6] 6 [1, 2, 3, 4, 5]
큐
- First In, First Out :
FIFO라고도 함, 선입선출
가장 먼저 삽입된 데이터가 가장 먼저 추출됨(대기표, 마트 결제 줄)
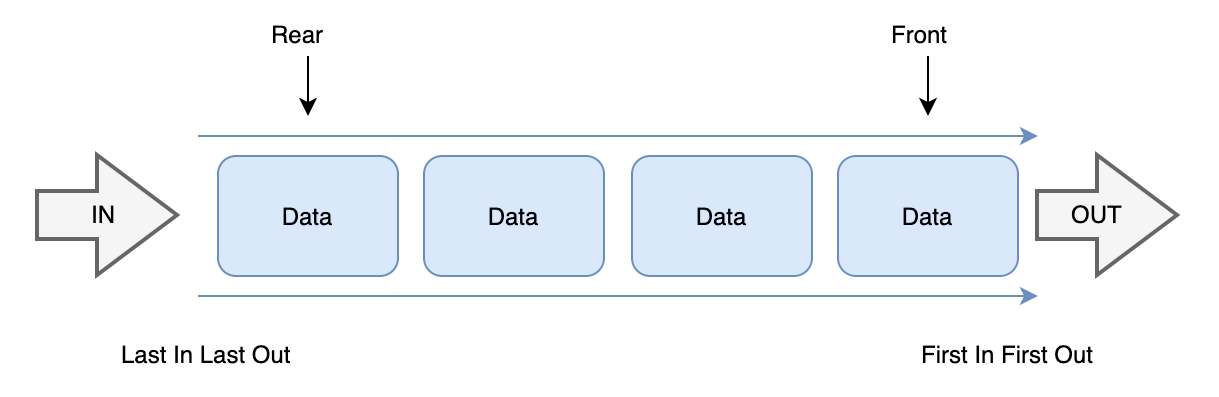
-
큐로 데이터를 삽입(push)하는 연산을 enqueue라 하고, 큐에서 데이터를 처리하는 연산은 dequeue라 함
-
파이썬에서는 기본으로 제공해주는 라이브러리
deque를 사용해서 큐를 구현 가능 -
값을 삽입(push)할 때는 queue.append() -> 시간복잡도 O(1)
-
값을 삭제할 때는 queue.popleft() -> 시간복잡도 O(1)
- queue.pop() -> 시간복잡도 O(n)
-
값을 탐색할 때는 시간복잡도 O(n)
-
BFS(너비 우선 탐색) 알고리즘
큐 구현
VSCODE에서 위의 내용을 구현해보았다.
INPUTfrom collections import deque lst = [1,2,3,4,5,6] queue = deque(lst) print(queue) queue.append(7) print(queue.popleft()) print(queue)
OUTPUTdeque([1, 2, 3, 4, 5, 6]) 1 deque([2, 3, 4, 5, 6, 7])
-
파이썬에서 queue를 print 문으로 출력하면 list 형식이 아닌 deque 형식으로 출력되는 것을 볼 수 있음
-
queue에서 popleft를 하면 맨 먼저 입력된 1 이 반환됨
-
queue에서도 pop을 사용할 수 있지만, 시간복잡도는 O(n)이라 비추천 !
우선순위 큐(Priority Queue)
일반적인 큐(Queue) 자료구조는 FIFO 구조
일반적인 큐가 먼저 들어온 데이터를 먼저 처리하는 구조라면, 우선순위 큐는 우선순위에 따라 우선순위가 높은 데이터를 먼저 처리하는 구조 !
* 4, 6, 3, 1, 2 순으로 데이터가 들어오고 각각의 숫자를 우선순위라 할 때
1) 4가 큐에 들어옴. 4가 현재 큐에서 우선순위가 제일 높음
2) 6이 큐에 들어옴. 6은 4보다 우선순위가 높으므로 6,4 순서로 정렬
3) 3이 큐에 들어옴. 3은 앞에 있는 두 데이터보다 우선순위가 낮으므로 변화 X
4) 1이 큐에 들어옴. 1도 앞에 있는 세 데이터보다 우선순위가 낮으므로 변화 X
5) 2가 큐에 들어옴. 2는 1보다 우선순위가 크므로 자리 교체 -
이렇게 우선순위를 고려해 큐에 삽입하면 [6,4,3,2,1]의 정렬된 리스트를 얻게 되고, 이를 순서대로 처리하면 우선순위에 맞게 데이터를 처리하는 것 !
-
이 과정에서 뒤에 위치하게 될 데이터들을 모두 한 칸씩 뒤로 밀어야 한다는 단점
-
삽입해야 하는 위치를 찾기 위해 모든 인덱스를 탐색해야 할 수 있으므므로 데이터가 n개면 O(n)의 시간복잡도를 가짐
-
이런 점들을 보완하기 위해 우선순위 큐를 구현할 때는 힙(Heap) 자료구조를 사용함 !
-
힙(Heap)
-
힙은 최대/최소값을 찾는데 최적화된 자료구조
-
힙은 기본적으로 완전 이진 트리 = 무조건 왼쪽 자식 노드부터 데이터 삽입
-
힙은 데이터의 중복을 허용
최대 힙(Max Heap)
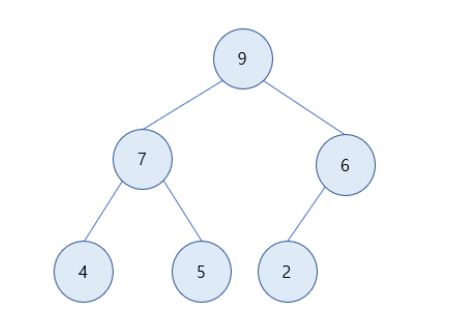
- 최대 힙은 루트노드가 가장 큰 값을 가지고, 부모노드가 항상 자식노드보다 값이 크거나 같다.
최소 힙(Min Heap)
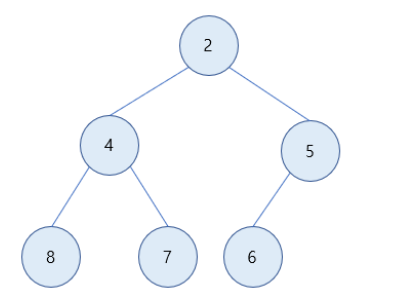
-
최소 힙은 루트노드가 가장 작은 값을 가지고, 부모노드가 항상 자식노드보다 값이 작거나 같다.
-
파이썬에서는 기본적으로 heap이 최소 힙 !
-
값을 삽입(push)할 때는 heap.heappush(lst, input할 값)
- 트리의 높이만큼 삽입할 자리를 찾아 넣어야 하므로 시간복잡도가 O(log n)임
-
값을 삭제할 때는 heap.heappop(lst)
- 시간복잡도 O(1), 루트노드부터 삭제 반환함(파이썬에서는 가장 작은 값) -> 하지만 삭제 시 최소힙의 조건이 깨져 노드 위치를 바꾸는 과정이 필요하므로 최종적으로 O(log n)의 시간 복잡도를 가짐
힙의 구현
VSCODE에서 위의 내용을 구현해보았다.
INPUTimport heapq as h a = [] h.heappush(a,2) h.heappush(a,4) h.heappush(a,5) h.heappush(a,8) h.heappush(a,7) h.heappush(a,6) print(a) h.heappush(a,1) print(a) h.heappop(a) print(a)
OUTPUT[2, 4, 5, 8, 7, 6] [1, 4, 2, 8, 7, 6, 5] [2, 4, 5, 8, 7, 6]
힙 삽입
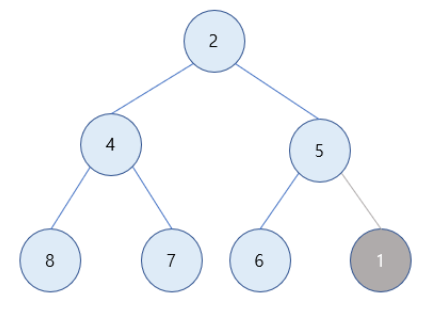
1) 1을 최소힙([2,4,5,8,7,6]에 삽입 시, 힙은 완전 이진 트리이므로 삽입 시에도 이를 유지해 완전 이진 트리를 만족하는 자리에 1 값이 삽입 !
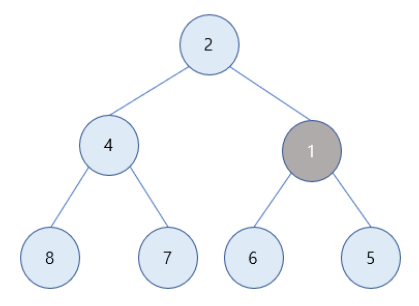
2) 1은 값이 5인 부모노드보다 값이 작으므로 최소힙의 성질을 만족하기 위해 부모노드와 자리를 바꿔줌
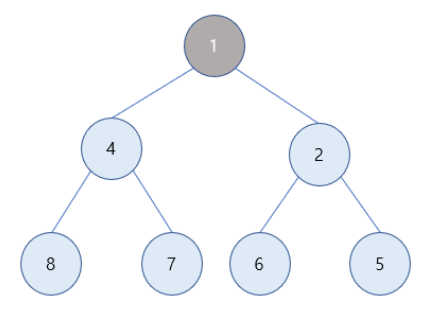
3) 1은 값이 2인 부모노드보다 값이 작으므로 최소힙의 성질을 만족하기 위해 부모노드와 자리를 바꿔줌
힙 삭제
- 최소 힙에서의 삭제는 값이 제일 작은 노드 = 루트 노드의 삭제를 의미
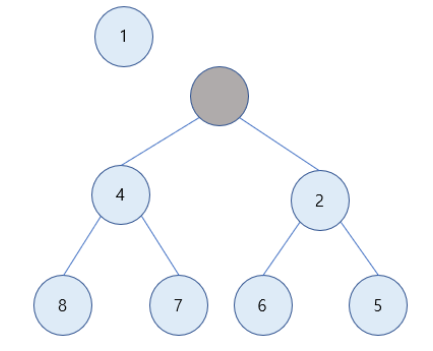
1) 1 값을 가진 노드 삭제
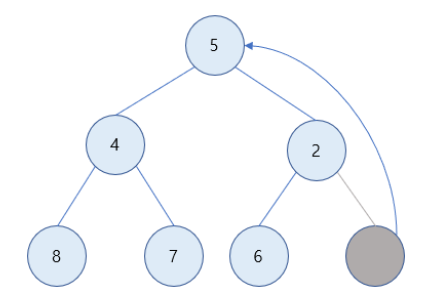
2) 루트 노드가 비게 되어, 이를 마지막 노드가 채움
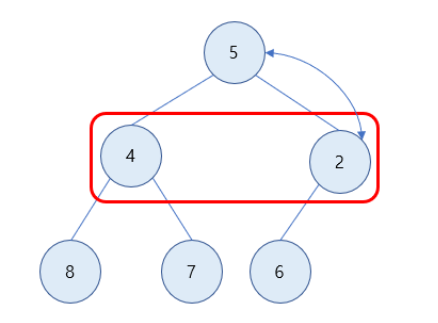
3) 자식 노드 값이 더 작으므로 값을 교환해주기 위해 더 작은 값을 구함. 2가 4보다 더 작으므로 2의 값을 가진 노드와 루트 노드의 자리를 바꿈
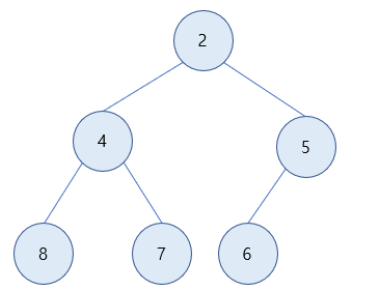
4) 최소 힙을 만족해 삭제가 종료됨
참고
https://c4u-rdav.tistory.com/34
https://c4u-rdav.tistory.com/14
