| 백기선님의 라이브 스터디를 참고하여 작성한 게시물입니다.
자바는 컴파일 언어? 인터프리터 언어?
C, C++은 컴파일 언어, Python, JavaScript는 인터프리터 언어... (중얼 중얼)우리는 컴퓨터는 소스코드를 컴파일 또는 인터프리팅하여 머신 코드를 생성한다는 사실을 알고 있다.
Q: 그렇다면 자바는 컴파일 언어? 인터프리터 언어?
A: 하이브리드 언어
이게 무슨 띠용한 소리인가컴퓨터는 어떻게 자바 코드를 실행할까
참고: Is Java a Compiled or an Interpreted programming language ?
JDK(?)의 자바 컴파일러는 자바로 작성된 소스코드를 컴파일 한다. 컴파일 결과물인 자바 바이트코드(?)는 JRE(?)의 구성요소인 JVM(?) 의해 실행되는데, 순차적으로 JVM의 구성요소인 ClassLoader(?)는 메모리에 클래스 메타 데이터를 Loading하는 역할을 담당하고...(중략)그전에 용어 정리 먼저
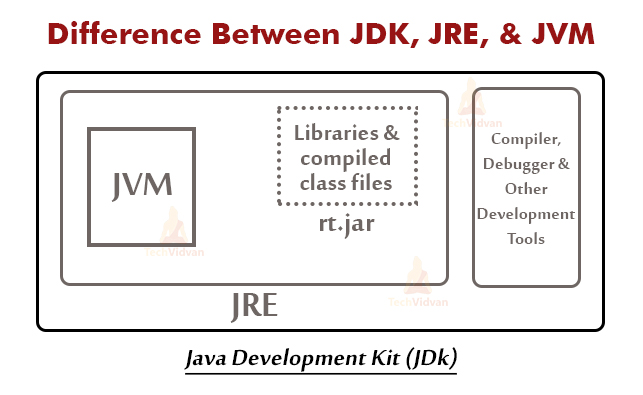 사진 출처: https://techvidvan.com/tutorials/java-virtual-machine/
사진 출처: https://techvidvan.com/tutorials/java-virtual-machine/
JDK: Java Development Kit
- 개발과 관련한 여러 편의 기능을 제공하는 개발 환경, 도구
- 여러 밴더들이 다양한 JDK를 제공한다.
- 명령을 치면
/Library/Java/JavaVirtualMachines/jdk-17.0.1.jdk/Contents/Home/bin에 위치한 실행 파일이 실행된다.
JRE: Java Runtime Environment
- Java Application이 작동할 수 있도록 도와주는 요소들의 집합(환경) (작동 = 개발 or 실행)
왜 JRE가 필요한가
- Software가 program을 실행시키기 위해선, 프로그램을 실행시킬 환경이 필요 (일반적으론 OS가 환경에 해당)
- 환경 도움 없이는 program은 다양한 기능과 자원 (OS의 기능, 자원 = 메모리, IO, 네트워크 등)사용에 제약을 받는다.
- 이때, JRE가 프로그램과 OS를 연결해주는 역할을 한다.
- OS를 추상화하여 Java Application에서 OS를 사용할 수 있도록 해줌
rt.jar? (jrt-fs.jar)
- rt.jar = runtime JAR (JAR: 일종의 자바 프로젝트 압축 파일)
- Core Java API의 핵심 기능을 담당하는 클래스들의 집합
- JDK 9버전 이후 부턴 성능 이슈 때문에 rt.jar가 사라졌다.
- rt.jar에 포함된 클래스들이 각각 다른 패키지로 흩어졌다.
- 대신 경량화된 jrt-fs.jar가 생겼다.
/Library/Java/JavaVirtualMachines/jdk-17.0.1.jdk/Contents/Home/lib에 위치java -verbose -version로 어떤 클래스 파일들이 포함되었는지 확인해보자
JVM: Java Virtual Machine
-
자바 바이트 코드를 실행하는 녀석
-
/Library/Java/JavaVirtualMachines를 확인해보자더 이상의 자세한 설명은 생략한다.는 아니고 아래에서 자세히 다루도록 하겠다.
Java Bytecode
- JVM이 이해할 수 있는 언어로 컴파일된 자바 소스 코드
즉, 자바 바이트 코드 = .class - 컴파일된 코드의 명령어 크기가 1바이트라서 자바 바이트 코드라고 불린다고 한다.
- JVM이 설치된 환경 어디에서든 실행될 수 있다.
이제 한 단계씩 살펴보자
1. JDK의 구성 요소인 자바 컴파일러가 바이트 코드를 생성한다.
참고: [조금 더 깊은 Java] Java Bytecode 를 알아보자 (자바를 컴파일하면 어떤 일이 일어날까?)
// Test.java
public class Test {
public static void main(String[] args) {
System.out.println("main");
printHi();
InnerClass.printBye();
}
public static void printHi() {
System.out.println("hi");
}
static class InnerClass {
static void printBye() {
System.out.println("bye");
}
}
}
위의 코드를 컴파일했더니, Test.class, Test$InnerClass.class생성 되었다.
과연 바이트코드란 놈은 어떻게 생겨먹었을까그냥은 확인하지 못한다. hex editor로 열어보자
봐도 뭔소린지 잘 모르겠다. JDK의 도움을 받아보자
javap -v -p -s Test.class
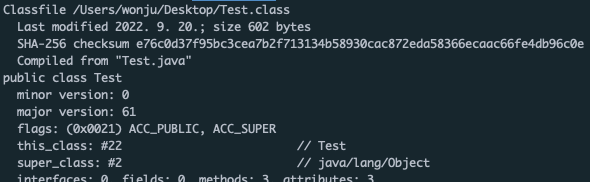
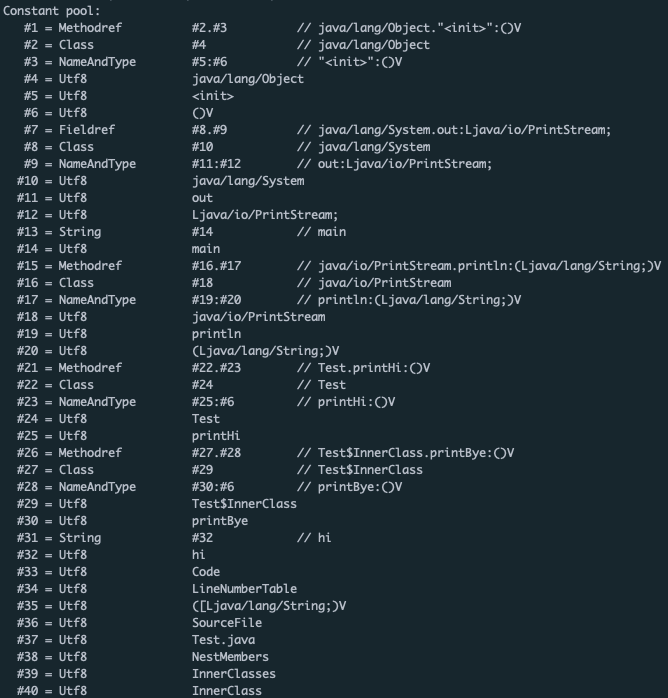
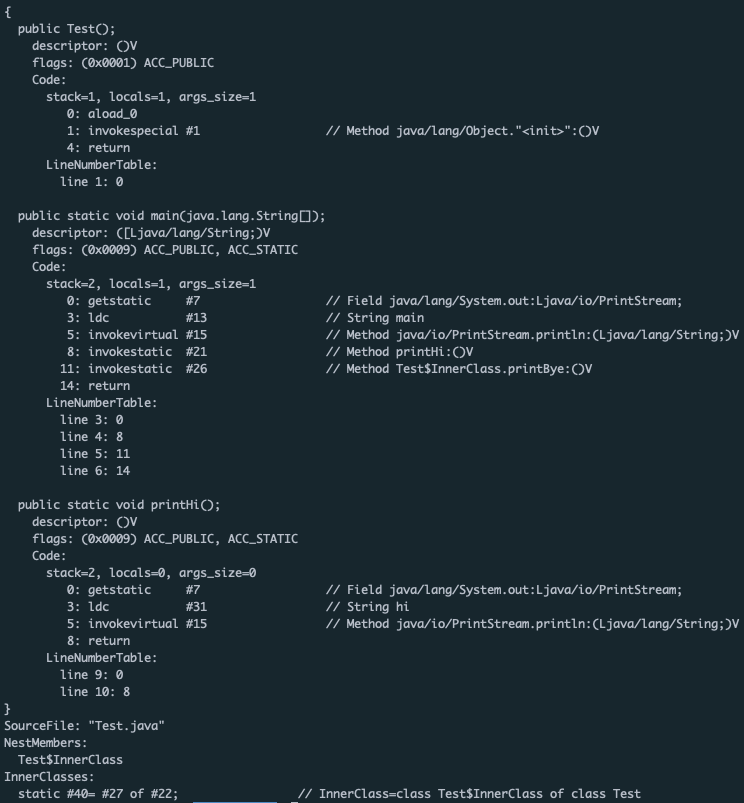
다음을 참고하자
2. JVM이 바이트 코드를 인터프리팅한다.
마침내 JVM에 대해 깊게 알아볼 시간이 왔다. (으악)
 사진 출처: https://dzone.com/articles/jvm-architecture-explained
사진 출처: https://dzone.com/articles/jvm-architecture-explained
JVM은 크게 ClassLoader, Runtime Data Area, Execution Engine으로 구분할 수 있다.
2-1. ClassLoader가 바이트 코드를 Run-time Data Area로 load한다
참고
Java 클래스로더 훑어보기
Oracle Java Virtual Machine Specification
자바는 매우 효율적으로 작동하도록 설계되었다.
그렇기 때문에 JVM은 모든 클래스를 최초 실행 시점에 메모리에 Load하지 않는다.
대신에, 자바 응용 프로그램이 특정 class를 필요로 할 때 동적으로 메모리에 클래스를 load한다.
Class Loader가 바로 그 기능을 수행한다.
Loading 3단계
ClassLoader의 작동 과정을 3 단계로 구분할 수 있다.
1. Loading
- 바이트 코드를 읽어서 JVM이 이해할 수 있는
바이너리 데이터를 생성 & 메모리(Method area)에 저장한다. 바이너리 데이터는 다음과 같은 정보들로 구성된다.- class, 부모 class를 식별할 수 있는 이름 (fully qualified name)
- interface, enum, class와 연관있는 바이트 코드 정보
- 식별자, 변수, 메소드 정보 등
- 바이트 코드(class)가 로딩 완료되면, JVM은 load한 class에 대한 메타 데이터를 가지고 있는
Class타입의 객체를 생성 & Heap Area에 저장한다.
Loading하려는 클래스들의 성격, 목적, 타이밍에 따라 서로 다른 ClassLoader가 사용된다.
1. Bootstrap ClassLoader
- 모든 ClassLoader 의 부모가 되는 최상위 ClassLoader
- 다른 ClassLoader와는 다르게 탑재되는 운영체제에 맞게 네이티브 코드로 작성됨 (Native C) - rt.jar를 포함한 JVM 을 구동시키기 위한 가장 필수적인 라이브러리의 클래스들을 JVM에 로딩
- Java 실행 초기에 작동
2. Extension ClassLoader
- BootStrap ClassLoader 다음으로 우선순위를 가지는 ClassLoader
- jre/lib/ext 폴더나 java.ext.dirs 환경 변수로 지정된 폴더에 있는 클래스 파일을 로딩
- Java로 작성됨
- Java9부터 platformClassLoader라고 불린다고 한다
ClassLoader.getPlatformClassLoader();3. Application ClassLoader
- Classpath 에 있는 클래스들을 로딩
- 개발자들이 자바 코드로 짠 클래스 파일들을 JVM에 로딩함 - Java로 작성됨
ClassLoader 작동 3원칙
1. Delegation Principle
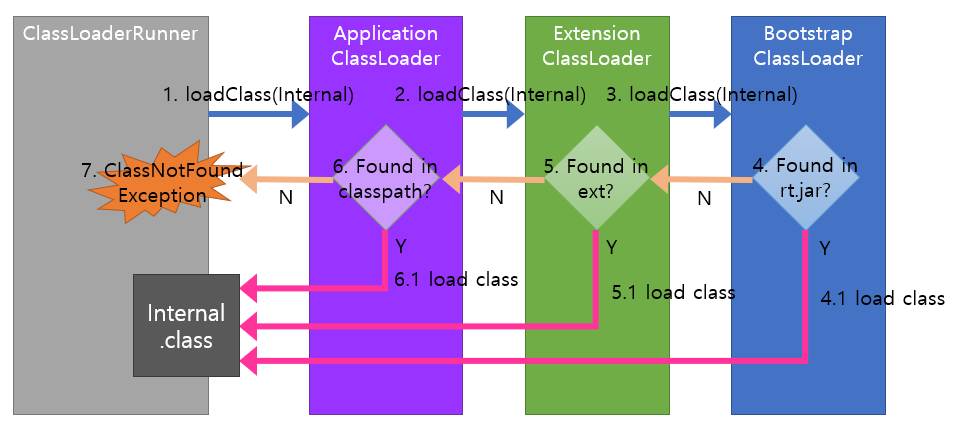 사진 출처:
사진 출처: 2. Visibility Principle
- 하위 클래스로더는 상위 클래스로더가 로딩한 클래스를 볼 수 있지만, 상위 클래스로더는 하위 클래스로더가 로딩한 클래스를 볼 수 없다.
public class ClassLoaderExample {
public static void main(String args[]) {
try {
// 이 클래스의 클래스로더를 출력한다.
System.out.println("ClassLoaderExample.getClass().getClassLoader(): " + ClassLoaderExample.class.getClassLoader());
// 확장 클래스로더를 통해서 이 클래스를 다시 로드한다.
Class.forName("ClassLoaderExample", true, ClassLoaderExample.class.getClassLoader().getParent());
} catch (ClassNotFoundException ex) {
ex.printStackTrace();
}
}
}코드 참고: https://blog.hexabrain.net/397
3. Uniqueness Principle
- 하위 클래스로더는 상위 클래스로더가 로딩한 클래스를 다시 로딩하지 않게 해서 로딩된 클래스의 유일성을 보장
2. Linking
로드된 클래스 파일들을 검증하고, 사용할 수 있게 준비하는 과정을 의미한다. Linking 과정을 세 단계로 구분할 수 있다.
2-1. Verification
- 클래스 파일이 유효한지를 확인하는 과정
- 접근 지정자에 따른 접근 범위에서 메서드에 접근하고 있는지
- 메서드의 매개변수 수와 자료형이 올바른지
- final 메서드와 클래스가 오버라이드 되지는 않았는지
- ...
- 클래스 파일이 JVM 의 구동 조건 대로 구현되지 않았을 경우에는 VerifyError 를 던진다.
2-2. Preparation
- 클래스 및 인터페이스의
static field(class Variable)를 위한 메모리를 할당하고, 이를 기본값으로 초기화 - 기본값으로 초기화된 static field들은 뒤의 Initialization 과정에서 코드에 작성한 초기값으로 변경된다. 때문에 Linking 단계에서 JVM 에 탑재된 클래스 파일의 코드를 실행되지 않는다.
2-3. Resolution
- Symbolic Reference 값을 JVM의 메모리 구성 요소인 Method Area의 런타임 환경 풀을 통하여 Direct Reference라는 메모리 주소 값으로 변경
- 임시로 배정한 메모리 주소(Symbolic reference)를 JVM의 실제 메모리 주소(Direct Reference)로 바꿔줌
- 해당 단계의 영향을 받는 JVM Instruction 요소는 new 및 instanceof 가 있다.
3. Initializing
- Linking과정을 거친 뒤, Initialization단계에서는 바이트 코드의 코드 영역을 읽는다.
- Java코드에서의 class와 interface의 값들을 지정한 값들로 초기화 및 초기화 메서드를 실행시켜줍니다.
- JVM은 멀티 쓰레딩으로 작동을 하며, 같은 시간에 한 번에 초기화를 하는 경우가 있기 때문에 초기화 단계에서도 동시성을 고려해주어야 합니다.
2-2. 바이트 코드가 Run-time Data Area에 위치한다.
ClassLoader를 통해 바이트 코드는 JVM의 Run-time Data Area에 로드된다.
Run-time Data Area는 운영체제로 부터 할당받은 자바 응용프로그램 프로세스의 메모리 공간을 의미한다.
그런데 JVM의 메모리 영역은 어떻게 생겼을까?
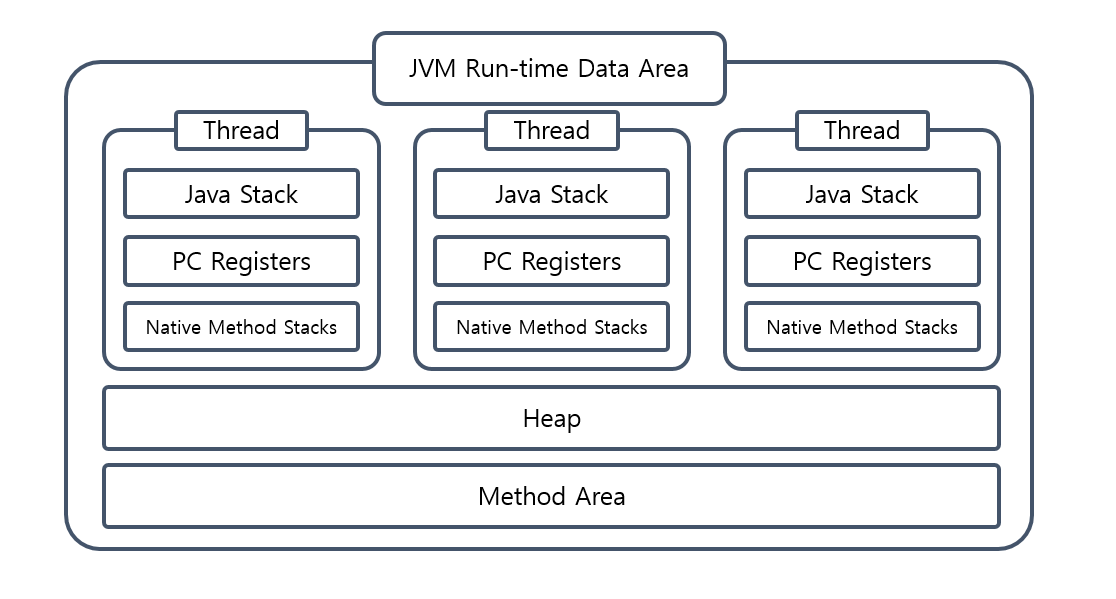
고놈 참 기똥차게 생겼네하나씩 살펴보자
1. Method Area
-
Method area에 모든 바이트 코드들이 load & store 된다.
- 클래스의 인스턴스 변수, 메소드 코드 (생성자 포함), 클래스 변수 등이 저장됨
- 즉, 인스턴스 생성과 관련된 정보들이 저장된다.
-
Constant Pool도 이곳에서 관리된다.
-
JVM 당 하나만 존재 -> 모든 Thread 들이 Method Area를 공유
-
JVM 의 다른 메모리 영역에서 해당 정보에 대한 요청이 오면, 실제 물리 메모리 주소로 변환해서 전달해줍니다. (?)
-
JVM 구동 시작 시에 생성이 되며, 종료 시까지 유지
2. Heap Area
- 코드 실행을 위한 객체 및 JRE 클래스들이 위치하는 곳
- 이곳에서는 문자열에 대한 정보를 가진 String Pool 뿐만이 아니라 실제 데이터를 가진 인스턴스, 배열 등이 저장이 됩니다.
- JVM 당 하나만 존재 -> 모든 Thread 들이 Heap Area를 공유
- Heap 영역이 가득 차게 되면 OutOfMemoryError 가 발생
- Heap 에서는 참조되지 않는 인스턴스와 배열이 존재 ->
GarbageCollection의 주 대상 - GarbageCollection 작동을 위해 Heap 영역은 5개의 세부 영역으로 나뉜다.
 사진 출처: https://junhyunny.github.io/information/java/what-is-jvm/
사진 출처: https://junhyunny.github.io/information/java/what-is-jvm/
3. Java Stack Area
참고: JVM stack과 frame
-
각 Thread 별로 따로 할당되는 영역 -> 동시성 문제에서 자유롭다.
-
각 Thread 들은 메소드를 호출할 때마다 Frame 이라는 단위를 push
-
메소드가 마무리되며 결과를 반환하면 해당 Frame 은 Stack 으로부터 pop
-
Frame 은 메소드에 대한 정보를 가지고 있는
Local Variable,Operand Stack그리고Constant Pool Reference로 구성이 되어있다.-
Local Variable은 메소드의 지역 변수들을 저장하는 영역

-
Operand Stack은 메소드 내 연산을 위한 작업 공간 -
Constant Pool Reference는 Constant Pool참조를 위한 공간
-
-
4. PC Register Area
- 멀티 스레딩을 위해, 최근에 실행한 명령어의 주소값을
PC Registers영역에 저장, 관리한다. - 스레드들은 각각 자신만의
PC Registers영역을 가진다. - 만약 실행한 메소드가 네이티브하지 않다면, PC Registers 는 JVM 에서 사용된 명령의 주소 값을 저장
- 네이티브하다면 undefined 가 저장
5. Native Method Stack Area
- Native Method Stacks 는 Java 로 작성되지 않은 메소드를 다루는 영역
- 다른 프로그래밍 언어로 작성된 메소드들을 Native Method 라고 한다.
- Java Stacks 영역과 비슷하게 Native Method 가 실행될 경우 Stack 에 해당 메서드가 쌓이게 됩니다.
- 각각의 Thread 들이 생성되면 Native Method Stacks 도 동일하게 생성이 됩니다.
2-3. Execution Engine이 byte code를 interpret & compile한다
참고
JVM - 실행 엔진(Execution Engine)
Understanding Java JIT Compilation with JITWatch, Part 1
JIT Compiler
How the JIT compiler boosts Java performance in OpenJDK
JIT(Just In Time) 컴파일러
JVM Interpreter
기본적으론 JVM은 interpreter를 통해 바이트 코드를 기계어로 interprete하는 방식을 취한다.
JIT Compiler
-
JIT: Just in Time = 제 때 = 메소드가 호출될 때
-
JVM 인터프리터를 통해 모든 플랫폼(운영체제)에서 동일한 바이트 코드를 실행할 수 있다는 장점 이면에는 '성능'이라는 문제점이 있다.
- 런타임에 기계어로 번역 -> 성능 문제
- 동일한 코드(EX: 반복문)을 여러 번 기계어로 번역해야 하는 문제점
-
이러한 문제를 해결하기 위해, JVM은 JIT Compiler를 사용한다.
-
동일한 코드에 대해 interprete하는 횟수가 threshold를 넘으면 JIT compiler가 별도의 스레드(컴파일 스레드)에서 해당 코드를 기계어로 컴파일한다.
- 컴파일이 완료될 때 까지는 계속 interprete방식으로 처리
- 컴파일된 코드로 전환되는 순간은 seamless
-
threshold는 두가지 측면을 고려하여 결정된다.
- method entry counter (JVM 내에 있는 메서드가 호출된 횟수)
- back-edge loop counter (메서드가 루프를 빠져나오기까지 돈 횟수)
- 테스트 해보자
package jit;
public class JitTest {
public static void main(String[] args) {
for (int i = 0; i < 500; ++i) {
long startTime = System.nanoTime();
for (int j = 0; j < 1000; ++j) {
new Object();
}
long endTime = System.nanoTime();
System.out.printf("%d\t%d\n", i, endTime - startTime);
}
}
}
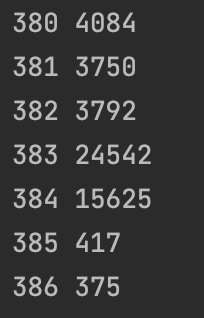
- 특정 시점에 실행 속도가 감소한 것을 확인할 수 있다.
java -XX:+PrintCompilation JitTest.java로 자세히 확인해보자
 실행시간(ms), 코드블록 번호 | 코드 분류(n,s,!,% 등) | 코드 컴파일 티어 | 실행한 클래스 정보
실행시간(ms), 코드블록 번호 | 코드 분류(n,s,!,% 등) | 코드 컴파일 티어 | 실행한 클래스 정보
n : native method
s : synchronized method
! : 이건 모르겠음;
% : 코드 캐싱된 작업이 수행됨 -> Jit compiler가 작동
코드 컴파일 티어: 얼마나 깊게(최적화 되어)컴파일 되었는가-
Jit compiler가 작동되어 도출된 최적화된 기계어를 code cache에 저장
-
Jit compiler는 내부적으로 2개의 하위 컴파일러로 구성
- C1: 1 ~ 3 level 수준의 컴파일 담당
- C2: 4 level 수준의 컴파일 담당
-
모든 컴파일된 코드를 code cache에 저장할 순 없다. (용량 문제)
- cache size 조절 & move-out 발생
- JVM이 설치된 OS에 따라 기본 cache size가 다름
+a: Garbage Collection
참고: Java Garbage Collection
JVM에 관하여 - Part 4, Garbage Collection 기초
공부 못하는 사람 특: 시험에 안 나오는 부분 공부함stop-the-world
- stop-the-world란, GarbageCollection(이하 GC)을 실행하기 위해 JVM이 애플리케이션 실행을 멈추는 것이다.
- stop-the-world가 발생하면 GC를 실행하는 쓰레드를 제외한 나머지 쓰레드는 모두 작업을 멈춘다.
- GC 작업을 완료한 이후에야 중단했던 작업을 다시 시작한다.
- 어떤 GC 알고리즘을 사용하더라도 stop-the-world는 발생한다.
- 대개의 경우 GC 튜닝이란 이 stop-the-world 시간을 줄이는 것이다.
-
Java에서는 개발자가 프로그램 코드로 메모리를 명시적으로 해제하지 않기 때문에 GC가 더 이상 필요 없는 객체를 찾아 지우는 작업을 한다.
- 명시적으로 지울수도 있으나, 성능상 매우 좋지 않기 때문에 비권장
-
GC는 두 가지 가설(전제 조건)을 기반으로 작동한다.
- 대부분의 객체는 금방 접근 불가능 상태(unreachable)가 된다.
- 오래된 객체에서 젊은 객체로의 참조는 아주 적게 존재한다. (weak generational hypothesis)
-
GC는 위 가설의 장점을 최대한 살리기 위해서 HotSpot VM에서는 크게 2개로 물리적 공간을 나누었다.
-
Yong Generation 영역
새롭게 생성한 객체의 대부분이 여기에 위치한다. 대부분의 객체가 금방 접근 불가능 상태가 되기 때문에 매우 많은 객체가 Young 영역에 생성되었다가 사라진다.
이 영역에서 객체가 사라질때Minor GC가 발생한다고 말한다. -
Old Generation 영역
접근 불가능 상태로 되지 않아 Young 영역에서 살아남은 객체가 여기로 복사된다. 대부분 Young 영역보다 크게 할당하며, 크기가 큰 만큼 Young 영역보다 GC는 적게 발생한다.
이 영역에서 객체가 사라질 때Major GC(혹은 Full GC)가 발생한다고 말한다.
-
추가 학습 주제
- Constant Pool, String Pool
- 여러 종류의 자바
- class path
