
네트워크
- 컴퓨터와 컴퓨터를 연결하여 데이터를 주고받거나 함께 협력할 수 있게 하는 것
- 각종 통신 장비들이 서로 그물망처럼 연결돼서 데이터를 주고받을 수 있게 하는 통신망
네트워크 형식
LAN (Local Area Network)
근거리 영역 네트워크
건물이나 방, 특정 지역을 범위로하는 컴퓨터나 주변장치를 연결하는 네트워크
- 연결하는 방식에 따라 STAR,,, 등의 방식으로 나눌 수 있다.
WAN (Wide Area Network)
광대역 네트워크
서로 다른 지역의 LAN을 연결한 네트워크
넓은 지역에서 여러 개의 LAN을 연결해서 통신하는 네트워크 구성방식
- 이미 LAN방식에서 구성 방식이 정해졌기에 WAN은 구성방식이 따로 존재하진 않는다.
규약 (Protocol)
서로 지키도록 협의하여 정하여놓은 규칙이다. 컴퓨터 네트워크에서의 프로토콜은 서로 다른 기종의 컴퓨터끼리 통신하기 위해서 미리 정해놓은 통신 규약 및 통신 약속이다.
OSI Model (Open Systems Interconnections)
OSI 7계층
네트워크 통신을 위해 프로토콜을 설계 및 구현할 때 효율성과 상호 운용성을 높이기 위해 기능별로 각 계층을 나누어 구현하기 위해 사용하는 방식이다.
- 7계층 -> 1계층 : 캡슐화
- 1계층 -> 7계층 : 역캡슐화
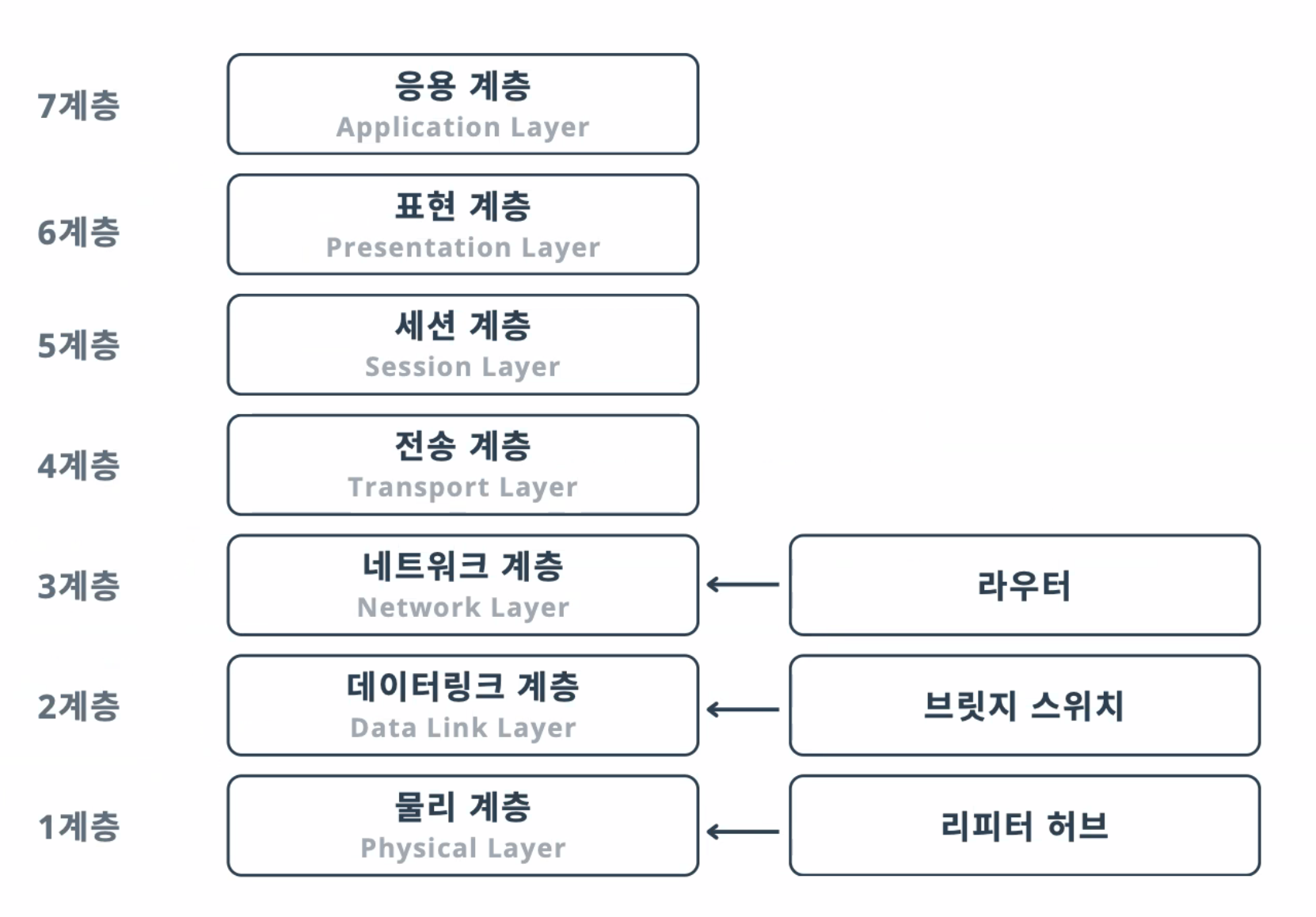
1. 물리 계층
전기 신호를 이용해서 케이블에 전기 신호를 주면서 데이터를 전달하는 역할
2. 데이터링크 계층
물리계층을 통해 송수신되는 정보의 오류와 흐름을 관리하여 안전한 정보의 전달을 수행할 수 있도록 도와주는 역할
3. 네트워크 계층
네트워크 장치 간에 경로를 선택하고 데이터 전송을 수행해주는 역할
4. 전송 계층
양 끝단의 사용자들 간의 신뢰성있는 데이터를 주고 받게 해주는 역할
5. 세션 계층
통신할 때 통신 설정, 관리 및 종료를 해준다.
6. 표현 계층
전송하는 데이터의 표현방식을 결정한다.
7. 애플리케이션 계층
사용자와 가장 가까운 계층
데이터를 송신하는 송신자 : 7계층 -> 1계층 (캡슐화)
데이터를 수신하는 수신자 : 1계층 -> 7계층 (역캡슐화)
왜 계층을 나누는 거지?
- 통신이 일어나는 과정 중 이상이 생기면, 원인 파악이 쉬워지고, 해결하기 쉬워진다.
- 각 계층이 독립적으로 존재하기 때문에 특정 계층의 기술을 개선하거나 변경해도 다른 계층에 영향을 주지 않는다.
TCP/IP
OSI 7계층을 좀 더 효율적으로 이용하기 위해 간략화해서 사용하는 것
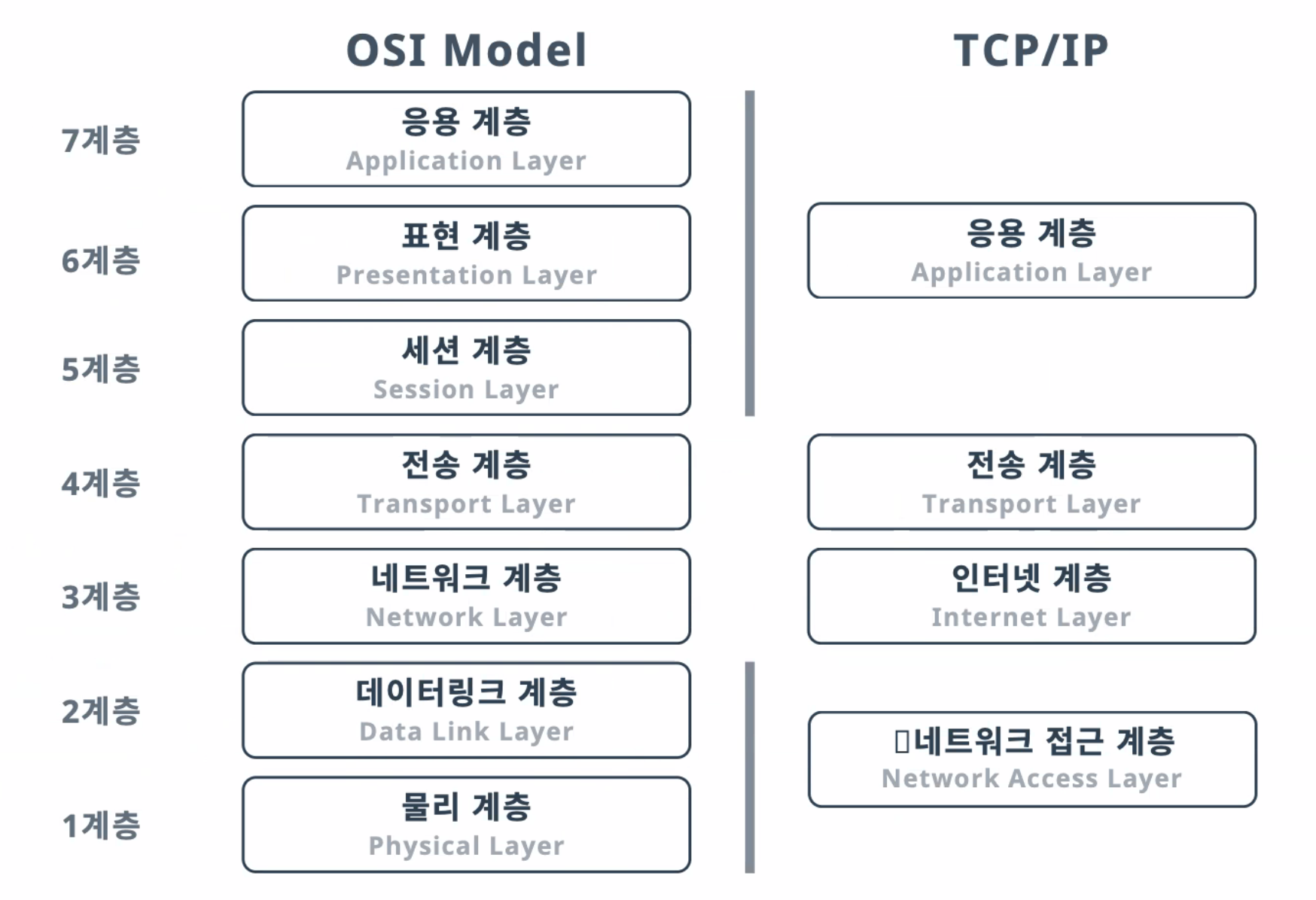
1. 네트워크 접근 계층 (Network Access Layer)
데이터를 전기신호로 변환한 후, 선로를 통하여 그 데이터를 전송하는 역할
2. 인터넷 계층(Internet Layer)
물리적인 데이터가 어떻게(어떤 경로로) 전송되어야 하는지 결정하는 역할
3. 전송 계층 (Transport Layer)
데이터가 전송될 때 신뢰성이 보장되어야 한다. 데이터의 전달을 보증하고 보낸 순서대로 받게 해준다.
4. 응용 계층(Application Layer)
사용자와 어플리케이션 간의 소통을 담당할 수 있도록 하는 역할
OSI 7계층 데이터 형식
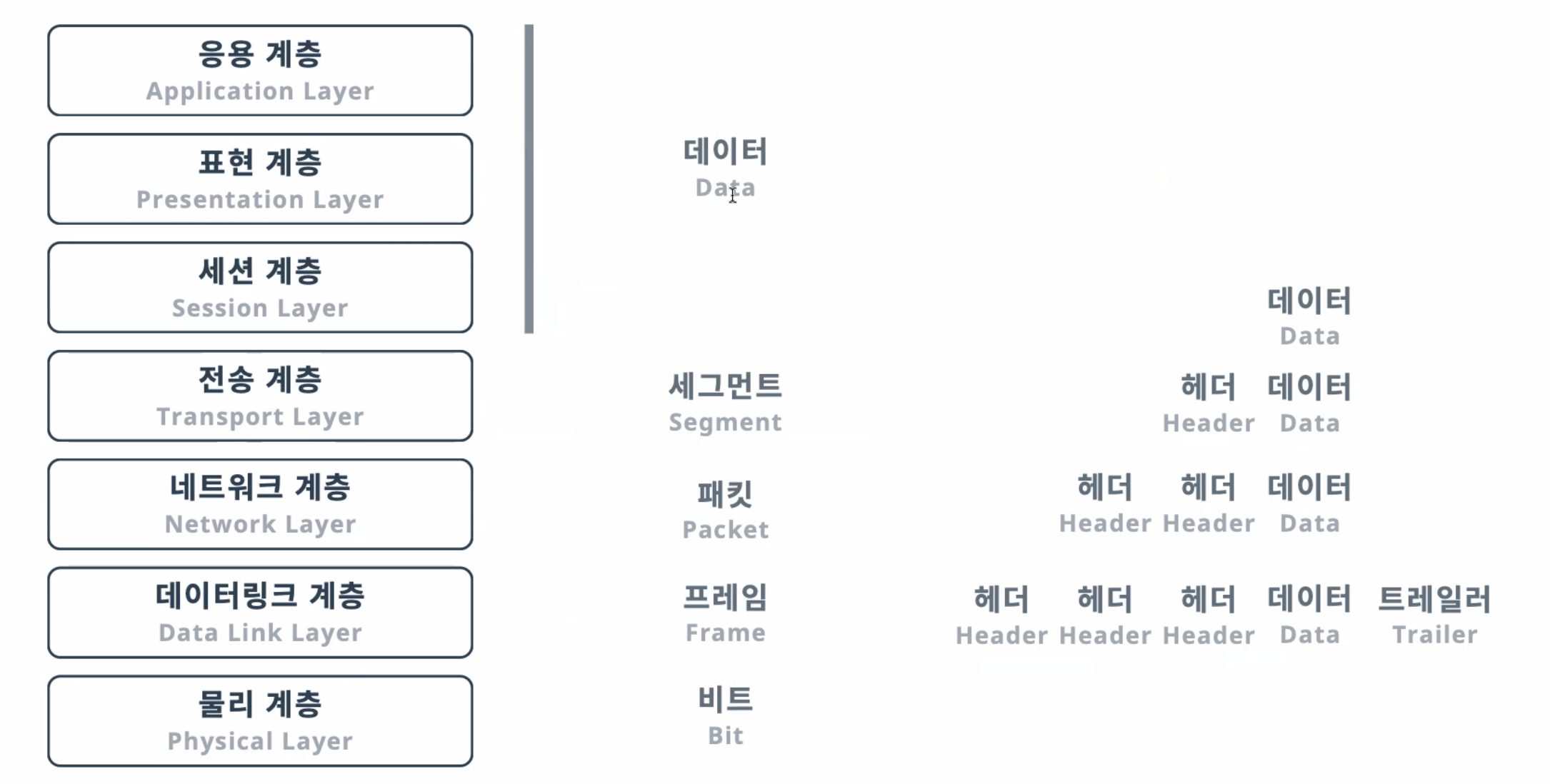
OSI 7계층
물리 계층 (Physical Layer)
전기 신호가 나가는 물리적인 장비로서 이 계층에서는 단지 데이터를 전달한다. 단지 데이터를 전기적인 신호로 변환해서 주고받는 기능만 있을 뿐이다.
- 데이터 전달 방식 : 비트
LAN Card
컴퓨터가 네트워크 연결과 데이터 전송을 할 수 있게 하는 컴퓨터의 통신장치
- 컴퓨터나 네트워크 장치가 데이터를 송수신할 때, 컴퓨터가 처리할 수 있는 형태로 데이터를 변환하는 역할
- 즉, 한 컴퓨터에서 처리된 데이터를 전기 신호로 변환해 네트워크 내 다른 컴퓨터로 전송하고, 이 전기 신호를 수신해 다시 컴퓨터가 처리할 수 있는 데이터로 변환하는 역할이다.
UTP Cable (Unschielded Twisted Pair)
네트워크 장치들 간에 데이터를 전송하는 물리적인 매체이다. (물리적인 경로를 제공) 예를 들어, 컴퓨터, 스위치, 라우터 등의 네트워크 장치 간에 데이터를 전달하는 역할을 수행한다. 일반적으로 구리로 되어있고, 광섬유로 구성되어있다. 랜 포트에 장착하고, 전기신호를 주고받는다.
HUB
네트워크 장치들 간에 데이터를 전달하는 장치로, 입력된 신호를 모든 포트로 동일하게 전송한다. 전송되는 데이터 신호를 정형하여 증폭해서 왜곡된 데이터들을 보정한다. 그러나 허브는 데이터를 전송할 때 '브로드캐스트' 방식으로 전송하여 네트워크 상의 모든 장치에게 데이터를 보내므로, 다른 장치들이 그 데이터를 받게 된다.
데이터 링크 계층 (Data Link Layer)
물리계층을 통해 송수신되는 정보의 오류와 흐름을 관리하여 안전한 정보의 전달을 수행할 수 있도록 도와준다. 따라서 통신에서의 오류도 찾아주고 재전송하는 기능을 가지고 있다. 데이터 링크 계층은 비트 스트림을 프레임으로 변환하고, 주소를 부여하고, 오류 검출 및 수정을 담당한다.
기능
1. 프레임화 : 물리 계층에서 전송된 비트들을 프레임이라는 단위로 묶는다.
2. 주소 지정: MAC 주소를 사용하여 프레임이 어떤 장비로 가야 할지 결정한다.
3. 오류 검사: 프레임에 오류가 발생했는지 확인하고, 오류가 있으면 다시 전송하도록 요청할 수 있다.
-
데이터의 신뢰성, 효율성과 관련된 것도 수행한다.
-
이 계층에서는 맥 주소를 가지고 통신하게 된다.
-
MAC 주소를 사용하여 프레임이 어떤 장비로 가야 할지 결정합니다.
-
데이터 전달 방식 : 프레임 (트레일러 포함)
이더넷 (Ethernet)
원칙적으로 하나의 인터넷 회선에 유/무선 통신장비 공유기, 허브 등을 통해 다수의 시스템이 랜선 및 통신포트에 연결되어 통신이 가능한 네트워크 구조 (네트워크를 구성하는 방식 중 한 방법)
CSMA/CD (Carrier Sense Multiple Access / Collision Detection
두 대 이상의 컴퓨터가 데이터를 보내는 상황을 충돌이라고 하는데, 이런 충돌 현상을 방지하기 위해 이더넷에서는 전류 강도를 확인하고 사용가능하면 데이터를 보낸다. 이더넷에서 충돌을 감지하기 위한 프로토콜이다
맥 주소 (Media Access Control Address)
컴퓨터 안의 LAN 카드 안에 할당된 고유한 값으로, 48비트로 표현할 수 있다. 랜카드를 만드는 회사에서 부여된다. MAC 주소 덕분에 네트워크를 통해 데이터가 출발지에서 목적지까지 정확하게 도착할 수 있다. (arp -p)
네트워크 통신 방식
유니 캐스트
네트워크에 다수의 대상이 있을 때 그 중 특정 대상이랑만 1:1 통신하는 방법
멀티 캐스트
네트워크에 다수의 대상이 있을 때, 그중 특정 대상들이랑만 1:N 통신하는 방법
브로드캐스트
네트워크에 다수의 대상이 있을 때, 그 모든 대상과 통신하는 방법 (전부 다에게 물어보는 것)
데이터링크 계층에서 전달되는 데이터
- 헤더 : 수신자 MAC 주소 | 송신자 MAC 주소 | 유형 (IPv4,IPv6...) -> 이더넷 헤더
- 데이터
- 트레일러
SWITCH
근거리 통신망(LAN)내의 장치를 연결하고 장치 간에 데이터 패킷을 전달하는 네트워킹 장치이다. 스위치는 MAC 주소를 사용하여 데이터 패킷을 식별하고 적절한 대상 장치로 전달하여 네트워크의 통신의 효율성을 향상시킨다.
- 데이터를 보내면 스위치에 연결된 컴퓨터에 데이터를 보내는 역할.
- 허브와의 차이점 : 입력된 데이터를 목적지에만 전송한다. (일괄 전송하지 않는다.)
- 맥 주소 필터링 : 스위치에는 맥 테이블이라는 게 존재한다. 연결된 장비들의 맥 주소를 기억하고, 비교 대조 후 목적지를 판단할 수 있다.
네트워크 계층 (Network Layer)
경로(Route)와 주소(IP)를 정하고 패킷을 전달해주는 역할
즉, 목적지까지 가장 안전하고 빠르게 데이터를 보내는 기능을 말한다. 따라서 최적의 경로를 설정해야 한다.
- 데이터 전달 방식 : 패킷
라우팅 (Routing)
출발점 라우터부터 끝점 라우터까지 최적의 경로를 찾는 것을 라우팅이라고 부른다.
라우터는 다른 라우터를 식별할 때 IP 주소를 사용한다. WAN의 상황에서 필요하다.
IP (Internet Protocol)
네트워크에 연결된 각 장치 식별을 위해 할당된 숫자 식별자. 사용 목적에 따라 공인 IP(Public IP)와 사설 IP(Private IP)로 구분된다. IP 주소는 네트워크에서 장치를 식별하고 찾는 데에 사용되어 데이터 패킷을 보내고 받을 수 있다.
IP는 다음과 같이 생겼다.
192.168.15.2 : 32비트로 구성이 되어있다.
각각의 바이트별로 .으로 구분하고, 음수 없이 양수로 나타낸다.
끝주소 0, 255 는 네트워크 주소와 브로드캐스트 때문에 사용하지 않는다.
네트워크 ID : (192.168.15)
호스트 ID : 2
ISP (Internet Service Provider)
KT, SKT, LG U+와 같은 인터넷 서비스를 제공하는 제공자. ISP에 연결되면, 연결과 동시에 공인 IP를 준다. 주기적으로 IP주소도 바꿔준다.
공인 IP (Public IP)
전 세계적으로 유일하게 식별될 수 있는 IP 주소이다. ISP로부터 할당받는다. 외부 네트워크와의 직접적인 연결을 제공한다. 영원히 고정적이지 않고, 바뀐다. (유동 IP)
사설 IP (Private IP)
내부 네트워크망에서만 사용하는 IP. 이 IP로는 외부 인터넷을 사용할 수 없다. 인터넷과의 연결은 라우터나 게이트웨이를 통해 이루어진다. 공인 IP를 받아서 내부 네트워크에서 사용하기 위해 분배해줄 때 사용하는 IP
192.168.15.2 : 32비트로 구성이 되어있다.
A class
(0 0~127). (0~255. 0~255. 0~255)
(네트워크 ID), (호스트 ID)
왜 127까지냐?
00000000. ... ~ 01111111.11111111. ....
루프백(Loop back) 주소 : Localhost (127.0.0.1)
B class
(1 0 128~191 . 0~255). (0~255. 0~255)
(네트워크 ID), (호스트 ID)
- ... ~ 10111111. 11111111. ...
C class
(1 1 0 192~223. 0~255. 0~255). (0~255)
(네트워크 ID), (호스트 ID)
- ... ~ 11011111.11111111. ...
- 일반적으로 사용하는 IP라고 생각해도 무방하다.
- C 클래스로도 약 5억 대의 컴퓨터를 처리할 수 있다.
A, B, C 클래스가 효율적일까?
비트가 남는 게 많아서 효율적이진 않다.
서브넷
하나의 네트워크가 분할된 작은 새로운 네트워크
작은 네트워크로 분할하는 것을 '서브네팅'이라고 한다.
호스트ID를 서브넷ID와 호스팅ID로 다시 나눠주는 것.

2분할 예시
네트워크 주소 172.16.0.0
서브넷 마스크 255.255.0.0
네트워크 ID/호스트 ID의 경계를 알기 위해 네트워크 ID는 1로 쭉 표현하겠다. 그래서 서브넷 마스크는 네트워크ID를 다 1로 만든 것이다.
2분할하게 되면, 네트워크 ID에게 1비트 더 주겠다는 것. 그리고 남은 비트는 재할당해서 분배하겠다는 것.
2분할 결과
서브넷1 주소 : 172.16.0.0/17
(17 : 네트워크 ID가 17비트를 사용한다는 것, 1의 개수, 17개니까 2분할 했다는 것도 알 수 있다.)
네트워크 주소 : 172.16.0.0
호스트 주소 범위 : 172.16.0.1 ~ 172.16.127.254 (0은 네트워크 주소이고 255는 브로드캐스팅이니까 빼고)
서브넷2 주소 : 172.16.128.0/17
네트워크 주소 : 172.16.128.0
호스트 주소 범위 : 172.16.128.1 ~ 172.16.255.254
전송 계층 (Transport Layer)
일련번호와 확인 응답번호를 이용하여 오류를 점검하는 기능과 컴퓨터가 데이터를 받았을 때 어떤 어플리케이션으로 가야할지 식별하는 기능을 한다. 양 끝단의 사용자들 간의 신뢰성있는 데이터를 주고 받게 해주는 역할을 한다. 오류 검출 및 복구, 흐름 제어와 중복검사 등을 수행한다. 데이터 전송을 위해 Port 번호가 사용된다. 대표적인 프로토콜로는 TCP와 UDP가 있다.
- 포트 번호를 사용하여 응용 프로그램 간의 통신을 관리합니다.
- Port 번호 : OS가 부여하는 프로그램 식별 번호
- 데이터 전송단위 : 세그먼트 (Segment)
포트
잘 알려진 포트 : 0 ~ 1023
사전 등록 포트 : 1024 ~ 49151
동적 포트 : 49152~65535
- 하나의 프로그램은 여러 Port 번호를 가질 수 있다.
- 여러 프로그램이 하나의 Port 번호를 가지는 것은 불가능하다.
자주 사용하는 포트, 알고 있으면 좋은 포트
| 포트 | 프로토콜 | 용도 |
|---|---|---|
| 20 | FTP | 파일 전송 프로토콜 |
| 22 | SSH | SSH, SFTP |
| 25 | SMTP | 이메일 전송 프로토콜 |
| 80 | HTTP | 웹 프로토콜 |
| 443 | HTTPS | 암호화 웹 프로토콜 |
- 원격 컴퓨터에 터미널로 접속할 때 22번, 파일을 전송할 때 20번 포트
- 근데 잘 알려진 포트(Well-Known Port)이기에 보안적으로 취약하다.
- 자연스레 쓰다보면 외워지기에, 따로 외울 필요는 없다.
3 Way Handshake
본격적으로 상대 클라이언트와 연결하기 전에 가상 연결을 해서 패킷을 보내며 확인하는 동작이다.
SYN : 접속 요청
ACK : 요청 수락
| 이름 | 의미 |
|---|---|
| SYN | 연결을 생성할 때 클라이언트가 서버에 시퀀스 번호를 보내는 패킷 |
| SYN-ACK | 시퀀스 번호를 받은 서버가 ACK 값을 생성하여 클라이언트에게 응답하는 패킷 |
| ACK | ACK 값을 사용하여 응답하는 패킷 |
- 클라이언트 -> 서버 : SYN 패킷 전송
- 서버 -> 클라이언트 : SYN + ACK패킷 전송
- 클라이언트 -> 서버 : ACK + 데이터 패킷 전송
- 데이터 패킷 전송
WEB
WWW (World Wide Web)
인터넷 위에서 동작하는 하이퍼 텍스트 기반 정보 공유 시스템
Hyper Text
문자를 뛰어넘는 ! 문서를 초월한 문서
하이퍼링크를 통해 페이지와 페이지를 연결해준다.
HTML (Hyper Text Markup Language)
HyperText(웹 페이지에서 다른 페이지로 이동할 수 있도록 하는 것) 기능을 가진 문서를 만드는 언어이다. 구조를 설계할 때 사용하는 언어로 hyper link 시스템을 가지고 있으며, 흔히 말하는 웹 페이지를 위한 마크업 언어라고 할 수 있다.
웹 브라우저
Chrome, FireFox, Opera, Safari, Microsoft Edge
Web Server
Apache Httpd, Nginx
- 클라이언트가 요청한 정적인 콘텐츠를 HTTP 프로토콜을 통하여 제공해주는 서버이다.
- 정적 콘텐츠 : 이미 작성되어있는 문서 형태의 정보
Client : 정보를 받는 주체
Server : 정보를 제공해주는 주체
- 동적 컨텐츠 요청이 클라이언트로부터 들어왔을 때, 해당 요청은 웹 서버에서 처리할 수 없기 때문에 컨테이너로 보내주는 역할을 한다.
WAS (Web Application Server)
Tomcat, Jetty
- 웹 서버로부터 오는 동적인 요청을 처리하는 서버
- 웹 서버와 컨테이너를 붙여놓은 서버
- 8080 포트를 가져간다.
리버스 프록시(Reverse Proxy)
클라이언트가 요청할 때 직접 웹 서버에 요청하는 것이 아닌 애플리케이션 서버 앞에 설치된 Proxy Server에 요청을 하고 Proxy Server가 애플리케이션 서버로 데이터를 요청하고 클라이언트 측에게 응답하는 방식
즉, 중간 매개체 역할
역할
-
부하 분산: Reverse Proxy는 여러 WAS 서버들 간에 부하 분산을 할 수 있다. 예를 들어, 여러 WAS 서버가 있을 때, Reverse Proxy가 요청을 적절한 서버로 분배하여 서버에 과부하가 걸리지 않도록 한다.
-
보안 강화: 클라이언트는 Reverse Proxy와만 상호작용하고, 실제 WAS 서버는 외부에 직접 노출되지 않기 때문에 보안적으로 유리하다. 예를 들어, DDOS 공격을 방어하거나, SSL 종료(SSL termination) 등의 작업을 Reverse Proxy가 처리할 수 있다.
-
캐싱: Reverse Proxy는 동적 컨텐츠를 캐시하여 성능 향상을 할 수 있다. 예를 들어, 자주 요청되는 데이터나 페이지를 캐시하여 WAS에 대한 부하를 줄이고, 클라이언트에 빠르게 응답할 수 있다.
-
SSL 종료: SSL 암호화 및 복호화 작업을 Reverse Proxy가 대신 처리하게 할 수 있다. 이 방식은 WAS 서버가 SSL을 처리할 필요 없이, 암호화 작업을 Reverse Proxy에서 맡겨서 서버의 부하를 줄이는 방식이다.
Front-End Web Application
React, Vue, Angular
- React 공부하는 걸 추천 ! -> Next.js : React의 풀스택 버전
Back-End Web Application
Express.js, nest (node.js)
django, Flask, FastAPI (python)
spring (java)
HTTP 프로토콜 (Hyper Text Transfer Protocol)
서버와 클라이언트가 서로 데이터를 주고받기 위해 사용되는 통신 규약
웹 문서 간에 링크를 통해 연결할 수 있는 프로토콜이며, 문서뿐만 아니라 HTML, TEXT, IMAGE, 음성, 영상, 파일, JSON, XML(API) 등 거의 모든 형태의 데이터를 폭 넓게 전송할 수 있다. 기본적으로 80번 포트를 사용한다.
GET HTTP://LOCALHOST:8080/
USER-AGENT:INTELLIJ HTTP CLIENT/INTELLIJ IDEA 2024.1.6
ACCEPT-ENCODING: BR, DEFLATE, GZIP, X-GZIP
ACCEPT:*/*
CONTENT-LENGTH: 0HTTPS
암호화하는 방식, 보안 방식이 추가된 것
HTTP에 보안을 추가한 버전으로, SSL/TLS 프로토콜을 사용하여 암호화된 통신을 제공한다. 기본적으로 443 포트를 사용한다.
url (Uniform Resource Locater)
https://www.example.com:8080/docs/page.html?a=10&b=value#section2
네트워크 상에서 리소스(웹 페이지, 이미지, 동영상 등의 파일)가 위치한 정보를 나타낸다.
해당 자원의 위치, Path를 의미한다.
프로토콜 : https
호스트명 : www.example.com
포트 : 8080
경로 : docs/page.html
? : 원하는 값을 넘겨줄 수 있다.
쿼리 : a=10&b=value
프래그먼트 :#section2
uri (Uniform Resource Identifier)
jdbc://[user[:password]@]localhost:3306/hello?charset=UTF-8#example
통합 자원 식별자, 인터넷의 자원을 식별할 수 있는 문자열을 의미한다.
리소스를 식별하는 고유한 식별자로, 리소스가 어디에 있는지, 어떤 이름을 가지고 있는지 등을 포함할 수 있다. URL은 URI의 하위 개념이다.
스키마 : jdbc
권한 : [user[:password]@]
호스트 : localhost
포트 : 3306
경로 : hello
쿼리 : charset=UTF-8
프래그먼트 : #exmaple
HTTP의 무상태성 (Stateless)
무상태(Stateless) : 클라이언트와 서버 사이에 통신 상태를 유지하지 않는다. 좀 더 쉬운 말로, 서버가 이전 요청을 기억하지 않는다.
장점 : 서버 확장성 높음(스케일 아웃)
단점 : 클라이언트가 추가 데이터 전송 (메모리 사용 커진다)
무상태(Stateless)
-
서버가 클라이언트의 상태를 보존하지 않는다.
-
홈페이지에서 회원 로그인을 하고 페이지를 옮겼는데 또 로그인을 하라는 페이지가 뜬다. 왜냐하면 서버는 클라이언트의 상태를 보존하지 않기 때문에 그 클라이언트가 회원인지 모르기 때문이다.
따라서 무상태 환경에선 회원 정보를 서버가 아닌 클라이언트가 토큰 형태로 들고 있으면서, 서버와 통신할때 실어 보내 인증하는 식이다.
이러한 무상태 환경은 클라이언트가 상태 정보를 갖고 있는 것이기 때문에, 아무 서버나 호출해도 되기 때문에 서버의 스케일아웃(수평확장)에 유리하다.
HTTP의 비연결성 (Connectionless)
HTTP는 기본이 연결을 유지하지 않는 모델이다. 즉, 서버와 클라이언트의 Connection 연결을 지속하지 않는다. HTTP가 요청과 응답 후 연결을 끊어버리는 특성이다.
- HTTP의 비연결성은 클라이언트와 서버가 데이터를 주고받은 후, 연결을 끊는다는 특징이다.
- HTTP에서 서버는 요청을 처리한 후 클라이언트와의 연결을 끊는다. 즉, 클라이언트가 서버에 요청을 보내면, 서버는 응답을 처리하고, 응답을 보낸 후 연결을 닫는다.
- 서버는 요청에 대해 응답을 끝내면 더 이상 그 연결에 대해 기억하거나 유지하지 않는다. 다시 말해, 서버는 이전 요청에 대한 정보를 보존하지 않는다.
Stateless와 Connectionless 차이
Stateless(무상태성) : 필요한 상태에 대한 정보를 클라이언트가 가지고 오기 때문에 클라이언트의 요청에는 어느 서버가 응답해도 상관 없다. 따라서 클라이언트의 요청이 대폭 증가하면 서버를 증설해 해결할 수 있다.
Connectionless (비연결성): 클라이언트가 서버에 요청을 하고 응답을 받으면 바로 TCP/IP 연결을 끊어 연결을 유지하지 않음으로써 서버의 자원을 효율적으로 관리하고 수 많은 클라이언트의 요청에 대응할 수 있게 한다.
HTTP 요청 (HTTP Request)
start-line : 시작라인 header : 헤더 empty line : 공백 라인 (CRLF) message body
start-line(request line)
POST/login/HTTP/1.0 : HTTP Method / path(URL) / version of Http
- Method : GET, POST, PUT, DELETE 등
header
Host:ww.example.com
Content-Type:application/json
User-Agent:Mozilla/5.0
Content-Length:27- 요청에 대한 정보가 들어있는 메타성 데이터
body
username=user&password=1234
- 클라이언트가 서버에게 실제 전송할 데이터(HTML 문서, 이미지, 영상, JSON 등)
HTTP 응답 (HTTP Response)
Status Line header empty line body
start-line(status line)
HTTP/1.1 200 OK : version of Http / status code / status message
- status code : 클라이언트가 보낸 요청이 성공인지 실패인지 숫자 코드로 나타낸다.
- status message : status code에 대한 결과를 사람이 이해할 수 있는 글로 표현
header
Date:Sun, 13 Oct 2024 00:00:00 GMT
Server:Apache/2.4.54(Ubuntu)
Content-Type:text/html
Content-Length:125multipart/form-data: 파일 전송을 포함하는 데이터를 서버로 보낼 때, 데이터를 여러 부분(파트)으로 나누어 전송하는 방식이다. 헤더에서 Content-Type으로 정의하며, 여러 데이터 조각(텍스트, 파일 등)을 하나의 HTTP 요청에 포함하여 서버로 보내는 방식입니다.
body
<html>
<body>Hello,World!</body>
</html>- 서버가 클라이언트에게 응답할 데이터
HTTP Method
클라이언트와 서버 사이에 이루어지는 요청(Request)과 응답(Response) 데이터를 전송하는 방식이다. 쉽게 말하면 서버에 주어진 리소스에 수행하길 원하는 행동, 서버가 수행해야 할 동작을 지정하는 요청을 보내는 방법이다.
GET
서버에서 리소스를 조회
POST
서버에 데이터를 전송하여 새로운 리소스 생성
- html form 방식으로는 GET, POST만 가능하다.
PUT
서버의 기존 리소스를 전체 수정
PATCH
서버의 기존 리소스를 일부 수정
DELETE
서버에 있는 리소스를 삭제
HTTP Status Code
상태 코드는 클라이언트가 보낸 요청의 처리 상태를 응답에서 알려주는 기능으로서, 3자리 숫자로 만들어져 있으며, 100 ~ 500번대 숫자로 이루어져 있다.
1xx (정보)
요청 수신 후 처리중에 있음 (요청을 받았으며 프로세스를 계속 진행)
2xx (성공)
요청이 정상적으로 처리되었음
3xx (리다이렉션)
요청한 리소스의 위치로 이동함 (요청 완료를 위해 추가 작업 조치가 필요)
4xx (클라이언트 오류)
요청한 내용에 오류가 있음
5xx (서버 오류)
요청에는 문제가 없으나 서버에 문제가 있음
데이터 베이스
- 방대한 데이터를 체계적으로 저장, 관리, 검색할 수 있도록 도와주는 필수적인 기술
- 체계적으로 조직된 데이터(자료)의 집합체로, 특정 목적을 위해 데이터를 효율적으로 저장하고 관리할 수 있는 시스템(체계)
관계형 데이터베이스 (Relational Database)
테이블 형식으로, 데이터와 데이터 간의 관계(Relation)를 정의하는 구조를 가지고 있으며, 각 테이블은 행(Row)과 열(Column)로 이루어져있다. RDB는 SQL(Structured Query Language)을 사용하여 데이터를 다룰 수 있다.
- 행 : 각 속성에 대한 값을 담고 있는 레코드 (예: 특정 학생의 정보)
- 열 : 데이터 가지고 있는 속성(특성), 각각의 속성(예: 이름, 나이, 주소)을 표현
EX) Oracle DB, MySQL, MariaDB, PostgreSQL
NoSQL 데이터베이스 (No SQL Database)
비관계형 데이터베이스로, 전통적인 RDB의 테이블 기반 구조를 사용하지 않고, 다양한 데이터 모델을 지원한다. NoSQL 데이터베이스는 대용량의 비정형 데이터를 효율적으로 처리할 수 있으며, 고성능과 높은 확장성을 제공한다.
EX) MongoDB, Redis
객체지향 데이터베이스 (Object-Oriented Database)
데이터를 객체로 표현하는 데이터베이스이다. 객체지향 프로그래밍의 개념을 데이터베이스에 적용한 시스템이다. 객체와 객체 간의 관계를 저장하고 관리하며, 객체지향 언어와의 통합성이 높다. 객체지향 데이터베이스는 복잡한 데이터 구조를 관리하는데 유리하며, 객체의 상속, 다형성 등의 개념을 데이터베이스에서도 사용할 수 있다.
EX) ObjectStore, ZODB
분산 데이터베이스 (Distributed Database)
여러 네트워크에 분산된 데이터베이스를 하나의 통합된 시스템처럼 관리하는 데이터베이스 시스템이다. 이 데이터베이스는 데이터가 여러 서버에 분산되어 저장되며, 고가용성, 확장성, 성능 향상을 목표로 한다. 분산 데이터베이스는 클라우드 환경에서 자주 사용되며, 대규모 데이터 처리와 실시간 데이터 접근에 적합하다. 설계가 어렵다.
EX) cassandra, amazon DynamoDB
데이터 웨어하우스 (Data Warehouse)
데이터베이스에서 발생하는 기록, 로그를 분석할 때 사용하는 것
쿼리나 분석같은 것을 수행하는 용도로만 사용된다. 일반적으로 애플리케이션 로그파일, 트랜젝션 로그파일 등이 수집되어 분석되고 보관된다.
EX) Google Big Query, amazon REDSHIFT
기타 데이터베이스
그래프 데이터베이스 등 다양한 데이터베이스가 존재한다.
오늘 궁금했던 것
Q1. 데이터 링크 계층에서 전달하는 데이터 전달방식은 프레임인데, 이 계층에서 사용하는 스위치는 데이터 패킷을 전달한다고 해서 헷갈렸다.
A1. 스위치는 MAC주소를 기반으로 프레임을 전달한다. 하지만, 이 프레임 안에 네트워크 계층의 패킷이 포함될 수 있다. 스위치는 데이터 링크 계층에서 작동하면서도 프레임 내부의 패킷을 포함하고 있기 때문에 패킷을 전달한다고 표현할 수 있다.
Q2. 허브는 연결된 모든 컴퓨터에게 다 알리는 브로드캐스팅 방식을 선택하고, 스위칭은 일괄 전송을 하지 않는다. 그렇다면, 1계층에서 허브, 2계층에서 스위칭을 사용하면 뭔가 이상한 거 아닌가? 다 알린다는 거야..? 목표 지점에만 보낸다는 거야? 만약에 둘 중 하나만 쓰면 특정 계층이 불안정한 건가? (특정 계층을 대표하는 장치를 사용하지 않아도 괜찮은 건가?)
A2. 모든 OSI 7계층은 서로 독립적으로 존재한다. 특정 장치의 기능에 집중할 것이 아니라 특정 계층이 하는 역할, 기능에 집중해야 한다. 간단히 말하자면, 물리 계층은 데이터를 물리적 전기 신호로 전달하는 것이 목표이고, 데이터링크 계층은 주소 지정(MAC)과 프레임 전송을 목표로 한다. 각 계층에서 이것만 잘 수행하면 되는 것이다.
즉, 허브, 스위칭을 둘 다 사용한다고 해도, 허브는 전기 신호를 전달하고, 스위치는 이 신호를 MAC 주소 기반으로 전달하는 것이다.
느낀점
오늘도 버텼다 ! .. ! 오늘은 네트워크 & 데이터베이스 맛보기 정도로 수업을 나갔는데, 확실히 어제 복습을 해두니까 오늘 수업 제일 초반 복습시간에 내가 따라잡은 내용이 맞는지, 빠뜨린 내용은 없는지 확인하기 좋았다. 또, 역시 아니까 .. ㅎ 더 재미있드라!!! 덕분에 집중해서 들을 수 있었다 ! 그리고 이후에 나가는 진도들도 집중해서 들으니 이해하기 쉬웠고, 어제 걱정했던 강의자료의 부재는 날 그렇게 괴롭히지 않았다. 수업 중 그래도 참고할 만한 사이트들을 옆에 띄워놓고 같이 들으니 이해하기 쉬웠던 것 같다. 그래도 이 추상적인 네트워크 개념을 이해하려니 어려운 점들이 있었다. 그래서 복습 시간에 궁금했던 것도 찾아보면서 오늘 내용 복습을 하였다 ! 이젠 데이터베이슨데... 백엔드 찍먹하면서 느꼈던 것이.. 데이터베이스가 정말 백엔드에서 중요하다는 거였다. 그래서 정말 빡 집중해서 잘 들어봐야겠다 !!
나 이제 TIL 적는 게 꽤 익숙해졌잖아? 칭찬해 아주 그냥 ~ :)
