[논문 리뷰] Anomaly transformer: Time series anomaly detection with association discrepancy
1. Introduction
기존에 여러 방식의 시계열 데이터 이상 탐지 기법이 존재한다.
하지만 이러한 기법들은 명확한 한계가 존재한다.
그 명확한 한계는 real-world dataset은 정상 데이터가 매우 많으며 이상 데이터가 소수이기에, 정상 타임 포인트에 지배적이며 이때문에 이상 샘플과 정상 샘플 구분이 어렵다.
이상 탐지를 위해서 reconstruction이나 prediction 기반의 다양한 방법이 있지만, 시계열 정보·문맥을 학습하기엔 다소 무리가 있다.
그 이유는 한 데이터 샘플에 대해서만 재구성 및 예측하기 때문이며, 시계열 정보는 학습할수 없기 때문이다.
그 외에 그래프 방식도 있다.
그래프 방식은 명백하게 연관성을 캡처할수 있다.
그 연관성 캡처를 통해 시계열 데이터를 학습할수 있게 되며 잠재 공간 상에서 의미있게 표현할수 있다.
다변량 GNN을 통해서 시계열 이상탐지하는 논문이 있지만, 단독 시점만 학습할수 있는 한계가 있으며, 좀 더 복잡한 시계열 데이터 (문맥 등)을 파악하기엔 한계가 있다.
본 논문은 이를 해결하기 위해 Transformer을 도입한다.
주로 NLP (자연어 처리)에서 주로 사용되는 기법이다.
Transformer은 장기 기억에 유리하며, 그로 인해 시계열 데이터 분석에도 유리하다.
본 논문에서는 transformer을 시계열에 적용시켜서,
self-attention map으로 부터 각 시점의 시간적 연관성을 얻을수 있다.
self-attention map은 그 각 시점별 다른 시점에 대한 시간적 연관성에 대한 가중치를 나타낸다.
이러한 연관성을 series-association이라고 한다.
하지만 이러한 transformer라고 하더라도 class가 imbalanced한 상황에서는 정상 샘플에 편향되는 경향이 있기에 한계가 존재한다.
이를 해결하기 위해 본 논문에서는 관측한게 있다.
그 관측은, 시계열에서 이상 시점이 인접한 시점에 집중하는 경향이 있다는 것이다.
그래서 본 논문에서는 이러한 특성을 이용하며 '인접 집중 유도 편향' 즉, prior-association이라고 참조된다.
반대로,
정상 시점의 샘플은 전체 시리즈 series-association 에서 정보적인 연관성을 발견할수 있다.
위와같이 이상 시점에서 바라 본 특성과, 정상 시점에서 바라 본 특성을 통해 중요한 사실을 관찰했다.
이 관측을 통해 정상/이상 샘플의 구분을 시도한다.
즉, series-association와 prior-association을 통해서 정상/이상을 구분한다는 의미이다.
이를 Association Discrepancy라고 한다.
본 논문에서 제안하고자 하는 최종적인 기법인 Anomaly Transformer은,
Assoication Discrepancy을 계산하기 위해 self-attention 메커니즘에 기반한 Anomaly-Attention을 사용한다.
이는 two-branch로 이루어져 있으며, prior-association과 series_association으로 각각 이루어져있다.
여기서 prior-association은 각 시점의 '인접 집중 유도 편향'을 표현하기 위해 학습 가능한 Gaussian kernel을 도입한다.
가령, 이상 샘플에서는 가우시안 커널 스케일이 매우 좁아지고 정상 샘플에서는 스케일이 더 커진다.
series_association에서는 원본 시리즈로부터 학습된 self-attention 가중치와 일치한다.
그리고 minmax starategy를 제안하며, 이것은 두 브랜치 사이에 적용이되며, Association Discrepancy정상-비정상 구별성을 더욱 더 증폭시켜준다.
요약하자면,
1)
Association Discrepancy라는 핵심 관측에 기반해서, Anomaly Transformer을 제안한다(Anoamly Attention에 기반한). 이 기법은 Association Discrepancy을 구현하기위해 prior-association과 series-association을 동시에 모델링 할수 있다.
2)
minmax strategy을 제안하여 정상-이상 샘플 구별성을 증폭시킨다.
3)
이 기법은 3개의 실제 appication을 위한 6개의 벤치마크에서 좋은 결과를 관측했다.
2.Related Work
Density-estimation methods
Clustering-based methods
Reconstruction-based methods
Autoregression-based methods
Transformer-based methods
3.Method
시계열 X는 각 시점들을 표현하는 데이터가 들어가있다.
X = {,,...,}
각 요소는 시점 에서의 데이터를 뜻한다.
는 의 형태이다.
그리고 d는 특징 개수이다.
즉, 시계열 데이터 X에는 타임 시점 별 각 데이터가 들어가 있으며, 그 데이터는 d개의 특징을 갖는 구조.
여기서 말하는 특징이랑 cpu 사용량, 메모리 사용량, 현재 접속자수 등을 나타낸다.
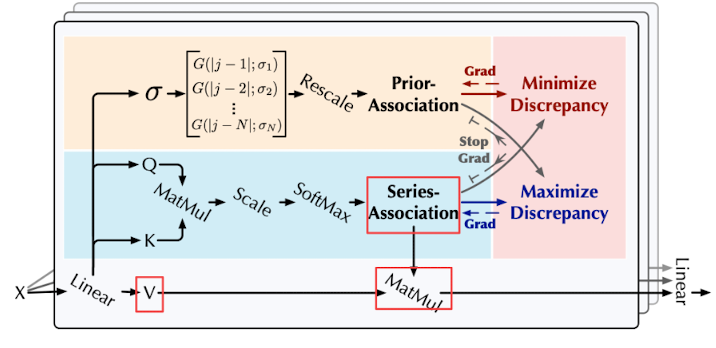
Anomaly Transformer
Overall Architecture
아래 그림이 재밌는게, 보통 MinMax Game을 하면 GAN처럼 두개의 디코더를 생각하지만, 이 아키텍처에선 같은 Anomaly Attetion Block 안에서 Min, Max을 번갈아가며 업데이트 하는 최적화 트릭을 사용 (중간에 grad 끄면서.).
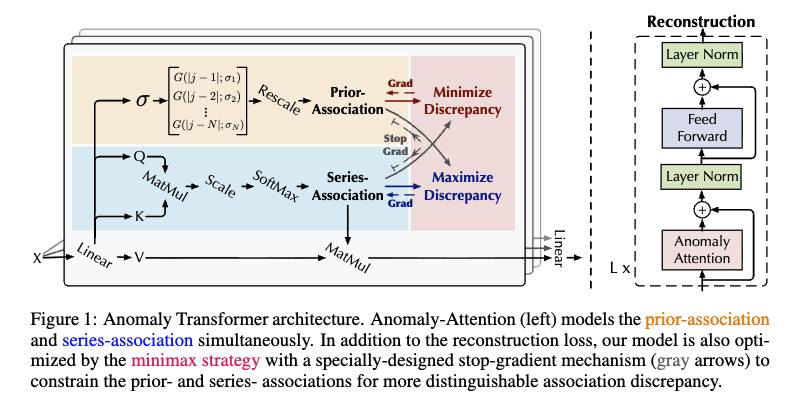
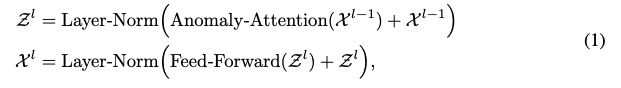
Anomaly Transformer 구조는, Anomaly-Attention Block들로 이루어져 있다.
그리고 [Anomaly Attention, Layer Norm, Feed Forward, Layer Norm]을 하나의 레이어 세트로 보며 이 세트가 L개로 이루어져 있다.
그래서 원 시계열 데이터 X로부터 각 레이어별 출력은 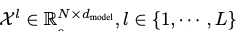
이 된다. 여기서 은 각 레이어별 채널 수.
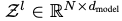
여기서 은 l번째 레이어의 잠재 표현이다.
은 아래 그림과 같이 표현 된다.
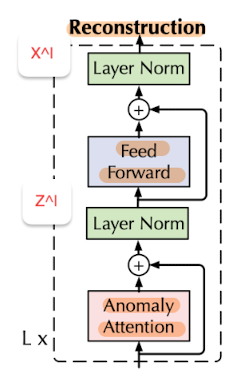
위 구조 보다시피 2개의 브랜치 구조로 이루어져있다.
prior-association(P) 브랜치에선 학습 가능한 가우시안 커널을 채택하며, series-association(S) 브랜치에서는 각 시점에서 다른 시점의 시간적 연관성을 보기 위해 채택한다.
P에선 학습 가능한 가우시안 커널로 인해 이상 샘플에 대해 인접 노드에 더 집중할수 있다.
특히, P에선 가우시안 커널을 스케일링하는 파라미터가 있다. 이걸 조절해 이상 샘플에서는 확률 분포가 인접하게 유도한다.
S에선 시계열 데이터의 표현을 학습할수 있다.
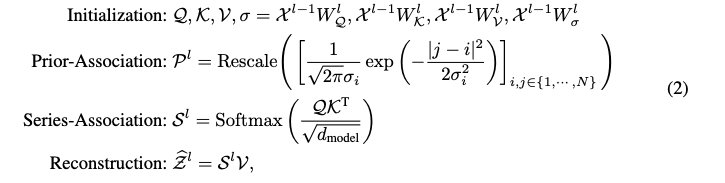
위는 P와 S를 학습하고, 최종적으로 재구성하는 형식에 관련된 수식이다.
Initialization에선,
Transformer에서 전통적으로 사용하는 Q,K,V가 있고, 까지 있다.
이를통해 각 레이어별 가중치 을 통해 학습될수 있도록 초기화 해준 부분이다.
Prior-Association (P)에선, 우선 가우시안 커널 스케일링 값인 에 대해 알아야한다.
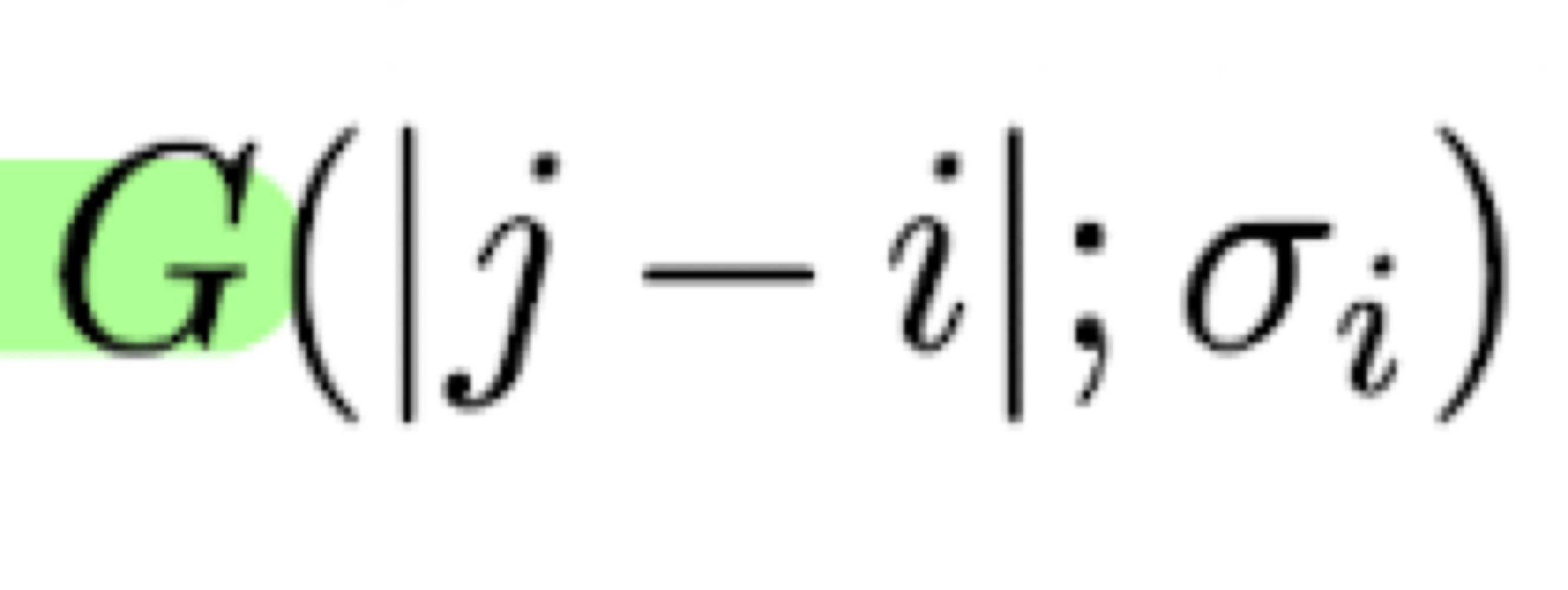
i번째 시점과 j번째 시점 사이의 시간 거리 (time distance), 즉 바로 옆 포인트면 1, 옆옆이면 2
σ_i는 i번째 시점의 가우시안 커널 폭 (scale) learnable 파라미터
σ의 값이 크면 인접 노드를 폭넓게 보고, σ이 작으면 인접 노드의 폭을 좁게 본다.
G의 ; 앞은 입력 데이터이며, 뒤는 파라미터이다.
그리고, 가우시안 커널 수식에 대해서 알아보자.
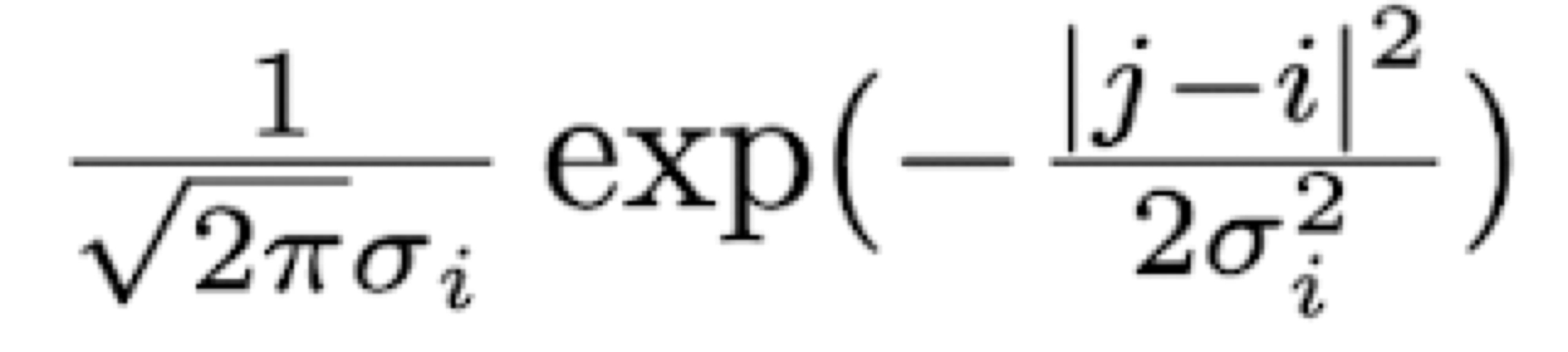
exp(x)는 e^x을 말하며, 여기서 e는 2.71828 자연 상수이다.
i와 j의 거리가 커질수록 가우시안 커널의 값이 작아진다.
시그마가 커질수록 가우시안 커널의 값이 커진다.
즉, 시그마(최적의 시그마로 학습된)에 의해 가우시안 커널의 스케일이 정해지며,
i와 j의 거리가 크다면 가우시안 커널 분포 값이 작을테고, i와 j의 거리가 작다면 가우시안 커널 분포 값이 클테다.
이 G를 이용해서 minimize phase에 사용한다.
minimize phase에는 S에 detach(gradient 제거)해서 P가 S를 최대한 따르도록 업데이트하고, (이게 G 관점이지.)
maximize phase에는 P에 detach해서 S-P가 커져 Association Discrepancy를 크도록 업데이트한다.
Rescale은
이를 통해 이 분포 값을 다 더하면 1이 된다특정 i가 모든 j에 대해 보는 가중치를 다 더한걸 row sum이라고 하며, 이를 나눠줘서 이산 확률 분포로 만든다.
이를 통해 이 분포 값을 다 더하면 1이 된다.
참고로 스케일 없는 순수한 가우시안 커널의 모형 P는 S의 이상 샘플보단 정상 샘플에 가깝다.
아래서 구체적인 예제가 나오겠지만 미리 말하자면
이상 샘플의 S는 현재 시점 및 인접시점에 급격한 큰 가중치가 있다면, 정상 샘플 S는 완만한 가중치로 구성되어있기 때문이다.
Series-Association (S)에선, 아래와 같은 수식이 사용된다.
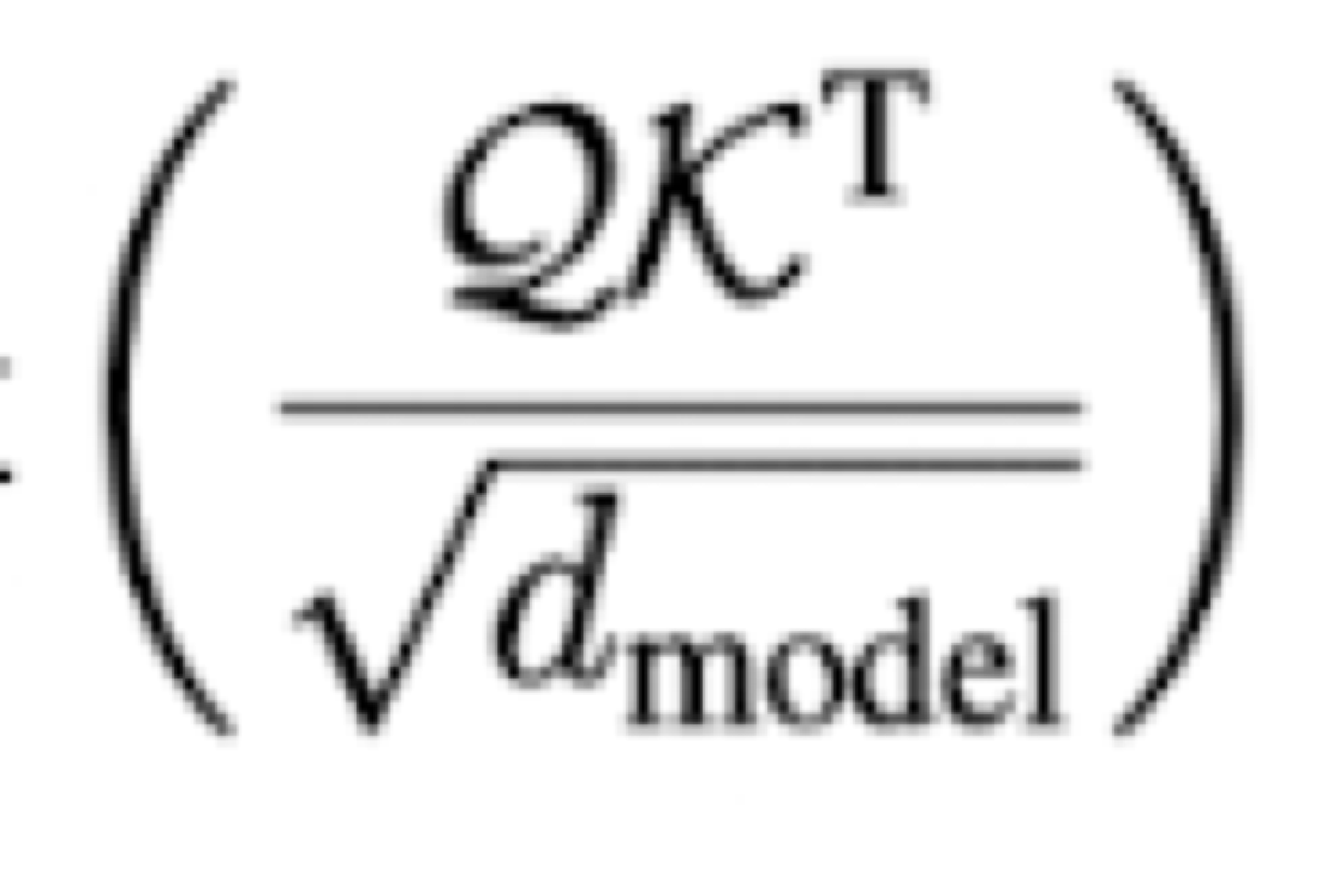
S는 위 수식에 의해서,
Q * K^T에서 보듯이 내적을 한다.
Q와 K가 얼마나 같은 방향을 바라보는지 얼마나 같은 성향을 갖는지를 판단한다고 보면 된다.
Q: 현재 시점이 어느 다른 시점들을 참고할지 결정할 때 쓰는 기준 벡터.
K: 각 시점이 현재 시점을 얼마나 참고할지 벡터.
V: 각 시점이 현재 시점을 참고하기로 했을 때 실제로 가져오는 정보가 담긴 벡터.
Reconstruction에선,
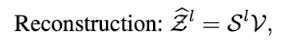
위와 같이 S와 V의 곱을 통해 이루어지며 아래 구조와 같다.
Association Discrepancy
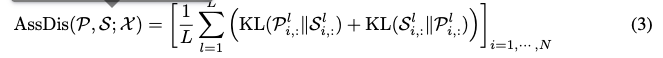
KL Divergence을 통해 P와 S 분포가 얼마나 다른지를 측정한다.
참고로 AssDis(·)인 P-S 차이가 크면 정상 샘플이고
P-S 차이가 작으면 이상 샘플이다.
KL(P∥S)+KL(S∥P) 을 왜 같이 쓰는지에 대하여
P=[0.9,0.1], S=[0.6,0.4]
이때 단순히 둘의 값 차이만 구한다면 중복이다.
하지만 KL은 단순 거리차이가 아니라 “P가 중요하게 여기는 구간을 S가 얼마나 틀리게 보고 있느냐”를 보게 된다.
즉, “P가 ‘중요하다’고 생각하는 부분일수록, S가 거기서 틀리면 더 크게 패널티를 주는 비대칭 평균 로그 오차”
ex)
- P가 어떤 구간에 0.9(거의 항상)라고 말하는데, S는 거기 0.6만 준다 → “진짜로는 거의 항상 일어나는 일인데, 근사 모델은 ‘그냥 좀 자주 일어나는 정도’라고 본다” → 큰 손해.
- 반대로 P가 0.1(가끔)라고 말하는 구간에서, S가 0.4(꽤 자주)라고 본다 →
“별로 안 중요한 구간을 모델이 중요하다고 착각하는 것”이라, 앞보다 상대적으로 덜 치명적.
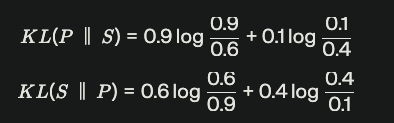
수식으로 보면 위와 같음
그래서 KL(P∥S)와 KL(S∥P)을 동시에 연산해주어
P에서 바라볼때와 S에서의 바라볼때의 KL Divergence 오차를 구해준다.
P와 S에 대한 예시 집고 넘어가기
-
트랜스포머 기본 메커니즘
S를 알아보기 전에 트랜스포머 메커니즘부터 알아야하는데
인코더(self-attention, Q와 K의 내적 정보 등) 디코더(reconstruction loss)로 이루어져 있으며
인코더에 입력으로 "I live near the rivier bank."가 들어가면 디코더에서 "나는 강둑 근처에 삽니다."로 번역하기 위해 학습 목표가 이루어진다.
이건 지도 학습에서의 이야기고, 본 논문에서는 지도 학습은 아니라서 "나는 강둑 근처에 삽니다."와 같은 정답이 주어지진 않는다. -
본 논문의 Series-association의 셀프 어텐션과, 일반적인 트랜스포머 셀프 어텐션과의 차이
결국은 S는 각 시점에서 바라본 다른 시점의 이산 확률 분포이다.
본 논문에서는 비지도 학습으로 이루어지며,
S에서의 셀프 어텐션은 재구성을 잘하기 위해 현재 시점에서 각 시점에 주어야할 가중치(확률 분포)를 정한다.이를테면 LLM에서 "I live near the rivier bank"는 bank 시점에서 봤을때 내가 은행이 아니라 둑이라고 해석 될수 있도록 제일 잘 정의해줄수 있는 river에 높은 가중치를 부여한다.
LLM과 본 논문의 차이가 있다면 비지도 학습이란것. 그래서 위 예제에서는 bank가 둑(라벨)으로 해석되도록 recon loss가 훈련되는 반면그에 반해 본 논문에선 단순히 S 관점에선, t_8 시점이 잘 재구성 되기 위해 self-attention이 그 관계를 파악하는것이 목표이며, 라벨(여기서는 이상/정상 라벨)이 없음을 명심해주자.
즉, 훈련할때 이상인지 정상인지 모르는 상태에서 훈련한다는 것이다.
-
Series-association 예제
-
정상 패턴
그렇다면 CPU 사용률을 예로 들면 어떻게 S의 확률 분포가 구성 될까?
(아래 그림에서 P는 스케일 파라미터 시그마 없이 진행된 가우시안 커널로만 진행된 테이블)
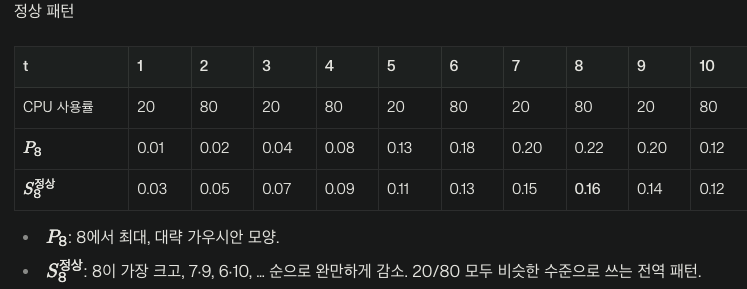
정상 패턴에서는 위와 같다.
여기서 S_8은 현재 시점을 잘 재구성 하기 위해 주로 두가지를 본다.첫번째로 전역적인 패턴이다.
보통 20 다음에 80으로 가기에 그 전역적인 패턴을 파악하기 위해서 모든 시점에서 S의 값이 골고루 분산되어있다.두번째로 국소적인 패턴이다.
아무래도 t=8이 80이 되기 위해서는 가장 이전의 시점인 t=7에서 무슨 값이였는지가 중요하다.
예를들어 t=7이 현재와 같이 20이라면 +60인 80이 될것이고, 10이라면 +60인 70이 될수도 있다.
그래서 인접할수록 좀 더 큰 가중치를 갖고 있다. (하지만 S_이상패턴 만큼의 인접노드에 큰 가중치를 주진 않는다. ) -
이상 패턴
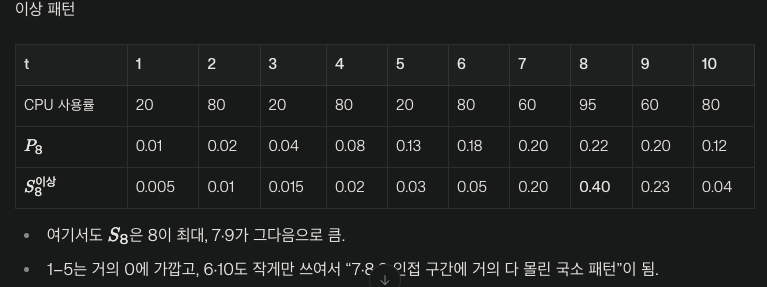
P부터 이야기하면 당연히 이상이든 정상이든 같다.S에서, t=7,8,9을 중점으로 보자.
8에서 가장 크고, 그 다음으로 인접 노드인 7,9가 상당히 크다.
정상 패턴에서는 인접 노드에서 S는 조금 컸다면, 이상패턴에선 상당히 크다.그 이유는, 원래는 전역적으로 퍼져야할 S의 가중치가 국소적인것에만 뭉쳐있는 이유는,
본 예제에서는 전역적인 패턴을 중점으로 보지 않게 훈련된다.다시 말하자면,
S는 트랜스포머 셀프 어텐션으로 현재 시점에서 각 시점과의 관계를 파악하고,
그 관계는 reconstruction 잘되도록 하는 관계이다.정상 패턴에서는 20->80이라는 패턴을 학습해서 이전이 20이니깐, 현재가 80으로 잘 재구성 될수 있도록 가중치를 전역적으로 부여했다.
하지만, 이상 패턴에서는 현재가 95이다 보니 전역적인 패턴인 20->80을 파악해봤자 95를 재구성하긴 힘들다.그래서 어텐션이 재구성 하기 위해 전역적인 패턴을 학습하진 않고,
"국소적인 인접 시점에서 비이상적으로 홀수 시점인데도 불구하고 상당히 큰 값이였다. 그러니 짝수 시점인 현재 시점에선 이것보다 더 커야한다."
라는 정보에 큰 가중치를 주어서 재구성 하도록 학습한다.
-
MinMax Association Learning
본 논문에서는 아래와 같이 AssDis에 도 같이 사용하며 이는 recon loss이다.
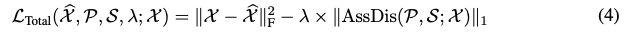
여기서 recon loss에 대한 수식이 있기때문에 셀프 어텐션이 (AssDis 함수 내에 있음) 현재 시점에서 다른 시점과의 관계를 정의할때 현재 시점이 재구성 되기 잘 되게 하기 위한 가중치를 부여한다.
Minmax Strategy
이상-정상 탐지를 더 쉽게하기 위해,
association discrepancy (P-S)를 직접적으로 maximizing하게 되면 극도로 가 감소한다.
그 이유는, P-S의 차이를 크게 만들기 위해서 P를 최대한으로만 인접하게 만들어 버리기 때문.
이로써 prior-association의 파라미터 을 의미 없게 만든다.
이를 해결하기 위해 MinMax Strategy를 사용.
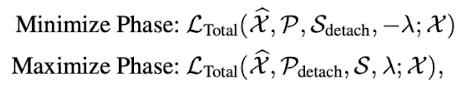
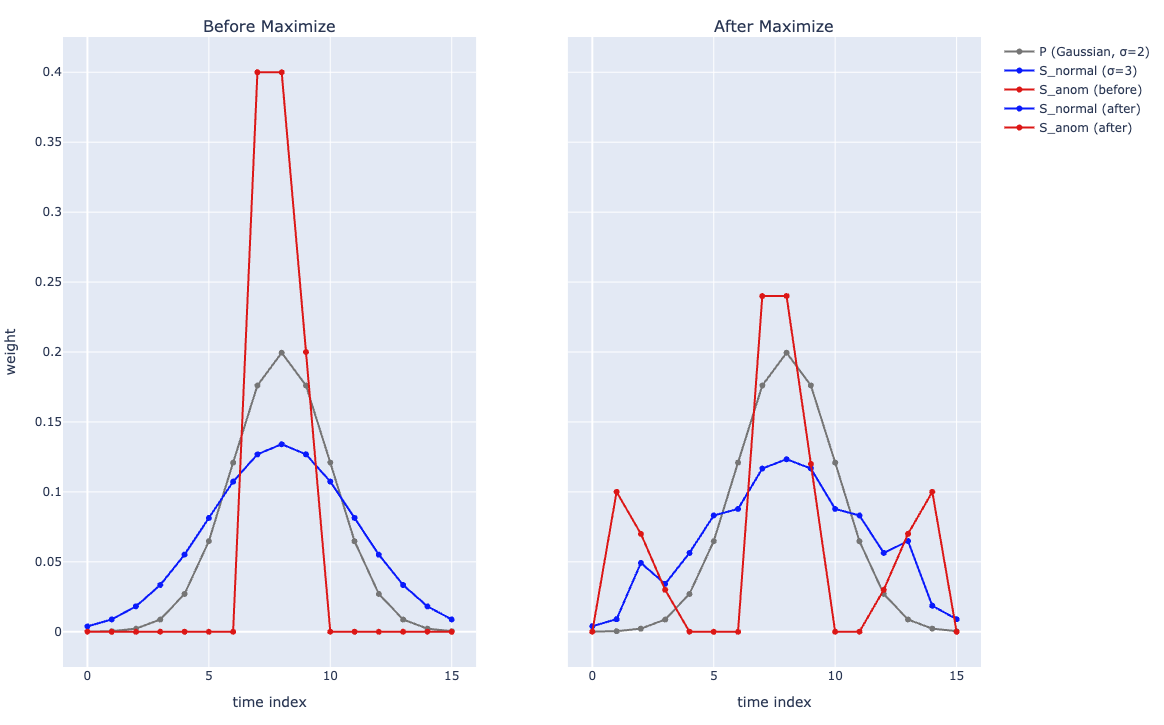
Maximize phase에서는,
S가 고정된 P와 다른 형태를 갖도록 한다.
그렇게 해서 Maximize phase에선 AssDis를 키운다.
정상 S와 이상 S 중에서 S_normal이 S_anom보다 가우시안 커널 P와 더 비슷한 형태라는 점을 먼저 떠올릴 수 있다. KL의 성질상 P가 큰 가중치를 갖는 곳에서 S도 크면 discrepancy가 상대적으로 작고, P가 거의 보지 않는(가중치가 작은) 시점에서 S가 크게 올라갈수록 AssDis가 더 크게 증가하는 경향이 있다.
정상 패턴 S_normal은 다수 샘플에서 반복적으로 관측되고, 서로 유사한 패턴을 공유한다. 그 결과, 모델은 정상 구간을 재구성하는 “정답 패턴”을 꽤 안정적으로 학습하고 있으며, 이때의 S_normal은 이미 P와 상당히 비슷하면서도 어느 정도 비인접 시점도 참고하는 경향이 있다. 이런 상태에서 S_normal을 P와 다르게 만들려고 비인접 노드 쪽으로 더 세게 밀어내면, 잘 맞던 재구성 패턴이 깨지면서 reconstruction loss가 민감하게 증가해 과도한 변화를 강하게 제약한다. 그래서 maximize를 거친 뒤에도 S_normal은 S_anom에 비해 변화폭이 상대적으로 작고, P와 어느 정도 비슷한 형태를 유지하는 쪽에 머무르기 쉽다.
반대로 이상 패턴 S_anom은 샘플 수가 적고, 각 이상 구간이 서로 다른 형태(짧은 스파이크, 장시간 레벨 상승, 진동 증가 등)를 가지는 경우가 많아 패턴이 제각각이다. 이 때문에 이상 구간에서는 “이렇게 보면 항상 잘 복원된다”는 공통된 재구성 규칙을 잡기 어렵고, 애초에 reconstruction이 정상만큼 잘 맞춰진 구조가 아니다. 이런 상태에서 S_anom을 P와 다르게 만들기 위해 비인접 시점으로 일부 가중치를 옮기면, 인접 가중치를 완전히 날려 버리는 극단적 변화가 아닌 한, 정상 구간만큼 recon loss가 예민하게 튀지 않을 수 있어 상대적으로 제약이 덜 강하게 걸릴 수 있다. 또한 S_anom은 초기에는 비인접 시점의 가중치가 매우 작게 시작하는 경우가 많기 때문에, maximize의 압박을 받으면 그 비인접 쪽 가중치가 이전보다 눈에 띄게 커지는 경향이 생기고, 이는 P가 거의 보지 않는 영역에서 S가 커지는 방향이라 AssDis를 크게 키우는 데 기여한다(KL의 특성).
한가지 주의할 점은 S_anom이 P을 따라가려하면 S_anom의 recon에서는 인접 노드를 강하게 볼테고 인접 노드 가중치의 일정 부분이 비인접 노드의 가중치로 가버리게 된다면 recon이 강하게 제약을 걸며 비인접 노드를 못보게 만드는게 아닌가? 라는 의문이 있을수도 있다.
하지만 실상은 그렇지 않다. 아래 예제를 보다시피 극단적으로 S_anom의 인접 부분의 가중치를 감소시키지 않으며, 비인접 노드를 보도록 구성된다.
정상 샘플 같은 경우는,
P의 가우시안 커널이 애초에 정상의 S와 매우 비슷하다. 그리고 완만하다.
그래서 S가 P가 중요하지 않게 보는 시점을 중요하게 보기 위해선 생각보다 많은 값이 변하지 않는다.
반면에 이상 샘플 같은 경우는,
P의 가우시안 커널이 이상의 S와 매우 다르다. 그리고 이상의 S가 매우 가파르다.
그래서 S가 P가 중요하지 않게 보는 시점을 중요하게 보게 하기 위해선 많은 값이 변하게 된다.
KL Divergentce (위에서 자세한 수식 설명)에 의해서
P가 중요하게 본 곳을 S가 더 중요하게 보는 그런것보단,
P가 중요하지 않게 본 곳을 S가 더 중요하게 본 그런 관계에서 더 큰 AssDis을 유발한다.
그런 면에서 위 그래프에서 After Maximize 그래프를 보면 이상 샘플인 S_anom (after)에서는 P에서 중요하게 생각하지 않은 0~2 시점에 정상 샘플에 비해 훨씬 더 큰 가중치를 갖고있다.
이때문에 AssDis가 최대화 단계에서 정상 샘플이 10만큼 커질때,
이상 샘플은 50만큼 커진다는 것이다.
이로 인해 정상-이상 샘플 구별이 더 쉬워질 것이다.
Minimize phase에서는,
P가 S에 가까워지도록 유도. (S는 detach)
즉, prior-association (P)의 스케일을 학습해 다양한 시간적 패턴에 적응하도록 유도.
이 minimize 작업을 안해주게 된다면,
P는 초기 설정대로 가우시안 커널의 prior로 남아서, 다양한 시간 패턴에 적응하지 못할 가능성이 크다.
P가 S에 가까워지도록 유도하기 위해서 S정상에서는 P의 가 커지면서 인접하지 않는 시점에 대해서도 그 특징을 학습하도록 유도하며,
S이상에서는 더 인접한 시점에 대해 그 특징을 학습하도록 유도한다.
예시로,
정상 샘플이 들어오면
S는 전역적으로도 고르게 가중치가 분포되어있을 것이다. (S_이상에 비해서)
이때 P는 그 S와 비슷해지기 위해 스케일이 커져 P의 분포도 고르게 퍼지도록 된다.
이 과정을 통해서 AssDis는 정상샘플에 관해서 더 작아지게 될것이다.
AssDis 값이 작아야 정상 샘플임을 생각하자.
반대로,
이상 샘플이 들어오면
S는 인접한 곳 위주로 가중치가 크게 분포되어 있을 것이다.
그렇기에 P는 인접 노드에 가중치를 주도록 학습된다.
근데 P가 인접 노드에 가중치를 줘서 S_이상과 비슷해지게 된다면
AssDis가 더 커질수 있는게 덜 커져서 이상 샘플 분류에 방해가 될것같다.
AssDis 값이 커져야 이상 샘플임을 생각하자.
실상은 그렇지 않다.
여기서 반드시 생각해야할게 90% 이상의 샘플이 정상 샘플이라는 점이다.
그래서 P는 이 최소화 단계를 통해서 정상 샘플 위주에 맞도록 설정된 값으로 학습 될 것이다.
또한 정상 샘플은 이상 샘플에 비해 그 패턴이 일정해서 P가 S의 그 패턴을 학습하기에 유리하다.
또 하나 의문점은,
'P가 정상 샘플에서는 비인접 노드에 가중치를 더 주고, 이상 샘플에서는 인접 노드에 가중치를 더 주도록 훈련 되지 않나?'라는 의문이 있을수 있겠지만, 그렇지 않다.
지도 학습이라면 BCE처럼 y(라벨)값에 따라 손실함수를 다르게 줄수 있다.
하지만 본 논문은 비지도 학습이며, y값에 따라 변치 않는 단 하나의 손실함수이다.
그리고, 로스함수에서 각 샘플수에 비례해서 sum을 한다.
그렇기에 아무리 이상 샘플에서 minimize 값이 더 크다고 할지라도 (이상에선 3만큼 크고, 정상에선 1만큼 크다고 가정)
그 개수가 9:1이기에 단순 계산으로 보면 정상 1x9, 이상 3x1이기에 정상 쪽에 더 가깝도록 되어있다.
이러한 이유들때문에,
Minimize에서 이상 샘플에 대해선 AssDis 차이가 작아져 분류에 불리해지는게 아닌가에 대한 의문은 해결됐다.
참고로, minimize의 P는 recon의 영향을 안받음에 유의하자.
실제로 그림 1에서도 S에만 Recon을 물린걸 볼수 있다.
MiMax Phase 결론
이를통해,
MinMax Phase의
Maxmize phase에선, recon의 제약과 KL Divergence의 특성으로 인해,
S정상 측면에선 AssDis (P-S)가 조금 커지고,
S이상 측면에선 AssDis (P-S)가 크게 커진다.
Minimize phase에선,
P가 S이상에는 작게 가까워지고, S정상에 크게 가까워져,
S정상 측면에선 AssDis (P-S)가 크게 작아지고,
S이상 측면에선 AssDis (P-S)가 조금 작아진다 (때론 조금 커질수도).
이로 인해 정상, 이상 샘플에서의 AssDis 격차는 훨씬 커진다.
Association-based Anomaly Criterion
최종적으로 이상인지 정상 샘플인지 비교하는 Score는 아래와 같은 수식으로 계산.
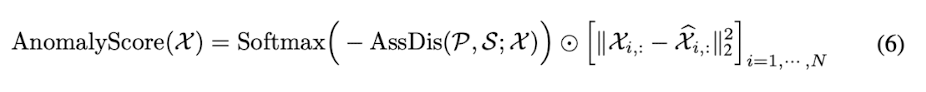
Experiments
Dataset
SMD (Server Machine Dataset), 5-week-long-dataset, large Internet Company, 38D
PSM (Pooled Server Metrics), eBay server nodes, 26D
Both MSL
SMAP
SWaT, 51개의 센서로부터 수집된 수자원 정보
NeurIPS-TS, 행동 기반 5가지 형태의 이상 시나리오, (point-global, pattern-contextual, pattern-shapelet, pattern-seasonal, patter-trend)
Implementation details
슬라이딩 윈도우로 긴 시계열 데이터를 100개씩으로 나누어 서브 시리즈로 구성. 즉, (샘플 1 = t=1~100), (샘플 2 = t=101~200)
AnomalyScore의 임계치 설정한 방법
Layer 개수 3개
h = 8
batch size = 32
gpu = NVIDIA TITAN RTX 24GB GPU
Baselines
18개의 baselines

4.1 MAIN RESULTS
Real-world datasets
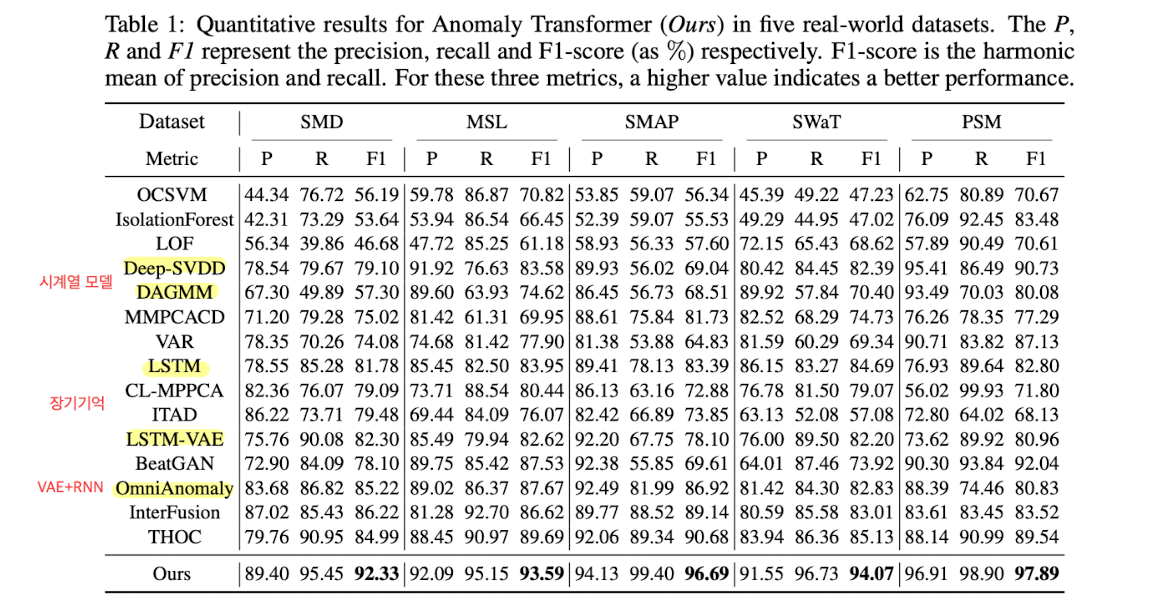
본 논문에서 제시하는 모델이 모든 데이터셋, 모든 기법에 비해 더 높은 F1 score 제시.
5개의 실세계 데이터셋과 10개의 경쟁적인 baselines와 비교.
Deep-SVDD, DAGMM은 시계열 데이터에 잘 적응하기 위한 모델.
LSTM, LSTM-VAE, OmniAnomaly는 장기기억 기반 모델
NeurIPS-TS benchmark
가장 시계열 데이터 분석 하기에 좋게 다듬어진 데이터셋.
point wise, pattern-wise 이상 탐지 가능하도록 데이터셋 제공.
Ablation Study
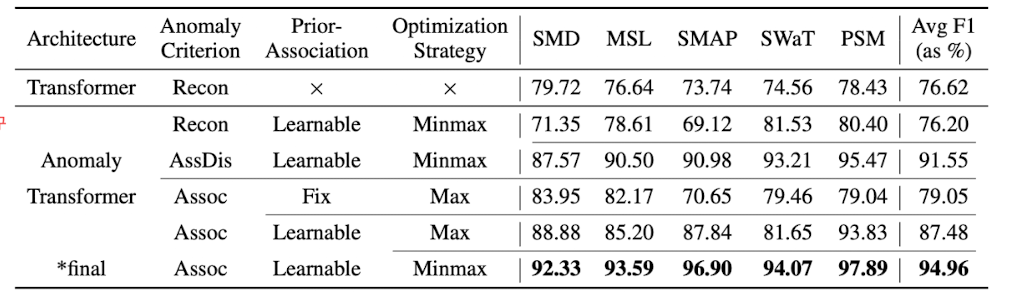
다른 Method가 아닌 본인 Method에 대해서만 구조를 바꾸거나 없애며 절제 연구.
Anomaly을 판별하기 위한 수식: (Recon, AssDis, Assoc)
Prior-Association: (X, Learnable, Fix)
Optimization: (X, MinMax, Max)
Anomaly Criterion = Assoc
Prior-Association = Learnable
Optimization Strategy = MinMax
일때 가장 좋은 성능
Model Analysis
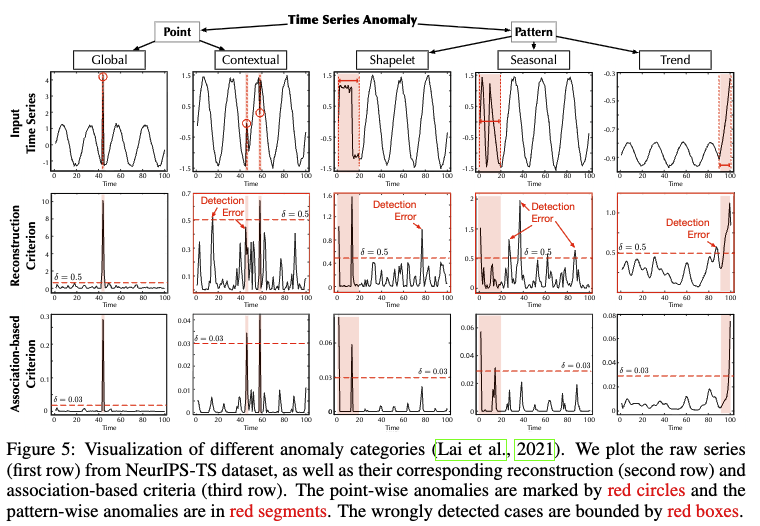
뉴립스-TS의 첫번째 샘플에 대한 실험. (되게 국소적으로 잡음...)
Recon Criterion으로 하게 된다면, Global에선 잘 판별하지만 그 외에서 모두 정상 샘플에 대해서도 임계치 이상의 값이 나옴.
반면 Association-based Criterion에선 잘 구별함.
Anomaly Criterion Visualization
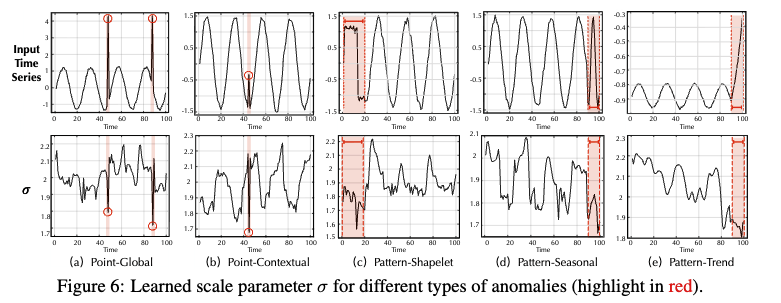
이상 시점에는 모두 가 매우 적은 스케일링 값을 갖고, 이렇게 된다면 P에서 인접 노드에 집중할수 있게 된다는 뜻. 즉, 스케일링은 잘 되고 있다.
Optimization Strategy Analysis
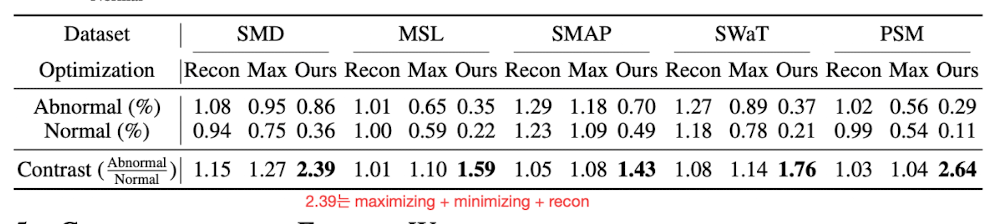
Max가 아닌 MinMax Strategy를 써야하는 이유이다.
5. Conclustion

끝.
