들어가며...
Text recognition 모델을 찾고 있었다. 찾는 과정에서 기준이라면 다국어를 지원하고, 가변운 모델이면서 정확도는 높고, 속도가 빠른 모델이어야만 했다.
그러다 PaddlePaddle에서 개발한 모델을 찾게 되었다.
우선 PaddlePaddle을 처음 들어봤는데, 중국에서 개발한 딥러닝 프레임워크로 사용자가 엄청 많다고 한다.
PaddlePaddle의 OCR 레포지토리 에서 PP-OCRv3가 나왔다. PP-OCRv3는 PP-OCRv2에 비해 중국어 scene text 인식이 5%가 향상되었고, 영어 scene text 인식이 11% 향상되었으며, 80개 언어 다국어 모델의 평균 인식 정확도가 5%이상 향상되었다고 한다.
그래서 어떤 방식을 사용하길래 모바일 환경에서 돌아갈 만큼 가벼운 모델이면서 정확도가 높은 모델인지 알아보기 위해 Text Recognition 부분의 논문을 찾아보고 리뷰를 남긴다.
Abstract
우선 시작부터 강조를 한다.
In this study, we propsoe a Single Visual model for Scene Text recognition within the patch-size image tokenization framework, which dispenses with the sequential modeling entirely.
"본 연구에서는 sequential modeling을 완전히 생략하는 패치별 이미지 토큰화 프레임워크 내에서 scene text recognition을 위한 단일 시각적 모델을 제안한다."
즉, 기존까지는 이미지에서 특징들을 뽑아내는 visual model과 뽑아낸 특징에서 텍스트로 변환하는 sequence model 두 가지 구성요소로 이루어졌는데, 이 연구에서는 두 개의 model을 하나로 합친 형태의 모델을 제안한 것이다.
SVTR이라고 불리는 방법은 이미지 텍스트를 문자 구성 요소라는 작은 패치로 분해하고, 구성 요소 수준의 혼합, 병합 및/또는 결합을 통해 계층적 단계가 반복적으로 수행된다. Global 및 Local mixing blocks은 문자간 및 문자 내 패턴을 인식하도록 고안되어 다양한 문자 구성 요소 인식을 유도한다. 따라서 문자는 간단한 선형 예측으로 인식된다.
모델의 구조에 대해서 좀 더 자세하게 알아보자.
Method
Overall Architecture
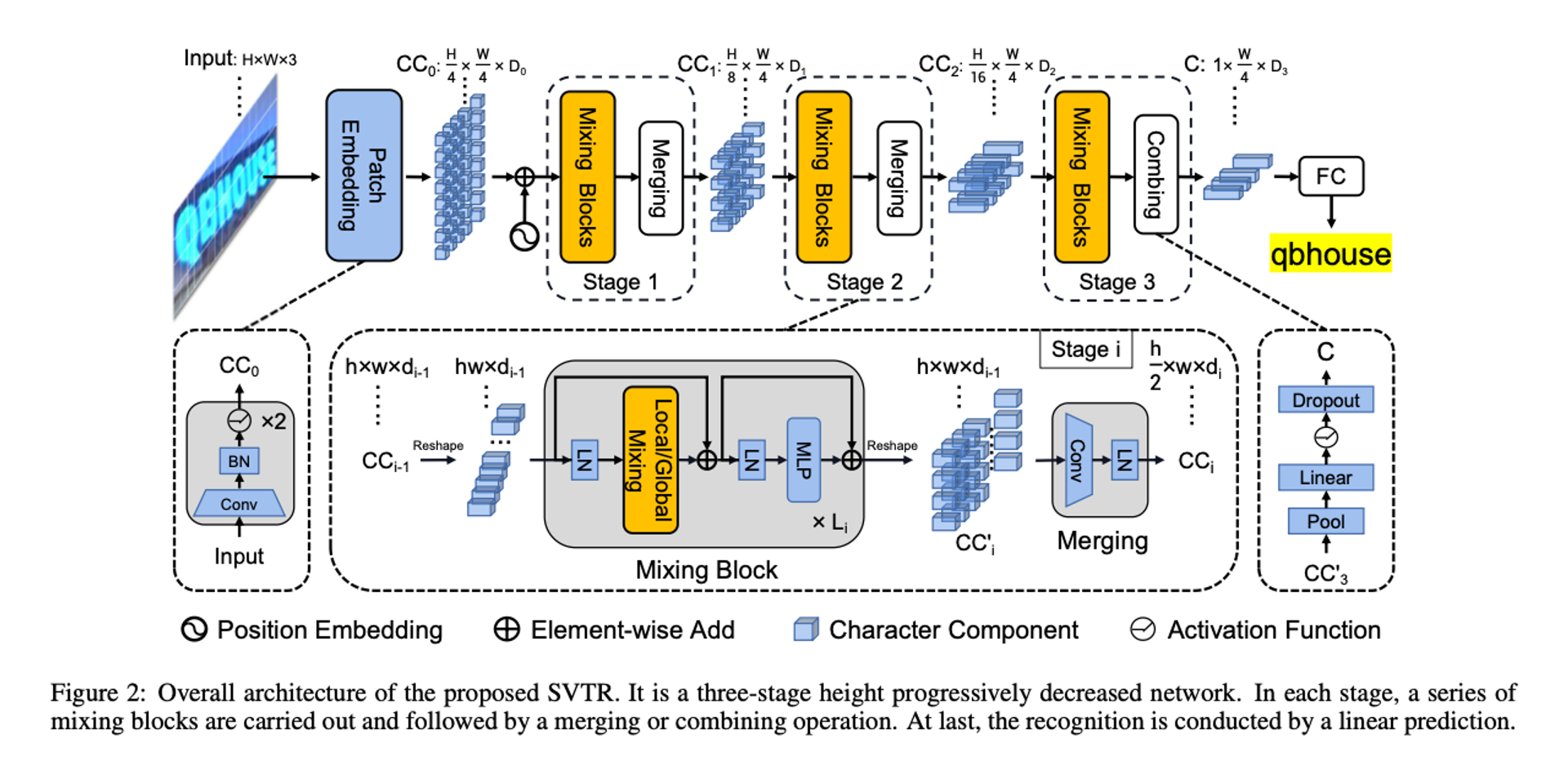
SVTR 개요는 위의 그림에 나와있다. 이는 Text Recognition 전용으로 height가 점진적으로 감소하는 3단계 네트워크이다.
크기의 이미지 텍스트의 경우 먼저 점진적으로 Overlapping patch embedding을 통해 차원 의 패치로 변환된다. 패치는 문자 구성 요소라고 하며, 각각은 이미지 텍스트 문자 일부와 연결된다. 그런 다음, 각각 일련의 mixing blocks으로 구성된 3단계와 병합 또는 결합 작업이 특징 추출을 위해 서로 다른 규모로 수행된다.
Local 및 Global mixing blocks은 획과 유사한 로컬 패턴 추출 및 구성 요소 간 종속성 캡처를 위해 고안되었다. Backbone을 사용하면 서로 다른 거리와 다양한 규모의 구성 요소 기능과 종속성이 특성화되어 크기의 C라는 표현이 생성되어 다중 문자 특징을 인식한다.
마지막으로 중복 제거를 통한 병렬 선형 예측을 수행하여 문자 시퀀스를 얻는다.
Progressive Overlapping Patch Embedding
이미지 텍스트의 첫 번째 작업은 에서 까지의 문자 구성 요소를 나타내는 기능 패치를 얻는 것이다. 이 목적을 위해 두 가지 일반적인 1단계 투영이 있다.
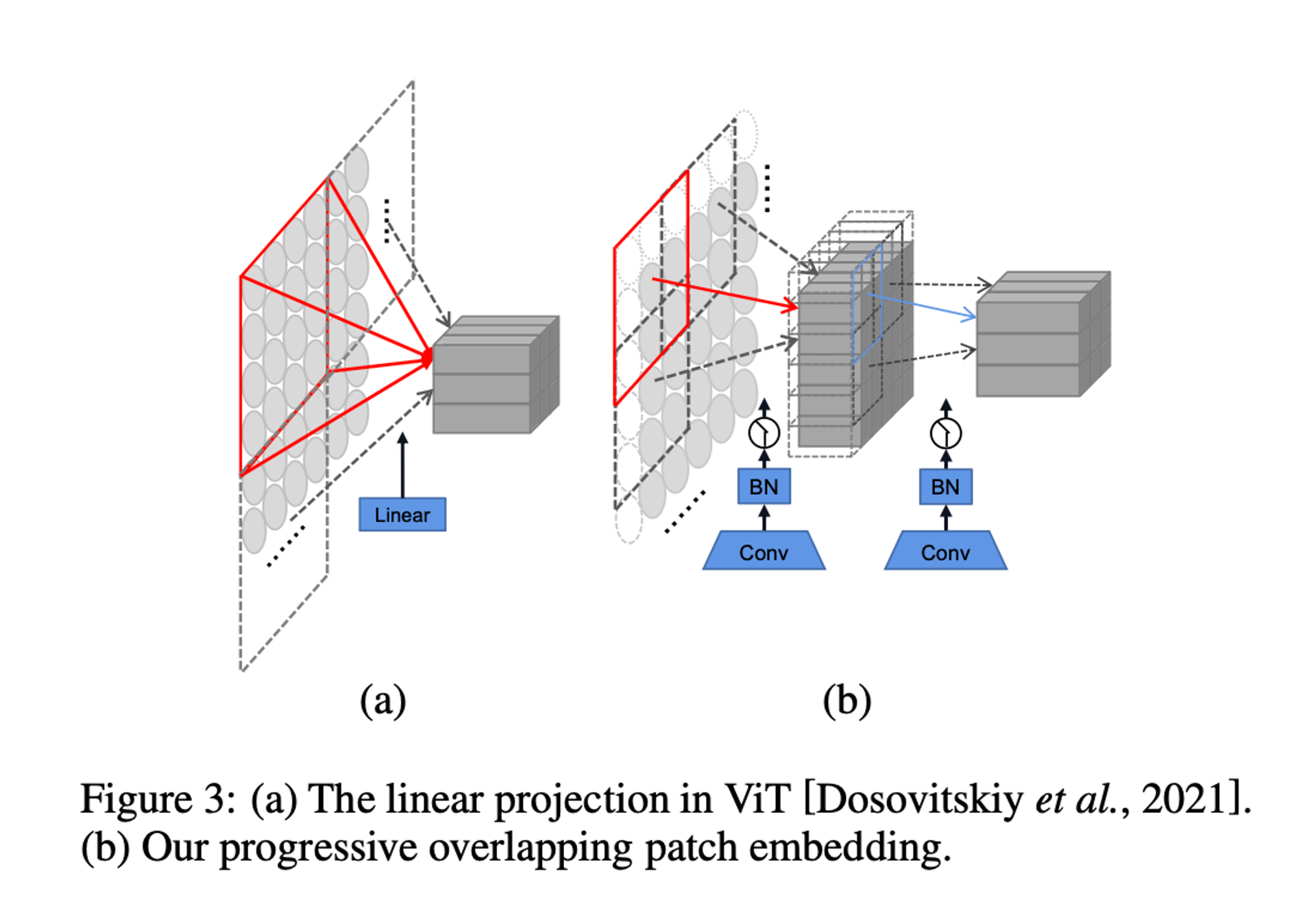
즉, 4 x 4 분리 선형 투영과 stride 4를 사용하는 7 x 7 Convolution이다.
대안으로 Figure 3(b)와 같이 stride 2 및 Batch Normalization을 사용하여 두 개의 연속 3 x 3 Convolution을 사용하여 Patch Embedding을 구현한다. 이 방식을 계산 비용이 약간 증가함에도 불구하고 feature fusion에 유리한 기능 차원을 점진적으로 추가한다.
Mixing Block
두 문자가 약간 다를 수 있으므로 텍스트 인식은 문자 구성 요소 수준의 기능에 크게 의존한다. 그러나 기존 연구에서 대부분 이미지 텍스트 표현하기 위해 특징 시퀀스를 사용한다. 각 특징은 얇은 조각 이미지 영역에 해당하며 특히 불규칙한 텍스트의 경우 잡음이 심한 경우가 많다. Character를 설명하는 데 최적이 아니다.
최근 Vision Transformer의 발전으로 2D 특징 표현이 도입되었지만 텍스트 인식의 맥락에서 이 표현을 활용하는 방법은 여전히 조사할 가치가 있다. 보다 구체적으로, Embedded Components를 사용하면 텍스트 인식에는 두 가지 종류의 기능이 필요하다고 주장한다.
첫 번째는 획과 같은 기능과 로컬 구성 요소 패턴이다. 이는 문자의 여러 부분 사이의 형태적 특징과 상관 관계를 인코딩한다.
두 번째는 서로 다른 문자사이 또는 텍스트와 텍스트가 아닌 구성 요소 사이의 상관 관계와 같은 문자 간 종속성이다. 따라서 우리는 서로 다른 수신 필드의 self-attention을 사용하여 상관 관계를 인식하기 위해 두 개의 혼합 블록을 고안했다.
Global Mixing
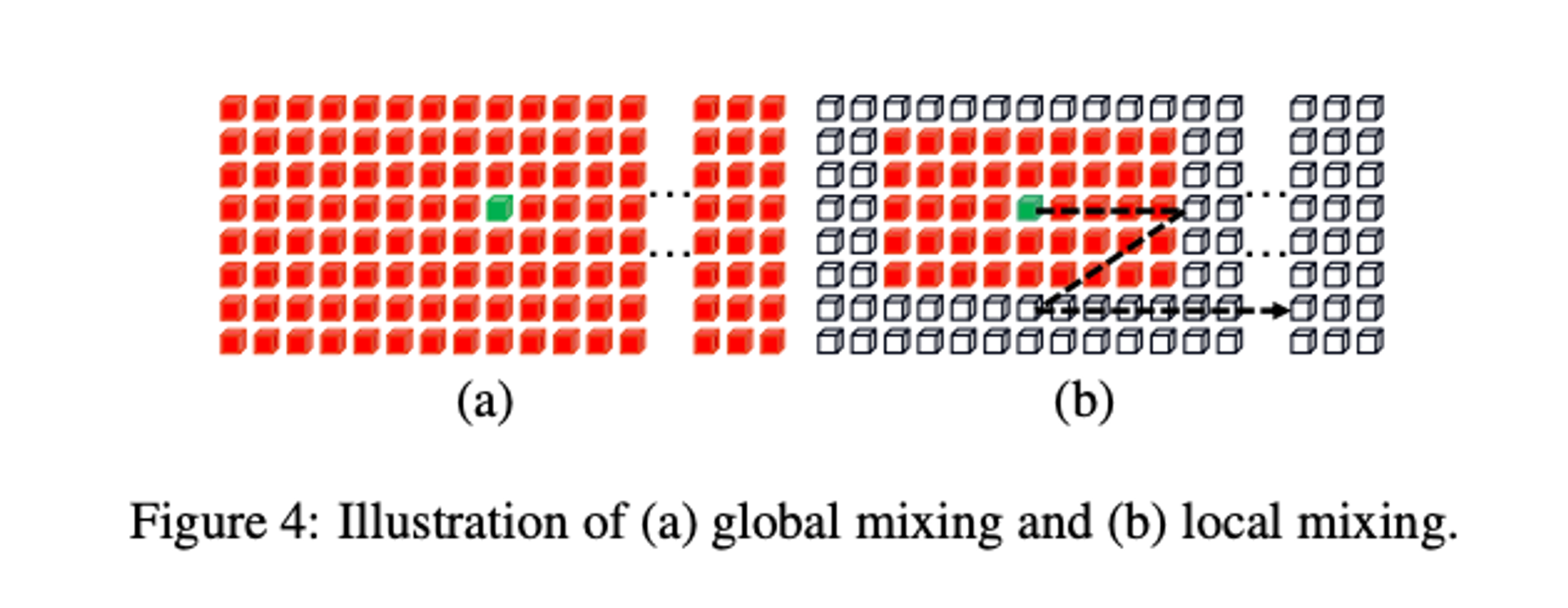
Figure 4(a)에서 볼 수 있듯이 전역 혼합은 모든 문자 구성 요소 간의 종속성을 평가한다.
텍스트와 텍스트가 아닌 것은 이미지의 두 가지 주요 요소이기 때문에 이러한 범용 혼합은 서로 다른 문자의 구성 요소 간의 장기적인 종속성을 확립할 수 있다. 게다가 텍스트가 아닌 구성 요소의 영향력을 약화시킬 수도 있다.
수학적으로 이전 단계의 문자 구성 요소 의 경우 먼저 Feature sequence로 재구성된다. Mixing block에 입력할 때 Layer Norm이 적용되고 종속성 모델링을 위한 multi-head self-attention이 이어진다. Feature fusion을 위해 Layer Norm과 MLP를 순차적으로 적용한다. Shortcut connection과 함께 Global mixing block을 형성한다.
Local Mixing
Figure 4(b)에서 볼 수 있듯이 Local mixing은 미리 정의된 Window 내 구성 요소 간의 상관 관계를 평가한다. 목적은 문자 형태 특징을 인코딩하고 문자 식별에 필수적인 획과 같은 특징을 시뮬레이션하여 문자 내 구성 요소 간의 연관성을 설정하는 것이다.
Global mixing과 달리 Local mixing은 각 구성 요소에 대한 이웃을 고려한다. Convolution과 유사하게 mixing은 Sliding Window 방식으로 수행된다. 경험적으로 Window 크기는 7 x 11로 설정되었다. Global mixing과 비교하여 self-attention 메커니즘을 구현하여 로컬 패턴을 캡처한다.
앞서 언급한 것처럼 두 개의 mixing blocks은 상호보완적인 서로 다른 특징을 추출하는 것을 목표로 한다. SVTR에서는 포괄적인 특징 추출을 위해 각 단계에서 블록을 여러 번 반복적으로 적용한다. 두 종류의 블록 순열은 나중에 제거될 예정이다.
Merging
여러 단계에 걸쳐 일정한 공간 해상도를 유지하는 것은 계산 비용이 많이 들고, 이는 중복 표현으로 이어진다. 결과적으로 우리는 각 단계(마지막 단계 제외)의 Mixing block을 따르는 Merging 작업을 고안했다.
마지막 Miing block에서 출력된 특징을 사용하여 먼저 현재 높이, 너비 및 채널을 각각 나타내는 크기의 embedding으로 모양을 변경한다. 그런 다음 높이 차원에 stride 2, 너비 차원은 stride 1인 3 x 3 Convolution을 사용하고 이어서 Layer Norm을 사용하여 크기의 embedding을 생성한다.
Merging 작업은 일정한 너비를 유지하면서 높이를 절반으로 줄인다. 전산 비용을 절감할 뿐만 아니라 텍스트 맞춤형 계층 구조를 구축한다. 일반적으로 대부분의 이미지 텍스트는 가로 또는 거의 가로로 나타난다. 높이 차원을 압축하면 너비 차원의 패치 레이아웃에 영향을 주지 않으면서 각 문자에 대한 다중 스케일 표현을 설정할 수 있다. 따라서 인접한 문자를 여러 단계에서 동일한 구성 요소로 인코딩할 가능성이 높아지지 않는다. 또한 정보 손실을 보장하기 위해 채널 차원 를 늘린다.
Combining and Prediction
마지막 단계에서는 Merging 작업이 Combining 작업으로 대체된다. 처음에는 높이 차원을 1로 Pooling 한 다음 다음 Fully-connected layer, Non-linear activation and Dropout이 이어진다. 이를 통해 문자 구성요소는 Feature sequence로 더욱 압축되며, 여기서 각 요소는 길이 의 특징으로 표시된다. Merging 작업과 비교하여 Combining 작업은 한 차원에서 크기가 매우 작은(예: 높이 2) embedding에 Convolution을 적용하는 것을 피할 수 있다.
결합된 특징을 사용하여 간단한 병렬 선형 예측으로 인식을 구현한다. 구체적으로 N개의 노드를 갖는 선형 분류기가 사용된다. 이는 크기의 transcript sequence를 생성한다. 여기서 이상적으로는 동일한 문자의 구성 요소는 중복 문자로 transcription되고, 텍스트가 아닌 구성 요소는 공백 기호로 transcription된다. sequence는 자동으로 최종 결과로 압축된다.
Architecture Variants
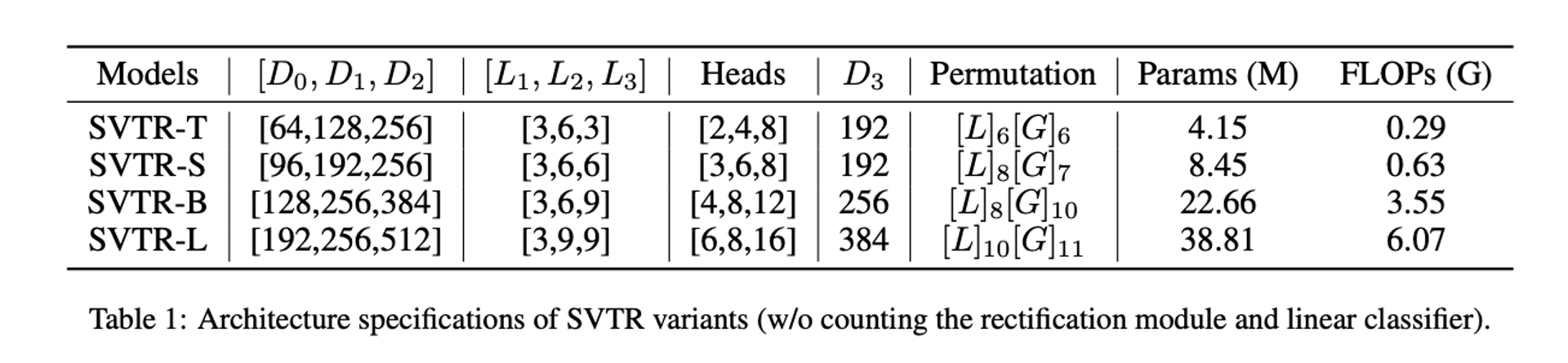
SVTR에는 channel의 깊이, 각 단계의 head 수, Mixing blocks의 수 및 순열을 포함하여 여러 가지 하이퍼 매개변수가 있다. 이를 변경함으로써 서로 다른 용량을 가진 SVTR Architecture를 얻을 수 있으며 SVTR-T(Tiny), SVTR-S(Small), SVTR-B(Base), SVTR-L(Large)의 네 가지 일반적인 Architecture를 구성한다.
Experiments
Implementation Details
SVTR은 왜곡 보정을 위해 이미지 텍스트의 크기를 32 x 64로 조정하는 rectification module을 사용한다. 훈련을 위해 가중치 감소가 0.05인 AdamW Optimizer를 사용.
영어 모델의 경우 초기 learning rate는 크기로 설정된다. 2 epochs 선형 워밍업을 갖춘 cosine scheduler는 21 epochs 모두에서 사용된다. 회전, 원근 왜곡, 모션 블러, 가우시안 노이즈와 같은 데이터 증대는 훈련 중에 무작위로 수행된다. 알파벳에는 대소문자를 구분하지 않는 모든 영숫자가 포함된다. 최대 예측 길이는 25로 설정된다. 길이는 대부분의 영어 단어를 초과한다.
중국 모델의 경우 초기 learning rate는 로 설정된다. 5 epochs의 선형 워밍업을 갖춘 cosine scheduler는 100 epochs 모두에서 사용된다. 데이터 증강은 훈련에 사용되지 않았다. 최대 예측 길이는 40으로 설정된다.
Ablation Study

The Effectiveness of Patch Embedding
Table 2 왼쪽에서 볼 수 있듯이 다양한 Embedding 전략은 인식 정확도에서 약간 다르게 동작한다. 점진적 Embedding 방식은 두 데이터 세트에서 평균 0.75%와 2.8%로 두 가지 기본 방식보다 성능이 뛰어나며 특히 불규칙한 텍스트에 효과적이라는 것을 나타낸다.
The Effectiveness of Merging
또한, 두 가지 선택 사항이 있다. 즉, 점진적으로 감소하는 네트워크를 구축하기 위해 병합 작업을 적용하는 것과 여러 단계에서 일정한 공간 해상도를 유지하는 것이다. Table 2의 오른쪽 부분에 표시된 대로 병합하면 계산 비용이 줄어들 뿐만 아니라 두 데이터 세트의 정확도도 높아진다. 높이 차원에 대한 다중 스케일 샘플링이 텍스트 인식에 효과적인지 검증한다.
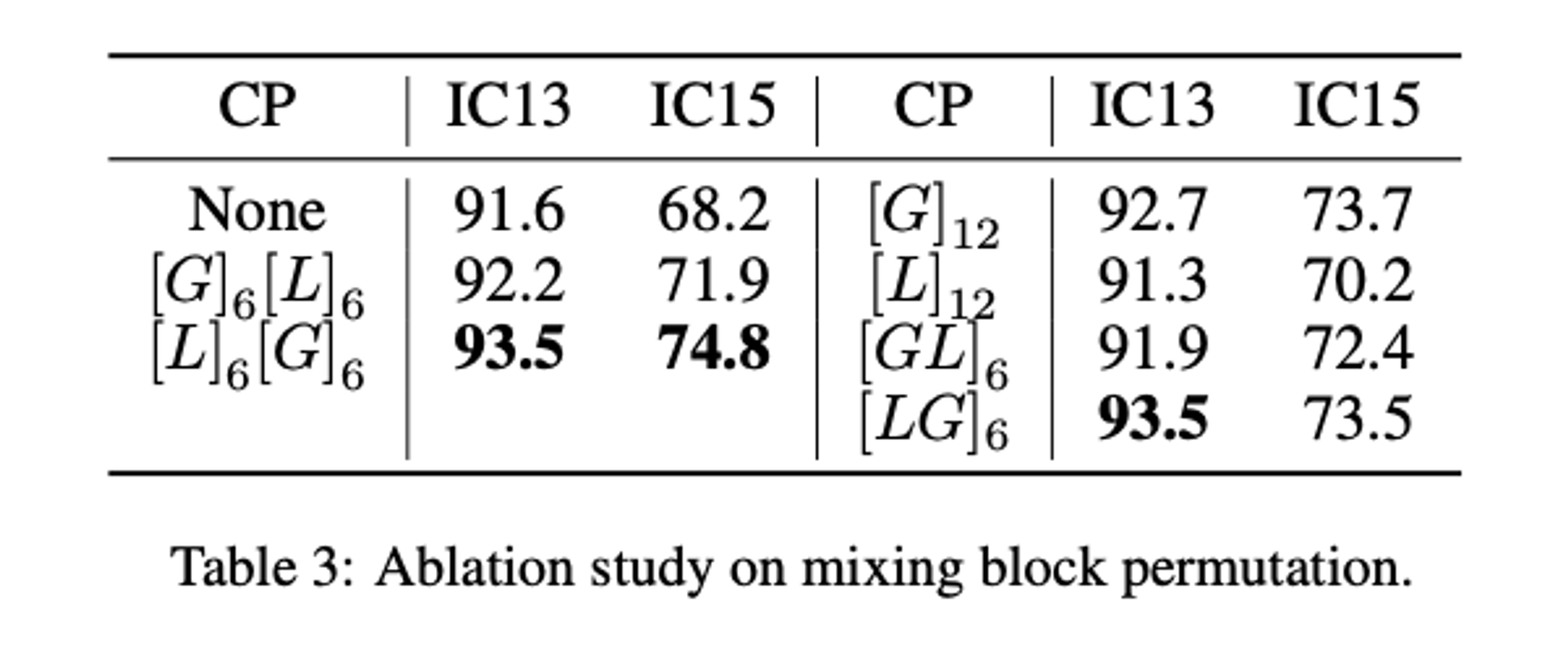
The Permutation of Mixing Blocks
각 단게에서 Global 및 Local mixing blocks을 그룹화하는 다양한 방법이 있다. Table 3의 은 각 단게에 대해 처음에는 6개의 Global mixing blocks이 수행되고 그 다음에는 6개의 Local mixing blocks이 수행됨을 의미한다.
Local mixing block을 Global mixing block 앞에 배치함으로써 Global mixing block이 장기적인 종속성 캡처에 집중하도록 안내하는 것이 좋다. 반대로 순열을 바꾸는 것은 지역적 특성에 반복적으로 참여할 수 있는 Global mixing block의 역할을 혼란스럽게 할 가능성이 높다.
Conclusion
scene text recognition을 위한 맞춤형 시각적 모델인 SVTR을 제시했다. 이는 획과 같은 로컬 패턴과 여러 높이 스케일에서 다양한 거리의 구성요소 간 종속성을 모두 설명하는 다차원 문자 특징을 추출한다. 따라서 단일 시각적 모델을 사용하여 인식 작업을 수행할 수 있으며 정확성, 효율성 및 언어 간 다양성의 장점도 누릴 수 있다.
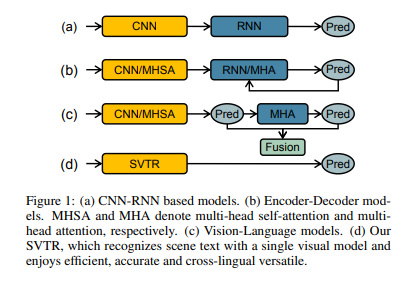
2단계의 걸친 과정에서 SVTR은 1단계로 줄인 방법이었다.
이 방법은 빠른 추론을 보여주었다. 더구나 사용 목적에 따라 작은 모델인 SVTR-Tiny를 사용할 수도 있었고, 한국어 이미지 텍스트를 학습한 한국어 모델도 제공되었다.
나의 기준에 만족한 이 모델을 선택하여 fine-tuning을 진행했다.
