
static
✏️static에 대해 설명해주세요(장점, 단점 등)
1) Java의 non-static 멤버와 static 멤버의 차이를 시간, 공간, 공유의 관점에서 설명해주세요
2) Java의 main 메서드가 static인 이유를 설명해주세요
static
static: 자바 언어 예약어로 클래스(정적) 필드, 크래스(정적) 메서드를 지정할 때 사용한다. static 필드와 메서드를 static 멤버 혹은 클래스 멤버라고 부른다.
특징
- Static 영역에 할당된 메모리는 모든 객체가 공유하여 하나의 멤버를 어디서든지 참조할 수 있다.
- Garbage Collector(GC)의 관리 영역 밖에 존재하기 때문에 Static 영역에 있는 멤버들은 프로그램의 종료 시까지 메모리가 할당된 채로 존재한다.
메모리 저장 위치
Static 멤버는 클래스 로드에 클래스를 로딩해서 Method 메모리 영역에 적재할 때 클래스별로 관리된다. 따라서, 클래스 로딩 후 바로 사용이 가능하다.
Method 영역은 Static 영역, Class 영역이라고도 부른다.
장점
Static이 메모리 측면에서 효율적일 수 있다.
Static영역에 저장되어 고정된 메모리 영역을 사용하기 때문에 매번 인스턴스를 생성하며 낭비되는 메모리를 줄일 수 있다.- 객체를 생성하지 않고 사용할 수 있기 때문에 속도가 빠르다. 클래스가 메모리에 적재되는 시점에 생성되어 바로 사용이 가능하기 때문에 속도면에서 이점을 가진다.
단점
-
메모리 관리 문제
우리가 만든 Class는 프로그램 실행 시 Static 영역에 생성된다. 위에서 언급했다시피, GC의 관리 대상이 되는 Heap 영역과는 다르게 Static 영역은 GC의 관리를 받지 않는다. 따라서, Static 영역은 프로그램 종료 시까지 메모리에 존재한다. 이로 인해 필요 이상으로 메모리를 차지할 가능성이 있다. 이는 메모리 누수(memory leak)로도 이어질 수 있다. 또한, 대량의 데이터가 저장될 경우 성능 저하를 초래할 수 있다. -
객체 지향적 특성을 해친다. (OOP 위반)
static메서드는 객체가 아닌 클래스에 바인딩되므로 다형성(Polymorphism)과 상속을 활용할 수 없다. 즉, 오버라이딩이 불가능하며 동적 바인딩 대신 정적 바인딩이 적용된다.
정적 바인딩 (Static Binding) 이란?
- 컴파일 타임에 어떤 메서드를 호출할지 결정한다.
static메서드는 클래스에 바인딩이 되므로, 객체의 타입과 관계없이 항상 선언된 클래스의 메서드가 호출된다.- 즉, 오버라이딩이 불가능하고 다형성을 활용할 수 없다.
class Parent { public static void greet() { System.out.println("Hello from Parent"); } } class Child extends Parent { public static void greet() { // 오버라이딩(X), 숨김(Hiding) System.out.println("Hello from Child"); } } public class Main { public static void main(String[] args) { Parent p = new Child(); p.greet(); // 🔹 "Hello from Parent" 출력 (Child의 greet()이 호출되지 않음) } }
-
인터페이스 구현 불가
static메서드는 인터페이스에서 구현할 수 없기 때문에 다형성과 유연성이 떨어진다. -
멀티 스레드 환경에서 동기화 문제
static변수는 모든 객체가 공유하므로, 멀티 스레드 환경에서 동기화를 하지 않으면 데이터 불일치 문제가 발생할 수 있다. -
테스트 및 유지보수 문제
static메서드는 객체의 상태를 유지하지 않으므로 Mocking이 어렵다. 따라서 단위 테스트(Unit Test)가 어려워지고 유지보수가 복잡해질 수 있다.
non-static vs staitc
시간
| static 멤버 | non-static 멤버 | |
|---|---|---|
| 초기화 시점 | - 클래스가 로딩될 때 메모리에 할당됨. - 프로그램 종료 시까지 유지됨. | - 객체 생성 시점에 메모리에 할당됨. - 객체가 존재하는 동안만 유지되고, GC에 의해 제거됨. |
| 생성 타이밍 | - 클래스를 로딩할 때 생성됨. - 클래스의 인스턴스를 생성하지 않고도 사용 가능 | - 클래스의 인스턴스를 생성해야 사용 가능 |
공간
| static 멤버 | non-static 멤버 | |
|---|---|---|
| 메모리 할당 | 클래스당 하나의 메모리 공간만 할당됨. | 객체마다 별도로 메모리 차지 |
| 메모리 위치 | Method 영역에 저장 | Heap 영역에 저장 |
| 메모리 효율 | 많은 객체가 생성되면 메모리 사용량 증가 | 여러 객체가 공유하므로 공간 효율적 |
공유
| static 멤버 | non-static 멤버 | |
|---|---|---|
| 객체별 개별 값 여부 | 모든 객체가 동일한 값 공유 | 객체마다 개별적인 값을 가짐 |
| 공유 여부 | 모든 객체가 공유함. | 객체 간 공유되지 않음. |
| 접근 방식 | 반드시 객체를 생성한 후 접근 | 클래스 이름으로 바로 접근 가능 |
| 변경 시 영향 범위 | 모든 객체가 공유하므로 변경 시 모든 객체에 영향 | 특정 객체의 값만 변경됨 (다른 객체에는 영향 없음) |
main 메서드가 static 인 이유
Java에서
main메서드는 프로그램의 시작점(Entry Point)이며, JVM이 클래스의 객체를 생성하지 않고도 실행할 수 있어야 한다.
1. 객체 생성 없이 JVM이 직접 호출해줄 수 있어야 한다.
main이static이 아니면, JVM이main을 실행하기 위해 객체를 먼저 생성해야 한다.- 객체를 생성하지 않고도 프로그램을 시작할 수 있도록 하기 위해
static으로 선언된다.
2. 불필요한 객체 생성을 방지한다.
- 만약
main이 non-static이면,main을 실행할 때마다 객체를 생성해야 한다. 프로그램이 실행될 때마다 객체가 필요하면 불필요한 메모리 낭비가 발생한다. static을 사용하면 객체 없이도 실행 가능하므로 메모리 효율적이다.
Reflection
✏️ Reflection에 대해 설명해주세요
정의
- 힙 영역에 로드된 Class 타입의 객체를 통해, 구체적인 클래스 타입을 알지 못하더라도 원하는 클래스의 인스턴스를 생성할 수 있도록 지원하고, 인스턴스의 필드와 메서드를 접근 제어자와 상관없이 사용할 수 있도록 지원하는 자바 API
- 로드된 클래스 : JVM 클래스 로드에서 클래스 파일에 대한 로딩을 완료한 후, 해당 클래스의 정보를 담은 Class 타입의 객체를 생성해 메모리의 힙 영역에 저장해둔 것을 의미한다.
- 컴파일 타임이 아닌 런타임에 동적으로 특정 클래스의 정보를 추출할 수 있는 프로그래밍 기법
Reflection 활용 예시
- IDE 자동완성 (자동 Mapping 기능 구현)
- IDE 사용 시 일부 입력된 것과 관련된 클래스 혹은 Method 목록들을 IDE가 먼저 확인하고 사용자에게 제공한다.
- 동적으로 Class를 사용해야 할 경우
- 코드 작성 시점에서는 어떠한 클래스를 사용해야 할지 모르지만 Runtime에 클래스를 가져와서 실행해야 하는 경우 (Spring Annotation)
- Test Code 작성
private변수를 변경하고 싶거나private메서드를 테스트할 경우
- Jackson, GSON 등의 JSON Serialization Library
- Reflection을 사용하여 객체 필드의 변수명/어노테이션명을 Json key와 매핑한다.
- 스프링의 어노테이션
- 어노테이션만 붙였을 뿐인데, 클래스가 컨트롤러로 인식되고, url 매핑까지 자동으로 된다.
어떤 정보를 가져올 수 있을까?
- Class
- Constructor
- Method
- Field
- Annotation
- extends, implements
예시 코드
public class PersonClass {
public static void main(String[] args) throws Exception {
Person persson = new Person();
Class<Person> personClass = Person.class;
// 클래스 이름 불러오기
System.out.println(personClass.getName());
// 생성자 불러오기
System.out.println(personClass.getDeclaredConstructor());
// 메서드 불러오기
System.out.println(personClass.getDeclaredMethod("메서드 이름"));
// 변수 불러오기
System.out.println(personClass.getDeclaredField("name"));
// 변수의 값 불러오기 및 변경하기
Field field = personClass.getDeclaredField("name");
System.out.println(field.get(person));
field.set(person, "민수");
System.out.println(field.get(person)); 장점
- 대량의 if/else 문을 사용하는 것보다 Reflection을 이용하여 재사용 가능한 컴포넌트로 만들 수 있게 하며 확장성을 높여준다.
- Reflection을 통해 메서드, 속성, 생성자를 미리 파악함으로써 사용할 정보를 열거하여 시각적 개발 환경을 구축할 수 있다.
- Java에서 지원하는 라이브러리가 아닌 특정 기업의 라이브러리를 사용하는 경우 해당 라이브러리에 존재하는 클래스 및 메서드를 분석할 수 있다.
단점
private메서드, 변수 접근 가능 문제
→field.setAccessible(true)처럼 접근 true/false 설정이 가능하기 때문에private로 설정해놓은 것도 직접 접근이 가능해진다.
⇒ 추상화와 캡슐화 위반- 컴파일러의 최적화를 받지 못한다.
- 클래스 로더에 있는 Class타입을 쓰기 때문에 성능에도 안 좋다.
- 리플랙션을 계속 사용하면, 새로운 객체를 계속 생성하는 것이기 때문에 비효율적이다.
try-with-resources
✏️ try-with-resource에 대해서 설명해주세요.
resource
외부의 데이터 (DB, Network, File) 를 일컫는다. 이런 resource 들은 자바 내부에 위치한 요소들이 아니기 때문에, 프로세스 외부에 있는 데이터에 자바 코드에서 접근하려고 할 때 문제(예외)가 발생할 수 있는 여지가 존재한다.
- 특히 입출력과 관련된 resource들에서 접근하고 사용한 후 닫는 것이 아주 중요하다.
try-catch를 사용하면 되겠구나! - NO !
FileWriter file = null;
try {
file = new FileWriter("textFile.txt");
file.write("Hello World!");
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
file.close();
}작업 중 예외가 발생하더라도 파일이 닫히도록 finally 블럭에 file.close()를 넣어주었다.
하지만, close() 자체도 IOException 예외가 일어날 수 있기 때문에 예외 처리를 해주어야 한다.
finally {
try {
file.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}이렇게 한 번 더 try-catch문을 써서 예외처리를 해주어야 한다.
-> 가독성이 좋지 않다 ! ❌
try-with-resource
주로 입출력(I/O)과 관련된 클래스를 사용할 때 유용하다. 입출력에 사용한 객체를 자동으로 반환해주기 때문이다.
사용법
try (파일을 열거나 자원을 할당하는 명령문) {
...
}- try 블록에 괄호()를 추가하여 파일을 열거나 자원을 할당하는 명령문을 명시하며, 해당 try 블록이 끝나자마자 자동으로 파일을 닫거나 할당된 자원을 해제해준다.
- 또한, 괄호 안에 명령문 두 개 이상을 넣어줄 수도 있다. 이 때는 세미콜론(;)으로 각 문장을 구분해 주어야 한다.
try-with-resources문을 사용하기 위해서는AutoCloseable인터페이스를 구현해야 한다.
예시
try (FileWriter file = new FileWriter("data.txt")) { // 파일을 열고 모두 사용되면 자동으로 닫아준다
file.write("Hello World");
} catch (IOException e) {
e.printStackTrace();
}
// try 괄호 안에 두문장 이상 넣을 경우 ';'로 구분한다.
try(
FileInputStream fis = new FileInputStream("a.txt");
DataInputStream dis = new DataInputStream(fis)
) {직렬화, 역직렬화
✏️직렬화와 역직렬화에 대해서 설명해주세요.
정의
데이터 직렬화는 메모리를 디스크에 저장하거나, 네트워크 통신에 사용하기 위한 형식으로 변환하는 것이다.
데이터 역직렬화는 디스크에 저장한 데이터를 읽거나, 네트워크 통신으로 받은 데이터를 메모리에 쓸 수 있도록 변환하는 것이다.직렬화는 왜 필요할까?
데이터 자료형 중 참조 자료형은 스택 메모리에 실제 값이 아닌 실제 값이 저장된 힙의 주소값을 저장하고 있다. 그렇기 때문에, 만약 객체 A를 파일에 포함하여 저장했다고 했을 때, 이후 프로그램을 종료하고 다시 실행해서 주소값을 가져왔다고 하더라도 기존 A 객체의 데이터를 가져올 수 없다. 프로그램이 종료되면 기존에 할당되었던 메모리는 해제되고 없어지기 때문이다.
네트워크 통신에서도 마찬가지로 각 PC마다 사용하는 메모리 공간 주소는 전혀 다르고, 다른 PC로 전송한 A 객체 데이터는 무의미하다.
데이터 직렬화 종류
- CSV, XML, JSON 직렬화
- 사람이 읽을 수 있는 형태
- 저장 공간의 효율성이 떨어지고, 파싱하는 데 오래 걸림
- 데이터 양이 적을 때 주로 사용함
- 최근에는 JSON 형태로 데이터를 직렬화 함
- Binary 직렬화
- 사람이 읽을 수 없는 형태
- 저장 공간을 효율적으로 사용할 수 있고, 파싱하는 시간이 빠름
- 데이터 양이 많을 때 주로 사용함
- Java 직렬화
- Java 시스템 간의 데이터 교환이 필요할 때 사용함
Java의 직렬화와 역직렬화
Java 직렬화
자바 시스템 내부에서 사용되는 데이터(객체)를 외부의 자바 시스템에서 사용할 수 있도록 바이트 형태로 데이터를 변환하는 기술이다.
Java 역직렬화
바이트 형태로 변환된 데이터를 다시 객체로 변환하는 기술이다.
직렬화, 역직렬화 구현
Serializable을 구현한 클래스
class Person implements Serializable {
String name;
int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
}- 직렬화가 가능한 클래스를 만들기 위해서는
java.io.Serializable인터페이스를 구현해야 한다. - 혹은
Serializable인터페이스를 구현한 클래스를 상속받으면 된다. - 특정 필드를 직렬화하고 싶지 않은 경우,
transient키워드를 붙일 수 있다.- 그 타입의 기본 값(int = 0, 객체 = null)으로 직렬화된다.
- 만약,
Serializable을 구현하지 않은 객체를 필드 멤버로 가지고 있다면,java.io.InvalidClassException예외가 발생한다.
직렬화 진행
Person person = new Person("김철수", 19);
byte[] serializedPerson;
try (ByteArrayOutputStream baos = new ByteArrayOutputStream()) {
try (ObjectOutputStream oos = new ObjectOutputStream(baos)) {
oos.writeObject(person);
serializedPerson = baos.toByteArray();
}
}
// 바이트 배열로 생성된 직렬화 데이터를 base64로 변환
System.out.println(Base64.getEncoder().encodeToString(serializedPerson));java.io.ObjectOutputStream을 사용하여 직렬화를 진행한다.serializedPerson은 직렬화된 person 객체를 담고있다.
역직렬화 진행
try (ByteArrayInputStream bais = new ByteArrayInputStream(serializedPerson)) {
try (ObjectInputStream ois = new ObjectInputStream(bais)) {
Object objectPerson = ois.readObject();
Person newPerson = (Person) objectPerson;
System.out.println(newPerson);
}
}java.io.ObjectInputStream을 사용하여 역직렬화를 진행한다.
serialVersionUID(SUID)
기존 Person 클래스에 String gender 필드가 추가 되어 클래스 구조에 변화가 생겼다고 가정해보자. 만약 이전에 직렬화해 둔 데이터를 역직렬화하면, java.io.InvalidClassException이 발생한다.
public class Person implements Serializable {
private static final long serialVersionUID = 1L;따라서 위와 같은 serialVersionUID를 명시해줄 수 있다.
새로운 필드가 추가되거나 삭제되는 것을 무시하면서 에러를 일으키지 않지만, 기존에 있던 age가 int 타입에서 long 타입으로 변경되면 다시 에러를 일으킨다.
Java 직렬화의 장점
추가적인 라이브러리 설치 없이 객체 데이터를 영속화시킬 수 있다.
Java 역직렬화의 단점
직렬화 결과물 용량이 상대적으로 커서 비효율적이다.
{"name":"김배민","email":"deliverykim@baemin.com","age":25}
serializedMember (byte size = 146)
json (byte size = 62)위와 같이 아주 간단한 객체의 내용도 2배 이상의 용량 차이가 발생한다.
일반적인 메모리 기반의 Cache에서는 Data를 저장할 수 있는 용량의 한계가 있으므로 json 형태와 같은 경량화된 형태로 직렬화하는 것이 좋다.
Stream
✏️ Stream에 대해 설명해주세요
Java 8부터 추가된 기술로, 람다를 활용해 배열과 컬렉션을 함수형으로 간단하게 처리할 수 있는 기술이다. Stream은 데이터 소스를 추상화하고, 데이터를 다루는 데에 자주 사용되는 메서드를 통해 데이터 소스에 상관없이 모두 같은 방식으로 다룰 수 있어 코드의 재사용성을 높인다.
특징
- 원본 데이터를 변경하지 않고, 읽기만 한다.
- 최종 연산 전까지 중간 연산을 수행하지 않는다.
- 일회용
- 병렬 처리가 쉬워 멀티 스레드에 사용하기 좋다.
Stream<Integer>대신IntStream과 같이 기본형 스트림을 제공하여 오토박싱과 언박싱과 같은 불필요한 과정이 생략되고, 숫자의 경우.sum(),.average()와 같은 유용한 메서드를 추가로 제공한다.
스트림 생성
- 배열 스트림 : Arrays.stream()
String [] arr = new String[]{"a", "b", "c"};
Stream<String> arrStream = Arrays.stream(arr);- 컬렉션 스트림 : .stream()
List<String> list = Arrays.asList("a","b","c");
Stream<String> listStream = list.stream();- Stream.builer()
Stream<String> builderStream = Stream.<String>builder()
.add("a").add("b").add("c")
.build();- 람다식 Stream.generate(), iterate()
Stream<String> generatedStream = Stream.generate(()-> "a").limit(3);
// 생성할 때 스트림의 크기가 정해져있지 않고 무한하기 때문에 최대 크기를 제한해줘야 한다.
Stream<String> iteratedStream = Stream.iterate(0, n-> n+2).limit(5);
// 0,2,4,6,8- 기본 타입형 스트림
IntStream intStream = IntStream.range(1,5); // 1~4까지의 Stream- 병렬 스트림 : parallelStream()
Stream<String> parallelStream = list.parallelStream();병렬 스트림이란 각각의 스레드에서 처리할 수 있도록 스트림 요소를 여러 청크로 분할한 스트림이다. 따라서, 병렬 스트림을 이용하면 추가 연산 시 스레드가 각각의 청크를 처리하도록 할당할 수 있다.
중간 연산
Stream에서 수행되는 연산들로, 다른 Stream을 반환한다. 중간 연산은 연쇄적으로 적용될 수 있다.
filter
조건에 맞는 요소만을 포함하는 Stream을 반환한다. (if문 역할)
람다식의 리턴값은 boolean이고, true인 경우 포함된다.
List<Integer> numList = Arrays.asList(1,2,3,4,5,6,7);
Stream<Integer> stream = numList.stream();
// 짝수 찾기
stream.filter(num -> num % 2 == 0);map()
각 요소를 주어진 함수에 따라 변환하여 새로운 Stream을 반환한다.
List<Integer> numList = Arrays.asList(1,2,3,4,5,6);
Stream<Integer> stream = numList.stream();
stream.map(num -> num + 10);
Stream<String> stream = list.stream()
.map(String::toUpperCase);
stream = stream.map(Integers::parseInt);
// 문자열 -> 정수sorted()
Stream의 값들을 오름차순으로 정렬하며, 인자로 Comperator를 제공하면 해당 객체의 정의된 규칙에 따라 요소들을 정렬하여 새로운 Stream을 반환한다.
List<Integer> numList = Arrays.asList(1,2,3,4,5,6);
Stream<Integer> stream = numList.stream();
stream.sorted();
List<String> list = Arrays.asList("a","aa","aaa");
Stream<String> listStream = list.stream()
.sorted(Comparator.comparingInt(String::length));
// 문자열 길이 기준 정렬 ["aaa","aa","a"] distinct()
중복된 요소를 제거한 후 새로운 Stream을 반환한다.
List<Integer> numList = Arrays.asList(1,2,3,4,5,6);
Stream<Integer> stream = numList.stream();
stream.distinct();이외의 연산
Stream<String> stream = list.stream()
.limit(max) // 최대 크기 제한
.skip(n) // 앞에서부터 n개 skip
.peek(System.out::println); // 중간 작업결과 출력최종연산
최종연산(Terminate Operation)은 Stream의 요소를 처리하여 결과를 반환하거나, 특정 작업을 수행한다. 최종 연산이 호출되면 Stream은 종료되어 더이상 사용할 수 없게 된다.
기본형 스트림 연산
IntStream intStream = list.stream()
.count() // 스트림 요소 개수 반환
.sum() // 스트림 요소의 합 반환
.min() // 스트림 최소값
.max() // 스트림 최대값
.average() // 스트림 평균값forEach()
각 요소에 대해 주어진 동작을 수행하며, 값을 반환하지 않는다.
List<Integer> numList = Arrays.asList(1,2,3,4,5,6);
Stream<Integer> stream = numList.stream();
stream.forEach( num -> System.out.println(num));
stream.forEach(System.out::println);collect()
Stream의 요소를 Collection 타입 혹은 다른 형식으로 반환한다. 대개 중간 연산의 결과물을 Collection (하위)타입으로 반환하는데 사용한다.
List<Integer> numList = Arrays.asList(1,2,3,4,5,6);
Stream<Integer> stream = numList.stream();
stream.collect(Collectors.toList()); // 리스트로 반환
// 중간 연산 후 반환된 Stream을 Collections로 반환
stream.map(num -> num + 10).collect(Collectors.toList());reduce()
Stream의 요소들을 누적하여 단일 결과를 생성한다.
List<Integer> numList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Stream<Integer> stream = numList.stream();
stream.reduce((x,y) -> x+y);
// reduce(초기값(생략 가능), (누적 변수, 요소) -> 수행문)다음과 같은 계산이 수행된다.
==
x = 1
y = 2
x + y = 3
==
x = 3
y = 3
x + y = 6
==
x = 6
y = 4
x + y = 10
==
x = 10
y = 5
x + y = 15
===
result = 15count()
Stream의 요소 개수를 반환한다.
List<Integer> numList = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Stream<Integer> stream = numList.stream();
stream.count();match
특정 조건을 만족하는 요소가 있는지 체크한 결과를 반환한다.
List<String> fruit = Arrays.asList("strawberry", "apple", "grape");
// anyMatch : 하나라도 만족하는 요소가 있는지
// "s"를 포함하는 요소가 있는지
boolean matchResult = fruit.stream()
.anyMatch(fruit -> fruit.contains("s")); // true
// allMatch : 모두 만족하는지
// 모든 요소의 길이가 6 이상인지
boolean matchResult = fruit.stream()
.allMatch(fruit -> fruit.length() >=6); // false
//noneMatch : 모두 만족하지 않는지
// "z"로 끝나는 요소가 하나도 없는지
boolean matchResult = fruit.stream()
.noneMatch(fruit -> fruit.endsWith("z")); // true
find
스트림에서 하나의 요소를 Optional로 반환한다.
조건에 일치하는 요소가 없다면 empty가 반환된다.
Optional<String> foundFruit = fruit.stream()
.filter(s -> s.startsWith("s"))
.findAny();
foundFirst = fruit.stream()
.filter(s -> s.length() == 5)
.findFirst() findAny(): 먼저 찾은 요소 하나 반환, 병렬 스트림의 경우 첫번재 요소가 보장되지 않는다.findFirst(): 첫번째 요소 반환
❓findAny() vs findFirst()
Stream을 직렬로 처리할 때는 두 메서드 모두 동일한 요소를 반환한다. 하지만, Stream을 병렬로 처리할 때는 차이가 생긴다.
findFirst()는 여러 요소가 조건에 부합해도 Stream의 순서를 고려하여 가장 앞에 있는 요소를 반환하는 반면에,findAny()는 멀티 스레드에서 Stream을 처리할 때 가장 먼저 찾은 요소를 반환한다. 따라서, Stream의 뒤쪽에 있는 요소가 리턴될 수도 있는 것이다.
Lambda
✏️ Lambda에 대해 설명해주세요
람다 표현식 (Lambda Expression)
람다 표현식이란 함수형 프로그래밍을 구성하기 위한 함수식이다. 즉, 자바의 메서드를 간결한 함수 식으로 표현한 것이다.
표현 방법
- 메서드 타입, 메서드 이름, 매개변수 타입, 중괄호, return문 (함수 리턴문이 한 줄 일 때)를 생략하고, 화살표 기호를 추가한다. 이런식으로 람다식을 이름이 없는 익명 함수(anonymous function)라고도 한다.
람다식과 함수형 인터페이스
MyFunction myfunc = (str) -> System.out.println(str);
myfunc.print("Hello World");- 람다식은 인터페이스를 익명 클래스로 구현한 익명 구현 객체를 짧게 표현한 것이다.
- 변수에서 메서드를 호출해서 사용한다. (객체처럼 사용한다.)
하지만, 아무 클래스나 추상 클래스의 메서드를 람다식으로 줄일 수는 없다. 인터페이스로 선언한 익명 구현 객체를 람다식으로 표현할 수 있는데, 그러한 인터페이스를 함수형 인터페이스라고 부른다.
함수형 인터페이스
딱 하나의 추상 메서드가 선언된 인터페이스를 말한다. 단, 인터페이스의 final 상수나 default, static, private 메서드는 추상 메서드가 아니기 때문에, 이런 것들이 여러 개 있어도 오로지 추상 메서드가 하나면 함수형 인터페이스로 취급된다.
// 함수형 인터페이스 O
interface Calc {
int add(int x, int y);
}
// 함수형 인터페이스 X
interface Calc {
int add(int x, int y);
int sub(int x, int y);
}
// 함수형 인터페이스 O
inteface Calc {
int add(int x, int y);
default void print() {}; // default 메서드
}@FunctionalInterface
인터페이스 선언 시 @FunctionalInterface 어노테이션을 붙이면 두 개 이상의 추상 메서드가 있을 때 컴파일 오류를 발생시켜준다.
람다 표현식 활용
람다식의 가장 큰 특징은 변수에 정수를 할당하듯이 함수를 할당할 수 있다는 것이다.
일급 객체(First Class Object)로서 파라미터나 반환 값으로 사용할 수 있다.
일급 객체(First-Class-Object)
다른 객체들에 일반적으로 적용 가능한 연산을 모두 지원하는 객체를 가리킨다.
자바에서 일급 객체는 변수, 매개변수, 반환값으로 사용(할당)할 수 있어야 한다.
람다식 변수 할당
inteface Calc {
int add(int x, int y);
}
public class Lambda {
public static void main(String[] args) {
Clac lambda = (x, y) -> x + y; // 함수를 변수에 할당
lambda.add(1,2); // 함수 사용
}
}람다식 매개변수 할당
inteface Calc {
int add(int x, int y);
}
public class Lambda {
public static void main(String[] args) {
int addResult = result( (x,y) -> x+y ); // 메서드의 매개변수에 람다식을 전달
System.out.println(addResult); // 3
}
public static int result(Calc lambda) {
return lambda.add(1,2);
}메서드의 매개변수에 람다식을 입력값으로 넣는 방식으로 자주 사용되는 방법이다. 함수를 메서드의 매개변수로 넘겨준다고 표현한다.
람다식 반환값 할당
inteface Calc {
int add(int x, int y);
}
public class Lambda {
public static void main(String[] args) {
Calc func = lambdaFunction();
int addResult = func.add(1,2);
System.out.println(addResult);
}
public static Calc lambdaFunction() {
return (x,y) -> x + y;
}
}메서드 반환값을 람다함수 자체를 리턴하도록 지정해줄 수 있다.
람다 메서드 변수 이용
public int outerMethod() {
int zero = 0;
int one = 1;
int two = 2;
// 외부 변수와 변수명이 중복되어 에러가 발생한다.
Calc lambda = (one, two) -> {
int three = 3;
return one + two + three;
};
// 에러 발생
Calc lambda = (x, y) -> {
int sum = one + two ; // 외부에서 정의된 변수를 사용할 수 있다.
one = 11; // 외부에서 정의된 변수를 변경할 수 없다.
return = sum + x + y;
};
// 람다식 내부에서 람다식 외부 메서드에 대한 return을 할 수 없다.
return 0;
}특징
- 람다식 안에서 지역 변수를 선언할 수 있다.
- 외부 변수를 공유하고 있다.
- 외부 변수의 값을 변경할 수 없다.
- 외부 메서드에 영향을 줄 수 없다.
외부 변수를 람다식 내부에서 사용할 때 주의점
| 변수 상태 | 설명 | 람다 내부 사용 가능 여부 |
|---|---|---|
| final 변수 | final 키워드로 선언, 값 변경 불가 | ✅ 가능 |
| effectively final 변수 | final 키워드 없음, 하지만 값 변경 안 됨 | ✅ 가능 |
| 값이 변경된 변수 | 초기값 이후 변경된 변수 | ❌ 사용 불가능 (컴파일 오류) |
Block/Non-Block, Sync/Async
✏️ Block/Non-Block, Sync/Async에 대해 설명해주세요
Block / Non-Block
현재 작업이 block(차단, 대기) 되느냐 아니냐에 따라 다른 작업을 수행할 수 있는지에 대한 관점 (제어권을 가지고 있느냐 없느냐)
제어권
함수의 코드나 프로세스의 실행 흐름을 제어할 수 있는 권리
Block
- 자신의 작업을 진행하다가 다른 주체의 작업이 시작되면 다른 작업이 끝날 때까지 기다렸다가 자신의 작업을 시작하는 것을 의미한다.
- A 함수가 B 함수를 호출할 때, B 함수가 자신의 작업이 종료되기 전까지 A 함수에게 제어권을 돌려주지 않는 것
- 호출된 함수가 실행이 끝날 때까지 제어권을 가지고 호출한 함수에게 바로 돌려주지 않는다.
Non-Block
- 다른 주체의 작업에 관련없이 자신의 작업을 하는 것을 의미한다.
- A 함수가 B 함수를 호출 할 때, B 함수가 제어권을 바로 A 함수에게 넘겨주면서, A 함수가 다른 일을 할 수 있도록 하는 것
- 호출된 B 함수는 실행되지만, 제어권은 A 함수가 그대로 가지고 있다.
- A 함수는 계속 제어권을 가지고 있기 때문에 B 함수를 호출한 이후에도 자신의 코드를 계속 실행한다.
Sync / Async
요청한 작업에 대해 완료 여부를 신경 써서 작업을 순차적으로 수행할지 아닌지에 대한 관점 (결과에 관심이 있느냐 없느냐)
Sync
- 요청한 작업에 대해 완료 여부를 따져 순차대로 처리하는 것 (순서가 지켜지는 것)
- A 함수가 B 함수를 호출 할 때, B 함수의 결과를 A 함수가 처리하는 것.
Async
-
요청한 작업에 대해 완료 여부를 따지지 않기 때문에 자신의 다음 작업을 그대로 수행하게 된다. (순서가 지켜지지 않는다)
성능 특징
- 요청한 작업에 대하여 완료 여부를 신경쓰지 않고 자신의 다음 작업을 수행한다는 것은, I/O 작업과 같은 느린 작업이 발생할 때, 기다리지 않고 다른 작업을 처리하면서 동시에 처리하여 멀티 작업을 진행할 수 있기 때문에 전반적인 시스템 성능 향상에 도움을 줄 수 있다.
Sync/Async + Block/Non-Block 조합
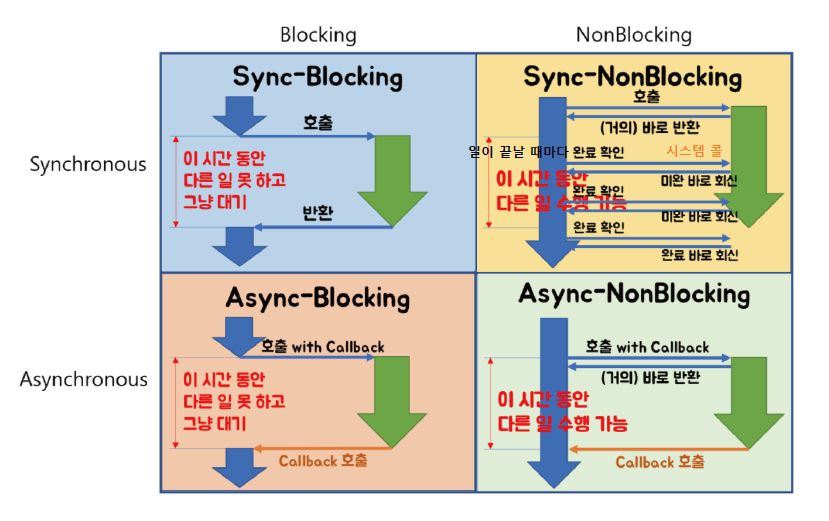
Sync Blocking (동기 + 블로킹)
다른 작업이 진행되는 동안 자신의 작업을 처리하지 않고 (Blocking), 다른 작업의 완료 여부를 바로 받아 순차적으로 처리하는 (Sync) 방식이다.
특징
- 코드가 순차적으로 실행된다.
- 일반적으로 작업이 간단하거나 작업량이 적은 경우에 사용된다.
- 작업량이 많거나 시간이 오래 걸리는 작업을 처리할 때는 작업을 처리하면 작업이 끝날 때까지 다른 작업을 처리하지 못하므로, 전체 처리 시간이 오래 걸려 비효율적이다.
예시
// 파일을 읽을 때까지 대기
try (FileInputStream fis = new FileInputStream("file.txt")) {
byte[] data = new byte[1024];
fis.read(data); // 이 줄에서 블로킹
System.out.println(new String(data));
}@GetMapping("/sync-blocking")
public String syncBlocking() {
// 외부 API 호출
RestTemplate restTemplate = new RestTemplate();
String result = restTemplate.getForObject(
"http://api.example.com/data",
String.class
); // 응답을 받을 때까지 블로킹
return result;
}Async Non-Blocking (비동기 + 논블로킹)
다른 작업이 진행되는 동안에도 자신의 작업을 처리하고 (Non-Blocking), 다른 작업의 결과를 바로 처리하지 않아 작업 순서가 지켜지지 않는 (Async) 방식이다.
특징
- 작업량이 많거나 시간이 오래 걸리는 작업을 처리해야 하는 경우에 적합하다.
- 다른 작업의 결과가 자신의 작업에 영향을 주지 않는 경우에 활용할 수 있다.
- 호출 함수에 콜백 함수가 있어 비동기 논블로킹 방식대로 처리된 작업의 결과를 후처리할 수 있게 된다.
- 작업량이 많거나 시간이 오래 걸리는 작업을 처리할 때 적합하다.
예시
// 콜백으로 처리
AsynchronousFileChannel.open(Paths.get("file.txt")).read(
ByteBuffer.allocate(1024), 0,
buffer,
new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer buffer) {
// 파일 읽기 완료 시 실행될 코드
System.out.println(new String(buffer.array()));
}
@Override
public void failed(Throwable exc, ByteBuffer buffer) {
exc.printStackTrace();
}
}
);
// 즉시 다른 작업 수행 가능
doSomethingElse();@GetMapping("/async-non-blocking")
public Mono<String> asyncNonBlocking() {
// WebClient를 사용한 비동기 호출
return WebClient.create()
.get()
.uri("http://api.example.com/data")
.retrieve()
.bodyToMono(String.class);
}Sync Non-Blocking (동기 + 논블로킹)
다른 작업이 진행되는 동안에도 자신의 작업을 처리하고 (Non Blocking), 다른 작업의 결과를 바로 처리하여 작업을 순차대로 수행하는 (Sync) 방식이다.
Sync Blocking vs Sync Non-Blocking ❓
둘 다 결국 코드를 순차적으로 진행하기 때문에 전체 작업의 최종 처리 시간이 차이가 없어보일 수 있다. 성능 차이는 상황에 따라 다르겠지만, 동기 + 논블로킹은 호출하는 함수가 제어권을 가지고 있어서 다른 작업을 병렬적으로 수행할 수 있기 때문에, 일반적으로 동기 + 논블로킹 방식이 더 효율적일 수 있다. 반면에, 동기 + 블로킹 방식은 호출하는 함수가 제어권을 잃어서 다른 작업을 수행할 수 없다.
좀 더 쉽게 말하자면, 호출된 함수가 바로 제어권을 돌려주어 호출한 함수는 다른 작업을 수행할 수 있으나, 호출한 함수는 호출된 함수의 결과를 처리해야하기 때문에 언제 종료되는지 알 수 없는 호출된 함수의 종료를 반복적으로 물어봐야 한다.
결국, 호출한 함수가 다른 작업을 수행할 수 있었음에도 불구하고 여전히 호출된 함수의 결과에만 신경쓰기에 제 할 일을 못하게 되는 형태가 된다.
예시
// 파일 읽기 가능 여부 확인하며 다른 작업 수행
FileChannel channel = FileChannel.open(Paths.get("file.txt"));
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (buffer.hasRemaining()) {
int bytesRead = channel.read(buffer); // 즉시 반환
if (bytesRead == 0) {
// 다른 작업 수행
doSomethingElse();
}
}Async Blocking (비동기 + 블로킹)
다른 작업이 진행되는 동안 자신의 작업을 멈추고 기다리는 (Blocking), 다른 작업의 결과를 바로 처리하지 않아 순서대로 작업을 수행하지 않는 (Async) 방식이다.
호출한 함수는 호출된 함수의 작업 결과에 관심이 없음에도 불구하고 호출된 함수의 결과를 기다리고 있어야 하는 형태이다.
예시
// CompletableFuture를 사용하지만 get()으로 블로킹
CompletableFuture<String> future = readFileAsync("file.txt");
String content = future.get(); // 이 줄에서 블로킹
System.out.println(content);Java의 동시성 이슈
✏️ Java의 동시성 이슈에 대해 설명해주세요
싱글 스레드와 멀티 스레드
스레드
CPU 작업의 한 단위
임계 영역 (critical section)
여러 스레드가 동시에 접근하게 된다면 데이터의 불일치나 예상하지 못한 결과가 발생할 수 있는 위험하고 중요한 코드 부분으로, 여러 스레드들이 동시에 접근해서는 안되는 공유 자원을 접근(조회)하거나 수정하는 부분
싱글 스레드 환경
애플리케이션이 스레드 하나로만 실행되는 것
멀티 스레드 환경
애플리케이션이 여러 개의 스레드로 실행되는 것
| 싱글 스레드 | 멀티 스레드 |
|---|---|
| 컨텍스트 스위칭 X | 빈번한 컨텍스트 스위칭으로 인해 성능 저하 가능성 O |
| 동기화 이슈 X | 스레드 간 동기화 이슈 O |
| 순차적 실행으로 응답성 및 전체 처리량이 낮음 | 동시성으로 사용자에게 응답성 향상 |
장점
멀티 스레드를 사용하면 공유하는 영역이 많아 프로세스 컨텍스트 스위칭보다 스레드 컨텍스트 스위칭의 오버헤드가 작고, 메모리 리소스가 상대적으로 적다는 장점이 있다.
단점
자원을 공유하기 때문에 단점도 존재한다. 그게 바로 동시성(Concurrency) 이슈이다.
동시성 이슈
여러 스레드가 동시에 공유 자원에 접근하여 발생하는 문제이다. 동시성 이슈는 멀티 스레드 환경에서 발생하며, 싱글 스레드 환경에서는 단 하나의 스레드로 애플리케이션이 실행되기 때문에 동시성 이슈가 발생할 수 없다.
싱글 스레드 환경
public class CurrencyIssueTest {
static int count = 0;
@DisplayName("싱글 스레드에서의 동시성 이슈")
@Test
void ConcurrencyIssueInSingleThread() {
for (int i = 1; i <= 10000; i++) {
count += 1;
}
for (int i = 1; i <= 10000; i++) {
count += 1;
}
Assertions.assertThat(count).isEqualTo(10000 * 2);
}
}멀티 스레드 환경
public class CurrencyIssueTest {
static int count = 0;
@DisplayName("멀티 스레드에서의 동시성 이슈 ")
@Test
void ConcurrencyIssueInMultiThread() {
Thread thread1 = new Thread(() -> {
for(int i = 1; i <= 10000; i++) {
count += 1;
}
}, "첫번째 스레드");
Thread thread2 = new Thread(() -> {
for(int i = 1; i <= 10000; i++) {
count += 1;
}
}, "두번째 스레드");
thread1.start();
thread2.start();
Assertions.assertThat(count).isEqualTo(10000 * 2);
}
}- 위의 테스트를 실행하면, 싱글 스레드와 달리 멀티 스레드 환경에서는 동시성 이슈가 발생하여 원하는 결과값이 나오지 않는 것을 확인할 수 있다.
동시성 이슈 해결방법
1️⃣. synchronized 키워드
public class Synchronized {
public synchronized void a() {
// 메서드 전체에 동기화 적용
}
public void b() {
synchronized (this) {
// 내부에 동기화 블럭 생성
}
}
}
public class Synchronized {
public static void syncMethod() {
synchronized (Synchronized.class) {
클래스 내부의 전역 메서드에서 동기화 블럭을 생성하는 방법
}
}
}⭐️장점
1. Race Condition : 두 개 이상의 스레드가 경쟁적으로 동일한 자원을 수정할 때 발생하는 문제를 해결해준다.
2. 데이터 일관성 : 여러 스레드가 동시에 읽고 쓰는 데이터의 일관성을 유지해준다.
🚨단점
- 락을 획득하기 위해 대기하는 스레드는 BLOCKED 상태가 되는데, 타임아웃도 없고 인터럽트도 발생하지 않아 중지시킬 수 없다.
synchronized는 스레드의 락 획득에 대한 공정성을 보장할 수 없다. 따라서 하나의 스레드가 오랜 시간동안 락을 획득하지 못할 수도 있다.- critical section의 크기 및 실행시간에 따라 성능 하락 및 자원 낭비가 심해질 수 있고, 스레드의 개수가 많으면 많을수록 실행 시간에 엄청난 지연이 생길 수 있다.
2️⃣. volatile 키워드
public volatile long count = 0;CPU 메모리 영역에 캐싱된 값이 아니라 항상 최신의 값을 가지도록 메인 메모리 영역에서 값을 참조한다. 즉, 동일 시점에 모든 스레드가 동일한 값을 가지도록 동기화한다.
하지만, ++와 같은 연산 작업이 있을 경우 동시성 문제는 동일하게 발생한다. 오직, 읽기/쓰기에서 동일한 값을 얻을 수 있다.
특징
1. mutual exclusion(상호 배제)를 제공하지 않고도 데이터 변경의 가시성을 보장한다.
2. 원자적 연산에서만 동기화를 보장한다.
(원자적 연산이란, 더 이상 쪼갤 수 없고, 중간에 다른 스레드가 개입할 수 없는 연산으로, 대표적으로 AtomicInteger 클래스가 있다.)
3️⃣. Atomic 클래스
내부적으로 CAS(Compare-and-Swap) 방식을 사용해 동시성을 제어한다. CAS란, 멀티스레드 환경에서 동시성을 보장하기 위한 컴퓨터 명렁어이다.
동작 방식
A의 값을 B로 업데이트할 때, 예상되는 A 변수의 현재 값을 실제 메모리 M에 위치한 A값과 비교하여 두 값이 일치할 때만 메모리의 값을 B로 업데이트 하는데, 이 모든 과정이 하나의 atomic한 명령어 안에서 수행된다.
⭐️특징
CAS는 다른 스레드의 접근을 막지 않는다. 즉, 하나의 스레드에서 특정 변수의 값을 업데이트하고자 할 때 다른 스레드의 접근을 금지하는 Lock 기반의 방식들과 달리, CAS를 이용할 경우 변수의 값을 업데이트 하기 위해 경합하던 스레드들은 그들이 값 업데이트에 성공했는지 여부 (true/flase)만 알 수 있을 뿐이다.
따라서, 스레드들은 값을 업데이트하기 위해 Lock이 해제되기를 기다리는 게 아니라 계속해서 그들의 작업을 수행할 수 있고, 이를 통해 Context-switching이 발생하는 것을 피할 수 있다.
🚨단점
CAS 연산이 실패했을 때, 스레드는 값을 다시 읽고 다시 시도하게 되는데 이것을 스핀 대기(Spin Waiting)이라고 한다.
이 때, 스레드는 Runnable 상태를 유지하면서 반복적으로 값을 비교하고 변경을 시도하지만, 다른 스레드가 계속 값을 변경하면 성공하지 못할 수 있다. 즉, 다른 스레드가 락을 해제할 때까지 기다리는 대신, CPU 자원을 사용해 계속 시도하는 것이다. 이로 인해 CPU 자원을 소모하게 되며, 스레드가 성능 저하를 겪을 수 있다.
4️⃣. ReentrantLock (명시적 Lock)
public class CountingTest {
public static void main(String[] args) {
Count count = new Count();
for (int i = 0; i < 100; i++) {
new Thread(){
public void run(){
for (int j = 0; j < 1000; j++) {
count.getLock().lock();
System.out.println(count.view());
count.getLock().unlock();
}
}
}.start();
}
}
}
class Count {
private int count = 0;
private Lock lock = new ReentrantLock();
public int view() {
return count++;
}
public Lock getLock(){
return lock;
};
}특징
해당 Lock의 범위를 메서드 내부에서 한정하기 어렵거나, 동시에 여러 Lock을 사용하고 싶을 때 사용한다.
직접적으로 Lock 객체를 생성하여 사용한다.
그렇다면 CAS vs Lock 뭘 선택해야 할까?
락을 사용하는 방식은 코드가 단순하고 이해하기 쉬우며, 복잡한 동기화가 필요한 경우 적합합니다. 하지만 성능 면에서는 잠금 대기 시간이 늘어나면 문제가 될 수 있습니다.
CAS 방식은 더 높은 성능을 제공할 수 있지만, 경쟁이 치열한 경우 스핀 락이 길어지면서 성능 저하가 발생할 수 있습니다. 따라서 낮은 경쟁 환경에서는 CAS 방식이 유리하지만, 경쟁이 많은 상황에서는 락이 더 나을 수 있습니다.
