
-
SQL에 대해 책 실습을 통해 알아봅시다!
-
모두의 SQL 책 실습입니다.
SQL
-
Single Quote VS Double Quote 참고!
-
ADD_MONTHS(날짜, 숫자) : 날짜에 월을 빼거나 더하는 함수
SELECT hire_date,
ADD_MONTHS(hire_date, 3) 더하기_적용결과,
ADD_MONTHS(hire_date, -3) 빼기_적용결과
FROM employees
WHERE employee_id BETWEEN 100 AND 106;- NEXT_DAY(날짜, '요일' or 숫자) : 지정된 요일의 돌아오는 날짜가 언제인지 계산하는 함수
SELECT hire_date,
-- NEXT_DAY(hire_date, '금요일') 적용결과_문자지정,
NEXT_DAY(hire_date, 'FRI') 적용결과_문자지정,
NEXT_DAY(hire_date, 6) 적용결과_숫자지정
FROM employees
WHERE employee_id BETWEEN 100 AND 106;
- 주의!
- 아직 지나지 않은 요일은 해당 주 날짜가 조회된다.
- 이미 지난 요일에 대해서는 정확하게 다음주 날짜가 조회된다.
SELECT hire_date,
-- NEXT_DAY(hire_date, '금요일') 적용결과_문자지정,
NEXT_DAY('11-AUG-22', 'FRI') 적용결과_문자지정
FROM employees
WHERE employee_id BETWEEN 100 AND 106;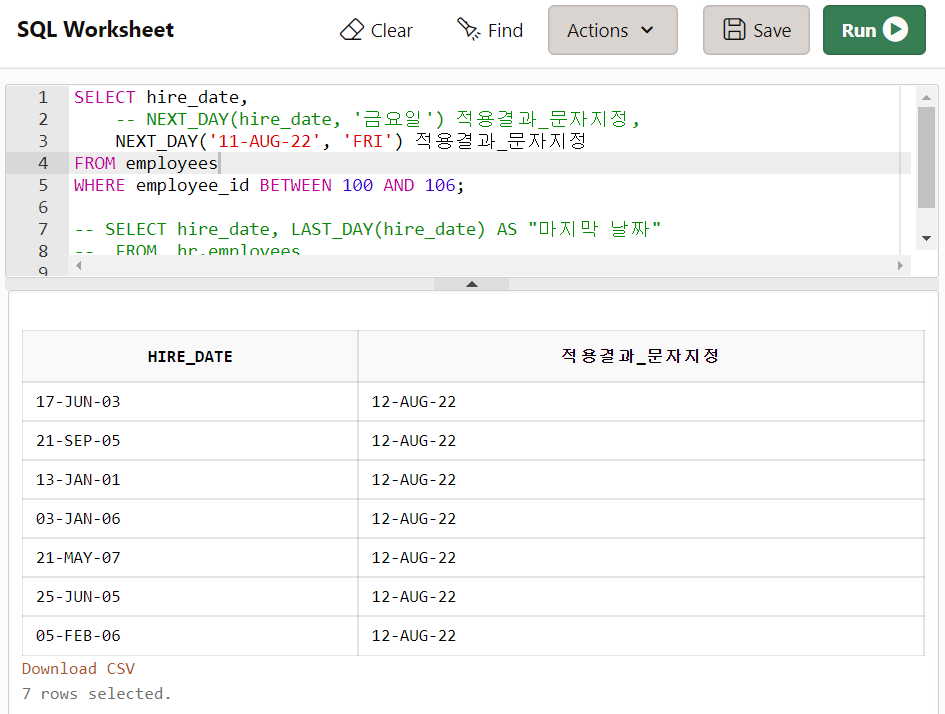
- LAST_DAY(날짜) : 돌아오는 월의 마지막 날짜 계산
SELECT hire_date, LAST_DAY(hire_date) AS "마지막 날짜"
FROM hr.employees
WHERE employee_id BETWEEN 100 AND 106;- ROUND, TRUNC : 날짜를 반올림하거나 절삭하기
SELECT hire_date,
ROUND(hire_date, 'MONTH') AS "MONTH 기준 반올림(16일 기준)",
ROUND(hire_date, 'YEAR') AS "YEAR 기준 반올림(7월 1일 기준)",
TRUNC(hire_date, 'MONTH') AS "MONTH 기준 절삭",
TRUNC(hire_date, 'YEAR') AS "YEAR 기준 절삭"
FROM employees
WHERE employee_id BETWEEN 100 AND 106;- 날짜 함수 : 연차나 주차 등 달력 형태의 계산이 필요할 때 주로 사용합니다.
자동 변환 / 수동 변환
SELECT 1 + '2'
FROM DUAL;
SELECT '1' + '2'
FROM DUAL;
SELECT '1q' + '002'
FROM DUAL; // invalid number-
숫자 <--> 문자 / 문자 <--> 날짜
-
숫자와 날짜 사이에는 바로 변환 X
-
날짜 및 시간 형식 반환하기
-
TO_CHAR(날짜 데이터 타입, '지정형식') : 날짜 => 문자, 숫자 => 문자
- 날짜 => 문자
SELECT TO_CHAR(SYSDATE, 'YY') 년,
TO_CHAR(SYSDATE, 'YYYY') 년,
TO_CHAR(SYSDATE, 'MM') 월,
TO_CHAR(SYSDATE, 'MON') 월,
TO_CHAR(SYSDATE, 'YYYYMMDD') 응용적용1,
TO_CHAR(TO_DATE('20171008', 'YYYYMMDD'), 'YYYYMMDD') 응용적용2
FROM dual;
-- TO_DATE => 문자 => 날짜 - 위에서 TO_DATE는 결과가 08-OCT-17로 나오기 때문에 날짜를 문자로 바꾸어주는 예시입니다.
SELECT TO_CHAR(SYSDATE, 'YYYY/MM/DD') 현재날짜1,
TO_CHAR(SYSDATE, 'YYYY"년" MM"월" DD"일"') 현재날짜2
FROM dual;- 시간 표현
SELECT TO_CHAR(SYSDATE, 'HH:MI:SS PM') 현재시간,
TO_CHAR(SYSDATE, 'YYYY/MM/DD HH:MI:SS PM') 현재_날짜와시간
FROM dual;
SELECT TO_CHAR(SYSDATE, 'HH-MI-SS PM') 현재시간,
TO_CHAR(SYSDATE, '"날짜:" YYYY/MM/DD "시각:" HH:MI:SS PM') 현재_날짜와시간
FROM dual;- TO_CHAR(숫자 데이터 타입, '지정 형식') : 숫자 값을 지정한 형식의 문자열로 변환하는 함수
SELECT TO_CHAR(salary, '9,9999,999'),
TO_CHAR(salary, 'L9999999'),
TO_CHAR(salary, '9999999')
FROM employees;- TO_NUMBER(number) : 문자 ==> 숫자
-- 명시적 변환
SELECT TO_NUMBER('123') + 1
FROM dual;
-- 묵시적 변환
SELECT '123' + 1
FROM dual;
- 문자 ==> 날짜 데이터로 변환
SELECT TO_DATE('20171007', 'YY/MM/DD')
FROM dual; // 예상했던 결과와 다름
// why?- 날짜 포맷은 데이터베이스 설정에 영향을 받는다.
SELECT TO_DATE('20171007', 'YYMMDD'),
TO_DATE('20171007', 'YYYYMMDD'),
TO_DATE('20171007', 'YYYY:MM:DD')일반함수
- NULL 처리를 위한 NVL
- NULL은 공백이나 0과는 다르다.
- 데이터 자체가 없는 상태를 의미한다.
- NULL에 대한 산술 연산의 결과는 NULL
- NULL에 대한 비교 연산의 결과는 거짓(false)
- 숫자 타입에서 NULL은 가장 큰 값으로 처리된다.
-- 전 직원의 모든 정보를 출력하되, 커미션을 오름 차순으로 정렬
SELECT *
FROM employees
ORDER BY commission_pct ASC;
SELECT salary,
commission_pct,
salary * commission_pct 최종급여
FROM employees
ORDER BY commission_pct;- NVL(열 이름, 치환 값) 함수 : NULL 데이터를 원하는 값으로 변경하여 리턴한다.
- NULL이 아닌 경우는 원래의 값을 리턴한다.
-- NULL이면 1로 바꾸고, 아니면 그냥 출력
SELECT salary,
commission_pct,
salary * NVL(commission_pct,1) 최종급여
FROM employees
ORDER BY commission_pct;-
DECODE: 복잡한 함수 - 조건에 따른 단순 분기처리-
DECODE(열 이름, 조건 값, 치환 값, 기본 값)
- 조건 값에 해당할 경우 치환 값 출력
- 조건 값에 해당하지 않을 경우 기본 값 출력
-
SELECT first_name,
department_id,
salary 원래급여,
DECODE(department_id, 60, salary * 1.1, salary) 조정된_급여,
DECODE(department_id, 60, '10%인상', '미인상') 인상_여부
FROM employees;- CASE 표현식 : 복잡한 조건에 대해서 다중 분기 처리하기
SELECT employee_id, first_name, last_name, salary,
CASE
WHEN salary >= 9000 THEN '상위급여'
WHEN salary BETWEEN 6000 AND 8999 THEN '중위급여'
ELSE '하위급여'
END AS 급여등급
FROM employees
WHERE job_id = 'IT_PROG';연습문제!
--- 다음과 같이 입사 직원의 사번, 입사일, 입사월, 입사 분기를 출력
SELECT employee_id, hire_date, TO_CHAR(hire_date, 'MM') AS 입사월,
CASE
WHEN TO_NUMBER(TO_CHAR(hire_date, 'MM')) BETWEEN 1 AND 3 THEN '1분기 입사자'
WHEN TO_NUMBER(TO_CHAR(hire_date, 'MM')) BETWEEN 4 AND 6 THEN '2분기 입사자'
WHEN TO_NUMBER(TO_CHAR(hire_date, 'MM')) BETWEEN 7 AND 9 THEN '3분기 입사자'
WHEN TO_NUMBER(TO_CHAR(hire_date, 'MM')) BETWEEN 10 AND 12 THEN '4분기 입사자'
END AS "입사분기"
FROM employees;-
RANK, DENSE_RANK, ROW_NUMBER : 데이터 값에 순위 매기기
- DENSE_RANK()는 골프에서 공동 순위 같은 개념이다. 공동 1등이 3명이며 네번째 선수는 2등이 된다.
- RANK()는 공동 순위 개념은 DENSE_RANK()와 동일하지만 공동 1등이 3명이면 4번째 선수는 4등이 된다.
SELECT employee_id,
salary,
RANK() OVER(ORDER BY salary DESC) RANK_급여,
DENSE_RANK() OVER(ORDER BY salary DESC) DENSE_RANK_급여,
ROW_NUMBER() OVER(ORDER BY salary DESC) ROW_NUMBER_급여
FROM employees;-
부서별로 급여 순위를 출력
-
PARTITION BY : 특정 컬럼을 기준으로 그룹핑한다.
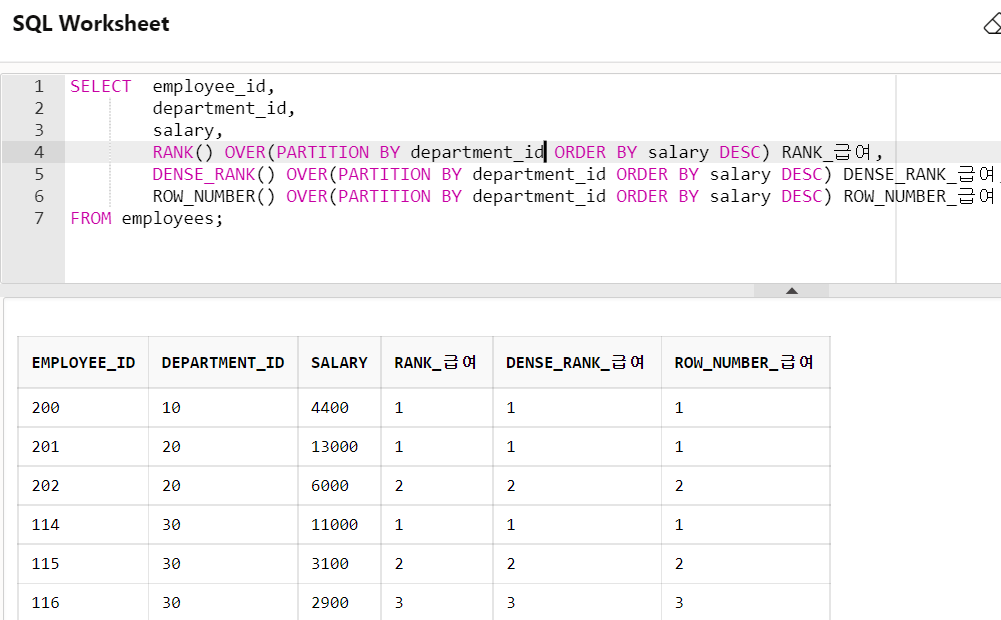
SELECT employee_id,
department_id,
salary,
RANK() OVER(PARTITION BY department_id ORDER BY salary DESC) RANK_급여,
DENSE_RANK() OVER(PARTITION BY department_id ORDER BY salary DESC) DENSE_RANK_급여,
ROW_NUMBER() OVER(PARTITION BY department_id ORDER BY salary DESC) ROW_NUMBER_급여
FROM employees;1) 전체 직원을 대상으로 입사일이 빠른 순서대로 순위를 출력하시오.
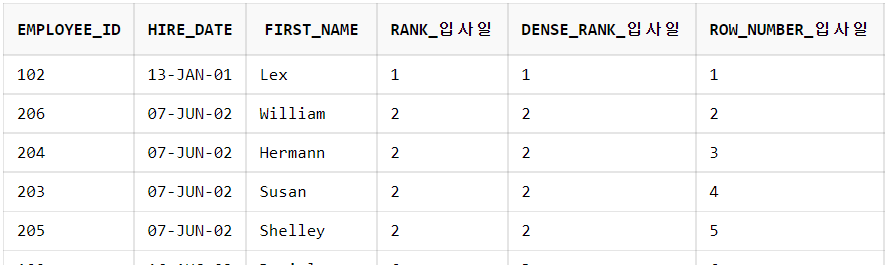
SELECT employee_id,
hire_date,
first_name,
RANK() OVER(ORDER BY hire_date) RANK_입사일,
DENSE_RANK() OVER(ORDER BY hire_date) DENSE_RANK_입사일,
ROW_NUMBER() OVER(ORDER BY hire_date) ROW_NUMBER_입사일
FROM employees;2) 각 부서별 입사일이 빠른 순서대로 순위를 출력하시오.
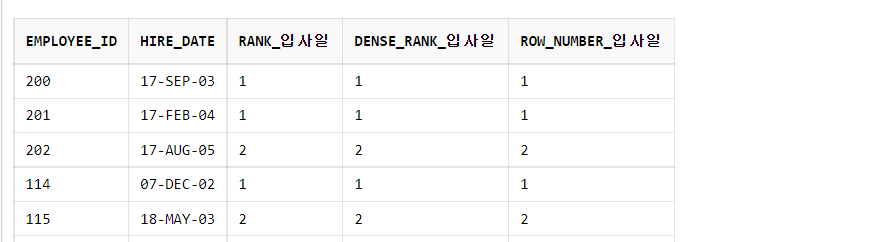
SELECT employee_id,
hire_date,
RANK() OVER(PARTITION BY department_id ORDER BY hire_date ASC) RANK_입사일,
DENSE_RANK() OVER(PARTITION BY department_id ORDER BY hire_date ASC) DENSE_RANK_입사일,
ROW_NUMBER() OVER(PARTITION BY department_id ORDER BY hire_date ASC) ROW_NUMBER_입사일
FROM employees;그룹 함수
-
COUNT(salary) : 급여를 받는 직원 수를 리턴(NULL 데이터는 제외)
-
COUNT(*) : 테이블 전체에 몇 건의 Row가 존재하는지 리턴(NULL 포함)
-
SUM(salary) : 급여의 총합 리턴
-
MAX(salary) : 최고 급여 리턴
-
MIN(salary) : 최소 급여 리턴
-
AVG(salary) : 급여 평균 리턴
SELECT COUNT(*) 전체직원수, COUNT(commission_pct) 커미션_직원수, COUNT(manager_id) 매니저있는_직원수 FROM employees;
-
SUM / AVG
-- 총합을 개수로 나누면 평균이 나오기 때문에 동일할 것!
SELECT
SUM(salary) 급여_총합,
AVG(salary) 함수_평균급여,
SUM(salary)/COUNT(salary) 산술연산_평균급여
FROM employees;-
주의! 문자에서는 A가 가장 작은 문자, Z가 가장 큰 문자로 처리된다.
-
MAX/MIN

SELECT MAX(salary) 최대_급여,
MIN(salary) 최소_급여,
MAX(first_name) 가장_큰이름,
MIN(first_name) 가장_작은이름
FROM employees;- 되지만 가독성이 떨어짐!
- 직무별 평균급여인지, 부서별 평균급여인지!
- 웬만하면 무엇을 기준으로 그룹핑했는지 SELECT 절에 표시해주는 게 좋음
-- BAD
SELECT AVG(salary)
FROM employees
SELECT AVG(salary)
FROM employees
GROUP BY department_id;
-- GOOD
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id;GROUP BY : 그룹으로 묶기
SELECT 컬럼목록
FROM 테이블이름
WHERE 조건
GROUP BY 그룹핑(특정 컬럼을 기준으로)
ORDER BY 정렬방식
- 각 부서별 평균급여를 출력하시오.
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id;
-- 정렬 포함
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id
ORDER BY department_id;-
만약 부서가 없는 직원이 있다면?
-
그룹핑 전에 WHERE 절에서 삭제한다.

SELECT department_id, AVG(salary) FROM employees WHERE department_id IS NOT NULL GROUP BY department_id ORDER BY department_id ASC;
-
-
주의! SELECT절에 기준열과 그룹함수가 같이 지정되면, GROUP BY 절에 기준 열 이름이 반드시 기술되어야 한다.
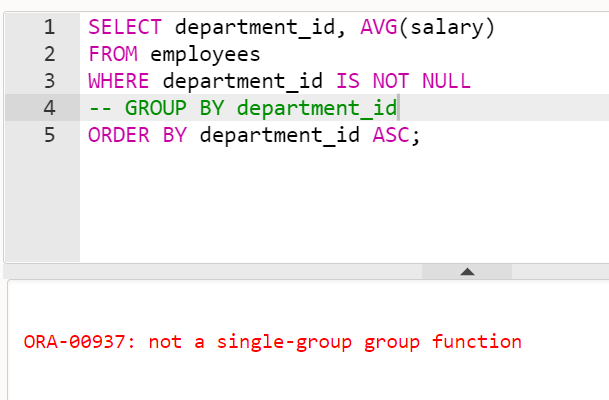
-
각 부서별 최대, 최소 급여를 출력하시오
- 단, 부서 아이디를 오름차순으로 정렬해서
SELECT department_id, MAX(salary), MIN(salary)
FROM employees
GROUP BY department_id
ORDER BY MAX(salary), MIN(salary);- 실제 급여를 받는 직원을 대상으로 직무별(job_id) 급여의 총합과 평균을 조회하시오.
SELECT job_id 직무,
SUM(salary) 직무별_총급여,
AVG(salary) 직무별_평균급여
FROM employees
WHERE department_id > 10
GROUP BY job_id
ORDER BY SUM(salary) DESC, AVG(salary);-
그룹에 대한 소그룹
- 부서배치를 받은 직원들을 대상으로 부서별, 직무별 급여 총합과 평균 급여를 조회하시오.
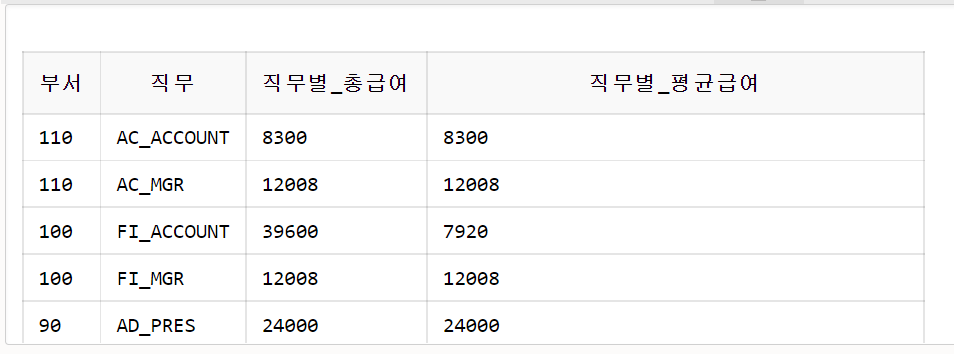
SELECT department_id 부서,
job_id 직무,
SUM(salary) 직무별_총급여,
AVG(salary) 직무별_평균급여
FROM employees
WHERE department_id >= 10
GROUP BY department_id, job_id
ORDER BY department_id DESC, job_id;-
부서별 직원 수 조회
- COUNT(*)는 NULL까지 포함이라, 정확히 Column이름을 정하는 게 좋음
- 지금은 COUNT(*)과 COUNT(employee_id)가 같음
SELECT department_id, COUNT(*) 직원수, COUNT(employee_id) 직원수 FROM employees GROUP BY department_id ORDER BY department_id ASC;
-
단, 직원수가 10명 이상인 부서정보만 조회 결과에 포함한다.
- having 절이 필요
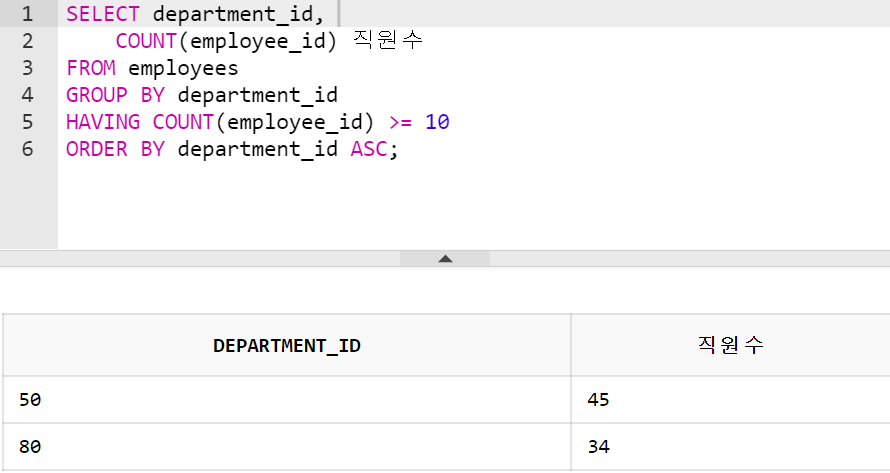
-
HAVING : 그룹 함수 결과에 대한 필터링(제약조건)
- GROUP BY 밑에 작성하는 것
-- 급여를 받는 직원을 대상으로 직무별 급여의 총합과 평균을 구하되, 급여 총합이 30000 이상인 데이터만 출력한다.
SELECT
job_id 직무,
SUM(salary) 직무별_총급여,
AVG(salary) 직무별_평균급여
FROM employees
WHERE employee_id >= 10
GROUP BY job_id
HAVING SUM(salary) > 30000
ORDER BY SUM(salary);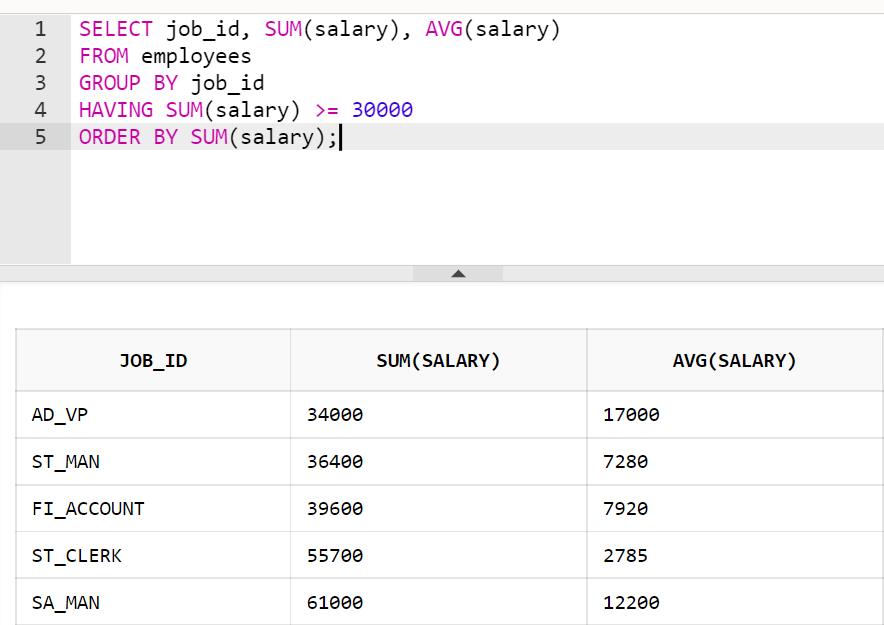
ERD + DB
- 101번 직원의 이름과 부서정보를 조회하시오.
-- A.department_id가 FK, B.department_id가 PK
SELECT A.first_name, B.*
FROM employees A, departments B
WHERE A.department_id = B.department_id
AND A.employee_id = 101;-
위의 코드에서 Alias를 명시하지 않으면 알 수 없음
- 중복되어 있지 않으면 굳이 Alias를 앞에 안 붙여도 됨
-
여러 개 컬럼을 연결해서 PK를 연결할 수 있다.
- ex) JOB_HISTORY ==> employee_id + start_date
- 각각은 겹칠 수 있음
-
관계 ==> 여러개와 하나의 구분
-
FK
- DEPARTMENTS와 EMPLOYEES에서 department_id
- DEPARTMENTS와 LOCATIONS에서 location_id
- LOCATIONS와 COUNTIRES에서 country_id
- COUNTRIES와 REGIONS에서 region_id
-
테이블의 개수 - 1개 만큼의 조인 조건이 필요함
EQUI_JOIN
-
SELECT * FROM EMP, DEPT
WHERE EMP.DEPTNO = DEPT.DEPTNO-
EMP와 DEPT 테이블 사이에 다리를 하나 두겠다.
-
같았을 때, 직원과 부서의 이름을 끄집어 내자
-
-
큰 테이블을 만들고 나면, 다시 뽑아내는 것은 같음
-
WHERE 절에 JOIN 조건이 기술되지 않으면 모든 경우의 수가 출력된다.
SELECT COUNT(*) FROM employees;
SELECT COUNT(*) FROM departments;
SELECT *
FROM employees A, departments B
WHERE A.department_id = B.department_id;- 직원의 사번, 부서아이디, 부서이름, 부서가 속한 도시명을 조회하시오.
SELECT E.employee_id, D.department_id, D.department_name, L.city
FROM employees E, departments D, locations L
WHERE E.department_id = D.department_id AND D.location_id = L.location_id;- 연습문제
- 'Seattle'에서 근무하는 직원의 수를 조회하시오.
SELECT COUNT(E.employee_id), L.city
FROM employees E, departments D, locations L
WHERE
E.department_id = D.department_id
AND D.location_id = L.location_id
AND L.city = 'Seattle'
GROUP BY L.city;
SELECT COUNT(*)
FROM employees E, departments D, locations L
WHERE
E.department_id = D.department_id
AND D.location_id = L.location_id
AND L.city = 'Seattle';- 각 도시별 근무 직원수를 조회하시오.
- 단, 출력 결과에 도시 이름이 포함되어야 한다.
SELECT COUNT(E.employee_id), L.city
FROM employees E, departments D, locations L
WHERE
E.department_id = D.department_id
AND D.location_id = L.location_id
GROUP BY L.city;
SELECT COUNT(*), L.city
FROM employees E, departments D, locations L
WHERE
E.department_id = D.department_id
AND D.location_id = L.location_id
GROUP BY L.city;- 100번 직원의 직무 이력을 조회하시오.
-
어떤 직무를 언제부터 언제까지 담당했었는지...
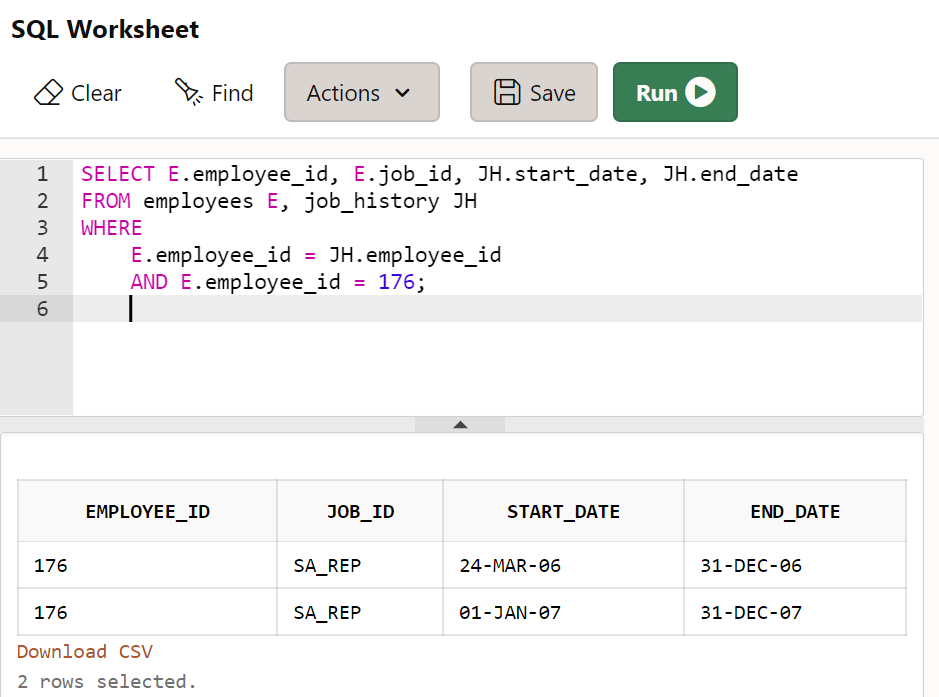
SELECT E.employee_id, E.job_id, JH.start_date, JH.end_date
FROM employees E, job_history JH
WHERE
E.employee_id = JH.employee_id
AND E.employee_id = 176;Outer JOIN
-
조인 조건을 만족하지 못하는 데이터까지 조회 결과에 포함시킬 때 사용하는 조인 기법
-
직원이 사번, 이름, 성, 부서아이디, 부서이름을 조회하되, 부서가 없는 직원 정보도 모두 출력하시오.
-
부서 배치를 받지 않은 직원이 있는 경우에는?
- 그래서 (+) 연산자를 추가하면?
-
-
(+): 외부 조인 연산자- 위치 : 전부 보고싶은 데이터가 있는 테이블의 반대쪽
SELECT E.employee_id, E.first_name, D.department_name
FROM employees E, departments D
WHERE E.department_id = D.department_id
ORDER BY E.employee_id;
-- 위, 아래 SQL 코드는 명확히 다름!
SELECT E.employee_id, E.first_name, D.department_name
FROM employees E, departments D
WHERE E.department_id = D.department_id(+)
ORDER BY E.employee_id;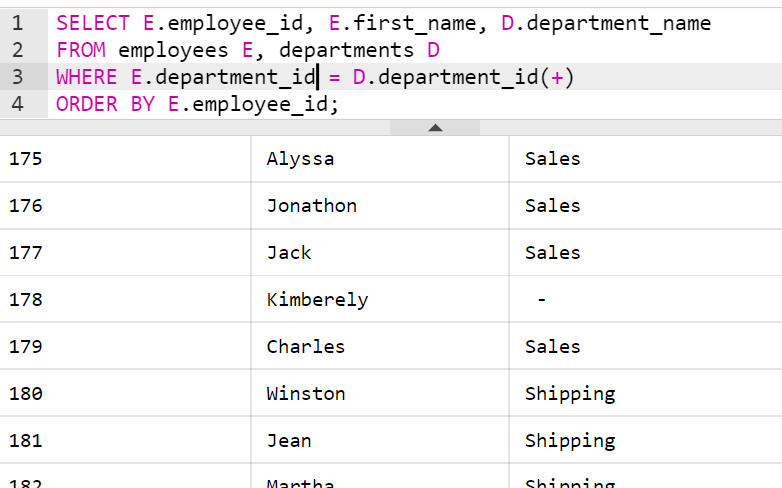
- 직원의 사번, 이름, 부서이름을 조회하되, 직원이 없는 부서가 있다면 해당 부서 정보도 모두 출력하시오.
SELECT E.employee_id, E.first_name, D.department_name
FROM employees E, departments D
WHERE E.department_id(+) = D.department_id
ORDER BY E.employee_id;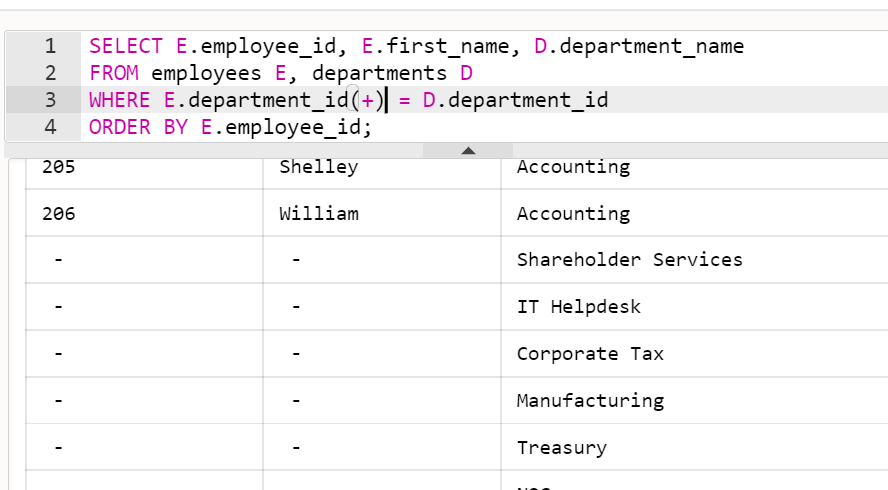
SELF JOIN
-
직원의 사번, 이름, 성, 그리고 관리자 아이디와 관리자 이름을 조회
-
하나의 테이블을 Alias만 다르게 해서 마치 두 개처럼 관리하는 것
-
그렇게 직원, 관리자 테이블로 나누어 FK가 PK를 참조하게 만듬
SELECT E.employee_id, E.last_name, E.first_name, E.manager_id, E1.last_name
FROM employees E, employees E1
WHERE E.manager_id = E1.employee_id
ORDER BY E.employee_id;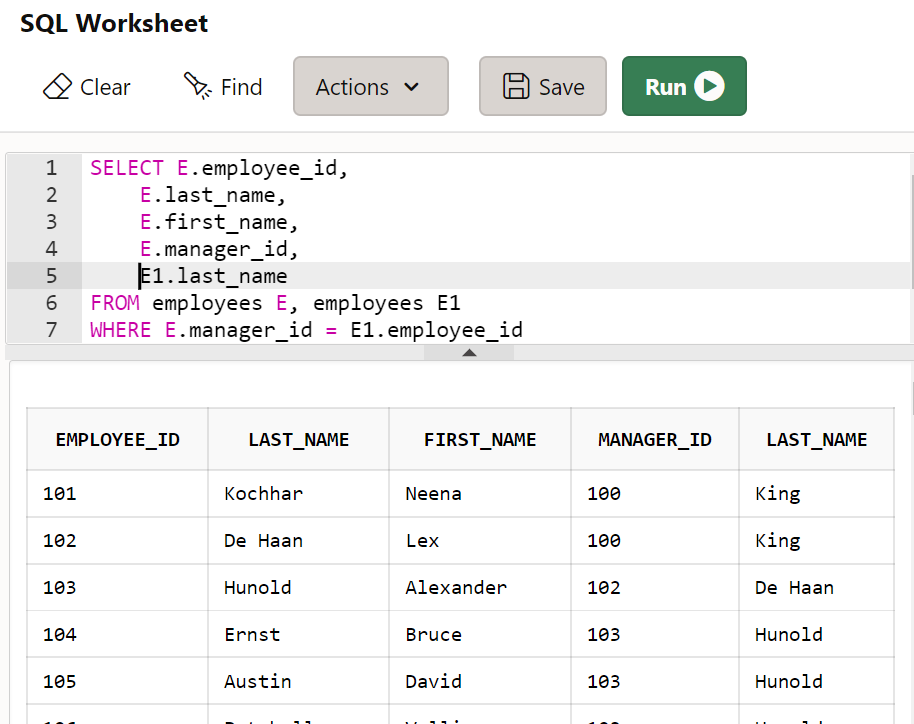
집합 연산자
- UNION : 합집합(중복 데이터를 하나로)
- UNION ALL : 합집합
- INTERSECT : 교집합
- MINUS : 차집합
SELECT department_id
FROM employees
UNION
SELECT department_id
FROM departments;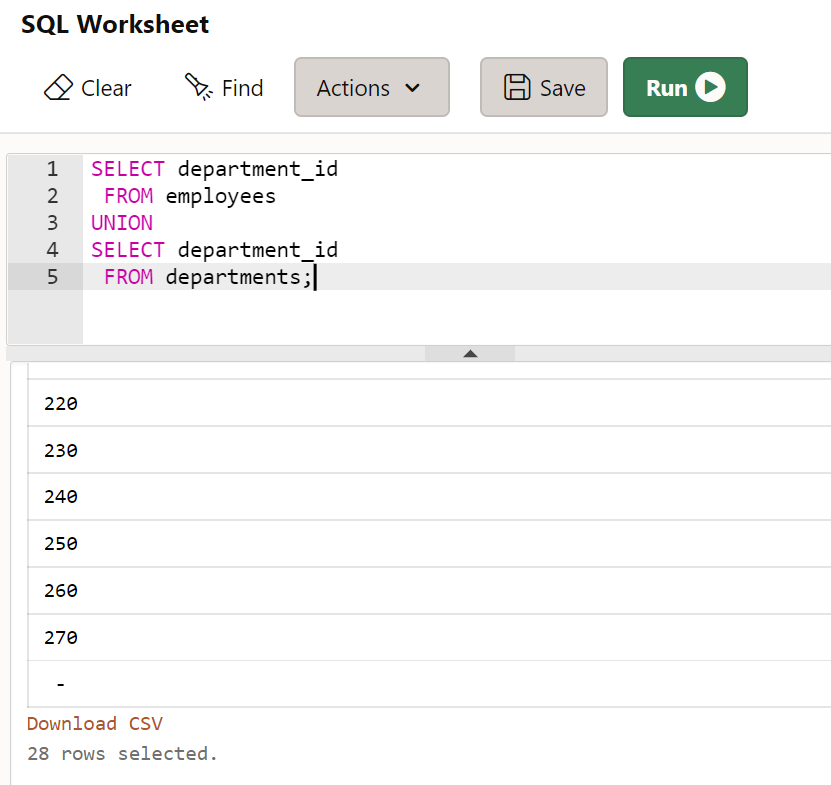
SELECT department_id
FROM employees
UNION ALL
SELECT department_id
FROM departments;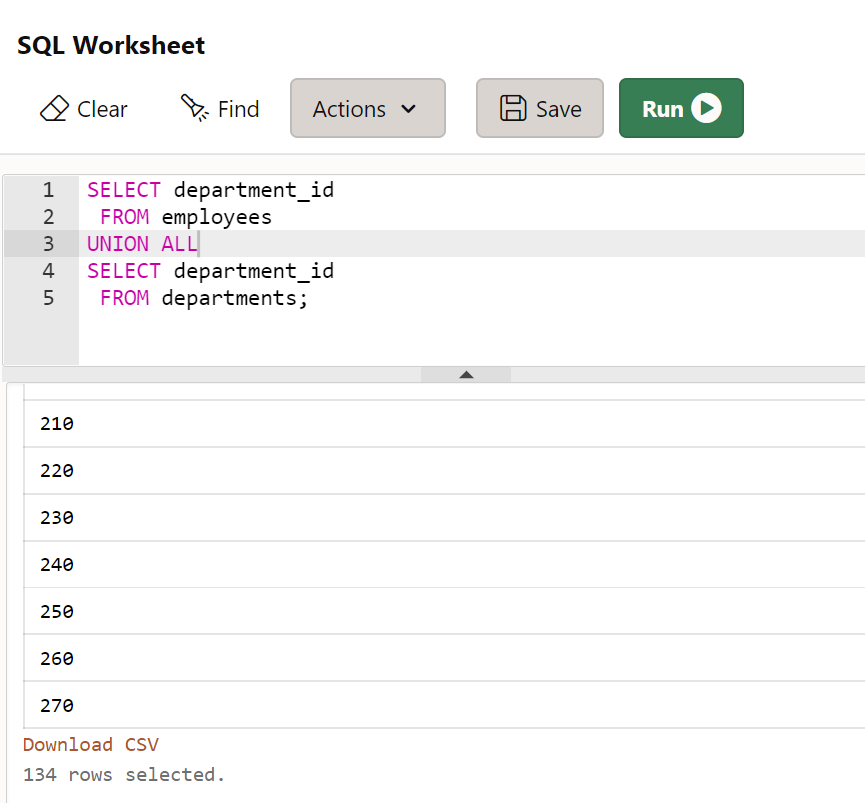
- 검색 결과에서 NULL 제거가 필요하다면?
SELECT department_id
FROM employees
WHERE department_id IS NOT NULL
UNION ALL
SELECT department_id
FROM departments;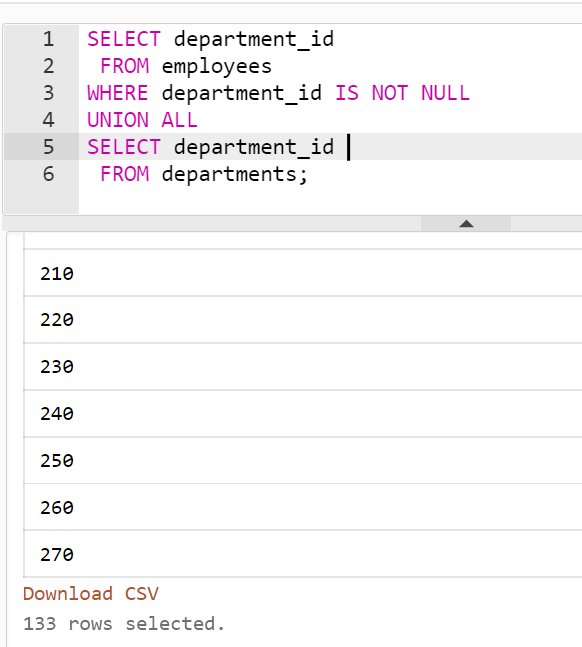
- 직원이 한 명 이상 소속되어 있는 부서의 번호만 출력하시오 (교집합)
-- 참고 : 10에서 110부서까지만 직원이 있다.
SELECT department_id
FROM employees
-- WHERE department_id IS NOT NULL
INTERSECT
SELECT department_id
FROM departments;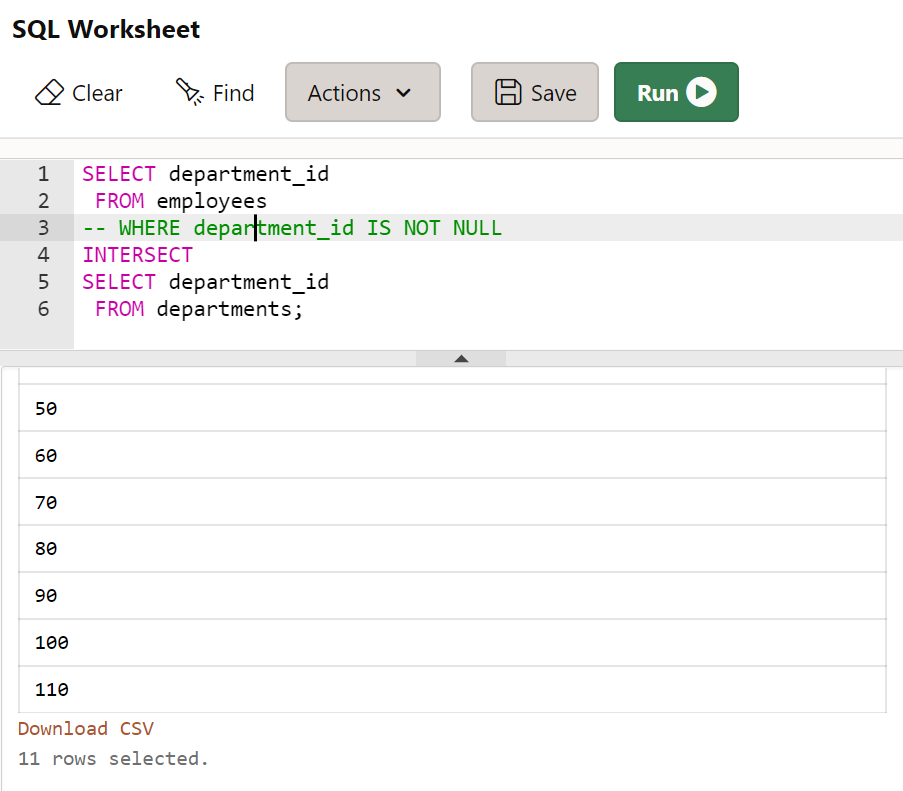
- 직원이 한 명도 없는 부서의 번호만 출력하시오 (차집합)
-- 참고: 120부터부터는 직원이 없다.
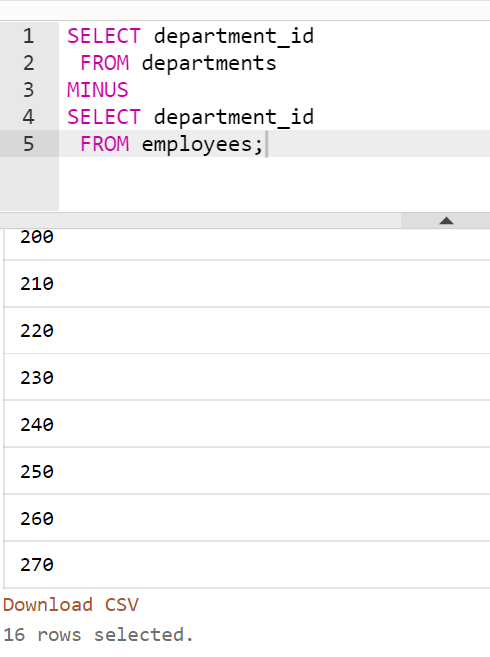
SELECT department_id
FROM departments
MINUS
SELECT department_id
FROM employees;Sub Query
- 이름이 'De Haan'이라는 직원의 급여를 조회
SELECT salary
FROM employees
WHERE last_name = 'De Haan';- 'De Haan'이라는 이름을 가진 직원의 급여와 동일한 급여를 받는 직원의 이름과 급여를 조회하시오.
SELECT last_name, salary
FROM employees
WHERE salary = (
SELECT salary
FROM employees
WHERE last_name = 'De Haan'
);- 연습문제
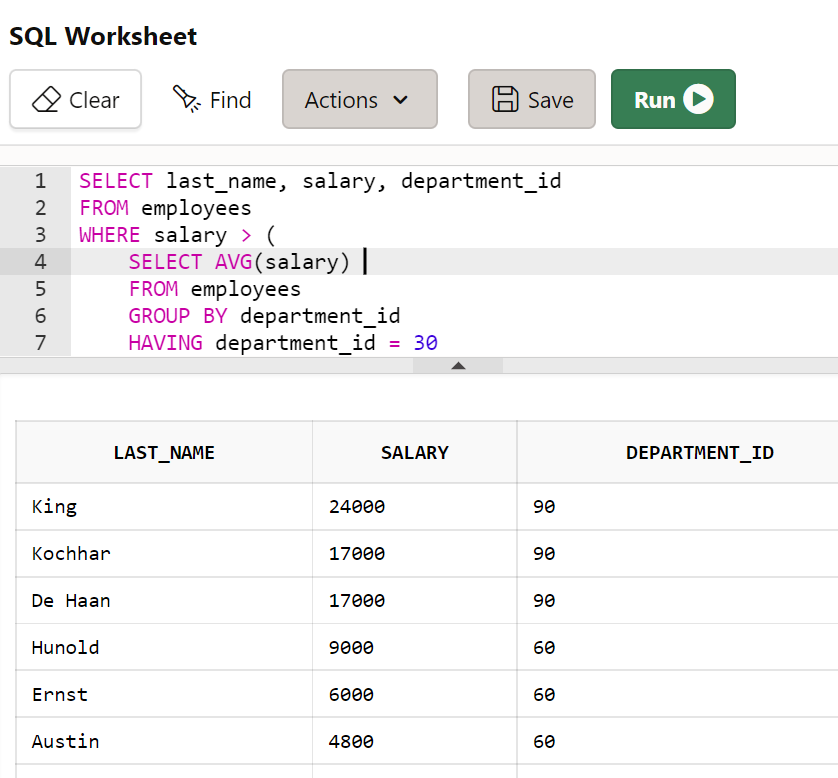
- 30번 부서의 평균 급여보다 급여를 많이 받는 직원의 이름, 급여, 부서번호를 조회하시오.
SELECT last_name, salary, department_id
FROM employees
WHERE salary > (
SELECT AVG(salary)
FROM employees
WHERE department_id = 30
-- GROUP BY department_id
-- HAVING department_id = 30
);
- 'Seattle'이라는 도시에 위치한 부서의 이름과 지역 아이디(location_id)를 조회하시오.
SELECT *
FROM departments
WHERE location_id = (
SELECT location_id
FROM locations
WHERE city = 'Seattle'
)
SELECT *
FROM departments A, locations B
WHERE A.location_id = B.location_id
AND B.city = 'Seattle'-
서브쿼리는 JOIN으로 변경할 수 있다.
-
JOIN을 하게 되면, FK, PK를 기준으로 두 개의 테이블이 붙는다.
- last_name이 'Taylor' 직원과 급여가 같은 직원의 정보를 조회하시오. (동명이인이라 에러)
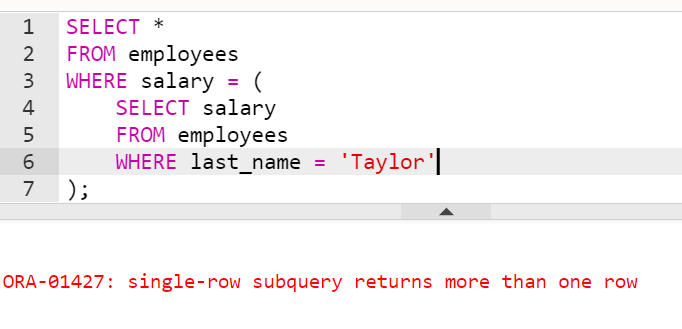
-
위와 같은 오류가 난다.
-
서브쿼리의 실행결과가 하나가 아니다?
=연산자를 쓰게 되면, 서브쿼리의 연산 결과가 유일해야 함
SELECT *
FROM employees
WHERE salary = (
SELECT salary
FROM employees
WHERE last_name = 'Taylor'
);
SELECT *
FROM employees
-- 이 부분을 in 연산자로 바꾸어주면 됨
WHERE salary in (
SELECT salary
FROM employees
WHERE last_name = 'Taylor'
);-
일단은, 서브쿼리를 떼어내서 먼저 실행을 해보자!
-
각 부서의 최소 급여를 구하고, 부서 최소 급여에 해당하는 직원의 사번, 이름, 급여를 조회하시오.
SELECT employee_id, last_name||' '||first_name, salary
FROM employees
WHERE salary in (
SELECT MIN(salary)
FROM employees
WHERE department_id IS NOT NULL
GROUP BY department_id
);
ORDER BY salary DESC;-
위처럼 하게 되면, 몇 번 부서의 최소 급여인지 모르게 됩니다.
- 그래서 다중 행 서브쿼리가 필요하게 됩니다.
-
각 직무 별 최소급여 해당하는 직원 정보 출력
SELECT *
FROM employees A
WHERE (A.job_id, A.salary) in (
SELECT job_id, MIN(salary) 최소급여
FROM employees
GROUP BY job_id
);
ORDER BY A.salary DESC;ex)
-
단일 행 서브쿼리 : 실행 했더니, 값이 하나만 나오더라
-
다중 행 서브쿼리 : 동명이인이 있어, 급여 정보가 두 개가 나오더라
=로 연결하는 것은 불가능하고, 이 때는 in 연산자를 이용해서 처리해주어야 한다.
