
데이터베이스
✏️ 데이터베이스에 대해 설명해주세요
데이터베이스와 데이터베이스 시스템
데이터베이스(DB)는 체계적으로 조직된 데이터(자료)의 집합체로, 데이터베이스 시스템은 특정 목적을 위해 데이터를 효율적으로 저장하고 관리할 수 있는 시스템이다. 방대한 데이터를 체계적으로 저장, 관리, 검색, 갱신, 삭제할 수 있도록 도와주는 필수적인 기술이다.
데이터베이스의 필요성
💿 파일 시스템 vs 데이터베이스 시스템
- 데이터 구조 차이
- 파일 시스템은 데이터를 파일 단위로 저장하지만, 데이터베이스는 데이터를 구조화된 형태로 저장한다.
- 데이터 중복, 데이터 불일치
- 파일 시스템의 경우 응용 프로그램 별로 독립된 파일을 가지므로 데이터의 중복 저장이 불가피하고 이로 인해 데이터 값의 불일치가 발생한다. 데이터베이스는 무결성 제약조건을 통해 중복을 피할 수 있으며 일관성 있게 유지될 수 있다.
-
보안 문제
파일 시스템의 경우 일부 유저에게 접근을 제한하는 것이 어렵다. 데이터베이스의 경우, 사용자를 식별하고 사용자별 세분화된 권한을 부여하기 위한 인증 및 권한 부여 매커니즘을 가지고 있다. -
성능과 속도
파일 시스템의 경우 각각의 작업마다 새로운 프로그램이 필요하기 때문에 필요한 데이터를 편리하고 효율적으로 검색하기 어렵다. 또, 대량의 데이터를 다루기엔 파일 관리와 성능을 보장하긴 어렵다.
데이터베이스의 경우 대량의 데이터를 처리할 때 효과적이고, 복잡한 연산과 쿼리를 실행 할 수 있다.
데이터베이스 특징
데이터
-
통합된 데이터 (Integrated Data)
여러 가지 데이터를 통합할 때 존재하는 중복된 정보에 대해서 데이터를 통합하여 자료의 중복을 최소화한 데이터들의 모임 -
저장된 데이터 (Stored Data)
컴퓨터 시스템이 직접 접근 가능한 저장 매체에 데이터를 저장한다. -
운영 데이터 (Operational Data)
주로 조직의 목적을 위해 존재하고 활용되는 운영 데이터를 다루는 데 이용된다. -
공유 데이터 (Shared Data)
여러 사람들이 공유하고 사용할 목적으로 통합 관리되는 데이터
기능
-
실시간 접근성 (Real-Time Accessibility)
데이터베이스는 사용자의 요구에 신속하고 정확하게 응답이 가능해야 한다. -
계속적인 변화 (Continuous Evolution)
현실세계의 변화를 계속적으로 반영하기 위해 데이터의 삽입(Insert), 삭제(Delete), 갱신(Update)로 항상 최신의 데이터를 유지한다. -
동시 공용 (Concurrent Sharing)
다수의 사용자가 동시에 같은 내용의 데이터에 접근할 수 있어야 한다. -
내용에 의한 참조 (Content Reference)
데이터베이스의 데이터를 참조할 때 사용자의 요구에 따른 데이터의 내용으로 데이터의 위치나 주소로 데이터를 찾는다.
즉, 데이터베이스는 실시간으로 다수의 사용자가 동시에 공유하는 데이터를 내용에 따른 참조로 조회하고 변화시킬 수 있어야 한다.
데이터베이스 종류
- 관계형 데이터베이스 (Relational Database)
: 데이터를 행과 열로 이루어진 테이블 형식으로 표현하고, 데이터와 데이터 간의 관계를 정의하는 구조를 가지고 있다. SQL(Structured Query Language)을 사용하여 데이터를 다룰 수 있다.
- Oracle, MySQL, MariaDB, PostgreSQL
- NoSQL 데이터베이스 (Not Only SQL Database)
: 비관계형 데이터베이스로, 전통적인 관계형 데이터베이스의 테이블 기반 구조를 사용하지 않고, 다양한 데이터 모델(문서, 키-값, 그래프 등)을 사용하며, 비정형/반정형 데이터를 유연하게 처리할 수 있다.
- MongoDB, Redis
- 객체지향 데이터베이스 (Object-Oriented Database)
: 데이터를 객체로 표현하는 데이터베이스로, 객체지향 프로그래밍의 개념을 데이터베이스에 적용한 시스템이다.
- ObjectStore, ZODB
- 분산 데이터베이스 (Distributed Database)
: 하나의 데이터베이스 관리 시스템(DBMS)이 여러 CPU에 연결된 저장장치들을 제어하는 형태의 데이터베이스로, 여러 네트워크에 분산된 데이터베이스를 하나의 통합된 시스템처럼 관리하는 데이터베이스이다. 분산 데이터베이스는 클라우드 환경에서 자주 사용된다.
- cassandra, amazon DynamoDB
DBMS (데이터베이스 관리 시스템, Database Management System)
컴퓨터의 시스템에서 데이터베이스를 관리하고 조작하는 소프트웨어로, 데이터의 저장, 검색, 갱신, 삭제 등의 작업을 수행한다.
RDBMS (관계형 데이터베이스 관리 시스템)
| 구분 | 이름 | 직책 | 이메일 |
|---|---|---|---|
| 1 | 민수 | 사원 | minzhu@example.com |
| 2 | 주성 | 대리 | zhuxing@example.com |
위와 같이 데이터를 행(Row)과 열(Column)로 구성된 테이블 형태로 저장하며, 테이블 간의 관계를 통해 데이터를 조직한다.
용어
스키마 (Schema)
: 하나의 데이터베이스 내에서 테이블의 구조와 제약 조건을 정하는 설계도로, 데이터베이스의 전반적인 구조를 알 수 있다.
테이블 (Table) 또는 릴레이션 (Relation)
: 데이터를 구조화하고 저장하는 기본 단위
키 (Key)
: 데이터베이스 테이블의 행(Row)을 고유하게 식별하거나 테이블 간의 관계를 정의하는 데 사용되는 식별값
행 (Row) 또는 튜플 (Tuple) 또는 레코드(Record)
: 각 행은 고유한 객체를 나타내며, 데이터를 표시하기 위한 역할을 한다.
열 (Column) 또는 속성 (Attribute)
: 각 열은 데이터의 특정 속성을 나타내며, 속성에 따라 필드에 오는 값이 결정된다.
SQL (구조화 질의 언어)
RDBMS에서 데이터를 정의, 조작, 제어, 검색할 때 사용되는 표준화된 프로그래밍 언어
DDL (데이터 정의 언어)
데이터베이스 구조를 정의하고 수정하는 데 사용되는 명령어 집합이다.
| 명령어 | 기능 |
|---|---|
| CREATE | 새로운 데이터베이스 객체(테이블, 뷰 등)를 생성하는 데 사용 |
| DROP | 기존의 데이터베이스 객체를 삭제 |
| ALTER | 기존 데이터베이스 객체의 구조를 변경 |
| TRUNCATE | 테이블의 모든 데이터를 빠르게 삭제 (구조는 유지) |
DML (데이터 조작 언어)
데이터베이스 내의 데이터를 삽입, 수정, 삭제, 조회하는 데 사용되는 명령어 집합이다.
| 명령어 | 기능 |
|---|---|
| INSERT | 새로운 데이터를 삽입 |
| DELETE | 기존 데이터를 삭제 |
| UPDATE | 기존 데이터를 수정 |
| SELECT | 데이터 조회 |
DCL (데이터 제어 언어)
데이터의 접근 권한과 보안을 관리하는 명령어 집합이다.
| 명령어 | 기능 |
|---|---|
| GRANT | 사용자에게 권환 부여 |
| REVOKE | 사용자에게 부여된 권환 회수 |
TCL (트랜잭션 제어 언어)
데이터베이스에서 트랜잭션을 제어하는 명령어 집합이다.
| 명령어 | 기능 |
|---|---|
| COMMIT | 트랜잭션의 작업을 영구 반영 |
| ROLLBACK | 트랜잭션의 작업을 취소하고 이전 상태로 되돌림 |
| SAVEPOINT | 트랜잭션 내에서 되돌릴 수 있는 지점을 설정 |
SQL
✏️ SQL 실행 과정을 설명해주세요
SQL 처리 과정
SQL 처리 과정을 크게 세 단계로 나눌 수 있다.
1️⃣ SQL 파싱
SQL Parser에 의해 아래와 같은 작업을 수행한다.
| 구분 | 설명 |
|---|---|
| 파싱 트리 생성 | SQL문을 이루는 개별 구성 요소를 분석하여 파싱 트리를 생성한다. |
| Syntax 검사 | 문법적 오류가 없는지 검사 (ex. 사용할 수 없는 키워드를 사용했거나 순서가 바르지 않거나 누락된 키워드가 있는지 확인) |
| Semantic 검사 | 의미적 오류가 없는지 검사 (ex. 존재하지 않는 테이블 또는 컬럼을 사용했는지, 사용한 오브젝트에 대한 권한이 있는지 확인) |
2️⃣ SQL 최적화
SQL 옵티마이저(Optimizer)가 미리 수집한 데이터 딕셔너리(Data Dictionary)에 미리 수집해 둔 오브젝트 통계 및 시스템 통계 정보를 바탕으로 다양한 실행 경로를 생성한 후 가장 효율적인 실행 계획을 선택한다.
SQL 옵티마이저 ❓
SQL 옵티마이저는 사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 엑세스 경로를 선택해주는 DBMS의 핵심적인 엔진이다.
옵티마이저의 최적화 단계
- 사용자로부터 전달받은 쿼리를 수행하는 데 후보군이 될만한 실행 계획을 찾는다.
- 데이터 딕셔너리에 미리 수집해 둔 오브젝트 통계 및 시스템 통계 정보를 이용해 각 실행 계획의 예상 비용을 산정한다.
- 최저 비용을 나타내는 실행 계획을 선택한다.
3️⃣ 로우 소스 생성
SQL 옵티마이저가 선택한 실행 경로를 로우 소스 생성기(Row-Source Generator)가 실제 실행 가능한 코드 또는 프로시저 형태로 포멧팅한다.
실행 계획과 비용
실행 계획 (실행 경로)
실행 계획(Execution Plan)이란, SQL 실행 경로를 미리보는 기능이다. SQL 옵티마이저가 선택한 처리 절차를 사용자가 확인할 수 있게 트리 구조로 표현한다.
비용
쿼리를 수행하는 동안 발생할 것으로 예상되는 I/O 횟수 또는 예상 소요 시간을 표현한 값이다. 실제로 측정한 값이 아닌 옵티마이저가 예측한 값이기 때문에, 실제 비용과 차이가 있을 수 있다.
옵티마이저 힌트
옵티마이저가 보통 최적의 실행 계획을 생성해주지만, 항상 최적인 것은 아니다. SQL이 복잡해질수록 옵티마이저가 실수할 가능성이 높다.
이 때 옵티마이저 힌트를 이용해 효율적인 엑세스 경로를 찾아낼 수 있다.
힌트 사용법
주석 기호에 +를 붙이면 된다.
SELECT /*+ INDEX(A 고객_PK) */
FROM 고객 A
WHERE 고객ID = '0000000008';힌트 목록
MySQL 옵티마이저 힌트 목록은 아래 링크에서 참고할 수 있다.
(MySQL 옵티마이저 힌트 목록)
SQL 공유 및 재사용
소프트 파싱, 하드 파싱
라이브러리 캐시 (Library Cache)란, SQL 파싱, SQL 최적화, 로우 소스 생성 과정을 거쳐 생성한 내부 프로시저를 반복 재사용할 수 있도록 캐싱해 두는 메모리 공간이다.
사용자가 SQL문을 전달하면 DBMS는 SQL파싱을 수행한 후, 해당 SQL이 이 라이브러리 캐시(Library Cache)에 존재하는지부터 확인한다. 캐시에서 찾으면 곧바로 실행 단계로 넘어가는데 이를 소프트 파싱(Soft Parsing)이라고 부른다.
캐시에 저장되어있지 않어 SQL 최적화와 로우 생성 생성 단계까지 모두 거치는 것은 하드 파싱(Hard Parsing)이라고 부른다. 하드 파싱은 CPU를 많이 소비하는 작업이기 때문에, 이렇게 어려운 작업을 거쳐 생성한 내부 프로시저를 한 번만 사용하고 버리는 것은 매우 비효율적이다. 그렇기 때문에 라이브러리 캐시의 역할은 아주 중요하다.
바인드 변수의 중요성
이름없는 SQL
SQL은 따로 이름이 없고, SQL 자체가 SQL를 식별할 수 있는 이름이 되기 때문에 아주 작은 부분이라도 수정되면 그 순간 다른 객체가 새로 탄생하는 구조다. DBMS에서 수행되는 일회성 SQL 또는 무효화된 SQL까지 모두 저장하려면 많은 메모리 공간이 필요하고, 그만큼 SQL를 찾는 속도도 느려지기 때문에 DBMS가 SQL를 영구 저장하지 않는다.
공유 가능 SQL
라이브러리 캐시(Library Cache)에서 SQL을 찾기 위해 사용하는 키 값이 'SQL문' 그 자체이다. 아래의 SQL은 모두 의미적으로는 같지만, 다른 SQL로 인식하기 때문에 실행할 때 각각 최적화를 진행하고 라이브러리 캐시에서 별도 공간을 사용한다.
SELECT * FROM emp WHERE empno = 7900;
select * from EMP where EMPNO = 7900;
select * from emp where empno = 7900;
select * from emp where empno = 7900 ;
select * from scott.emp where empno = 7900 ;
select /* comment */ * from emp where empno = 7900;
select /*+first_rows */ * from emp where empno = 7900;따라서 반복적인 쿼리에 바인드 변수를 사용하면 SQL에 대한 하드 파싱은 최초 한 번만 일어나고, 캐싱된 SQL을 여러 사용자가 공유하면서 재사용할 것이다.
바인드 변수
바인드 변수란, SQL 쿼리문에서 WHERE 절에 value 값으로 사용하는 변수로, 호스트 환경에서 생성되어 데이터를 저장한다.
예시
select * from user where id = 1;위와 같은 SQL문이 있고, 시스템에서 id를 입력받아 매번 각 id에 대해 쿼리를 실행한다고 가정하자.
Connection con = null;
Statement stmt = null;
String query = "select * from user where id = " + id;
stmt = con.createStatement(stmt);
ResultSet rs = stmt.executeQuery();위와 같이 코딩하면 아래와 같은 SQL문이 DBMS에 개별적으로 들어간다.
select * from user where id = 1;
select * from user where id = 2;
select * from user where id = 3;
select * from user where id = 4;
select * from user where id = 5;위의 모든 쿼리문이 다른 쿼리문으로 처리되어 하드 파싱되고, 이는 CPU를 많이 사용하게 된다.
그래서 아래와 같이 ?와 같은 바인드 변수를 사용하여 쿼리문을 짤 수 있다. 그럼 아래와 같은 sql문으로 치환된다.
select * from user where id = ?;
//
select * from user where id = :id_val;자바의 경우 아래와 같이 PreparedStatement를 사용하여 이 쿼리를 실행할 수 있다.
String query = "select * from user where id = ?";
PreparedStatement pstmt = con.prepareStatment(query);
pstmt.setInt(1, id);이렇게 되면 DBMS에는 하나의 쿼리인 select * from user where id = ?만 들어가고, DBMS는 이 쿼리를 한 번만 하드 파싱하여 실행 계획을 생성하고, 그 이후 같은 쿼리 구조는 소프트 파싱으로 처리한다.
Key
✏️ key에 대해 설명해주세요
Key 종류
-
슈퍼키 (Super Key) : 유일성을 만족하는 키
-
복합키 (Composite Key) : 2개 이상의 속성을 포함하는 키
-
후보키 (Candidate Key) : 유일성과 최소성을 만족하는 키. 기본키가 될 수 있는 후보이기 때문에 후보키라고 불린다.
-
기본키 (Primary Key) : 후보키 중 선택된 키. NULL이 들어갈 수 없다.
-
대체키 (Alternate Key) : 후보키 중 기본키로 선택되지 않은 키
-
외래 키 (Foreign Key) : 어떤 테이블에서 다른 테이블의 기본 키를 참조하는 속성이다.
슈퍼키 (Super Key)
테이블 내의 모든 튜플(행)을 고유하게 식별할 수 있게 하는 속성들의 집합
| 학번 | 주민번호 | 이름 | 전화번호 |
|---|---|---|---|
| 202301 | 990101-1234567 | 김민수 | 010-1234-5678 |
| 202302 | 990202-2345678 | 이주성 | 010-5678-1234 |
슈퍼키
-
학번 -
주민번호 -
학번 + 이름 -
학번 + 전화번호 -
유일성을 만족한다.
유일성 (Uniqueness)
키가 테이블의 각 튜플(행)을 중복 없이 구분할 수 있어야 한다.
후보키 (Candidate Key)
테이블에서 각 행(Row)을 고유하게 식별할 수 있는 속성(또는 속성들의 집합) 중에서 유일성과 최소성을 동시에 만족하는 키
후보키
학번주민번호
최소성 (Minimality)
꼭 필요한 속성만 포함해야 하며, 속성을 더 제거하면 유일성을 잃게 된다.
기본키 (Primary Key)
후보키들 중에서 실제로 선택된 대표 키로, 유일성과 최소성을 모두 만족하는 키이다.
- 테이블에서 오직 1개만 지정할 수 있다.
- 기본키는 NULL이 될 수 없고, 중복된 값을 가질 수 없다.
유니크 키 (Unique Key)
테이블 내의 특정 열 또는 열들의 조합이 중복되지 않는 값을 갖도록 보장하는 제약 조건
- 중복된 값을 가질 수 없다.
- NULL 값을 가질 수 있다.
- 하나의 테이블에서 여러 개의 유니크 키를 설정할 수 있다.
- 컬럼의 고유성을 보장하기 위한 조건키
대체키 (Alternate Key)
후보키 중 기본키로 선택되지 않은 나머지 키로, 기본키는 아니지만 여전히 유일성과 최소성을 갖는 잠재적인 기본키
- 기본키가 없어지게 되면 대체키가 기본치를 대체할 수 있다.
즉, 기본키로 학번이 설정되면, 주민번호가 대체키이다.
외래키 (Foreign Key)
다른 테이블의 기본키를 참조하는 키로, 두 테이블(Relation)들 간의 관계를 정의할 때 사용한다.
- 참조되는 테이블이 먼저 만들어지고, 참조하는 테이블에 값이 입력된다.
- 부모 테이블이 삭제되면 자식 테이블은 참조하는 테이블이 삭제되어 외래키 오류가 생길 수 있다. 그렇기 때문에 외래키 관계에서 부모 테이블을 삭제하려면 자식 테이블을 먼저 삭제한 후 부모 테이블을 삭제해야 한다.
복합키 (Composite Key)
단일 열만으로는 테이블 내의 행(튜플)을 유일하게 식별할 수 없을 때 유일성을 만족시키도록 속성을 조합한 키
개별 열의 중복은 허용되지만, 결합된 기본키는 중복될 수 없다. (속성이 2개 이상으로 이루어진 기본키)
- 유일성과 최소성을 보장한다.
- 복합키를 구성하는 열 중 하나라도 NULL 값을 가질 수 없다.
Join
✏️ Join 연산에 대해 설명해주세요
JOIN
관계형 데이터베이스에서 두 개 이상의 테이블을 연결해서 데이터를 조회할 때 사용하는 SQL 연산자
🔗 JOIN의 종류 정리
| JOIN 종류 | 설명 | 키워드 |
|---|---|---|
| INNER JOIN | 두 테이블에서 공통된 값이 있는 경우만 반환 | INNER JOIN 또는 JOIN |
| LEFT OUTER JOIN | 왼쪽 테이블의 모든 행과 일치하는 오른쪽 테이블의 값을 반환 (일치하는 값이 없을 경우 NULL표시) | LEFT JOIN |
| RIGHT OUTER JOIN | 오른쪽 테이블의 모든 행과 일치하는 왼쪽 테이블의 값을 반환 (일치하는 값이 없을 경우 NULL표시) | RIGHT JOIN |
| FULL OUTER JOIN | 양쪽 테이블의 모든 행과 일치하지 않는 값은 NULL로 표시 | FULL JOIN (MySQL에서는 UNION으로 구현) |
| CROSS JOIN | 두 테이블의 모든 조합 (곱집합) | CROSS JOIN |
| SELF JOIN | 하나의 테이블을 자기 자신과 조인 (계층 구조 등에서 사용) | JOIN (자기 자신과, AS 별칭 필수) |
| NATURAL JOIN | 같은 이름의 컬럼을 기준으로 자동 조인 (조건 생략, 공통 컬럼 자동 인식) | NATURAL JOIN |
각각의 JOIN 예시 + 설명
사용할 데이터베이스
🧑💼 employees 테이블 (직원 정보)
| emp_id | name | dept_id |
|---|---|---|
| 1 | 민수 | 10 |
| 2 | 지은 | 20 |
| 3 | 현우 | NULL |
| 4 | 나래 | 30 |
🏢 departments 테이블 (부서 정보)
| dept_id | dept_name |
|---|---|
| 10 | 인사부 |
| 20 | 개발부 |
| 40 | 마케팅부 |
1️⃣ INNER JOIN
✅ 개념
두 테이블 간 일치하는 조건의 데이터만 추출하는 조인
🔍 작동 방식
ON 조건에 맞는 데이터만 결과로 출력됨
조건이 맞지 않으면 해당 행은 결과에서 제외
📌 언제 사용하나?
양쪽에 모두 데이터가 있을 때만 의미가 있을 경우
외래키로 연결된 테이블 간 데이터 조회 시
SELECT e.name, d.dept_name
FROM employees e
INNER JOIN departments d ON e.dept_id = d.dept_id;| name | dept_name |
|---|---|
| 민수 | 인사부 |
| 지은 | 개발부 |
결과
공통된 dept_id가 있는 경우만 결과에 나온다. (NULL, 불일치 제외)
2️⃣ LEFT OUTER JOIN
✅ 개념
왼쪽(기준) 테이블의 모든 행을 출력하고, 오른쪽 테이블에서 조건이 맞는 데이터만 매칭해서 조인
🔍 작동 방식
일치하는 않는 오른쪽 테이블 행은 NULL로 채워진다.
SELECT e.name, d.dept_name
FROM employees e
LEFT JOIN departments d ON e.dept_id = d.dept_id;| name | dept_name |
|---|---|
| 민수 | 인사부 |
| 지은 | 개발부 |
| 현우 | NULL |
| 나래 | NULL |
결과
employees의 모든 행이 유지되고, 일치하지 않는 부서는 NULL
3️⃣ RIGHT OUTER JOIN
✅ 개념
오른쪽(기준) 테이블의 모든 행을 출력하고, 왼쪽 테이블에서 조건이 맞는 데이터만 매칭해서 조인
🔍 작동 방식
일치하지 않는 왼쪽 테이블 행은 NULL로 채워진다.
SELECT e.name, d.dept_name
FROM employees e
RIGHT JOIN departments d ON e.dept_id = d.dept_id;| name | dept_name |
|---|---|
| 민수 | 인사부 |
| 지은 | 개발부 |
| NULL | 마케팅부 |
결과
departments의 모든 행이 유지되고, 일치하지 않는 직원들은 NULL
4️⃣ FULL OUTER JOIN
✅ 개념
양쪽 테이블의 모든 행을 포함한다.
→ 조건이 일치하면 병합, 안 맞으면 NULL 로 채워진다.
🔍 작동 방식
조건이 일치하면 병합, 조건이 일치하지 않으면 한 쪽은 데이터, 다른 쪽은 NULL로 채워진다.
MySQL에서는 FULL OUTER JOIN을 지원하지 않기 때문에 LEFT OUTER JOIN 과 RIGHT OUTER JOIN 의 결과를 UNION을 이용하여 나타낼 수 있다.
여기서 UNION은 중복된 결과를 제거하지만, 중복된 결과도 필요하다면 UNION ALL을 사용할 수 있다.
SELECT e.name, d.dept_name
FROM employees e
LEFT OUTER JOIN departments d ON e.dept_id = d.dept_id;
UNION
SELECT e.name, d.dept_name
FROM employees e
RIGHT OUTER JOIN departments d ON e.dept_id = d.dept_id;
// FULL OUTER JOIN을 지원하는 RDBMS
SELECT e.name, d.dept_name
FROM employees e
FULL OUTER JOIN departments d ON e.dept_id = d.dept_id;| name | dept_name |
|---|---|
| 민수 | 인사부 |
| 지은 | 개발부 |
| 현우 | NULL |
| 나래 | NULL |
| NULL | 마케팅부 |
결과
employees, departments 양 쪽 테이블의 모든 행을 포함하고, 일치하지 않는 부분은 NULL
5️⃣ CROSS JOIN
✅ 개념
두 테이블의 모든 행을 곱집합으로 결합한다. (카티션 곱)
🔍 작동 방식
A 테이블에 3행, B 테이블에 4행 → 결과는 3×4 = 12행
조건 없음 (그냥 전부 조합)
SELECT e.name, d.dept_name
FROM employees e
CROSS JOIN departments d;| name | dept_name |
|---|---|
| 민수 | 인사부 |
| 민수 | 개발부 |
| 민수 | 마케팅부 |
| 지은 | 인사부 |
| 지은 | 개발부 |
| 지은 | 마케팅부 |
| 현우 | 인사부 |
| 현우 | 개발부 |
| 현우 | 마케팅부 |
| 나래 | 인사부 |
| 나래 | 개발부 |
| 나래 | 마케팅부 |
결과
employees, departments 두 테이블의 모든 조합을 반환 (곱집합)
6️⃣ SELF JOIN
✅ 개념
자기 자신과 조인하는 방식이다.
→ 하나의 테이블을 두 개처럼 사용하며, JOIN을 사용한다.
🔍 작동 방식
같은 테이블을 별칭으로 구분해서 사용한다.
보통 계층 구조(상사-직원, 카테고리-상위카테고리)에 사용된다.
예를 들어, employees 테이블에 직원의 상사가 있는 구조라고 가정해보자.
employees에 상사 컬럼을 추가 하면 다음과 같다.
| emp_id | name | manager_id |
|---|---|---|
| 1 | 민수 | NULL |
| 2 | 지은 | 1 |
| 3 | 현우 | 1 |
| 4 | 나래 | 2 |
그리고, 직원의 상사를 찾고 싶을 때 다음과 같은 sql을 실행할 수 있다.
SELECT e.name AS 직원, m.name AS 상사
FROM employees e
JOIN employees m ON e.manager_id = m.emp_id;| 직원 | 상사 |
|---|---|
| 지은 | 민수 |
| 현우 | 민수 |
| 나래 | 지은 |
결과
같은 테이블을 두 번 사용해서 자기 자신과 조인한 경우
7️⃣ NATURAL JOIN
✅ 개념
두 테이블 간 같은 이름의 컬럼을 기준으로 자동 조인
→ ON 없이도 동작
🔍 작동 방식
공통된 이름의 컬럼을 찾고, 자동으로 ON A.컬럼 = B.컬럼 조건 적용한다.
중복된 컬럼은 한 번만 출력된다.
현재의 DB의 경우, employees와 departments 모두 dept_id라는 같은 이름의 컬럼이 있으므로 NATURAL JOIN이 가능하다.
SELECT name, dept_name
FROM employees
NATURAL JOIN departments;| name | dept_name |
|---|---|
| 민수 | 인사부 |
| 지은 | 개발부 |
결과
같은 이름의 컬럼 dept_id로 자동 조인되며 ON 조건은 생략 가능하다.
그림으로 JOIN 표현
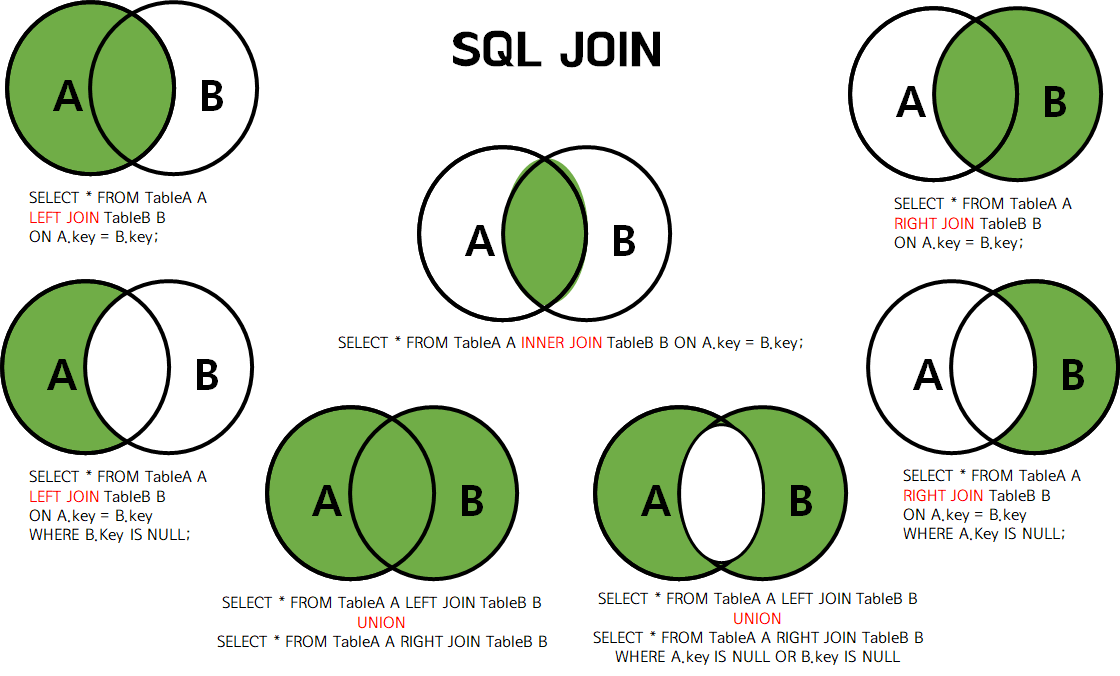
정규화 (Normalization)
✏️ 정규화에 대해 설명해주세요
정규화
정규화(Normalization)는 데이터 중복을 제거하고, 데이터의 무결성을 유지하며, 이상(anomaly)을 방지하기 위해 데이터베이스의 구조를 체계적으로 분해하는 과정이다.
정규화 목적
- 데이터 중복 최소화 : 같은 정보가 여러 테이블에 저장되지 않도록 하여 테이블 불일치 위험을 최소화한다.
- 무결성 유지 : 데이터를 삽입, 수정, 삭제할 때 오류 발생 가능성을 줄인다.
- 일관성 유지 : 데이터 변경 시 전체 테이블에 영향을 미치지 않도록 데이터 구조의 일관성을 최대화한다.
- 관리 효율성 : 구조가 명확해지고, 유지보수가 쉬워진다.
정규화의 단점
- JOIN 연산 증가 : 데이터를 나눠 놓았기 때문에 복잡한 조회가 필요할 때 여러 테이블을 조인해야 한다.
- 성능 저하 : 다수의 조인으로 인해 속도가 느려질 수 있다.
- 설계 복잡도 증가 : 테이블이 너무 작게 나뉘면 구조가 복잡해지고 개발이 어려울 수 있다.
- 과도한 정규화로 인한 과잉 설계 : 이론상으로는 완벽하지만, 현실과 맞지 않거나 실용적이지 않은 구조가 될 수 있다.
이상 현상 (Anomalies)
| 종류 | 설명 |
|---|---|
| 삽입 이상 (Insertion Anomaly) | 일부 정보만 입력하려 해도 전체 정보가 필요해서 입력 못함 |
| 삭제 이상 (Deletion Anomaly) | 하나의 정보 삭제 시 관련 없는 정보도 같이 사라짐 |
| 갱신 이상 (Update Anomaly) | 중복 데이터의 일부만 수정되면 데이터 불일치 발생 |
함수 종속 (Functional Dependency)
함수 종속이란, 어떤 속성 A의 값이 주어졌을 때, 속성 B의 값이 항상 하나로 결정되는 경우를 의미한다.
정규화 단계별 설명
1️⃣ 제1정규형 (1NF) - 원자성 (Atomicity)
각 칼럼은 더 이상 분해할 수 없는 단일 값(원자값)만을 가져야 한다.
✅ 특징
- 반복되는 속성을 제거한다.
- 테이블에 중첩된 값, 리스트 형태의 값을 가지지 않는다.
💡 예시 (정규화 전)
| 학생ID | 이름 | 수강과목 |
|---|---|---|
| 1 | 철수 | 수학, 과학 |
| 2 | 영희 | 영어 |
📘 정규화 후
| 학생ID | 이름 | 수강과목 |
|---|---|---|
| 1 | 철수 | 수학 |
| 1 | 철수 | 과학 |
| 2 | 영희 | 영어 |
2️⃣ 제2정규형 (2NF) - 부분 함수 종속 제거
부분 함수 종속을 제거한다. (완전 함수 종속 관계)
✅ 특징
- 제 1정규형을 만족해야 한다.
- 모든 컬럼이 부분적 종속이 없어야 한다. 즉, 모든 컬럼이 완전 함수 종속을 만족해야 한다.
❓ 부분 함수 종속 (Partial Functional Dependency) & 완전 함수 종속 (Full Functional Dependency)
부분 함수 종속 : 기본키의 일부 속성에만 의존하는 것을 말한다.
완전 함수 종속 : 기본키의 부분집합이 결정자가 되어서는 안된다.
💡 예시 (정규화 전)
| 학생ID | 이름 | 교수이름 |
|---|---|---|
| 1 | 수학 | 김교수 |
| 1 | 과학 | 박교수 |
- PK : {학생ID, 이름}
- {학생ID, 이름} -> {교수이름}
- {이름} -> {교수이름}
=> Partial dependency가 존재한다 !
📘 정규화 후
| 학생ID | 과목 |
|---|---|
| 1 | 수학 |
| 1 | 과학 |
| 과목 | 교수이름 |
|---|---|
| 수학 | 김교수 |
| 과학 | 박교수 |
3️⃣ 제3정규형 (3NF) – 이행 함수 종속 제거
기본키가 아닌 속성이 또 다른 비기본키에 종속되는 것을 제거한다.
✅ 특징
- 제2정규형을 만족해야 한다.
- 기본키를 제외한 속성들 간의 이행 종속성 (Transitive Dependency)이 없어야 한다.
❓ 이행 함수 종속 (Transitive Functional Dependency)
A->B, B->C 일 때, A->C를 만족하면 이행 함수 종속이라고 한다.
💡 예시 (정규화 전)
| 학생ID | 이름 | 학과코드 | 학과이름 |
|---|---|---|---|
| 1 | 철수 | C01 | 컴퓨터공학과 |
| 2 | 영희 | M01 | 기계공학과 |
- PK : {학생ID}
- {학생ID} -> {학과코드}, {학과코드} -> {학과이름} => {학생ID} -> {학과이름}
=> Transitive Dependency가 존재한다 !
📘 정규화 후
| 학생ID | 이름 | 학과코드 |
|---|---|---|
| 1 | 철수 | C01 |
| 2 | 영희 | M01 |
| 학과코드 | 학과이름 |
|---|---|
| C01 | 컴퓨터공학과 |
| M01 | 기계공학과 |
✚ BCNF (보이스-코드 정규형, Boyce-Codd Normal Form)
모든 결정자가 후보키가 되도록 테이블을 분해하는 정규형이다.
✅ 특징
- 제3정규형을 만족해야 한다.
- 테이블의 존재하는 모든 함수 종속 관계에서, 결정자(왼쪽에 오는 속성)가 반드시 후보키여야 한다.
💡 예시 (정규화 전)
| 과목 | 교수 | 강의실 |
|---|---|---|
| 자료구조 | 김교수 | 101호 |
| 운영체제 | 이교수 | 102호 |
| 알고리즘 | 김교수 | 101호 |
| 컴퓨터네트워크 | 박교수 | 103호 |
- PK : {과목}
- {과목} -> {교수}
- {교수} -> {강의실}, 하지만 교수는 후보키가 아니다 !
📘 정규화 후
| 교수 | 강의실 |
|---|---|
| 김교수 | 101호 |
| 이교수 | 102호 |
| 박교수 | 103호 |
| 과목 | 교수 |
|---|---|
| 자료구조 | 김교수 |
| 운영체제 | 이교수 |
| 알고리즘 | 김교수 |
| 컴퓨터네트워크 | 박교수 |
4️⃣ 제4정규형 (4NF) – 다치 종속 제거
하나의 키가 여러 개의 독립적인 다중 값을 가질 때 분리한다.
✅ 특징
- BNCF을 만족해야 한다.
- 다치 종속(Multi-valued Dependency)이 없어야 한다.
❓ 다치 종속 (Multi-valued Dependency)
하나의 속성이 두 개 이상의 독립적인 다중 값을 가질 때 발생하는 종속성이다.
즉, A->B인 의존성에서 단일 값 A와 다중 값 B가 존재한다면 다치 종속이라고 할 수 있다. 이러한 종속을 A↠B로 표기한다.
더 쉽게 말하자면, 하나의 키가 있을 때,
-> 이 키에 대해 여러 개의 B 값도 있고
-> 여러 개의 C 값도 있는데
-> B 값과 C 값은 서로 아무 상관도 없는 독립적인 정보일 때
💡 예시 (정규화 전)
| 교수ID | 강의과목 | 연구분야 |
|---|---|---|
| P01 | DB | AI |
| P01 | OS | ML |
- 하나의
교수ID의 키가 있는데,
-> 이 키에 대해 여러 개의강의과목값도 있고, (DB, OS)
-> 여러 개의연구분야값도 있는데 (AI, ML)
->강의과목과연구분야는 서로 독립적인 속성이다.
=> 다치 종속이 존재한다 !
📘 정규화 후
| 교수ID | 강의과목 |
|---|---|
| P01 | DB |
| P01 | OS |
| 교수ID | 연구분야 |
|---|---|
| P01 | AI |
| P01 | ML |
5️⃣ 제5정규형 (5NF) – 조인 종속 제거
조인한 결과가 원래 테이블과 동일하지 않거나 정보 손실이 생기는 경우 분해가 필요하다.
모든 조인 종속이 후보키에 의해 발생하는 경우 제5정규형에 속한다.
✅ 특징
- 제4정규형을 만족해야 한다.
- 후보키에 의해 유도되지 않는 조인 종속을 제거해야 한다. 즉, 테이블이 조인 종속에 의해 분해되지 않아야 하며, 조인에 의한 정보 손실이 없는 상태여야 한다.
❓ 조인 종속 (Joint Dependency)
하나의 릴레이션을 여러 개의 릴레이션으로 분해했다가 다시 조인했을 때, 데이터 중복이나 손실 없이 동일한 원래의 릴레이션이 나와야 한다.
- 모든 조인 종속성을 제거한다는 게 더 나눌 수 있는 경우가 있을 때라고 이해하니까 좀 이해가 잘된다..!
- 정규화 자체가 더 분해하는 게 포인트니까, 여러 테이블로 나누고 합쳤을 때 같은 테이블로 만들 수 있는 경우의 수가 있다면 (그게 조인 종속이 있는 것!) 나눠라!
💼 실무 적용
3NF까지만 해도 대부분의 중복과 이상 현상이 제거되기 때문에 보통 3정규형(3NF)까지만 하는 경우가 많다.
또, 성능 개선 목적으로 역정규화를 하기도 한다.
역정규화 (De-Normalization)
정규화된 테이블을 다시 통합하거나 중복을 일부 허용하여, 조회 성능이나 사용 편의성을 높이는 작업
