
1. Scaling : Partitioning, Sharding, Replication
1. (Vertical) Partitioning : 컬럼(열) 쪼개기
하나의 테이블을 여러 데이터로 쪼개어 저장하는 것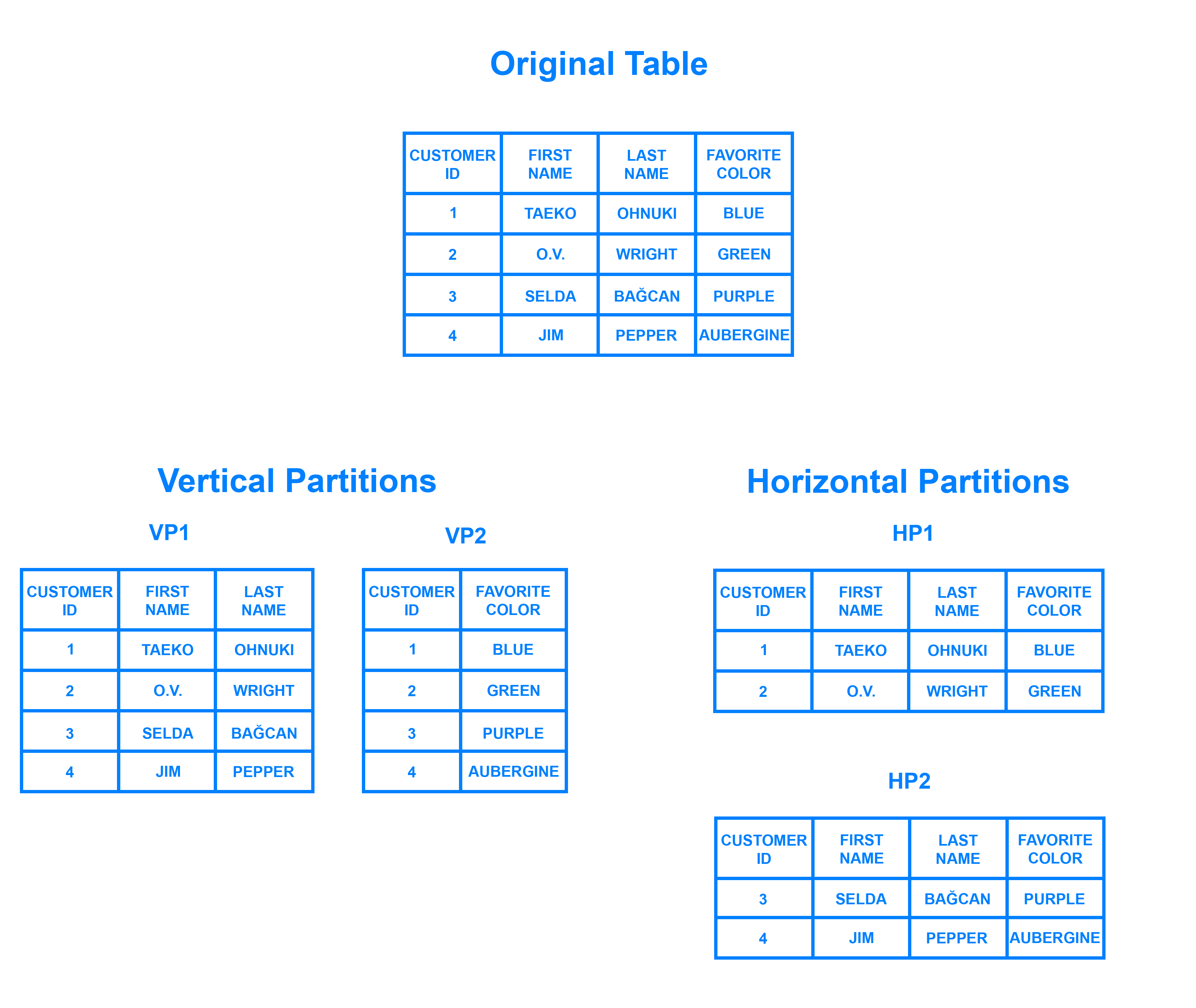 [ 사진 출처 : Understanding Database Sharding ]
[ 사진 출처 : Understanding Database Sharding ]
2. Horizontal Partitioning = Sharding : 로우(행) 쪼개기
- Range-based Sharding
: 알파벳, 한글 순서 혹은 값의 순서로 차등 분리 - Hash-based Sharding
: 해시 함수를 통해 균등 분리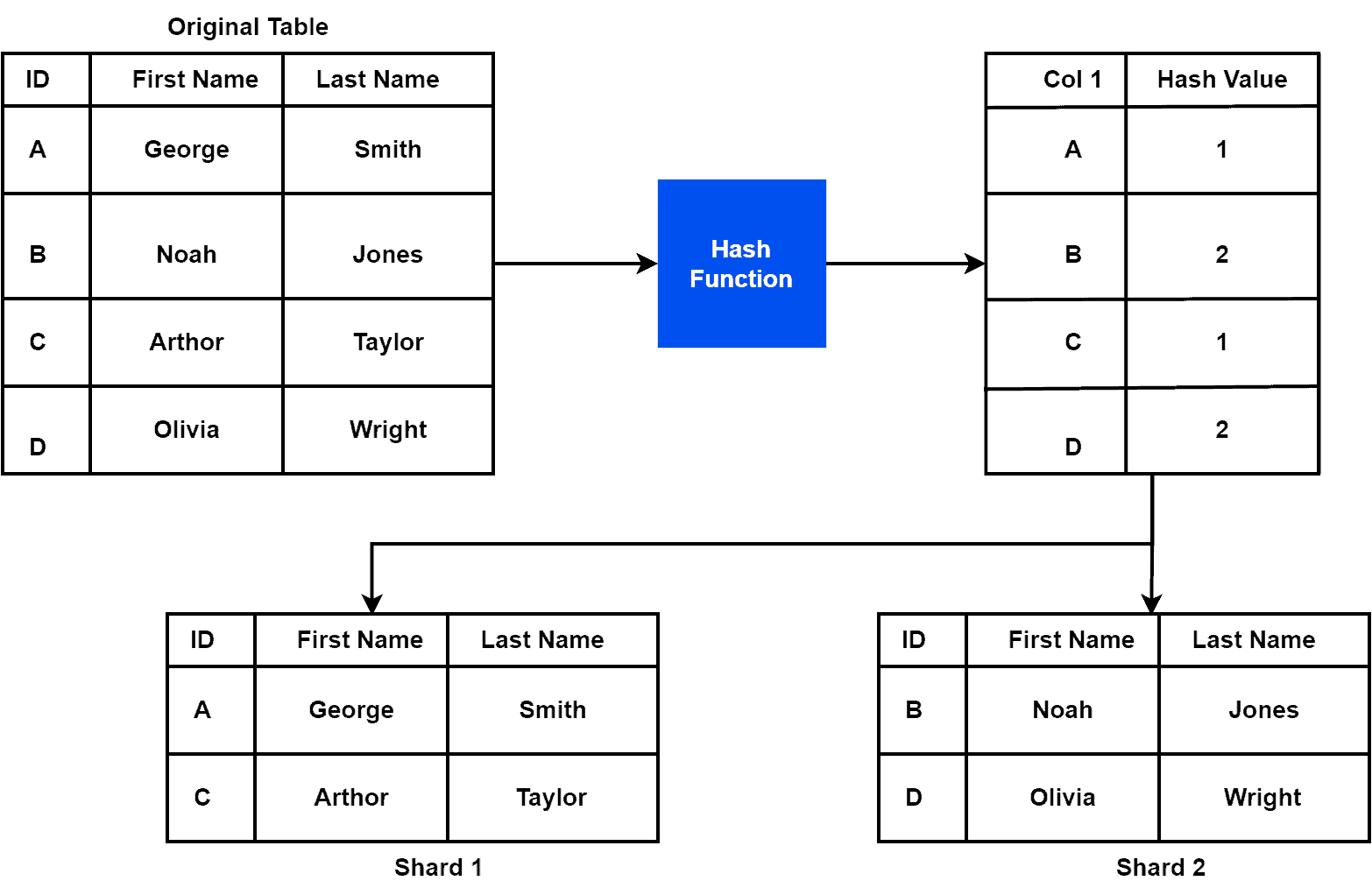
- Composite Sharding
: 위 두 방식 혼합 사용 (Range-based, Hash-based)
3. Replication
같은 데이터를 여러 분산 노드에 동일하게 저장
-
쓰기 담당 / 읽기 담당을 나누어, 쓰기 발생 시 읽기 담당 노드 모두에 동기화 일치
- ex ) MySQL 에서 Master/Slave(Read, Standby) 로 나누었을 때의 이점
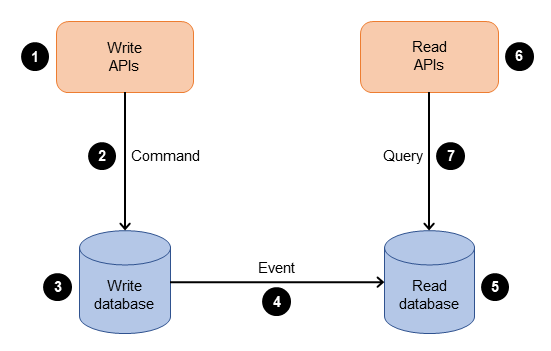
→ DB 로드 분산- 데이터 저장소로부터의 읽기와 업데이트 작업을 분리하는 패턴
- CQRS (Command and Query Responsibility Segregation)
- ex ) MySQL 에서 Master/Slave(Read, Standby) 로 나누었을 때의 이점
-
CQRS 사용 시 어플리케이션의 퍼포먼스, 확장성, 보안성을 극대화
2. Concurrency Control : Pessimistic/Optimistic Lock
1. Concurrency Control 동시성 제어의 핵심 : Locking Mechanism
- 데이터베이스 동시성의 Locking 제어 메커니즘은 2가지
→ Pessimistic / Optimistic Lock - 둘의 차이는 카페 화장실 사용 방식의 차이로 비유하여 이해
(화장실은 한 개, 한 번에 한 사람만 사용)
2. Pessimistic Lock : “분명히 충돌날 수 있으니 먼저 체크하자” 비관주의
Pessimistic Concurrency Control(PCC)
작업 수행 전 잠금으로 충돌을 방지하고 하나의 작업만 수행
-
데이터베이스 Built-in Lock
: “데이터 일관성은 데이터베이스가 알아서”- 단위 : Table 단위 Lock(큰 잠금 단위) / Row 단위 Lock(작은 잠금 단위)
- 잠금 단위 증가 : 동시성 수준 감소, 트랜잭션 제어 간단
- 잠금 단위 축소 : 동시성 수준 증가, 트랜잭션 제어 복잡
- 범주
- Shared Lock (공유, 읽기 잠금, s-lock)
: 다중 s-lock(읽기) 가능 / x-lock(쓰기) 접근 불가 - Exclusive Lock (베타, 쓰기 잠금, x-lock)
: 모든 lock (s-lock, x-lock) 접근 불가
- Shared Lock (공유, 읽기 잠금, s-lock)
- 단위 : Table 단위 Lock(큰 잠금 단위) / Row 단위 Lock(작은 잠금 단위)
-
선 Lock 체크 (Preempt 선점, 점유) → 후 작업
: Lock 을 통해 작업 전에 잠그고, 작업 후에 Lock 을 해지- 결국 Pessimistic Lock 이란,
특정 데이터에 Lock 을 가진 스레드만 접근이 가능하도록 제어하는 방법 - 충돌을 예상하고, 매 요청마다 Lock 설정하기에 ⇒ 성능 하락
- 읽기 / 쓰기 중 쓰기 비중이 높을 때 사용
(쓰기 간 충돌이 절대로 일어나선 안되며, 안정적인 쓰기 가능)
- 읽기 / 쓰기 중 쓰기 비중이 높을 때 사용
- 결국 Pessimistic Lock 이란,
데이터 무결성 보장 수준이 높으나 (Lock 으로 충돌 여부를 미리 방지) | 동시성 떨어짐 + 데드락 발생 위험성
- 데드락 발생
- ORM 내 ID 생성을 위한 접속 시 Thread 부족
- 같은 데이터 2개를 순서 / 역순 업데이트
Pessimistic Lock 세부 방법론
1. Lock-based Concurrency Control
- 2PL (2 Phase Locking) : Serializable 보장을 위한 Locking 방법
- 2PL 을 확장한 더 많은 방법론(Strict 2PL(S2PL), Rigorous 2PL(SS2PL))들 존재
3. Optimistic Lock : “에이, 설마 충돌나겠어? 그냥 먼저 해” 낙관주의
Non-locking Concurrency Control 혹은 Optimistic Concurrency Control(OCC)
동시에 발생한 요청 중 먼저 완료 표기한 하나의 승자 요청을 제외하고 나머지 요청에게 실패 전달 및 롤백
-
소프트웨어적 Lock : 개발자가 알아서 처리
- 데이터별로 추가 컬럼 혹은 테이블을 통해 Versioning
- 개발자가 직접 소프트웨어로 Versioning, Exception 처리
- DynamoDB, Redis, Firestore, ES 등 Transaction(Lock) 없는 (분산 저장) NoSQL 에서 채택
- 왜 NoSQL (분산 저장 시스템) 에는 Lock 이 없을까?
- DynamoDB, Redis, Firestore, ES 등 Transaction(Lock) 없는 (분산 저장) NoSQL 에서 채택
-
선 작업 → 후 버전 체크
: Lock 없이 먼저 수행한 뒤에, Commit 직전에 꼭 버전 체크 (중간에 누가 썼나)-
OptimisticLockException
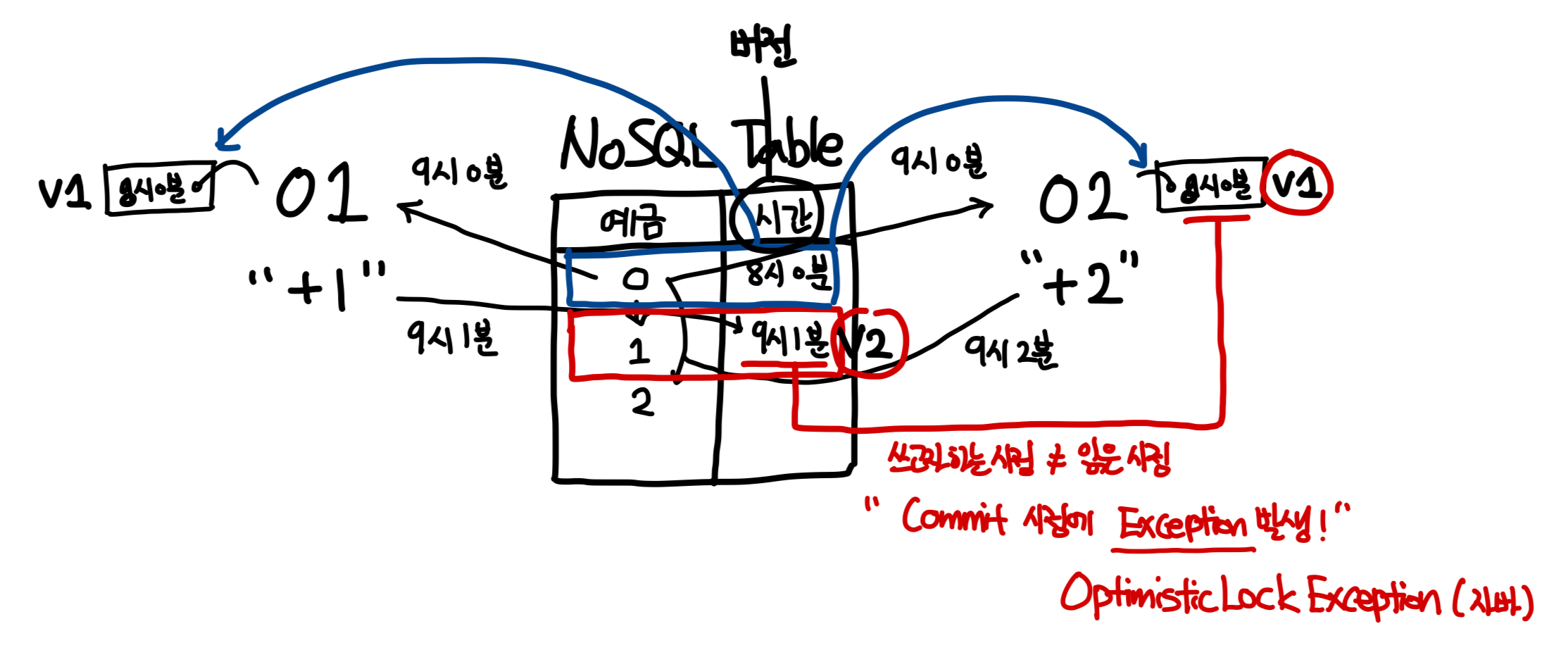
: 쓰기 시 버전 충돌이 발생하면 작업한 내용을 개발자가 직접 롤백 필요- 좌측 명령 01번이 9시 0분에 0 값(8시 0분)을 읽어 +1 하여 1 값을 9시 1분에 저장했고
- 우측 명령 02번이 9시 0분에 0 값(8시 0분)을 읽어 +2 하여 2 값을 9시 2분에 저장하려던차
- 0 값(8시 0분)이 아닌 1 값(9시 1분)으로 되어있어 처음 버전 혹은 타임스탬프와 달라 에러
- Commit 시점에 처음 읽었던 해당 값의 시간 ≠ 쓰고자할때 해당 값의 시간 때문에 Exception 발생
- 충돌을 예상하지 않고, Lock 없이 수행된 시점 혹은 버전만 표기해놓고 모든 걸 수행하기에 성능 강화
- 읽기 / 쓰기 중 읽기 비중이 높을 때 (쓰기 비중이 높다면, 쓰기 충돌이 너무 빈번할 것)
- 좌측 명령 01번이 9시 0분에 0 값(8시 0분)을 읽어 +1 하여 1 값을 9시 1분에 저장했고
-
-
동시성 좋으나 | 데이터 무결성 보장 수준이 낮고 + Versioning, Exception 처리에 대한 추가 개발 필요
Optimistic Locking 세부 방법론
1. Timestamp-based Concurrency Control
2. Multiversion Concurrency Control (MVCC)
- MVCC 는 동시성(Concurrency) 과 성능(Performance) ↔ 일관성(Consistency)과의 trade-off
- MVCC 는 MySQL 와 PostgresQL 에서도 사용
→ 트랜잭션에 따른 전체 DB 처리량 저하 방지 위해- MVCC 동작 원리
- Lock 기법만 적용된 DBMS 보다 훨씬 빠르게 동작
- 사용하지 않는 데이터가 매번 생기므로 데이터를 정리하는 시스템 필요
- 데이터 버전이 충돌 시 애플리케이션 영역에서 (소프트웨어적으로) 문제 해결
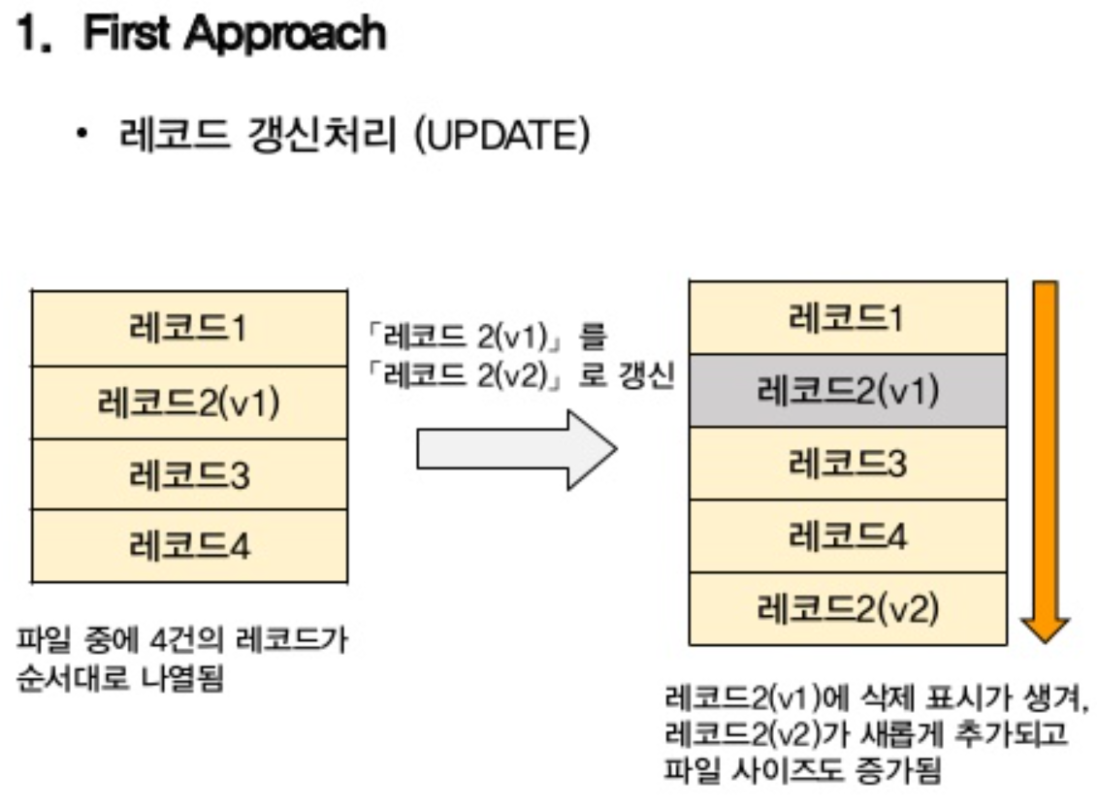
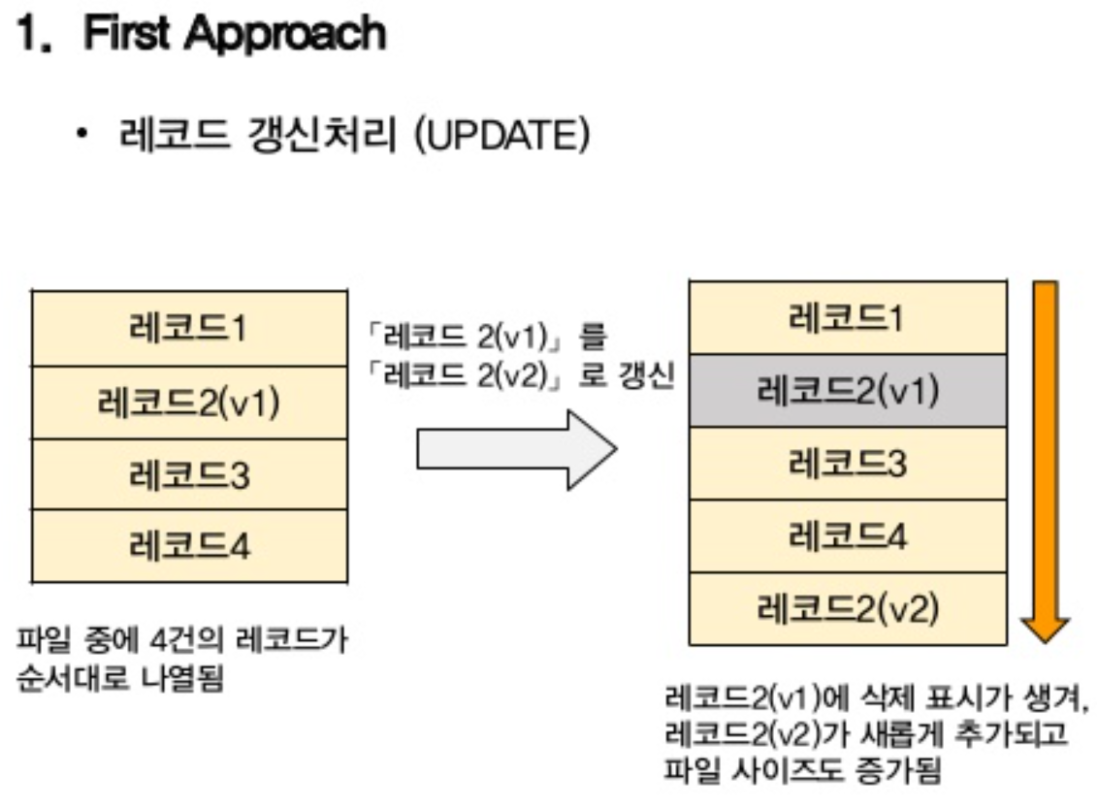
A. 데이터베이스 내 다중 버전의 데이터를 저장
: PostgreSQL 에서 사용하는 방식
B. 최신 버전의 데이터만 데이터베이스에 저장
: Oracle, MySQL 에서 사용하는 방식[ 사진 출처 : [MySQL] MVCC(다중 버전 동시성 제어)와 데이터베이스가 트랜잭션을 지원하는 방법과 동작 과정 ]
- NoSQL 중 하나인 Couchbase 는 CAS(Compare-and-Swap) 를 사용
값이 변경될 때마다 “변경여부만” 알 수 있는 값을 CAS 라 하며
매 번 문서를 읽을 때마다 CAS 값을 읽고, 수정(Write) 할 때마다 앞서 읽은 CAS 값을 DB 에게 전달
이때 DB 는 CAS 값이 변경되었는지 확인(받은 CAS 값과 현재 CAS 값 비교)하여 다르면 에러 반환
→ 저렴하지만 매우 간단하다는 특징
