Autoencoder와 Upsampling
Semantic Segmentation의 경우?
-
Semantic segmenation이란?
모든 pixel에 대한 classification (pixelwise classification) -
Pixel 개수만큼 CNN 돌리기는 비효율적
224x224 = 50,176 pixel >> 2000개 region proposal(selective search)
=> 앞에서 너무 많아 오래 걸린다고 불만이였던 기본 CNN의 탐색 보다 더 오래걸리게 됨 -
그래서 아이디어가 한 번에 여러 pixel에 대한 결과를 얻어야함
Encoder-Decoder 구조
- Encoder-Decoder 구조란?
Encoder : 입력 데이터에서 의미 있는 feature를 추출하는 네트워크
Decoder : Feature 로부터 원하는 결과 값을 생성하는 네트워크
Latent feature : Encoder에 의해 압축된 입력 데이터의 feature
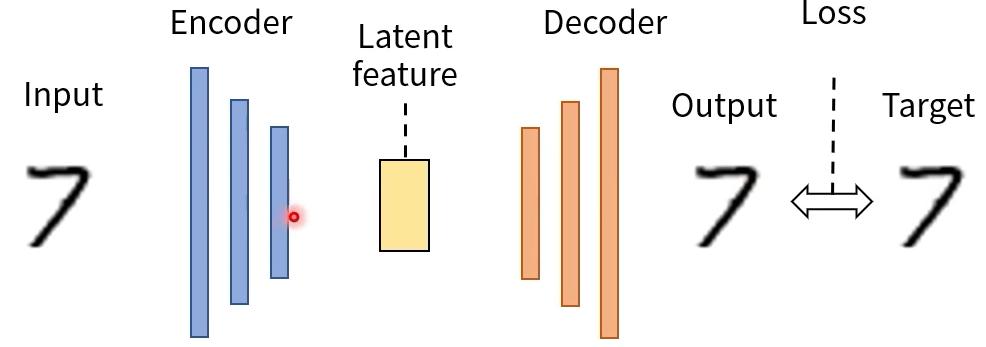
Autoencoder
- Autoencoder란? 입력과 출력이 같은 구조를 가진 인공신경망
- Autoencoder의 학습
Target을 input과 동일한 데이터로 줌 - label에 해당
output과 target이 같아지도록 loss를 계산하여 학습
=> 원본에 encoder와 decoder를 거치면서 원본 값과 비교해 loss가 발생.
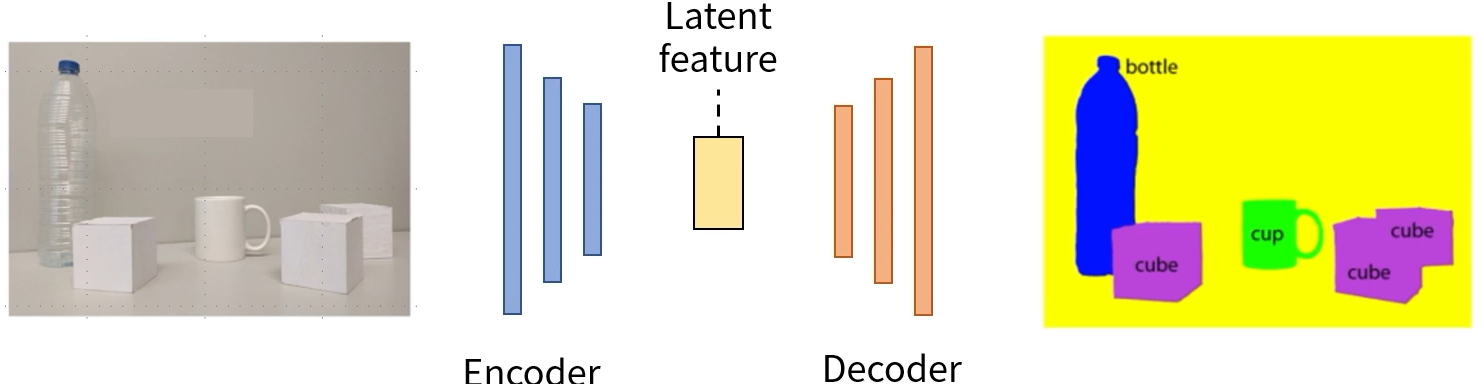
Autoencoder의 쓰임새
- Label없이도 입력 데이터의 feature를 추출할 수 있음
- Feature 차원 축소 - 중요한 정보만 살리기
노이즈 제거에 활용
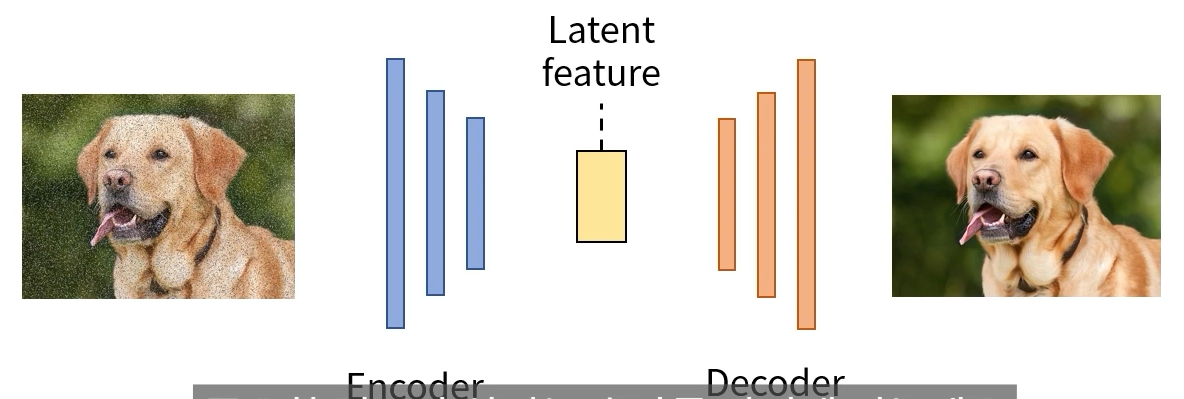
=> pca 차원축소와 비슷한 개념...?
=> 이해 안됨.
=> 아래 영상을 보시구 이해하세요

긍정적인 에너지를 가진 개발자, 이태성입니다.