오늘부터 코딩테스트 대비를 위한 알고리즘 공부를 시작할 예정이다. 👊👊
먼저 알고리즘 개념에 대해서 벨로그에 정리->백준/프로그래머스 코테를 풀 계획 !
알고리즘의 종류들은 다음과 같이 프로그래머스 고득점 kit에 있는 알고리즘들이다 !!
😎 자료구조와 알고리즘
자료구조와 알고리즘의 차이에 대한 내용은 여기에서 확인할 수 있었다.
자료구조: 자료를 담는 구조. 데이터가 저장된 형태를 결정하는 것이 자료구조. 선형, 비선형, 파일구조가 있다. 어떻게 효율적으로 자료를 저장할 것인가에 대한 고민이 필요하다.
알고리즘: 어떤 문제를 해결하기 위한 방법. 문제 풀이에 대한 계산절차 또는 처리과정의 순서를 뜻한다. 문제를 해결하기 위한 절차에 대한 고민이 필요하다.
🐤 해시란 ?
첫번째로 정리할 알고리즘인 해시(Hash)란 임의의 크기를 가진 데이터를 고정된 크기의 데이터로 변환시키는 것을 말한다. 이를 통해 특정한 데이터의 검색과 저장을 빠르게 할 수 있다.
Direct Addressing Table
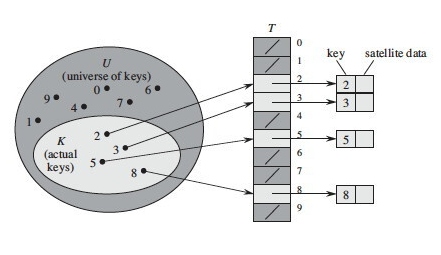
Direct Addressing Table은 key-value쌍의 (배열에 저장할) key값을 직접적으로 배열의 인덱스로 사용하는 방법이다. 똑같은 키 값이 존재하지 않는다고 가정하고, 삽입 시에는 각 key마다 자신의 공간이 존재하므로 해당 위치에 저장하면 되고, 삭제 시에는 해당 key의 위치에 null값을 넣어주면 된다. 탐색 시에는 해당 키의 위치를 그냥 찾아가서 참조하면 되므로, 탐색 삭제 저장 갱신 모두 O(1)의 빠른 속도로 처리가 가능하다.
다만 최대 key값만큼 배열의 크기가 결정되므로, 배열의 크기가 매우 큰데 저장하고자 하는 데이터는 적다면 공간 낭비의 단점이 발생한다.
Hash Table
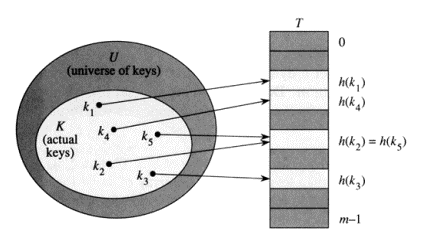
Hash Table은 key-value쌍의 key값을 테이블에 저장할 때, 앞선 Direct Addressing Table과 달리 key값을 함수를 이용해 계산한 후, 그 결과값을 배열의 인덱스로 사용해 저장하는 방식이다. 여기서 key값을 계산하는 함수를 해시 함수(Hash Function)라고 부르며, 해시 함수는 입력으로 key값을 받아 0부터 len(배열)-1 사이의 값을 출력한다.
이는 위에서 언급한 해시의 정의인 임의의 숫자를 배열의 크기만큼으로 변환시킨다는 의미 ! 이 경우 k값이 h(k)로 해시되었다고 하며, h(k)는 k의 해시값이라고 한다.
Hash Table은 앞선 Direct Addressing Table보다 공간낭비가 적은데, 이는 key값의 최대값에 테이블의 크기가 좌우되는 것이 아닌 h(k)만큼의 공간에 저장되기 때문이다.
하지만 Hash Table은 "충돌(collusion)"이 일어날 수 있다는 문제점이 존재한다. 위의 사진에서와 같이 다른 k값인 k2와 k5의 해시값이 동일한 경우이다. h(k2)=h(k5), 이러한 충돌을 최소화하는 것이 Hash Table에서 중요한 문제이다.
Separate Chaining 방식
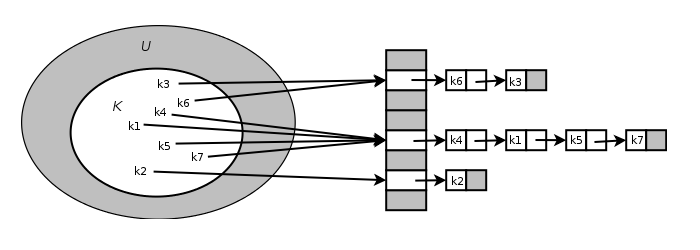
Chaining 방식은 충돌을 허용하지만 이를 최소화하기 위한 방법 중 하나이다. Hash Table에서 동일한 해시값이 출력해 충돌이 일어나면 그 위치에 있던 key값을 뒤이어 연결한다. 따라서 최초로 h(k)에 저장된 데이터 이후 출력되는 데이터는 모두 linkedlist의 형태를 취한다.
즉, 최초의 위치를 탐색하는 해시 과정 이후에는 모든 탐색, 삽입, 삭제 과정은 연결리스트와 유사한 방식으로 진행된다. 최악의 경우, 모든 데이터의 해시값이 일치하여 한 인덱스에 저장될 경우에는 연결리스트의 탐색 시간과 동일한 선형시간을 갖는다.
Open Addressing
Open Adressing은 인덱스의 충돌이 일어났을때 linkedlist와 같은 추가적인 메모리를 사용하지 않고, Hash Table 배열의 빈 공간을 활용하는 방법이다. 추가적인 메모리 공간을 사용하기 위해 chaining방식에 비해 메모리를 덜 사용하며, Linear Probing, Quadratic Probing, Double hashing 등의 방식이 존재한다.
Linear Probing
Linear Probing이란 인덱스의 충돌이 발생할때, 해당 인덱스 다음 비어있는 인덱스에 데이터를 저장하는 방식이다. 충돌이 일어나지 않을때까지 다음 인덱스로 이동을 해가며 빈 공간을 찾아 저장하는 것이다.
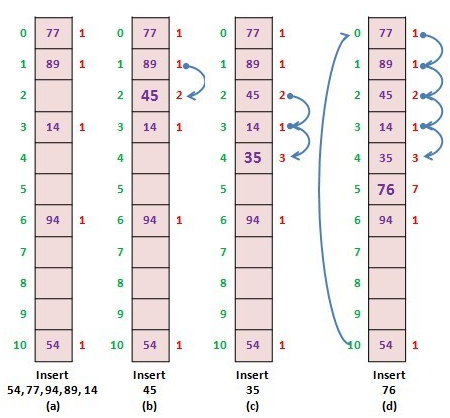
이때 해시 함수는 h(k,i) = (k+i) mod m, i는 충돌횟수
이는 구현이 용이하지만, 충돌이 자주 발생하는 위치 즉 특정 위치에만 데이터가 밀집해 탐색 시간이 굉장히 증가하게 되는 단점이 있다.
Quadratic Probing
Quadratic Probing이란 인덱스의 충돌이 발생할때, 해당 인덱스에서 충돌이 발생한 횟수의 제곱만큼을 더한 위치의 인덱스에 데이터를 저장하는 방식이다.
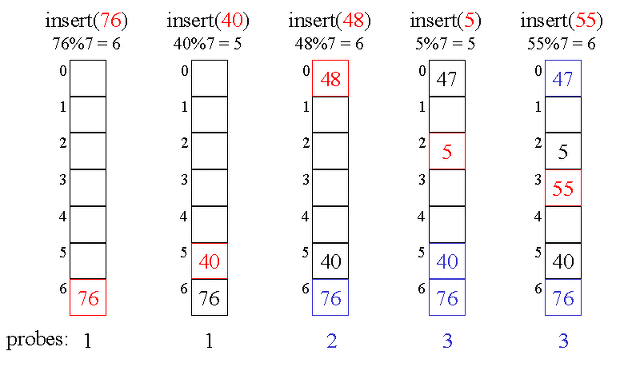
이때 해시 함수는 h(k,i) = (k+i^2) mod m, i는 충돌횟수
이는 처음 시작하는 해시값이 동일하면 그 이후의 해시값도 계속 충돌이 반복적으로 일어난다는 단점이 있다.
Double hashing
Double hashing이란 인덱스의 충돌이 발생할때, 다른 해시 함수를 한번 더 적용해 해시값을 구하는 방식이다.
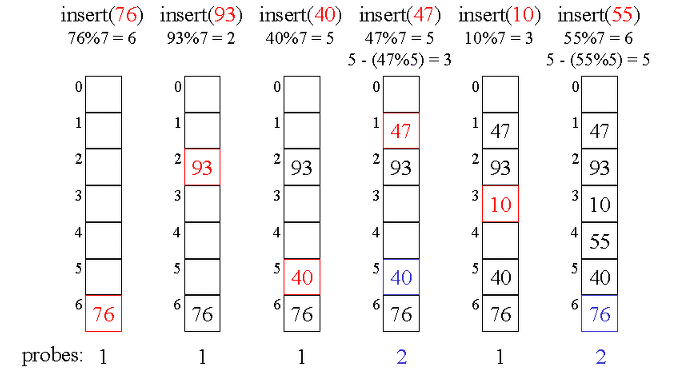
이때 해시 함수는 h1(k) = k mod m1, h2(k) = k mod m2, h(k,i) = (h1(k)+i*h2(k)) mod m, i는 충돌횟수
✏️ python에서 해시를 구현하는 방식: dictionary
해시를 사용하면 좋은 경우 !
1. 리스트를 쓸 수 없을 때
리스트는 숫자 인덱스를 이용하여 원소에 접근하는데 즉 list[1]은 가능하지만 list['a']는 불가능하다. 인덱스 값을 숫자가 아닌 다른 값 '문자열, 튜플'을 사용하려고 할 때 딕셔너리를 사용하기 !
2. 빠른 접근/탐색이 필요할 때
딕셔너리 함수의 탐색, 삭제, 삽입의 시간복잡도는 대부분 O(1)이므로 아주 빠른 자료구조
3. 집계가 필요할 때
코테에서 많이 출제되는 원소의 개수를 세는 문제. 이때 해시와, collections 모듈의 Counter 클래스를 사용하기 !
dictionary 사용법
- 탐색
my_dict = {'a':1, 'b':2}
my_dict['a'] #1
my_dict.get('a', 0) #1
my_dict.get('c', 0) #0 -> dict안에 없을 경우 0 반환- 삽입
my_dict = {'a':1, 'b':2}
my_dict['c'] = 3
my_dict # {'a':1, 'b':2, 'c':3}- 삭제
my_dict = {'a':1, 'b':2}
del my_dict['a']
my_dict # {'b':2}
my_dict.pop('a',100) #100 -> dict안에 없을 경우 100 반환- 순회
my_dict = {'a':1, 'b':2}
for i in my_dict:
print(i) # a \n b -> key값만 반환
my_dict = {'a':1, 'b':2}
for key,value in my_dict.items():
print(key, value) # a 1 \n b 2-> key, value 둘다 반환- 값 존재 여부 확인
my_dict = {'a':1, 'b':2}
print('a' in my_dict) #True
print('a' not in my_dict) # False- key 또는 value값만 빼오기
my_dict = {'a':1, 'b':2}
my_dict.keys() # dict_keys(['a', 'b'])
my_dict.values() # dict_values(['1', '2'])
my_dict.items() # dict_items([('a', 1), ('b', 2)])해당 포스팅을 작성하는데 참고한 블로그
해시 알고리즘을 활용한 코딩테스트 문제 풀이
