-
cuda 진짜 제대로 쓰기 위한 셋팅법
->
1. 우선 이 링크 참고 (https://tkayyoo.tistory.com/17, "https://aeong-dev.tistory.com/1"(이게 가장 정확), https://operationcoding.tistory.com/145)
2. 실제로 cuda.isavailable() 결과가 True가 나올지라도 호환이 안되면 CPU를 쓸 가능성 매우 높음!!!
3. GPU(ex. A100)에 따른 엔비디아 드라이버 설치> 그 엔비디아 드라이버와 호환되는 CUDA 설치 (참고로 nvidia-smi할때 나오는 CUDA version은 compatible한 버전을 말하는것)
4. cuDNN 설치
쿠다 버전에 맞는 cuDNN 설치
5. pytorch 설치
CUDA, cuDNN에 맞는 버전으로 설치 -
과연 GPU에서 CUDA 호환 문제로 CPU를 더 많이 쓴걸까?
->
아니다. 그냥 A10의 CPU가 더 좋았을뿐.
CL시, 문제 상황은 다음과 같다. (둘다 available True 나오는 상황, 나름의 호환도 다 해준 상황)
A: GPU 15%, CPU 33% (A10), CL시 1에폭당 1초
B: GPU 7%, CPU 70% (A5000), 1에폭당 1.8~2초
그리고 GPU, CPU 각각에 대한 성능
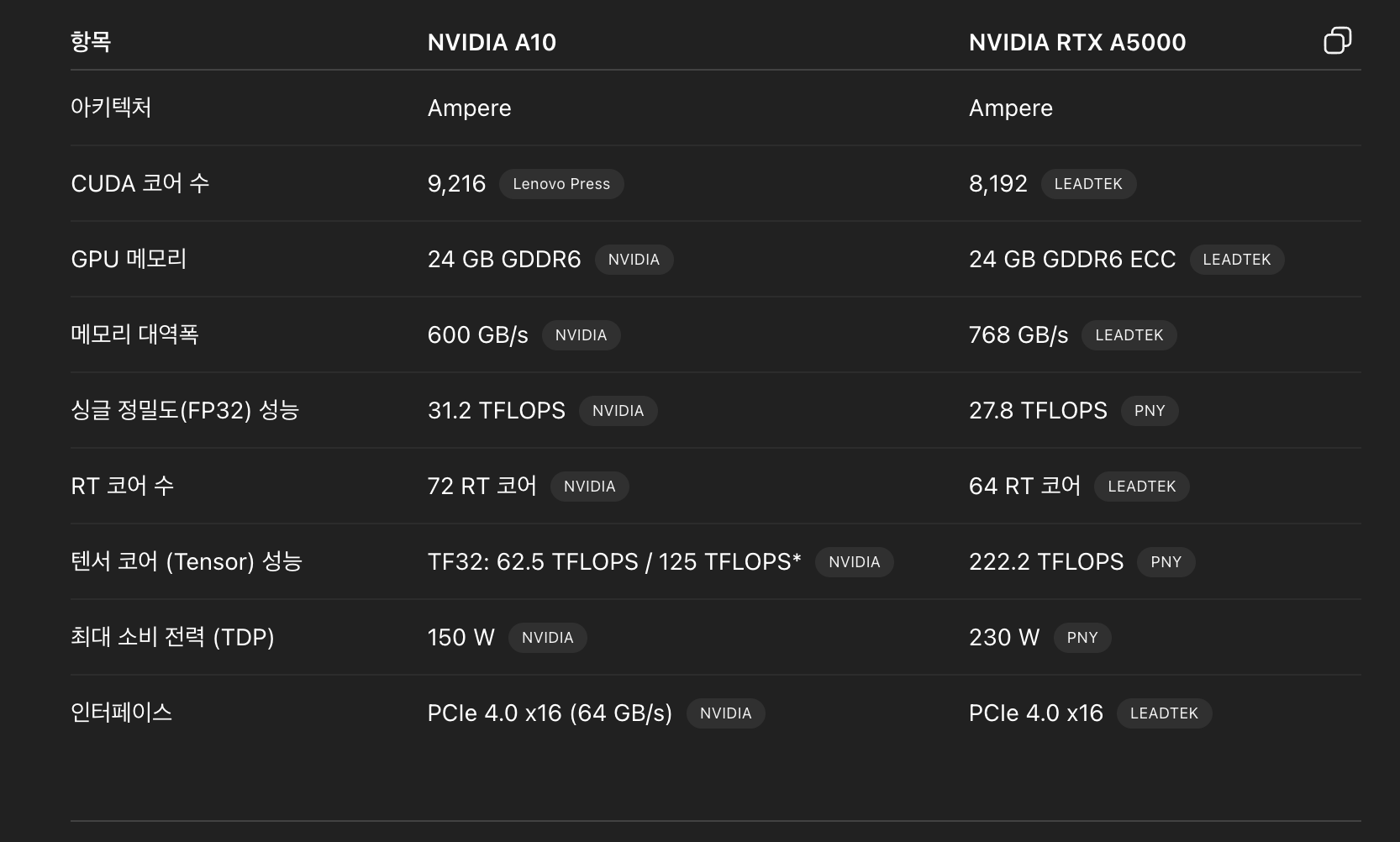

위에 보다시피 GPU 측면에서, A5000이 텐서코어에선 성능이 앞서지만, 쿠다 코어에선 A10이 앞선다.
즉, CL과 같이 병렬처리가 중요하지 않은 경우엔 쿠다 코어가 훨씬 더 중요하다. (GPU 활성도가 A10이 훨씬 앞선다)
CPU 측면에서도 마찬가지이다.
A5000의 멀티코어 점수가 훨씬 좋지만 (멀티쓰레드에 쓰임) CL에서는 싱클코어 점수가 훨씬 중요하다. 그래서 A5000에서는 CPU를 조금만 써도 70%로 너무나도 무리가 된다.
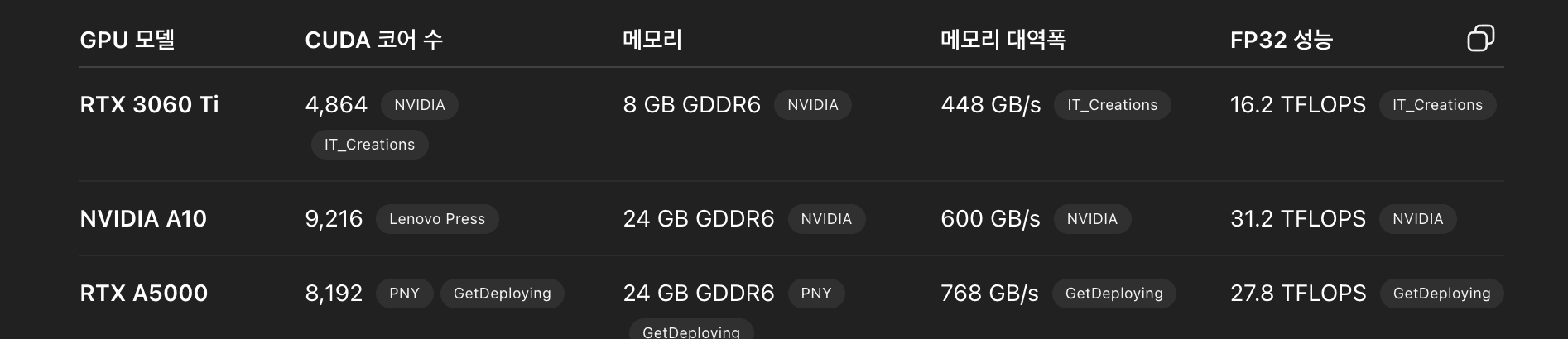
즉, 집에 있는 3060Ti에서 성능 좋게 나온건, CPU가 상당히 좋은 컴퓨터라서 CPU를 써야할때 잘 써주고 있었으며, 아래와 같이 쿠다 코어수도 많이 부족하지만, 실질적으로 배치사이즈가 작기에 쿠다 코어로 내적 계산 빨리하는것보단 런치 오버헤드 영향이 더 커서 두 GPU의 CL 훈련 시간이 비슷한것이다.
-
CL위한 GPU 구축시 성능 좋은 CPU 구매해야한다.
->
1-way기준으로도 CL 훈련시엔 괜찮은데, drifitng sample 찾을때 CPU 과부하가 상당히 온다.
근데 2-way, 4-way가 된다면 동시에 drifting sample 찾게 되면 엄청난 과부하가 올수있다. -
3060Ti에서 PRO6000보다 성능 좋았던 이유?
->
CPU 차이이다. 자세한건 아래 내용 참조 -
CL 관점, CPU가 좋을수록 좋은 이유?
->
RTX3060Ti가 A10보다, PRO6000보다 훈련 속도가 더 빨랐다.
그 이유는 어차피 나는 배치가 작아서 쿠다코어가 적당히만 있으면 되는 상황, 그래서 훈련 딱 1개만 돌린다 가정할때 GPU가 그렇게 중요하진 않았다(당연히 있어야지만 필요로하는 GPU 성능이 매우 낮다). 하지만 CPU가 좋으면, 데이터 로더라던지 역전파라던지 여러가지 이점이 있다. 여기서 속도 차이가 나버려서 CL에선 CPU가 중요하다. 좋을수록 빨리 데이터 로딩이 된다 생각, 역전파도 마찬가지. -
CL 관점, GPU가 좋을수록 좋은 이유?
->
CL에서 테스트 1개만 돌리면 상관 없는데 Androzoo 기준으로 3060Ti에서 테스트 동시에 3개, 4개 돌리기 시작한다면 GPU 메모리 초과 및 GPU 쿠다 코어가 모잘라지게 된다. 그래서 2개까지는 1개 돌릴때랑 훈련속도가 매우 비슷한데 (차이가 있다면 GPU에서 오버헤드 발생하는 딱 그정도? 즉, 거의 없음), 3개 돌리는 순간 나머지를 기달려야해서 쿠다코어 부족해서, 쿠다코어를 기달려야한다. 그래서 훈련속도가 N배씩 늦어진다. -
CPU는 scale-up 관점, GPU는 scale-out 관점
->
즉, CPU는 CL에서 CPU 성능 좋으면 훈련 속도 자체가 빨라지고, GPU는 CL에서 GPU 성능 좋아져도 병렬로 처리할수 있는게 많아지는거기에 속도 자체가 빨라지진 않는다. -
CPU, CUDA CORE, TENSOR CORE 비유
->
CPU는 소수의 똑똑한 전문 엔지니어, CUDA CORE는 수천명의 단순 작업자(CPU랑 비슷, 다만 CPU의 멀티스레드가 훨씬 많다고 생각, 대신 성능은 안좋음), Tensor Core는 행렬곱에 특화된 수천명의 단순 작업자

-
CL에서 CPU 쓰는 구간과 GPU 쓰는 구간?
->
CPU:
(1) 훈련전: tripletSampler등으로 훈련 전 딱 한번만 데이터 로딩(Anchor, Positive, Negative), 데이터 로딩은 CPU로만 가능하다
(2) 1 에포크 당: train_loader로부터 로딩된 매 에폭마다 다르게 배치 데이터 선정, 그리고 그 데이터를 cpu to GPU로 적재하는 것 또한 CPU 사용
(3) 매 배치 당: 로스함수 업데이트 및, 런치 오버헤드
특히! CL에서 배치가 작기때문에 메모리는 아낄수 있어도, (3)의 매 배치 당 일어나는 CPU 사용은 더욱 더 심해진다.
이를 통해 알수 있는건 CL에서 CPU를 많이 쓰는건 CL의 수식과 같은 것들때문이 아닌, 배치 사이즈가 작거나, 데이터 로드때문에 그렇다고 생각해야한다.
GPU:
행렬곱 (그래서 굳이 positive, negetive mask를 만드는 것임 행렬 곱으로 표현하기 위해), 내적 (백터화로 표현되어있기에 내적도 GPU 사용), BCE(이거 CPU에서 될것같지만, 아래 수식에서와 같이 행렬곱으로 표현이 안돼도 각 샘플에 대해서 병렬처리한다. (이때 쿠다 코어 사용!!!)
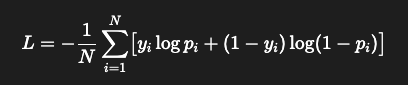
-
CL 로스 보면 CPU 사용할것 같이 생겼는데?
예를들어 아래의 KLD Loss을 보면 뭔가 CPU 쓰게 생겼다. 하지만 cuda()에 올라가있으므로 GPU 쓴다. 단, 행렬곱같은걸 안쓰는 수식이다보니 텐서 코어가 아닌 쿠다 코어를 사용한다. BCE에서와 마찬가지로 각 샘플에 대해 병렬적(쿠다코어 멀티스레드)으로 loss를 구해준다. 흠.. 하지만 배치가 너무 작아서 쿠다 코어 용량의 반에 반에 반도 못쓴다.

-
런팟 클라우드 등에서 컨테이너 수준에서 사용시, cuda 버전 호환이 안되는거 같다는것은 오해일 가능성이 높다.
->
그 이유는, GPU A5000, A6000, A100 등을 써도 CL에서 성능 안나온건 cuda 버전 호환 문제라고 생각했었는데,
사실은 그게 아니라 CPU 성능이 안좋았기때문일 가능성이 높다.
실제로 PRO6000에서는 CL 훈련 속도 RTX3060Ti만큼은 좋게 나왔었다(배치 1024). 아마 그게 가능했던 이유는, PRO6000은 CPU 성능이 좋았지 싶다. 3060Ti는 CPU 하나만큼은 되게 좋은걸로 했었다. -
cuda 세팅 환경을 도커로?
->
이게 호환만 잘되면 좋겠는데 내가 찾아본 이상 호환 되는거끼리 묶여있는 도커가 없다. 그래서 그냥... 내가 첨부터 세팅을 하는게 오히려 편한것 같다. 이거때매 시간을 너무 많이 소비했다.
참고로 >= 이렇게 호환되는거는 그냥 그 버전 이상이면 되는듯? recommend가 아니더라도? driver는 그냥 상위 호환이긴해서. 근데 어쨌든 때론 호환 안될수 있어서 주의해야긴한다. (아마 호환 안될 가능성도 크다) -
도커로 컨테이너 생성시 주의점
->
도커로 이미지 만들때 host의 엔비디아 드라이버가 다 제각각일수가 있다. 그리고 파이썬 버전도. 도커에 명시된 파이토치, 우분투, 쿠다 버전 제외하곤 제각각일수 있다. -
엔비디아 드라이버 호스트 vs 컨테이너
->
컨테이너에선 드라이버 버전 다르게 설정할수 없다. 무조건 호스트에 의존... 그래서 pod의 container만 지원하는걸로 하면 위험하다(호스트 드라이버 설정위하 호스트 접근 못하기때문). 호스트 자체를 지원하는 GPUaaS 이용하자. -
쿠다코어 vs 텐서코어
->
쿠다코어는 스칼라, 백터 연산에 강하다. FP32로 쿠다코어 성능 지표를 본다. CL로 치면 내적과 같은 연산이다.그래서 CL에선 쿠다코어 성능 지표가 더 중요하다. (단.. 런치 오버헤드가 없다는 가정하에..)
텐서코어는 병렬연산에 강하다. 그래서 LLM에선 쿠다코더보단 텐서코어를 봐야한다. -
A100을 LLM에서 많이 쓰는 이유?
->
텐서코어가 좋기도 하고 Multi GPU(NVLink) 지원한다. LLM 모델이 100GB라할때 A100 40GB 3개를 붙여서 하게 된다면 GPU간 통신 속도가 중요.
A100은 그 GPU간 통신속도가 NVLink 덕에 빨라서 한몸처럼 움직일수 있지만 PRO6000같은 경우는 NVLink가 없어 거의 GPU간 통신 속도가 10배 정도 느릴수 있다.
근데 100GB 모델이 아니라 90GB 모델로 한다면 PRO6000은 96GB 지원이기에 문제 없겠다. -
3060Ti vs PRO6000, Contrastive Learning 실제 훈련 속도에 큰 차이 없었던 이유
->
FP32 차이로만 보면 7배 이상의 성능 향상을 예측했지만 실제 테스트해보니 거의 1배의 성능이였다.(그래도 PRO가 1.3배는 좋아야할텐데)
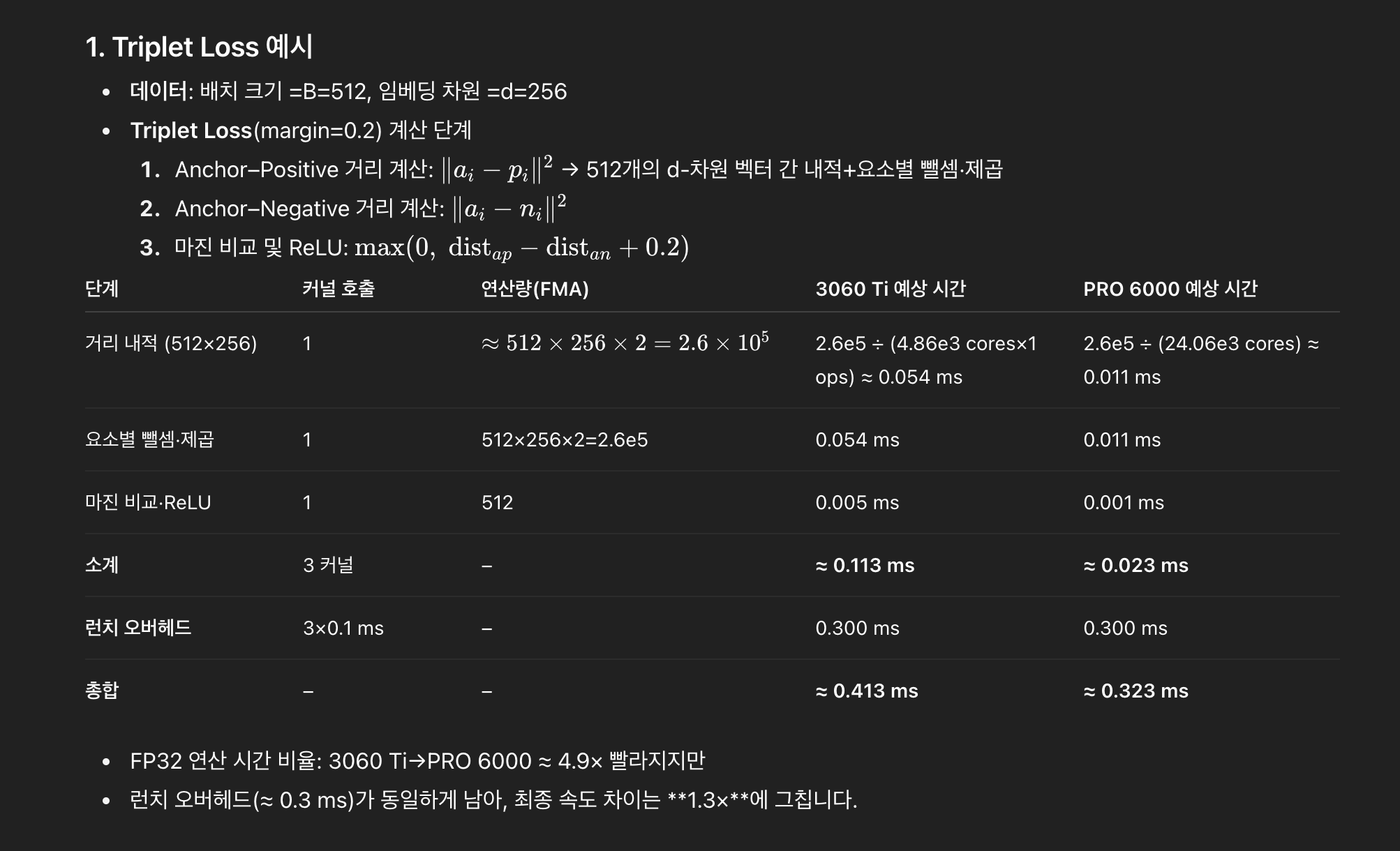
위와 같이 FP32는 스칼라, 백터 연산에 강하기에 실제 내적을 구할땐 5배 이상 PRO 6000이 빨랐다.
근데 런치 오버헤드로 인해서 최종 속도차이는 1.3x에 그친다.
런치오버헤드란, 커널 호출을 말한다. 거리내적, 제곱, 마진비교에서 총 3번을 부르게 된다.
그래서 실질적으론 FP32의 이점이 런치 오버헤드로 인해 가려진다.
물론 위 현상은 Triplet뿐 아니라 Xent Loss에서도 마찬가지. -
3060Ti보다 PRO6000이 더 좋은 경우?
->
당연히 LLM에선 병렬처리, 행렬곱, 텐서 코어 사용하기에 PRO6000이 더 좋다.
근데 CL과 같은 상황에서는 언제 PRO6000이 더 좋을까?
배치크기가 클때 특히 좋다.
"3060Ti vs PRO6000, Contrastive Learning 실제 훈련 속도에 큰 차이 없었던 이유"를 참고해보면, FP32속도가 빠른건 실제 유효하지만 런치 오버헤드때문에 전체 속도 향상은 미비하다고 했다.
그렇다면, 배치크기를 10배로 하면 FP32의 이점은 상대적으로 10배가 된다. 왜냐면, 오버헤드 소요 시간은 그대로지만, FP32 계산해야할 양은 10배로 늘었으니 상대적으로 그 이점도 10배가 되는 상황.
실제로,
(3060Ti, b=1024)=> 0.8~0.9 sec per a epoch
(PRO6000, b=1024)=> 0.8~0.9 sec per a epoch
(3060Ti, b=10240)=> 2.2 sec per a epoch
(PRO6000, b=10240)=> 1.55 sec per a epoch
위와같이 배치가 커지니 확실히 PRO6000의 이점이 커졌다.
배치 사이즈가 10배가 아닌 20배가 된다면, 그 이점은 더 커질것이다. -
PRO6000 에디션
-> 워크스테이션, MAX-Q, Server Edition이 있는데
워크스테이션은 1way만 가능. 즉, GPU마다 1:1 매칭으로 메인보드, CPU 등 필요
MAX-Q는 다중 way 지원. 하지만 워크스테이션 600W까지 가능하지만 얘는 300W까지만 가능. 이로인한 성능 트레이드 오프 존재. 발열잡기 위한 조치로 보임
서버에디션은 GPU에 팬이 안달려있음. 대신 400~600W까지 자유로이 사용하고 다중 way 가능. 하지만 소음 심각하고 에어컨 잘나오는 서버실 필요. -
그래서 나한테 맞는 GPU는?
->
PRO6000을 MIG 4개 이용하면 좀 좋을수도 있겠지만, 그럼에도 불구하고 A5000을 4개 사는게 더 나을수도 있겠다.
A5000 320만원
PRO6000 1,4000만원
근데 NVLink 안되는거 생각하면 메모리 높은 PRO6000이 더 합리적인 소비일수도 있다.
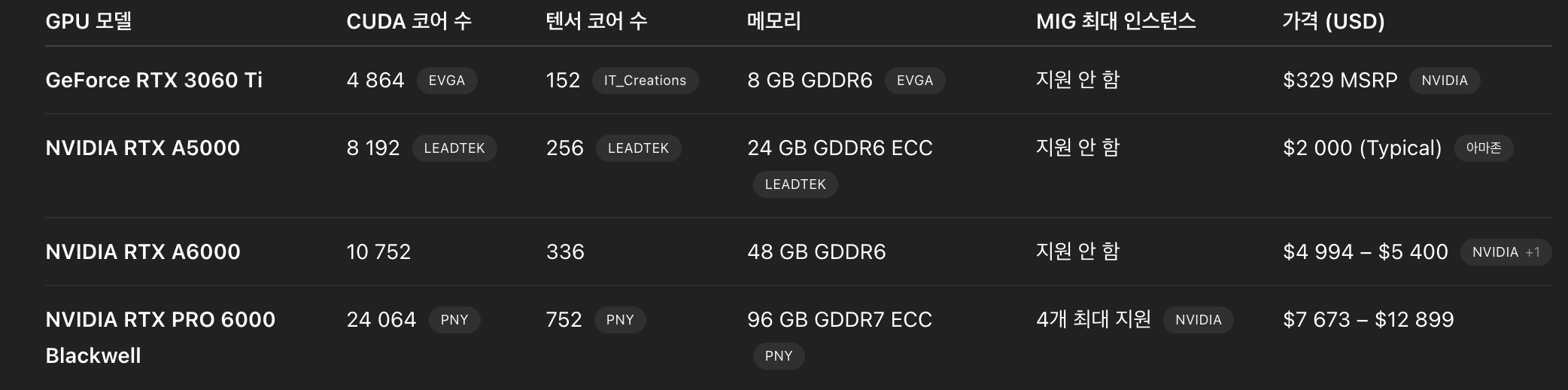
결론은, PRO6000에서 MIG 사용시 실제로 4배만큼 테스트를 더 돌릴수 있다면, PRO6000을 구매하자.
아! 그리고, 메모리 96GB는 엄청난 이점이 맞다. 테스트 동시에 2개정도(이정도는 3060Ti 기준동시에 돌릴때 속도 손실 거의 없음, 하지만 그 이상시 쿠다코어 부족 + 메모리 부족으로 속도 손실 N배)가 아니라 10개정도 동시에 돌릴거면 메모리 부족하지 않는게 중요하다! -
MIG를 통해 4개의 인스턴스를 사용하면 CL에선 4배의 효율을 낼수 있을까?
->
아래 언급에 따르면 그렇다. CPU 성능만 따라준다면 OK일것 같다.

