
String, StringBuilder, StringBuffer
✏️String, StringBuilder, StringBuffer를 설명하고, 각각의 차이에 대해 설명해주세요.
모두 자바에서 문자열을 다루는 대표적인 자료형 클래스
📌 String
자바 String 객체는 '불변(immutable)자료형'
String str1 = "hello";
String str2 = "hello";
System.out.println(str1 == str2); // true
str1 = str1 + "world"; // "helloworld"라는 새로운 객체가 힙 메모리 어딘가에 생성된다.
System.out.println(str1); // helloworld
이 경우, 불변인 String 객체의 값을 변경한 것으로 보일 수 있다. 하지만, 실제로는 메모리에 "hello world" 값을 저장한 영역을 따로 만들고 변수 str가 그 영역을 다시 참조하는 식으로 작동한다.
- 기존 문자열은 GC의 제거 대상이 되고, 변경한 문자열로 새로운 객체가 생성하여 리턴하는 것이다.
String을 불변하게 함으로써 String pool에 각 리터럴 문자열의 하나만 저장하며 다시 사용하거나 캐싱에 이용가능하며 이로 인해 힙 공간을 절약할 수 있다는 장점이 있다.
단점
불변적인 특징 때문에 값을 업데이트하면, 매 연산 시마다 새로운 문자열을 가진 String 인스턴스가 생성되어 메모리 공간을 차지하여 성능 저하 및 메모리 낭비가 발생한다.
📌 StringBuilder
StringBuilder는 '가변(Mutable)객체'
StringBuilder sb = new StringBuilder("hello");
sb.append("world");
System.out.println(sb); // "helloworld"가변 객체이기 때문에 문자열을 업데이트했을 때, 새로운 객체를 생성하는 것이 아니라 동일 객체 내에서 수정이 가능하다.
.append(),.delete(),.replace()등의 메서드를 이용하여 문자열의 추가, 수정, 삭제 등을 수행할 수 있다.
StringBuilder 클래스는 동기화(`synchronized` 키워드 X)를 지원하지 않기 때문에 단일 스레드에서 빠르다.
단점
동기화를 지원하지 않기 때문에 멀티스레드 환경에서는 안전하지 않다. 여러 스레드에서 한 개의 자원에 접근할 때, 데이터 충돌이 발생할 수 있다.
📌 StringBuffer
StringBuffer도 StringBuilder처럼 '가변(Mutable)객체'
StringBuilder 클래스는 동기화를 지원하기 때문에 멀티 스레드 환경에서도 안전하게 동작할 수 있다.
synchronized키워드를 사용
단점
동기화 처리 때문에 StringBuilder 보다 속도가 느릴 수 있다.
단일 스레드 환경에서는 동기화 오버헤드가 성능 저하를 일으킬 수 있다.
✅ 정리
String 을 사용해야 할 때 :
- 문자열의 불변성이 중요할 때
- 문자열 연산이 적고 변하지 않는 문자열을 자주 사용할 경우
- String도 Thread safe이기 때문에 멀티 쓰레드 환경일 경우
StringBuilder 를 사용해야 할 때 :
- 문자열의 가변성이 중요할 때
- 문자열의 연산이 많이 발생할 때
- 단일 스레드 환경이거나 동기화를 고려하지 않아도 되는 경우
- 단일 스레드에서는, 속도면에서 StringBuffer보다 성능이 좋다.
StringBuffer 를 사용해야 할 때 :
- 문자열의 가변성이 중요할 때
- 문자열의 연산이 많이 발생할 때
- 멀티 스레드 환경일 때
- 현업에서는 자바 앱이 대부분 멀티 스레드 이상의 환경에서 돌아가기 때문에 StringBuffer로 통일하여 코딩하는 것이 좋다고 한다.
final 키워드
✏️ 자바의 final 키워드에 대해 설명해주세요(final, finally, finalize())
📌 final
final 키워드는 변수, 메서드, 클래스에서 사용될 수 있다.
변수
final 변수는 수정할 수 없다.
- 변수에 적용 : 해당 변수의 값은 변경 불가능 (상수)
- 변수의 참조에 적용 : 참조 변수가 힙 내의 다른 객체를 가리키도록 변경 불가능 (참조값 변경 불가능)
초기화 이전에 사용할 수 없으며, 변수를 선언할 때 또는 생성자를 통해 초기화가 가능하다.
메서드
final 메서드는 자식 클래스에서 오버라이딩할 수 없다.
클래스
final 클래스는 상속이 불가능하다.
Integer와 같은 랩퍼(Wrapper)클래스가 대표적인 예
📌 finally
finally 블록은 try-catch 구문에서 예외 상황 발생 여부와 관계없이 항상 실행되는 블럭
- 보통 DB 연결 및 해제, I/O 스트림을 열었을 때 닫아주는 작업 등에 사용
try{
System.out.println("예외 상황이 발생하지 않았습니다 !");
return 0;
} finally {
System.out.println("finally 블럭을 실행중입니다 !");
return 1;
}
return -1;위와 같은 상황에서의 반환값은 무엇일까? (예외 발생 X 가정)
try블록이 정상적으로 실행된다. 이 경우return 0;이 실행된다. (현재 반환값0)try블록에서return이 실행되지만,try블록이 끝나고 나서finally블록이 실행된다.finally블록에서return 1;이 실행되면,finally블록에서의return값이try블록에서의return값을 덮어쓴다.
결론 :return값은1!
하지만, finally 블록은 주로 자원을 정리하거나 마무리 작업을 위해 사용되기 때문에. finally 구문에 반환문을 잘 쓰지 않는다.
📌 finalize()
finalize() 메서드는 가비지 컬렉션(GC)에 의해 객체가 제거될 때 호출된다.
Object클래스로부터 상속받아 모든 객체가 가지고 있는 메서드- 만약 객체가 삭제되기 직전에 실행되어야 하는 로직이 있으면
finalize()를 오버라이딩할 수 있다. (파일 핸들러나 네트워크 연결과 같은 자원 해제 작업) - 하지만,
finalize()는 언제 호출될지 알 수 없기 때문에 (GC의 객체 수거 시점 예측 불가능) 이 메서드에 의존하는 것은 권장되지 않는다.
불확실성, 성능 문제, 자원 해제 순서 등의 이유로 자바 9 이후로는 사용을 권장하지 않으며, 대신 try-with-resources 구문과 AutoCloseable 인터페이스를 사용하는 것이 바람직하다.
예외 (Exception)
✏️ 자바에서 다루는 예외 2가지와 예외를 처리하는 3가지 방법에 대해 설명해주세요.
1. 언체크드 예외 (Unchecked Exception)
컴파일 시점에 검사되지 않는 예외(런타임 시점에 검사되는 예외)로, 명시적으로 예외 처리를 강제하지는 않는다. 예외 처리를 하지 않아도 프로그램 실행은 가능하나, 예외 상황을 맞닥들이면 예외 상황이 발생하여 프로그램이 예기치않게 종료될 수 있다.
RuntimeException과 이를 상속한 예외 클래스들이 이에 속한다.ArrayIndexOutOfBoundsException,NullPointerException등이 있다.
2. 체크드 예외 (Checked Exception)
컴파일 시점에 검사되는 예외로 명시적으로 예외를 처리하도록 강제한다. 반드시 예외 처리가 필요하며, 그렇지 않을 경우 컴파일 에러로 인해 프로그램 실행이 되지 않는다.
Exception과 이를 상속한 예외 클래스들 중에서RuntimeException을 제외한 모든 예외 클래스들이 이에 속한다.ClassNotFoundException,DataFormatException등이 있다.
예외 처리 방법
1. 예외복구
- 예외 상황을 파악하고 문제를 해결해서 정상 상태로 돌려놓는 방법
- 예외가 발생하더라도 적절히 처리하여 어플리케이션이 정상적으로 동작하도록 복구하는 것
- 예외 발생 시 기본값을 사용하거나 대체 가능한 값을 반환하여 예외를 복구를 시도
- 예외가 발생했을 때 일정 횟수만큼 다시 시도하여 복구를 시도
- 네트워크 연결, 파일 시스템, 데이터베이스 연결등의 로직에서 유용하다.
public class GracefulDegradationExample {
public static void main(String[] args) {
String user = getUserDetails();
System.out.println("현재 사용자: " + user);
}
public static String getUserDetails() {
try {
// 예시로 로그인 시 예외가 발생한다고 가정
throw new RuntimeException("로그인 실패"); // 로그인 예외
} catch (RuntimeException e) {
System.out.println("로그인 실패! 기본 사용자로 동작합니다.");
return "게스트 사용자"; // 기본 동작으로 복구
}
}
}2. 예외 처리 회피
- 예외를 직접 처리하지 않고 호출한 곳으로 예외 처리를 전가하는 방법 (
throws) - 단, 예외를 회피하는 것은 프로그램의 안정성을 해칠 수 있으므로 신중하게 사용해야 한다.
- 호출한 곳에서 예외를 처리하는 것이 바람직하거나, 회피하는 것이 최선의 방법일 때 사용한다.
public class ExceptionHandlingAvoidance {
public static void main(String[] args) {
try {
int result = 10 / 0; // ArithmeticException 발생
} catch (ArithmeticException e) {
// 예외를 잡고 아무 처리도 하지 않음
}
System.out.println("프로그램 계속 실행 중...");
}
}3. 예외 전환
- 예외 처리 회피와 비슷하게 메서드 밖으로 예외를 던지지만, 특정 예외를 다른 적절한 예외로 변환하여 던지는 방법
- 주로 메서드에서 처리할 수 없는 예외를 호출한 곳으로 전달할 때 유용합니다.
- 외부 라이브러리 예외를 사용자 정의 예외로 변환하여 시스템에서 일관되게 처리하도록 할 때 사용한다.
- 체크 예외를 비체크 예외로 변환하여 호출자에게 예외 처리를 강제시키고 싶지 않을 때 사용한다.
- 더 구체적인 예외 정보를 제공하기 위해 상위 클래스가 아닌 정확한 예외 클래스를 던지고 싶을 때 사용한다.
public static void processData(String data) {
try {
if (data == null) {
throw new NullPointerException("데이터가 null입니다");
}
// 데이터 처리 로직
} catch (NullPointerException e) {
// NullPointerException을 CustomNullPointerException으로 변환하여 던짐
throw new CustomNullPointerException("잘못된 데이터: null 값이 입력됨", e);
}
}equals / hashcode()
✏️ equals()와 hashcode()에 대해 설명해주세요.
equals()
Object 에 정의된 equals() 함수는 객체의 주소값을 비교한다. 이는 사실상 == 연산자와 동일한 동작을 하게 된다. (실제로 Object의 equals() 함수를 보면 == 연산자의 결과값을 반환한다.)
equals() 오버라이딩
만일 객체 자료형을 비교할 때, 주소 값이 아닌 객체의 값을 비교하도록 구현하고 싶다면, equals() 메서드를 오버라이딩한다. 예를 들어, String 클래스나 Integer 클래스에서는 객체의 참조 주소가 아니라, 객체가 가진 데이터(값)를 비교한다.
- 두 참조 변수의 값이 같은지 다른지 동등성 비교를 위해 사용하는 메소드
📌 객체 필드를 비교하는 또 다른 함수를 만들면 되지 왜 굳이 equals를 오버라이딩을 하지?
- 일관성 부족 :
isSamePerson()이라는 비교 메서드를 직접 정의해서 사용하면, 여러 클래스나 라이브러리에서 객체를 비교할 때 일관되게 사용할 수 없다. 반면,equals()를 재정의하면,==연산자나Objects.equals()와 같은 표준 비교 메서드와 호환되어, 코드의 일관성을 유지할 수 있다.- 상속과 다형성 :
equals()는Object클래스에 정의되어있기 때문에 모든 클래스가 기본적으로 가지고 있다. 직접 정의한 메서드를 사용하면 상속이나 다형성을 제대로 활용할 수 없다.
일관성 부족 추가 설명 : Java의 컬렉션 클래스(예: HashSet, HashMap 등)에서는 기본적으로 equals()를 사용하여 객체를 비교한다. 만약 Person 클래스에서 equals()를 오버라이드하지 않으면, 이 컬렉션 클래스들이 equals()가 아닌 참조값(주소값)을 기준으로 객체를 비교하여 원하는 결과가 나오지 않을 수 있다.
hashcode()
객체의 주소값을 해싱하여 해시코드(주소값으로 만든 고유한 숫자값)를 반환해주는 메서드
hashcode() 오버라이딩
equals()의 결과가 true인 두 객체의 해시코드는 반드시 같아야 한다.
왜?
두 메소드를 함께 재정의하지 않을 시, hash값을 사용하는 Collection Framework(HashSet, HashMap, HashTable)을 사용할 때 문제가 발생하기 때문이다.
EX) hashcode()를 재정의하지 않고, HashSet에 필드값이 같은 Person 객체를 2개 추가했을 때, 동등성을 인지하지 못하고 해시코드가 다르기 때문에 둘 다 컬렉션에 추가된다.
hashcode와 equals의 동작순서
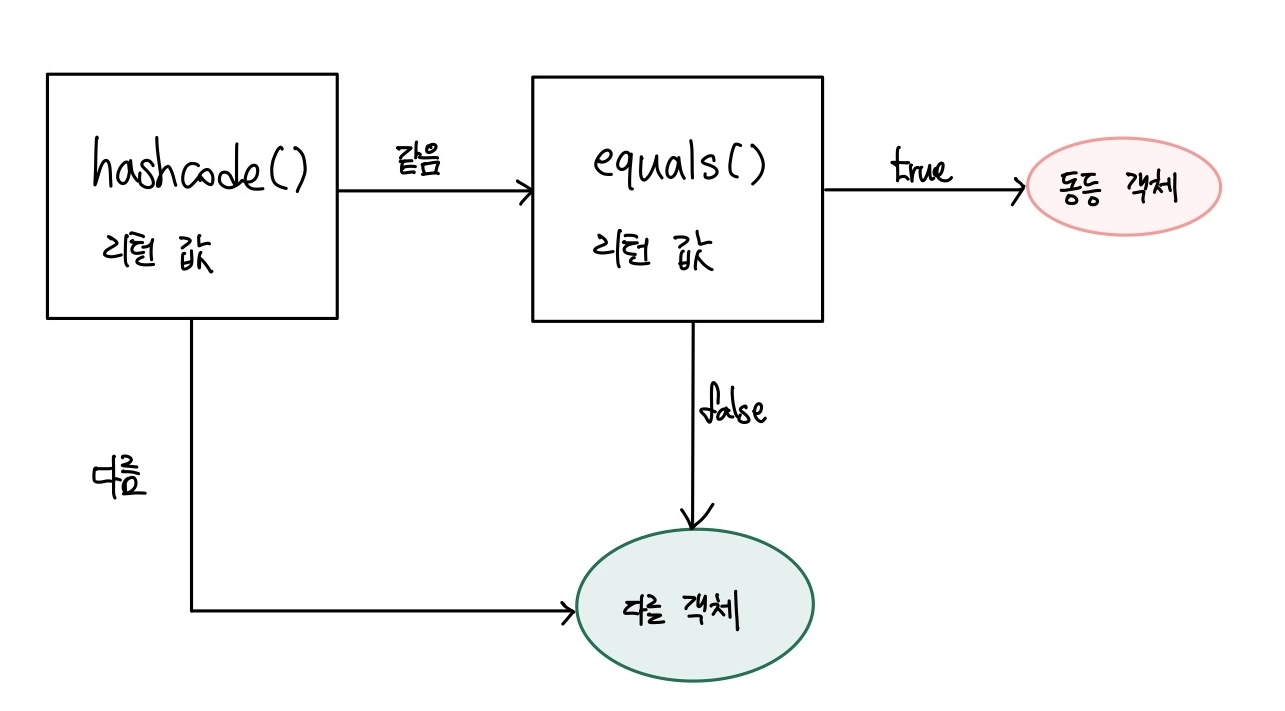
다음과 같이, 데이터가 추가되면, 가장 먼저 데이터의 hashCode()의 리턴값을 컬렉션에 가지고 있는지 비교한다. 만약 해시코드가 같다면 다음으로 equals() 메서드의 리턴값을 비교하고, true라면 논리적으로 같은 객체라고 판단한다.
SOLID (객체지향 5대원칙)
✏️ SOLID(객체지향 5대원칙)에 대해서 설명해주세요.
SOLID원칙이란, 객체지향 설계에서 지켜야 할 5개의 소프트웨어 개발 원칙이다. SOLID 객체 지향 원칙을 적용하면 코드를 확장하고 유지 보수 관리하기가 쉬워지며, 불필요한 복잡성을 제거해 리팩토링에 소요되는 시간을 줄인다.
📌 SRP (Single Responsibility Principle) : 단일 책임 원칙
- 하나의 클래스는 하나의 책임만 가져야 한다.
-> 하나의 클래스는 하나의 기능만 담당하도록 클래스를 따로 설계하라는 원칙 - 하나의 클래스에 여러가지 기능이 담겨있다면, 기능 변경이 필요할 때 수정해야 할 코드가 많아진다.
- SRP를 따를 경우, 한 책임의 변경으로부터 다른 책임의 변경으로의 연쇄작용을 극복할 수 있게 된다. (기능 변경이 필요할 경우, 한 클래스만 기능 변경을 하면 되도록)
- 프로그램의 유지보수성을 높이기 위한 설계 기법
📌 OCP (Open Closed Principle) : 개방 폐쇄 원칙
- '확장성은 개방하고, 수정은 폐쇄한다'는 것을 의미
- 기능 추가 요청이 들어오면 클래스 확장을 통해 구현하면서, 확장에 따른 클래스 수정은 최소화하도록 설계하라는 원칙 (즉, 기존의 코드 수정은 최소화하면서 기능을 추가, 수정할 수 있도록)
- 상속, 추상화를 활용하여 클래스 간의 관계를 구축을 권장하는 것
📌 LSP (Liskov Substitution Principle) : 리스코프 치환 원칙
- 자식 클래스 객체는 언제나 부모 클래스 타입으로 교체할 수 있어야 한다.
- 다형성의 특징을 이용하기 위해 부모 클래스 타입으로 객체를 선언하여 하위 클래스의 인스턴스를 받으면, 업캐스팅된 상태에서 부모의 메서드를 문제없이 의도대로 이용할 수 있어야 한다는 것을 의미한다.
📌 ISP (Interface Segregation Principle) : 인터페이스 분리 원칙
- 인터페이스를 각각 사용에 맞게 잘 분리해야 한다는 설계 원칙
- 클래스의 단일 책임(SRP)처럼 인터페이스도 단일 책임을 강조하는 것(ISP)
- 클라이언트의 목적과 용도에 맞게 적합한 인터페이스를 제공해야 한다.
특정 클라이언트를 위한 인터페이스 여러 개가 범용적인 인터페이스보다 낫다. (세부적인 인터페이스로 나누기) - 각 클라이언트가 필요로 하는 인터페이스를 분리하여, 클라이언트의 요구에 변화가 있더라도 다른 인터페이스는 영향을 받지 않도록 하는 것
- 인터페이스는 다중 상속(구현)이 가능하기 때문에, 분리할 수 있으면 분리하여 각 클래스 용도에 맞게
implements하라는 설계 원칙
📌 DIP (Dependency Inversion Principle) : 의존 역전 원칙
- 의존 관계를 맺을 때, 변화하기 쉬운 구체적인 것보다는 변하기 어려운 추상적인 것에 의존해야 한다는 것
-> 즉, 특정 구현 클래스에 의존하지 말고, 그 대상의 상위 요소(추상 클래스, 인터페이스)에 의존하라는 뜻 - 각 클랜스간의 결합도(coupling)을 낮추는 것
원시타입 vs 참조타입
✏️ 원시 타입과 참조 타입에 대해 성능 관점, 메모리 관점, NULL 관점, 제네릭 관점에서 비교해주세요.
원시 타입
크게 논리형(boolean), 문자형(char), 정수형(byte, short, int, long), 실수형(float, double)으로 나뉘며 실제 데이터 값을 저장하는 데이터 타입
참조형 타입
기본적으로 위의 8가지 원시타입을 제외하고는 모두 참조형 타입이라고 볼 수 있다. 참조형 타입은 데이터가 저장된 주소 값을 저장(참조)하는 데이터 타입으로 주소값을 통해 실제 객체를 참조하는 데이터 타입
비교
📌 메모리 위치 관점
원시형 타입
원시형 타입은 변수 선언과 동시에 메모리가 생성되며, 스택(Stack)에 실제 값을 저장한다.
참조형 타입
참조형 타입의 실제 값은 힙(Heap)에 저장되고, 실제 객체(데이터)의 주소값은 스택에 저장된다.
즉, 스택에는 주소값, 힙에는 실제 객체(데이터)
📌 메모리 사용량 관점
원시형 타입
원시형 타입은 메모리 사용량이 작고 고정되어 있다.
참조형 타입
힙에 저장되는 참조형 타입의 실제 데이터는 객체의 크기와 구조에 따라 메모리 사용량이 다를 수 있다. 원시형 타입의 데이터보다 많은 메모리를 사용할 수 있다.
📌 성능 관점
원시형 타입은 스택에 실제 값이 저장되는 점에 반해, 참조형 타입은 스택에 저장된 주소값(참조값)을 통해 힙 영역에 저장된 실제 객체에 접근할 수 있기 때문에 최소 2번 메모리에 접근해야 한다. 그래서 참조형 타입은 원시 타입과 비교해서 접근 속도가 느리다.
📌 NULL 관점
원시형 타입
비객체 타입으로 null 값을 가질 수 없다. 값을 명시적으로 초기화하지 않을 때는 각 타입별 기본값으로 초기화된다.
참조형 타입
null로 초기화할 수 있다.
📌 제네릭 관점
원시형 타입
Generic 타입으로 사용할 수 없다.
참조형 타입
Generic 타입에서 사용할 수 있다.
