
(1) DB(데이터베이스)와 DBMS(데이터베이스 관리 시스템)
- DB : 데이터 = 데이터의 나열 : CSV 혹은 EXCEL 같은것
- DBMS : 데이터 + 엔진 : (데이터 / 스키마 조작, 쿼리 최적화) + 관리 : DB 에 대한 CRUD 엔진, 관리 등 제공
데이터에 대한 스키마(테이블) 정의(DDL), 저장 및 분석(DML)
그리고 관리를 제공하는 응용 프로그램
프로그램을 생성하는 다양한 언어 및 엔진이 있는 것처럼
DB 도 데이터에 대한 다양한 DBMS 가 존재- 데이터
- 엔진 (스키마 / 데이터 조작, 쿼리 최적화 포함)
- 정의, DDL
: 스키마(메타데이터)에 대한 CRUD (테이블 만들고, 변경하고 삭제하고)- 스키마 : 데이터베이스의 구조와 제약 조건을 정의한 것
- 조작, DML (저장, 분석)
: 데이터에 대한 CRUD + JOIN, AGG 등을 통한 분석
- 정의, DDL
- 관리 : 계정, 노드 개수, 메모리, 네트워크, 커넥션 풀 관리 등
(2) 관계형 데이터베이스 & 비관계형 데이터베이스
1. 관계형 데이터베이스 (RDBMS) : 행렬 | 관계 | Fixed Schema
- 행렬 : 2차원 배열 데이터 → 복잡한(다차원) 데이터 표현하기엔 한계 = Relation 이 필요한 이유
- 관계 : 복잡한(다차원) 데이터를 → 다수의 2차원 Entity(테이블)들로 분할 (PK-FK)
- Fixed Schema : 고정된 Column 정의대로 데이터 적재
관계형 데이터베이스 (RDBMS, SQL) 특징 상세
-
High Reliability 고신뢰성
= Data Integrity 데이터 무결성 (ACID-compliant, ACID 준수 -
Guaranteed Consistency (강력한, 보장된 Consistency)
개발자 혹은 어플리케이션 레벨에서 잠재적으로 비일관 Inconsistent 데이터에 대한 신경 불필요- Pessimistic Lock : 데이터베이스가 알아서 처리
= 데이터베이스 빌트인 Lock
= Pessimistic Concurrency Control
- Pessimistic Lock : 데이터베이스가 알아서 처리
-
Transaction 지원
- 데이터 변조가 일어나지 않는다 ← High Reliability 고신뢰성 = Data Integrity 데이터 무결성 보장
- 데이터 변조를 방지하기 위한 Transaction : Operation 의 독립성, 고신뢰성과 무결성 보장
패키지 여행 예약 서비스 예시를 통한 Transaction 동작 원리 이해
패키지 여행의 구매는 아래의 요소들 모두 예약 완료 필수
- 항공권 (1) 가는 편, (2) 오는 편
- 기차표 (1) 가는 편, (2) 오는 편
- 숙소 1박
본 예시에서 트랜젝션은 아래와 같이 상위 1개, 하위 3개로 구성
- 패키지 여행 구매 Transaction (1 부모 = 3 자식)
- 왕복 항공권 구매 Transaction
- 왕복 기차권 구매 Transaction
- 숙소 1박 구매 Transaction
1. 롤백 케이스 : 하위 트랜젝션
- 왕복 항공권 구매 Transaction 에서
- (1) 가는편 예약 완료
- (2) 오는편 예약 중 에러 발생 시
- 왕복 항공권 구매 Transaction 에 Rollback 발생
- (1) 가는편 예약 취소
2. 롤백 케이스 : 상위 트랜젝션
- 왕복 항공권 구매 Transaction, 왕복 기차권 구매 Transaction 예약 모두 완료
- 숙소 1박 구매 Transaction 도중 해당 숙소에 방이 존재하지 않아 예약 실패
- 숙소 1박 구매 Transaction 에 Rollback 발생
- 상위 패키지 여행 구매 Transaction 에 Rollback 전이
- 하위 왕복 항공권 구매 Transaction Rollback 전이 (1) (2) 왕복 예약 취소
- 하위 왕복 기차권 구매 Transaction Rollback 전이 (1) (2) 왕복 예약 취소
= 결과적으로는 성공했었던 모든 예약 Rollback
- 매 번 DBMS 에서 Operation(Query) 수행이 될 때마다 트랜잭션을 생성
- Application 에서도 DBMS 에 Query 수행 시 DBMS 의 트랜잭션을 활용
- Application 백엔드 개발자에게 있어 트랜잭션은 DB 활용의 전부
- 데이터 구조 형태 : 2차원(행렬) 구조 데이터 + 관계(Relation) 기반 데이터 간 종속성 표현
- Fixed Schema
- 관계형(DB : 2차원 구조 데이터) ↔ 객체지향(Application : 트리 구조 객체 데이터) 이형 ⇒ ORM
- 빠른 분류, 정렬, 탐색 속도 : 자체 쿼리 최적화
(Parsing → Query Plan → Query Optimization)
- 단점 : 스키마 수정이 어려우며, 수평적 확장에 한계
→ 불만이면 NoSQL 쓰세요- RDBMS 에선 수평적 확장을 해도, Guaranteed Consistency 보장을 위해 대기 시간 증가
- Fixed Schema
ACID : Transaction 성질 (트랜잭션이 안전하게 수행된다는 것을 보장하기 위한 성질)
- Atomicity 원자성
: 완벽하게 수행이 되거나 / 완벽하게 수행이 되지 않거나- Consistency 일관성 = Guaranteed Consistency 일관성
- 데이터 정합성(Data Integrity)의 정의
: 0 + 1 = 1 → 1 + 1 = 2
1. 데이터 저장 시 모든 제약 조건들을 만족
2. 데이터 조작 발생 직후, 조회 시 최신 값을 확인 가능- Isolation 격리성
: 동시에 다수 쿼리가 발생 시 모든 쿼리 당 트랜잭션은 독립(고립) = 직렬화
- Isolation Level (격리 수준)
: Transaction 독립(고립)의 정도에 대한 정의
- 0 Level : Read Uncommitted 정책 하에서는 에러 Dirty Read 발생
- 1 Level : Read Committed 정책 하에서는 에러 Non-Repeatable Read 발생
- 2 Level : Repeatable Read 정책 하에서는 에러 Phantom Read 발생
- 3 Level : Serializable 정책에서는 어떠한 에러도 발생하지 않으나, 시간(성능) 하락
- 위배 시 “Could not serialize access due to concurrent update” 발생
- Isolation Level (격리 수준) 을 통해 독립(고립)의 정도를 정의
- 데이터베이스 : 데이터베이스에 기본 설정 + 쿼리마다 세부 설정 가능
- 어플리케이션 : 쿼리마다 세부 설정 가능 (DB 호출 함수에 각각에 대해, Spring JPA)
- Durability 지속성
: 어떠한 이슈에도 데이터는 지속적으로 존재 ← 로그 및 백업을 통한 보완
관계형 데이터베이스 (RDBMS, SQL) 종류
관계형 데이터베이스는 정형화된 2차원(행렬) 데이터 구성을 갖기에,
수많은 RDBMS 종류가 있어도 쿼리만 다를 뿐
= 쿼리 문법이나 쿼리 수행 시 최적화 방식의 차이
- 쿼리 문법
: 표준 ANSI SQL 문법을 기반으로 DBMS 각자 독자적인 기능을 위한 다양한 SQL Dialect - 쿼리 수행 시 최적화 방식
: Query Optmization, 어떻게 적은 탐색 비용으로 더 빠르게 결과를 반환할 지
2. 비관계형 데이터베이스 (NoSQL) : 비정형 | 비관계 | Schemaless
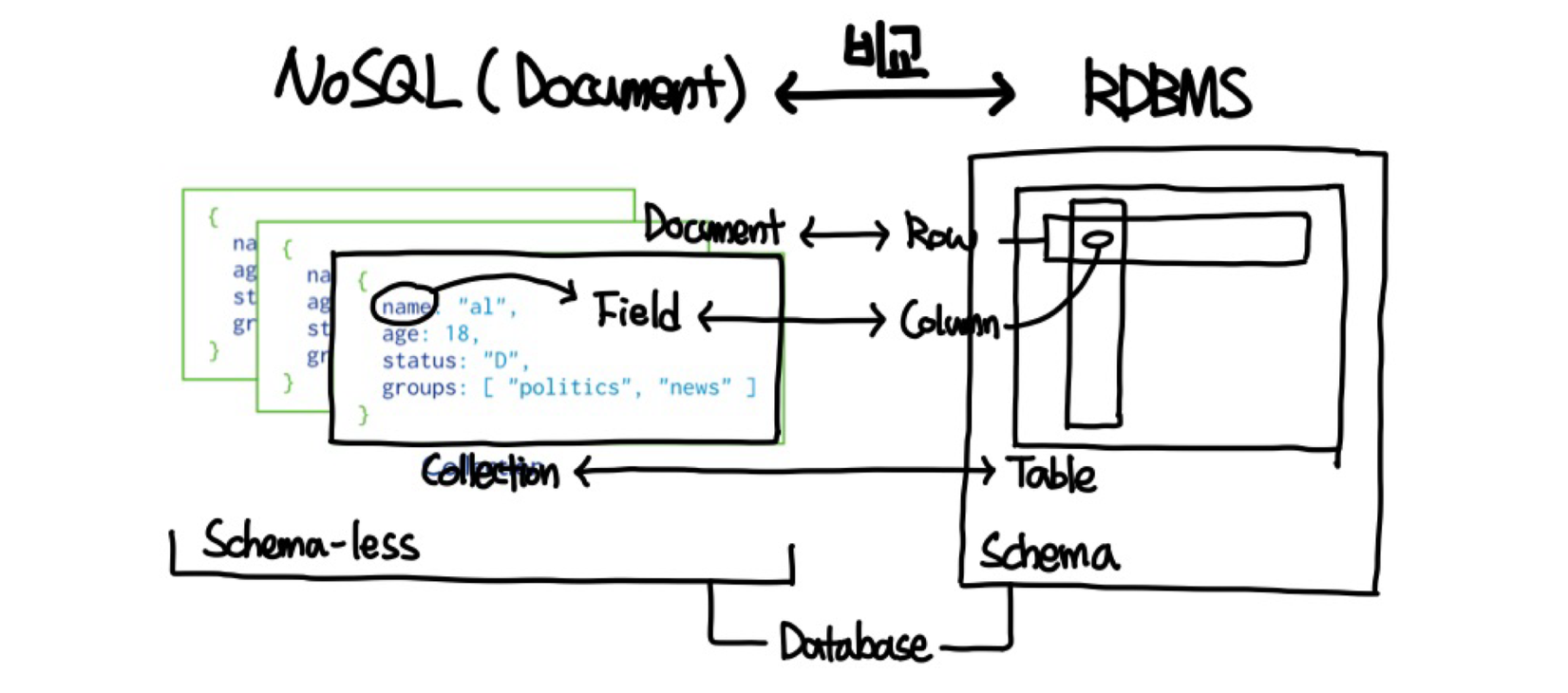
- 비정형 (자유) : 복잡한(다차원) 데이터 → Key-Value 나 JSON 형태로 저장
- 비관계 : 한 데이터에 수많은 (차원의) 데이터가 들어가있기에 관계가 불필요
- Schemaless : 무엇이든 Key-Value 로 데이터 적재
{
"Id": 1,
"Name": "Seonga",
"Car": {
"Name": "Sonata",
"Eng": "X기통",
"Size": "준중형"
}
}비관계형 데이터베이스 (NoSQL) 특징 상세
-
High Scalability 확장성, Availability 가용성
: 이 둘 특성은 사실상 분산 시스템의 특성 -
Eventual Consistency (어쨌든 Consistency)
: 개발자 혹은 어플리케이션 레벨에서 잠재적으로 비일관 Inconsistent 데이터에 대한 신경 필요- Optimistic Lock
: 소프트웨어적으로 개별 처리 필요= 소프트웨어적 Lock
= Optimistic Concurrency Control(OCC) 혹은 Non-locking Concurrency Control
- Optimistic Lock
-
Transaction 미지원
- 데이터 변조 가능성 존재 ← Data Integrity 데이터 무결성 비보장
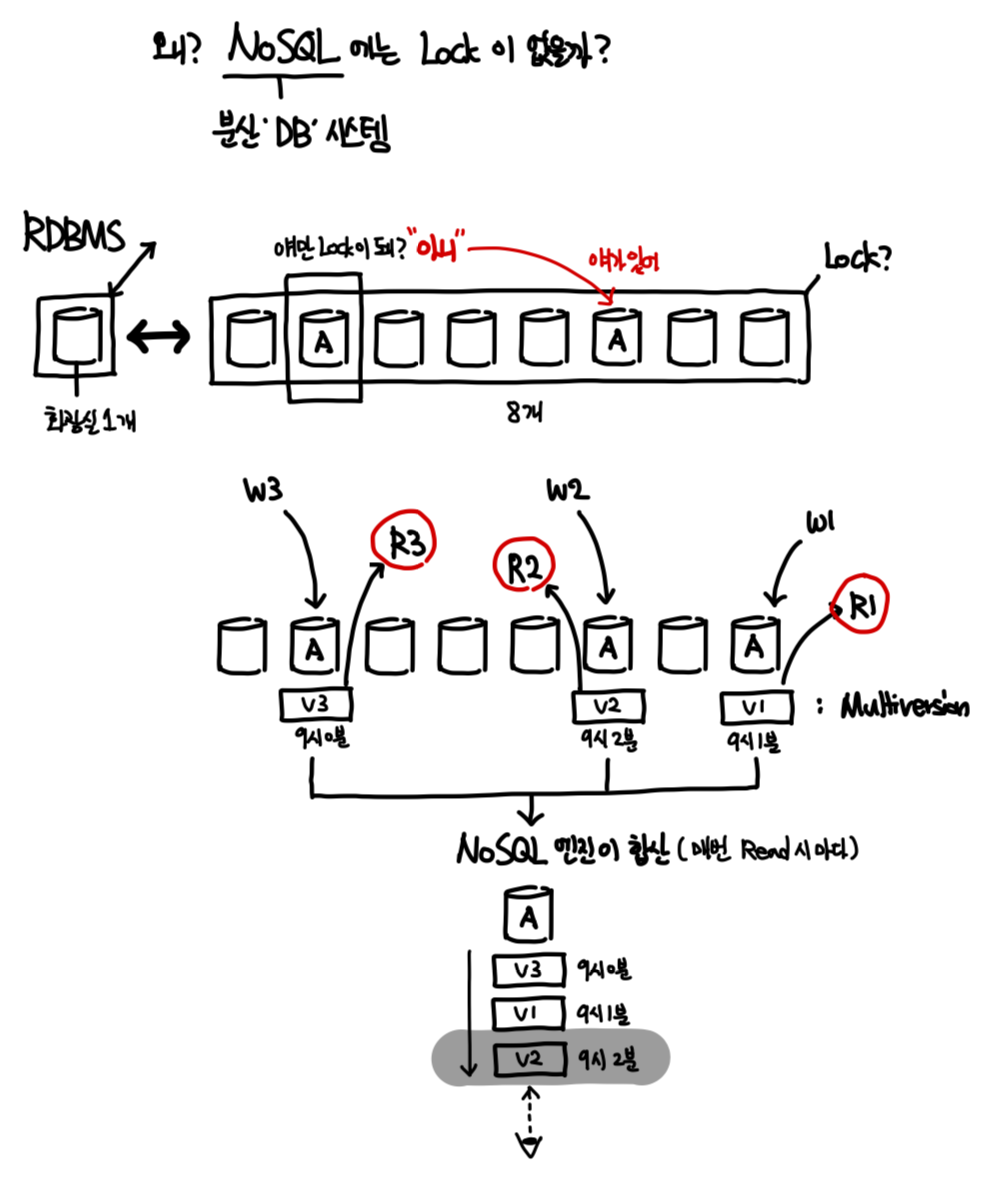
Q. "왜 NoSQL 에는 Lock 이 없을까?"
A. 수많은 NoSQL 분산 데이터베이스 노드 각자 다른 Write 인입 - 8개 분산 데이터베이스 노드 중 1개에 대해 Lock 적용 시, 다른 노드에 Write 되니 무의미**
- 8개 분산 데이터베이스 노드 모두에 대해 Lock 적용 시, 모든 노드에 대한 접근 불가 = 성능 저하
- 데이터 구조 형태
: 트리 구조 데이터 = (그 자체로) 트리 기반 데이터 간 종속성 표현- NoSQL 은 왜 등장했나?
: 웹 2.0 과 빅데이터 시대에 빅데이터 특성에 따른 무한 확장 가능한 DB 필요
- 비정형성
: 복잡한 데이터 구조 저장 가능, 불확실성 높은 데이터 우선 쌓고보자
→ Schemaless- 웹 2.0 JSON, XML 포맷 및 빅데이터 등장으로 복잡한 데이터 형태 저장 필요
- 대용량
: 방대한 트래픽 및 데이터양의 처리
→ 수평적 확장에 유리한 분산 저장 및 효율적 쿼리- 며칠 안에 수테라바이트가 쌓이는 상황에서 수직적 확장 시, 매 번 인스턴스 교체 필요
- 단점 : 데이터 무결성 제약이 미약 → 불만이면 RDBMS 사용
- NoSQL 은 왜 등장했나?
BASE 염기성 : ACID 의 데이터 무결성을 희생하고, 확장성 및 가용성을 얻기위해 Transaction 포기
BASE 데이터베이스는 ACID 의 데이터 일관성을 버리는데, BASE 의 기본 컨셉 중 하나가 데이터 일관성은 데이터베이스가 처리할 것이 아니라 개발자가 처리해야할 문제라는 것
- Basically Available (기본적인 가용성)
: 분산 시스템의 특징, 부분 고장 시 나머지가 커버- Soft state (소프트 상태)
= Eventual Consistency (어쨌든, 최종적으로는 일관성)
- ACID 에서의 Guaranteed Consistency 보다 훨씬 느슨
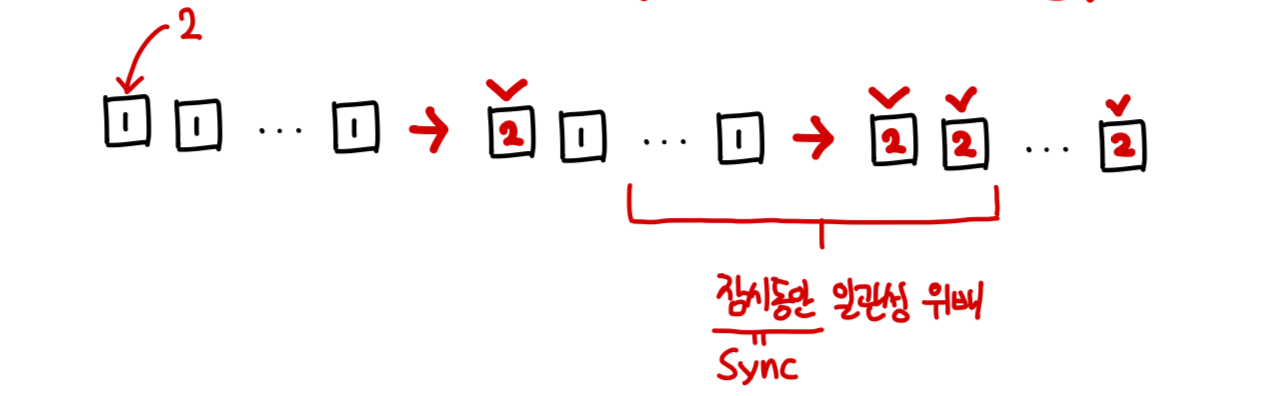
- UPDATE, DELETE, INSERT 시 순간적(일시적)으로 일관성이 깨지는 상태가 존재
- 분산 시스템 특성 상, 일부에선 최신 상태를 보유
- 일정 시간 후에는 전체 분산 시스템이 동기화되어 일관성이 있는 상태가 되는 성질
: 0 + 1 = 1 (Write 이전) → 1 + 1 = 1 (Write 직후, Sync 이전) → 1 + 1 = 2 (Sync 완료)
비관계형 데이터베이스 (NoSQL) 의 종류\
- Key-Value DB : Redis
- Redis 로 저장할 수 있는 모든 데이터 타입 및 주요 타입
String, Hash, List, Set, Sorted Set 등[ 사진 출처 : Key-value NoSQL Database ]
[ 사진 출처 : Redis representation of temporal data ]
- Document DB : MongoDB, CouchDB (CouchBase = memcached + CouchDB)
- Document = JSON 으로 생각
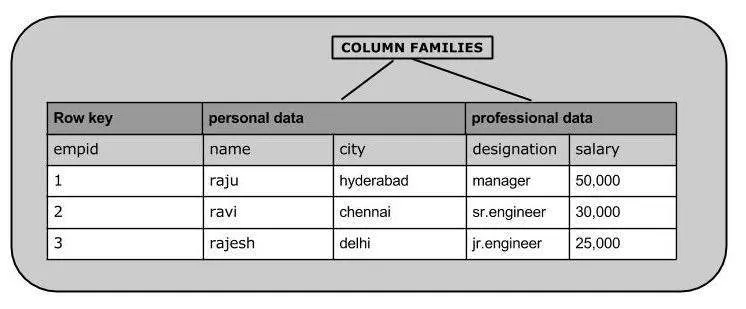
- Column DB : Cassandra, HBase
- Row-Oriented vs Column-Oriented
(Columnar 혹은 C-Store) : 락커룸 내 축구화 섹션
- Row-Oriented : 앞서 배운 RDBMS
- Column-Oriented (Columnar) : 대부분 NoSQL 중 Column DB (일부는 RDBMS 도 존재)
- 장점
데이터 분석을 위해 사용, 빅데이터 쿼리 시 굉장히 빠른 결과 도출, 높은 확장성
- Aggregation 데이터 분석 쿼리
: 그룹/서브그룹 데이터에서 단일 데이터를 계산해내는것
- 그룹/서브그룹 데이터 : GROUP BY, HAVING
- 단일 데이터를 계산 : COUNT, SUM, AVG, MIN, MAX
- Scalability 높은 확장성 : Large Cluster 내 사실상 무한으로 확장 가능
- Massive Parallel Processing 빅데이터 (병렬처리) 쿼리
- 단점
굉장히 느린 SELECT * (ALL) ← 모든 Column 들을 모아서 Row 를 생성해야하기 때문- 결론
Aggregation 필요하면 Column DB 사용 / Row 단위 조회가 많으면 RDBMS 사용
- Graph DB : Neo4j
- 테이블 간 관계(Relationship)가 아닌 데이터 간 관계(Relationship) 정의
CAP Theorem
- CAP Theory
: 분산 시스템은 3개 특성을 모두 만족할 수 없다는 이론, 최대 2개 보장 가능- Consistency 일관성
: UPDATE, INSERT, DELETE 시 모든 노드가 같은 값을 가져야함 - Availability 가용성
: 분산 시스템 중 일부가 실패해도 나머지는 정상적으로 서비스 - Partition Tolerance 파티션 허용
: 네트워크 장애에 대한 내결함성(Fault Tolerance)
- Consistency 일관성
(3) 관계형 데이터베이스 & 비관계형 데이터베이스 비교
| 특징 | 관계형 데이터베이스 (RDBMS) | 비관계형 데이터베이스 (NoSQL) |
|---|---|---|
| 구조 | 행렬 / 관계형 / Fixed Schema | 비정형 (자유) / 비관계형 / Schemaless |
| 신뢰성 | High Reliability (고신뢰성) | High Scalability (확장성) |
| 데이터 무결성 | Data Integrity (정합성) | Eventual Consistency |
| Consistency 보장 | Guaranteed Consistency | Optimistic Lock (개발자가 직접 처리) |
| Lock 처리 | Pessimistic Lock (DB가 알아서 처리) | Optimistic Lock (개발자가 직접 처리) |
| 트랜잭션 지원 | Transaction 지원 | Transaction 미지원 |
| 성질 | ACID (원자성, 일관성, 고립성, 지속성) | BASE (확장성 및 가용성 중심) |
