[논문 리뷰] Tranad: Deep Transformer Networks for Anomaly Detection in Multivariate Time Series Data
간략 요약
- phase 1의 recon loss을 통해 이상 데이터에 대해 큰 가중치 갖는 focus score 도출
- phase 2에서는 focus score을 묻힌 상태에서 Adversarial Traning 수행
- focus score을 묻히는 이유는, 정상-이상 샘플의 차이를 극대화 하여 추후 수행할 Adversarial Training의 효율을 높이고자함
- Adversarial Traning은 디코더 1에서는 와 W의 차이를 최소화, 디코더 2에서는 와 W의 차이를 최대화함
- 이를 통해 W가 재구성이 잘 되면서도, 이상 시점에 대해선 그 벡터 값이 매우 크게 생성
시간관계상 핵심 Method, Mechanism만 소개하겠다.
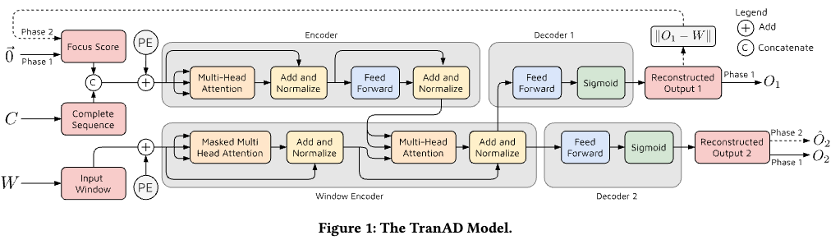
위 그림은 TranAD 아키텍처이다.
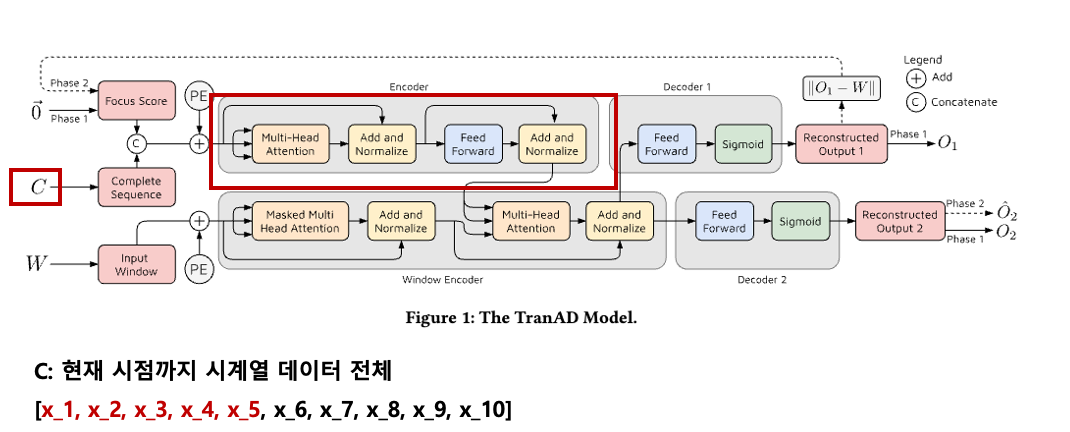
입력으로 C가 들어가게 되는데,
현재 시점까지 시계열 데이터 전체이다.
현재 시점이 t=5라면 x_1~x_5까지.
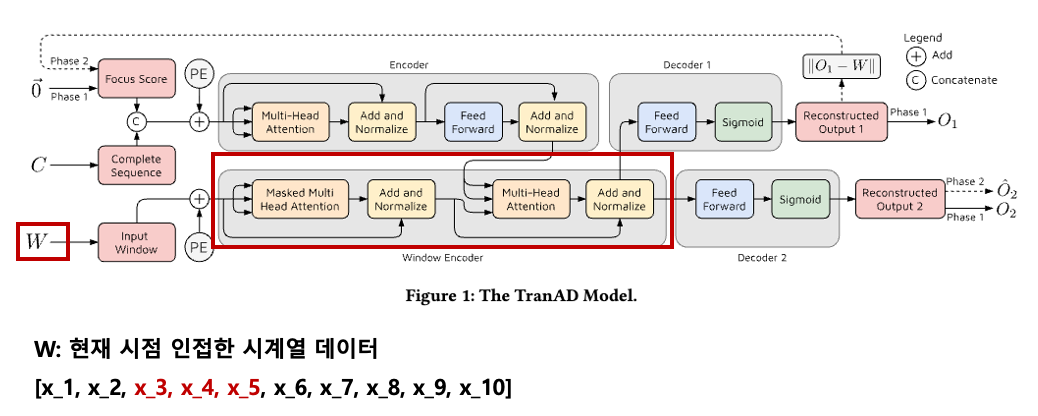
입력으로 W도 들어가게 되는데,
현재 시점 인접한 시계열 데이터이다.
현재 시점 t=5이고 인접 시점을 3개까지 본다면
W= x_3~x_5가 된다.

주의해야할게 있는데, W에서 K(윈도우 사이즈 길이)가 T보다 크다면, 현재 시점인 x_t을 부족한 개수만큼 복제해준다.
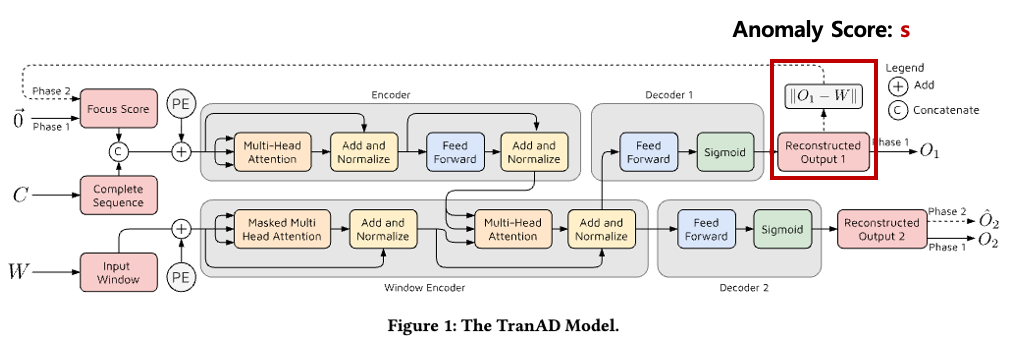
그리고 이상 점수인 Anomaly Score인 s는 recon loss을 통해 구한다.
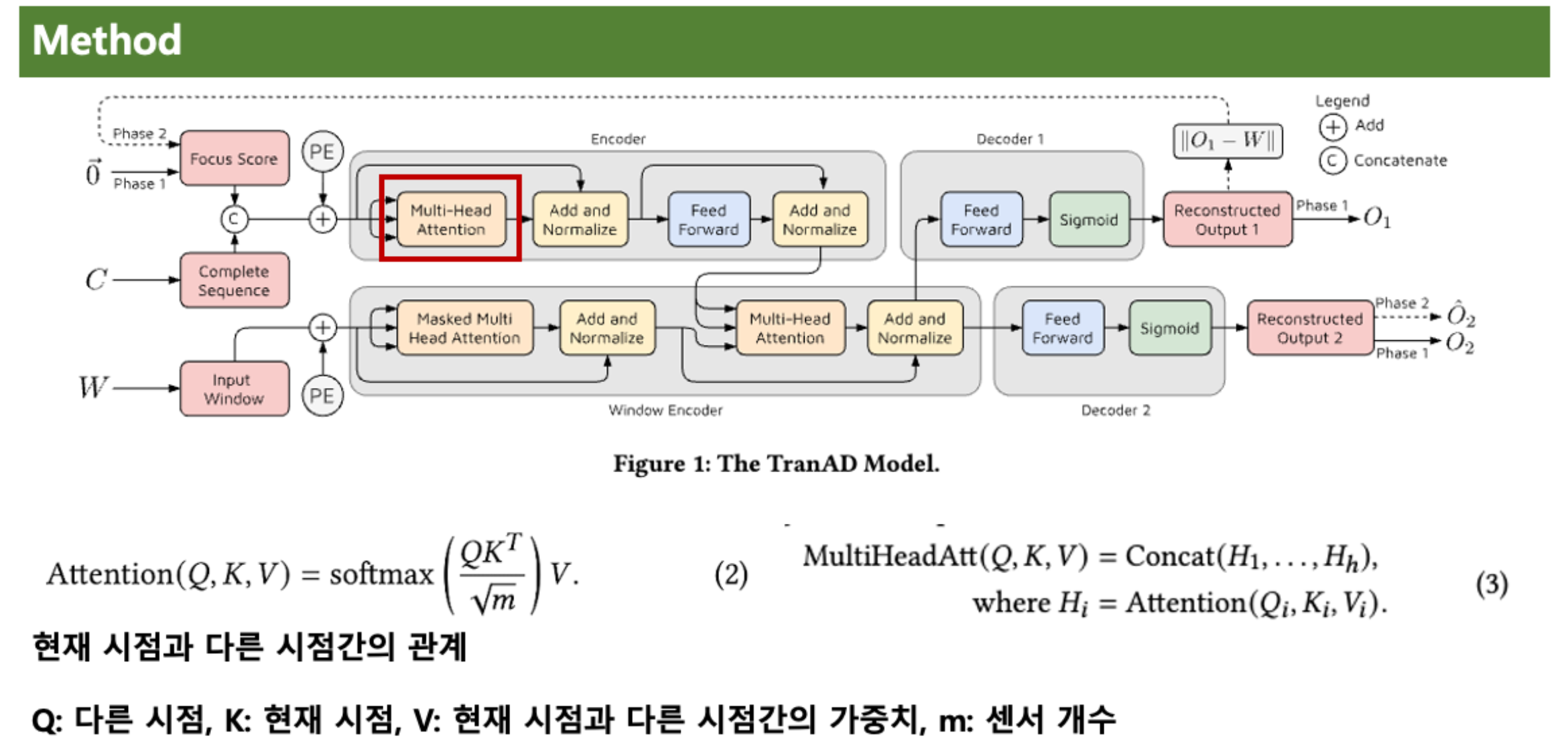
본 논문의 아키텍처에 대해 좀 더 자세히 알아보자면,
C와 Focus Score이 concat되고, PE(Positional Encoding)되어, Multi-Head Attention을 거친다.
수식 (2)는 트랜스포머 어텐션의 기본적인 구조이다.
이를 통해 현재 시점과 다른 시점간의 관계를 알수 있다.
그리고 Focus Score은 뒤에서도 설명하겠지만 Recon loss로 이루어진다.
그래서 일반적으로 정상 샘플에 대해 매우 많은 샘플이 있고, 이상 샘플에 대해 매우 적은 샘플이 있다.
그렇기에 Recon은 정상 샘플에 대해 많은 학습이 이루어졌을 것이다.
그래서 이상 샘플이 recon을 거치면 매우 큰 s을 갖게 될것이다. 특히 그 이상 시점에 매우 큰 s을 갖게 되며, 이걸 Focus Score로 상정하여 이상 시점에 큰 가중치를 갖게되어 이상 시점에 더 포커싱 줄수 있도록 돕는다.
위 Focus Score는 본 논문의 Contribution.

그리고 본 논문에 Attention을 Concat하여 MultiHeadAtt로 만드는데,
Attention은 현재 시점과 각 시점간의 관계만 나타내지만,
MultiHeadAtt는 센서간의 관계 파악 가능.
즉, CPU 사용률과 메모리 사용률의 관계 등 파악 가능.
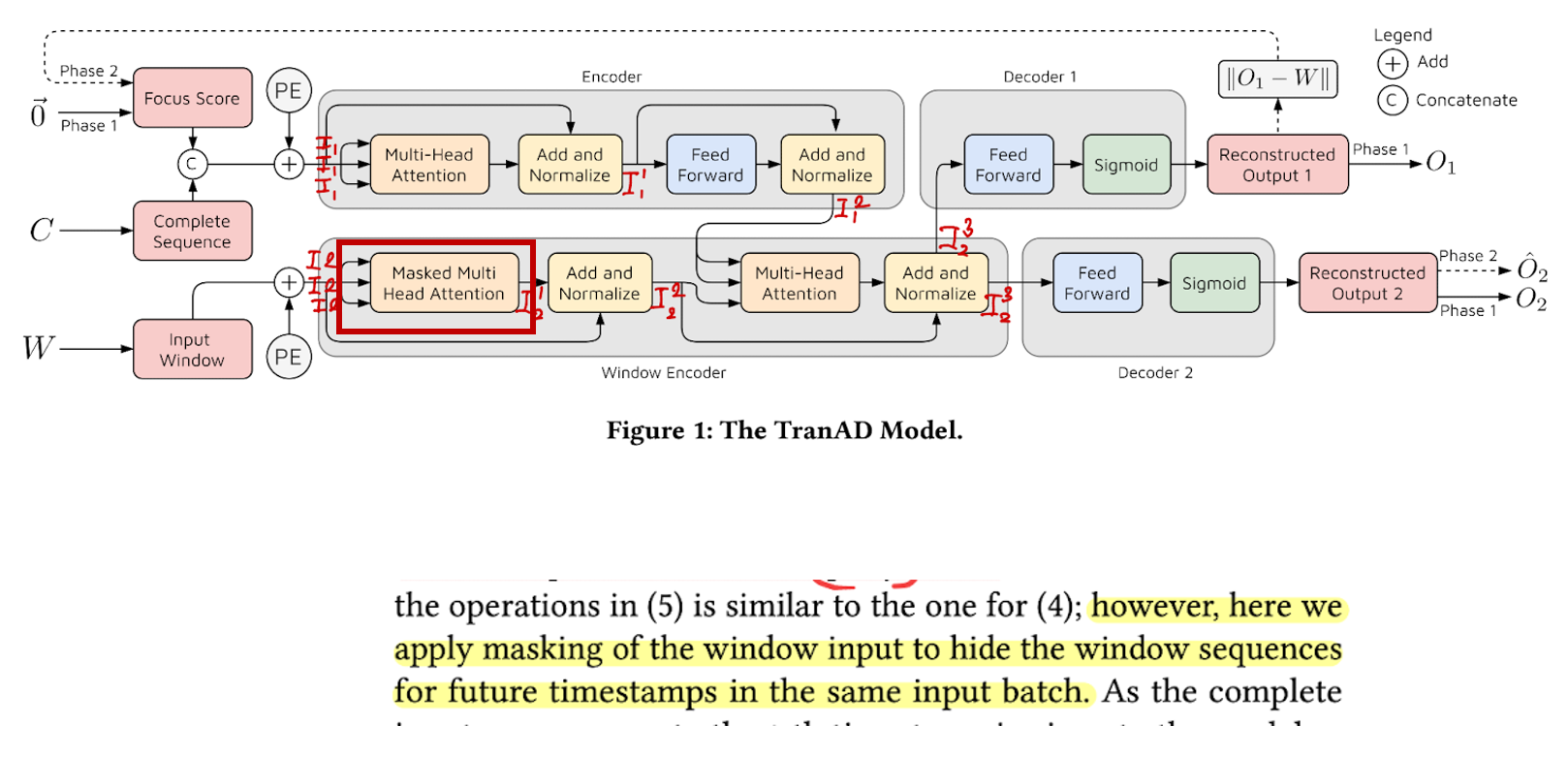
Masked Multi Head Att같은 경우는 현재 시점 이후는 못보게 하는게 당연한것이기에 마스킹 한다.
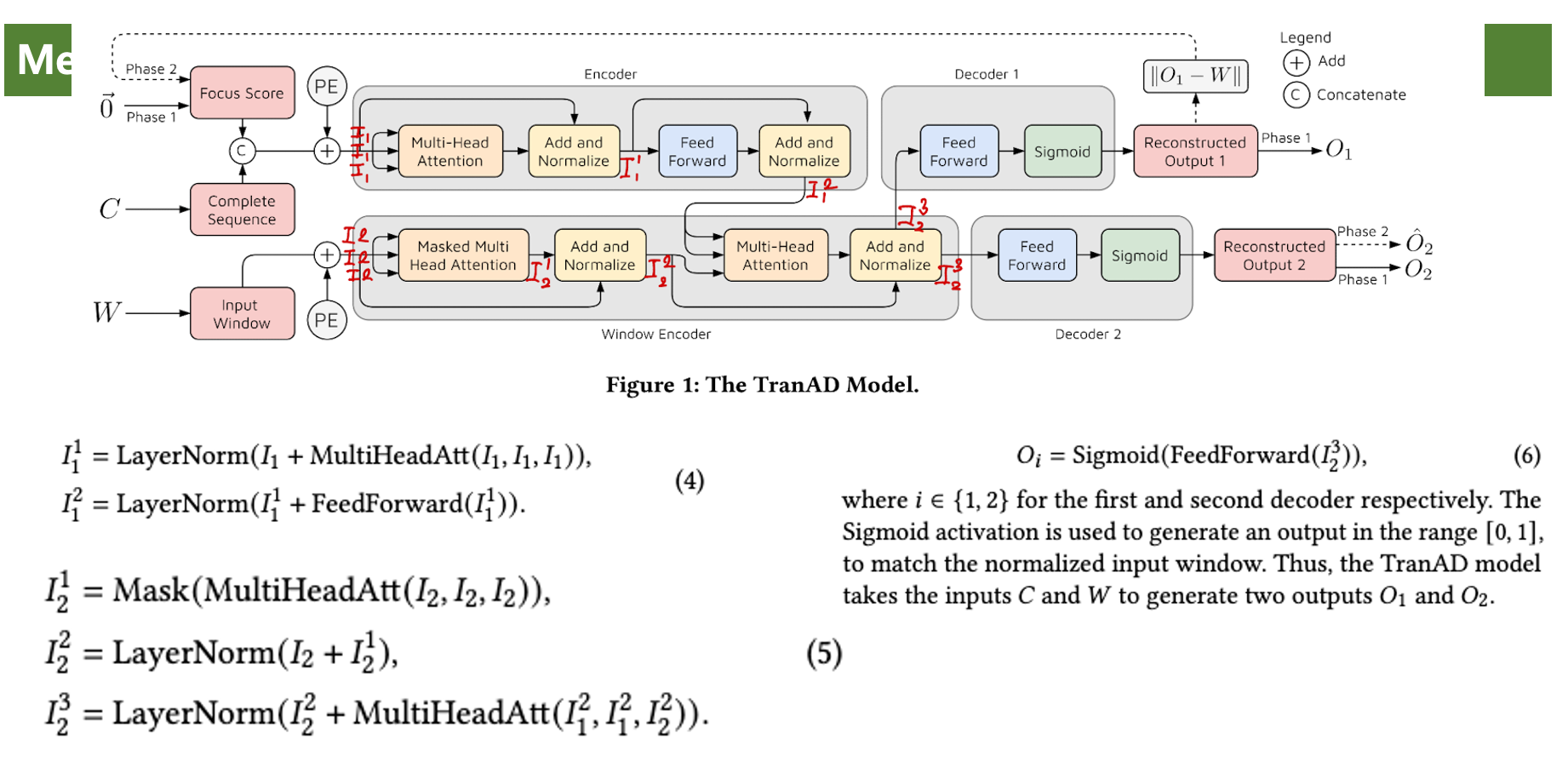
본 논문에서 아키텍처를 Q,K,D 관점으로 표현하면 위와 같음.
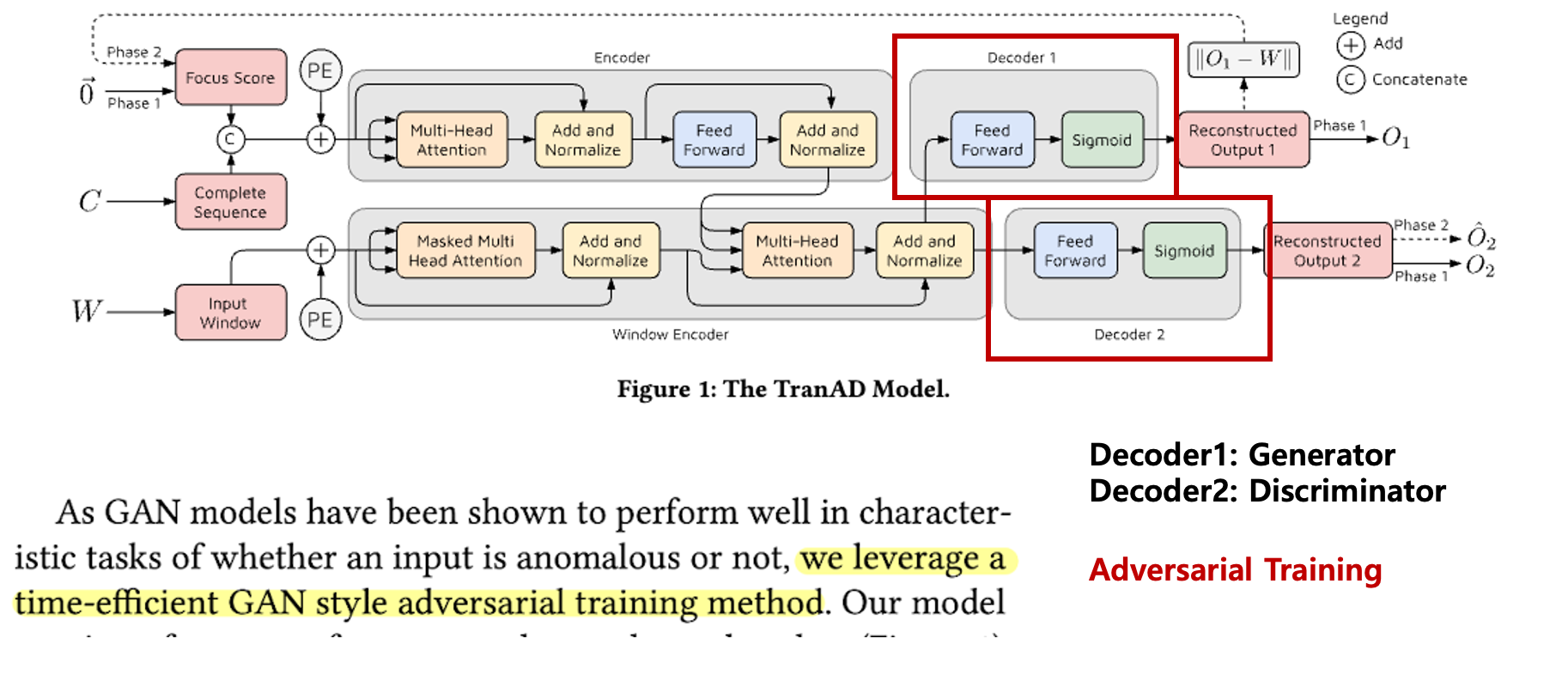
본 논문에는 두 개의 디코더가 있음.
Decoder1을 GAN의 생성자, Decoder2을 GAN의 판별자 비슷하게 보면 됨.
그래서 훈련 이름도 Adversarial Training.
특히나 이 훈련은 Phase2에서 수행.

TranAD을 수행하기 위해 2단계의 절차로 구성됨
1단계에서는, 두 디코더 모두 입력 W을 잘 재구성하기가 목표.
Recon loss만 최적화.
이를 통해 O1, O2 출력
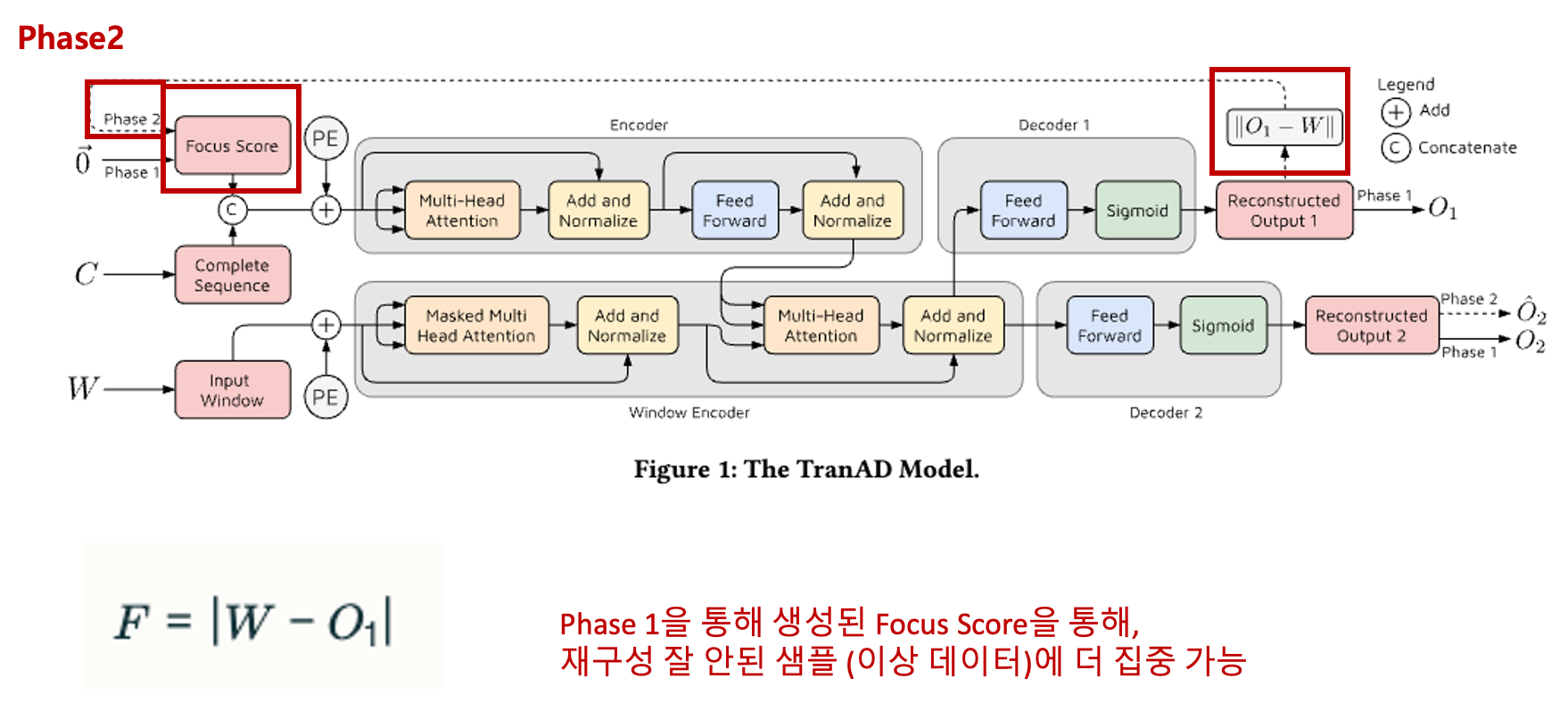
Phase 2에서는,
Phase 1을 통해 재구성 loss 값인 Focus Score을 통해, 재구성 잘 안된 샘플 (이상데이터)에 더 집중 가능.
이를 self-conditioning이라고 함.
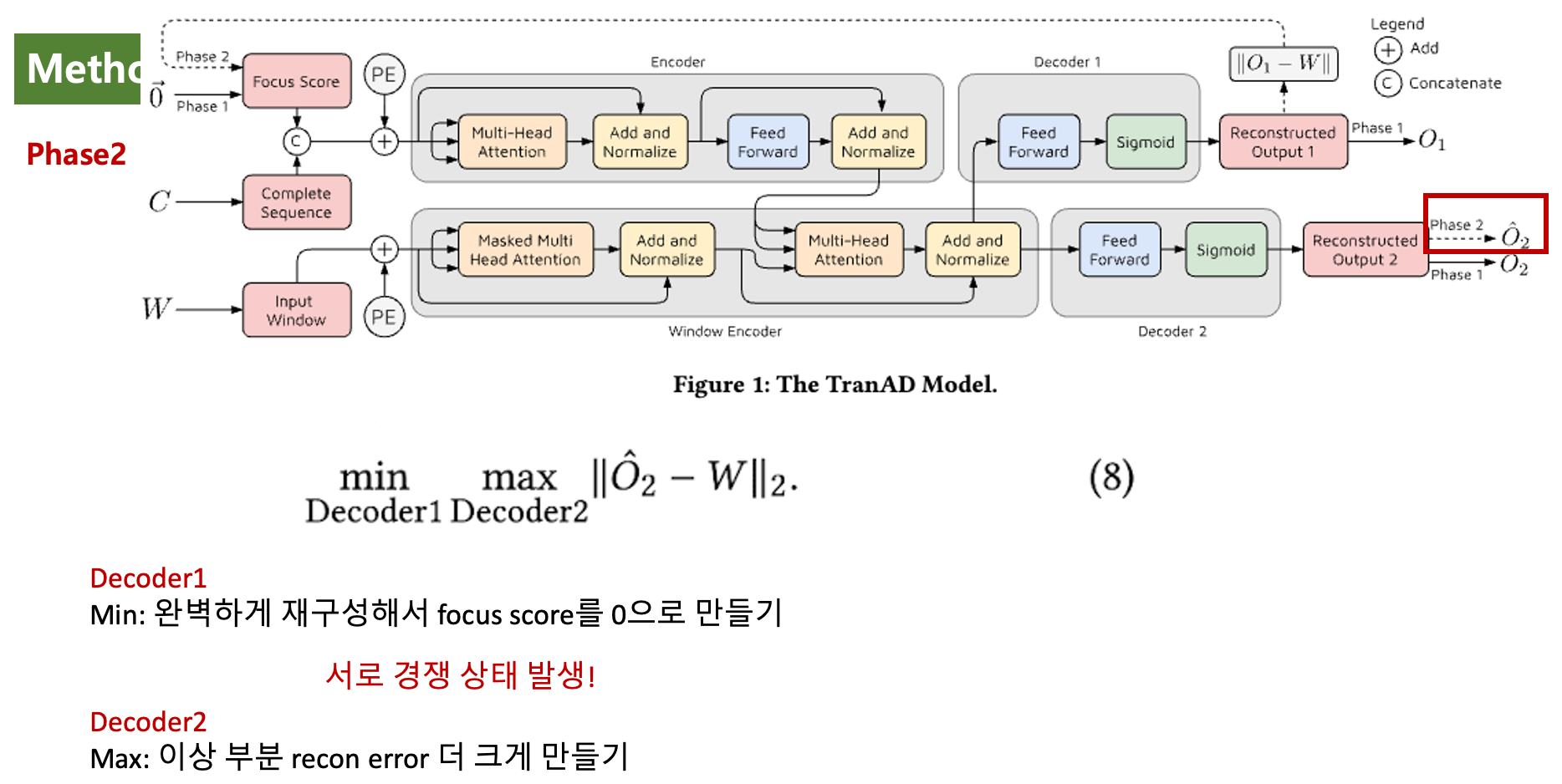
또한 Phase 2에서는 경쟁 상태를 유발시킴 (min-max game).
수식(8)에 의해서,
디코더 2에서는 을 출력하는데,
와 W의 차이가 최대화 되도록 훈련됨
디코더 1에서는 와 W의 차이가 최소화 되도록 훈련됨.
즉 서로 정 반대의 지향점을 갖고 있으며 이를 통해 경쟁 상태 유발.
다만 주의할것은 디코더1에서 을 최소화 하는게 목표인데,
디코더 1은 이랑만 관련된것처럼 보인다.
사실 Phase2에서는 Focus Score을 통해 self-conditioning을 수행하는데, 여기에 결국 이 묻는다.
Phase2에서 이 묻은 상태로 디코더 2에서 이 출력되기에,
수식 (8)에서 -W을 최소화 한다는것은 결국 focus score을 0에 가깝게 만든다는것이고 이는 최종적으로 Phase1의 reconstruction error을 0에 가깝게 만든다는것이랑 같은 말이된다.
결론적으로 Adversarial Training을 통해서
재구성을 잘하면서도, 이상 시점에 대해 더 큰 가중치를 얻도록 훈련한다.

Adversarial Training에 대한 계수가 초반에 너무 크면 학습이 망가질 가능성이 있어 위와 같이 epoch별로 가중치를 조절한다.

수식 (13)은 Adversarial Score인 s인데,
을 통해 이상데이터에 대해 더 큰 값을 얻는게 가능해진다.
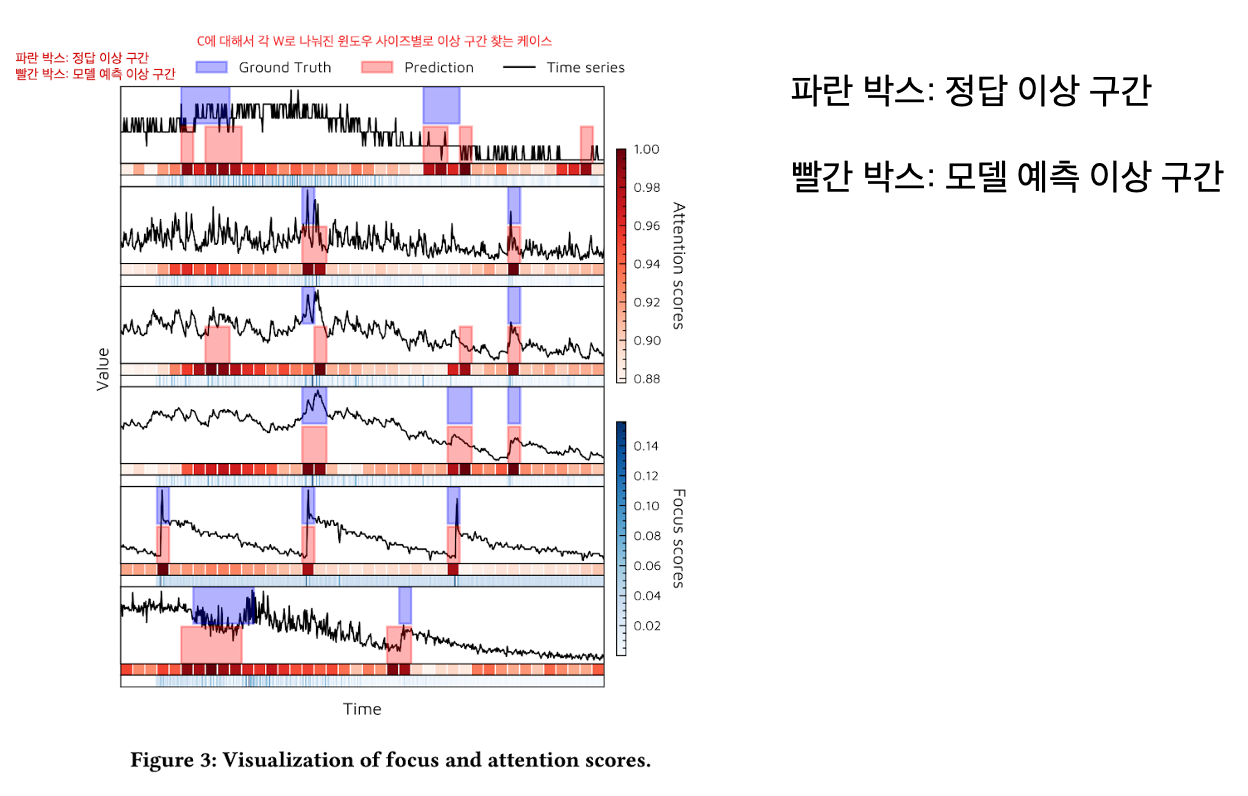
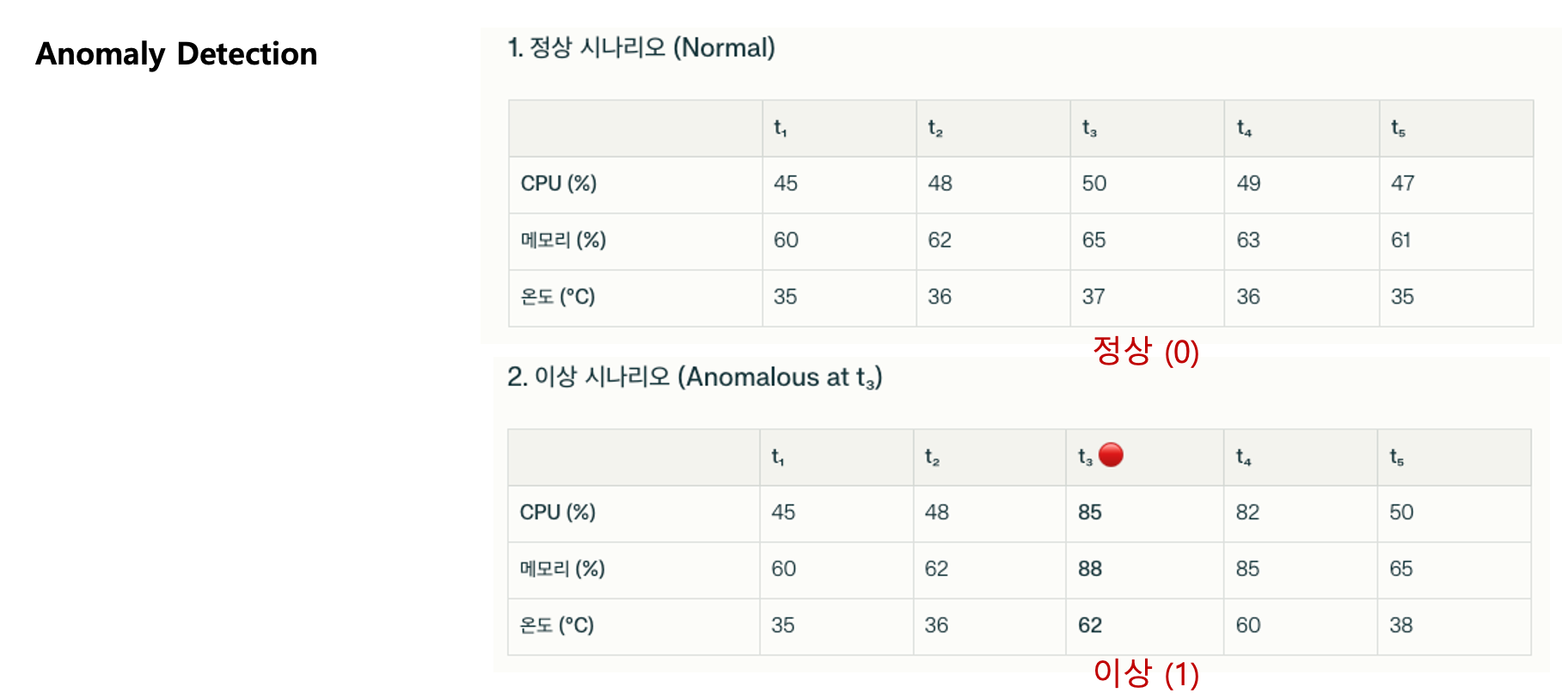
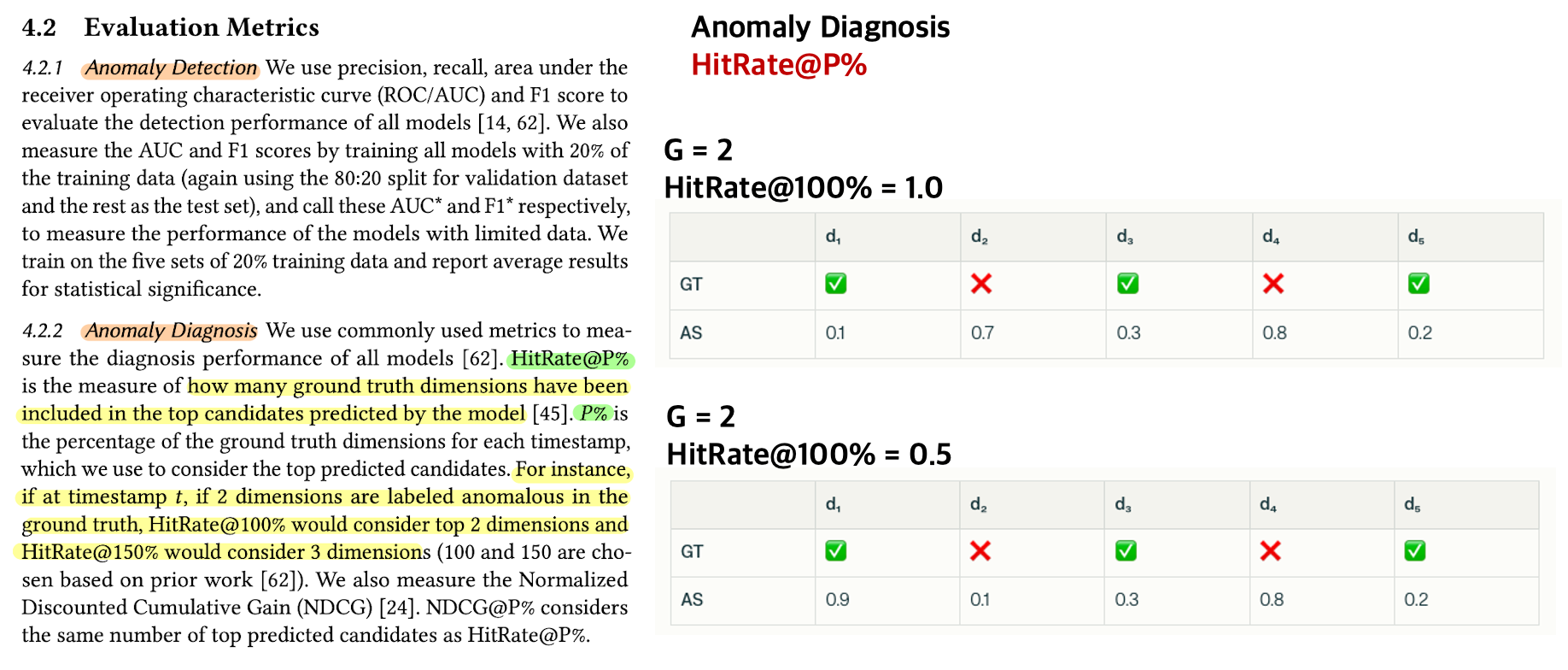
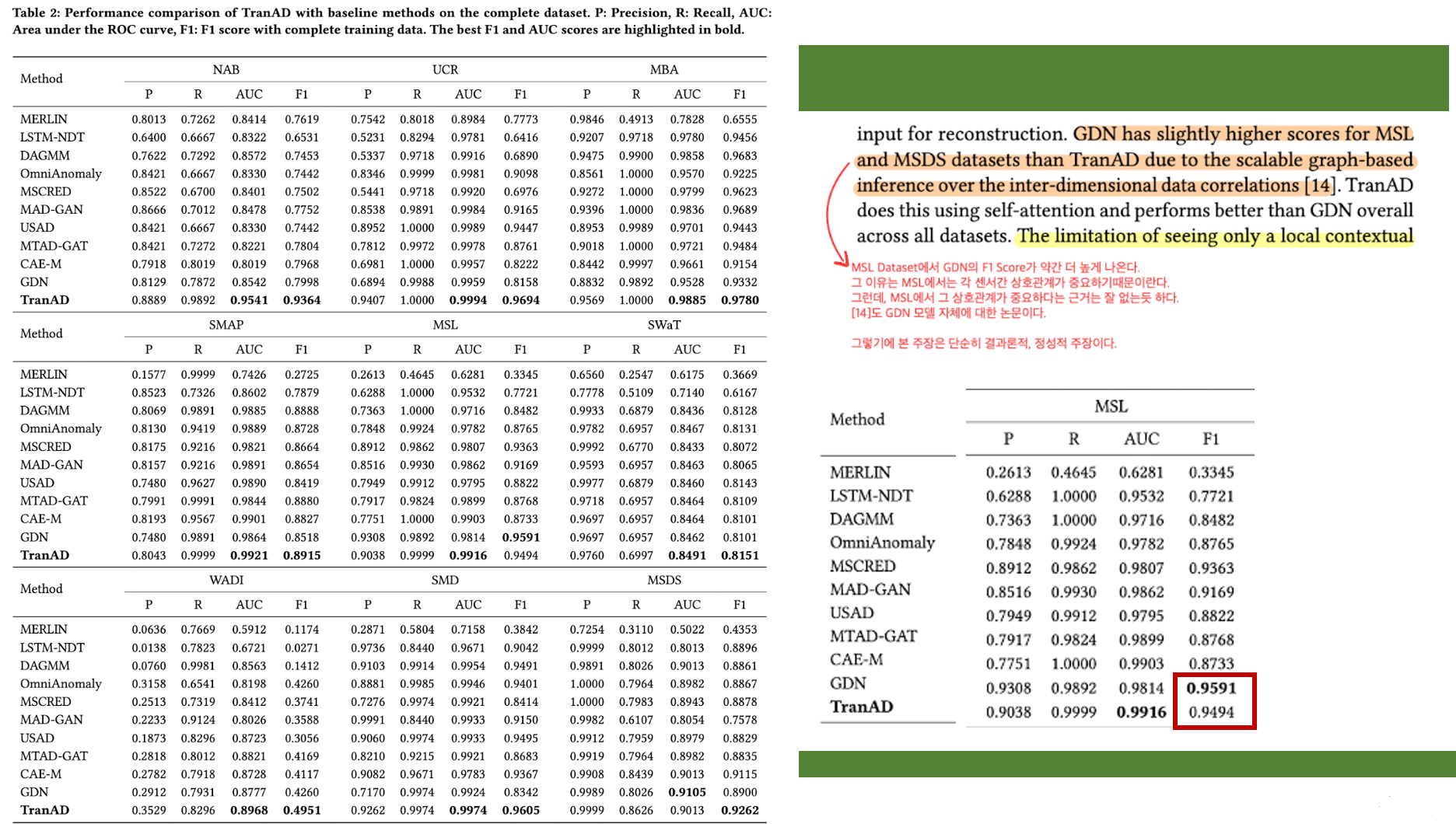
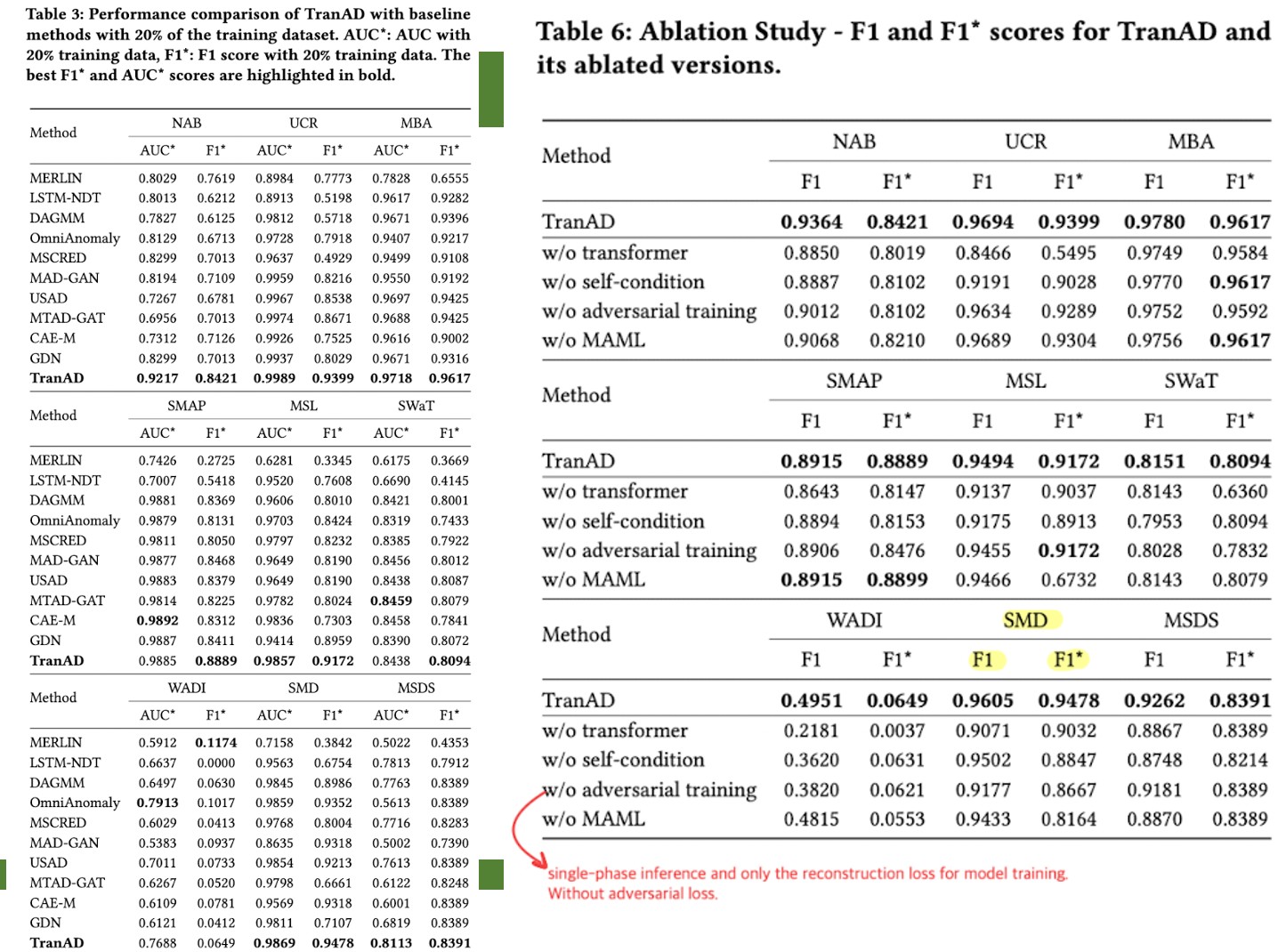
그 밖의 Experiments는이미지로 대체한다.