RNN, attention, transformer
RNN
Recurrent neural network(순환 신경 네트워크)
말 그대로 recurrent하다.
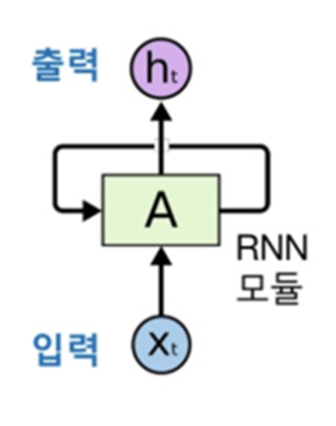
이때 문제가 되는 것은 오래된 시그널이 점점 소실된다는 문제가 있었는데,
이를 LSTM (long short term memory)로 해결하였다.
Attention
seq2seq 모델은 인코더에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, 디코더는 이 컨텍스트 벡터를 통해서 출력 시퀀스를 만들어냈습니다.
하지만 이러한 RNN에 기반한 seq2seq 모델에는 크게 두 가지 문제가 있습니다.
첫째, 하나의 고정된 크기의 벡터에 모든 정보를 압축하려고 하니까 정보 손실이 발생합니다.
둘째, RNN의 고질적인 문제인 기울기 소실(vanishing gradient) 문제가 존재합니다.
결국 이는 기계 번역 분야에서 입력 문장이 길면 번역 품질이 떨어지는 현상으로 나타났습니다. 이를 위한 대안으로 입력 시퀀스가 길어지면 출력 시퀀스의 정확도가 떨어지는 것을 보정해주기 위한 등장한 기법인 어텐션(attention)을 소개합니다.
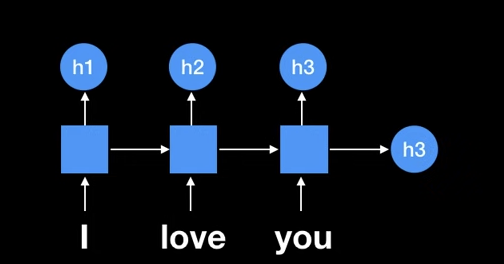
위의 사진에서 h3가 seq2seq가 사용하는 문맥 벡터(context vector)였다.
이때 인용에서 말한 문제점들이 발생하였다.
때문에 i, love, you를 지나면서 나온 h1, h2, h3를 이용해보는 것이다.
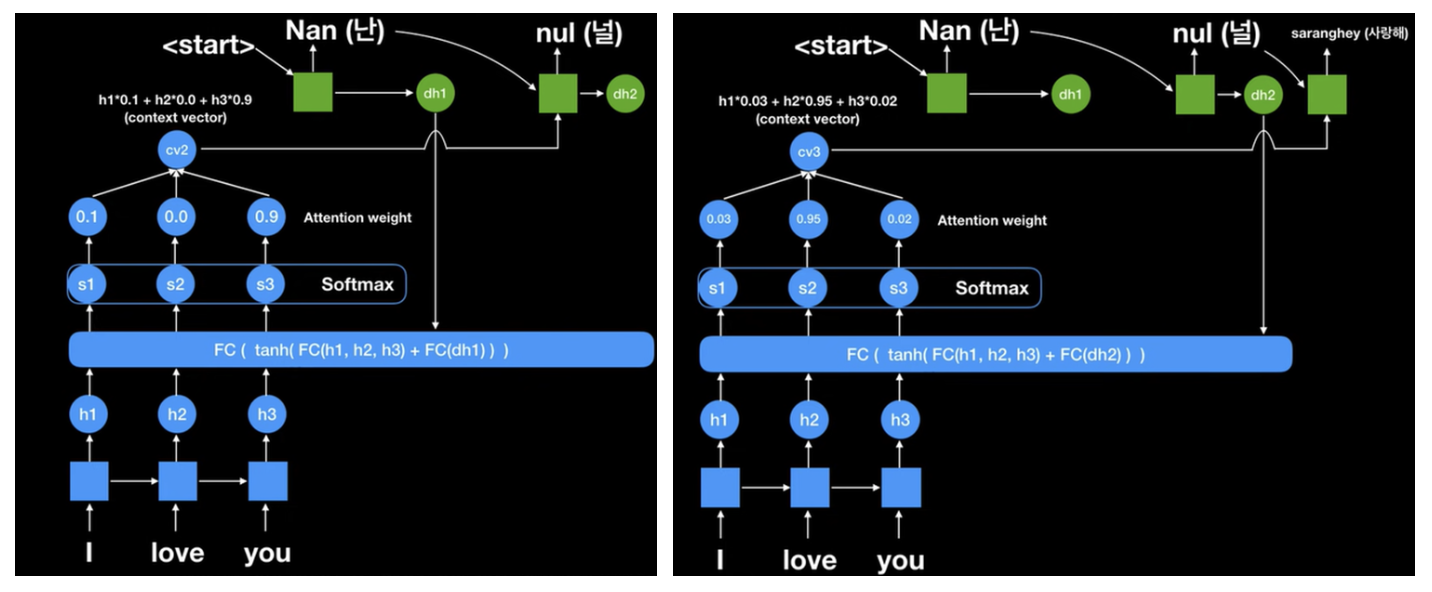
Transformer
only attention based network : encoders and decoders
