[논문 리뷰] MORPH: Towards Automated Concept Drift Adaptation for Malware Detection
안녕하세요.
오늘은 MORPH: Towards Automated Concept Drift Adaptation for Malware Detection에 대해서 논문 리뷰 해보도록 하겠습니다.
본 논문에서 의미하는 MORPH는 (autoMated cOncept dRift adaPtation algoritHm) 을 의미합니다.
문장 그대로 해석해보면 자동화된 concept dritf 적용 알고리즘 정도로 봐주시면 될 것 같습니다.
MORPH의 의미에서 유추할수 있듯이 본 논문에서는 concept drift에 대응하기 위해 자동으로 어떠한 알고리즘을 적용하는 것입니다.
여기서 말하는 그 어떠한 알고리즘은 semi-supervised learning을 이용한 pseudo label을 구하는 것입니다.
이를 통해 unlabeled 된 data를 학습시켜주고 concept drift에 대해 사람의 개입 없이 대응 할 수 있다는 것입니다.
자세한건 아래 Introduction에서 설명하도록 하겠습니다.
1. Introduction
본 논문에서는 pseudo label을 통해 사람의 annotation effort를 줄였습니다.
이전에 소개 드린 Continuous Learning for Android Malware Detection에서는 active learning을 하며 매 달 가장 uncertain한 sample들을 우선순위 매겨 사람이 직접 label을 annotation 해주었습니다.
이를 통해 10,000개를 사람이 직접 labeling할 것을 100개만 해줄수 있게 annotation effort를 줄인 것은 사실입니다.
하지만 본 논문은 annotation에 대한 사람의 effort를 사실상 0에 수렴하도록 automate 시키면서 concept drift를 탐지하는 것이 목표입니다. 사람이 직접 100개 조차도 labeling 하지 않는다는 것을 의미합니다.
본 논문에서는 pseudo labels를 제안합니다.
즉, 모델 스스로 semi-supervised learning을 하여 labeling을 해줍니다.
자동화된 concept drift 탐지에 관련해서 DroidEvolver라는 기법이 있습니다.
이 기법은 총 5가지의 모델을 결합한 앙상블 모델입니다.
앙상블 모델들의 prediction을 이용해 앙상블 모델로부터 aging models를 찾습니다.
이러한 앙상블 모델에는 몇 가지 단점이 있습니다.
1) 선형 모델로 이루어져 있기 때문에 고차원 데이터에 다소 약한 모습을 보입니다.
2) self-poisoning로 인해 성능이 급격히 나빠질 위험이 있습니다.
물론 본 논문에서 제안하는 pseudo labeling에도 문제가 있습니다.
모델에 의해 자동적으로 labeling되기 때문에 noise가 생길 수 있습니다.
noise가 생기는 이유는 단순합니다.
모델이 자동적으로 labeling 하기 때문에 잘못된 label을 입력할 수 있다는 것입니다.
이를 해결하기 위해 모델의 decision boundary를 조정합니다.
예를들어, malware를 predict 할 때 0.6 이상이 나오면 그것을 malwware로 labeling 하는 식으로 treshold를 정해준다고 생각해도 될 것 같습니다. 이에 대한 자세한 내용은 뒤에서 다시 설명 드리겠습니다.
본 논문에서 제안하는 방식이 효율적이다 라는 것을 증명해내기 위해 3가지 Question에 대한 입증을 합니다.
그 3가지는 다음과 같습니다.
RQ1
실제로 pseudo-labeling이 자동적으로 concept drift에 대응할 수 있는지?
-> 이를 입증하기 위해 ground-truth labels 없이 pseudo labels를 평가하였습니다.
RQ2
pseudo-label-based 기법이 실제로 concept drift adaption에 대한 annotation effort를 줄였는지?
-> 이를 입증하기 위해 기본적인 active learning의 한 기법과 비교하였습니다.
RQ3
기존의 pseudo-label-based 접근법인 DroidEvolver++와 비교했을 때 본 논문에서 제안하는 신경망 기반 MORPH는 어떤지?
-> 이를 설명하기위해 DroidEvolver++와 신경망 기법인 본 논문을 비교 평가했습니다.
2. Motivation
Concept drift는 시간이 지남에 따라 Benign 혹은 Malware dataset의 distribution의 변화에 따라 일어납니다.
이러한 Concept drift 현상을 해결하기 위해 supervised-learning 환경에서는 절대적으로 labeled dataset에 의존하게 됩니다.
이러한 의존은 annotation effort를 매우 증가시킵니다.
즉, 효율성이 매우 떨어집니다.
그에 반해 본 논문에서 제안하는 semi-supervised learning은 상대적으로 data를 훈련시키기 쉽습니다.
그 이유는 unlabeled data에 대해 훈련하기 때문입니다.
이를 통해 annotation effort를 감소시킵니다.
일반적으로 Benign과 Malware을 구분하기 위해 softmax로 이루어진 NN을 사용합니다.
이 모델의 특징은 Benign 혹은 Malware을 구분할 때 약간 확증 하는 경향이 있는 듯 합니다.
물론 Benign을 Benign으로 확증 하는 경우에는 상관 없지만,
concept drift가 일어나 Malware을 Benign으롤 보는 경우에 또한 확증 하는 경향이 그대로 남아있어
Malware를 Benign이라고 확증 할 것입니다. (Benign에 대해 높은 %를 갖을 것입니다.)
방금 한 설명을 도식화 하여 설명하자면 아래와 같습니다.
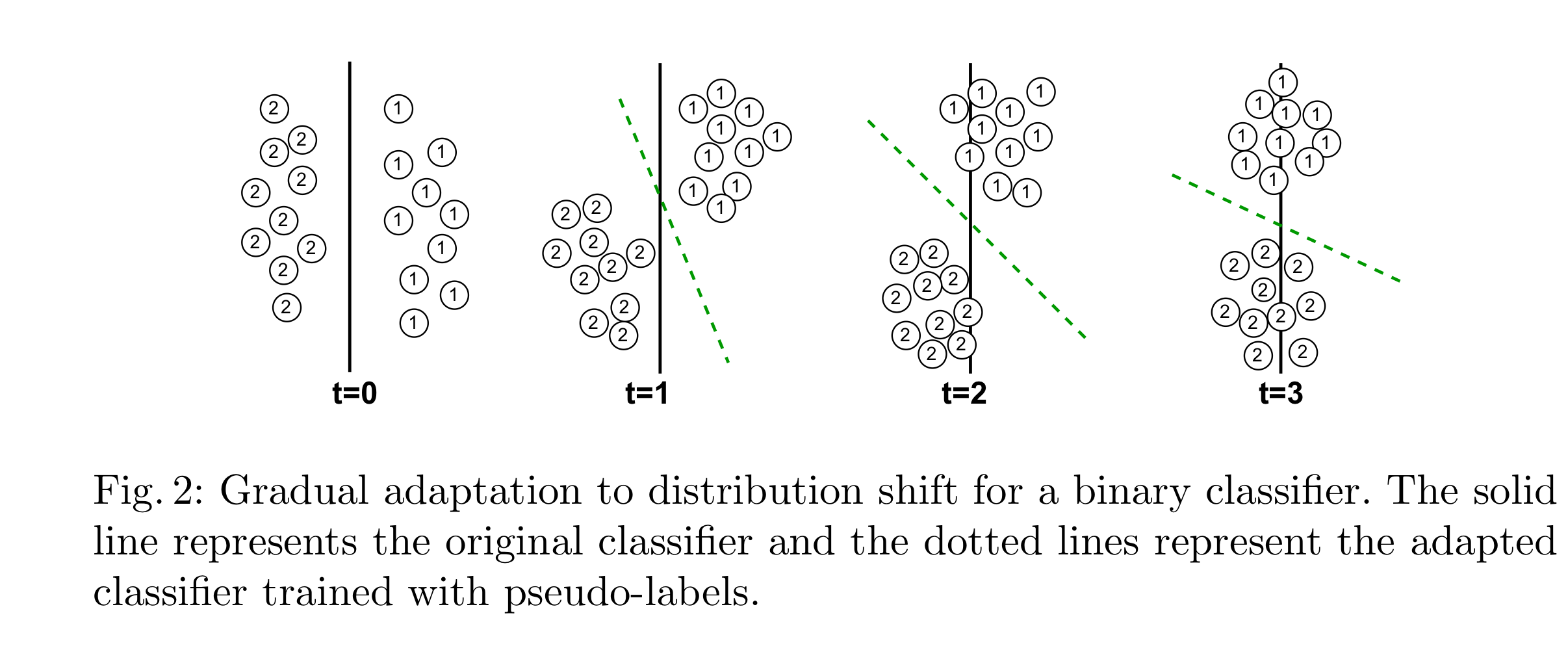
시간이 갈수록 즉, t 값이 커질수록 1과 2의 distribution에 변화가 생기며 원래 classification 했던 decision boundary인 검은 실선을 기준으로 정확히 나눠지지가 않습니다.
이를 해결하기 위해 본 논문에서는 self-training (semi-supervised learning)을 하였고
그에 따라 검은 실선이 아닌 초록 점선을 통해 decision boundary가 생성되어 1과 2를 보다 더 잘 나눠줍니다.
self training 방식에도 단점은 있는데 그것은 noise label에 대해서도 training data로써 훈련해준다는 것입니다.
본 논문에서는 이러한 문제를 malware에 대한 treshold를 0.6으로 지정하여 해결합니다.
3. Proposed Methodology
본 논문에서 제안하는 방식의 아키텍처는 아래 그림과 같습니다.
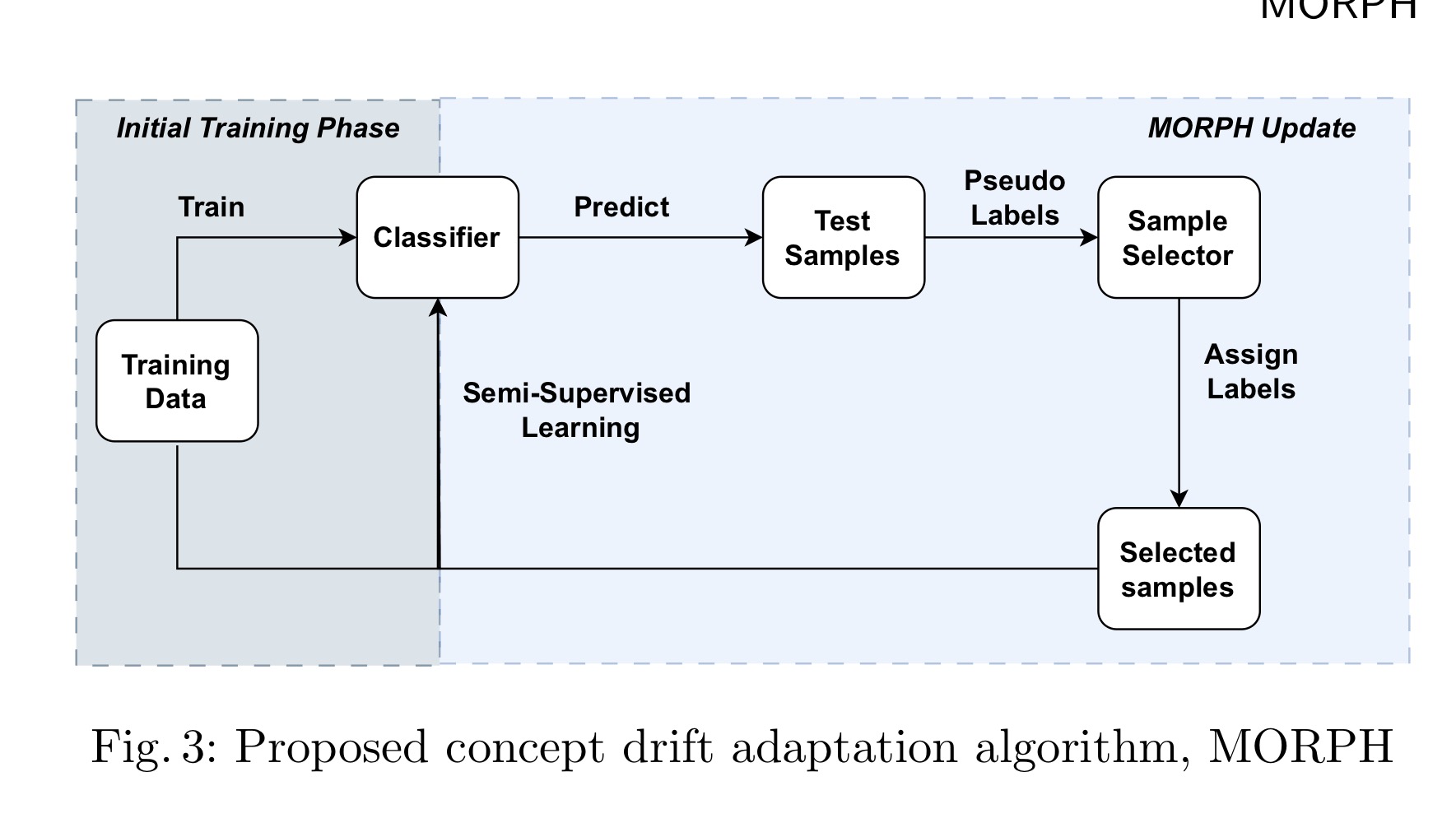
첫 번째로,
initial training data에 대해서 훈련합니다.
여기서 initial training data는 labeled data에 대해서 훈련합니다.
두 번째로,
훈련된 classifier을 통해 데이터를 예측하고 Test Samples라고 가정합니다.
여기서 예측된 데이터는 Pseudo labels의 softmax 값 즉, 예측된 y값에 대한 확률이라고 봐주시면 됩니다.
세 번째로,
Pseudo Labels를 입력으로 Sample Selector을 통해 retraining할 sample들을 select 합니다.
네 번째로,
selected labels를 이용해 semi-supervised learning을 합니다.
즉 retraining을 합니다.
이러한 절차를 통해 MORPH는 unlabeled data를 이용해 그리고 pseudo labels를 이용해 semi-supervised learning을 해줍니다.
이런 방식으로 semi-supervised learning을 하게 되면 concept drift에 대해 상대적으로 강한 모델이 만들어지게 됩니다.
3.1 Sample Selection Algorithm
본 논문에선 각 라벨에 대해 다른 Treshold를 주어서 Pseudo Labels를 지정해줍니다.
각 라벨에 대해 즉, Benign과 Malware에 대해 다른 Treshold를 주는 이유는 아래 Fig. 4를 참고하면 됩니다.
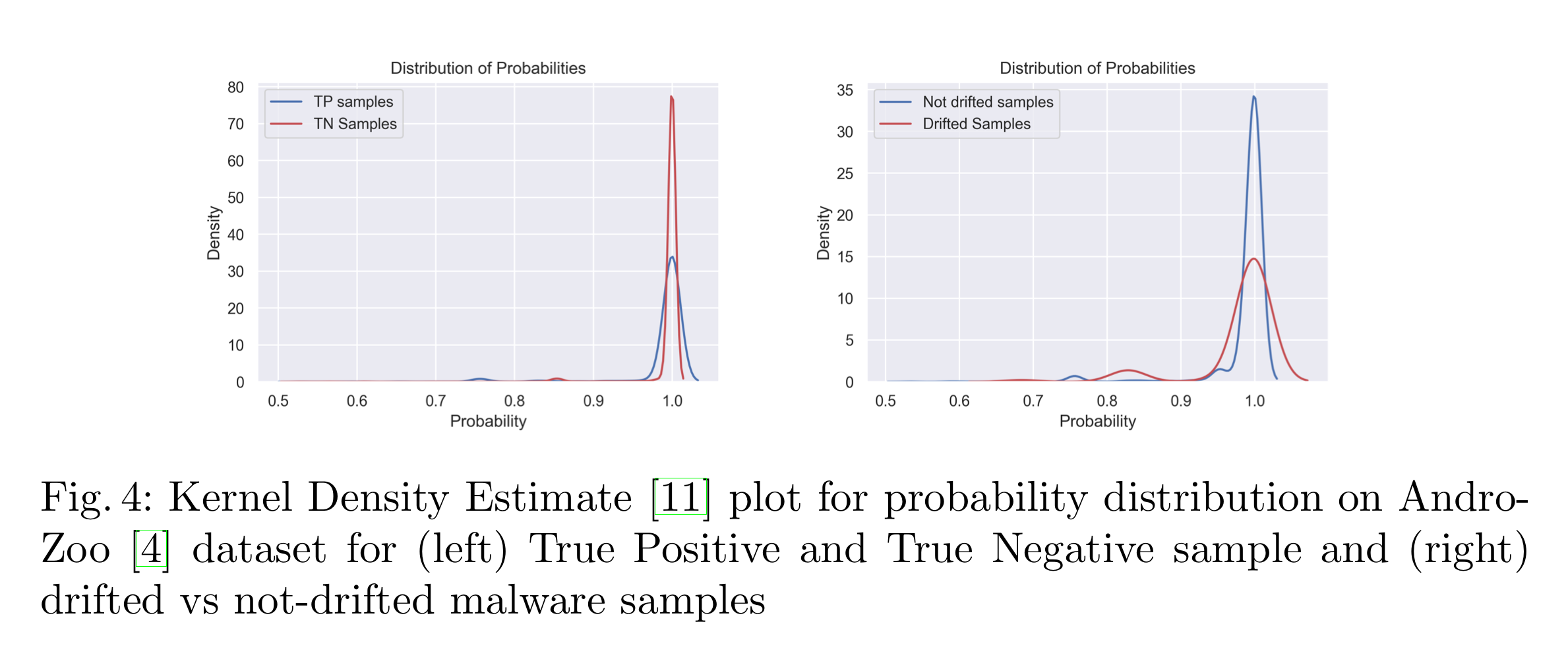
위 Fig. 4의 왼쪽 부분은, Malware와 Benign에 대한 TP와 TN을 나타냅니다.
Probability 1.0에 대해 TN의 Density는 상당히 높게 나오고 그에반해 TP의 Density는 상당히 낮게 나옵니다.
여기서 가리키는 TP는 Malware를 Malware로 분류한 케이스이고 TN은 Benign을 Benign으로 분류한 케이스입니다.
Malware를 Malware로 분류가 잘 안되는 이유는 보통 공격자가 Malware를 최대한 Benign처럼 보이게 해 공격을 성공하려는 특성이 있기 때문입니다.
Fig. 4의 오른쪽 부분은 Drifted Samples에 대한 Probability입니다.
Drifted Sample에 대해 낮은 Density가 나오는 이유도 위와 마찬가지입니다.
Pseudo Labels를 정하는 방법에 대한 자세한 알고리즘은 다음과 같습니다.

Line 1-3:
Test sample에 대해 Malware로 예측한 것은 에 추가하고,
Benign으로 예측한 것은 에 추가합니다.
Line 4:
에서 개 만큼 샘플을 랜덤하게 뽑습니다. 단, condifence가 보다 커야합니다.
추후에 은 실험적으로 0.6으로 상정됩니다.
또한 은 confidence가 보다 큰 개수로 상정됩니다.
Line 5:
에서 개 만큼 샘플을 뽑습니다. 단, confidence가 보다 커야하며, 는 보단 커야합니다.
그도 그럴것이 직관적으로 생각해볼때도 Fig. 4에서 설명했듯이 Malware를 Benign처럼 보이게 하려는 특성이 있으므로 보다 이 대체로 낮을 것입니다.
여기에선 개 만큼 랜덤하게 뽑는게 아닌, confidence가 높은 순서대로 뽑습니다.
Line 6:
Selected 된 Benign, Malware Sample을 return 하여줍니다.
3.2 Semi-Supervised Training
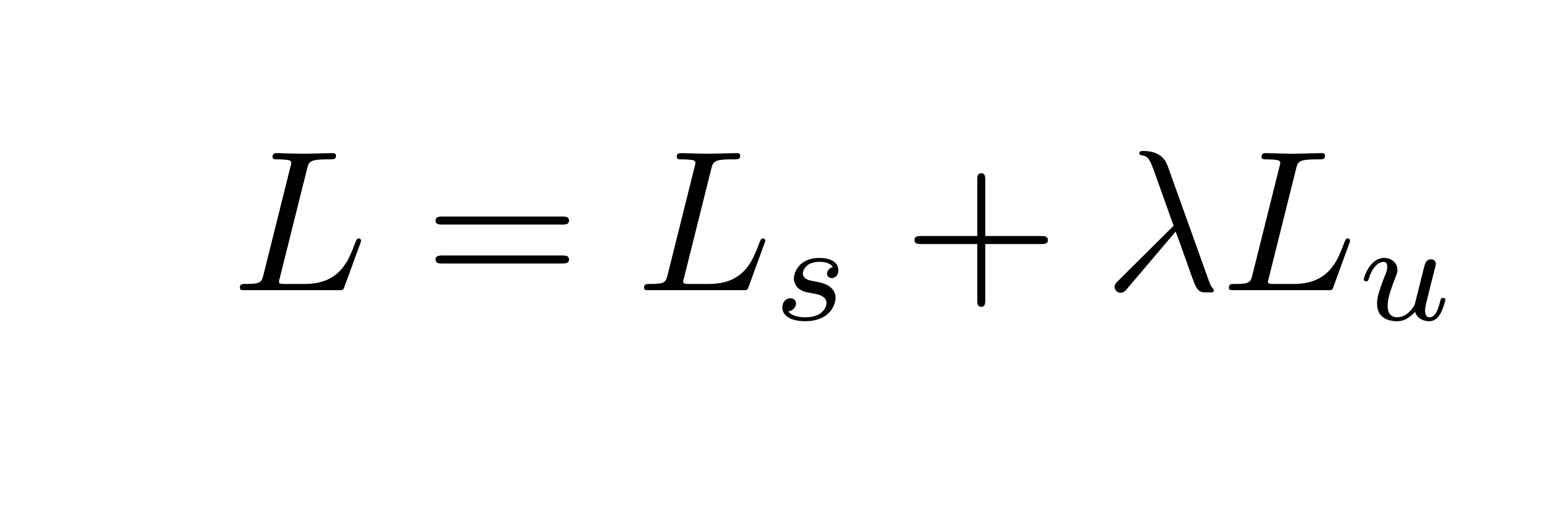
최종 로스 값은 위와 같습니다.
는 supervised learning에 대한 loss 값이고,
는 semi-supervised learning에 대한 loss 값입니다.
training이 진행될 때 각 Loss에 입력되는 샘플의 개수는 같으며
supervised loss에는 manually annotated samples을 입력하고,
semi-supervised loss에는 Algorithm 1에서 return 된 pseudo-labeled 된 sample들을 입력합니다.
여기서 주의할 점은 두 sample의 개수는 같습니다.
λ는 상대적으로 각 Loss의 weight를 조정하기 위한 값이지만 본 논문에선 1로 상정합니다.
4. Dataset
데이터셋은 간단히 어떤 데이터셋을 어떻게 쓰는지를 소개하도록 하겠습니다.
4.1 Androzoo dataset
Androzoo dataset은 제게 익숙한 데이터셋이며, hierarchical dataset에서도 사용하였습니다.
Android malware dataset에서 대표적인 데이터셋이라고 봐주시면 됩니다.
2019년 ~ 2021년 까지의 데이터가 수집되어 있으며 16,978개의 binary features가 존재합니다.
본 논문에서는 2019년 모든 월의 데이터를 training dataset으로 사용하였으며
2020년 1월 데이터는 validation dataset으로 사용하였습니다.
그리고 나머지 23개월 분량의 데이터는 test dataset으로 사용합니다.
4.2 EMBER dataset
EMBER dataset은 Androzoo dataset와 다르게 Window 환경에서의 malware dataset입니다.
총 2381개의 features가 존재합니다.
Androzoo에 비하면 더 적은 feature을 갖고 있습니다.
2017년 ~2018년 까지의 데이터가 수집되어 있습니다.
2017년 1월의 데이터에 대해서만 훈련을 하고, 2017년 2월의 데이터셋을 통해 검증 합니다.
그리고 나머지 22개월의 데이터셋을 통해 테스트합니다.
참고로 훈련 데이터셋으로 2017년 1월 데이터셋만 사용한 이유는 Androzoo dataset에 비해 데이터의 개수가 크기때문에 한 달의 데이터셋으로도 충분하다고 판단한 것 같습니다.
여기서 주의할 것은,
EMBER dataset의 2018년 dataset은 의도적으로 분류하기 어려운 데이터셋이 선택되었습니다.
그렇기 때문에 이전의 데이터로 훈련된 모델이 안좋은 성능을 보일 것으로 예상됩니다.
Androzoo dataset이 binary feature인데에 비해 Ember dataset은 그렇지않기 때문에 StandardScaler을 이용하여 표준화 하였습니다.
5. Experiments and Results
5.1 Experimental Setting
을 구하기 위해서 Androzoo의 처음 6개월의 데이터셋을 사용하였습니다.
그 결과 은 0.6일 때 가장 효율적인 분류를 하는 것으로 측정되었습니다.
여기서 은 malware에 대한 softmax 결과의 confidence를 의미합니다.
5.2 Utility of Pseudo Labels
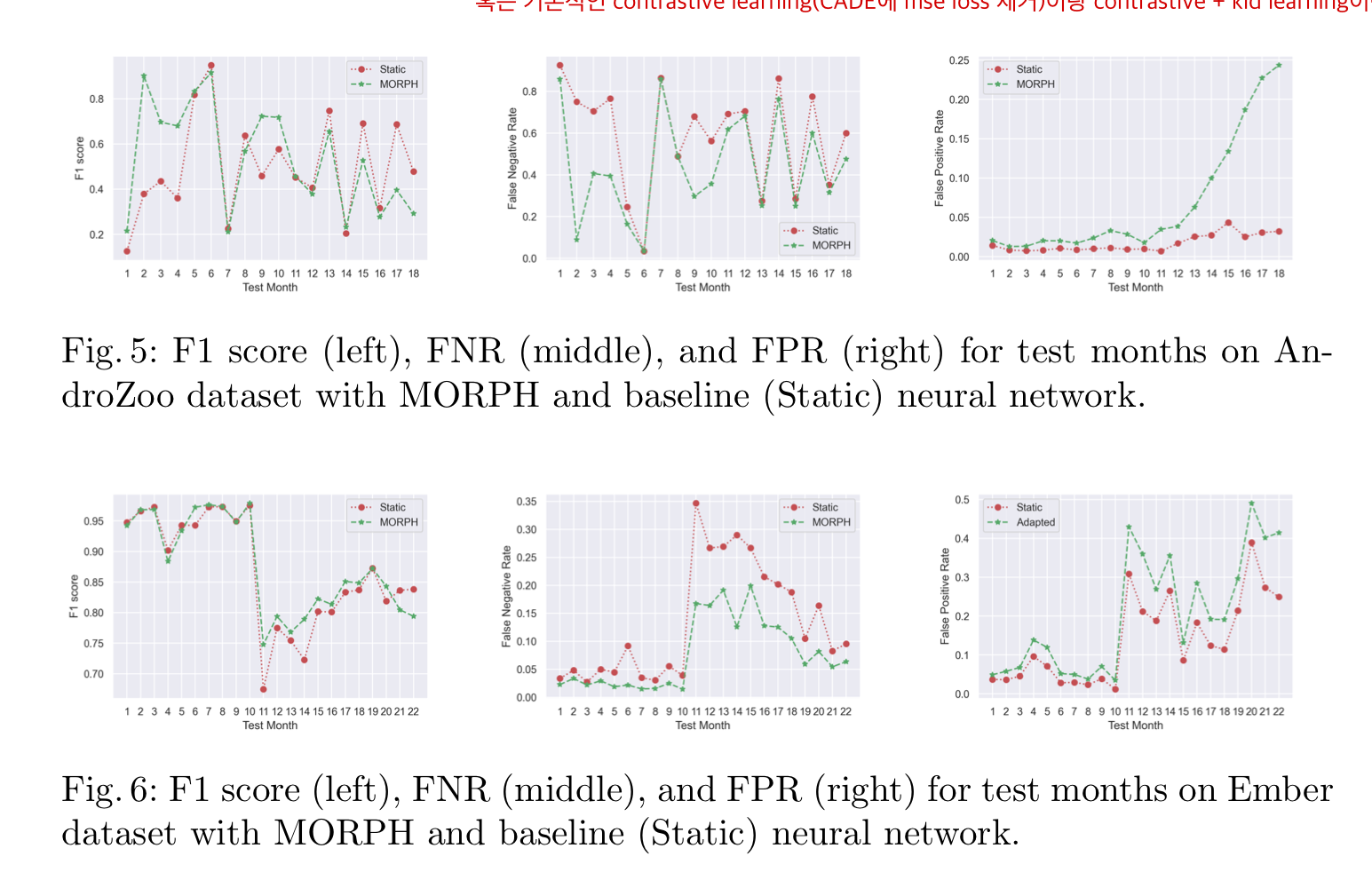
본 논문에서는 아래 이미지와 같이 기존 Static model에 비해 본 논문에서 제안하는 MORPH가 전체적으로 F1 Score가 더 높은 것을 확인할 수 있습니다.
또한 전체적으로 FNR score또한 낮게 형성되어있습니다.
즉, 새롭게 들어오는 악성 데이터를 양성 데이터로 판단하는 비율이 낮다는 의미입니다.
하지만 Fig 5와 6의 가장 오른쪽 이미지를 보면 알수 있듯이 기존의 모델보다 FPR이 높게 형성되는것을 알 수 있다.
이는 semi-training의 한계로 볼 수 있는데, self-poisining 문제로 보여집니다.
본 논문에선 EMBER, Androzoo 데이터셋만 사용하였는데
제 생각에는 semi-training 특성상 Month가 많아지면 많아질수록 self-poisioning의 영향을 누적해서 받기 때문에 비교적 month의 갯수가 적은 EMBER, Androzoo dataset을 사용하고 APIGraph dataset은 사용하지 않은 것으로 보입니다.
그래서 본 논문에서 RQ1에 대해 입증 가능해집니다.
RQ1: Can pseudo-labeling alone enable automatic concept drift adaptation in neural network-based malware detection?
5.3 Combination with Active Learning
RQ2에 대한 물음에 대한 답을 하기 위해 본 논문에서는 MORPH와 active learning을 혼합합니다.
active learning에서 하는 역할인 uncertain sample select를 수행하기 위해 가장 uncertain한 prediction을 샘플링합니다. (예를들어 uncertain sample을 측정하기 위해 softmax layer의 출력 계층을 사용합니다.)
본 논문에서는 매 달 100개의 가장 uncertain한 sample을 select 하였습니다.
그리고 매 달 100개의 uncertain sample에 대해 retrain 해주었습니다.
그 결과 MORPH가 아닌 경우에 비해 MORPH인 경우에 labeling 하는 effort를 50% 가량 감소시켰습니다.
또한 SOTA인 HC method를 이용, 비교해 active learning을 SOTA 환경에서도 적용시켜보았습니다.
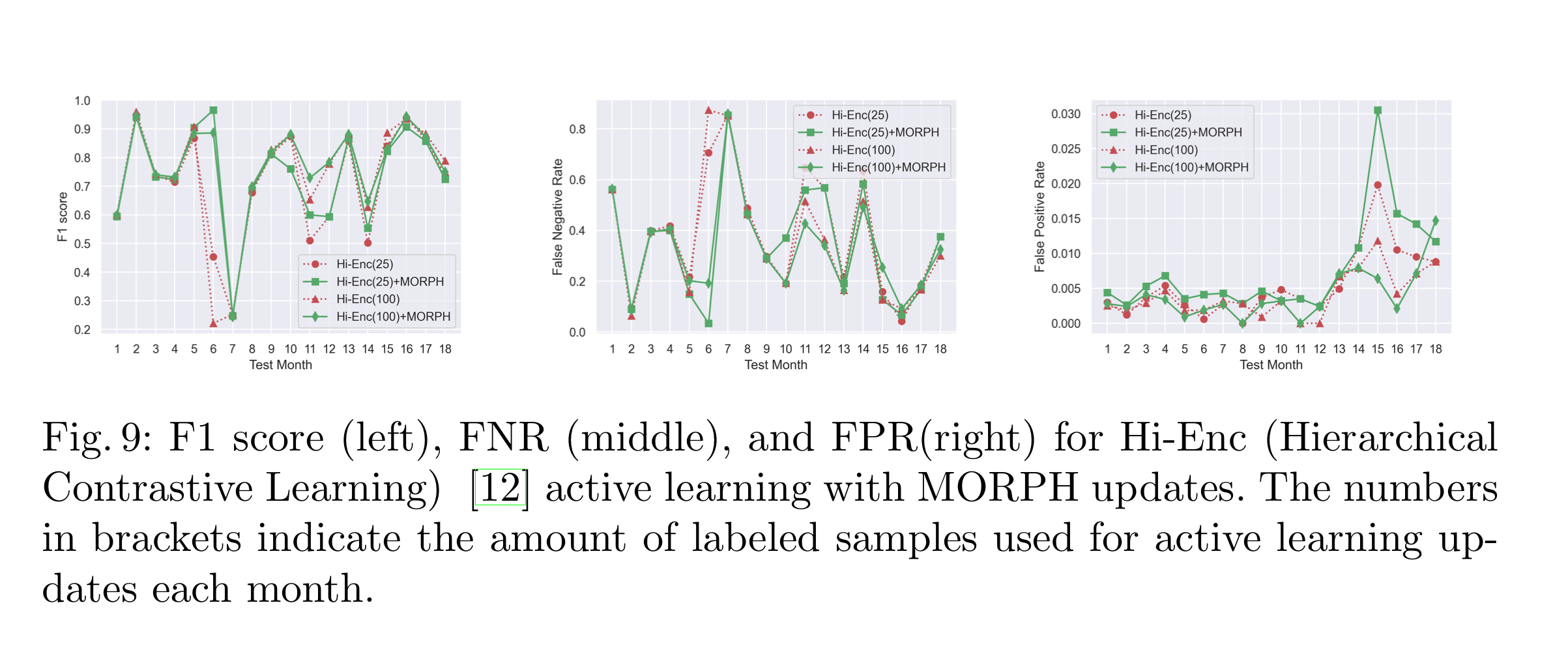
위 이미지에서 보듯이 HC만을 사용하여 active learning을 하는 것 보다 HC + MORPH를 했을 때 F1 score가 3.46% 높은 것을 확인할 수 있습니다.
또한 우리는 RQ2의 물음에 아래의 3가지 답을 할 수 있게 됩니다.
RQ2: To what extent can pseudo-label-based adaptation reduce the frequency of annotation in active learning?
To explore this question, we quantify the reduction in annotation require- ments by comparing the performance of the pseudo-label-based adaptation algorithm with traditional active learning approaches.
- MORPH는 안정적인 모델 성능을 유지하기 위한 active learning의 노력을 줄일 수 있다. (가령 uncertain sample select를 300개 할 것을 100개만 하면 된다는 의미)
- active learning은 semi-training의 단점인 self-poisoning인 noisy pseudo labels의 영향을 감소시킬 수 있다. (제 생각엔 self-posining인 noisy pseudo labels의 영향을 받긴 하지만, 그렇게 영향을 받은 상태의 model이 가장 uncertain sample을 select하고 retraining하기 때문에 self-poisning 영향을 감소시킬 수 있다고 설명하는 것 같습니다.)
- MORPH는 다른 active learning 기법과 같이 사용될 때도 효율적입니다.
6.4 Comparison With DroidEvolver++
DroidEvolver와 그 업데이트 버전인 DroidEvolver++은 concept drift adaptation 영역에서 잘 알려진 기법입니다. 이 모델은 시간에 따라 변하는 data distribution에 adapting합니다.
하지만 사실 DroidEvolver은 본 논문에서 제안하는 모델과 Architecture가 근본적으로 다르기 때문에 비교 대상이 아닐 수 있습니다.
그럼에도 불구하고 본 논문에서 제안하는 모델과 concept drift adaption에서의 공통점이 있기 때문에 비교를 합니다.
DroidEvolver에서는 5개 신경망의 앙상블 기법을 활용합니다.
그리고 이 앙상블은 유기적으로 서로 연결돼 최종적으로 예측을 합니다.
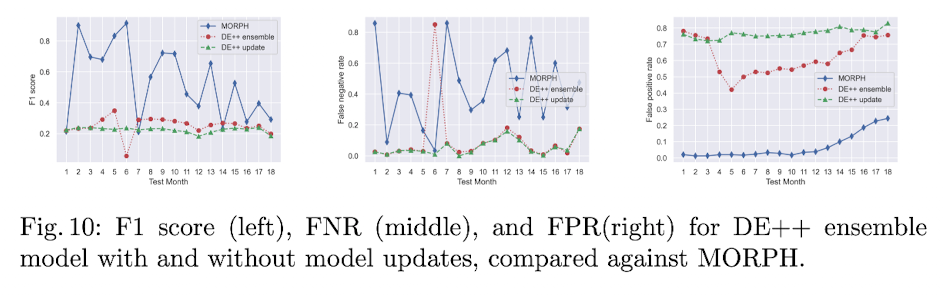
위 이미지에서 보듯 DE++ 기법과 DE++에 update model을 하는 기법을 비교했을 때 MORPH가 더 높은 F1 score을 얻습니다.
이제 우리는 RQ3에 대한 답을 할 수 있습니다.
RQ3: How does our pseudo-label-based approach with neural networks com- pare to prior automated concept drift adaptation methods?
To investigate, we benchmark our model performance against DroidEvolver and DroidEvolver++ to demonstrate the efficacy of the proposed neural network-based method.
- 본 논문에서 제안하는 모델이 DE++ 앙상블 기법보다 concept drift에 강했습니다.
- 본 논문에서 제안하는 모델이 DE++ 앙상블 기법보다 self-posining 영향에 더 강인한 것으로 보여집니다.
Discussion
Different in Datasets
EMBER dataset과 AndroZoo dataset에는 하나 큰 차이가 있습니다.
그것은 바로 benign sample과 malware의 비율 차이입니다.
EMBER dataset에는 비슷한 비율로 benign과 malware가 존재합니다.
하지만 AndroZoo에는 benign이 malware에 비해 압도적으로 많습니다.
9:1의 비율이 넘어간다고 생각하시면 될 것 같습니다.
또한 AndroZoo의 family에 최소 5개 이상의 data sample을 갖고 있는 게 122개 family 중 단 45개 입니다.
그래서 concept drift 현상을 AndroZoo가 더 심하게 받는다고 생각해주시면 될 것 같습니다.
다시 말해서, 각 famamily에 sample의 개수가 많으면 해당 family의 다양한 유형의 data distribution에 대해 학습할 수 있어 concept drift 현상에 더 강할수 있지만 그 개수가 너무 적게 되면 자연스레 concept drift 현상에 약해지게 됩니다.
Feasibility of Complete Automation
본 논문에서는 MORPH를 이용해 완전한 자동화를 통해 model을 훈련, 재훈련하였습니다.
하지만 어떤 상황에서는 이러한 완전 자동화가 불가능할 수 있습니다.
그 상황은 공격자가 기존 공격과 매우 다른 형태의 공격을 할 때입니다.
그 이유는 본 논문에선 malware에 대한 prediction treshold t를 0.6으로 보고 있는데,
매우 다른 형태의 malware 공격이라면 0.6 그 이하로 볼 것이기 때문입니다.
Conclusion
결론적으로 본 논문에서는 semi-training을 통해 malware에 대한 treshold인 t를 기준으로 malware와 benign을 분류 해줍니다.
이렇게 분류된 labels은 pseudo labels라고 부르며, 이 pseudo labels를 매 달 retraining 해줍니다.
이 모든 과정은 t를 하이퍼 파라미터로 사용자가 직접 지정해주는 것 이외에는 모두 자동화 됩니다.
위 과정을 거치는 기법을 MORPH라고 하며 기존 static model 보다 높은 성능을 보이며 심지어 active learning 환경에서도 더 높은 성능을 보입니다.
