-
모두의 SQL 2번째 실습입니다.
-
연습환경은 Oracle Live SQL의 Code Library의 HR Object and Data For Live SQL을 이용하였습니다! 참고!
DML
- DDL : 테이블을 만드는 것
- TCL : 트랜잭션 제어 명령어
- DCL : 권한을 주는 것 = GRANT, REVOKE
INSERT 작업
- 271번 부서 정보를 입력한다.
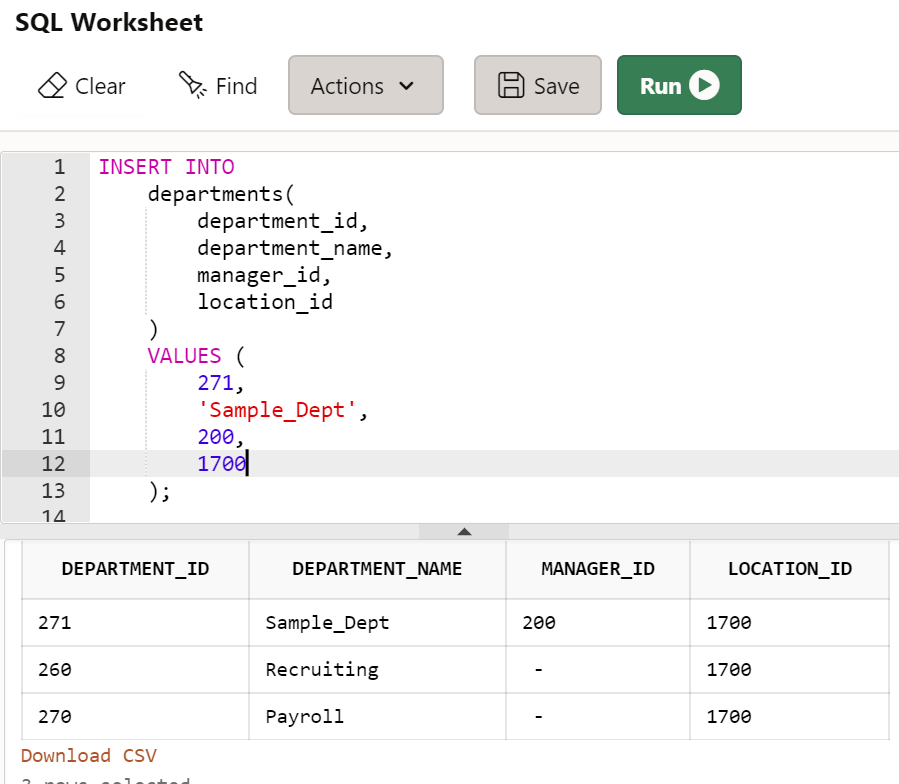
INSERT INTO
departments(
department_id,
department_name,
manager_id,
location_id
)
VALUES (
271,
'Sample_Dept',
200,
1700
)
-- 확인!
SELECT *
FROM departments
WHERE department_id > 250;-
모든 컬럼에 값을 입력하는 경우, 컬럼 목록은 생략 가능하다.
-
또 한번, 같은 INSERT 문을 실행하는 경우에 PRIMARY가 중복을 허용하지 않을 때 에러가 발생합니다.
- PK : UNIQUE + NOT NULL이기 때문
-
데이터 타입이 일치하지 않아도 에러가 납니다!
연습문제
-
서브쿼리를 이용해서 풀어보자
-
departments 테이블에 새로운 부서 정보를 저장하시오.
- 부서이름은 'Test_Dept'이고, 관리자 아이디는 101, 부서 위치아이디는 1800이다.
- 이때, 부서 아이디는 현재 입력된 부서의 최대 번호에 1을 더해서 자동으로 입력되도록 한다.
- INSERT할 때 서브쿼리를 이용할 수 있어요
INSERT INTO
departments (
department_id,
department_name,
manager_id,
location_id
)
VALUES (
(SELECT
-- 서브쿼리를 이용해서 +1의 값을 구할 수 있겠지
MAX(department_id) + 1
FROM departments
),
'Test_Dept', 101, 1800
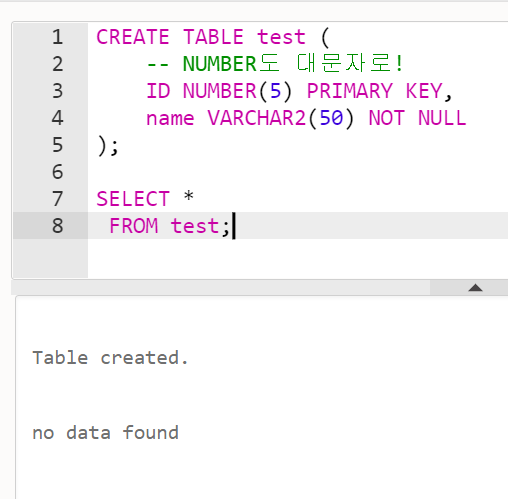
);- 테이블 만들고, 테스트해보자
CREATE TABLE test (
-- NUMBER도 대문자로!
ID NUMBER(5) PRIMARY KEY,
name VARCHAR2(50) NOT NULL
);
-- 이 이후에 INSERT 하려고 하면 에러가 납니다.
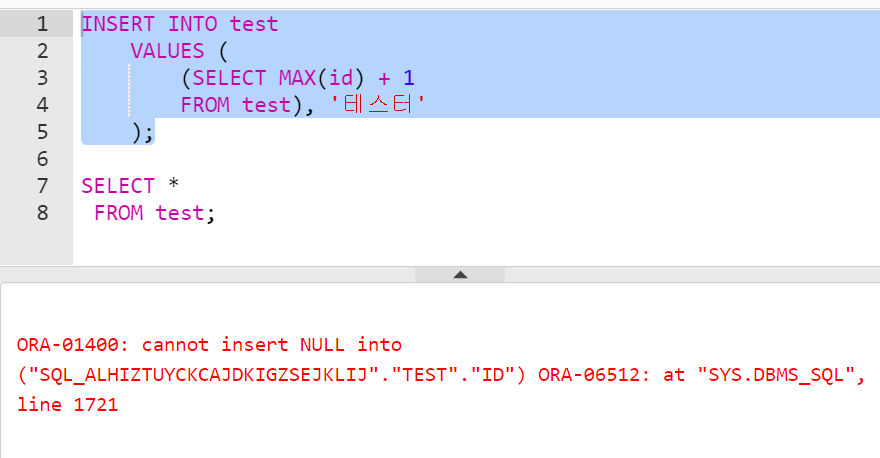
INSERT INTO test
VALUES (
(SELECT MAX(id) + 1
FROM test), '테스터'
);
-
똑같은 쿼리인데, 왜 실행이 안 되었을까?
- 서브쿼리만 테스트해보자
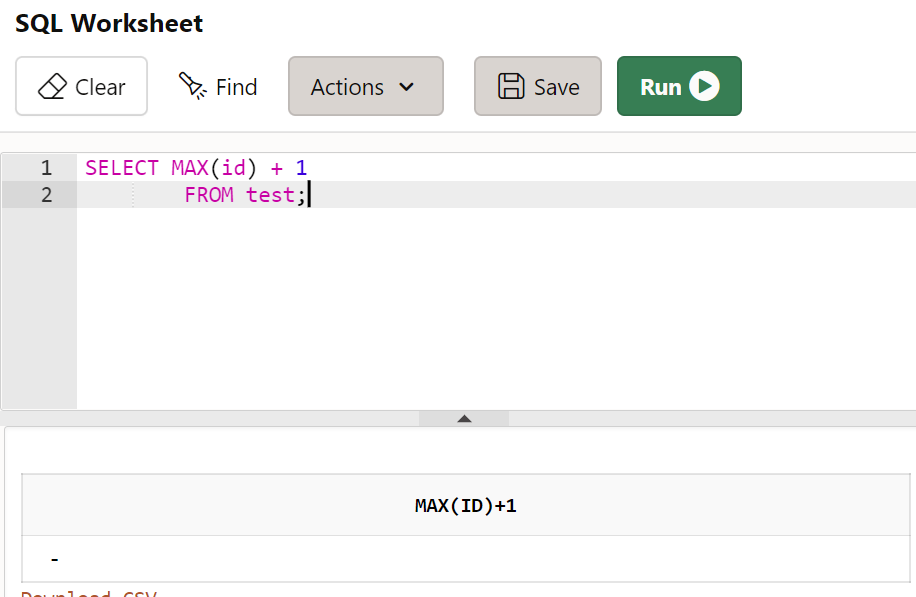
- NULL이 나오면, 연산 시 오류가 발생하기 때문에, 어제배운 것을 활용해보면 ==> NVL을 활용하자
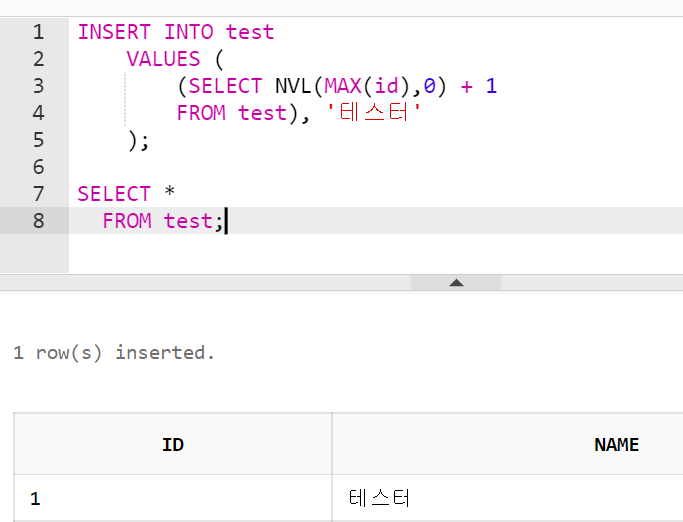
INSERT INTO test
VALUES (
(SELECT NVL(MAX(id),0) + 1
FROM test), '테스터'
);
UPDATE
- 부서 아이디가 273번인 부서의 관리자 아이디를 100으로, 부서 이름은 연구개발부로 수정하시오.
UPDATE departments
SET manager_id = 100,
department_name = '연구개발부'
WHERE department_id = 273;
SELECT *
FROM departments
WHERE department_id = 273;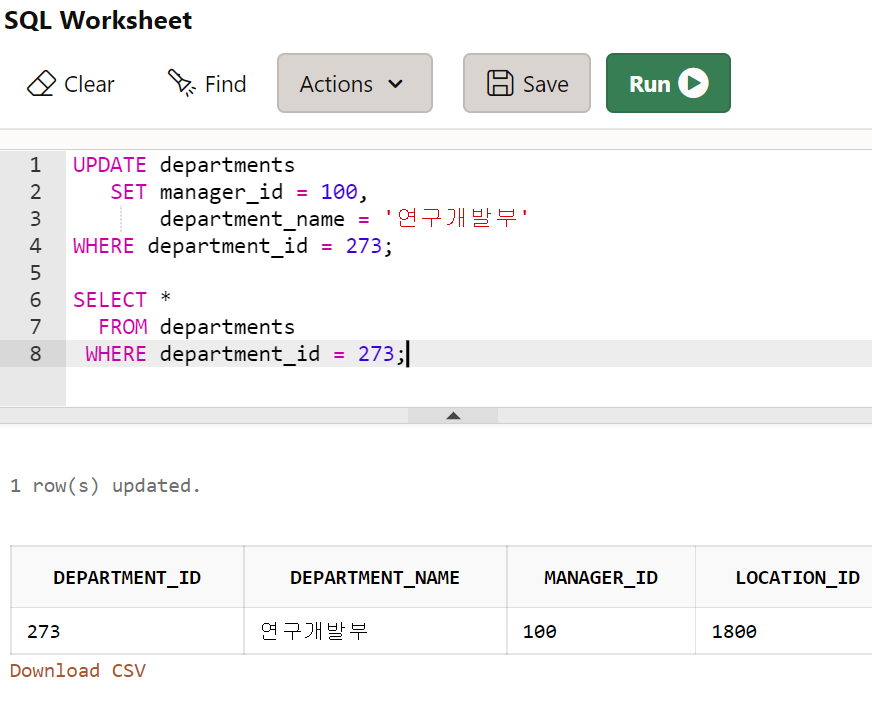
-
WHERE를 안 써도 되지만, PRIMARY KEY가 정말 중요함
-
UNIQUE한 값들을 통해서 각각의 ROW을 구별할 수 있음
- 그래서 위처럼, 273 ROW만 변경할 수 있던 것
-
-
수정, 삭제에 대해서 특정 ROW만 가능하게 하는 것
- 이때 거의 99%는 PK를 이용해 특정 DATA만 수정, 삭제할 수 있음
-
SET 마지막에
,을 찍어서 문법 오류를 발생시키는 경우를 주의! -
departments 테이블에서 부서이름이 'Sample_Dept'인 부서의 관리자 아이디와 지역 아이디를 수정하시오.
UPDATE departments
SET manager_id = 201,
location_id = 1800
WHERE department_name = 'Sample_Dept';
SELECT *
FROM departments
WHERE department_name = 'Sample_Dept';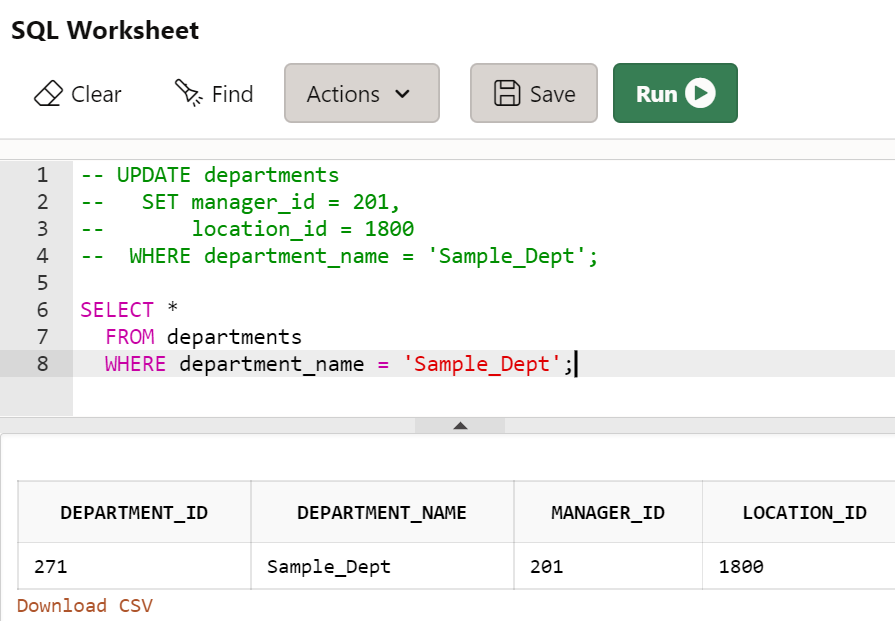
-
UPDATE에서도 서브쿼리를 이용해 데이터 수정이 가능!
-
부서이름이 'Sample_Dept'인 부서의 관리자 아이디와 부서 위치 아이디를 273번 부서의 관리자 아이디와 부서 위치아이디로 수정하시오
-
서브쿼리를 통해 내가 모르는 데이터를 얻어내고, 그 검색결과를 이용해서 수정하던지, 추가작업을 이루게 하는 것
UPDATE departments
SET (manager_id,location_id) = (
SELECT manager_id, location_id
FROM departments
WHERE department_id = 273
)
WHERE department_name = 'Sample_Dept';
SELECT *
FROM departments
WHERE department_id > 270;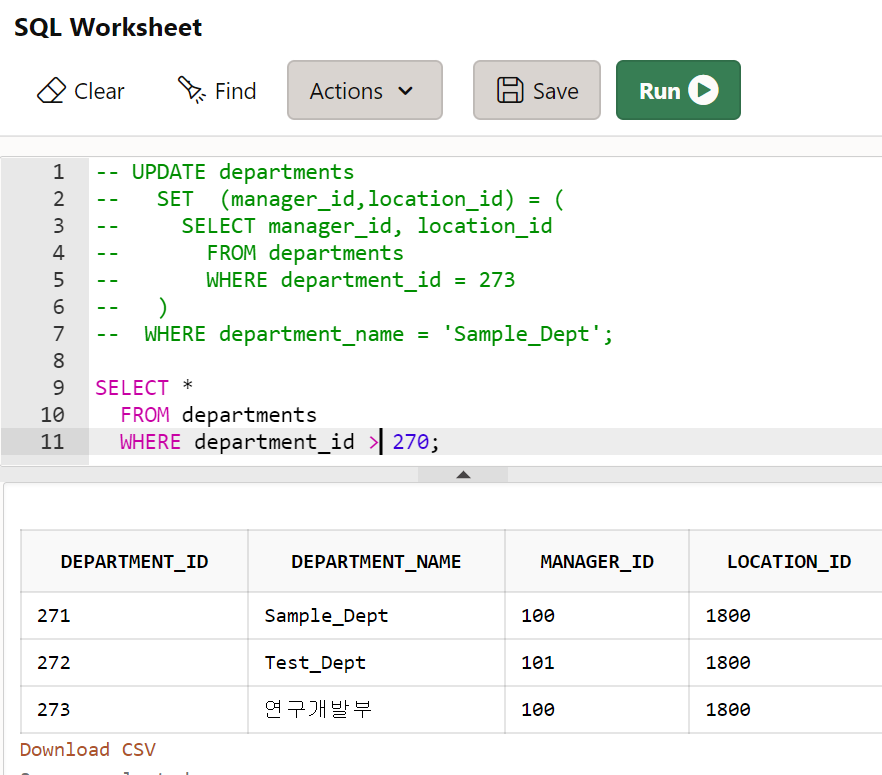
- 부서 이름이 'Sample_Dept'인 부서의 부서 아이디를 NULL로 수정하시오. -- PK는 NOT NULL을 포함하고 있다.
UPDATE departments
SET department_id = null
WHERE department_name = 'Sample_Dept';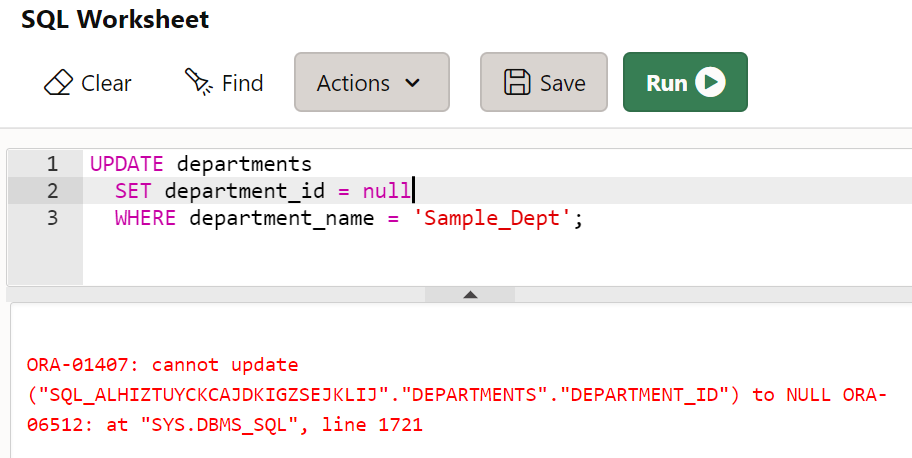
DELETE
- 부서 이름이 'Sample_Dept'인 부서의 정보를 삭제하시오.
SELECT * FROM departments
WHERE department_name = 'Sample_Dept';
DELETE
FROM departments
WHERE department_name = 'Sample_Dept';
SELECT * FROM departments
WHERE department_name = 'Sample_Dept';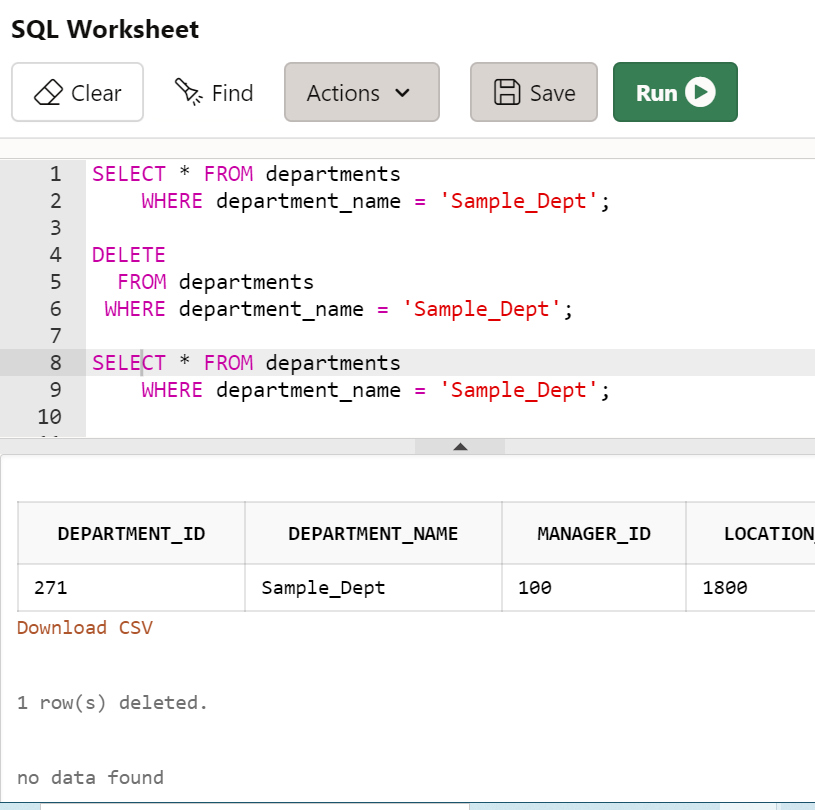
-
주의! FK는 NULL을 허용하기 때문에
- PK에 없는 값을 FK가 가질 수 없음
- INSERT, UPDATE, DELETE할 때 항상 고려되어야 합니다.
-
FK 기준 삭제는 아무 문제가 없지만, PK가 있는 ROW을 삭제할 때는 문제가 됩니다.
-
참조하고 있기 때문에 삭제하는 것이 불가능하다.
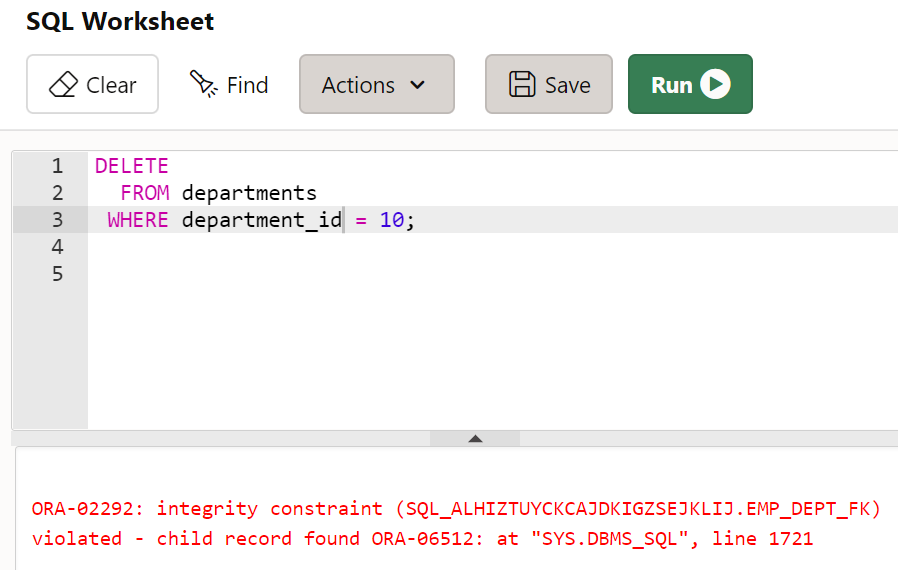
-
주의! employees 테이블에서 참조되고 있는 부서 데이터는 삭제할 수 없다.
-
UPDATE, INSERT, DELETE 모두 Sub-Query를 이용할 수 있다!
데이터 무결성과 트랜잭션
제약조건

-
제약조건을 기술할 때는 CONSTRAINT 키워드를 특정 컬럼에 추가
- CONSTRAINT '이름'(내가 기억하기 쉬운 이름으로 등록하는 게 좋아)

- FK 설정이 약간 복잡합니다

- REFERENCES 뒤에 있는 테이블의 FOREIGN KEY 뒤에 있는 FK가 있는지 검사합니다.
연습문제
-
PK 제약조건 위배
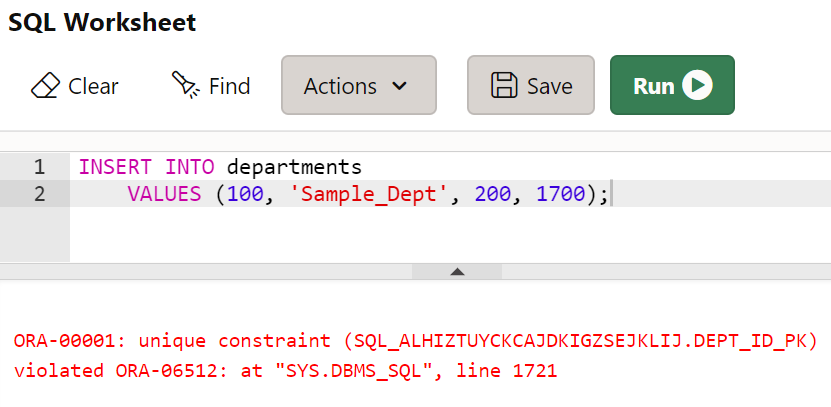
-
100번 부서를 등록한다. 기본 키 제약 조건 위배
- PK = UNIQUE + NOT NULL
-- PK 조건 위배 INSERT INTO departments VALUES (100, 'Sample_Dept', 200, 1700);
- PK = UNIQUE + NOT NULL
-
FK 제약 조건 위배
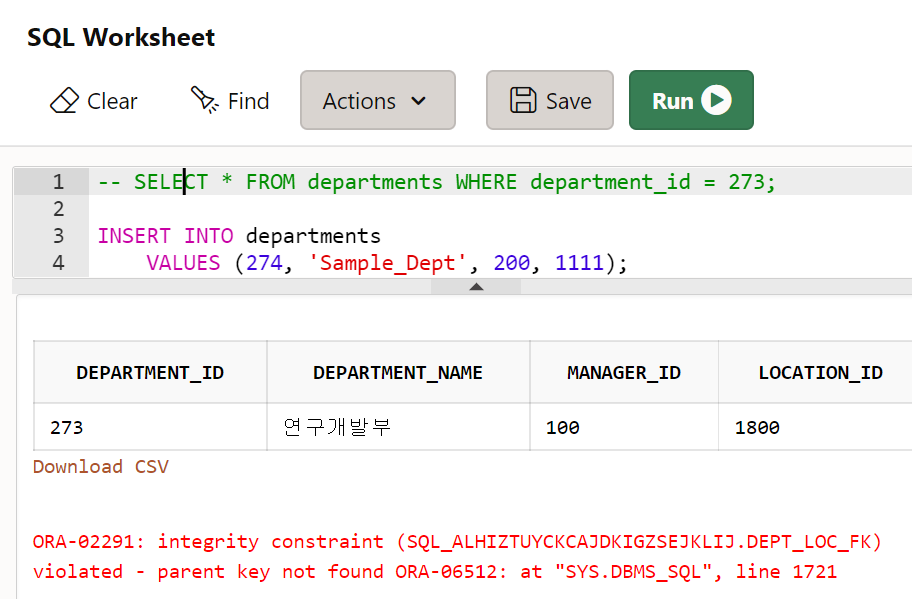
-
1111이 없으니까 에러가 남
-- FK 조건 위배
INSERT INTO departments
VALUES (273, 'Sample_Dept', 200, 1111);- UNIQUE 제약 조건 위배
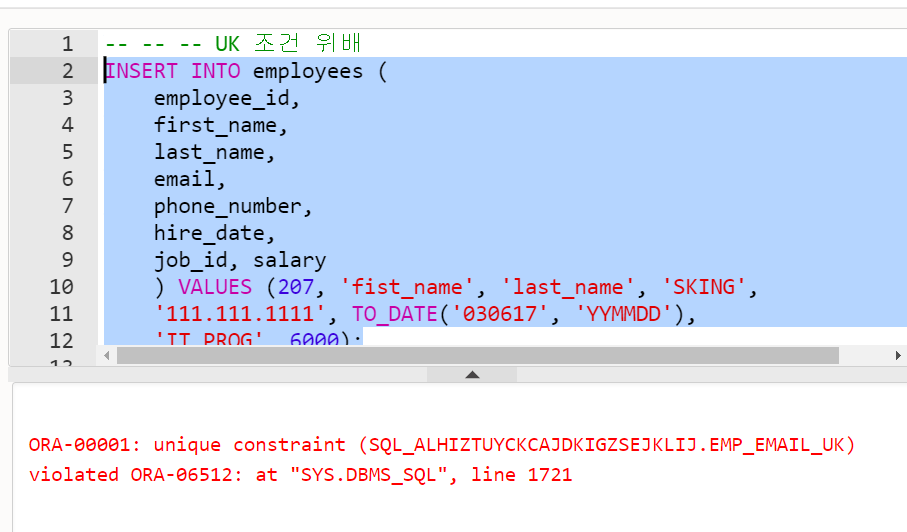
-- UK 조건 위배
INSERT INTO employees (
employee_id,
first_name,
last_name,
email,
phone_number,
hire_date,
job_id, salary
) VALUES (207, 'fist_name', 'last_name', 'SKING',
'111.111.1111', TO_DATE('030617', 'YYMMDD'),
'IT_PROG', 6000);- NOT NULL 제약 조건 위배
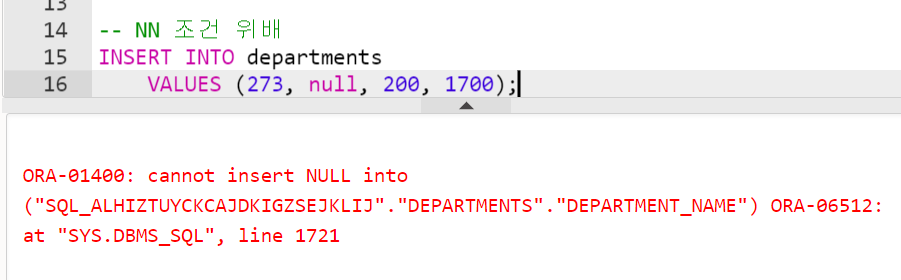
-- NN 조건 위배
INSERT INTO departments
VALUES (273, null, 200, 1700);- CHECK 제약 조건 위배
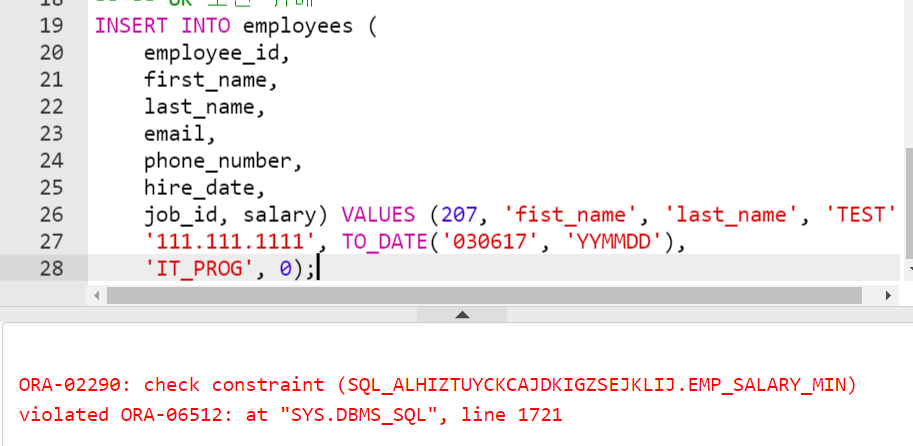
-- CHECK 조건 위배
INSERT INTO employees (
employee_id,
first_name,
last_name,
email,
phone_number,
hire_date,
job_id, salary) VALUES (207, 'fist_name', 'last_name', 'TEST',
'111.111.1111', TO_DATE('030617', 'YYMMDD'),
'IT_PROG', 0);트랜잭션
-
이 부분은 h2 Database를 통해서 실습합니다.
- 자동 커밋 해제 -
`SHIFT + ENTER' : RUN Selected
-
CTRL + ENTER: 전체 실행 -
COMMIT이 되면, INSERT가 영구적으로 반영되는 것 (불가역적인)
- 어떤 작업을 했는데, 결과가 이상하다 ==> ROLLBACK;
- 문제없다면 ==> COMMIT ㄱㄱ
-
왜 중요한가?
- ex) 계좌이체
-
내 통장에서 인출한다(UPDATE)
-
친구 통장에 입금한다.(UPDATE)
-
트랜잭션 : 논리적으로 분리할 수 없는 하나 이상의 DML 작업(단, SELECT는 제외)
- ROLLBACK을 통해서 원래 상태를 유지할 수 있게끔 하자
-
과정!
SELECT * FROM test

INSERT INTO TEST VALUES(2, '임호정')

SELECT * FROM test

ROLLBACK

DDL(Data Definition Language)
CREATE
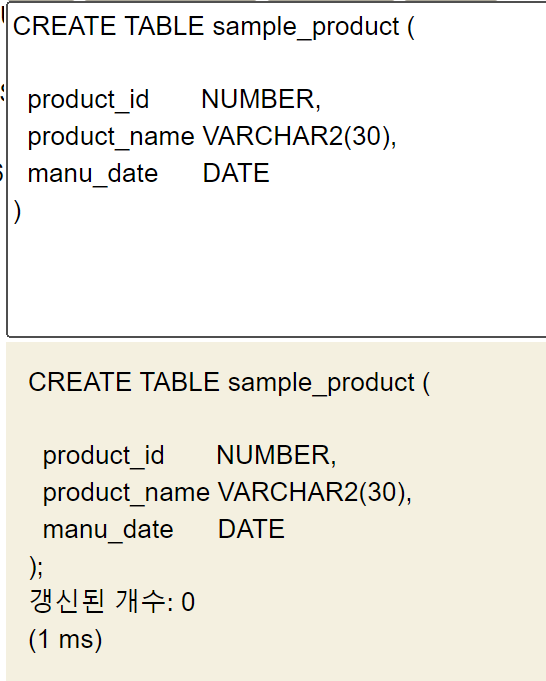
CREATE TABLE sample_product (
product_id NUMBER,
product_name VARCHAR2(30),
manu_date DATE
);
-
참고! DESC는 Oracle에서만 쓸 수 있음
- TO_DATE도 h2 database에서 쓸 수 없음
-
INSERT
INSERT INTO sample_product
VALUES(1, 'television',
CURRENT_DATE)
INSERT INTO sample_product
VALUES(2, 'washer',
CURRENT_DATE)
INSERT INTO sample_product
VALUES(3, 'cleaner',
CURRENT_DATE)
ALTER
- Oracle하고 다른 부분들이 있음
https://www.h2database.com/html/commands.html
ALTER - ADD
ALTER TABLE sample_product
ADD (factory VARCHAR2(10));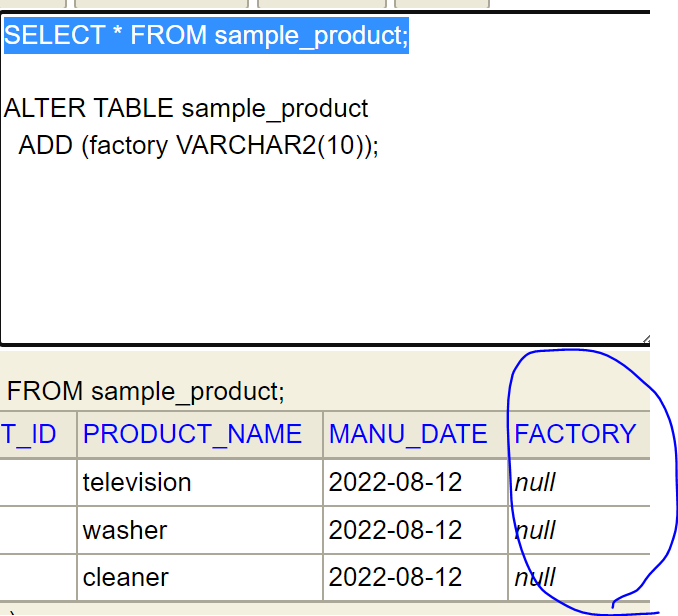
ALTER - MODIFY
ALTER TABLE sample_product
MODIFY (factory VARCHAR2(10));ALTER - RENAME COLUMN
ALTER TABLE sample_product
RENAME COLUMN factory TO factory_name;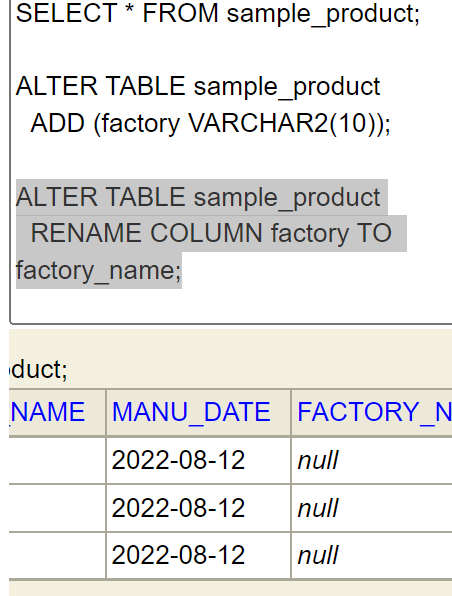
ALTER - DROP COLUMN
ALTER TABLE sample_product
DROP COLUMN factory_name;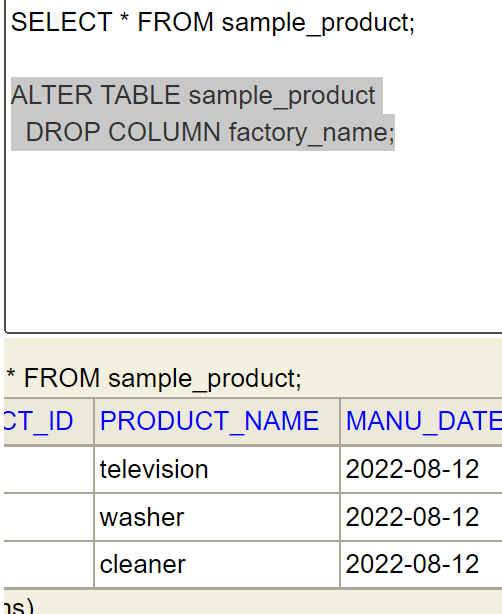
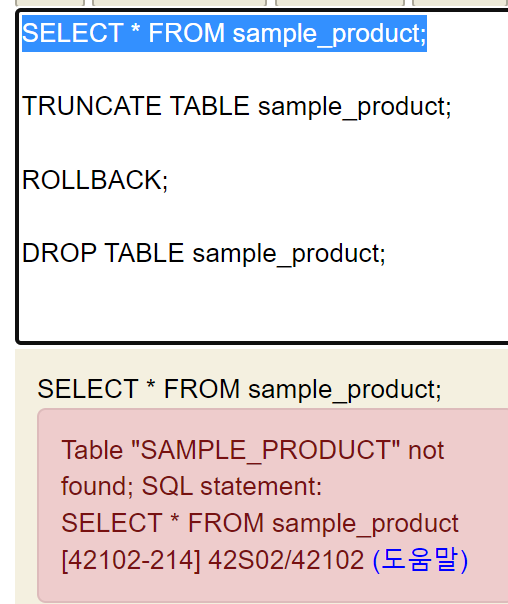
TRUNCATE = DELETE(ALL ROW) + COMMIT;
- 특정 테이블의 모든 데이터를 삭제하고, 커밋까지 해버림
- 테이블은 그대로 유지하면서, 테이블 안에 들어있는 모든 데이터를 제거할 때 사용합니다

- ROLLBACK해도 살아나지 않아요
DROP : 테이블 삭제
- TABLE 삭제
View, Optimizer, Index
View
-
CREATE [OR REPLACE] VIEW AS (SELECT ~~) -
OR REPLACE는 VIEW가 이미 있다면, 그 VIEW를 대체하겠다.
-
가만히 보니까, 두 개의 테이블을 자주 조인하게 되고, 주로 검색하는 COLUMN을 보니까 나머지 컬럼은 잘 조회하지도 않아
- 이러한 COLUMN으로 구성된 가상의 테이블을 만들어놓고 SELECT 하면 속도가 매우 빨라짐
-
JOIN을 많이 하면 할 수록 성능은 떨어짐
- JOIN을 최소화시키려면, VIEW를 활용하자
-
Oracle에는 이미 존재합니다.