
나는 현재 인도어 스마트팜 스타트업에서 소프트웨어 개발자로 일하고 있다. 맨 처음 아무것도 없던 상태에서 이제 기초가 되는 환경 데이터 관련 기술들이 완성이 되어가고 있다. 이에 이어 작물과 직접적으로 관련된 생육 데이터 그리고 이 데이터들을 어떻게 활용할지에 대한 고민도 시작하고 있다.
이 고민은 여전히 현재진행형이고 오랜기간동안 해결되지 않을 수 있다. 그러나 최근 있었던 세가지 일을 나열하고 정리하여 시간이 지나 이 고민들이 어떻게 변화하고 혹은 결정됐는지 비교해보고 싶다.
- Agtech에 강화학습?
대표님께서 캐나다 출장을 갔다오신 후 우리 팀에 던진 키워드가 있었다. 그것은 바로 '강화학습'.
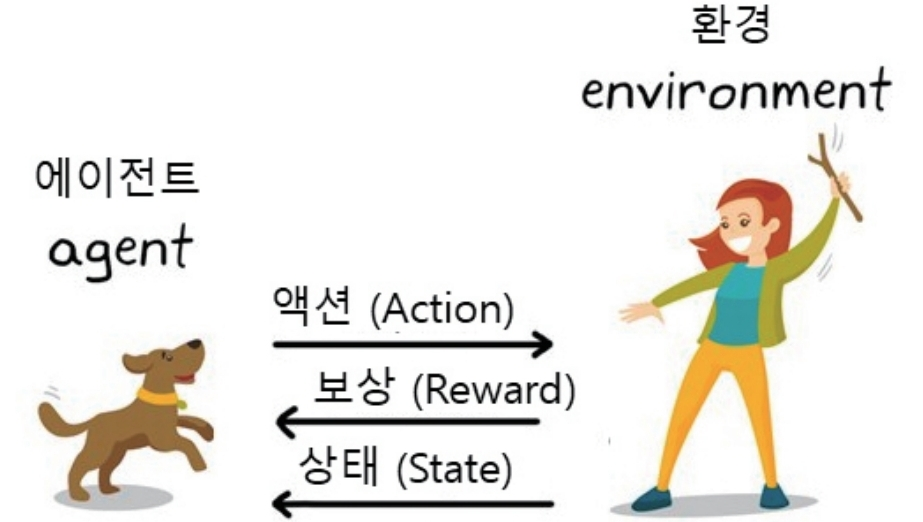
나는 강화학습에 대해 솔직히 잘 몰랐다. 인공지능을 공부했을 때, 내 개인적인 판단으로 강화학습은 몇십년 후의 기술이라고 생각했기 때문에 의도적으로 피했다. 그러나 스터디를 진행하면서 다양한 분야의 전문가들을 만나며 생각이 달라졌다.
특히, 강화학습이 네덜란드 농업인공지능(AI)경진대회 예선전에 적극적으로 활용되는 사례를 보게된 이유가 컸다.(해당 대회 예선전은 주최측이 제공하는 시뮬레이터를 이용한다) 결론적으로 정리된 데이터들도 많이 필요할거고 적절한 시뮬레이터도 필요할테지만 강화학습은 Agtech에서도 적용이 가능...할 것 같다.
하지만 우리 팀 내부에서도 강화학습에 대한 갑론을박이 있다. 강화학습이 데이터가 한정되고 수집하기 어려운 Agtech에 적용하는데 적절하냐? 단순 최적의 값들을 찾는거라면 다른 대안들이 충분히 존재한다 등. 당시 러프하게 다양한 의견들이 충돌했었다.
그리고 그 이후 나는 스터디를 통해 꾸준히 강화학습에 대해 개인적으로 학습을 이어왔다. 강화학습은 딥러닝과는 다르다라고 사람들은 말한다. 맞다. 강화학습이라는 개념이 인공지능이 나오기 전부터 정립되어 있던 개념이였기에 이렇게 따지면 다르긴 다르다.
그러나 우리가 말하는 인공지능에서 강화학습은 보상이라는 경제학적 개념을 컴퓨터가 활용할 수 있게 수학적 공식으로 정의하고 이를 딥러닝으로 최적화 시킨 것이다. 그러므로 어떤 분야에서나 데이터들을 활용해 딥러닝을 한다면 이 보상이라는 원리를 가진 강화학습은 문제를 해결하고 원하는 결과를 얻기 위한 좋은 수단이 된다.

이를 위해 필요한 것은 해당 공식을 만들기 위한 데이터, 보상을 정의하는 공식, 공식을 활용한 시뮬레이터이다. 우리 팀이 목표를 이루기 위해 강화학습이라는 수단을 선택하진 않았지만 인도어 스마트팜 우리 회사만의 보상을 정의하는 공식을 만들기 위해선 이에 기반이 되는 데이터를 잘 정의해 수집해야한다.
- 생육 기록 데이터의 활용
우리 회사에는 실력 있는 재배사 연구원 분들이 소속되어있다. 우리는 소프트웨어를 기획하고 개발하는데 이 분들과의 미팅을 계속 진행하고 있다. 그리고 생육 기록 관련 회의를 하며 발견한 엄청난 사실은. 현재 재배 전문가 분들도 농업 데이터들을 어떻게 활용해야하는지 잘 모르고 있다는 사실이였다.
물론, 교과서, 논문 등을 통해 대략적인 가이드라인들은 줄줄 외우고 있었지만 이 데이터들을 실질적으로 어떻게 활용해야하는지는 아무도 모르고 있었다. 또한, '인도어' 스마트팜이기에 고려해야할 것들도 더 많고 관련 레퍼런스가 거의 없었다.
그러므로 우리는 현재 활용되고 있는 해당 데이터들을 이어가 돼 추가적인 시행착오를 통해 우리의 목표를 위한 데이터들을 정의하고 또 앞으로 하나씩 차근차근 수집해나가야한다.

현재 가장 신경을 쓰고 있는 부분은 환경 데이터와 생육 기록 데이터들과의 연결이다. 이 생육 기록 데이터들은 필수적으로 환경 데이터들과 관련이 있다. 그런데 어떤 생육 기록 데이터가 어떤 환경의 데이터와 관련이 되는지. 또, 각각 데이터 기록되는 주기의 다른 점들을 어떻게 극복해야하는지 등등을 필수적으로 해결해야한다.
- AI 대회
그러던 중 최근 농업 관련 AI 대회를 알게 되었다. 타이밍이 좋았던게 관련 도메인 지식을 가진 전문가 박사님이 자문으로 우리 회사에 조인이 된 상황이였다. 아직 AI 관련 아무런 준비가 되어있지 않은 상황에서 좋은 스터디 케이스였다.
또한, 여러모로 네덜란드의 농업 AI 대회와 유사한 면들이 많아 보였다. 그래서 내가 해당 프로젝트를 제안했고 팀장님은 고민 끝에 업무에 지장이 생기지 않는 선에서 추진을 허락받았다. 그리고 기대를 갖고 본격적으로 해당 데이터에 대해 미팅을 가졌다.
그리고 기대는 산산히 무너졌다. 데이터가 정말 형편 없었기 때문이다. 대표적으로 작물에 가장 중요한 환경 데이터 온도, 습도 등이 주차 단위로 평균으로 묶여있었다. 단위가 주차인 데이터가 어떻게 작물에 의미가 있을 수 있을까.
아마 주최측에서 이걸 몰랐을리 없다. 많은 관련 전문가들이 자문으로 포진해있었기 때문이다. 그래서 박사님께 여쭤봤고 관련 산업의 구조와 지자체의 운영 문제 등등을 들을 수 있었다. 아마도 이 대회 역시 이러한 현실적인 문제로 인해 어쩔수 없었던 것이다.(계약 농가들 및 비파괴 조사의 한계 신뢰성 등등...)
이를 통해 한편으로 회사에서 전폭적인 지원을 받아 활용 목표를 브레인스토밍하고 이를 위해 데이터 정의부터 시작하는 우리들에게 큰 기회가 있다는 사실을 깨달았다.
우리의 앞으로의 데이터들은 우리가 정의하고 우리가 직접 수집하고 우리가 오너쉽을 가진 식물공장들에서 데이터들을 수집하고 활용할 수 있게 된다. 이 데이터들의 가치를 느낄 수 있었다.

앞으로 우리만의 데이터를 정의하고 수집하고 활용 목표를 설정하는게 정말 중요하다는 생각을 다시 한번 하게 되었다. 레퍼런스가 아무것도 없다고 생각할 수 없는 현재 상황은 새로운 산업과 기술에 대한 도전의 당연한 부분이다. 그러므로 이 상황을 부정적으로 생각하지말고 오히려 감사한 기회로 생각해 소중히 그리고 우리 팀들과 정열적으로 임하려 한다.
