
오늘 배운 것
데이터 베이스
- 방대한 데이터를 체계적으로 저장, 관리, 검색할 수 있도록 도와주는 필수적인 기술
- 체계적으로 조직된 데이터(자료)의 집합체로, 특정 목적을 위해 데이터를 효율적으로 저장하고 관리할 수 있는 시스템(체계)
관계형 데이터베이스 (Relational Database)
테이블 형식으로, 데이터와 데이터 간의 관계(Relation)를 정의하는 구조를 가지고 있으며, 각 테이블은 행(Row)과 열(Column)로 이루어져있다. RDB는 SQL(Structured Query Language)을 사용하여 데이터를 다룰 수 있다.
- 행 : 각 속성에 대한 값을 담고 있는 레코드 (예: 특정 학생의 정보)
- 열 : 데이터 가지고 있는 속성(특성), 각각의 속성(예: 이름, 나이, 주소)을 표현
EX) Oracle DB, MySQL, MariaDB, PostgreSQL
NoSQL 데이터베이스 (No SQL Database)
비관계형 데이터베이스로, 전통적인 RDB의 테이블 기반 구조를 사용하지 않고, 다양한 데이터 모델을 지원한다. NoSQL 데이터베이스는 대용량의 비정형 데이터를 효율적으로 처리할 수 있으며, 고성능과 높은 확장성을 제공한다.
EX) MongoDB, Redis
객체지향 데이터베이스 (Object-Oriented Database)
데이터를 객체로 표현하는 데이터베이스이다. 객체지향 프로그래밍의 개념을 데이터베이스에 적용한 시스템이다. 객체와 객체 간의 관계를 저장하고 관리하며, 객체지향 언어와의 통합성이 높다. 객체지향 데이터베이스는 복잡한 데이터 구조를 관리하는데 유리하며, 객체의 상속, 다형성 등의 개념을 데이터베이스에서도 사용할 수 있다.
EX) ObjectStore, ZODB
분산 데이터베이스 (Distributed Database)
여러 네트워크에 분산된 데이터베이스를 하나의 통합된 시스템처럼 관리하는 데이터베이스 시스템이다. 이 데이터베이스는 데이터가 여러 서버에 분산되어 저장되며, 고가용성, 확장성, 성능 향상을 목표로 한다. 분산 데이터베이스는 클라우드 환경에서 자주 사용되며, 대규모 데이터 처리와 실시간 데이터 접근에 적합하다. 설계가 어렵다.
EX) cassandra, amazon DynamoDB
데이터 웨어하우스 (Data Warehouse)
데이터베이스에서 발생하는 기록, 로그를 분석할 때 사용하는 것
쿼리나 분석같은 것을 수행하는 용도로만 사용된다. 일반적으로 애플리케이션 로그파일, 트랜젝션 로그파일 등이 수집되어 분석되고 보관된다.
EX) Google Big Query, amazon REDSHIFT
기타 데이터베이스
그래프 데이터베이스 등 다양한 데이터베이스가 존재한다.
데이터 베이스 트랜잭션 (Database Transaction)
데이터베이스의 트랜잭션은 데이터베이스 내에서 수행되는 작업의 단위이다. 데이터의 일관성과 무결성을 유지하기 위해 설계된 중요한 개념이다. 트랜잭션은 데이터베이스에 대한 일련의 연산을 하나의 작업 단위로 묶어서 처리한다.
ACID
Atomicity(원자성), Consistency(일관성), Isolation(격리성), Durability(지속성)
원자성 (Atomicity)
트랜잭션 내의 모든 연산은 원자적인 단위로 처리되어야 하며, 트랜잭션이 모두 수행되거나 모두 취소되어야 한다. 일부 성공, 일부 실행 이런 건 없다.
일관성 (Consistency)
트랜잭션이 완료가 되면 데이터베이스의 상태는 일관적으로 유지되어야 한다. 트랜잭션 전후에 데이터베이스는 정의된 모든 규칙과 제약 조건을 만족해야 한다.
격리성 (Isolation)
트랜잭션이 동시에 실행되는 상황에서, 트랜잭션이 서로의 작업에 영향을 미치지 않도록 보장하는 원칙으로, 각 트랜잭션은 독립적으로 실행된다. 잠금이라는 형태로 보장해준다.
지속성 (Durability)
트랜잭션이 완료되면, 그 결과는 데이터베이스에 영구적으로 저장되어야 한다.
트랜잭션 상태
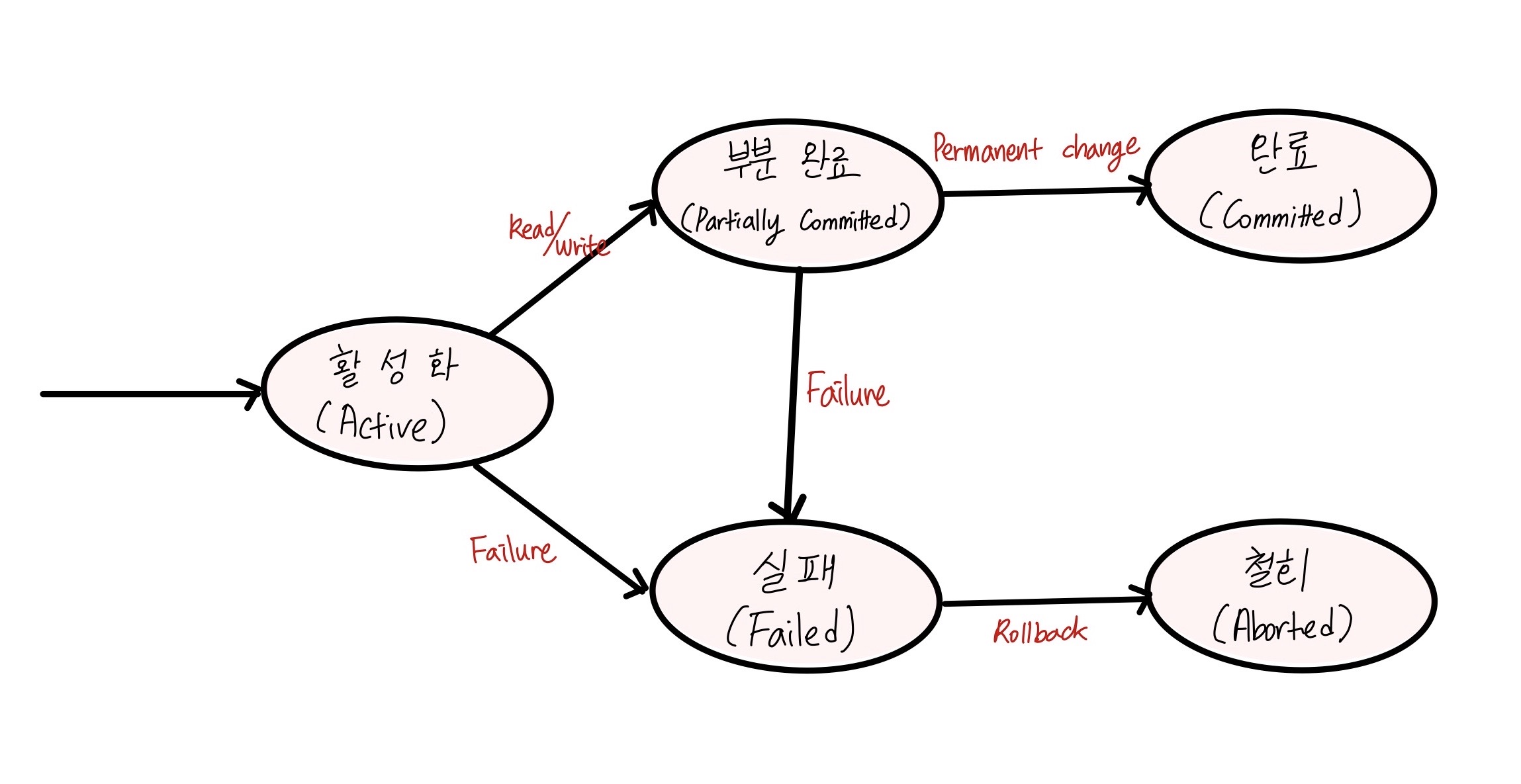
활성(Active)
트랜잭션이 작업을 시작하여 실행 중인 상태
부분 완료(Partially committed)
트랜잭션의 마지막 연산까지 실행하고 commit 요청이 들어온 직후의 상태.
최종 결과를 데이터베이스에 아직 반영하지 않은 상태
완료(Committed)
트랜잭션이 성공적으로 종료되어 commit 연산을 실행한 후의 상태
실패(Failed)
트랜잭션에 오류가 발생하여 실행이 중단된 상태
철회(Aborted)
트랜잭션이 비정상적으로 종료되어 Rollback 연산을 수행한 상태
세이브 포인트
ROLLBACK할 포인트를 지정하는 것
데이터베이스 관리 시스템 (DBMS)
컴퓨터의 시스템에서 데이터베이스를 관리하고 조작하는 소프트웨어
데이터의 저장, 검색, 업데이트, 삭제 등의 작업을 수행한다.
RDBMS : 관계형 데이터베이스 관리 시스템
DBMS는 서버에서 실행되고, 클라이언트의 요청에 따라 데이터를 관리한다.
관계형 데이터베이스 관리 시스템 (RDBMS)
테이블 예시
| 구분 | 이름 | 직책 | 이메일 |
|---|---|---|---|
| 1 | 민수 | 사원 | minzhu@example.com |
| 2 | 주성 | 대리 | zhuxing@example.com |
스키마 (Schema)
- 하나의 데이터베이스 내에서 테이블 구조와 제약조건을 정하는 설계도
- 데이터베이스의 전반적인 구조를 알 수 있다.
- 데이터의 구조와 조직을 정의하는 명세(Description)
- 데이터가 규칙에 맞게 저장되는 것을 보장할 수 있다.
- 데이터의 일관성을 보장한다.
테이블 (Table)
- 테이블, 엔티티, 릴레이션 : 하나의 주제를 중심으로 데이터를 저장
- 데이터를 구조화하고 저장하는 기본 단위
키 (Key)
데이터베이스 테이블의 행을 고유하게 식별하거나 테이블 간의 관계를 정의하는 데 사용되는 수단
기본 키 (Primary Key)
주키라고도 불리며, 테이블의 각 행을 고유하게 식별할 수 있는 열(또는 열의 집합)이다. 기본 키는 중복된 값이나 NULL을 허용하지 않으며, 일반적으로는 자동 증가(AUTO INCREMENT)을 사용하여 관리한다.
외래 키 (Foreign Key)
한 테이블의 열이 다른 테이블의 기본 키를 참조하는 제약 조건이다. 외래 키는 테이블 간의 관계를 정의하고, 참조 무결성을 보장한다.
유니크 키 (Unique Key)
열의 값이 테이블 내에서 중복되지 않도록 보장하는 제약조건이다. 기본 키와 비슷하지만 NULL을 허용한다는 점에서 다르다.
복합 키 (Composite Key)
두 개 이상의 열을 조합하여 테이블의 각 행을 고유하게 식별하는 키
행 (Row)
- 행, 튜플, 레코드 : 데이터를 표시하기 위한 역할
- 각 행은 고유한 개체를 나타낸다.
열 (Column)
- 열, 속성 : 속성에 따라 필드에 오는 값이 결정된다.
- 각 열은 데이터의 특정 속성을 나타낸다.
- 열에는 제약조건(Constraint) 및 인덱스(index)를 설정할 수 있다.
엑셀과 비슷한 거 아닌가? NO ! 엑셀 vs 데이터베이스 차이점
1. 데이터를 조작하고 관리하는 방법
2. 데이터에 접근할 수 있는 자
3. 데이터의 양
RDBMS 예시
Oracle
규모가 있는 기업군에서 자주 사용되는 RDB 중 하나
- 대규모 트랜잭션 처리
- 비용이 비싸다.
MSS (Microsoft SQL Server)
Microsoft에서 만든 RDBMS
- 윈도우 서버 환경에 최적화 (요즘에는 Ubuntu 등에서도 사용할 수 있도록 범용성)
- 데이터 분석, 처리 기능
PostgreSQL
- Web, 연구에서도 많이 사용
- 플러그인을 자유롭게 지원할 수 있도록 해준다.
MySQL
- 경량 RDBMS
- 리눅스 서버에서 이용
- 간단한 프젝부터 복잡한 프젝까지 사용 가능
MariaDB
- MySQL와의 호환성이 좋다.
- MySQL과 동일한 SQL 구문을 사용한다.
- 분산 데이터베이스 환경 제공
구조화 질의 언어 (Structured Query Language)
관계형 데이터베이스 관리 시스템(RDBMS)에서 정의, 조작, 제어, 검색 등을 수행하는 데 사용되는 표준화된 프로그래밍 언어
데이터 정의 언어(Data Definition Language, DDL)
RDBMS에서 데이터베이스 구조를 정의하고 수정하는 데 사용되는 명령어 집합이다. DDL의 주요 목적은 데이터베이스의 객체를 생성, 수정, 삭제하는 것이다.
| 명령어 | 내용 |
|---|---|
| CREATE | 새로운 데이터베이스 객체를 생성하는 데 사용됩니다. 가장 일반적인 용도로는 테이블, 인덱스, 뷰 등을 만드는 데 사용됩니다. |
| DROP | 데이터베이스 객체를 삭제하는 데 사용됩니다. |
| ALTER | 기존 데이터베이스 객체의 구조를 변경하는 데 사용됩니다. |
| TRUNCATE | 특정 테이블의 모든 데이터를 삭제하지만 테이블의 구조는 유지하는 명령어입니다. |
데이터 조작 언어(Data Manipulation Language, DML)
RDBMS에서 데이터를 조작하는 데 사용되는 명령어 집합이다. DML의 주된 목적은 데이터베이스 내의 데이터를 삽입, 수정, 삭제, 조회하는 것이다. DML은 사용자가 데이터베이스에 저장된 데이터를 직접적으로 다룰 수 있게 하며, 데이터의 추가, 갱신, 제거 등 다양한 작업을 수행할 수 있다.
| 명령어 | 내용 |
|---|---|
| SELECT | 데이터베이스에서 데이터를 조회(검색, 질의)하는 데 사용됩니다. |
| INSERT | 새로운 데이터를 테이블에 삽입(등록)하는 데 사용됩니다. |
| UPDATE | 기존 데이터를 수정하는 데 사용됩니다. |
| DELETE | 테이블에서 데이터를 삭제하는 데 사용됩니다. |
데이터 제어 언어(Data Control Language, DCL)
데이터베이스에서 데이터의 접근 권한과 보안을 관리하는 명령어 집합이다. DCL은 데이터베이스 관리자가 특정 사용자나 사용자 그룹에 대해 데이터베이스 객체에 대한 접근 권한을 부여하거나 철회하는 데에 사용된다. DCL을 통해 데이터베이스의 무결성과 보안을 유지하며, 적절한 사용자만이 특정 데이터에 접근하고 조작할 수 있도록 제어할 수 있다.
| 명령어 | 내용 |
|---|---|
| GRANT | 특정 사용자나 사용자 그룹에게 데이터베이스 객체에 대한 권한을 부여하는 데 사용됩니다. |
| REVOKE | 이미 부여된 권한을 철회하는 데 사용됩니다. |
SQL 자료형
숫자 자료형
BIT, BOOL, TINYINT, SMALLINT, MEDIUMINT, **INT**, INTEGER, BIGINT(**LONG**), FLOAT, **DOUBLE**, **DECIMAL**문자 자료형
**CHAR**, **VARCHAR**, BINARY, VARBINARY, TINYTEXT, **TEXT**, MEDIUMTEXT, **LONGTEXT**, TINYBLOB, BLOB, MEDIUMBLOB, LONGBLOB, ENUM, SET- CHAR : CHAR(10)을 하고 두 글자만 넣으면, 열 글자를 다 채운다. 공백으로 채운다.
- VARCHAR : VARCHAR(10)를 하고, 두 글자를 넣으면, 두 글자만큼만 들어간다. 공백으로 채우지 않는다.
- BLOB : 파일 같은 걸 집어넣을 수 있다.
데이터베이스에는 이미지, 파일 등을 넣지 않음.
날짜 자료형
DATE, **DATETIME**, TIMESTAMP, TIME, YEAR- DATE : 'YYYY-mm-DD' 형식
- DATETIME : (YYYY-MM-DD HH:MM:SS) 형식
- TIMESTAMP : (YYYY-MM-DD HH:MM:SS) 형식, TIME_ZONE 변수 영향
쿼리 (Query)
사용자
CREATE USER
'ID'@'host'
IDENTIFIED BY
'PWD'
;GRANT
... // 어떤 권한을 줄 건지
ON
database.table
TO
'ID'@'host'
;데이터베이스
데이터베이스 생성
CREATE DATABASE [데이터베이스 이름];데이터베이스 제거
DROP DATABASE [데이터베이스 이름];데이터베이스 전체 조회
SHOW DATABASES;데이터베이스 사용
USE [데이터베이스 이름];테이블
테이블 생성
CREATE TABLE
[테이블 이름](
[컬럼 이름] TYPE constraint,
...
KEY [컬럼 이름] REFERENCES [타겟테이블 이름]([컬럼 이름])
)
;SELECT
[컬럼 이름] [as alias], //alias : 별칭
FROM
[테이블 이름]
[CONDITIONS]
;테이블 데이터 조회
SELECT [컬럼이름], [...]
[FROM 테이블명]
[JOIN 다른 테이블 이름]
[ON 조건]
[WHERE 데이터 추출 조건절]
[GROUP BY 컬럼 이름]
[HAVING 그룹화 조건절]
[ORDER BY 컬럼 이름 [ASC | DESC]]
[LIMIT offset, 조회할 행의 갯수];SELECT 구문 작동 순서
- FROM: 가장 먼저 데이터베이스가 쿼리에 지정된 테이블에서 데이터를 가져온다. JOIN절이 포함되어있다면 해당 테이블간 결합을 수행한다.
- JOIN: 여러 테이블을 결합하여 단일 데이터 세트를 생성한다.
- WHERE: JOIN 또는 FROM 절에서 가져온 데이터에 대해 필터링이 이루어진다. 이 단계에서 지정된 조건에 맞는 행들만 남겨지고 나머지 행들은 제외된다.
- GROUP BY: 남은 데이터가 지정된 열 또는 표현식에 따라 그룹화된다. 각 그룹은 고유한 그룹 식별자에 따라 하나의 행으로 결합된다.
- HAVING: GROUP BY로 생성된 그룹에 대해 추가적인 필터링이 이루어진다. WHERE 절과 비슷하지만, 그룹화된 데이터에 대한 조건을 필터링할 때 사용된다.
- SELECT: 이 단계에서 실제로 선택된 열들이 반환된다. SELECT 절에서 정의된 열 또는 표현식이 출력된다.
- ORDER BY: SELECT된 결과가 지정된 열이나 표현식에 따라 정렬된다. 기본 정렬 순서는 오름차순
- LIMIT: 결과에서 반환할 행의 수를 제한한다. MySQL에서는 결과의 일부만 가져올 수 있다.
테이블 조인 (Join)
여러 테이블을 결합하여 하나의 결과 집합으로 만드는 데 사용되는 기능이다. JOIN은 이 분할된 데이터를 다시 결합함으로써 사용자가 필요한 정보를 통합적으로 조회할 수 있다. JOIN을 사용하면 서로 다른 테이블 간의 논리적 관계를 기반으로 데이터를 검색할 수 있다.
INNER JOIN
교집합과 같은 개념으로, 조건에 일치하지 않는 데이터는 결과에서 제외된다. 테이블 1과 테이블2에서 공통되는 키를 기준으로 데이터를 결합하면, 두테이블 모두에서 일치하는 행들만 결과에 포함된다.
LEFT JOIN
왼쪽 테이블의 모든 행과, 그에 일치하는 오른쪽 테이블의 행을 결합한다. 일치하는 데이터가 없는 경우에도 왼쪽 테이블의 모든 행이 결과에 포함되며, 오른쪽 테이블에서 일치하지 않는 데이터는 NULL로 표시된다.
RIGHT JOIN(RIGHT OUTER JOIN)
오른쪽 테이블의 모든 행을 포함하고, 왼쪽 테이블에서 일치하는 데이터를 결합한다. 일치하지 않는 왼쪽 테이블은 NULL로 표시된다. LEFT JOIN과 바꿀 수 있다. 테이블 선택 순서를 바꿔주면 된다.
FULL JOIN(FULL OUTER JOIN)
왼쪽 테이블과 오른쪽 테이블의 모든 데이터를 포함하는 결합 방식이다. 왼쪽 또는 오른쪽 테이블에만 존재하는 데이터도 포함되며, 어느 한 쪽 테이블에만 있는 데이터는 NULL로 표시된다.
FULL JOIN vs UNION
JOIN은 테이블의 구조가 달라도 같은 값을 가지는 속성을 통해 테이블을 연결할 수 있지만, UNION은 테이블의 구조가 다르면 연산 자체가 불가능하다.
결합되는 방식의 차이점
JOIN 은 테이블의 컬럼이 추가되는 형식으로 데이터가 옆으로 연결됩니다.
UNION 은 데이터가 추가되는 형식으로 아래에 연결됩니다.
ON
JOIN절과 함께 사용되며, 테이블 간의 결합 조건을 정의한다. ON절에서 지정된 조건은 두 테이블 간의 관계를 설정하고, 데이터가 어떻게 결합될지를 결정한다.
< 표 1 > 선수 명단
| 번호 | 이름 | 팀 번호 |
|---|---|---|
| 1 | 김ㅇㅇ | 1 |
| 2 | 이ㅇㅇ | 2 |
| 3 | 박ㅇㅇ | 1 |
| 4 | 최ㅇㅇ | 2 |
< 표 2 > 팀 명단
| 팀 번호 | 이름 |
|---|---|
| 1 | 1팀 |
| 2 | 2팀 |
- 번호, 팀 번호 : 주키
- <표 1> 테이블은 <표 2> 테이블의 주키인 팀 번호를 외래키로 가지고 있다.
- ON절에서는 선수 명단의 팀 번호와 팀 명단의 팀 번호를 비교하여 두 테이블을 합칠 수 있도록 비교를 수행한다.
- ON 절에 조건이라기 보단, 다음에 오는 것들을 비교하여라.. 의 느낌인 것 같다.
엔티티-관계 다이어그램 (Entity-Relation Diagram)
Entity 개체와 Relation 관계를 중심적으로 표시하는 데이터베이스 구조를 한 눈에 알아보기 위해 그려놓는 다이어그램
엔티티
정의 가능한 사물 또는 개념
데이터베이스의 테이블이 엔티티로 표현된다.
엔티티 속성
개체가 갖고 있는 속성을 포함한다.
데이터베이스의 테이블의 각 필드(컬럼)들이 엔티티 속성
엔티티 관계
- One-to-One : 하나의 엔티티가 하나를 포함
- One-to-Many : 하나의 엔티티가 여러 개를 포함
- Many-to-Many : 여러 개의 엔티티가 여러 개를 포함
오늘 어려웠던 것
백엔드 찍먹하면서 ERD 설계하는 게 제일 어려웠는데,, 이 부분이 빠르게 지나가서 이 정도만 알고도 괜찮은 건가..? 싶기도하고, 아니면 이 외의 것들은 자습에 맡긴다는 건가..? 싶기도 하고 .. ㅠㅠ 실습하면서 다시 해주시려나..? 사실 다시 ERD 설계를 해봐야 알겠지만, 어떤 엔티티를 만들어야하는지, 엔티티와 엔티티 간의 관계를 설정하는 것 .. 다 너무 어려웠던 걸로 기억한다. 나만 어렵나.. ㅠ
팀 활동 후기
팀원분들이랑 항상 어려운 걸 나누면 나만 어려운 게 있다. 하핫 사실 나도 와 어려워서 어지럽다 후 울고 싶다 이 정도로 어려운 건 아니고,, 난 강의를 볼 때 복습의 관점으로 아~ 오케이 오케이 이런 Chill한 수준이 아닌, 강의 끝나고 자습 시간 때 한 번 더 정리를 하면서 보고 그 외에 또 모르는 건 검색을 해봐서 공부를 해야 이해가 더 잘 되는 정도라.. ㅠ 하루하루 빡빡하게 열심히 하고는 있는데, 내가 오늘 강의 정리 할 때 다른 분들은 오늘 강의 흡수 + 이외의 것들을 더 하고 있으니 조금 내가 잘못하고 있는 건가 ? 싶긴하다. 물론 나도 스터디 공부, 알고리즘 문제 등등을 풀고 있지만, TIL 이후에 시간을 쓰는 거니까.. 나도 복습의 관점으로 아는 거 확인하면서 강의를 듣고 싶다 하핫 ! 그치만 지금 안 하면, 똑같은 내용을 나중에 다시 배운다 했을 때 나중에도 복습의 관점으로 못 보겠지. 그니까 지금 열심히 하자 내가 할 수 있는 것을 !! :) 이라고 생각해본다. 허허
느낀점
오늘 SQL 실습도 해보고 재미있었다 ! 아직도 ERD가 참.. 마음에 걸리긴 하지만, 데이터베이스 .. 아직까진 괜찮은 걸로 (아니 모르겠다 사실) :,)
예전에 그냥 막 mysql 사용하고 할 때보다, 하나씩 여긴 뭐가 들어가야 하고~ 이런 걸 배우니까 유익했던 것 같다 ! 알고 보니 보이는 것도 많은 너낌..?
어제 늦게 자서 그런가 오전에 피곤함은 좀 있었다. 근데 뭐 잠온다까진 아니고,, 이제 수요일.. 수.ㅎㅎ.요일..ㅎ 금요일 언제 와? 그래도 내일만 버티면 곧 금요일이다 !!! 파이팅 하자 !!!!!!
오늘의 응원
나에게 보내는 응원이지만, 누구에게나 해주고 싶은 말 .. !
남들과 비교하지 말고,, ! 너에게 집중하고 최선을 다 하자 !
넌 이미 잘 하고 있어 !!! 아자 아자 :)
