
🤍 활성화 함수 (activation)
- 분류 초기의 활성화 함수 : Step Function
- 계단 함수에서 Sigmoid 함수로 바뀌었는데 왜 바뀌었을까?
- 계단 함수는 최적의 값을 지나버리면 다시 찾기 어렵다.
- 역치의 개념과 미분이 가능한(기울기를 가진) Sigmoid 함수를 사용하게 되었다.
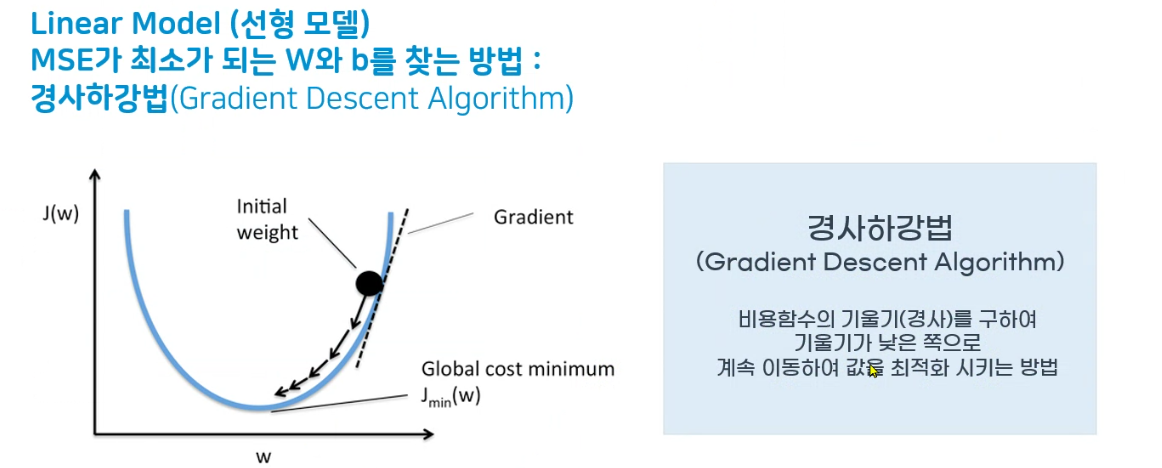
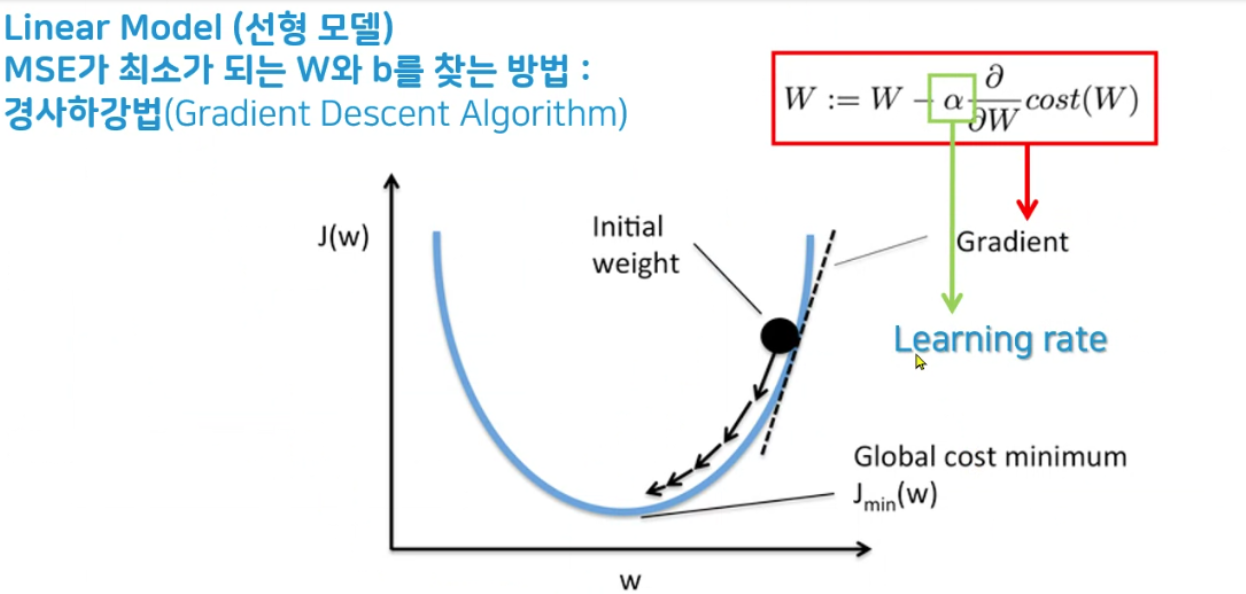
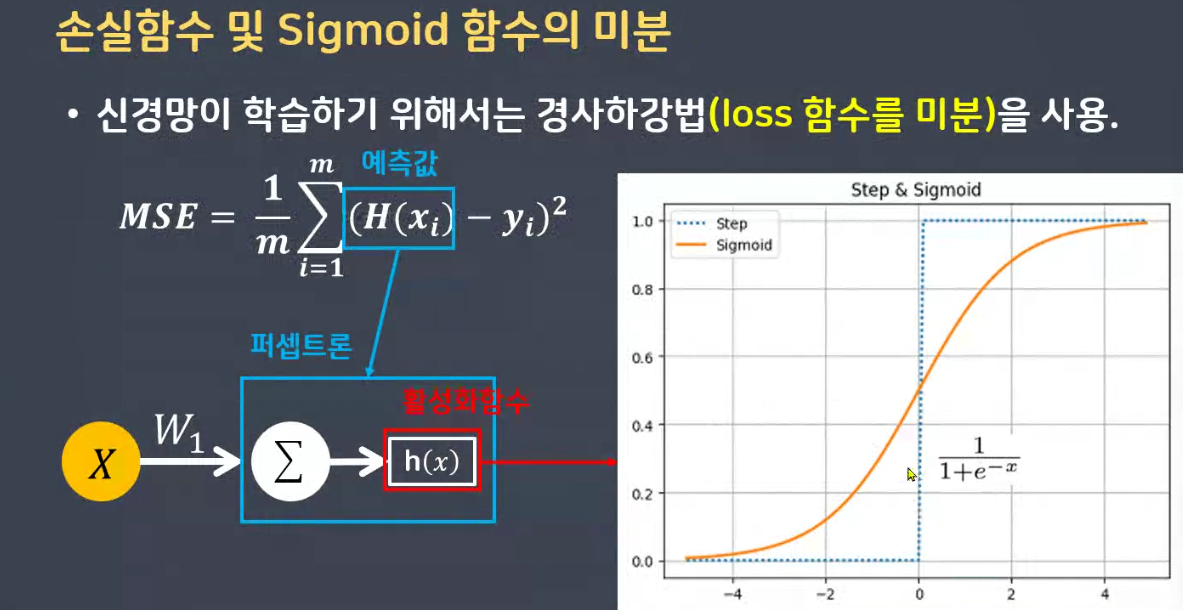
경사하강법
- MSE가 최소가 되는 W와 b를 찾는 방법
- 비용함수의 기울기를 구하여 기울기 낮은 쪽으로 이동하여 값을 최적화 시키는 방법
-> 아래에서 상세설명
✅ Learning rate (학습률)
: 예측하는 값으로 이동할 때의 이동크기를 말하며, 쉽게 보폭의 크기라고 생각하면 된다.
경사하강은 기울기가 낮은 쪽(최적해값)으로 이동하는 것
가장 초기의 예측값은 랜덤이다.
기울기를 구할 때 미분 시행
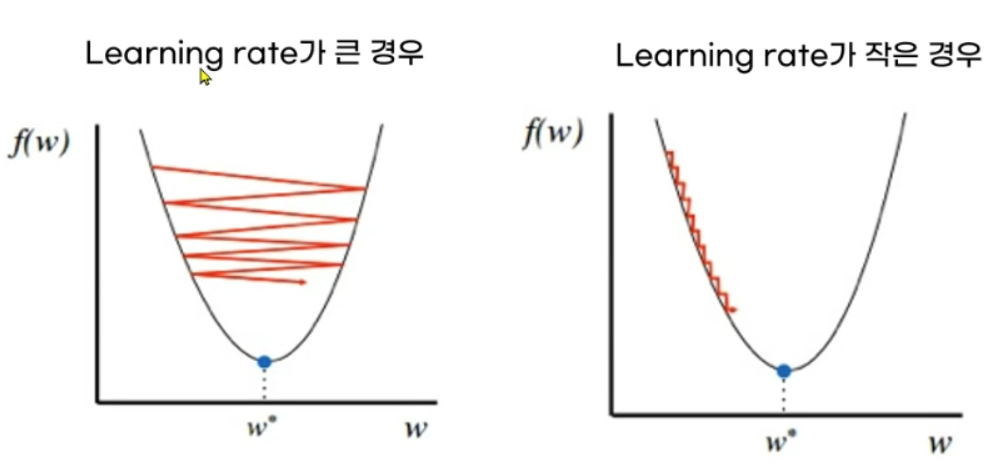
- Learning rate를 너무 클 시 비효율적인 학습을 하게 됨.
- Learning rate를 너무 작을 시 시간이 오래 걸림 (정해진 시간에 최적해에 도달하지 못할 수 있다.)
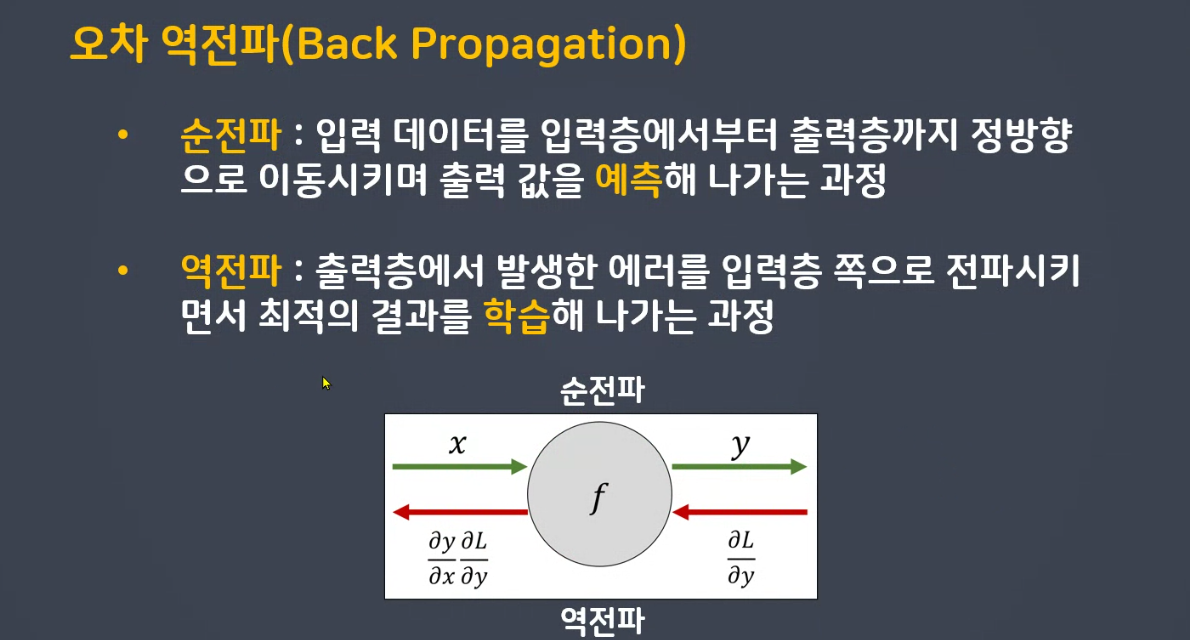
🤍 오차역전파
- 순전파 : 입력 데이터를 입력층에서부터 출력층까지 정방향으로 이동시키며 출력값을 예측해 나가는 과정
- 역전파 : 출력층에서 발생한 에러를 입력층 쪽으로 전파시키면서 최적의 결과를 학습해 나가는 과정
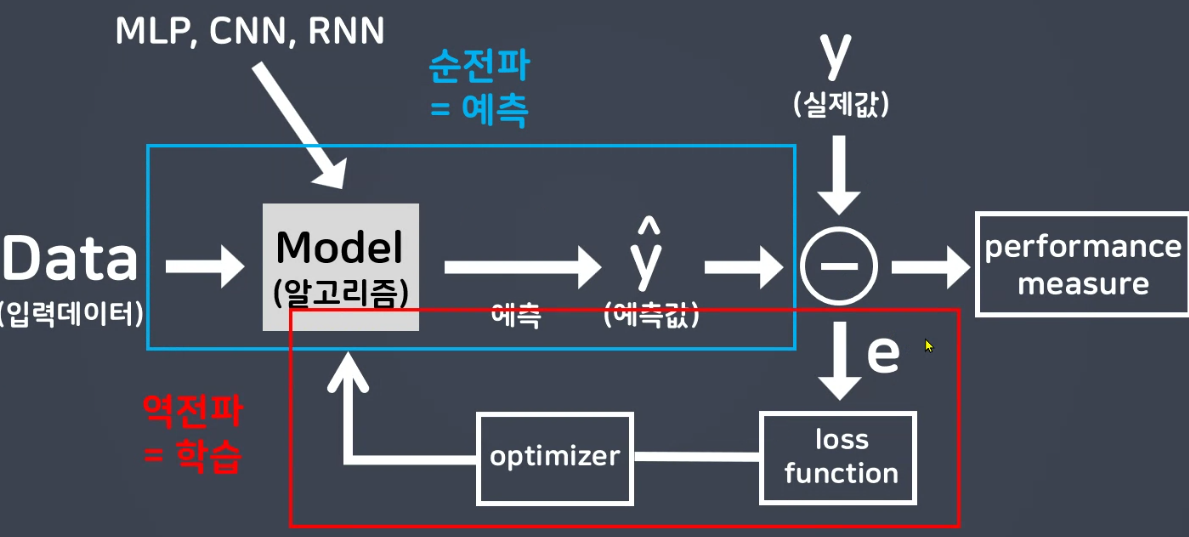
- 1epoch에 순전파 + 역전파가 들어가 있다.
- 역전파의 최적화함수에서 경사하강법을 통해 최적의 결과를 만든다
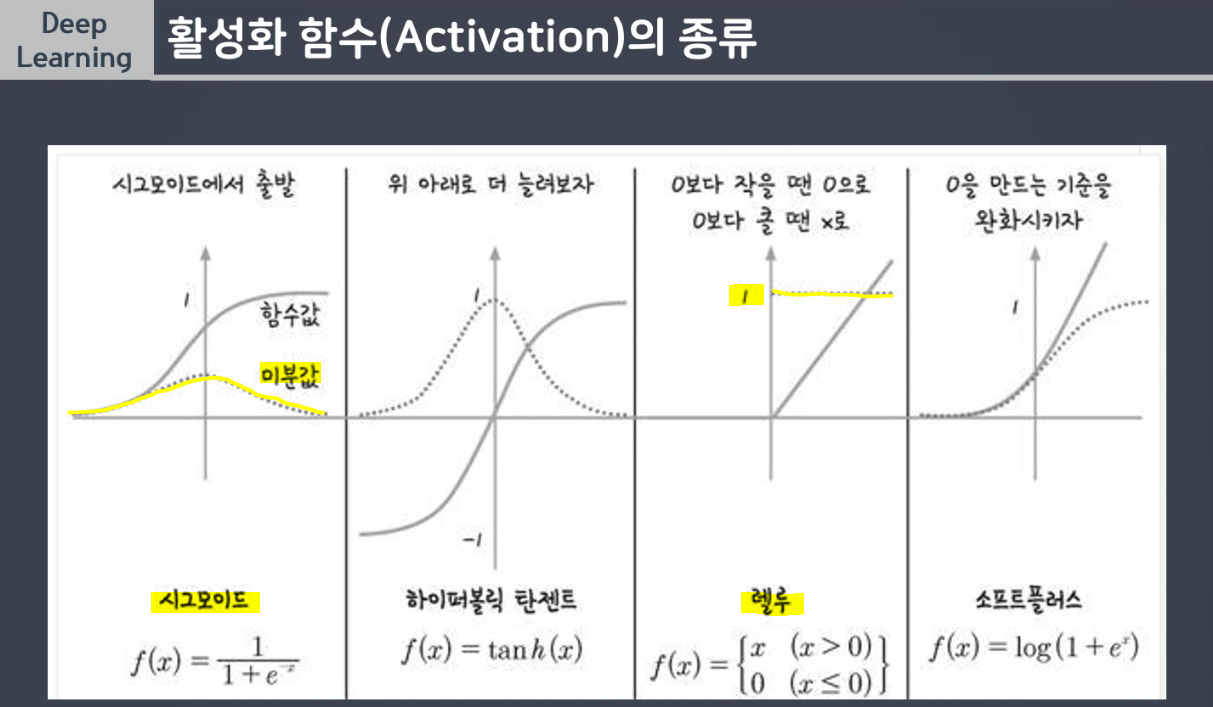
✅ 기울기 소실 문제 (Vanishing Gradient)
: ❗ Sigmoid 함수의 문제점
- 경사하강법을 시행하며 역전파에서 활성화함수를 같이 미분을 시행하게 되는데 (퍼셉트론 안에 있으므로)
- 시그모이드 함수는 미분시 값이 0.25가 되면서, 층이 깊을수록 기울기 소실 문제(Vanishing Gradient)가 생겨 예측을 제대로 하지 못하게 된다.
- 층이 적을 때는 시그모이드 함수를 사용하여도 기울기 소실이 적어 사용했지만
- ex03 다중분류 실습에서 중간층을 많이 생성(units수도 많이)해서 돌려보면 val_accuracy가 전보다(중간층을 적게 했을 때보다) 점점 감소하는 것을 볼 수 있다.
- 더 좋은 학습을 위해 앞으로 Relu 함수 사용할 것이다!!
- 층이 적을 때는 시그모이드 함수를 사용하여도 기울기 소실이 적어 사용했지만
- Relu 함수 : 0보다 작을 땐 0으로, 0보다 클 땐 x로 출력된다.
최적화함수(Optimizer)의 종류
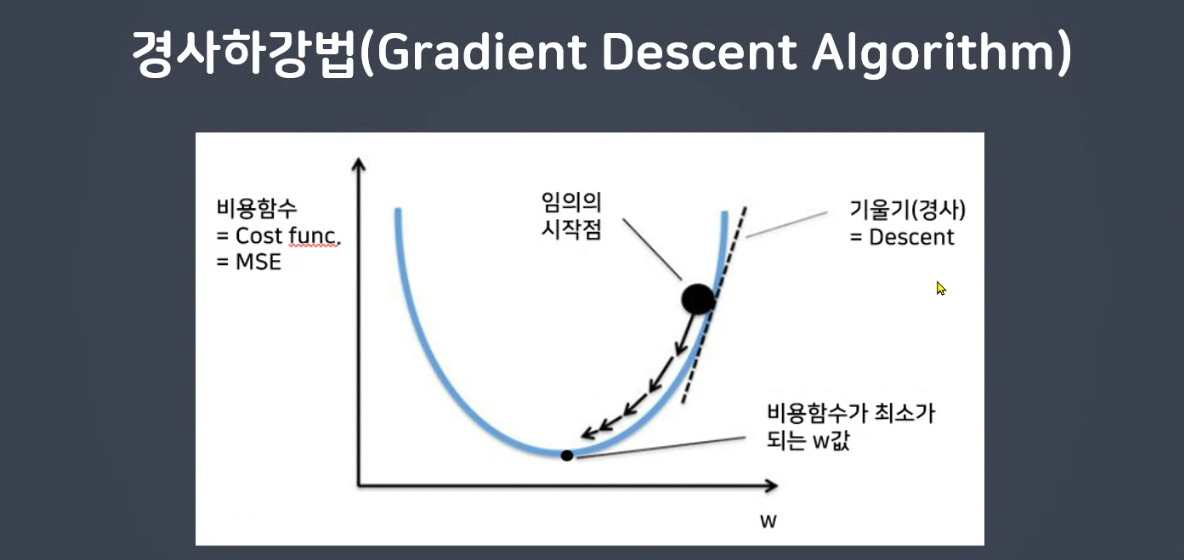
🤍 경사하강법
: MSE가 최소가 되는 W와 b를 찾는 방법
: 비용함수의 기울기를 구하여 기울기 낮은 쪽으로 이동하여 값을 최적화 시키는 방법
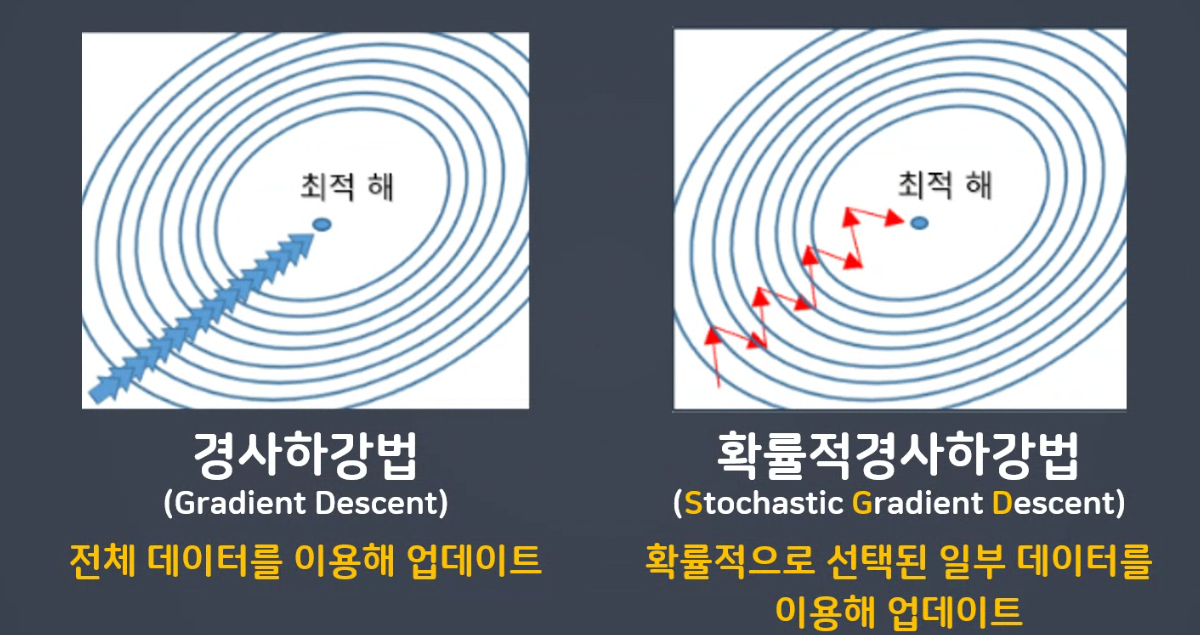
💜 경사하강법 (Gradient Descnet, GD)
: 전체 데이터를 이용해 업데이트
💜 확률적경사하강법 (Stochastic Gradient Descent, SGD)
: 확률적으로 선택된 일부 데이터를 이용해 업데이트
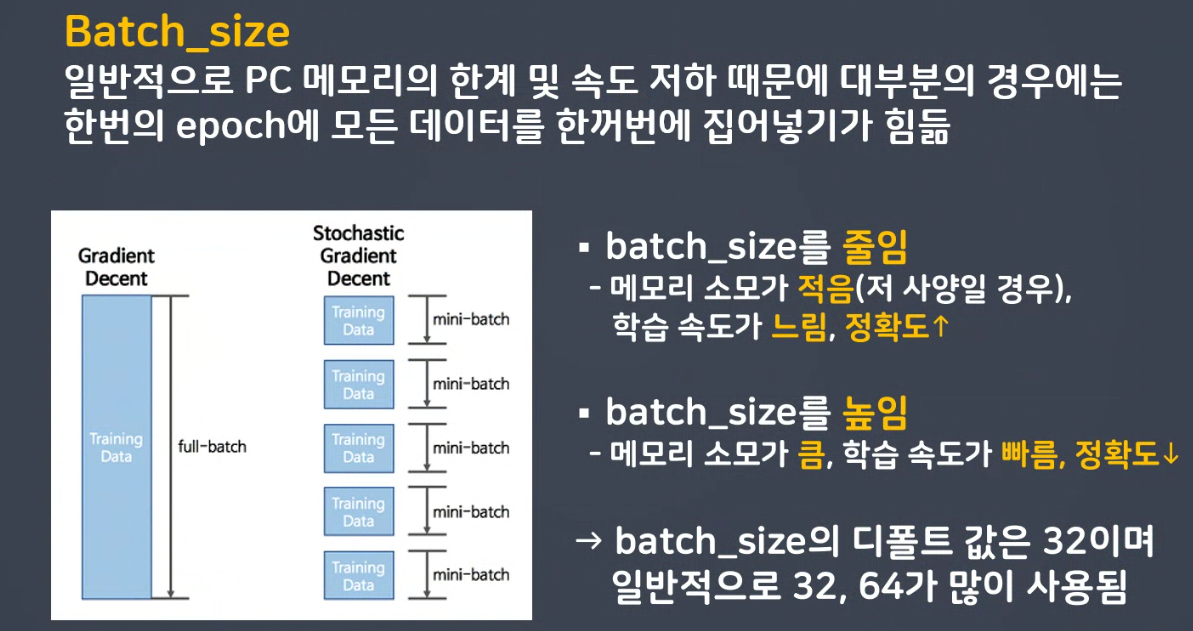
SGD에서 일부데이터를 선택하기 위해 batch_size를 사용함
✅ SGD의 장단점
- 배치 GD보다 더 빨리 더 자주 업데이트 함
- 지역 최저점을 빠져나갈 수 있다
- 탐색 경로가 비효율적이다 (진폭이 크고 불안정)
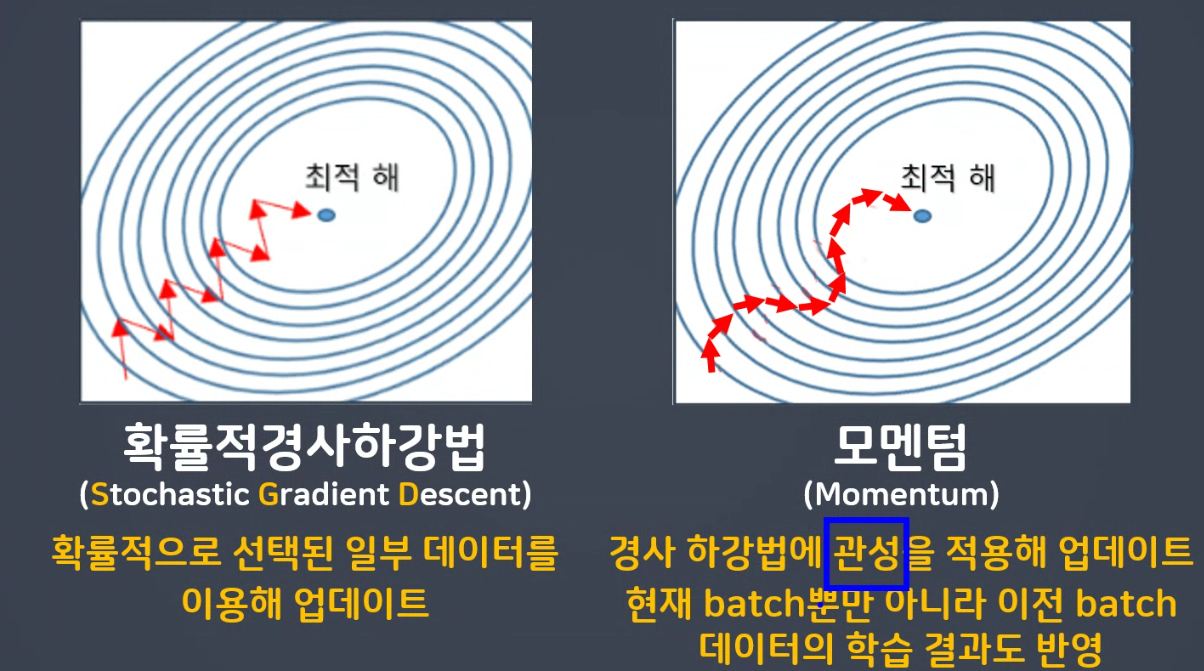
💜 모멘텀 (Momentum)
: 경사 하강법에 관성을 적용해 업데이트, 현재 batch 뿐만 아니라 이전 batch 데이터의 학습 결과도 반영
-> 그렇다면 이후 배치도 보면 좋지 않을까?
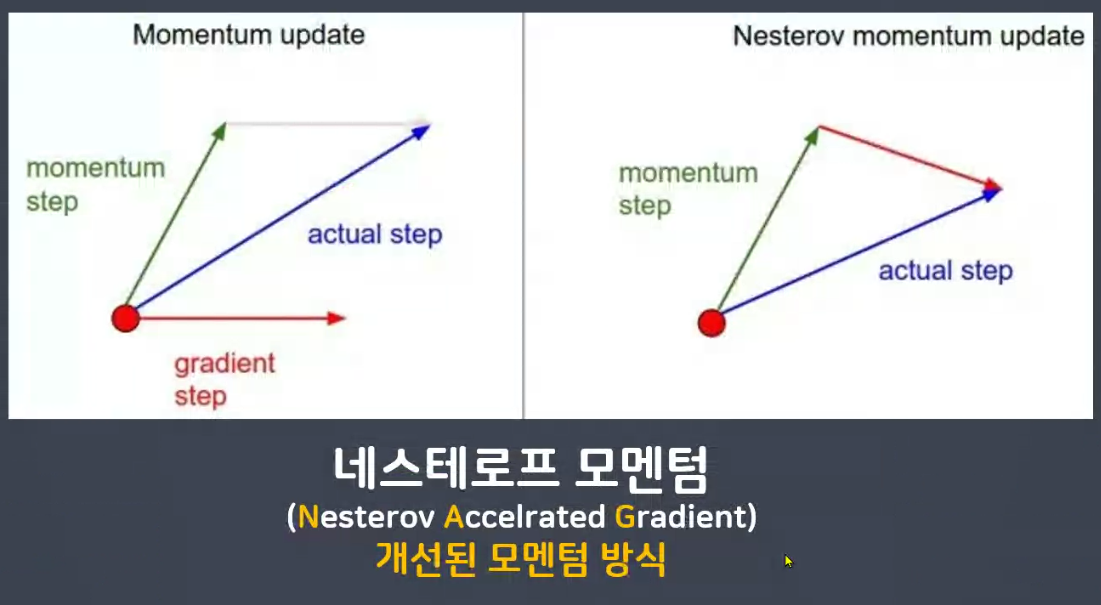
💜 네스테로프 모멘텀 (Nesterov Accelrated Gradient, NAG)
- 미리 해당방향으로 이동한다고 가정하고 기울기를 계산해본 뒤 실제 업데이트 반영
- 불필요한 이동을 줄일 수 있다.
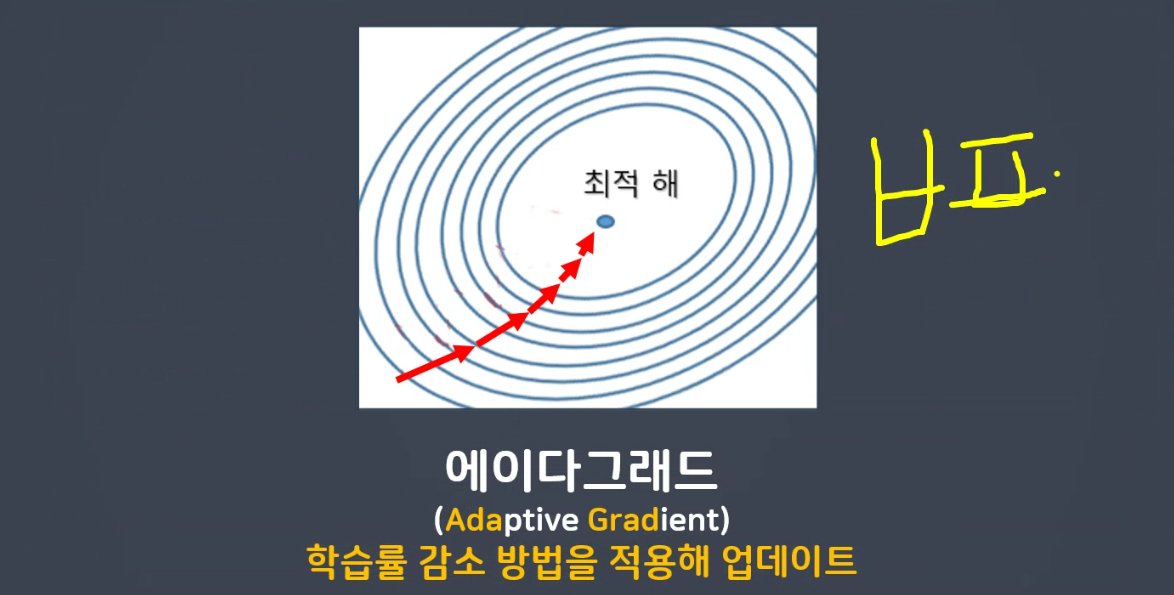
💜 에이다그래드 (Adaptive Gradient, Adagrad)
- 학습률 감소 방법을 적용해 업데이트
- 학습을 진행하면서 학습률을 점차 줄여감
- 학습을 빠르고 정확히 할 수 있음
💜 Adam
- 방향과 스텝사이즈 적절히 조절
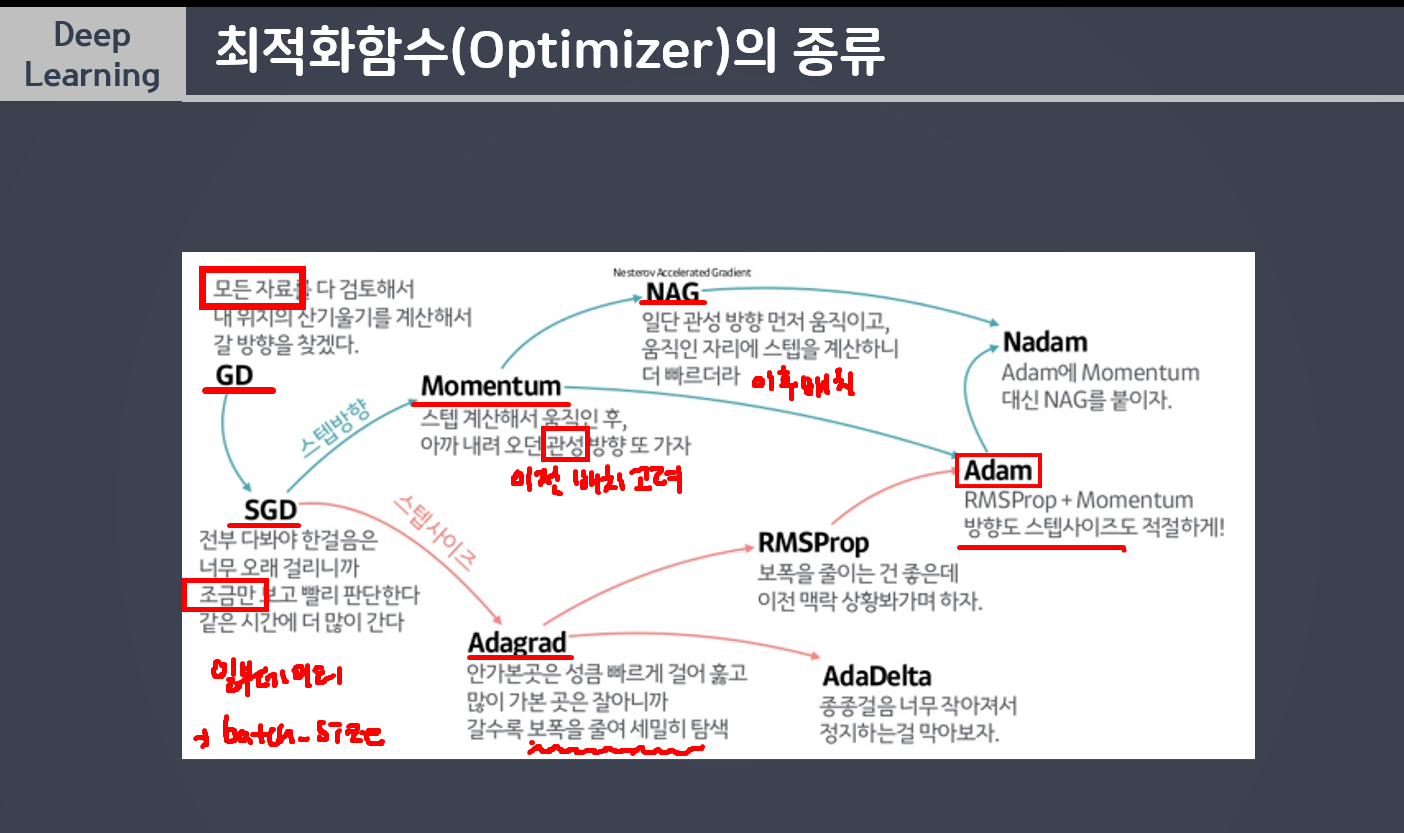
가장 많이 사용하는 함수
- 중간층 활성화함수 : Relu
- 평가 최적화함수 : Adam

Hello, World!