Deep Learning for Time Series Anomaly Detection: A Survey
1. Introduction
https://dl.acm.org/doi/pdf/10.1145/3691338
최근 TSAD 기법에는 DAEMON, TranAD, DCT-GAN, Interfusion가 있음
Txaonomy 기반 기법에는 다음이 있음: forecasting-based, reconstruction-based, representation-based and hybrid methods
2. Background
2.1 일변량 타임시리즈 (UTS)
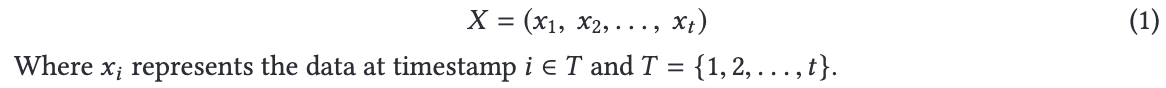
예를들어,
X = 습기
x1, x2, ..., xt = timestamp 1 시점의 습기, timestamp 2 시점의 습기, timestamp t 시점의 습기
2.2 다변량 타임시리즈 (MTS)

X = 시계열 데이터
X1 = 습기, X2 = 온도
= timestamp 1 시점의 습기, = timestamp 2 시점의 습기
= timestamp 1 시점의 온도, = timestamp 2 시점의 온도
위를 통해 장점은, 시간별 습기의 특성을 파악하는것 뿐만 아니라 습기와 온도의 관계도 파악이 가능하다는 점이다.
2.3 시계열 분해
Secular trend, Seasonal variations, Cyclical fluctuations, Irregular variations로 분해 가능.
Secular trend (장기 트렌드):
장기 트렌드를 말함. 선형적이지 않음.
예를들어 수년에 걸쳐 한 지역의 인구의 증감처럼 올랐다 내렸다 함.
계속 오르거나, 내리거나 하지만은 않음.
Seasonal variations (계절적 변화):
달별, 월별, 일별로 시계열은 계절적 변화가 나타남.
계절성은 고정된 주파수를 일으킴.
예를들어 전기 소비량은 일년동안 같은 커브를 그리지 않음.
여름에는 에어컨때매 더 많이 사용할것임.
그래서 계절성, 지역성에 따라 시계열 패턴은 다를것임
Cyclical fluctuations(주기적 변동):
Secular trend, Seasonal variations을 더 넓은 의미에서 본것 같다.
가령 경기 호황, 경기 리세션 등과 같은 주기
Irregular variations (규칙적이지 않은 변화):
랜덤하거나 불규칙한 이벤트로 인한 변화. 지진 생각하면 됨.
이 변화는 다른 컴포넌트에서(위 3개)의 나머지라고 생각하면 됨.
시계열은 위 4가지를 통해서 수학적으로 표현될수 있음.
각개로는 정상 행동과 거리가 있을수 있음.
참고:
LLMDetector에선 patch-wise, point-wise가 있었으니, 아마 Secular trend, Seasonal variations을 본게 아닐까 싶다.
2.4 Anomalies in Time Series
It is possible to see changes in time series datasets owing to concept drift, which occurs when values and trends change over time gradually or abruptly [3, 128].
라는 말이 있다. 그렇다는 것은 concept drift와 관련 있다는 것이다.
2.4.1 Types of Anomalies
UTS, MTS에서의 Anomalies는 시간적, 상호적, 시간-상호적으로 나뉜다.
Global anomalies는,
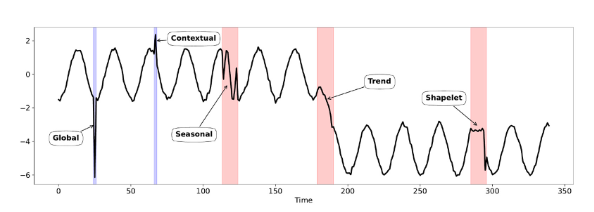
위 이미지에서 보면 타임시리즈 내에서 특정 point에 이상치가 있다.
즉, point 이상치같다. 수식으로 보면 아래와 같다.

예를들면, 오후 12시~오후 10시까지가 가장 큰 체크카드 결제가 이루어지는데
갑자기 오전 3시에 엄청 큰 결제가 이루어진 상황.
Contextual(전후 관계) anomalies는,
어느 지점에서는 정상일수도, 비정상일수도 있다. 이웃들의 값에 따라서.
위 이미지 보면, 정상으로 판단된다.
하지만 Global anomalies 기준으로 보면 비정상이여야한다.
하지만 정상인 이유는 이웃 지점이 자연스럽게 증가하는 추세이기에 정상으로 나온다.
즉, 주변 문맥 정보를 고려한다는 뜻이며,
수식도 Global anomalies랑 똑같지만, 주변 문맥 정보에 따라 임계값이 다르다.
Seasonal anomalies는,
시즌성을 나타냄.
예를들어 레스토랑에서의 매출도 주마다 (시즌성) 흐름이 있음.
그래서 이 시즌성도 파악을 해주고 이에 따른 anomalies도 찾아줘야함.

는 두 시퀀스 사이의 닮지 않은 정도를 측정하는 기능임.
는 실제 시즌성을 나타내고, 는 예측된 시즌성을 나타냄
위 이미지 (a)에서 시즌성 빨간 부분 보면,
global 측면에서 봐도 정상이고, contextual로 봐도 정상이겠지만
해당 시즌에서는 내려 꽂기만 해야는데, 올라갔다 내려갔다 반복함.
즉, 해당 시즌에는 이상하다. 라고 한단하여 이상탐지를 함.
Trend anomalies는,
노래 신곡이 발매 됐을때는 한창 잘나가다가, 1달 뒤부터 차트에서 인기가 떨어져, 트렌드 자체가 바뀔수 있다.
이런 트렌드의 변화를 탐지하는 것이다. 수식은 아래와 같으며, 는 실제 트렌드, 는 정상 트렌드를 말한다.
Shapelet
Trend가 바뀌는건 아니고, Trend보다 더 짧은 기간인 subsequence pattern에서 "차별성"을 본다.
예를들어 코로나로 인한 2~3달정도의 짧은 침체때문에 매출이 감소할수 있고,
무역 문제로 인해 요소수 수입이 감소할수 있다.
장기적인 트렌드는 그대로이지만, 단기적으로 변화가 있는 현상이다.
물론, 해당 시퀀스를 보고 이게 Trend 이상인지, Shapelet 이상인지는 나중에 가서야 알수 있는것이다.
3.2 예측 기반
3.2.1 RNN 기반, ex) RNN, LSTM
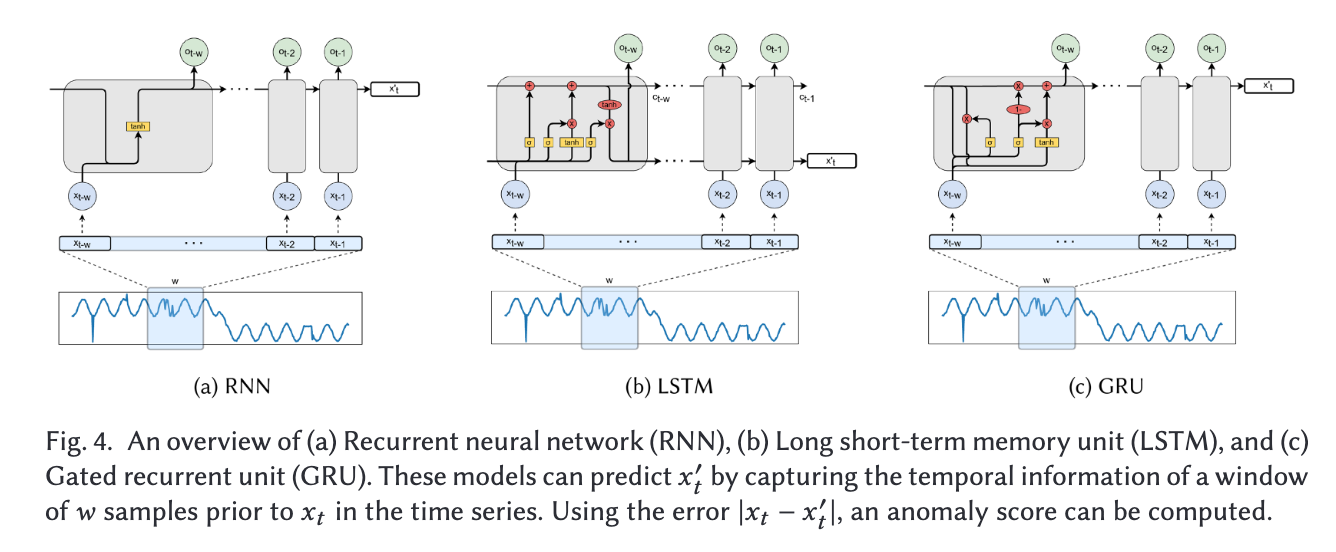
장기 기억에 약해서 트랜스포머한테 안된다.
3.2.3 GNN 기반 (Graph TSAD), ex) GDN
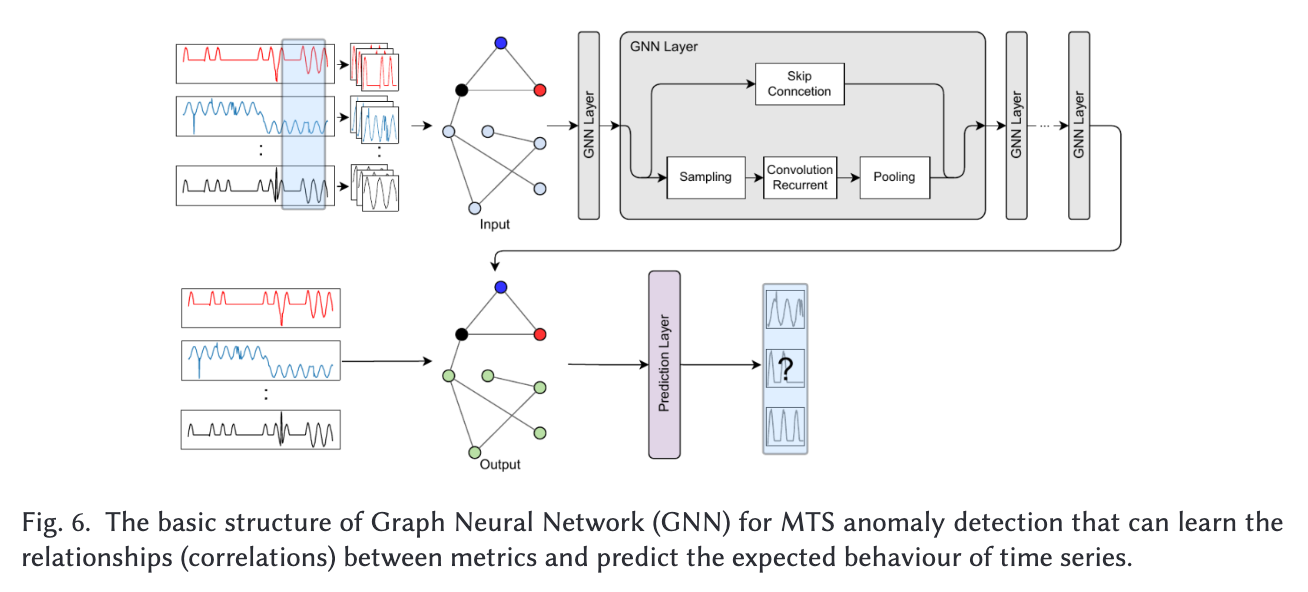
MTS에서, 그래프 노드는 각 차원이다. V = {1,...,d} 로 표현한다.
엣지 E는 각 차원간 상호관계를 나타낸다.
V에 속하는 각 노드 u가 메세지 통과 계층이 K+1만큼 반복하여 출력한다:
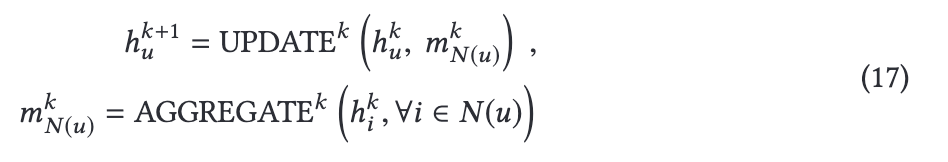
는 각 노드의 임베딩이다. N(u)는 node u의 이웃이다.
GNN은 구조적 설계를 학습함으로써 MTS 모델링을 강화한다.
여기서 말하는 구조적 설계란 노드와 엣지를 통해 그 구조를 학습한다는걸 말한다.
GDN이 그 예시중 하나다. GNN based attention 기법이다.
GDN에서는 센서 특성을 노드로, 그 노드들간의 관계를 엣지로 한다. 이웃 센서(노드)를 기반으로 행동을 예측하면서.
참고로 엣지 관계를 맺는것은 full connected가 아니라,
임베딩들간 유사도를 계산해서 각 노드와 가장 비슷한 Top-K 개의 노드만을 이웃으로 선택한다.
수식으로 표현하자면 각 노드와 다른 노드들간의 내적을 이용해서 표현하면 된다. 내적 큰 값 top-K개 선정.
3.3 Reconstruction-based Models
VAE 기반
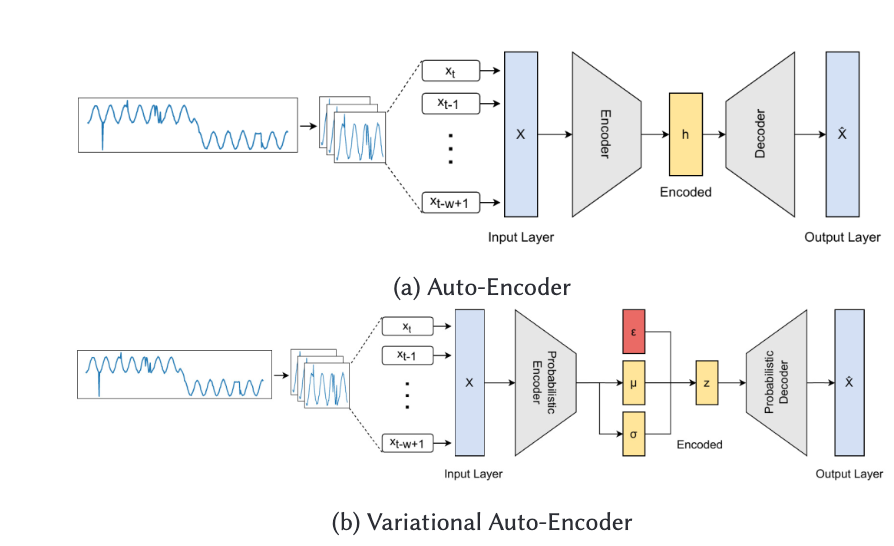
위 그림은 너무나도 잘 알고 있는 VAE 구조
OmniAnomaly
VAE와 stochastic RNN을 같이 쓴다.
뭘 위해서? 다변량 데이터, 비가우시안 잠재 공간 분포를 위한 평면 정규화 흐름의 강인한 표현을 위해서.
stochastic RNN을 VAE에게 얹은 형태인데,
RNN이 시간축을 대변해주니, 시계열 데이터도 탐지 가능한 VAE가 되겠다.
그리고 VAE의 가우시안을 비가우시안으로 변경하는 이유는
가우시안은 단조로워 복잡한 형태를 표현하기 어렵다. 그래서 이를 평면 정규화 흐름을 통해서 비가우시안 공간 분포로 만들어준다.
아래는, 평면 정규화 흐름을 통해 비가우시안으로 비트는 아이디어에 관한 수식

위에서 를 계속 곱하는건 설정한 flow 갯수만큼 진행된다.
그래서 f을 따를수록 점차 비가우시안 분포로 변경이 된다.
그리고 h는 단지 tahn 활성화 함수. (0~1로 제한)

각 변수는 위 shape을 갖는다.
그렇게해서 z'을 구하기 위한 식을 차근 차근 확인해보면,
z에서 는 주어진 벡터 z에서 중요하게 보는 차원(방향)이다. (내적이므로)
즉, z와 가 같은 방향을 바라본다면 (가 중요하게 보는 차원에 대한 z의 값이 크다면), z 값 역시 클 것이다.
* z이 계산된다면 행렬곱 원칙에 의해 단 하나의 스칼라 값이 나온다.
이 값에 tahn 활성화 함수인 h까지 거치면 (0~1의 값 갖음) 주어진 z값에 대한 "왜곡의 강도 스칼라"라고 한다. (스칼라 단 하나의 값이니깐)
그리고 이 방향의 크기에 u을 곱해주는데, 여기서 u는 가우시안 분포를 왜곡하기 위함이다.
예를들어 z + h()만 된다면, 그냥 가우시안에 스칼라 하나의 값만 더해지게 되기때문에 그 분포 그대로 위치만 변하는 느낌이 된다.
하지만 벡터 u를 곱하게 된다면?
값이 각 차원별로 다양하게 곱해지게 되면서 비로소 왜곡이 된다.
그래서 나는 u를 "왜곡 방향(차원) 벡터"라고 한다.
이를통해 가우시안 -> 비가우시안으로 표현이 가능하다.
굳이 이렇게까지 할거면 왜 VAE을 사용하나...?
VAE는 AI/ML에서 학습, 추론이 안정적이고 수학적으로 다루기 쉬운 틀로 입증되었고, 단지 거기서 제한만 살짝 풀어주기 위함이다.
TSAD에서 가우시안이 아닌 비가우시안으로 복잡성을 훈련, 표현해야하는 이유?
시점/환경에 따라 multi-modal하게 갈라지거나, 일부 차원이 두꺼운 꼬리(heavy tail)를 가지거나
이런 경우를 해결하기 위함.
위에서 말하는 멀티 모달하게 갈라진다거나 두꺼운 꼬리를 갖는다는 거는,
(정상 상태)
평일 낮 10시: 평균 1분에 1000건
평일 새벽 3시: 평균 1분에 100건
주말: 평일보다 전반적으로 더 낮아서 평균 1분에 300건
위와 같다고 할때, 정상 범위를, 평균 450, 표준편차 500 정도. 이렇게 하나로 뭉퉁그릴수 있음.
그럼 정상도 비정상이, 비정상도 정상이 되어버릴수 있어서,
각 시간/시점별로 예를들어 낮 10시엔 평균 1000, 편차 100, 새벽 3시엔 평균 100, 편차 10 정도로 정상 범위를 더 효율적으로 구분할수 있음.
Hierarchical Variational Autoencoder (HVAE)
아래 문장은 애초에 Hierarchical이라는 개념이 불균형 데이터셋 한계 해결로써 자주 쓰인다는 참조 논문.
Hierarchical Variational Autoencoder (HVAE) with two stochastic la-
tent variables for intermetric and temporal representations, along with a two-view embedding. To
prevent overfitting anomalies in training data, InterFusion employs prefiltering temporal anom-
alies. The paper also introduces MCMC imputation, MTS for anomaly interpretation, and IPS for
assessing results.
GAN 기반
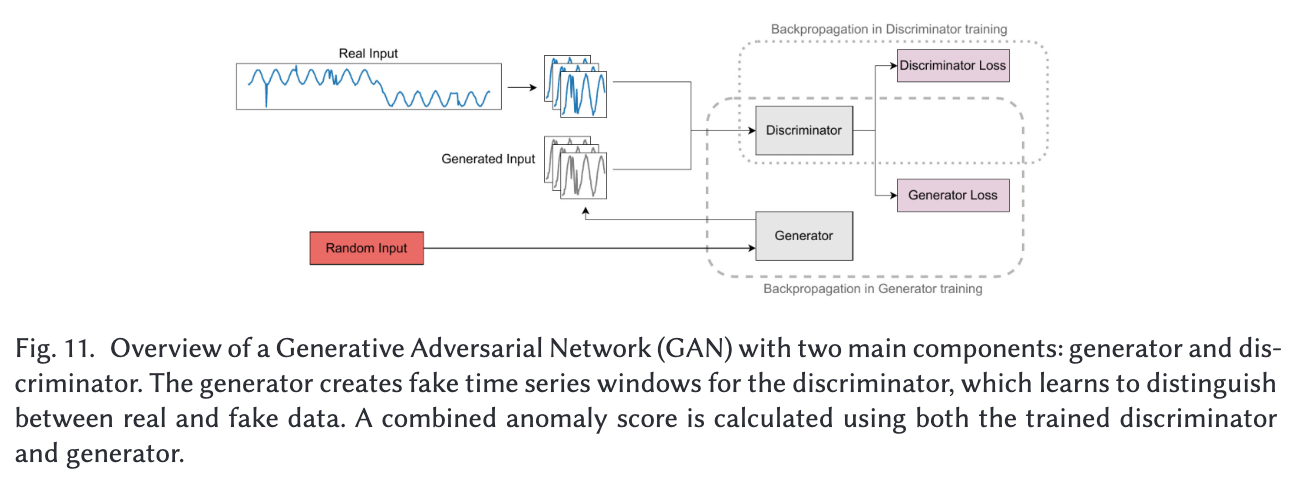
GAN 구조는 위와 같다.
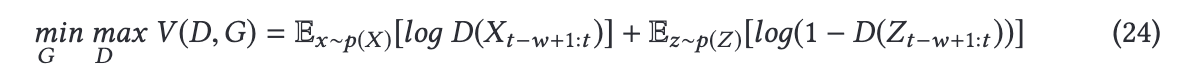
수식은 위와 같다.
p(z)는 사전 확률 분포, 는 랜덤 공간으로부터 주어진 생성된 입력 윈도우.
GAN은 일반적으로, adversarial learning이 판별자를 현재 데이터셋 외부 데이터에 대해 더 예민하게 만든다. 그러한 데이터들의 재구성(reconstruction)을 더욱 힘들게 만들면서.
GAN이야 항상 그렇듯, 생성된 적대적 샘플을 훈련해서 이상탐지 하는 것인데,
적대적 샘플과 거리가 멀다면 그걸 이상으로 탐지한다.
그래서 시계열 데이터셋 기반으로 적대적 샘플 통해 이상 탐지 수행한다.
BeatGAN은 재구성을 더 강인하게 정규화 한다. AE와 GAN을 함께 사용함으로써 (AE가 재구성 강인하게 해준듯).
그리고 BeatGAN은 시계열 데이터의 time warping (시간 왜곡) 기법을 사용하면서 탐지율을 높였다.
시간 왜곡 기법은 훈련 데이터셋에서 속도 증가를 한다. 훈련 속도를 줄인다는게 아니라 시계열에서 시간 속도 증강을 한다는거다. 예를들어, ECG(심장박동) 데이터셋에서 환자 상태에 따라 심장박동이 빠를수도 있다. 이럴때도 탐지율을 높이기 위해 속도 증가 시키고 시간 왜곡시킨단거다.
이러한 노력에도 불구하고 GAN은 생성자 판별자 사이의 조심스런 밸런스가 매우 중요하다.
이런 밸런스가 중요하기에 계속 데이터가 추가되는 online에서는 적합하지 않다.
DAEMON은 AAE(Adversarial Autoencoder) 계열이다.
encoder을 거친 잠재 공간에서 잠재 변수를 가져오고, 이 잠재 변수를 갖고 GAN으로 적대적 훈련 해주고, 디코딩 해주는 flow다.
그리고 이 기법은은 3가지 스텝으로 이루어진다.
첫번째로, 1차원 CNN을 통해 MTS을 인코딩한다.
그리고 잠재변수(잠재 백터에 적용된 사전 분포)를 직접적으로 디코딩 하지 않고, 적대적 전략이 사후 분포와 사전 분포를 정렬한다 (CNN에서 나온 사후 분포가 사전 분포를 따르게 하는듯).
이렇게 하면 처음보는 패턴의 재구성 부정확함을 완화할수 있다 (왜냐면 분포를 따르게 하는거라서 그렇다. 일반화 성능 up).
즉, 위에서 말한 새로운 data가 입력되는 Online에 대해서도 비교적 좋은 성능을 보일수 있다는 것이다.
마지막으로, 그렇게 생성된 시계열 사후 분포를 디코더가 재구성한다. 그렇게 해서 원본 데이터와 재구성된 데이터의 차이를 최소화 하는걸 목표로 한다.
Transformer 기반
Anomaly Transformer은 당연하게도 attention mechanism을 사용한다.
이 메커니즘을 통해 각 타임스탬프마다 동시에 사전 그리고 시리즈 연관성들을 모델링함으로써 자주 사용하지 않는 패턴을 발견한다. 이것은 드문 이상현상을 더 구분가능하게 만들어준다.
어떻게 그게 되는거냐면, 이상 샘플은 이 메커니즘에서 전체 시리즈와 연결되기가 더 힘들다. 반면에 정상 샘플은 연결 쉽게 된다.
prior associations는 가우시안 커널을 사용해서 근처 포인트들을 보고, series associations는 self-attention을 사용한다 (시리즈니까 어텐션?).
attention mechanism 이외에도 recon loss와 Minmax 기법(GAN)을 정상과 비정상을 구분하기 위해 사용한다. 즉, Anomaly Transformer은 attention + recon + MinMax Phase 통해 이상 탐지한다.
TranAD는 특히 큰 입력을 다룰때 효율적인 기법이며 (큰 입력에선 작은 이상이 있을텐데 그런 작은 이상을 큰 데이터셋에선 캐치하기가 힘든데 이거에 특화된 기법),
기존의 Transformer가 미세한 이상 탐지는 못한다면, TranAD는 그 부분에서 더 강인하다.
recon loss가 큰 것에 더 포커싱을 줘서 다시 self-attention에 입력하는 self-conditioning을 통해 이 문제를 해결한다.
3.4 Representation-based Models
CNN 기반
DCdetector은 CNN과 이중 attention을 사용한다. 이 기법은 정상과 비정산 패턴의 분리를 향상시키기 위한 contrastive learning을 통해 시간적, 공간적 차원에 집중한다.
긍정 쌍은 같은 타임시리즈의 다른 뷰로부터 표현으로 구성된다.
반면에, 부정 샘플은 사용하지 않고 anomalies을 구분하기 위해 이중 어텐션 구조에 의존한다. 정상과 비정상 샘플 사이에서 차별성 표현을 최대화 하면서.
다음 시간엔
다음 시간엔, 트랜스포머 기반 TSAD인 TranAD, Anomaly Transformer에 대해 알아보겠다.
