2장 알고리즘 설게와 분석의 기초
바람직한 알고리즘
- 명확해야 한다
- 효율적이여야 한다
알고리즘의 수행 시간

상수 K 만큼 시간이 걸린다

n에 비례하는 시간이 소요

n에 비례하는 시간이 소요
재귀와 귀납적 사고
재귀적 구조
- 어떤 문제 안에 크기만 다를뿐 성격이 똑같은 작은 문제들이 포함되어있는 것
- 팩토리얼, 수열의 점화식 등
ex) 병합 정렬

알고리즘의 분석 이유
- 무결성 확인
- 자원 사용의 효율성 파악
크기가 작은 경우
- 알고리즘의 효율성이 중요하지 않음
크기가 충분히 큰 문제
- 알고리즘의 효율성이 중요
- 점근적 분석 : 입력의 크기가 충분히 큰 경우에 대한 분석
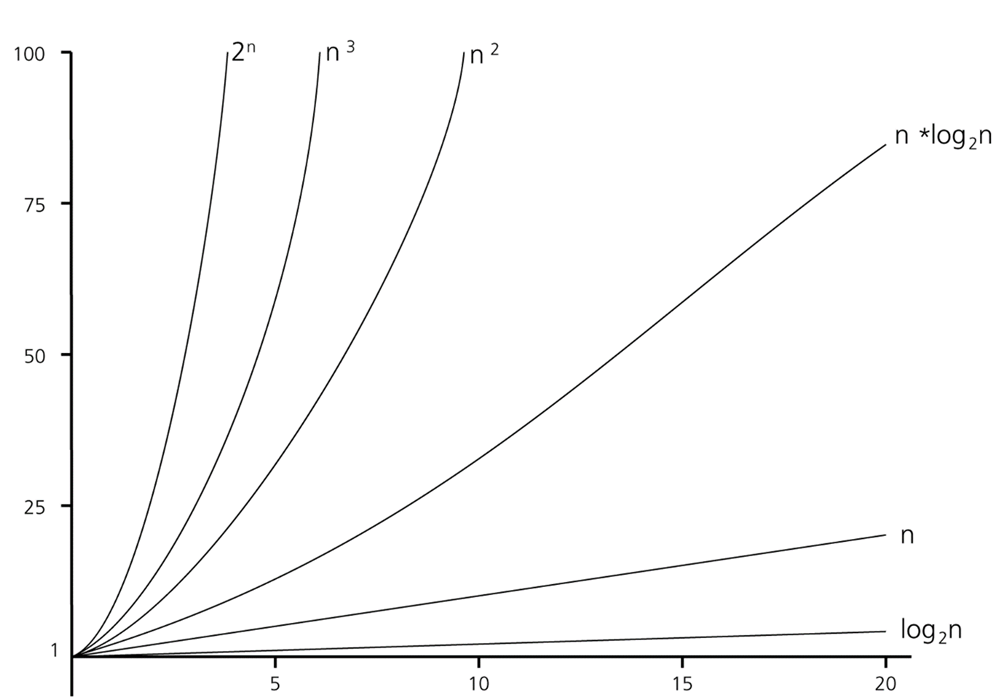
점근적 분석
입력의 크기가 충분히 큰 경우에 대한 분석
대표적인 점근적 개념
점근법 표기법

-
f는 g보다 빠르게 증가하지 않는다(상수 비율의 차이는 무시)

-
f는 g보다 느리게 증가하지 않는다
-
f는 g보다 같은 정도로 증가한다.
-
f는 g보다 느린 정도로 증가한다.
-
f는 g보다 빠른 정도로 증가한다.
3장 점화식과 점근적 복잡도 분석
점화식
- 어떤 함수를 자신보다 더 작은 변수에 대한 함수와의 관계로 표현한 것
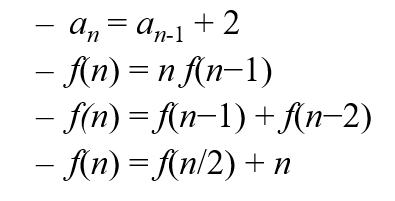
병합 정렬의 수행시간
T(n) = 2T(n/2) + 오버헤드
-> 크기가 n인 병합 정렬 시간 == 크기가 n/2인 병합 정렬 * 2 + 오버해드
점화식의 점근적 분석 방법
반복대치
- 더 작은 문제에 대한 함수로 반복해서 대치해나가는 방법
추정후 증명
- 결론을 추정하고 수학적 귀납법을 이용하여 증명하는 방법
마스터 정리
- 형식에 맞는 점화식의 복잡도를 바로 파악
ppt 참고
3장 정렬
- 대부분 O(n^2)와 O(nlogn) 사이
- input이 특수한 성질을 만족하는 경우 O(n)도 가능
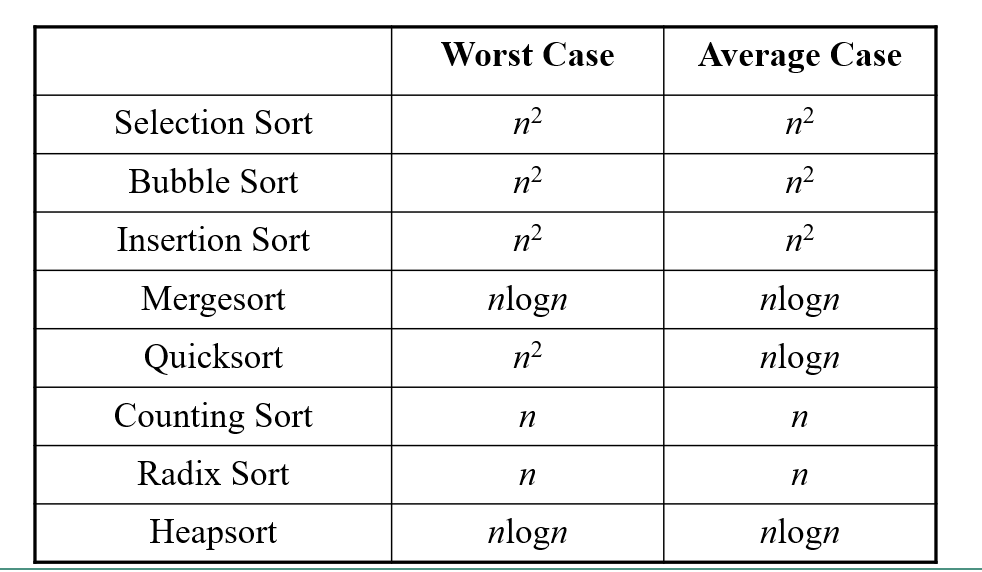
O(n^2) 시간이 소요되는 정렬 알고리즘
선택 정렬

각 루프마다
- 최대 원소 탐색
- 최대 원소와 맨 오른쪽 원소를 교환
- 맨 오른쪽 원소를 제외
하나의 원소만 남을때까지 위의 루프를 반봅

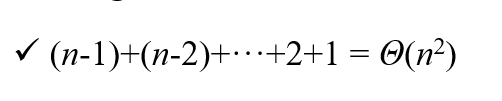
버블 정렬

- 왼쪽부터 시작해 이웃한 쌍을 비교
- 순서대로 되어 있지 않으면 자리 변경
- 맨 오른쪽에 도착하면 그 원소를 정렬대상에서 제외
- 반복
삽입 정렬
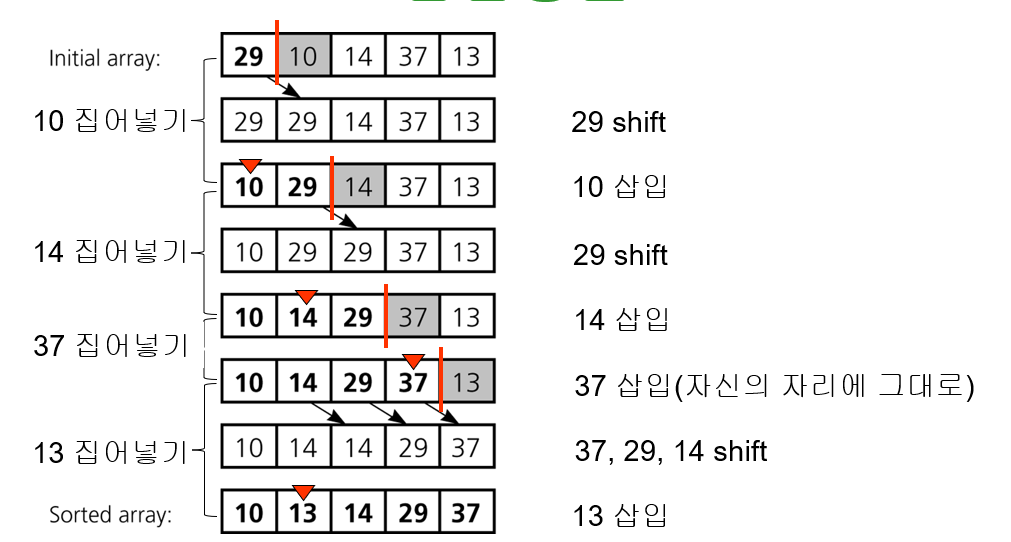
베스트 케이스의 점화식 : O(n)
-> 이미 모든 원소가 배열 되어 있을 경우
고급 정렬 알고리즘(O(nlogn)의 시간이 소요)
두 원소를 비교하는 것을 기본 연산으로 하는 정렬의 하한선 == O(nlogn)
병합 정렬


퀵정렬

워스트 케이스 수행시간 : O(n^2)
힙정렬
주어진 배열을 힙으로 만든 다음, 차례로 하나씩 힙에서 제거

O(n) 정렬
원소들이 특수한 성질을 만족하는 경우
기수 정렬
- 원소들이 모두 k 이하의 자릿수를 가졌을때
- 안정성 정렬 : 같은 값을 가진 원소들은 정렬 후에도 원래의 순서가 유지되는 성질을 가진 정렬

계수 정렬
원소들의 크기가 모두 -O(n) ~ O(n) 인 경우

6장 검색 트리
- 레코드 : 개체에 대해 수집된 모든 정보를 포함하고 있는 단위
- 필드 : 레코드에서 각각의 정보를 나타내는 부분
- 검색키 : 다른 레코드와 중복되지 않도록 각 레코드를 대표할 수 있는 코드
- 검색 트리 : 각 노드가 규칙에 맞도록 하나의 키를 가지고 있는 것
이진 검색 트리
- 각 노드는 서로다른 하나의 키값을 가진다
- 각 노드는 최대 2개의 자식을 가진다
- 자신보다 왼쪽 자식 노드의 값은 작아야 하며, 오른쪽 자식 노드 값은 커야 한다

이진 검색 트리의 검색

이진 검색 트리의 삽입
레드블랙트리
이진 검색 트리의 모든 노드에 블랙 또는 레드의 색을 칠하되, 다음 특징을 만족해야 한다
- 루트노드는 블랙
- 모든 리프는 블랙
- 노드가 레드이면, 그 노드의 자식은 반드시 블랙
- 루트 노드에서 임의의 리프 노드에 이르는 경로에서 만나는 블랙 노드의 수는 모두 같다
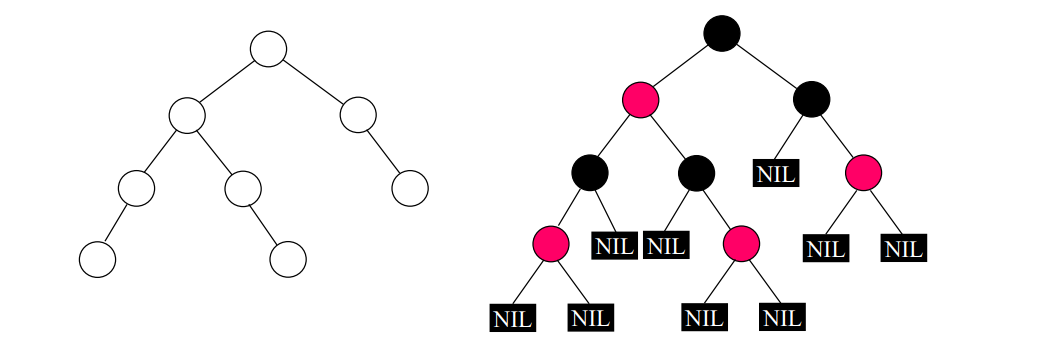
삽입 방법
이진검색트리와 같으나, 삽입된 노드를 레드로 칠한다
만약 부모노드 색상이
- 블랙인 경우 : 문제 없음
- 레드인 경우 : 조건에 맞게 색을 변경해야 함
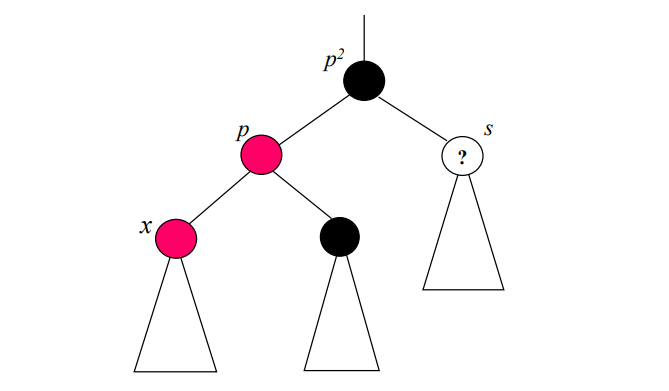
case 1 : s가 레드인 경우
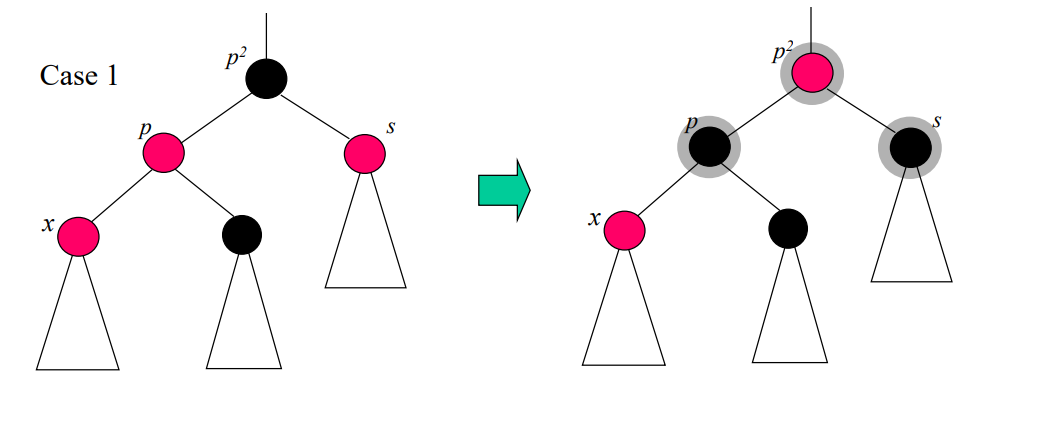
다음과 같이 부모노드 색을 변경
case 2-1 : s가 블랙이고, x가 p의 오른쪽 자식인 경우
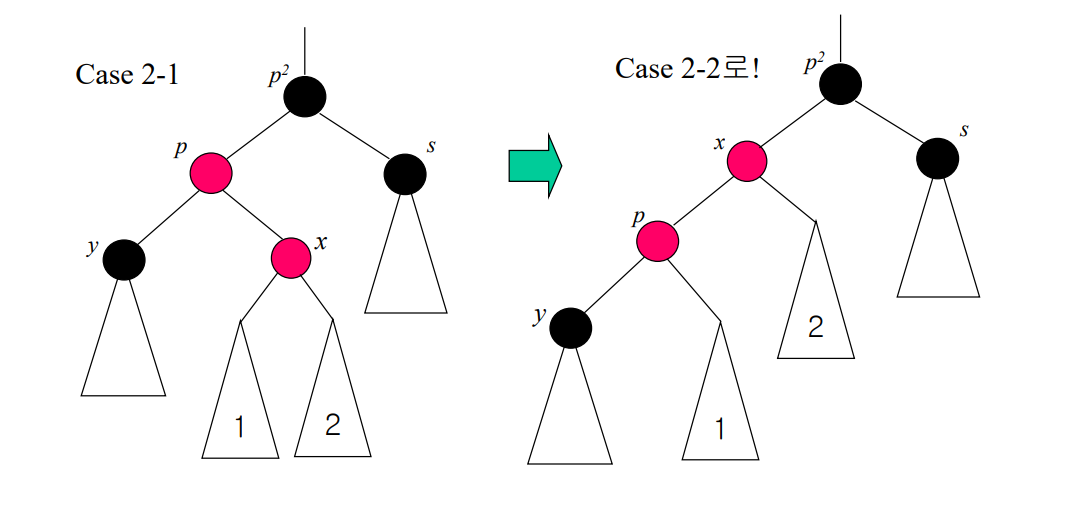
case 2-2 : s가 블랙이고, x가 p의 왼쪽 자식인 경우
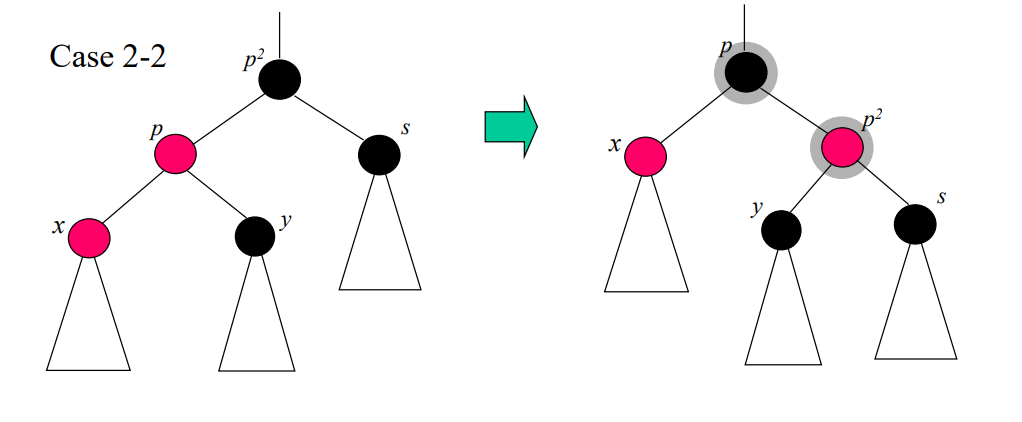
삭제
삭제노드가 레드인 경우,
삭제노드가 블랙이고 유일한 자식이 레드인 경우 문제 없음
ppt 참고
B-트리
- 디스크의 접근 단위는 블록
-> 한번 접근하는 시간은 수십만 명령어의 처리 시간과 동일하다 - 따라서 트리의 높이를 최소화하여, 최악의 경우 디스크 접근 횟수를 줄인 것이 b트리
다음의 성질을 만족한다
- 루트를 제외한 모든 노드는 k/2~k개의 키를 가진다
- 모든 루프 노드는 같은 깊이를 가진다

b-tree 삽입 방법
다차원 검색
검색키가 두개 이상의 필드로 이루어진 검색
KD-Tree
각 레벨에서 필드를 번갈아가면 검색에 사용
- 한 레벨에서는 하나의 필드만 사용
- 총 k개의 필드를 사용하는 검색이라면, k개의 레벨을 내려가야 검색에 사용하는 필드가 일치
KDB-Tree
kd-tree와 b-tree의 특성을 결합
- 다차원 키 + 디스크의 한 페이지가 한 노드와 일치 + 밸런스 트리
- 각 레코드는 k차원 공간에서 하나의 점에 해당
internal node는 k차원 공간에서 한 영역을 담당
- 루트 노드는 k차원 공간 전체를 커버
- 같은 레벨에 있는 모든 노드들은 서로 곂치는 영역이 없다
- 같은 레벨에 있는 모든 노드들의 담당 영역을 합하면 k 차원 전체가 됨
리프노드의 경우, 데이터 페이지 정보를 저장
R-tree
- b-트리의 다차원 확장
- 균형잡힌 검색 트리
- 모든 레코드는 리프노드에서만 가리키며
- 다차원 도형의 저장 가능
그리드 파일
- 트리가 아님
- 공간을 서로 배타적인 격자영역으로 나눔
-> 해당 영역에 속하는 레코드들을 모아서 저장
-> 검색키 값이 저장되는 위치와 직접 상관이 있다
7장 해시테이블
- 원소가 저장될 자리가 원소의 값에 의해 결정
- 매우 빠른 응답을 요하는 응용에 유용
- 최소 원소를 찾는 것과 같은 작업은 지원하지 않음

입력값 % 테이블 크기 == 저장하는 위치
해시 테이블에 고르게 입력원소를 저장하는 방법
나누기 방법
- h(x) = x mod m
- m == 해시 테이블 사이즈 (m은 소수)
곱하기 방법
- h(x) = (xA mod 1) * m
- m은 소수일 필요가 없으며, 2^p로 잡는다
충돌
해시 테이블의 한 주소를 놓고 두개 이상의 원소가 자리를 다투는 것
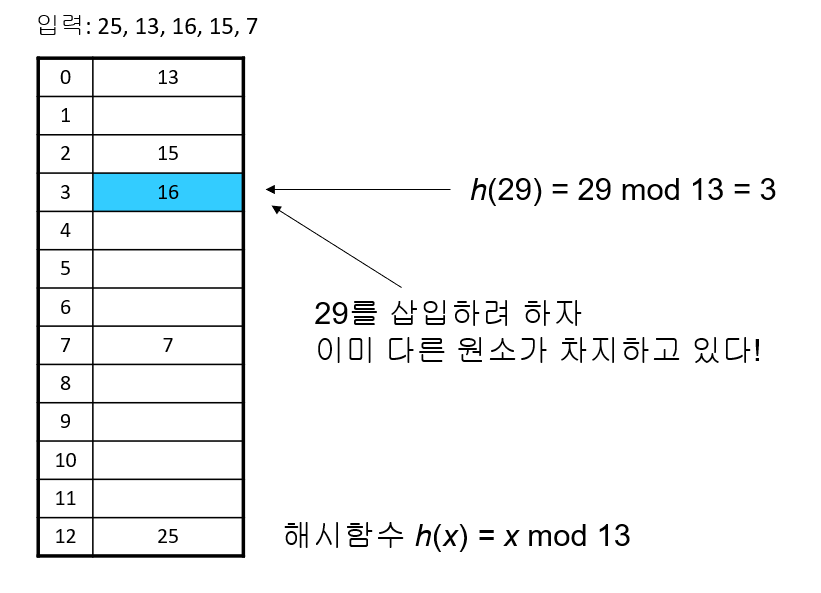
체이닝
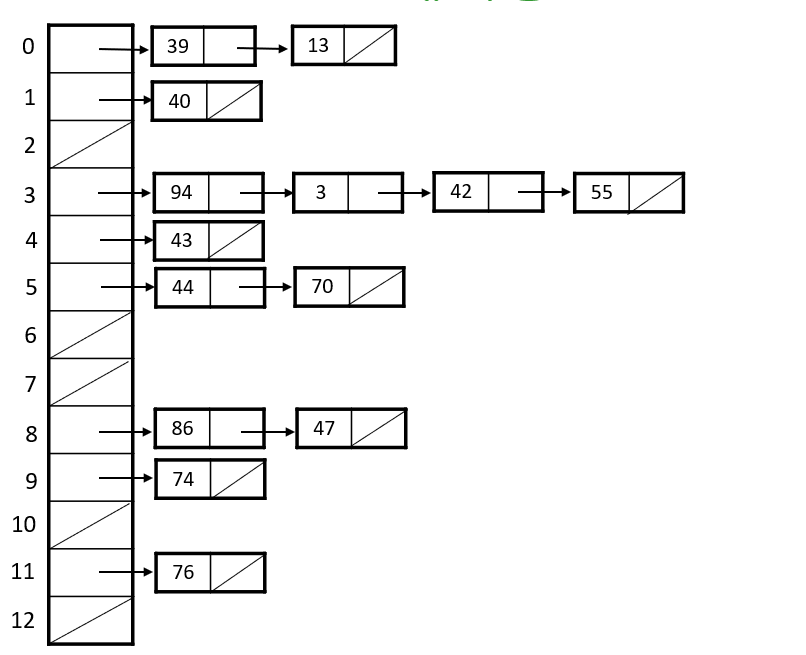
- 같은 주소로 해싱되는 원소를 모두 하나의 연결리스트로 관리
개방주소방법
- 충돌이 있어도 어떻게든 주어진 테이블 공간에서 해결
- 빈자리가 생길 때까지 해시값을 계속 생성
선형조사 방법
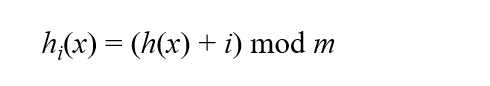
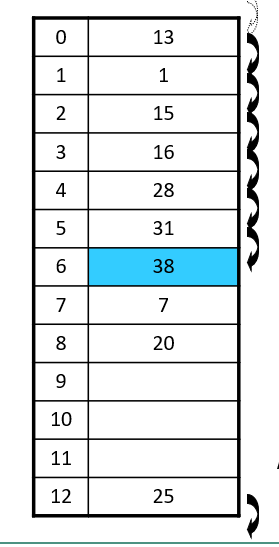
- 빈자리가 없으면 다음 자리로 이동
- 1차군집(특정 영역에 원소가 몰리는 현상)에 취약
이차원 조사
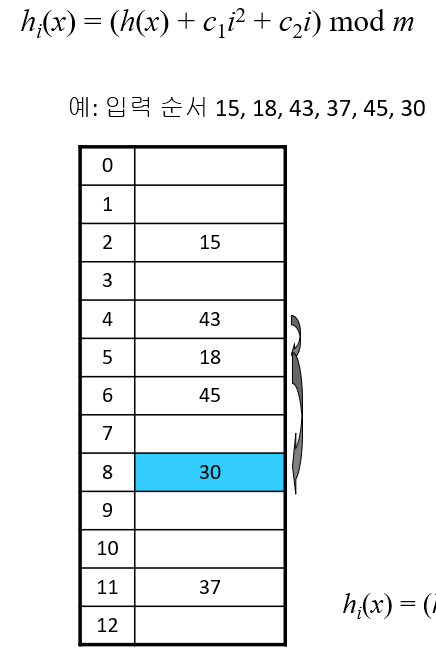
- 2차군집에 취약(여러 개의 원소가 동일한 초기 해시 함수값을 가지는 현상)
더블 해싱

= 주의 =
삭제시 생기는 빈자리로 인해 문제가 생길 수 있음
-> 표식을 해둠으로써 문제 해결
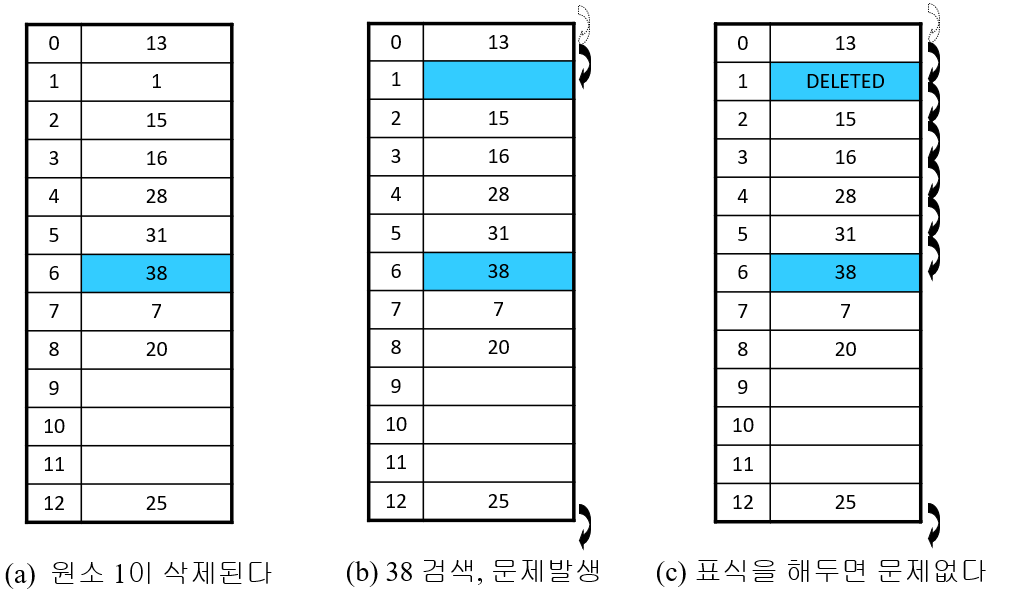
해시 테이블의 검색 시간
적재율이 높아지면 검색효율이 낮아진다
따라서 입계값에 가까워지면 해시 테이블의 크기를 2배로 늘린후, 모든 원소를 다시 해싱해서 저장한다
적재율 a
- 적재된 n개의 원소 / 테이블의 크기
체이닝인 경우
정리 1
- 체이닝을 이용하는 해싱에서 적재율이 a일때, 실해하는 검색에서 조사 횟수의 기대치는 a이다
정리 2
- 성공 하는 검색에서 조사횟수의 기대치는
1 + a/2 + a/2n 이다
개방주소인 경우
가정
- 조사순서 h0(x), h1(x), …, hm-1(x)가 0부터 m-1 사이의 수로 이루어진 순열을 이루고, 모든 순열은 같은 확률로 일어난다
정리 3
- 실패하는 검색에서 조사횟수의 기대치는 최대 1/(1- α )이다
정리 4
- 성공하는 검색에서 조사횟수의 기대치는 최대 (1/ α) log(1/(1- α)) 이다
8장 상호 배타적인 집합의 처리
연결리스트를 이용한 처리
- 같은 집합의 원소들은 하나의 연결 리스트로 관리
- 연결 리스트의 맨 앞의 원소를 집합의 대표 원소로 삼는다
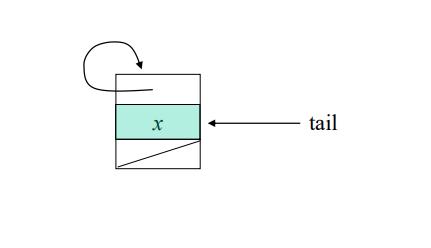
하나의 원소로 이루어진 집합
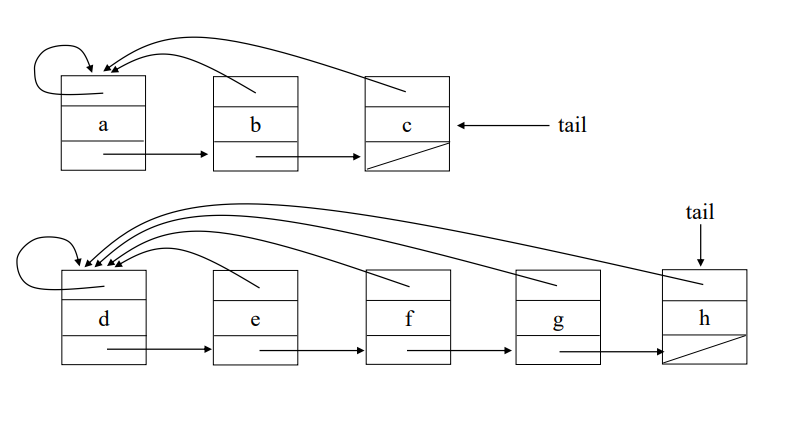
연결리스트로 된 두 집합
무게를 고려한 union
- 연결리스트로 된 두 집합을 합칠 때 작은 집합을 큰 집합 뒤에 붙인다
- 대표 원소를 가리키는 포인터 갱식 작업을 최소화하기 위함
정리
연결 리스트를 이용해 표현되는 배타적 집합에서
무게를 고려한 Union을 사용할 때, m번의 Make Set, Union, Find-Set 중 n번이 Make-Set이라면 이들의 총 수행 시간은 O(m + nlogn)이다
트리를 이용한 집합의 철이
- 같은 집합의 원소들은 하나의 트리로 관리
-> 자식 노드가 부모 노드를 가리킴 - 트리의 루트를 집합의 대표 원소로 삼는다
연산의효율을 높이는 방법
랭크를 이용한 union
- 각 노드는 자신을 루트로 하는 서브 트리의 높이를 랭크라는 이름으로 저장
- 두 집합을 합칠 대 랭크가 낮은 집합을 랭크가 높은 집합에 붙임
경로 압축
- find-set을 행하는 과정에서 만나는 모든 노드들이 직접 루트를 가리키도록 포인터를 변경해줌
트리를 이용해 표현되는 배타적 집합에서
랭크를 이용한 Union과 경로압축을 이용한
Find-Set을 동시에 사용하면, m번의 Make-Set,
Union, Find-Set 중 n번이 Make-Set일 때 이들의
수행 시간은 O(mlog*n)이다.
