데이터 전처리
목표
- 개,고양이 이미지(사진) 을 배열로 변환하는 작업 진행 (이미지데이터 전처리)
- 압축된 형식의 배열로 저장 (npz파일)
- npz: numpy 에서 제공하는 파일형식 -> 여러개의 numpy 배열을 하나의 압축된 파일로 저장할 수 있도록 해줌
- 대용량의 데이터를 압축형태로 정리해두면 저장공간 효율, 공유시 빠른 공유가 가능
- 압축 폴더 해제
- 이미지 접근
- 이미지 크기 조정
- 넘파이배열로 변환
- npz 형식으로 저장
# 라이브러리 불러오기~
from zipfile import ZipFile # 압축된 파일을 열고 해제하는데 사용
import os # 파일관리
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from PIL import Image # 이미지 처리
from google.colab import drive
drive.mount('/content/drive')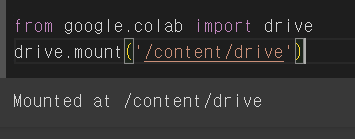
# 현재 파일의 위치를 나의 drive 안으로 변경
%cd "/content/drive/MyDrive/Colab Notebooks/24.08.29 DeepLearning"
zip_path = "data/cats_and_dogs_filtered.zip"
# 파일 다루는 코드
with ZipFile(zip_path, 'r') as f:
f.extractall(path = 'data/') # 압축파일 해제 후 저장할 위치# 압축해제된 폴더 확인
# train - cats, dogs
# test - cats, dogs
# 이미지 파일에 접근하여 불러오기~
# 4개의 폴더 경로를 변수에 저장
train_cats_dir = 'data/cats_and_dogs_filtered/train/cats/'
train_dogs_dir = 'data/cats_and_dogs_filtered/train/dogs/'
test_cats_dir = 'data/cats_and_dogs_filtered/test/cats/'
test_dogs_dir = 'data/cats_and_dogs_filtered/test/dogs/'
# 폴더의 이미지에 접근
# os.listdir(폴더경로): 해당경로에 있는 모든 파일명을 리스트로 출력
train_cats_fnames = os.listdir(train_cats_dir)
train_dogs_fnames = os.listdir(train_dogs_dir)
test_cats_fnames = os.listdir(test_cats_dir)
test_dogs_fnames = os.listdir(test_dogs_dir)
# 각각의 이미지 파일이 몇개씩있는지 확인
print(len(train_cats_fnames), len(train_dogs_fnames), len(test_cats_fnames), len(test_dogs_fnames))
# train -> 고양이, 강아지 각각 1000장
# test -> 고양이 , 강아지 각각 500장

img = Image.open(tmp_path)
np.array(img) # 이미지 넘파이 배열화
# (374, 500, 3)
# (가로픽셀, 세로픽셀, 색상차원 -> 컬러 3차원 RGB)
tmp_path = os.path.join(train_cats_dir, train_cats_fnames[0]) # 경로를 합쳐주는 기능
tmp_path
img = Image.open(tmp_path).resize((224,224)) # 이미지 크기를 맞춰주기 위해서 resize
np.array(img)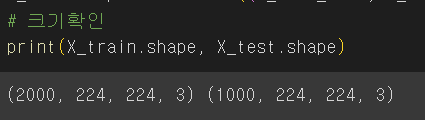
# 이미지 전처리해주는 함수 생성
# 사진 불러오기 -> 배열로 변경 -> 사이즈 맞춰주기
def prepro_img (fold_path, filenames, img_size = (224,224)):
imgs = [] # 변경 후의 데이터를 담아줄 비어있는 리스트 생성
# 이미지 접근해서 불러오기 -> 크기조정 -> 배열화 -> 누적
for i in filenames:
tmp_path = os.path.join(fold_path, i) # 경로 합치기
img = Image.open(tmp_path).resize(img_size) # 해당 경로의 이미지파일 불러오기 -> 크기조정
img = np.array(img) # 넘파이배열화
imgs.append(img) # 누적
return np.array(imgs)# 함수적용
X_train_cats = prepro_img(train_cats_dir, train_cats_fnames)
X_train_cats[0]
# 이미지 1장 확인 -> 3차원 (컬러), 1000장
# 나머지 3개 데이터 모두 변환
X_train_dogs = prepro_img(train_dogs_dir, train_dogs_fnames)
X_test_cats = prepro_img(test_cats_dir, test_cats_fnames)
X_test_dogs = prepro_img(test_dogs_dir, test_dogs_fnames)
# 크기 확인 -> shape
print("훈련데이터:", X_train_cats.shape, X_train_dogs.shape)
print("테스트데이터:", X_test_cats.shape, X_test_dogs.shape)
# (이미지의 개수, 가로픽셀, 세로픽셀, 색상차원)# train -> cats, dogs 병합
X_train = np.concatenate((X_train_cats, X_train_dogs), axis = 0)
# test 병합
X_test = np.concatenate((X_test_cats, X_test_dogs), axis = 0)
# 크기확인
print(X_train.shape, X_test.shape)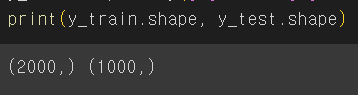
# 정답데이터 생성
# numpy 배열의 1차원 생성
# cat = 0, dog = 1
y_train = np.array([0]*1000 + [1]*1000)
y_test = np.array([0]*500 + [1]*500)
print(y_train.shape, y_test.shape)# npz 파일로 저장
np.savez_compressed('data/np_cats_dogs.npz',
X_train = X_train,
X_test = X_test,
y_train = y_train,
y_test = y_test)목표
- 개고양이 데이터 이진분류 실습
- MLP, CNN, 전이학습
- CNN 학습 : 개, 고양이 각각 1000장 총 2000 train 데이터의 개수가 적은 편
- 이미지 증식 (확장)
- 전이학습
# 구글 마운트
# 경로 설정
%cd "/content/drive/MyDrive/Colab Notebooks/24.08.29 DeepLearning"# 라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt# 데이터 불러오기
data = np.load('data/np_cats_dogs.npz')# 데이터 개수 확인
len(data)
# X_train, X_test,y_train, y_test# 데이터를 변수에 저장
X_train = data['X_train']
X_test = data['X_test']
y_train = data['y_train']
y_test= data['y_test']# 크기확인
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)MLP 모델 학습
# 라이브러리
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.callbacks import EarlyStopping# 모델 설계
mip_model = Sequential()
mip_model.add(Flatten(input_shape = (224,224,3)))
# 중간층
mip_model.add(Dense(256, activation="relu"))
mip_model.add(Dense(128, activation="relu"))
mip_model.add(Dense(64, activation="relu"))
# 출력층 (이진분류)
mip_model.add(Dense(1, activation="sigmoid"))# 컴파일
mip_model.compile(loss="binary_crossentropy",
optimizer="Adam",
metrics=["accuracy"])# 학습
# 조기 학습 중단
es = EarlyStopping(monitor = 'val_accuracy',
patience=10,
verbose=1)
mip_h = mip_model.fit(X_train, y_train,
validation_split=0.3,
epochs=50,
batch_size=64,
callbacks=es)# 시각화
plt.figure(figsize=(5,5))
plt.plot(range(1,18), mip_h.history['accuracy'], label='accuracy', color='lightgreen')
plt.plot(range(1,18), mip_h.history['val_accuracy'], label='val_accuracy', color='lightpink')
plt.title('mip_accuracy')
plt.legend()
plt.show()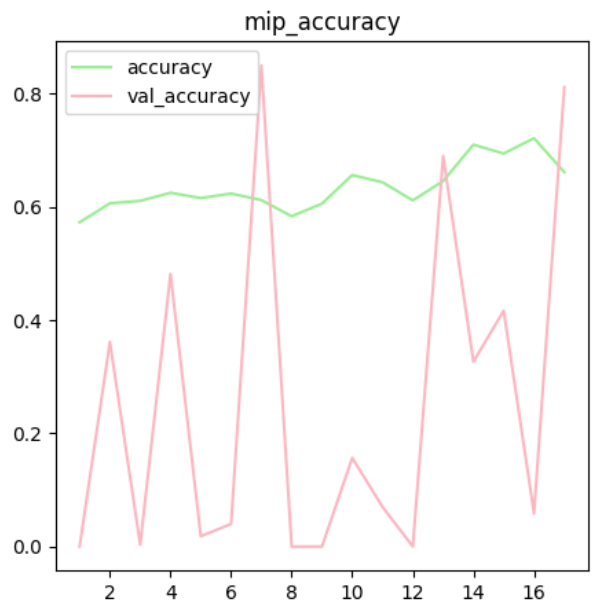
MLP는 위치에 민감하다!!!
모델이 학습을 제대로 하지 못하고 있음을 확인
복잡한 데이터, 모델은 너무 단순
MLP 모델은 특성상 이미지에 대해 학습성능이 떨어지는 것이 사실
이미지 분류에 특화된 모델인 CNN 모델을 활용하여 분석 -> 이미지의 특성 추출
CNN 모델
# CNN 모델링
from tensorflow.keras.layers import Conv2D, MaxPooling2D
# 뼈대
cnn_model = Sequential()
# 특성추출부
# Convolution : 필터32개, 커널사이즈(3,3), 패딩값 주기, 활성화함수:Relu
# Pooling: 맥스풀링-풀사이즈,(2,2)
# Convolution : 필터128개, 커널사이즈(3,3), 패딩값 주기, 활성화함수:Relu
# Pooling: 맥스풀링-풀사이즈,(2,2)
cnn_model.add(Conv2D(kernel_size = (3,3),
filters = 32,
input_shape = (224,224,3),
padding='same',
activation="relu"))
cnn_model.add(MaxPooling2D(pool_size = (2,2)))
cnn_model.add(Conv2D(kernel_size = (3,3),
filters = 128,
padding='same',
activation="relu"))
cnn_model.add(MaxPooling2D(pool_size = (2,2)))
# Flatten
cnn_model.add(Flatten())
# 분류부, 분석부, 분류기(1층, 512)
cnn_model.add(Dense(units=512, activation='relu'))
# 출력층
cnn_model.add(Dense(units=1, activation='sigmoid'))# 컴파일
cnn_model.compile(loss="binary_crossentropy",
optimizer="Adam",
metrics=["accuracy"])# 학습(검증데이터 30%, 반복횟수 50, 조기학습중단 es)
es = EarlyStopping(monitor = 'val_accuracy',
patience=10,
verbose=1)
cnn_h = cnn_model.fit(X_train, y_train,
validation_split=0.3,
epochs=50,
batch_size=64,
callbacks=[es])# 시각화
plt.figure(figsize=(5,5))
plt.plot(range(1,19), cnn_h.history['accuracy'], label='accuracy', color='lightgreen')
plt.plot(range(1,19), cnn_h.history['val_accuracy'], label='val_accuracy', color='lightpink')
plt.title('cnn1_accuracy')
plt.legend()
plt.show()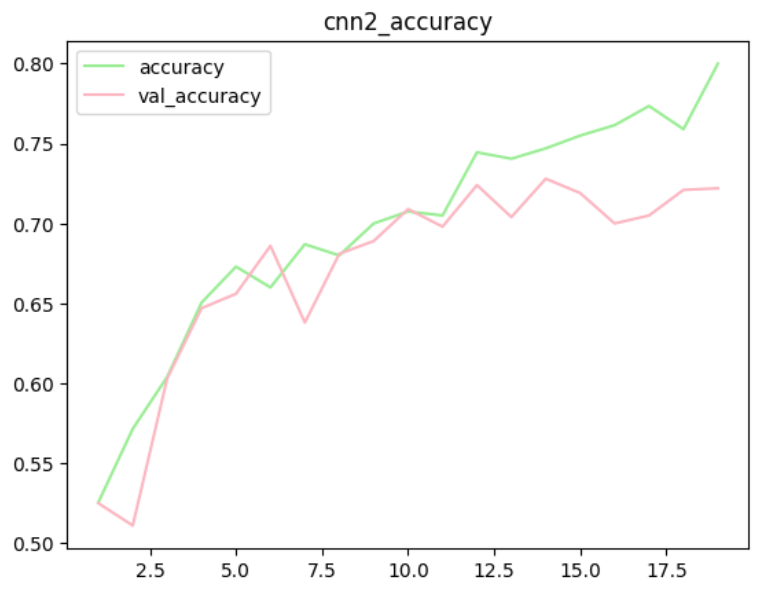
- MLP 모델링에 비해 성능이 향상된 것을 확인
- train에 대해서는 높은 성능을 보이나 검증 데이터에 대해서는 낮은 현상
- 과대적합의 확률이 높음
- 과대적합을 해소하여 모델의 일반화 성능을 높여보자
이미지 증식(확장)
- 데이터의 증식을 통한 CNN모델 성능 개선
from tensorflow.keras.preprocessing.image import ImageDataGenerator

# 변형될 형식 설정
# 0~255 -> 분산이 크다 -> 0~1 사이의 숫자로 변경 (정규화)
# 다양한 이미지 변형을 통해 이미지 증식
train_gen = ImageDataGenerator(rescale = 1./255, # 0~1 사이의 값으로 정규화
zoom_range = 0.2, # 20%까지 이미지를 확대, 축소
horizontal_flip = True, # 가로로 뒤집기, 좌우반전
rotation_range = 20 # 20도까지 회전
)
test_gen = ImageDataGenerator(rescale = 1./255)
# test 데이터는 증식할 필요가 없음
# 분산만 맞춰주면 됨# 이미지 데이터에 설정한 증식방법을 적용
train_generator = train_gen.flow_from_directory(train_dir, # train 데이터 경로
target_size = (224,224),
batch_size = 10,
class_mode="binary"
)
test_generator = test_gen.flow_from_directory(test_dir, # train 데이터 경로
target_size = (224,224),
batch_size = 10,
class_mode="binary"
)💛 과대적합 방지
- Dropout
- 이미지증식
Dropout
: 딥러닝에서 과대적합(Overfitting)을 방지하기 위하여 사용되는 기술
- 학습 중에 사용하는 뉴런의 일부를 무작위로 비활성화하는 기법
- model.add(Dropout(0.2))
- 전체 뉴런 중 20% 뉴런은 비활성화 후 학습진행
- 적용 이유 : 모델의 일반화 성능을 높이기 위함
from tensorflow.keras.layers import Dropout# CNN 모델링
cnn2_model = Sequential()
cnn2_model.add(Conv2D(kernel_size = (3,3),
filters = 32,
input_shape = (224,224,3),
padding='same',
activation="relu"))
cnn2_model.add(MaxPooling2D(pool_size = (2,2)))
cnn2_model.add(Conv2D(kernel_size = (3,3),
filters = 128,
input_shape = (224,224,3),
padding='same',
activation="relu"))
cnn2_model.add(MaxPooling2D(pool_size = (2,2)))
cnn2_model.add(Flatten())
# 분류부, 분석부, 분류기(1층, 512)
cnn2_model.add(Dense(units=512, activation='relu'))
# Dropout
cnn2_model.add(Dropout(0.2)) # 20% 비활성화 후 학습
# 출력층
cnn2_model.add(Dense(units=1, activation='sigmoid'))# 컴파일
cnn2_model.compile(loss="binary_crossentropy",
optimizer="Adam",
metrics=["accuracy"])
es = EarlyStopping(monitor = 'val_accuracy',
patience=5,
verbose=1)
# 학습(검증데이터 30%, 반복횟수 50, 조기학습중단 es)
cnn2_h = cnn2_model.fit(train_generator,
validation_data = test_generator,
epochs=20,
callbacks=[es])# 시각화
plt.plot(range(1,11), cnn2_h.history['accuracy'], label='accuracy', color='lightgreen')
plt.plot(range(1,11), cnn2_h.history['val_accuracy'], label='val_accuracy', color='lightpink')
plt.title('cnn2_accuracy')
plt.legend()
plt.show()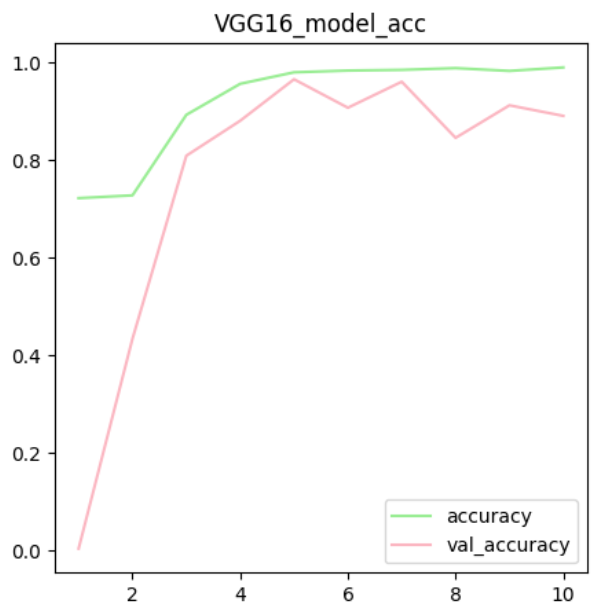
- 이미지 증식을 통해서 나름대로의 과대적합이 해소된 것을 확인할 수 있다.
- 이미지 증식으로 모델의 성능 개선
- 단점 : 시간이 너무 오래 걸림
- 자체적으로 설계한 모델은 검증을 여러번 진행하면서 수정 -> 시간이 오래 걸림
전이학습 (Transfer Learning)
-
기존에 학습되어 있는 모델을 가져다가 사용
-
다른 사람이 학습시켜놓은 모델의 일부를 추가학습시켜 사용하는 방법
- 적은 데이터로도 좋은 성능
- 학습을 빠르게 진행
- 학습데이터에 대해 특징을 추출하는 시간이 필요 없게 됨.(시간 단축)
-
완전히 똑같은 데이터로 학습X, 비슷한 이미지를 학습한 모델을 가져다가 내가 하고자 하는 이미지를 추가 학습
-
분류할 대상은 다르나, 판단하는 기준은 비슷하기 때문에 가능
VGG16 모델 활용
- VGG16 : 이미지넷 데이터 100만장을 학습시킨 모델
- class 1000개 가짐
# 사전학습된 모델 객체 생성
vgg16_model = VGG16(include_top = False, # 분류기의 포함 여부
weights = "imagenet",
input_shape = (224,224,3)
)
# include_top = False
# VGG16 모델은 다중분류 (클래스가 1000개) BUT 우리는 이진분류임.
# 우리의 데이터분석에 맞는 분류기를 추가해야 함
# weights = 'imagenet'
# 사전학습된 가중치를 불러오는 옵션, 어떤 이미지를 사용하였는가
vgg16_model.summary()# 미세조정 (Fine_Tunning)
# 사전학습된 모델의 일부분을 추가학습시켜 우리의 데이터에 잘 작동하도록 학습
vgg16_model.trainable = False # 동결
# 추가학습xxxxx
# 모든 층에 대하여 가중치 업데이트 xxx
# 왜?
# 100만장 이미지로 학습된 모델로 매우 우수한 성능
# 재학습할 경우 기존학습된 최적의 가중치가 훼손, 과대적합# 2. 미세조정 하되 마지막층만 학습하도록 설정
# 특징 추출하는 층에서 가장 마지막 층에 있는 층 block5_conv3만 학습시킨다
# 초기에 있는 특성 추출층은 저수준(엣지, 모서리, 큼직한 특징)의 특징을 추출
# 일반적으로 적용 가능 기존의 가중치를 유지
# 모델의 마지막층은 고수준의 특징을 추출(상세한 객체의 특징) ->
# 새로운 데이터인 개와 고양이의 중요한 정보를 학습시켜야 하기 때문(재학습)
for layer in vgg16_model.layers: # VGG16 모델의 모든 층을 반복적으로 탐색
if layer.name == 'block5_conv3': # 마지막층이라면?
layer.trainable = True # 재학습
else:
layer.trainable = False # 동결# 사전학습모델(특성추출부) + 우리의 분류기(이진분류)
# 모델 설계
v_model = Sequential()
v_model.add(vgg16_model) # 사전학습된 모델을 특성추출기로 사용
# 분류기
v_model.add(Flatten())
v_model.add(Dense(64, activation="relu"))
v_model.add(Dense(1, activation='sigmoid'))# 컴파일
v_model.compile(loss="binary_crossentropy",
optimizer="Adam",
metrics=["accuracy"])
# 학습
v_model_h = v_model.fit(X_train, y_train, validation_split=0.3, epochs=10) # 시각화
plt.figure(figsize=(5,5))
plt.plot(range(1,11), v_model_h.history['accuracy'], label='accuracy', color='lightgreen')
plt.plot(range(1,11), v_model_h.history['val_accuracy'], label='val_accuracy', color='lightpink')
plt.title('VGG16 model_acc')
plt.legend()
plt.show()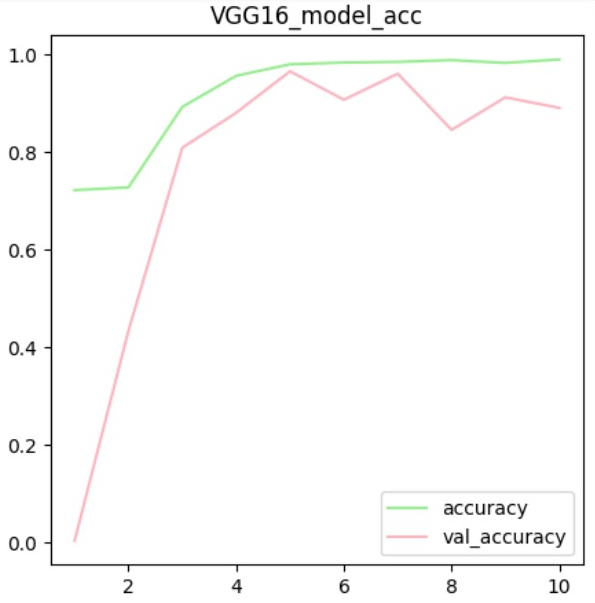

Hello, World!