내일배움캠프 AI
오늘 한 일
실전 머신러닝 적용 강의
딥러닝의 개념
- Multilayer Perceptrons를 사용이 딥러닝의 핵심
- Backpropagation이 성능을 극한으로 끌어올려 반복적으로 피드백을 주며 학습을 시킨다.
Deep Neural Networks 구성 방법
- Layer(층) 쌓기
- 딥러닝 네트워크 구조
- Input layer(입력층): 네트워크의 입력 부분, 우리가 학습시키고 싶은 x 값
- Output layer(출력층): 네트워크의 출력 부분, 우리가 예측한 값, 즉 y 값
- Hidden layers(은닉층): 입력층과 출력층을 제외한 중간층
- 기본적인 뉴럴 네트워크(Deep neural networks)에서는 보통 은닉층에 중간 부분을 넓게 만드는 경우가 많다. 예를 들면 보편적으로 아래와 같이 노드의 개수가 점점 늘어나다가 줄어드는 방식으로 구성한다.
- 딥러닝 네트워크 구조
- 네트워크의 Width(너비)와 Depth(깊이)
-> Baseline model(베이스라인 모델)을 실험(튜닝)을 통해 성능 테스트를 한다.Baseline model(베이스라인 모델)
- 입력층: 4
- 첫 번째 은닉층: 8
- 두 번째 은닉층: 4
- 출력층: 1
- 네트워크의 너비 늘리기 (은닉층의 개수 그대로 은닉층의 노드개수 늘리기)
ex)너비를 2배로 늘린다.
- 입력층: 4
- 첫 번째 은닉층: 8 * 2 = 16
- 두 번째 은닉층: 4 * 2 = 8
- 출력층: 1
- 네트워크의 깊이 늘리기 (은닉층 개수 늘리기)
- 입력층: 4
- 첫 번째 은닉층: 4
- 두 번째 은닉층: 8
- 세 번째 은닉층: 8
- 출력층: 1
- 너비와 깊이 둘 다 늘리기
- 입력층: 4
- 첫 번째 은닉층: 8
- 두 번째 은닉층: 16
- 세 번째 은닉층: 16
- 네 번째 은닉층: 8
- 출력층: 1
딥러닝 주요 개념
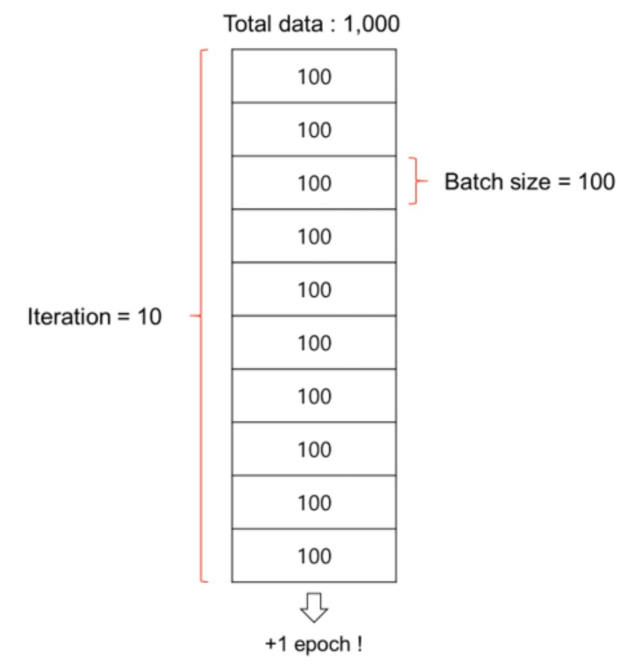
- Batch(배치) : 데이터셋을 작은 단위로 쪼개서 학습을 시키는데 쪼개는 단위
- iteration(이터레이션) : 데이터셋을 반복하는 과정
- epoch(에폭)
ex) 1천만개의 데이터셋을 1천개 단위의 배치로 쪼개면, 1만개의 배치가 되고, 이 1만개의 배치를 100에폭을 돈다고 하면 1만 * 100 = 100만번의 이터레이션을 도는 것
딥러닝 주요스킬
-
Data augmentation (데이터 증강기법) : 원본 이미지 한 장을 여러가지 방법으로 복사하여 학습시키는 것

-
Dropout (드랍아웃) : 가장 간단하고 쉬운 방법, 각 배치마다 랜덤한 노드를 끊어버리는 것
-
Ensemble (앙상블) : 여러개의 딥러닝 모델을 만들어 각각 학습시킨 후 각각의 모델에서 나온 출력을 기반으로 투표를 하는 방법, 랜덤포레스트 기법과 비슷
-
Learning rate decay (Learning rate schedules) :앞부분에서는 큰 폭으로 건너뛰고 뒷부분으로 갈 수록 점점 조금씩 움직여서 효율적으로 Local minimum을 찾는 것 (Keras에서는 tf.keras.callbacks.LearningRateScheduler() 와 tf.keras.callbacks.ReduceLROnPlateau() 를 가장 많이 사용)

🐶🦶📏