아키텍쳐
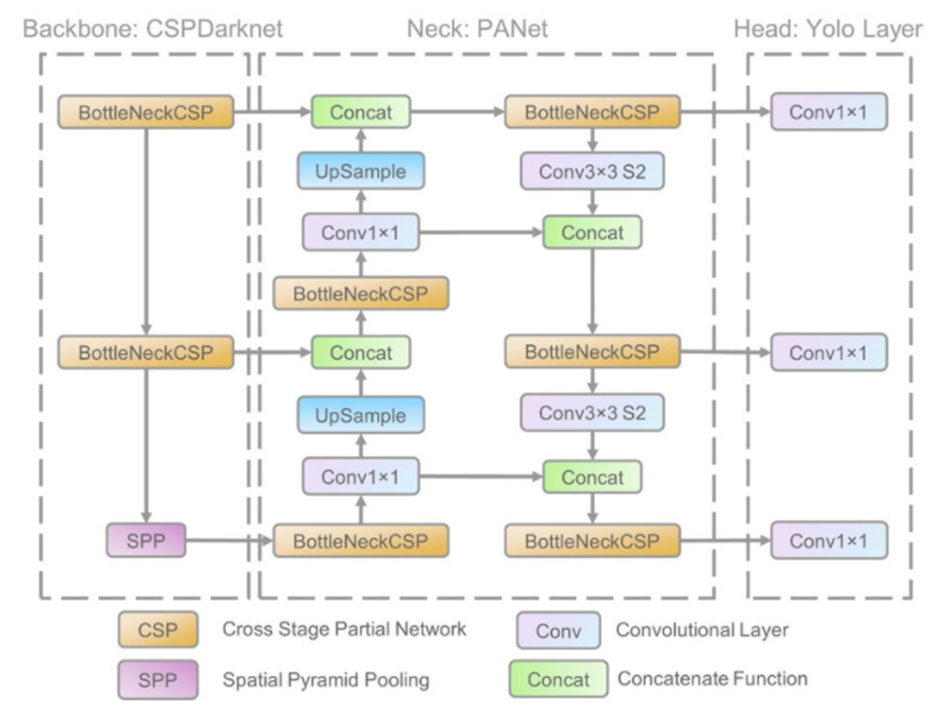
벌써부터 난관이다! backbone, neck, head? 이게 다 뭐람.
backbone
input layer를 feature map으로 변환한다. 즉, Backbone은 원본 이미지에서 유용한 정보를 추출하고, 이를 보다 추상적이고 고차원적인 특징으로 변환합니다. yolov5는 CSPDarkNet을 사용하였다.
CSPDarkNet
CSPDarkNet을 알기 전에 CSPNet이 무엇인지 알아야한다.
CSPNet
컴퓨터 비전 영역에서 놀라운 방법들이 많이 나왔음에도 불구하고 이를 사용하기 위해서는 높은 컴퓨팅 파워가 필요하였다. 그 이유는 연상량이 많아지는 이유는 네트워크가 optimaization하는 과정에서 gradients의 정보 중복으로 인한 것이라고 말하며, 제안하는 네트워크가 gradients의 다양성을 시작단과 끝 단의 통합 과정을 통해 이를 줄일 수 있다고 한다. (어렵지만 포기하지 말자. 수식으로 이해하는게 더 쉽다!)
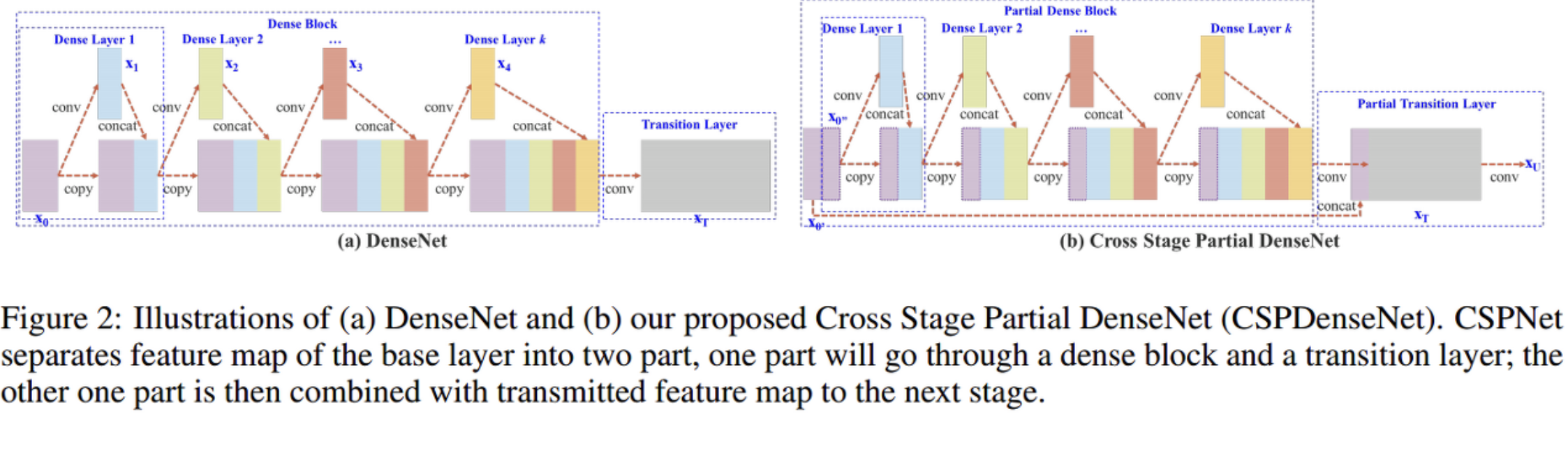
왼쪽의 그림 (a) DenseNet을 보자. DenseNet를 수식으로 나타내면 이렇다.
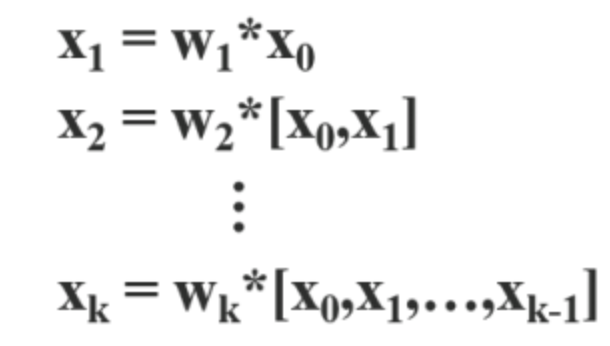
feed forward 계산식이다. 이전 레이어들의 출력 값이 현재 레이어의 입력값으로 들어오고 있다.
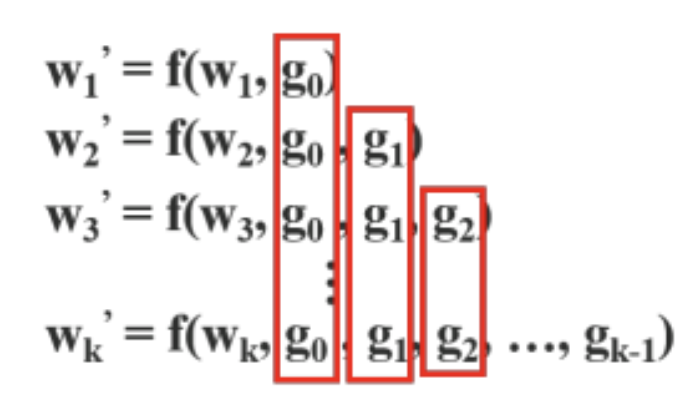
backpropagation을 할 때는 이러한 수식이 만들어진다.
w: forward pass의 가중치, g: 미분을 통해 얻어지는 기울기, f: 가중치를 업데이트하는 함수이다.
이를 보면 g(gradient)가 중복적으로 사용됨을 알 수 있다. 이 중복적인 과정을 CSPNet은 새로운 방법을 고안해 중복을 줄일 수 있었다.

(a)의 DenseNet과 비교해보자. (b) 그림의 제일 앞단인 보라색 덩어리를 잘 살펴보자. 두번째 레이어에 들어가는 것은 첫번째 레이어의 절반뿐이다. 나머지 절반은 가만히 놔둔다. 그 이후의 연산과정은 DenseNet과 동일하다.
맨마지막 부분에서 차이점이 있다. 첫번째 레이어의 절반(conv하지 않은)을 마지막에 combined된다. (논문에 그렇게 써있음)
절반만을 convolution 연산하니 당연히 기울기의 중복이 줄어들 수 밖에 없다. 심지어 정확도도 유지된다.
그렇다면 CSPDarkNet은 뭔가요?
CSPNet에 BottleneckCSP, SPP를 더해준 것이다.
정확히 말하자면, CSPNet에 DarkNet을 합한것인데 Darknet의 구조를 보면 다음과 같다.
먼저 BottleneckCSP을 설명하겠다.
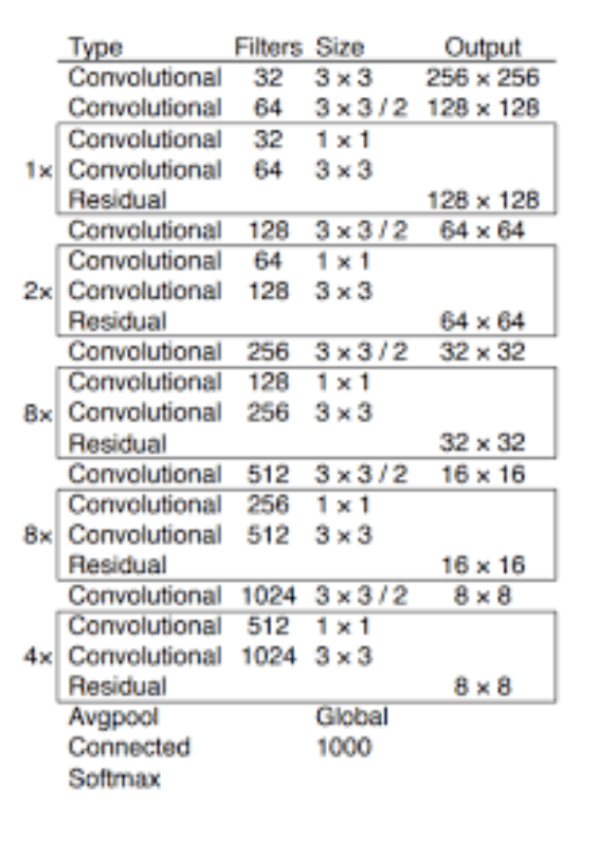
Residual이라는 글자가 보이는데, 이는 잔차 학습(Short-cut connection block or bottleneckCSP)을 말하는 것이다.
이는 ResNet에서도 쓰이는데 이건 나중에 포스팅 하겠다..
다시 잔차학습으로 돌아와서 설명을 하자면,
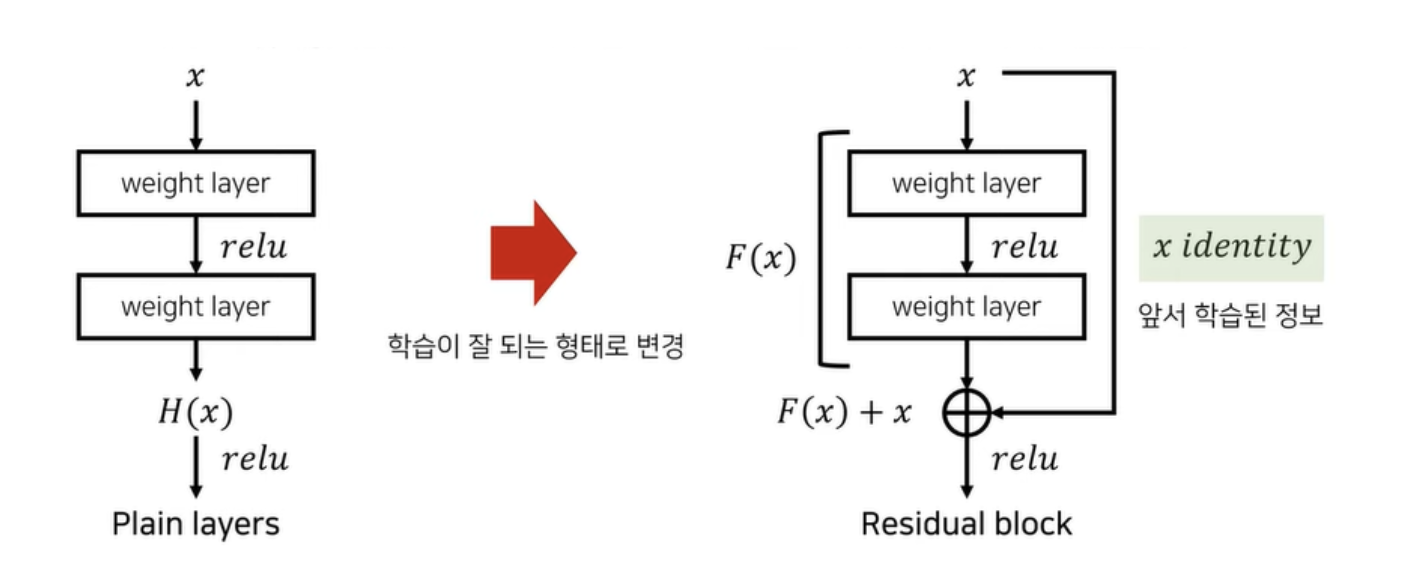
여기서 F(x)는 잔여 정보가 된다.
layer 마다 학습을 해줘야하는 plain layers와는 달리, 잔여 정보만 학습하면 되므로 학습이 쉬워진다. 오른쪽 그림이 하나의 residual block이다.
사실 이것만으로는 이해가 잘 안돼서 다른 사진을 갖고 왔다.
SPP는 spatial pyramid pooling Layer이다.

정말 간단히 말하자면 fully connected layer에 들어갈 수 있게 해주는 것이다.
CNN 아키텍쳐에서 고정된 크기가 필요한 이유는 fully connected layer 때문이다. 이러한 제약에 맞추기 위해서 SPP가 등장하였다.
SPP는 Convolution Layer에서 생성된 feature map을 입력 받고, 각 feature map에 대해 pooling 연산을 하여 고정된 길이의 출력을 만들어 낼 수 있다.
SPP의 작동 방식을 위의 이미지를 예시로 설명해보겠습니다.
Convolution Layer로 부터 feature map을 입력 받는다.
받은 입력을 사전적으로 정해진 영역으로 나눈다. (위 이미지의 경우 4x4, 2x2, 1x1의 세가지 영역을 제공하며, 각각을 하나의 피라미드라고 부른다.)
각 피라미드의 한 칸을 bin이라고 부르며, 각 bin에 대해서 max pooling 연산을 적용한다.
max pooling의 결과를 이어 붙여 출력으로 내봅니다.
입력(feature map)의 크기가 k, bin의 개수를 M이라고 한다면 SPP의 최종 출력은 kM차원의 벡터이다.
즉, 입력의 크기에 상관없이 사전에 설정한 bin의 개수와 채널값으로 SPP의 출력이 정해지기에 항상 동일한 크기의 출력을 생성한다고 할 수 있다.
neck
neck은 backbone에서 뽑아낸 특징을 정제하고, 서로 다른 크기의 feature map을 조합하거나 변형해 head에 넣기 좋은 형태로 만든다.
yolov5에선 PANet이 사용되었다.
head
Head는 추출된 Feature map을 바탕으로 물체의 위치를 찾는 부분이다.
Anchor Box(Default Box)를 처음에 설정하고 이를 이용하여 최종적인 Bounding Box를 생성하는데 다음 사진으로 보면 이해가 잘 될 것이다.

어쩌다보니 backbone에만 집중해버린 글이 나와버렸다..
틀리게 써놓은 정보가 있을 수도 있으니 필자를 100% 믿지 말 것..
