[논문 리뷰] DCdetector: Dual Attention Contrastive Representation Learning for Time Series Anomaly Detection

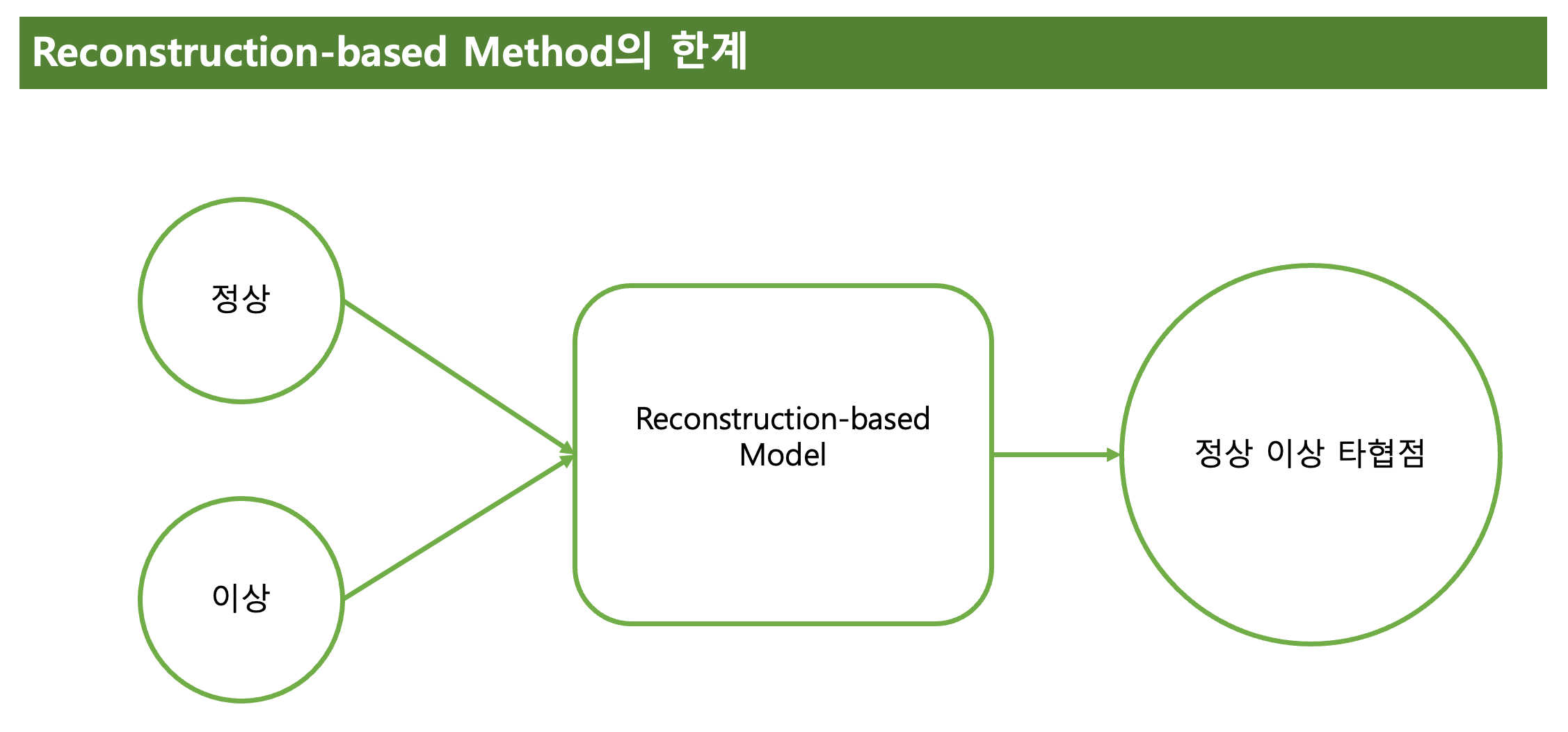
본 논문에서 제안하는 DCdetector은, 기존에 Recon-based Model로 정상, 이상 탐지하는 한계를 해결하고자 한다.
Recon-based Model에 한계가 있는 이유는
비지도 학습에서 정상, 이상 샘플 모두 입력하여 재생성 하게 되는데 이때 재생성되는 샘플은 정상-이상 샘플의 타협점이 된다.
그렇기에 정상-이상을 분류하는데 이도 저도 아닌 샘플처럼 보일수 있기에 한계가 있다고 한다.
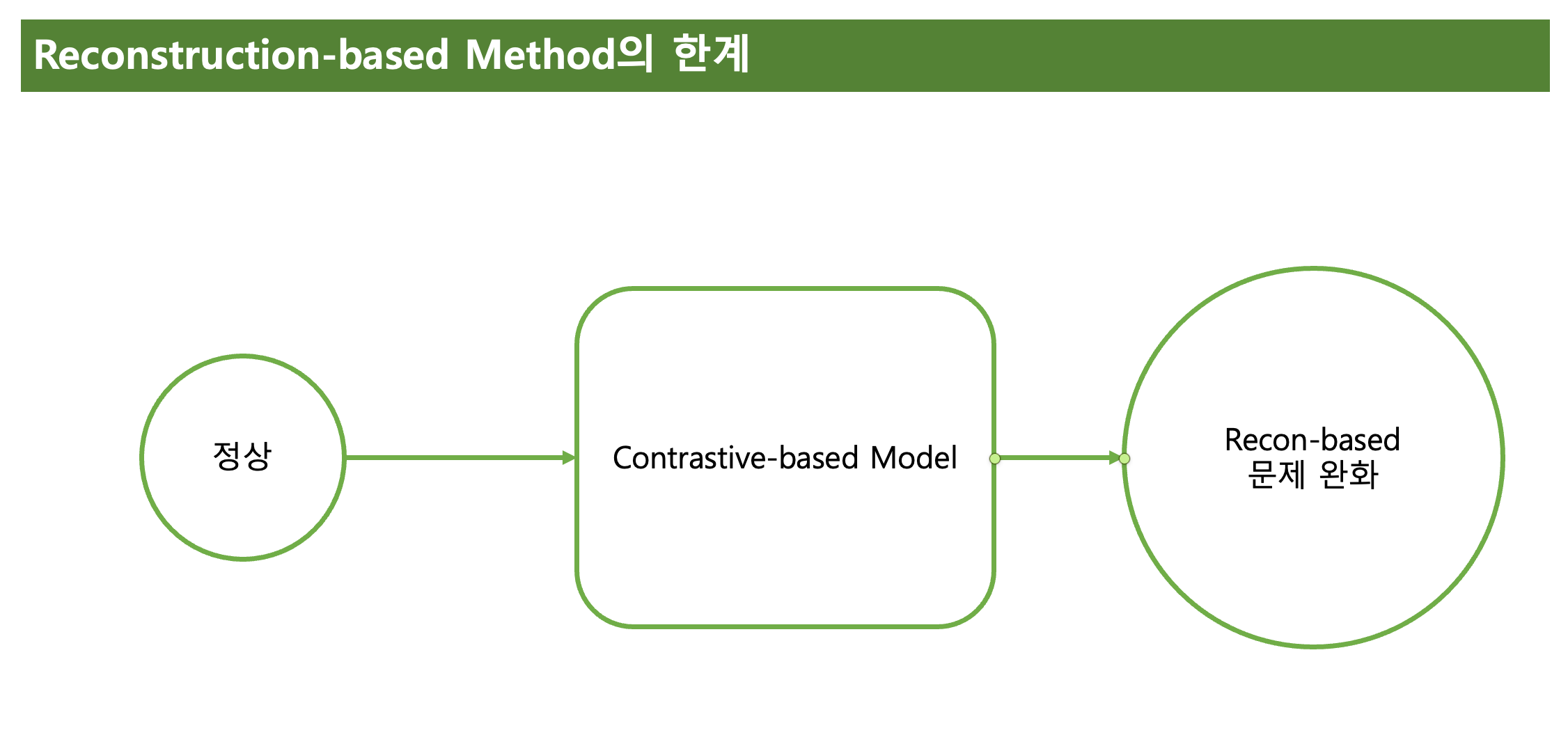
그래서 본 논문은 위와 같이 정상 샘플로만 입력된 Contrastive-based Model을 통해 해당 문제를 완화한다.
여기서 말하는 Contrastive-based Model은 Triplet Loss같은 Contrastive Learning이 아니다. 단순히 정상 샘플로만 훈련되는 KL을 통해 정상 샘플에선 두 분포를 비슷하게 해주고, 이상샘플에 대해선 Contrastive하게 벌려주는 것이다.
정상 샘플만 입력되었기에 Contrastive-based Model은 이상 샘플에 대해선 큰 에러값을 보일 것이다.
여기서 의문, 그럼 Recon-based Model에도 그냥 정상 샘플만 입력하면 됐던거 아니냐?
이론적으로 설명하긴 힘들지만, 실험적 사실로 증명되었다.
인용 논문: "Learning Not to Reconstruct Anomalies" (2021): 정상만 학습한 AE도 이상 잘 재구성 → 전용 방법 제안
본 논문 실험: AnomalyTrans (recon + KL): MSL F1=93.93
DCdetector (pure contrastive): F1=96.60 +2.67pt ↑
AnomalyTrans도 "정상 데이터 + reconstruction"인데 DCdetector보다 낮음 → recon 자체 한계 증명
위와 같은 이유로 인해 recon보단 contrastive-based model을 통해 이상 탐지를 수행하기로 한다.

본 논문의 Contribution은
Architecture
- Contrastive learning based dual-branch attention structure
- Enlarges the representation differences between normal and anomalies.
- Channel-Independence patching
- Multi-scale Design
Optimization
- Contrastive Loss without Recon Loss
Performance & Justification
- sota performance
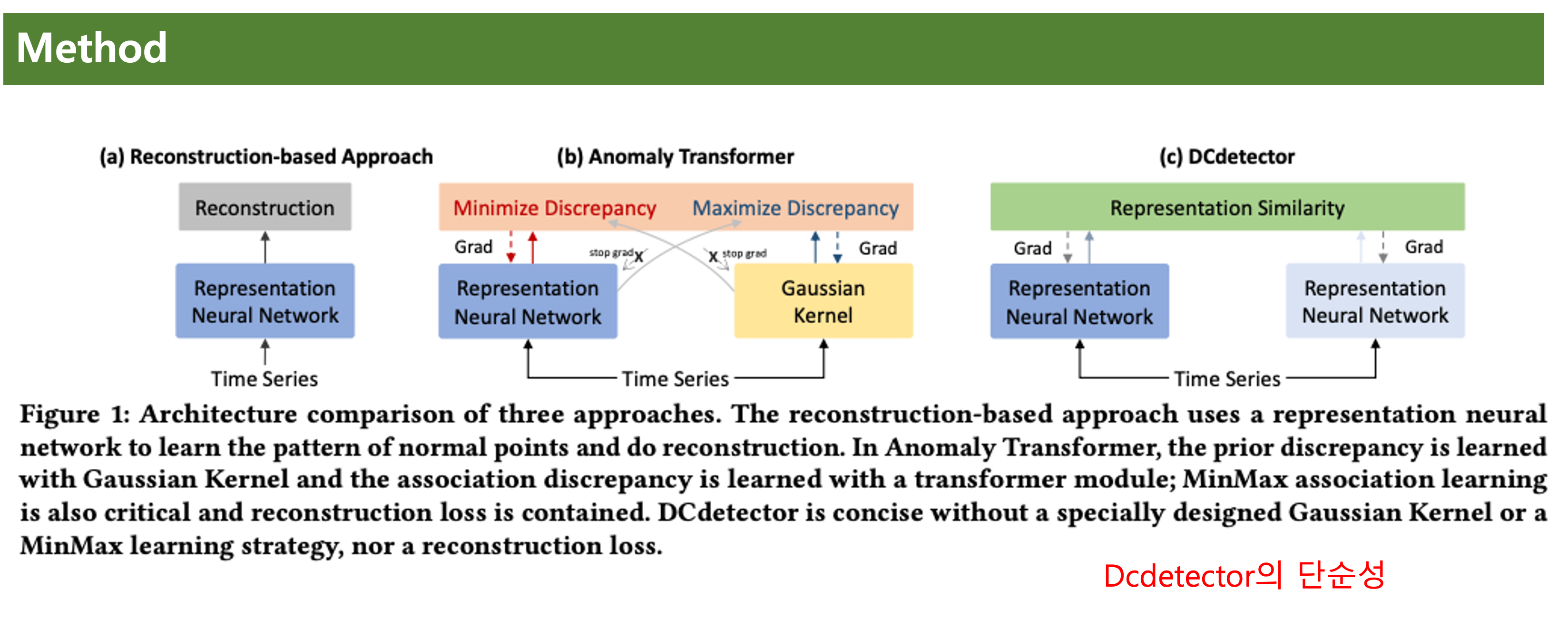
(a)는 Recon-based model이고
(b)는 Anomaly Transformer 아키텍처이고,
(c)는 DCdetector이다.
(c)가 (b)에 비해 아키텍처가 단순한걸 볼수 있다.
복잡하게 정상-이상 분류 위해 Minimize Discrepancy, Maximize Discrepancy가 필요 없다.
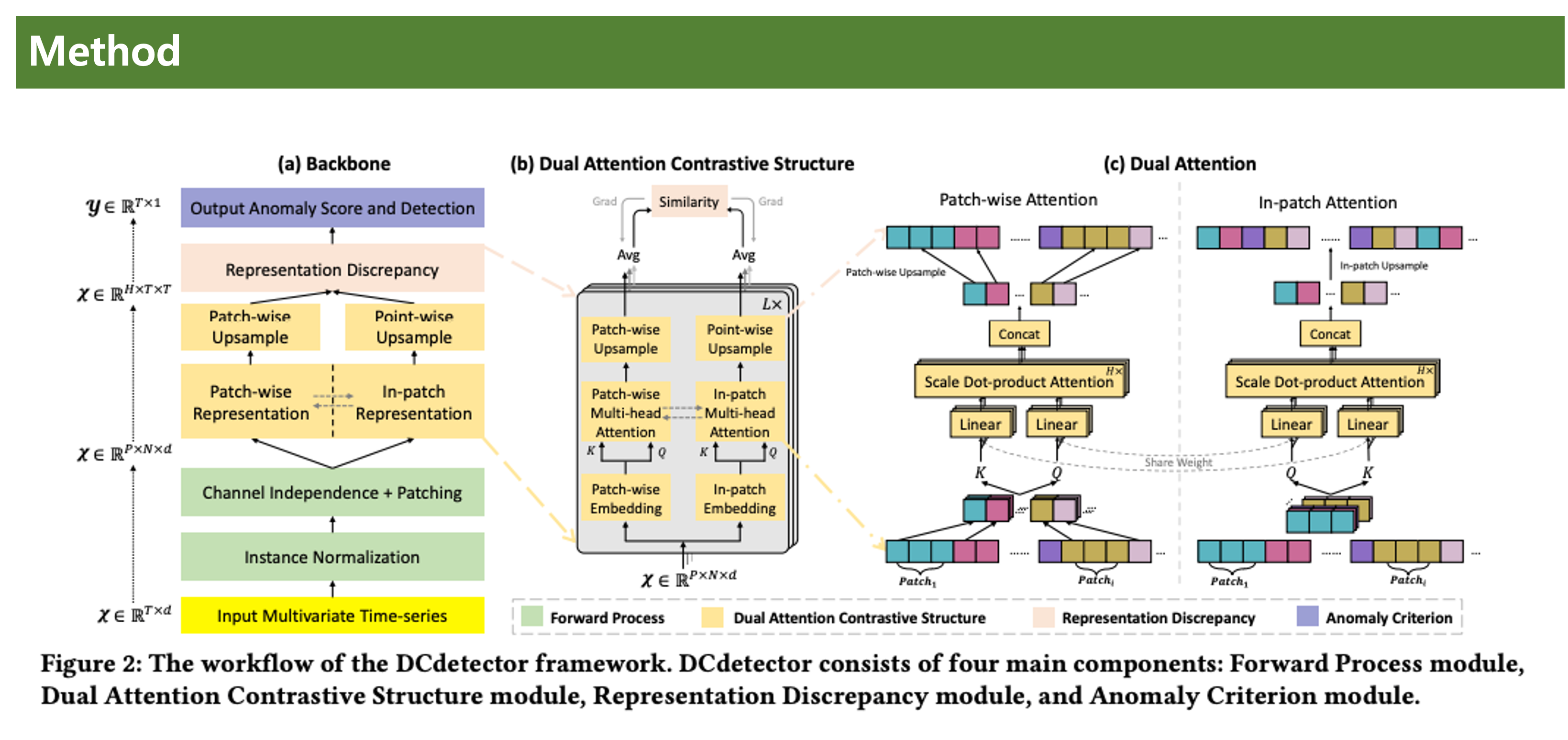
(a)는 전체적인 흐름도이고
(b)는 dual branch로 나누어진 구조이다. 각 브랜치에서 patch-wise, In-patch 임베딩 및 어텐션을 수행한다.
(c)는 Dual Attention에 대한 상세 구조이다. 여기선 Patch-wise, In-patch의 형태를 일치시키기 위해서, upsampling을 볼수 있다.
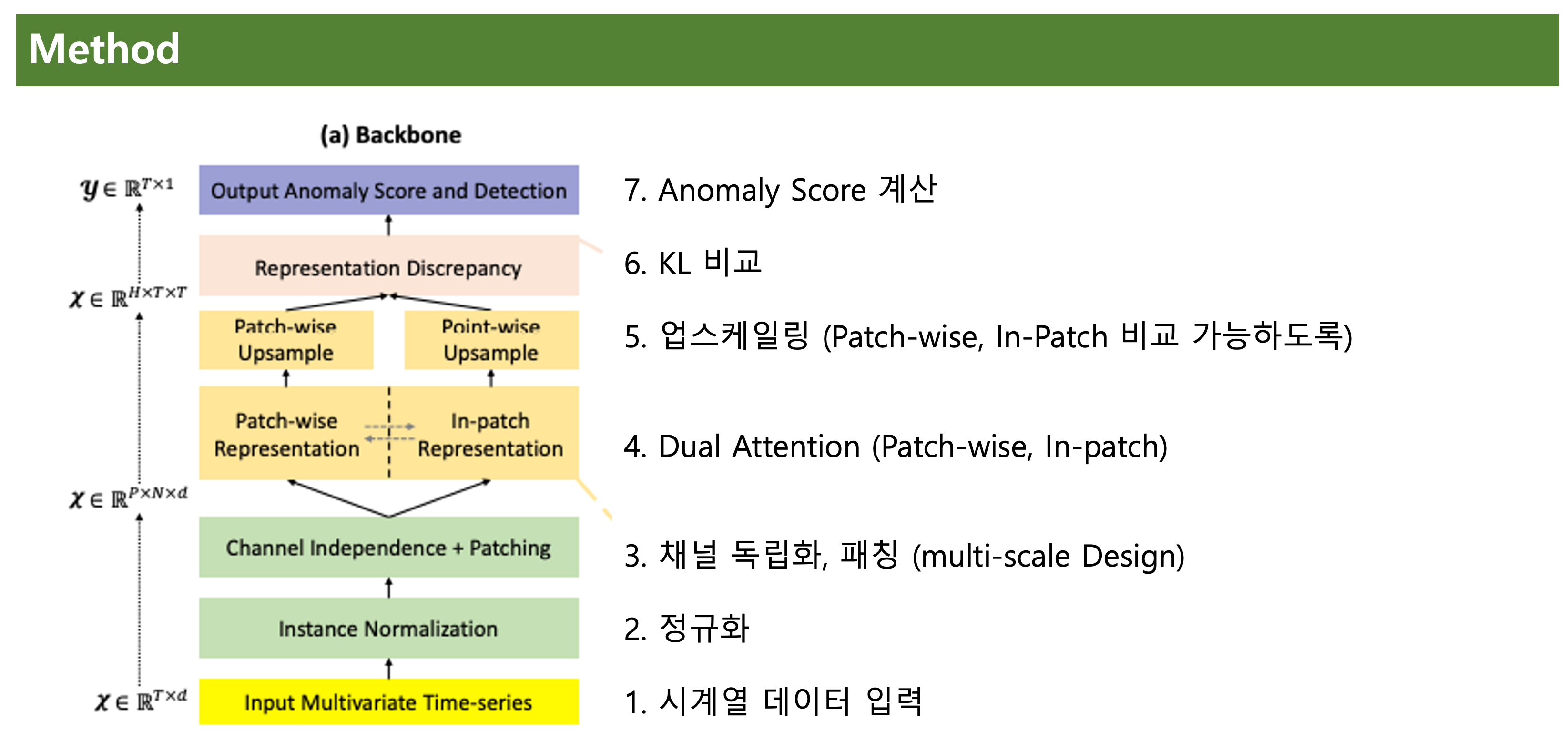
백본에 신경을 써서 알아보겠다.
1~7까지 결국은 Anomaly Score을 구하기 위해서 채널 독립화, 패칭, 듀얼 어텐션, 업스케일링, KL 비교 (Contrastive-based)을 하게 된다.

1, 2번은 간단한 작업이니 3번부터 알아보겠다.
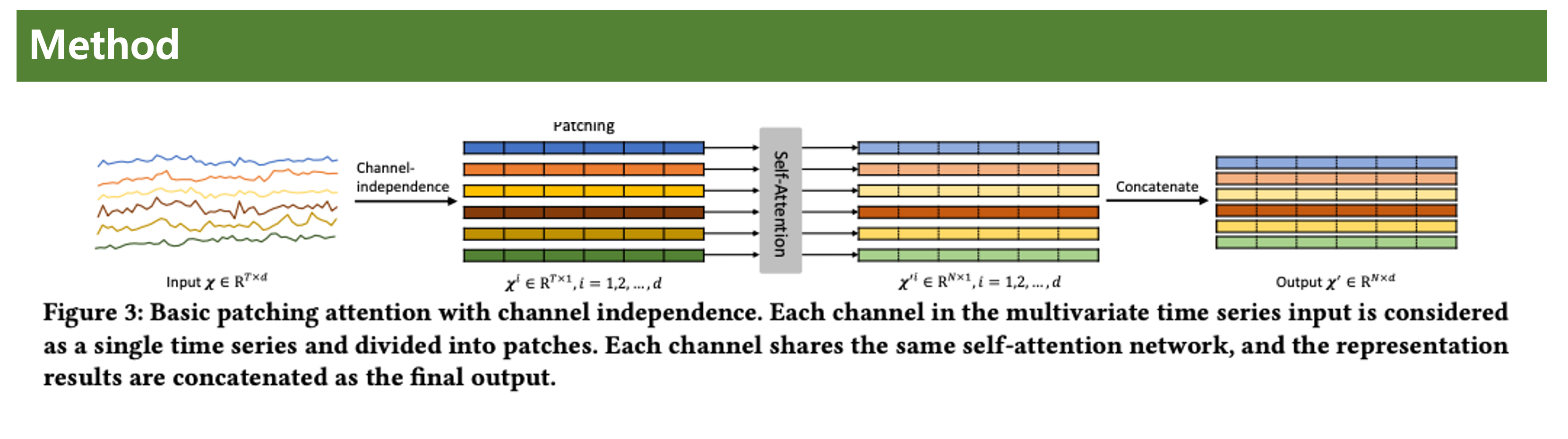
위 플로우는 입력값 -> 채널 독립화 -> 패칭 -> 어텐션 -> 결합 -> 출력값의 흐름을 따른다.
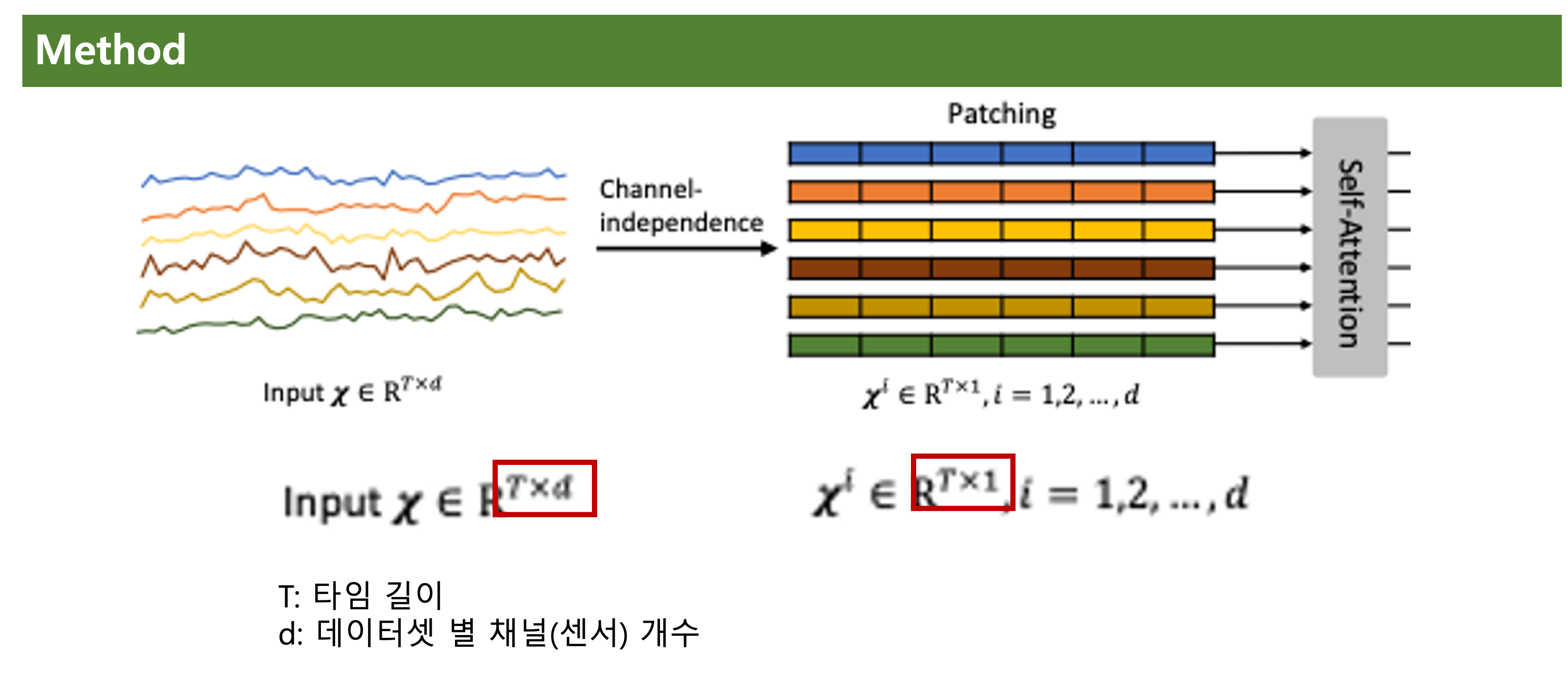
채널 독립화 (Channel-independence)을 하고 있다.
Input의 Txd 형태를 채널 독립화 하여 형태로 변환한다.
이렇게 되면, 실제 임베딩 되는 값의 형태는 가 된다는 의미이다.

위와 같은 채널 독립화 하면 2가지 장점이 있다.
파라미터 절약과 과적합 방지이다.
참고로 채널 독립화와 반대되는 개념인,
MLPMixer라는것도 있다. 이를 통해 채널간의 관계를 믹싱 해주는 것이다.
또한 GNN을 바탕으로 채널간 관계를 학습하기도 한다.
하지만, 보통은 채널 독립화가 성능이 더 좋다.
그 이유는 칼람간 관계를 통해 채널 정보를 학습해서 더 좋은 성능이 나오려면, 채널들간 상관관계가 매우 밀접하고 유기적이여야한다. 그래서 실제로 특정 몇 몇 그런 특성을 갖는 데이터셋에 대해서만 효율적이다고 한다.
실제 여러 다른 논문 테스트에서도 오히려 채널간 학습보다, 채널 독립화를 통해 차원의 저주 완화로 인한 성능 향상이 더 효율적이였다.

파라미터 절약과 같은 경우는 실제 위와 같이 연산되는 파라미터 값이 축소 된다.

또한 파라미터 절약으로 인한 차원 축소로 인해 차원의 저주 및 과적합 문제가 완화 된다.
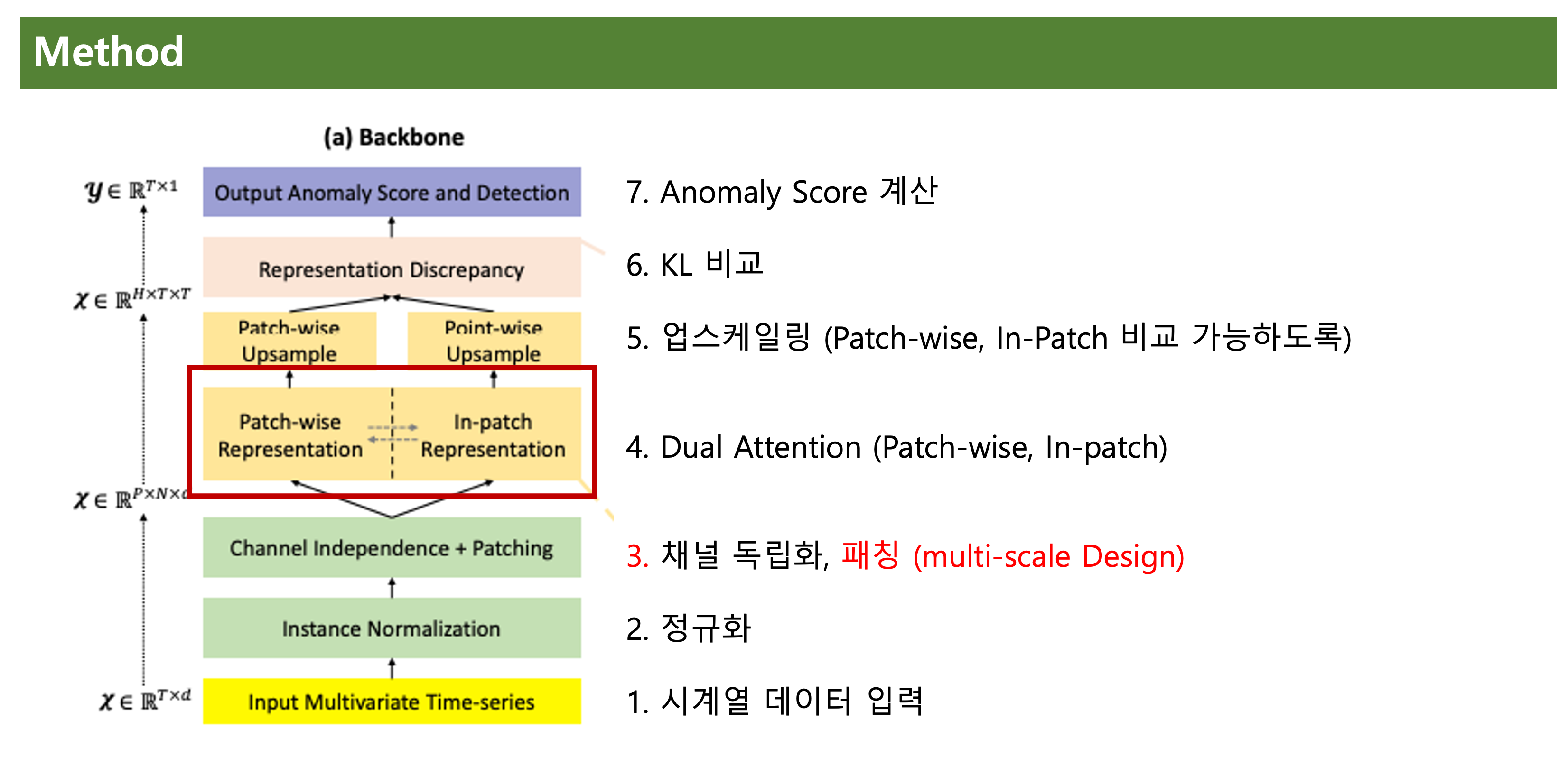
채널 독립화 뒤엔 패칭을 수행한다.

위 그림은 패칭을 표현한 것이다.
시계열 데이터의 모양이 T였다면, 이를 PxN으로 패칭(분할)한다.
패칭, 퓨즈 두 단계로 이루어진다.
패칭 단계에선,
입력 데이터의 Txd을 PxNxd으로 분할 한다.
즉, batch x (PxNxd)가 된다.
퓨즈 단계에선,
차원을 배치로 올린다.
즉, (batch x d) x (PxN)
특히 차원을 배치로 올리는건 이전에 알아본 채널 독립화의 그 설명과 일치한다.
즉, 패칭과 퓨즈 단계를 통해서 채널 독립화를 실제로 적용한다.
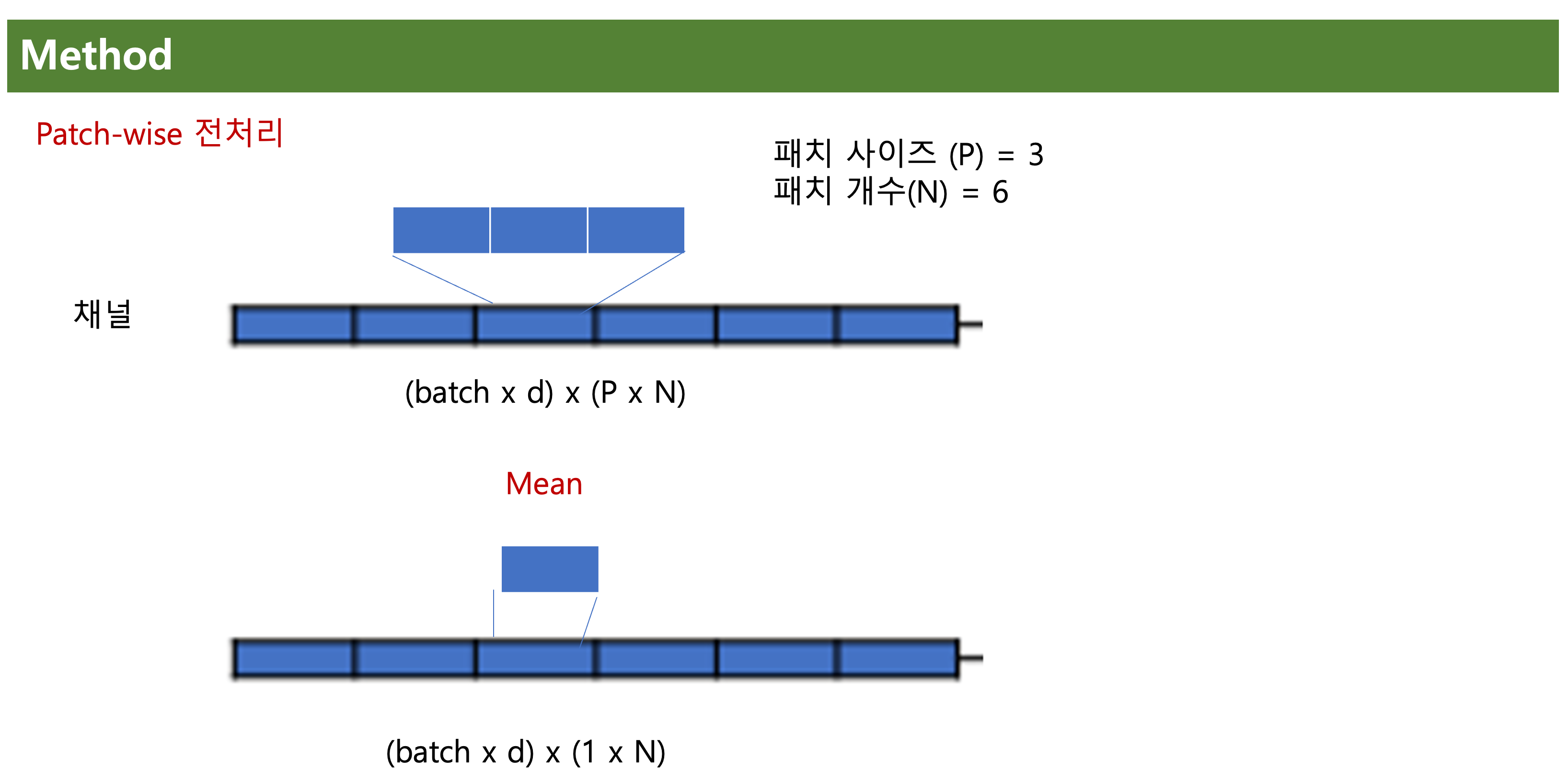
채널 독립화를 실제 적용 했으니 이젠 patch-wise, in-patch로 나눠주는 전처리 작업이 필요하다.
위와 같이 (batch x d) x (P x N)을 통해,
(batch x d) x (1 x N)을 통해, 패치 사이즈가 3이였던걸 1로 바꿔서 패치간의 관계를 볼수 있게 해준다.

patch-wise와 비슷하게 In-patch도 전처리를 해줘서,
한 패치 안에서의 시점간 관계를 학습할수 있도록 해준다.

다음으로 Dual Attention에 대해 알아보자.
patch-wise, patch의 각 시점 간의 학습을 수행한다.

(2)을 보면 패치간 표현 학습을 하고 있고,
(3)에서 각 패치간 관계인 어텐션 값을 하나의 텐서로 concat 해준다.
(5)을 보면 패치 안의 각 시점간 표현 학습을 하고 있고,
(6)에서 각 시점간 관계인 어텐션 값을 하나의 텐서로 concat 해준다.

위의 (3), (6)에서 각각 어텐션 값을 구했는데,
(3)은 패치간이고 (6)은 시점간이기에 그 형태(Shape)가 다르다.
이를 통일 시키기 위해 업스케일링을 수행해준다.
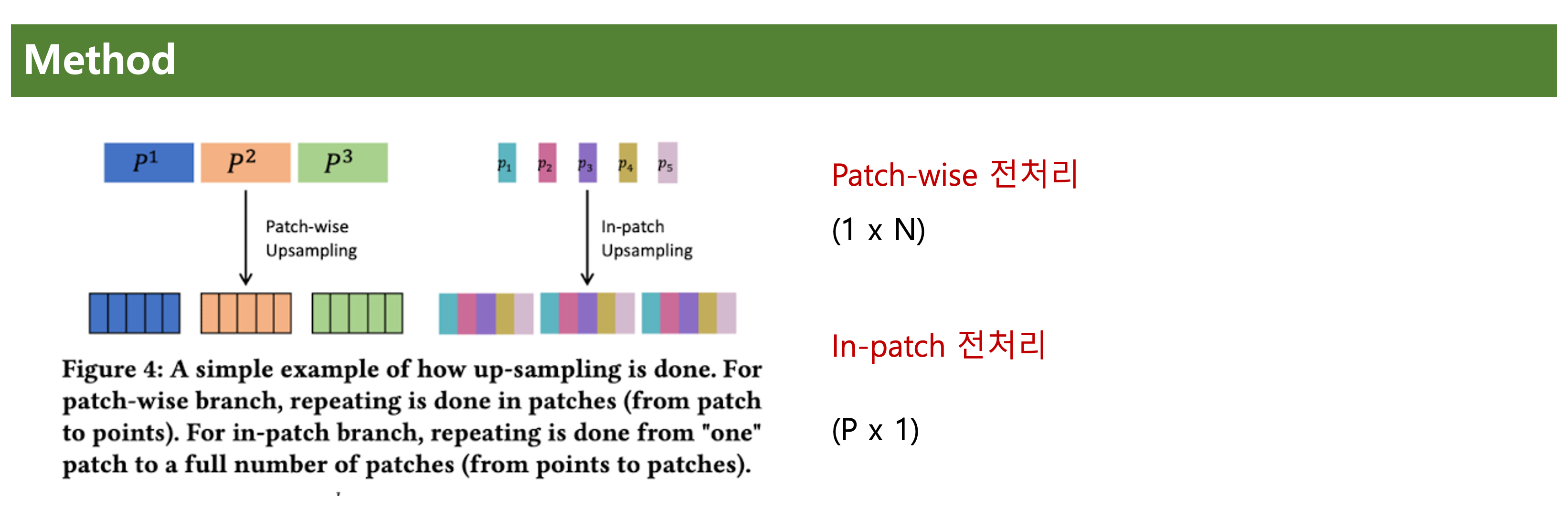
패치의 개수가 N이면, 어텐션을 지난 잠재 벡터 값의 형태는, 1xN일것이고
시점 개수가 P이면, 어텐션을 지난 잠재 벡터 값의 형태는 Px1일 것이다.

이를 같은 형태로 만들기 위해 위와 같이 업샘플링 수행한다.
같은 형태로 만들려는 이유는, KL 비교를 위함이다.
KL은 두 분포를 비교하는 것이기에, 같은 형태여야한다.

KL을 수행하여 Representation Discrepancy 수행한다.

어텐션도 거치고 업샘플링 된 벡터들을 대상으로 KL 훈련하게 된다.
정상 샘플로만 훈련을 하게 되고, 정상 샘플시에는 Patch-wise, Point-wise 모두 분포가 비슷할것이다.
그렇기에 이상 샘플이 들어오면 이 둘의 분포는 그 차이가 극명할 것이다.
이와같이 정상 샘플로만 KL 훈련을 하게 되어 정상 샘플, 이상 샘플의 분포 차이를 벌려주어 Contrastive 표현을 학습하게 된다.
여기서 주의할 점은 Triplet Loss와 같은 Contrastive Learning은 아니라는 점이다.
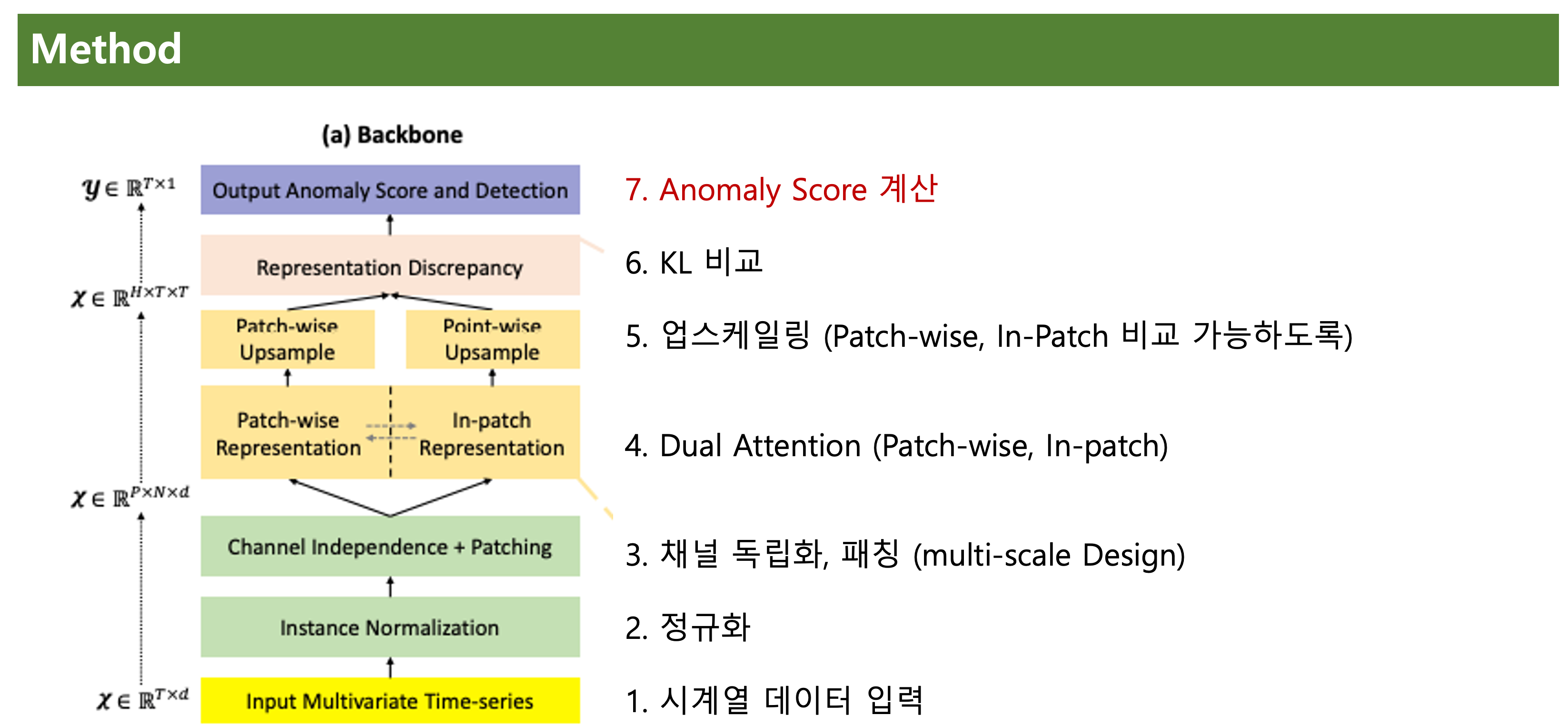
비로소 Anomaly Score을 계산해준다.

임계점보다 크면 이상 샘플, 임계점보다 작으면 정상 샘플이다.
dual-branch 구조와 KL을 통한 Contrastive 분포 표현을 학습하여 Anomaly Score을 정상-이상 샘플에 대해 분명히 해준다.
