
1. Outline
1.1 인터넷의 개요
1.1.1 네트워크
네트워크는 상호 연결이 가능한 통신 장비의 집합체이다. 여기서 장비는 호스트(종단 시스템, end system)가 될 수 있다. 또한 장비는 다른 네트워크에 네트워크를 연결하는 라우팅, 장비를 연결하는 스위치, 데이터의 형식을 변경하는 모뎀(변조기-복조기)와 같은 연결 장비가 될 수 있다.
근거리 통신망
근거리 통신망(LAN)은 일반적으로 사무실, 빌딩, 또는 학교에서 일부의 호스트를 사적으로 연결하여 사용되며, LAN에 있는 각각의 호스트는 LAN에서 호스트를 정의하는 고유한 식별자를 가진다.
과거에는 한 네트워크 안의 모든 호스트들이 한 공용 케이블을 통해 연결되어 있었다. 따라서 한 호스트에서 다른 호스트로 전송되는 패킷이 모든 호스트들에게 수신되었다. 의도된 수신 호스트는 패킷을 유지하고, 다른 호스트들은 패킷을 드롭한다. 오늘날 대부분의 LAN들은 패킷의 목적지 주소를 인식하여 다른 모든 호스트로 전송하지 않고 해당 목적지로 패킷을 전송하는 스위칭 기법을 사용한다. 이러한 스위칭 기법은 LAN에 트래픽을 완화하고 같은 시간에 다수의 패킷이 서로 통신을 할 수 있게 한다.
LAN은 다른 네트워크와 연결되지 않고 홀로 고립되어 사용되었을 때, 서로 간의 자원을 호스트 간에서 공유할 수 있도록 설계되었다. 오늘날의 LAN은 서로 다른 네트워크와 연결되고, WAN과 연결된다.
광역 네트워크
광역 네트워크(WAN)도 상호 간의 통신이 가능한 시스템이다. 그러나, LAN과 WAN 사이에는 몇 가지 차이점이 있다. LAN은 제한된 크기의 건물 또는 학교에, WAN은 넓은 도시, 국가에 사용된다. LAN은 호스트들을 상호 연결하고, WAN은 스위치, 라우터 또는 모뎀과 같은 연결 장치를 상호 연결한다. LAN은 개인이 사적으로 활용하는 경우 사용하지만, WAN은 통신회사가 만들고 임대한다. WAN에는 점-대-점 WAN과 교환형 WAN이 있다.
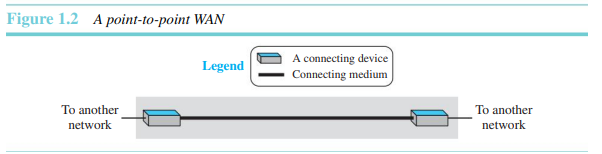
- 점-대-점 WAN
전송 매체(케이블 또는 공기)를 통해 두 통신장치를 연결하는 네트워크다.
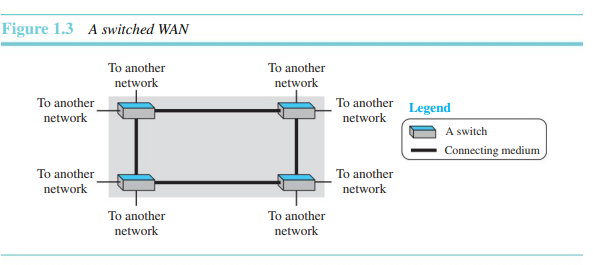
- 교환형 WAN
두 개보다 더 많은 끝점을 가진 네트워크이다. 교환형 WAN은 통신 백본망에 사용된다. 교환형 WAN은 스위치에 의해 연결된 여러 개의 점-대-점 WAN의 조합이라고 할 수 있다.
인터넷
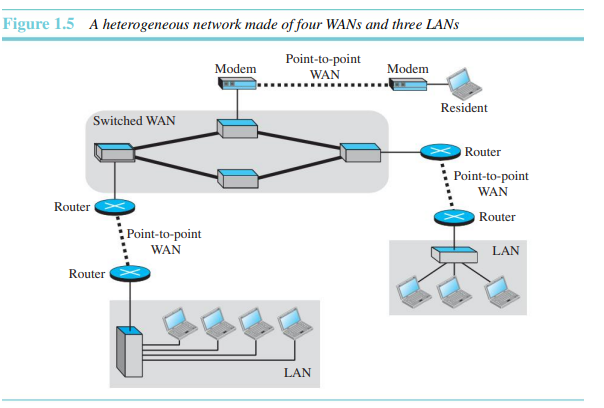
오늘날 LAN이나 WAN은 서로 연결되어 있다. 두 개 이상의 네트워크가 연결될 경우, 인터넷을 구성한다. 그림 1.5는 여러 LAN과 WAN 연결된 하니의 인터넷을 보여준다. 하나의 WAN은 네 개의 스위치로 구성된 교환형 WAN이다.
1.1.2 교환
인터넷은 스위치가 둘 이상의 링크를 연결하는 교환식 네트워크이다. 스위치는 필요할 때 한쪽 링크에서 다른쪽 링크로 데이터를 포워딩해야 한다. 교환식 네트워크에는 회선 교환 네트워크와 패킷 교환 네트워크가 있다.
회선 교환 네트워크
두 종단 시스템 사이에 회선이라 불리는 전용선이 항상 이용된다. 스위치는 단지 이 회선을 활성화 또는 비활성화할 수 있다. 그림 1.6은 각 종단에 4개의 전화가 연결되어 있는 단순한 교환식 네트워크의 모습을 보여준다.
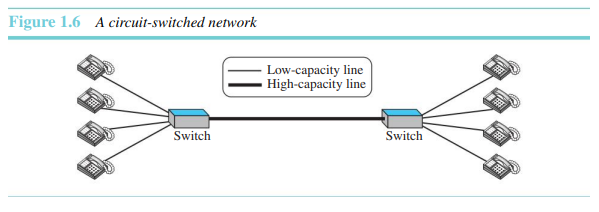
위 그림에서 각 종단에 있는 4개의 전화들은 스위치에 연결되어 있다. 스위치는 한쪽 단의 전화기를 다른 쪽 종단의 전화기와 연결시켜 준다. 두 스위치를 연결하는 굵은 선은 동시에 4개의 음성 통신을 다룰 수 있는 대용량의 통신선이다. 이 용량은 모든 전화기 쌍들에 의해 공유된다. 이 예에서 쓰인 스위치들은 포워딩만 할 뿐 저장능력은 없다.
이제 두 가지 경우에 대해 살펴보면, 하나는 모든 전화기가 사용되고 있는 경우이다. 한쪽 단의 4명의 사용자가 다른 쪽 단의 4명의 사용자와 전화 통화를 한다. 굵은 선의 용량이 모두 이용된다. 두 번째 경우는 한쪽 단의 오직 하나의 전화기가 다른 쪽 단의 한 전화기와 연결되어 있는 경우이다. 굵은 선의 용량 중 1/4만 이용된다. 이것이 의미하는 것은 회선 교환 네트워크는 용량이 모두 이용될 때만 효율적이라는 것이다.
패킷 교환 네트워크
컴퓨터 네트워크에서 두 종단 사이의 통신은 패킷이라는 데이터 블록에 의해 이루어진다. 이것은 스위치가 포워딩과 저장을 할 수 있게 해주는데, 이는 패킷이 저장된 후 나중에 포워딩될 수 있는 독립체이기 때문이다. 그림 1.7은 한쪽 단의 4대의 컴퓨터를 다른 쪽 단의 4대의 컴퓨터와 연결시켜 주는 작은 패킷 교환 네트워크이다.
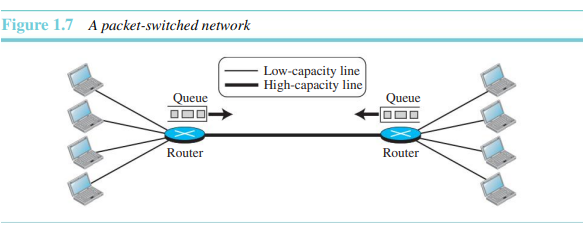
패킷 교환 네트워크에서 라우터는 패킷을 저장하고 포워딩하기 위한 큐를 갖는다. 이제 굵은 선의 용량이 컴퓨터와 라우터 사이의 데이터 선 용량보다 두 배 많다고 가정해보자. 오직 두 컴퓨터만이 서로 통신해야 한다면, 패킷은 기다려야 할 필요가 없다. 하지만 만약 굵은 선의 용량이 모두 사용되고 있을 때 라우터에 패킷이 도착한다면, 이 패킷들은 저장된 후 도착한 순서대로 포워딩되어야 한다. 이는 패킷이 지연될 수 있음을 보여준다.
1.1.3 인터넷
인터넷(internet, 소문자 i로 시작)은 서로 통신할 수 있는 둘 또는 그보다 많은 네트워크들의 집합이다. 그 중 가장 대표적인 것이 인터넷(Internet, 대문자 I로 시작)으로, 수천 개의 상호 연결되어 있는 네트워크들로 이루어져 있다. 그림 1.8은 인터넷의 개념적 모습을 보여준다.
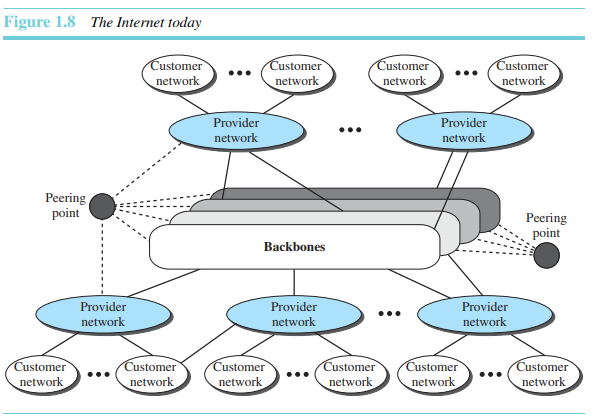
그림은 여러 개의 백본, 제공자 네트워크, 그리고 사용자 네트워크들로 이루어진 인터넷의 모습을 보여준다. 최상위 레벨에서 백본은 통신회사들이 소유하고 있는 거대한 네트워크이다. 백본 네트워크들은 대등점(peering point)이라고 불리는 복잡한 교환 시스템들에 의해 연결된다. 두 번째 레벨에서는 제공자 네트워크라는 보다 작은 네트워크들이 있는데, 이 네트워크들은 요금을 지불하여 백본의 서비스를 이용한다. 제공자 네트워크는 백본에 연결되며, 때때로 다른 제공자 네트워크와도 연결된다. 사용자 네트워크는 인터넷의 말단에 위치하며, 실질적으로 인터넷에서 사용되는 서비스를 이용한다. 서비스를 이용하기 위해서 제공자 네트워크에게 요금을 지불한다. 백본과 제공자 네트워크는 인터넷 제공자(ISP)라고도 불린다.
1.1.4 인터넷 접속
오늘날의 인터넷은 사용자들이 그 일부가 되게 하지만, 사용자들은 물리적으로 ISP에게 연결되어야 한다. 이런 물리적 연결은 보통 점-대-점 WAN에 의해 이루어진다.
전화 네트워크의 이용
오늘날 대부분은 전화 네트워크와 연결되어 전화 서비스를 이용한다. 대부분의 전화 네트워크들이 인터넷에 연결되어 있기 때문에, 가정이나 직장에서 인터넷에 연결하기 위한 한 가지 방법은 직장과 전화국 사이의 음성 선을 점-대-점 WAN으로 바꾸는 것이다. 이것은 두 가지 방법으로 이루어진다.
- 다이얼업 서비스
전화선에 데이터을 음성으로 바꾸어 줄 수 있는 모뎀을 다는 것이다. 컴퓨터에 설치된 SW가 ISP를 호출하고, 전화 연결을 하는 것처럼 동작한다. 그러나 이는 매우 느리고, 인터넷에 연결되어있는 동안 전화(음성) 연결을 할 수 없다. - DSL 서비스
DLS 서비스는 전화선들이 동시에 음성 통신과 데이터 통신이 가능하도록 한다.
케이블 네트워크의 이용
무선 네트워크의 이용
무선 WAN을 통해 인터넷에 연결할 수 있다.
인터넷에 직접 연결
큰 조직이나 회사들은 그 자체가 하나의 지역 ISP가 되어 인터넷에 연결될 수 있다. 이것은 조직이나 회사가 서비스를 제공 업자로부터 고속 WAN을 임대하여 스스로를 백본에 연결할 때 이루어진다.
1.2 프로토콜 계층화
프로토콜은 효율적인 통신을 위해 송신자와 수신자, 그리고 그 사이의 모든 중계기들이 따라야 할 규칙이다. 통신이 복잡할 때에는 서로 다른 계층 사이에 작업을 나누어야 할 수도 있는데, 이 경우에는 프로토콜 계층화가 필요하다.
1.2.1 프로토콜 계층화의 원칙
첫 번째는 우리가 양방향통신을 하기를 원한다면, 각 계층이 각 방향으로 한 가지씩, 상반되는 두 가지 작업을 수행할 수 있도록 만들어야 한다는 것이다.
두 번째는 양 사이트의 각 계층 아래에 있는 두 객체는 서로 동일해야 한다는 것이다.
1.2.2 TCP/IP 프로토콜 그룹
TCP/IP는 현재의 인터넷에서 사용하는 프로토콜 그룹(여러 계층들에서 조직된 프로토콜 세트)이다. 그것은 상호 작용하는 모듈들로 이루어진 계층적 프로토콜인데, 각 모듈은 특정한 기능을 제공한다. 계층적이라는 말은 각 상위 계층 프로토콜들이 한 개 이상의 하위 계층 프로토콜로부터 제공되는 서비스의 지원을 받는다는 것이다. 원래 TCP/IP 프로토콜 그룹은 하드웨어에 설치된 네 개의 SW 계층으로 정의되었으나, 현재는 5계층 모델로 간주된다.
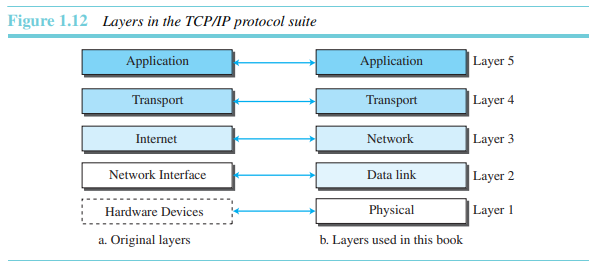
TCP/IP 프로토콜 그룹의 계층
그림 1.14는 단순한 인터넷에서의 논리적 연결의 모습을 보여준다.
논리적 연결이란 네트워크 통신에서 데이터가 전송되는 두 장치(호스트) 사이에 설정되는 연결을 의미합니다. 이 연결은 물리적인 연결이 아니라, 소프트웨어(프로토콜)를 통해 관리되는 가상의 연결입니다. 이런 종류의 연결은 데이터의 전송 순서, 손실, 에러 검출 및 수정, 흐름 제어 등을 관리하며, 두 호스트 간의 신뢰성 있는 통신을 보장합니다.
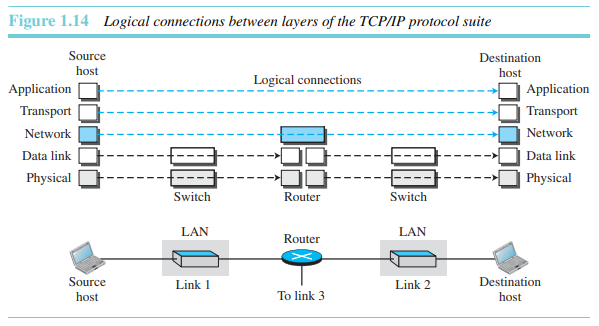
논리적 연결을 사용하는 것은 각 계층의 역할에 대해 생각하는 것을 쉽게 해준다. 그림이 보여주듯이, 응용, 전송, 네트워크 계층의 의무는 종단-대-종단이다. 하지만, 데이터링크 계층과 물리 계층의 의무는 홉-대-홉이며, 여기서 홉은 호스트 또는 라우터를 말한다. 다시 말해 최상위 세 계층의 의무를 갖는 도메인은 인터넷이고, 그 아래 두 계층의 의무를 갖는 도메인은 링크이다.
논리적 연결에 대해 생각해 보기 위한 다른 방법은 각 계층에서 만들어지는 데이터 단위에 대해 생각해 보는 것이다. 최상위 세 계층에서는 패킷이 라우터나 링크 계층 스위치에 의해 변하지 말아야 한다. 그 아래 두 계층에서는 호스트에 의해 생성된 패킷이 링크 계층 스위치가 아닌 오직 라우터에 의해서만 변한다.
주목할 것은 비록 네트워크 계층에서의 논리적 연결이 두 호스트 사이에 존재할지라도 이 상황에서 말할 수 있는 오직 한 가지는 두 지점 사이에 동일한 객체가 존재한다는 것이다.
주소지정
인터넷에서 프로토콜 계층화에 관련된 또 다른 개념인 주소지정에 대해 언급하는 것은 매우 가치있다. 우리는 이 모델에서 계층들의 쌍 사이에서의 논리적 연결을 가지고 있다. 두 개의 파티를 포함하는 어떠한 통신도 발신지 주소와 목적지 주소를 필요로 한다. 비록 우리가 보기에는 필요한 주소의 쌍의 개수가 한 계층에 한 쌍식 5쌍인 것처럼 보이지만 사실 물리 계층은 주소를 필요로 하지 않기 때문에 주로 4쌍의 주소만을 가진다. 물리 계층에서의 데이터 교환의 단위는 비트이므로 이것은 절대로 주소를 가질 수 없다. 그림 1.17은 각 계층의 주소지정을 보인다.
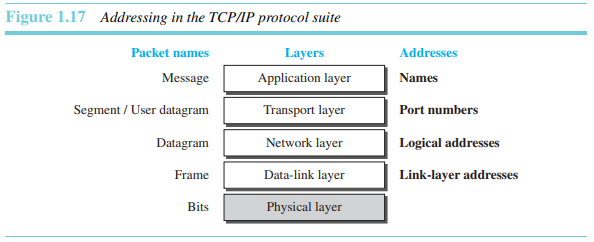
위 그림이 보이는 것과 같이 계층, 그 계층에서의 주소, 그 계층에서의 패킷 이름 사이에는 관계가 존재한다. 응용 계층에서 우리는 someorg.com 같은 서비스를 제공하는 사이트 이름, 또는 somebody@coldmail.com 과 같은 이메일 주소를 이용한다. 전송계층에서의 주소들은 포트번호로 불리고 이 번호들은 발신지와 도착지의 응용들을 정의한다. 포트번호들은 동시에 동작하는 여러 개의 프로그램들을 구분하기 위한 지역 주소들이다. 네트워크 계층에서 주소들은 전역적이며 전체 인터넷을 범위로 가진다. 하나의 네트워크 주소는 인터넷에 접속하는 장치를 유일하게 정의하는 주소이다. 때때로 MAC 주소로 불리는 링크 계층 주소들은 지역적으로 정의된 주소이며, 이 각각의 주소는 네트워크에서의(LAN 또는 WAN) 특정 호스트 또는 라우터를 정의한다.
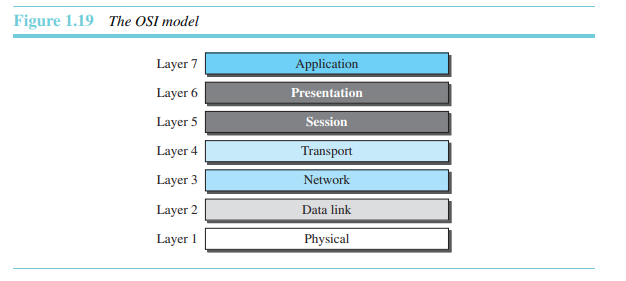
1.2.3 OSI 모델
OSI(개방 시스템 상호연결, Open System Interconnection)은 70년대 후반에 처음 소개되었다.
개방 시스템(Open System)은 기반 구조와 상관없이 서로 다른 시스템 간의 통신을 제공하는 프로토콜의 집합이다. OSI 모델은 HW나 SW 기반의 논리적인 변화에 대한 요구 없이 서로 다른 시스템 간의 통신을 원활하게 하는 데 그 목적이 있다. OSI 모델은 프로토콜이 아니다. 유연하고 안전하며, 상호 연동이 가능한 네트워크 구조를 이해하고 설계하기 위한 모델이다. OSI 모델은 OSI 스택에 있는 프로토콜 생성의 기초가 된다.
OSI 모델은 모든 종류의 컴퓨터 시스템 간 통신을 가능하게 하는 네트워크 시스템 설계를 위한 계층구조이다. 이 모델은 서로 연관된 7개의 계층으로 구성되어 있고, 각 계층에서는 네트워크를 통해 정보를 전송하는 일련의 과정이 규정되어 있다.
1.3 데이터와 신호
1.3.1 성능
네트워크에서 중요한 문제 중 하나는 네트워크가 얼마나 좋은가 하는 것이다.
대역폭
이 용어는 두 가지 다른 값을 측정하는 다른 뜻으로 사용될 수 있는데 하나는 Hz를 단위로 하는 대역폭이고 다른 하나는 초당 비트 수이다.
- 헤르츠 단위의 대역폭
복합 신호에 포함된 주파수 영역 또는 채널이 통과시킬 수 있는 주파수 영역을 말한다. 예를 들어 가입자 전화선의 대역폭이 4kHz라고 하는 식이다. - 비트율 단위의 대역폭
대역폭은 채널이나 링크 또는 심지어 네트워크가 통과시킬 수 있는 초당 비트 수를 일컬을 때가 있다. 예를 들어 고속 이더넷이 최대 100Mbps의 대역폭을 갖는다고 말할 수 있는 것이다. 이는 네트워크가 100Mbps로 전송할 수 있다는 것을 말한다. - 대역폭이 2배이면 전송률도 약 2배이다.
처리율
어떤 지점을 데이터가 얼마나 빠르게 지나가는지를 측정하는 것이다. 얼핏 보면 비트율 단위의 대역폭이나 처리량이 동일해 보이나 둘은 서로 다르다. 어느 링크가 B bps의 대역폭을 가질 수 있으나 이 링크를 사용하여 항상 B보다 작은 T bps의 처리량만 가능한 것이다. 다시 말하면 대역폭은 링크의 잠재 성능 측정치이며 처리량은 얼마나 빠르게 데이터를 전송할 수 있는지의 실제 전송 속도인 것이다.
1.4 전송 매체
전송 매체는 제 0계층에 속한다고 할 수 있다.
전송 매체(transmission medium)는 발신지로부터 목적지로 정보를 나를 수 있는 어떤 것이라고 폭넓게 볼 수 있다.
데이터통신에서의 정보와 전송 매체의 정의는 보다 구체적이다. 전송 매체는 보통 자유 공간, 금속 케이블, 또는 광섬유이다. 정보는 흔히 다른 형식으로부터 데이터를 반환한 결과로 얻어진 신호이다.
원격통신의 목적을 위해 전송 매체는 유도매체와 비유도매체의 두 가지의 큰 부류로 나눌 수 있다.
1.4.1 유도 매체
한 장치에서 다른 장치로의 통로를 제공하는 유도 매체에는 꼬임쌍선, 동축 케이블, 광섬유 케이블이 포함된다. 이와 같은 매체를 따라 이동하는 신호는 매체의 물리적 제한에 따라 전송방향이 설정되고 적재된다. 꼬임쌍선과 동축 케이블은 전류의 형태로 신호를 받고 전달하는 금속성(구리) 도선을 사용하고, 광섬유는 빛의 형태로 신호를 받고 전달하는 유리나 플라스틱 케이블을 사용한다.
꼬임쌍선 케이블
플라스틱 절연체를 입히고 서로 꼬인 한 쌍의 전도체(보통 구리)로 되어 있다.
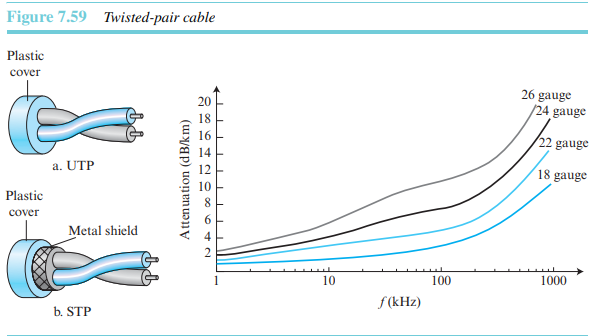
신호선과 접지선을 꼬아 만든다. LAN과 ADSL에 사용된다. 통신에서 가장 널리 쓰이는 꼬임쌍선은 비차폐 꼬임쌍선(UTP, Unshielded twisted pair)이다. IBM은 차폐 꼬임쌍선(STP, shielded twisted pair)라고 하는 꼬임쌍선을 만들었다. STP는 절연된 전도체 쌍을 감싸는 금속 그물 덮게를 갖고 있다. 금속 덮개가 잡음이나 혼선이 파고들지 못하도록 보호한다.
동축 케이블
동심축을 플라스틱 절연체로 피복 후 그물형 구리망으로 감싼다. 이는 잡음 방지를 위해서이다. 넓은 주파수 대역을 제공하고(아날로그, 디지털 전송), 이더넷의 표준이며, 장거리 전화망에 쓰인다.
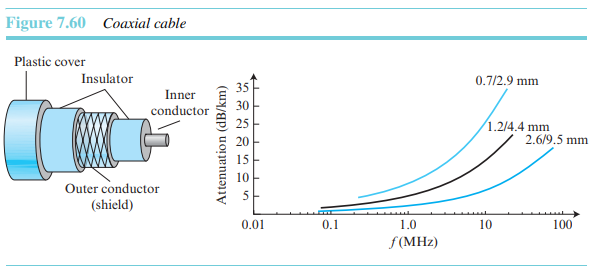
광케이블
유리나 플라스틱으로 만들어지는 광섬유는 빛의 형태로 신호를 전송한다. 광섬유는 채널을 통해 빛을 유도하기 위해 반사를 사용한다. 유리나 플라스틱 중심부는 더 낮은 밀도의 유리나 플라스틱 피복으로 둘러싸여 있다. 두 가지 밀도의 차이는 중심부를 통해 이동하는 광선이 피복(cladding)에 굴절되어 들어가지 않고 반사될 정도가 되어야만 한다.
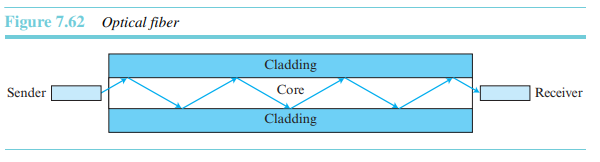
100km 이상의 장거리 전송이 가능하며, 수 Gbps의 고속전송을 한다.
1.5 다중화
두 장치를 연결하는 매체의 전송용량이 두 장치가 필요로 하는 전송량보다 클 경우에는 언제든지 그 링크를 공유할 수 있다. 이처럼 다중화는 단일 링크를 통하여 여러 개의 신호를 동시에 전송할 수 있도록 해주는 기술이다.
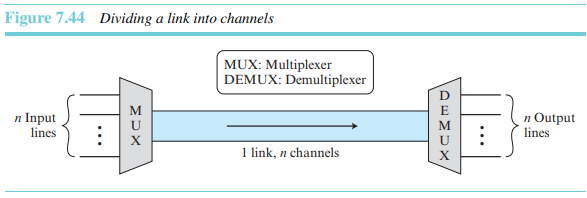
다중화된 시스템에서는 n개의 장치가 단일 링크의 용량을 공유한다. 그림 7.44는 다중화 시스템의 기본형식을 보여준다. 왼편에 있는 n개의 장치는 자신들이 전송할 데이터 흐름을 다중화기(MUX)로 보내고, 다중화기는 그 흐름들을 1개의 흐름으로 조합하게 된다(다 대 일). 송신단은 이 흐름을 다중복구기(DEMUX)로 보내고, 다중복구기는 이 흐름을 각 요소별로 분리하여 각각을 해당 선로로 보낸다(일 대 다). 그림 7.44에서 링크(link)는 물리적인 경로를, 채널(channel)은 주어진 1쌍의 장치들 사이의 전송을 위한 하나의 경로를 말한다. 따라서 하나의 링크에는 여러 개(n)의 채널이 있을 수 있다.
신호는 주파수 분할 다중화(FDM)와 시분할 다중화(TDM), 반송파 분할 다중화(CDMA)의 기본적인 기법을 사용하여 다중화된다.
1.5.1 FDM
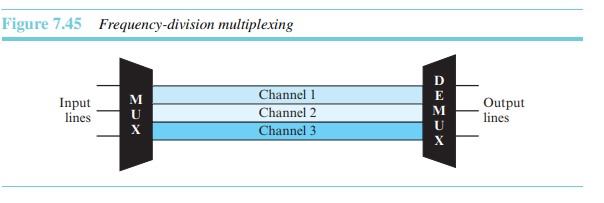
주파수분할 다중화(frequency-division multiflexing)는 전송되어야 할 신호들의 대역폭을 합친 것보다 링크의 대역폭이 클 때 적용할 수 있는 아날로그 기술이다. 채널들은 신호가 겹치지 않게 하기 위해 사용하지 않는 대역폭만큼 서로 떨어져야 한다. 그림 7.45는 FDM의 개념을 보이고 있다. 그림에서 전송경로는 세 부분으로 나누어져 있고, 각각은 하나씩 전송할 수 있는 채널을 나타낸다.
1.5.2 TDM
시분할 다중화(time-frequency multiflexing)는 링크의 높은 대역폭을 여러 연결이 공유할 수 있도록 하는 디지털 과정이다. FDM에서 대역의 일부를 공유하는 대신에 시간을 공유하는 것이다. 그림 7.48은 TDM의 개념을 보여 준다. FDM에서와 마찬가지로 같은 링크가 사용되지만, 링크는 주파수가 아닌 시간별로 구획지어져 있다는 점에 유의하자.
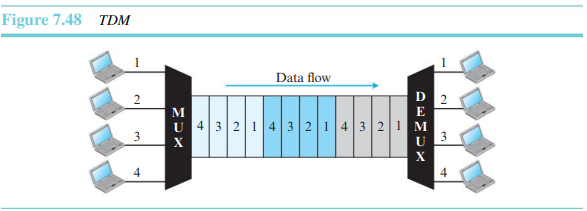
그림 7.48에서는 오직 다중화에만 관심을 갖고 교환에는 관심을 두지 않는 것에 유의하라. 이는 출발지 1로부터 오는 메시지는 목적지가 1, 2, 3, 4 중 무엇이 되었든 항상 그 중 하나로만 전달되는 것을 의미한다. 전달되는 곳은 항상 일정하게 정해져 있다.
1.5.3 CDMA
1.5.4 응용-ADSL
모뎀(modem)이라는 용어는 신호 변조기와 복조기라는 모뎀 장치를 구성하는 두 가지 기능의 혼합어이다. 변조기(modulator)는 이진 데이터로부터 아날로그 신호를 생성한다. 복조기(de-modulator)는 변조된 신호로부터 이진 데이터를 복구해 낸다. 이런 연결은 오직 한 부분이 디지털 신호를 사용하고 있는 중에만 연결이 사용 가능하다. 디지털을 아날로그로 바꾸는 업로드보다 아날로그를 다지털로 바꾸는 다운로드가 더 빠른 비대칭이다.
DSL은 기존의 전화를 사용하는 고속 디지털 통신을 지원하기 위한 기술이다. ADSL(Asymmetric Digital Subscribe Line)은 비대칭 DSL로서 업스트림 방향보다 다운스트림 방향에서 더 높은 속도를 제공한다. ADSL의 설계자들은 FDM 다중화를 통해 사용가능한 대역폭을 불균등하게 나누었다. ADSL은 가입자 동시에 음성 채널과 데이터 채널을 사용할 수 있다.
2. 응용계층
2.1 개요
2.1.1 서비스 제공
만약 한 프로토콜이 각 계층에 추가된다면, 그것은 더 낮은 계층 안의 프로토콜 중 하나에 의해 제공되는 서비스를 사용하는 방법으로 설계되어야 한다. 만약 한 프로토콜이 계층에서 삭제된다면, 삭제된 프로토콜의 서비스를 사용하는 더 높은 다음 계층 안의 프로토콜을 수정하기 위한 관리가 이루어져야 한다.
그러나 응용계층은 최상위 계층이므로, 프로토콜들이 이 계층으로부터 쉽게 제거되고 추가될 수 있다.
표준과 비표준 프로토콜
인터넷의 원활한 동작을 위해 TCP/IP 집합의 처음 4계층에서 사용되는 프로토콜들에 대한 표준화와 문서화가 필요하지만, 응용계층 프로토콜들은 표준과 비표준 모두가 될 수 있다.
- 표준 응용계층 프로토콜
인터넷 관리기관들에게 의해 표준화와 문서화가 된 몇 가지 응용계층 프로토콜들이 있다. 이러한 응용계층 프로토콜의 경우, 이 응용들과 함께 사용할 수 있는 옵션 등을 알아야 한다. - 비표준 응용계층 프로토콜
만약 프로그래머가 전송계층과의 상호작용을 하여 사용자에게 서비스를 제공하는 두 프로그램을 만들 수 있다면, 그는 비표준 응용계층 프로그램을 생성할 수 있다. 개인 회사는 어떠한 표준 응용프로그램들도 사용하지 않고, TCP/IP 프로토콜 집합의 처음 4계층에 의해 제공되는 서비스를 사용하여 새로운 맞춤형 응용 프로토콜을 만들 수 있다. 컴퓨터 언어들 중 하나로 프로그램을 만들기 위해 필요한 것은 전송계층 프로토콜에 의해 제공되는 사용 가능한 서비스들을 이용하는 것이다.
2.1.2 응용계층 패러다임
전통적인 패러다임: 클라이언트-서버
서버 프로세스는 반드시 항상 실행되고 있어야만 하며 클라이언트 프로세스는 클라이언트가 서비스를 필요로 할 때 시작된다. 비록 클라이언트-서버 패러다임의 통신이 두 응용프로그램 사이에 있지만, 각 프로그램의 역할은 전체적으로 다르다.
이 패러다임의 한 가지 문제는 서버측에 통신 부담이 집중된다는 점이다. 또한 특정한 서비스를 위해 많은 비용이 들아간다는 것이다.
WWW, HTTP, FTP, SSH, 이메일 등 전통적인 서비스들은 여전히 이 패러다임을 사용하고 있다.
새 패러다임: 대등-대-대등
이 패러다임에서 서버 프로세스는 항시 동작하면서 클라이언트 프로세스의 접속을 대기해야 할 필요가 없다. 그 책임은 대등들에게로 나누어지며, 한 컴퓨터는 동시에 서비스를 제공하거나 제공받는 것 또한 가능하다. 한 집단은 다른 집단과의 통화를 위해 영구대기를 수행할 필요가 없다.
비트토렌트, 스카이프, IPTV, 인터넷 전화가 이것을 사용한다.
2.2 클라이언트-서버 패러다임
클라이언트의 요청 시 서버는 반드시 실행 중이어야 하지만, 클라이언트는 자신이 필요할 때만 실행하면 된다.
2.2.1 API
우리가 한 프로세서와 다른 프로세서가 통신하는 것을 필요로 한다면, TCP/IP 집합의 가장 낮은 4계층에서의 연결 시작, 데이터의 송수신, 연결의 종료를 지시하는 새로운 명령어 집합이 필요하다. 이것을 API로 정의한다. 통신을 위해 설계된 API가 소켓 인터페이스이다.
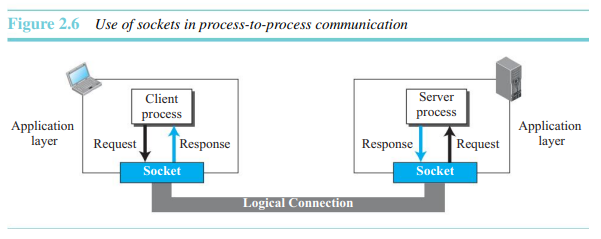
소켓
소켓은 응용프로그램에 의해 생성, 사용되는 자료구조이다. 클라이언트 와 서버 간 통신은 두 소켓 사이의 통신이며, 그림 2.6처럼 두 종단에서 생성된 것이다.
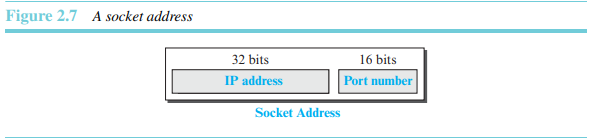
소켓 주소 탐색
클라이언트와 서버는 어떻게 통신을 위한 한 쌍의 소켓 주소를 찾는가? 그 상황은 각 부분마다 다르다.
- 서버 부분
1) 지역 소켓 주소: OS에 의해 제공된다. OS는 서버 프로세스가 실행되는 호스트의 IP 주소를 알고 있지만, 포트번호는 직접 할당이 필요하다. 서버 프로세스가 인터넷 관리기관에 의해 정의된 표준이라면, 포트번호는 이미 할당되어 있다. well-known 포트번호는 이미 할당되어 있는 포트번호이다. 서버가 동작을 시작할 때, 서버는 지역 소켓 주소를 알게 된다.
2) 원격 소켓 주소: 서버는 클라이언트가 서버에 접속을 시도했을 때에야 소켓 주소를 찾아낼 수 있다. - 클라이언트 부분
1) 지역 소켓 주소: 역시 OS에 의해 제공된다. OS는 클라이언트의 IP 주소를 알고 있으나, 포트번호는 프로세스가 통신을 시작하려 할 때마다 할당되는 임시 정수(16비트)이다. 그러나 포트번호는 인터넷 관리기관에 의해 정의된 정수의 집합으로부터 할당되고, 일시적(임시의)포트번호라고 불린다. OS는 새 포트번호가 다른 클라이언트 프로세스에 의해 사용되지 않도록 보장해야 한다.
2) 원격 소켓 주소: 서버 소켓 주소를 찾는 것은 복잡하다. 두 가지 상황을 갖는다.
A) 종종 서버 포트번호와 IP 주소를 모두 알고 있는 경우이다. 테스트하는 상황에서 발생한다.
B) 각 표준 응용이 well-known 포트번호를 갖고 있더라도 거의 대부분의 시간 동안 IP 주소를 알지 못한다. IP 주소는 DNS를 통해 알 수 있다.
2.2.2 전송 계층의 서비스 사용
TCP, UDP
UDP는 무접속, 비신뢰성, 데이터그램 서비스를 제공한다. 무접속이라는 말은, 메세지 교환 시 두 종단 사이에 논리적 연결이 없음을 의미한다.
TCP의 문제점은 메시지 교환에 대한 영역을 제공하지 않는 메시지 지향적이지 않은 방식이라는 것이다(데이터가 세그먼트로 나누어져 전송되므로 개별 메시지 간의 경계를 명확히 정의하지 않는다).
SCTP
SCTP 프로토콜은 서로 다른 두 프로토콜을 결합하는 서비스를 제공한다. TCP처럼 연결 지향적이며 안정적인 서비스를 제공하지만 바이트-스트림 지향적인 것은 아니며, UDP처럼 메시지-지향적이다. 또한 다중 네트워크 계층 연결에 의해 멀티스트림 서비스를 제공할 수 있다.
SCTP는 일반적으로 하나의 네트워크 계층 연결 안에서 하나의 실패가 발생하더라도 연결이 유지되고, 신뢰성을 필요로 하는 특정 응용에 적합하다.
2.3 표준 클라이언트-서버 응용매체
WWW, HTTP, 이메일, 텔넷~, SSH, DNS를 소개한다.
2.3.1 WWW와 HTTP
WWW
- 구조
오늘날 WWW는 분산 클라이언트-서버 서비스다. 즉 브라우저를 사용하는 클라이언트가 서버를 사용하여 서비스를 받는다.
1) 웹 클라이언트(브라우저)
브라우저는 웹 문서를 해석하여 표현한다. 제어기, 클라이언트 프로토콜, 해석기의 세 부분으로 구성된다.
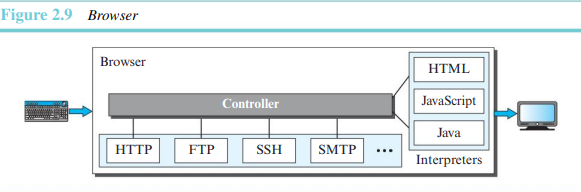
제어기는 키보드나 마우스로부터 입력을 받아 클라이언트 프로그램을 사용하여 문서에 액세스한다. 그 후 해석기를 사용하여 문서를 화면에 표현한다. 클라이언트 프로토콜은 HTTP, FTP, 텔넷 등이 될 수 있다.
2) 웹 서버
웹페이지는 서버에 저장된다. - 단일 자원 위치기(URL):
한 파일로서 웹페이지는 다른 웹페이지로부터 자신을 식별자를 필요로 한다. 웹페이지를 정의하기 위한 3개의 식별자는 호스트, 포트, 경로이다. 그러나 웹페이지를 정의하기 전에 브라우저에게 우리가 사용하기를 원하는 클라이언트 서버 응용이 무엇인지 말해줘야 한다. 그것은 프로토콜이다. 즉 웹페이지를 정의하려면 4개의 식별자가 필요하다.
A) 프로토콜: 첫 번째 식별자는 웹페이지에 접속하기 위해 필요로 하는 클라이언트-서버 프로그램의 약어이다. HTTP를 가장 많이 사용한다.
B) 호스트: 호스트 식별자는 IP 주소이다. 이는 도메인 이름으로 표현된다.
C) 포트: 16비트 정수이며, 일반적으로 클라이언트-서버 응용프로그램을 위해 미리 정의된다. 예를 들어 HTTP 프로토콜이 웹에 접속하기 위해 사용된다면, 잘 알려진 포트번호 80을 사용한다. 하지만 다른 포트가 사용되면 숫자는 반드시 주어져야 한다.
D) 경로: 경로는 파일의 위치와 이름을 식별한다.
이 4가지를 모두 결합한 것이 URL이다. URL은 모든 자원 접근을 단일화한다.

- 웹 문서
WWW에서 문서는 정적, 동적 액티브로 나뉜다.
1) 정적 문서는 서버에서 생성되어 저장된 고정 내용 문서이다. 클라이언트는 문서의 복사본만을 얻을 수 있다.
2) 동적 문서는 브라우저가 문서를 요청할 때마다 웹 서버에 의해 생성된다. 요청이 들어오면, 웹 서버는 동적 문서를 만드는 응용 프로그램이나 스크립트를 수행한다. 서버는 프로그램의 출력이나 스크립트를 그 문서를 만드는 응용프로그램이나 스크립트를 브라우저에게 응답으로 반환한다.
3) 액티브 문서는 클라이언트에서 수행되는 문서이다. 예로 자바 애플릿이 있다.
HTTP
클라이언트-서버 프로그램이 웹 페이지를 웹에서 어떻게 검색할 수 있는지 정의하는 프로토콜로, TCP 서비스를 사용한다.
- 영속적 연결 vs 비영속적 연결
1) 비영속적 연결에서는 각 요청/응답에 대해 하나의 TCP 연결이 만들어진다. 만약 한 파일이 다른 파일들(모두 동일한 서버에 위치) 안에 있는 N개의 다른 그림들의 링크를 포함한다면, 연결의 시작과 종료가 N+1번씩 발생한다.
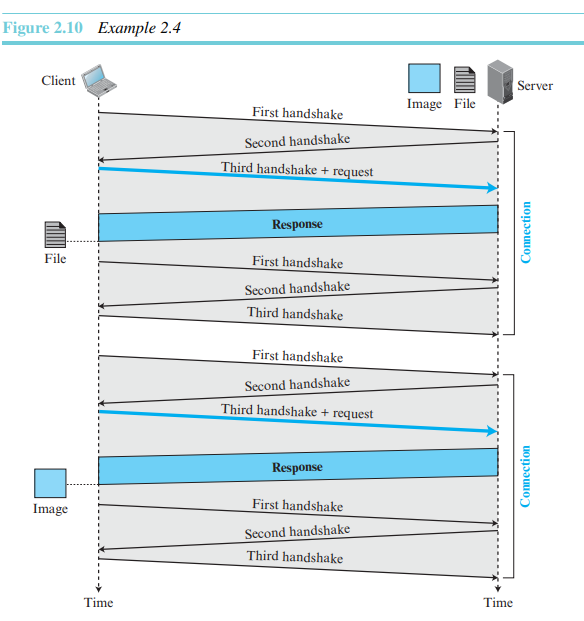
2) 영속적 연결에서 서버는 응답을 전송한 후에 차후의 요청을 위해 연결을 열어놓은 상태로 유지한다. 서버는 클라이언트의 요청이 있을 때나 타임아웃이 되면 연결을 닫을 수 있다.
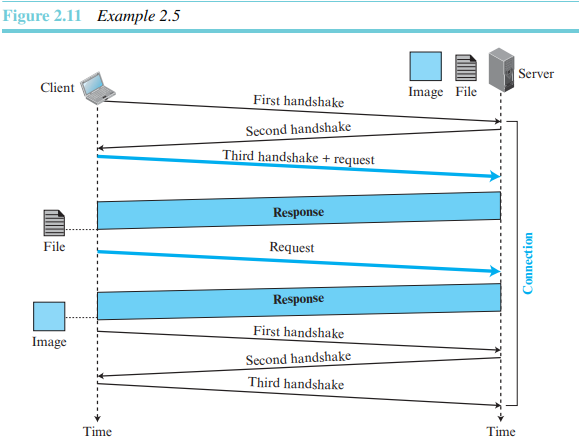
- 메세지 형식들
HTTP는 그림 2.12와 같이 요청 메시지와 응답 메시지의 형식을 정의한다. 각 메시지는 4개의 부분으로 구성된다. 요청 메시지의 첫 부분은 요청라인이라 부르고, 응답 메시지의 첫 부분은 상태라인이라 부른다. 나머지는 같은 이름을 갖는다(그러나 다른 내용을 갖는다).
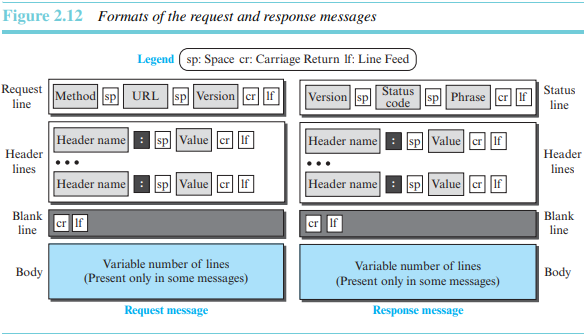
1) 요청 메시지
요청라인에는 세 개의 필드가 있다. 이들은 한 공백에 의해 분리되고 2개의 문자들(CR, LF)에 의해 끝난다. 이 필드들은 메소드와 URL, 버전이다.
메소드 필드는 요청의 유형(request type)을 정의한다. 대부분의 시간 동안 클라이언트는 요청하기 위해 GET 메소들르 사용한다. 이 경우, 메세지의 몸체(Body)는 비어 있다.

URL은 해당 웹페이지 주소와 이름을 정의하고, 버전은 프로토콜의 버전을 알려준다.
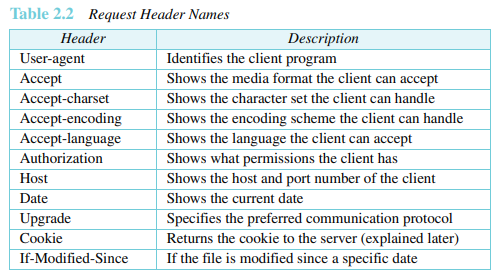
요청라인 뒤에 0개 이상의 요청 헤더라인들을 볼 수 있다. 각 헤더라인은 클라이언트로부터 서버로 추가 정보를 전송한다. 예를 들어, 클라이언트는 특별한 형식으로 문서가 전송되도록 요청할 수 있다.
몸체가 요청 메시지에 있을 수 있다. PUT 또는 POST 메소드가 있을 때, 일반적으로 그것은 송신할 설명 또는 웹 사이트에 생성되기 위한 파일을 포함한다.
2) 응답 메시지
상태라인은 세 개의 필드로 구성된다. 각 필드는 공백으로 구성되며, CR과 LF로 종료된다. 첫 필드는 HTTP 프로토콜의 버전을 의미한다. 상태 코드 필드는 요청 상태를 정의한다. 상태 문구는 문자 형태로 상태 코드를 설명한다.
상태라인 뒤에 0개 이상의 응답 헤더라인을 가질 수 있다. 각 헤더라인은 서버로부터 클라이언트까지 추가적은 정보를 전송한다. 예를 들어, 서버는 문서에 대한 추가적인 정보를 전송할 수 있다. 헤더라인은 헤더 이름, 콜론, 공백, 헤더 값으로 구성된다.
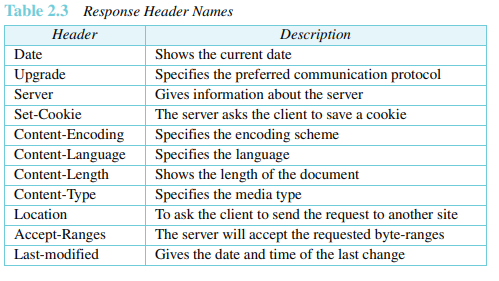
몸체는 서버로부터 클라이언트까지 전송되는 문서를 포함한다. 응답이 오류 메시지가 아니라면 몸체는 존재한다.
예제 2.6
이 예제는 문서를 검색하기 위한 예제이다. 우리는 경로 usr/bin/image1 을갖는 이미지를 읽어오기 위해 GET 메소드를 이용한다. 요청라인은 메소드, URL, HTTP 버전을 표시한다. 헤더는 두 줄을 갖는데, 이들은 클라이언트가 GIF 또는 JPEG 형식으로 이미지를 수용할 수 있음을 나타낸다. 요청은 몸체가 없다. 응답 메시지는 상태라인과 네 라인의 헤더를 포함한다. 헤더라인은 날짜, 서버, MIME 버전, 문서의 길이를 정의한다. 문서의 몸체는 헤더 뒤에 온다.
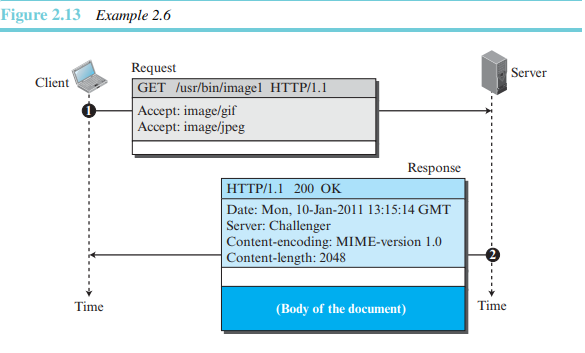
예제 2.7
이 예제에서는 클라이언트가 웹페이를 서버에게 송신하기를 원한다. 다라서 PUT 메소드를 사용한다. 요청라인은 메소드, URL, HTTP 버전을 표시한다. 네 라인의 헤더가 존재한다. 응답 메시지는 상태라인과 네 줄의 헤더를 포함한다. 요청 몸체는 웹페이지를 포함한다.
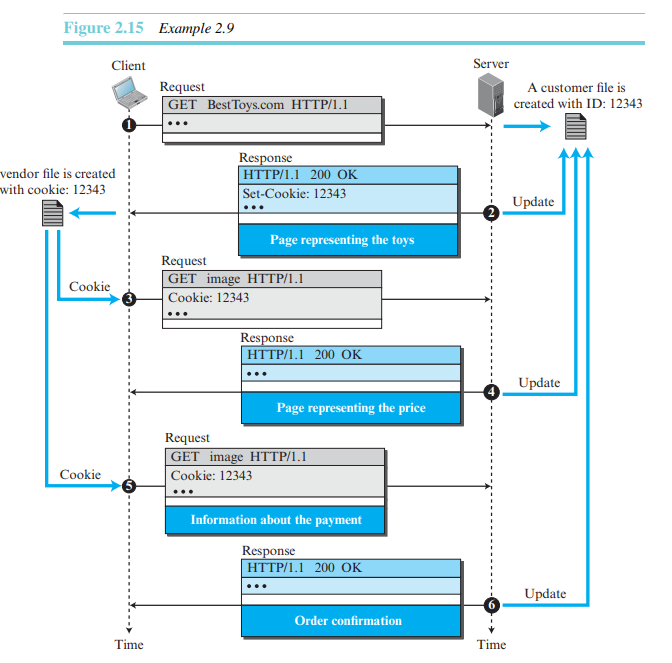
- 쿠키
WWW는 원래 상태가 존재하지 않는 개체로 설계되었다. 이를 보완하는 것이 쿠키이다. 쿠키는 클라이언트와 웹서버 사이에 신뢰성 있는 연결을 유지한다. 쿠키는 등록된 사용자만 접근을 허용하게 할 수도, 사용자 지향적인 정보를 제공할 수도 있고, 광고에도 사용된다.
1) 쿠키의 생성과 저장
1.서버가 클라이언트로부터 요청을 받았을 때, 클라이언트에 관한 정보를 파일이나 문자열로 저장한다.
2.서버는 클라이언트에게 보내는 응답에 쿠키를 포함한다.
3.클라이언트가 응답을 받으면, 브라우저는 쿠키를 도메인 서버 이름으로 정렬되는 쿠키 디렉터리에 저장한다.
2) 쿠키 사용
클라이언트가 서버에게 요청을 보낼 때, 브라우저는 쿠키 디렉터리를 검색하여 서버가 보낸 쿠키를 찾는다. 만일 존재한다면, 쿠키를 요청에 포함시킨다. 쿠키를 포함된 요청을 받은 서버는 클라이언트가 기존 클라이언트라는 것을 알게 된다. 쿠키의 내용은 브라우저가 읽을 수 없거나 사용자에게 보이지 않는다. 이것은 서버가 만들고 서버사 사용하는 쿠키이다.
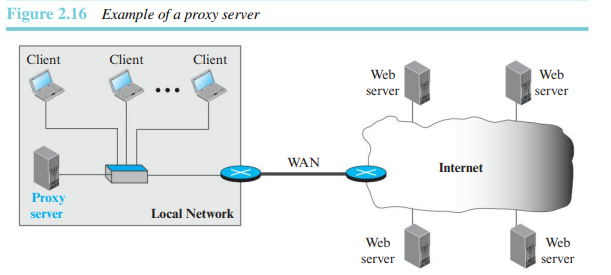
웹 캐싱: 프록시 서버
최신 요청에 대한 응답의 복사본을 가지고 있는 컴퓨터이다. HTTP 클라이언트는 프록시 서버로 요청을 보낸다. 프록시 서버는 캐시를 검사한다. 만일 응답이 캐시에 저장되어있지 않으면, 프로시 서버는 적절한 요청을 서버로 보낸다. 수신된 응답은 프록시 서버로 보내지고 다음 클라이언트의 요청에 대비해 저장된다.
프록시 서버는 원래의 서버 부하를 경감시키고, 트래픽을 감소시키며, 지연을 개선한다.
1) 프록시 서버 위치
프록시 서버는 클라이언트 사이트에 위치한다.
2) 캐시 갱신
프록시 서버에서 응답이 삭제되고 대치되기 전 얼마나 오랫동안 프록시 서버에 존재해야 하는가의 매우 중요한 문제이다.
HTTP 보안
HTTP 자체는 보안을 제공하지 않는다. 하지만 HTTP는 SSL(Secure Socket Layer)에서 수행될 수 있다. 이 경우 HTTP는 HTTPS라 부른다.
2.3.2 FTP
FTP는 제어와 데이터 전송을 분리한다.
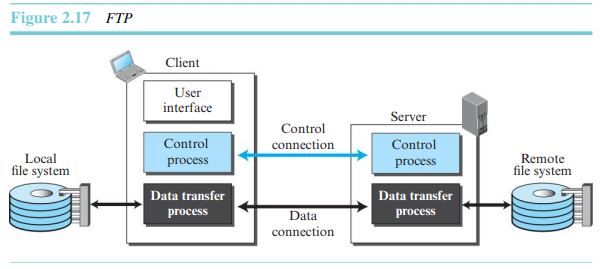
두 연결의 라이프타임
FTP에서 두 연결은 서로 다른 라이프타임을 가진다.
제어 연결은 FTP 세션 내내 연결된 상태로 유지된다.데이터 연결은 전송되는 각 파일마다 열렸다 닫힌다.
제어 연결
제어 통신은 명령과 응답을 통해 이루어진다. 이는 한 번에 하나의 명령 또는 응답을 전송하므로 제어 연결에 적합하다. 명령은 클라이언트에서 서버로, 응답은 서버에서 클라이언트로 전송된다. 잘 알려진 포트 번호 21을 사용한다.
데이터 연결
데이터 연결은 서버측 잘 알려진 포트번호 20을 사용한다. 데이터 연결의 생성은 제어 연결과는 다르다. 다음은 FTP에서의 데이터 연결 과정이다.
- 서버가 아닌 클라이언트가 임시 포트를 사용하여 수동적 연결 설정을 시도한다. 클라이언트가 파일 전송 명령을 보내므로 이는 반드시 클라이언트가 수행해야 한다.
- 클라이언트는 이 포트번호를 PORT 명령어를 사용하여 서버에 전송한다.
- 서버는 포트번호를 수신한 후 포트 20과 임시 포트번호를 사용하여 능동적 연결을 시도한다.
- 데이터 연결 상의 통신
클라이언트는 전송될 파일의 종류와 데이터의 구조, 전송 모드를 정의해야 한다.
1) 데이터 구조: 파일 구조, 레코드 구조, 페이지 구조 중 하나를 사용한다.
2) 파일 종류: ASCII, EBCDIC, 이미지 파일
3) 전송 모드: 스트림, 블록, 압축 모드
4) 파일 전송: FTP에서 파일 전송은 세 개 중 하나이다. 파일받기, 파일저장, 디렉터리나열.
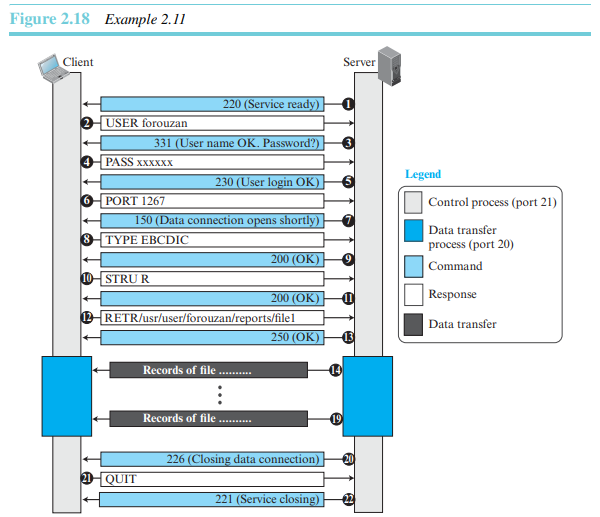
예제 2.11
그림 2.18은 디렉터리에 있는 항목들의 목록을 검색하기 위해 FTP를 사용한다. 제어 연결은 항상 열려 있지만 데이터 연결의 설정과 해제는 반복적으로 이루어진다. 파일은 6개의 섹션으로 송신된다. 모든 파일이 전송되면 서버는 제어 연결로 데이터의 전달을 응답한다. 클라이언트 제어 프로세스가 가져올 파일이 없으면 QUIT 명령을 통해 서비스를 종료한다.
예제 2.12
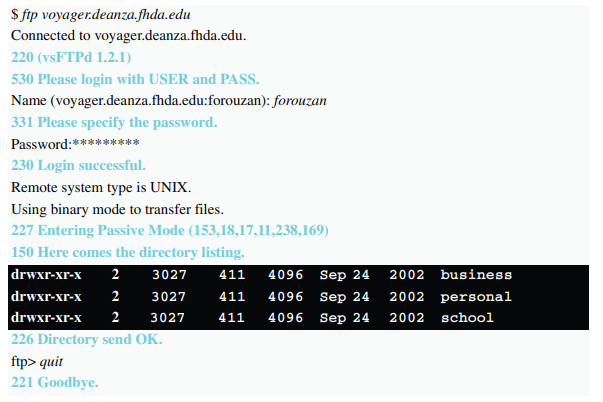
예제 2.11을 예시로 하는 실제 FTP 세션이다. 색깔이 있는 줄은 서버 제어 연결로부터의 응답을, 검은색 줄은 클라이언트에 의해 전송되는 명령어를, 흰색 줄은 데이터 전송이다.
FTP 보안
FTP는 비밀번호를 요구하지만, 비밀번호가 평문으로 전송되어 공격자가 가로챌 수 있다. 보안을 위해 FTP 응용계층과 TCP 계층 사이에 보안 소켓 계층을 추가할 수 있는데, 이러한 경우의 FTP는 SSL-FTP라 부른다.
2.3.3 이메일
일반적 경우의 클라이언트-서버 모델에서, 서버 프로그램은 항상 실행되며, 클라이언트로부터 요청을 기다리고, 요청이 도착하면 서버는 서비스를 제공한다. 그러나 이메일은 단방향통신이다.
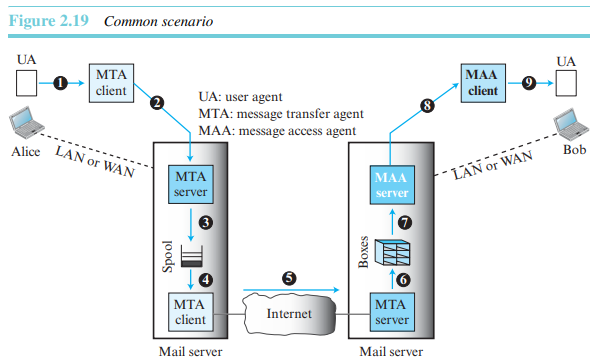
일반적 시나리오에서, 송신자인 앨리스와 수신자인 밥이 LAN 도는 WAN을 통하여 두 개의 메일 서버에 연결되어 있다. 관리자는 각 사용자를 위해 수신된 메시지가 저장될 편지함을 하나씩 생성한다. 편지함은 서버 HDD의 일부로, 접근 제한을 갖는 특정 파일이다. 편지함의 소유자만이 이에 액세스할 수 있다. 또한 관리자는 전송되기를 기다리는 메시지 등을 저장하기 위해 큐를 생성한다.
앨리스와 밥은 각각 3개의 다른 에이전트를 사용한다. 사용자 에이전트(User Agent, UA), 메일 전송 에이전트(Main Transfer Agent, MTA), 그리고 메시지 액세스 에이전트(Message Access Agent, MAA)이다.
이메일 시스템은 두 개의 UA와 두 쌍의 MTA들(클라이언트와 서버), 한 쌍의 MAA들이 필요하다.
사용자 에이전트
메시지를 송수신하는 과정을 보다 쉽게 할 수 있도록 하는 서비스를 제공한다. UA는 메시지를 구성하고, 읽고, 답장을 보내고, 전달하는 SW이다. UA는 명령 수행형과 GUI 기반형이 있다.
-
이메일 송신
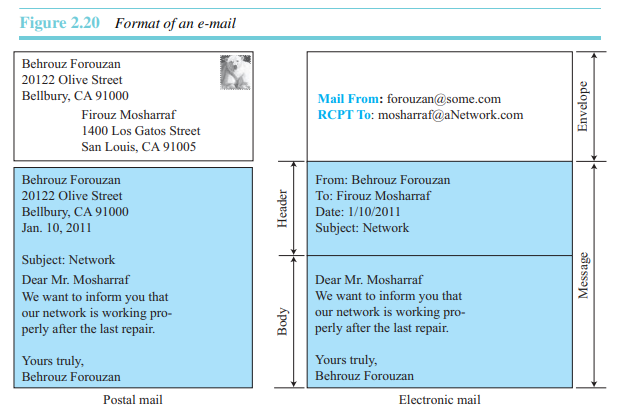
그림 2.20처럼 이메일은 봉투와 메시지로 이루어져 있다. 봉투는 송신자 및 수신자 주소와 그 외의 다른 정보들로 채워진다. 메시지는 헤더와 본문을 포함한다. 헤더에는 송신자, 수신자, 메시지 제목과 그 외의 다른 정보들을 규정한다. 메시지의 바디에는 수신자가 실제 읽을 정보가 들어 있다.
-
이메일 수신
-
주소
이메일 배달을 위해 이메일 처리 시스템은 유일한 주소를 갖는 주소 체계를 사용하여야 한다. 주소 체계는 @에 의해 분리된 로컬 부분과 도메인 이름 부분으로 나누어진다.

로컬 부분은 수신자의 편지함 주소이다. 도메인 이름은 메일 서버의 주소이다. -
주소 목록 혹은 그룹 목록
이메일은 여러 개의 다른 이메일 주소를 표현하는 하나의 이름, 별칭(alias)을 제공한다. 이를 주소 목록이라 부른다.
메시지 전송 에이전트: SMTP
이메일은 작업을 성취하기 위해 세 가지의 전형적인 클라이언트-서버의 사용을 요구하는 응용 중 하나이다. 그림 2.22은 세 가지의 클라이언트-서버 응용을 보인다. 첫 번째와 두 번째는 MTA고, 세 번째는 MAA이다.
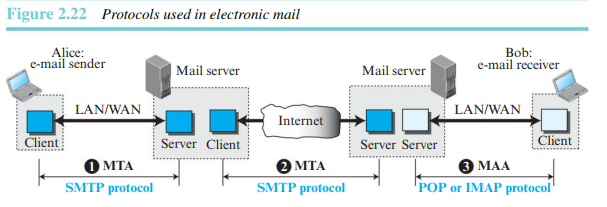
인터넷에서 MTA 클라이언트와 서버를 규정하는 공식적인 프로토콜이 SMTP이다. SMTP는 송신자와 송신자의 메일 서버 사이 그리고 두 메일 서버들 사이에서 총 두 번 사용된다. 메일 서버와 수신자 사이에 또 다른 프로토콜이 필요하다. SMTP는 단지 명령과 응답들이 어떻게 송신되고 수신되어야 하는지를 규정한다.
- 명령과 응답
SMTP는 명령과 응답을 사용하여 MTA 클라이언트와 MTA 서버 사이에서 메시지를 전송한다. 명령은 MTA 클라이언트에서 MTA 서버까지고, 응답은 MTA 서버에서 MTA 클라이언트까지다.
명령의 형식은 다음과 같다.Keyword: argument(s)
이는 키워드와 뒤에 따라오는 0 또는 그 이상의 인수로 구성된다.
- 이메일 전송 단계
연결 설정, 이메일 전송, 연결 종료로 구성된다.
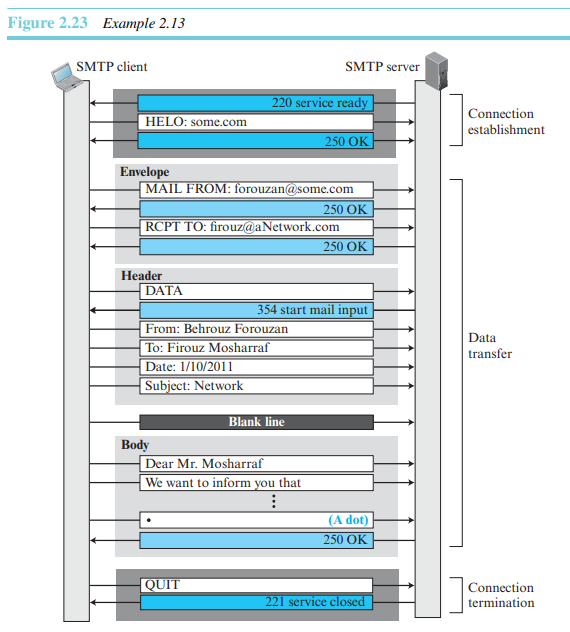
예제 2.13
세 가지 메일 전송단계를 그림 2.23에 나타내었다. 그림에서는 데이터 전송단계에서 봉투, 헤더, 바디로 메시지들을 분리하였다. 그림 안의 단계들은 이메일 전송 시 두 번 반복됨을 유의하라. 한번은 이메일 송신자로부터 로컬 메일 서버로, 한번은 로컬 메일 서버에서 원격의 메일 서버로. 로컬 메일 서버는 전체 이메일 메시지를 수신한 뒤 이를 스폴(spool)하고, 나중에 원격 메일 서버로 이를 보낸다.
메시지 액세스 에이전트: POP과 IMAP
이메일 배달의 첫 번째와 두 번째 단계는 SMTP를 사용한다. 하지만 SMTP는 세 번째 단계에는 참여하지 않는데 그 이유는 SMTP가 푸시 프로토콜이기 때문이다. SMTP는 메시지를 클라이언트로부터 서버로 밀어낸다. 달리 말하면, 대량 데이터(메시지)의 방향이 클라이언트로부터 서버 쪽이다. 반면에 세 번째 단계는 풀 프로토콜을 필요로 한다. 클라이언트는 서버로부터 메시지를 가져와야 한다. 대량 데이터의 방향이 서버로부터 클라이언트 쪽으로 가야 한다. 세 번째 단계는 메시지 액세스 에이전트를 사용한다.
현재 두 가지의 이메일 액세스 프로토콜을 사용할 수 있다. POP3과 IMAP4이다.
- POP(Post Office Protocol)3
POP3는 메일 서버에 있는 메일을 클라이언트의 컴퓨터로 가져와 관리한다. POP3는 간단하지만, 기능상의 제약이 존재한다. 클라이언트 POP3 소프트웨어는 수신자 컴퓨터에 설치되고, 서버 POP3 소프트웨어는 메일 서버에 설치된다.
이메일 액세스는 사용자가 메일 서버에 있는 편지함으로부터 이메일을 내려받을 필요가 있을 때 클라이언트에서 시작한다. 클라이언트는 TCP 포트번호 110으로 서버와의 연결을 연다. 그리고 편지함에 액세스하기 위해 사용자 이름과 비밀번호를 송신한다. 사용자은 그 후 메일 메시지들의 목록을 보고 하나씩 받아볼 수 있다. 그림 2.24에 POP3를 사용하여 내려받기를 하는 경우의 예를 보였다.
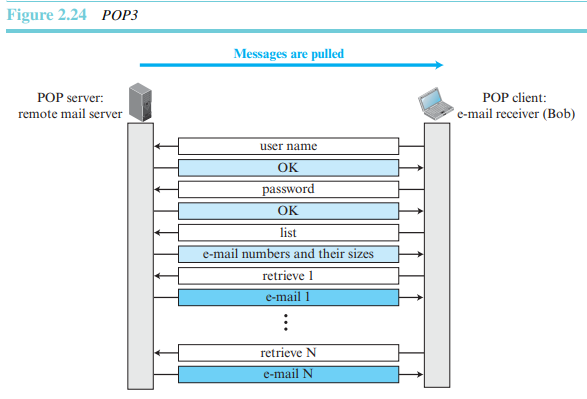
- IMAP(Internet Mail Access Protocol)4
POP3와 비슷하나 더 많은 기능을 갖는다.
POP3는 여러 방면에서 결함이 있다. 사용자가 서버에서 메일을 체계적으로 정리하는 기능을 제공하지 않는다. 사용자는 서버에서 여러 폴더를 가질 수 없다. 또한 POP3는 사용자가 메일을 내려받기 전에 메일의 내용을 부분적을 검사할 수 있도록 하는 기능도 제공하지 않는다. IMAP4는 다음과 같은 추가적 기능을 제공한다.
-서버에 직접 접속해 메일을 관리할 수 있다.
-이메일을 내려받기 전 헤더를 검사할 수 있으며, 특정 문자열로 내용을 검색할 수 있다.
-이메일을 부분적으로 내려받을 수 있고, 메일 서버에서 편지함을 생성하거나, 삭제하거나, 이름을 변경할 수 있다.
-편지함들을 체계적으로 관리할 수 있다.
MIME
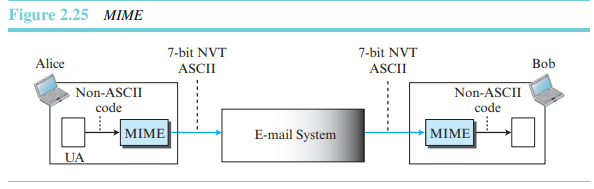
이메일은 간단한 구조를 갖고 있다. 그러나, 오직 NVT 7비트 ASCII 형식으로 된 메시지만을 전송할 수 있다.
MIME(Multipurpose Internet Mail Extensions)은 이메일을 통하여 아스키가 아닌 데이터가 송신될 수 있도록 허용하는 부가적인 프로토콜이다. MIME은 송신 사이트에서 ASCII가 아닌 데이터를 NVT ASCII로 변환하고 이를 인터넷을 통해 송신할 클라이언트 MTA로 배달한다.
우리는 MIME을 ASCII가 아닌 데이터를 ASCII로 변환하고 또 그 역을 수행하는 소프트웨어 기능들의 조합으로 간주할 수 있다.
- MIME 헤더
MIME은 변환 인수들을 정의하기 위해 원래의 이메일 헤더 부분에 추가될 수 있는 5개의 헤더를 규정한다.

MIME 버전: 사용된 MIME의 버전을 규정한다.
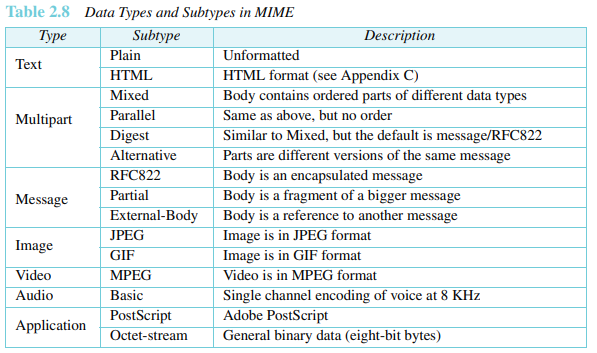
내용 유형(Content-Type): 메시지의 본문에서 사용되는 데이터의 종류를 규정한다. 내용 유형과 내용 서브유형을 슬래시로 구분한다. 서브유형에 따라 헤더는 다른 인수들을 가질 수도 있다. 표 2.8에서처럼 MIME은 7개의 데이터 유형을 허용한다.
내용 전달 인코딩(Content-Transfer-Encoding): 이 헤더는 전송을 위해 메시지를 0과 1로 인코딩하는 방법을 정의한다. 표 2.9에 인코딩의 다섯 가지 종류가 나열되어 있다.

마지막 두 개의 인코딩 방법이 흥미롭다. Base 64는 연속된 비트로 이루어진 2진 데이터를 먼저 6비트의 문자열의 청크로 나눈다.
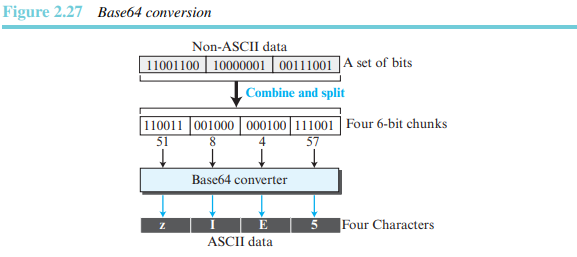
각 6비트 청크는 표 2.10에 따라 하나의 문자로 해석된다.
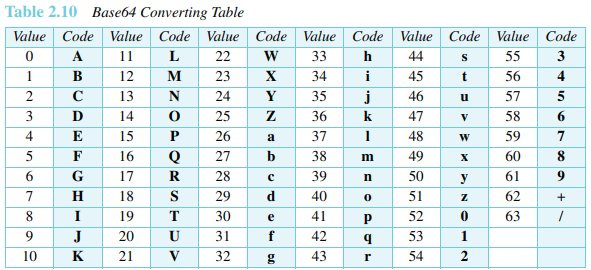
Base64는 남는 정보를 보내는 인코딩 방식이다. 즉 매 6비트마다 한 개의 문자가 되고, 최종적으로 8비트가 전송된다. 이것은 25퍼센트의 오버헤드를 유발한다. 만일 데이터가 대부분의 ASCII 문자와 소수의 ASCII가 아닌 부분으로 구성되어 있다면, Quoted-printable 인코딩을 사용할 수 있다. Quoted-printable에서 ASCII 문자는 있는 그대로 전송된다. ASCII가 아닌 문자는 세 개의 문자로 인코딩되어 전송된다. 첫 번째 문자는 등호(=)이다. 그 다음 두 개의 문자들은 해당 바이트의 16진수 표현이다. 그림 2.28에 예를 보였다. 세 번째 문자는 ASCII가 아니다. 그 이유는 첫 바이트가 1로 시작하였기 때문이다. 이는 3개의 ASCII 문자들(=, 9, D)로 교체된 두 개의 16진수()으로 해석된다.
내용 Id(Content-Id): 이 헤더는 여러 개의 메시지가 있는 상황에서 전체 메시지를 유일하게 식별한다.
내용 기술(Content-Description): 이 헤더는 본문이 사진인지, 소리인지, 영상인지를 정의한다.
웹 기반 이메일
이메일은 오늘날 몇몇 웹사이트들이 사이트를 액세스하는 모든 이에게 이 서비스를 제공하는 아주 일반적인 응용이 되었다. 개념은 아주 단순하며, 두 가지 경우를 그림 2.29에 보였다.
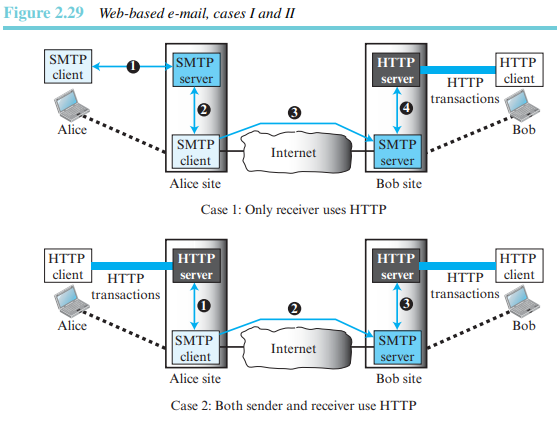
- 경우 1
송신자 앨리스는 전통적인 메일 서버를, 수신자 밥은 웹기반 서버에 계정을 갖고 있다. 앨리스의 브라우저로부터 그녀의 메일 서버까지의 이메일 전송은 SMTP를 통해 수행된다. 송신 메일 서버로부터 수신 메일 서버로까지의 메시지 전달도 SMTP를 통해 수행된다. 그러나 수신 서버(웹 서버)로부터 밥의 브라우저까지 메시지는 HTTP를 통해 전달된다. - 경우 2
밥과 앨리스는 웹 서버를 사용하지만 같은 서버일 필요는 없다. 앨리스는 HTTP 트랜잭션을 사용헤 웹 서버로 메시지를 보낸다. 앨리스는 밥의 메일함의 이름과 주소를 URL로 사용하여 그녀의 웹 서버에 HTTP 요청을 보낸다. 앨리스의 서버는 SMTP 클라이언트에게 메시지를 전달하고, 그것을 SMTP 프로토콜을 사용하여 밥의 사이트에 있는 서버로 전송한다. 밥은 HTTP 트랜잭션을 이용해 메시지를 수신한다. 그러나 앨리스의 서버에서 밥의 서버로 온 메시지는 여전히 SMTP 프로토콜을 사용 중이다.
2.3.5 SSH
SSH는 원격로깅과 파일전송 등을 목적으로 하는 안전한 응용프로그램이다. SSH에는 두 가지 버전이 있다. 각각 SSH-1과 SSH-2이며 둘은 전혀 호환되지 않는다. 처음 버전인 SSH-1은 그 자체에 결함이 있어 지금은 사용되지 않는다.
컴포넌트
SSH는 그림 2.32에서와 같이 4개의 컴포넌트를 가지도록 제안된 응용 계층 프로토콜이다.
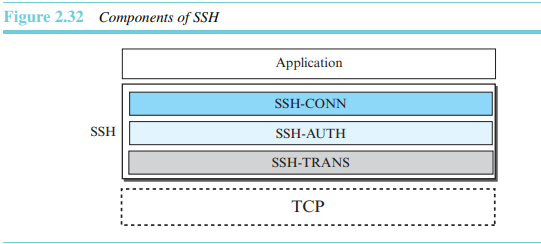
- SSH 전송 계층 프로토콜(SSH-TRANS)
TCP가 안전한 전송 계층 프로토콜이 아니므로 SSH는 먼저 TCP상에 안전한 채널을 생성하는 프로토콜을 사용한다. 이 새로운 계층은 SSH-TRANS라 불리는 독립적인 프로토콜이다. 이 프로토콜을 구현한 프로시저가 호출될 때, 클라이언트와 서버는 우선 TCP 프로토콜을 사용하여 안전하지 않은 연결을 맺는다. 그 후 TCP상에 안전한 채널을 설정하기 위해 몇 가지 보안 변수들을 교환한다. 이 프로토콜이 제공하는 서비스 몇 가지를 나열하자면
- 교환되는 메시지의 기밀성과 비밀성
- 데이터 무결성
- 서버의 인증. 이는 클라이언트가 자신이 제대로 된 서버와 통신하고 있음을 확신하게 함
- 시스템의 효율을 개선하고 공격을 더 어렵도록 만드는 메시지의 압축
- SSH 인증 프로토콜(SSH-AUTH)
클라이언트와 서버 간에 안전한 채널이 설정되고 클라이언트에 대해 서버 인증이 이루어진 후 SSH는 서버에 대해 클라이언트를 인증하는 소프트웨어를 호출할 수 있다. SSH의 클라이언트 인증 절차는 SSL(Secure Socket Layer)와 매우 유사하다. 클라이언트의 인증은 서버에게 메시지를 요구할 때 시작된다. 이 요구 메시지에는 사용자 이름, 서버 이름, 인증 방법 그리고 요구한 데이터가 포함된다. 서버는 클라이언트가 인증되었음을 확인하는 성공 메시지로 응답하거나, 새로운 요청 메시지로 과정을 반복해야 한다는 실패 메시지로 응답한다. - SSH 연결 프로토콜(SSH-CONN)
안전한 채녈이 설정되고 서버와 클라이언트 간에 상호 인증이 이루어진 뒤 SSH는 세 번째 프로토콜인 SSH-CONN을 구현한 SW의 일부를 호출할 수 있다. SSH-CONN 프로토콜에 의해 제공되는 서비스 중의 하는 다중화 수행이다. SSH-CONN은 앞선 두 프로토콜에 의해 설정된 안전한 채널을 취해서 그 위에 복수의 논리 채널들을 클라이언트로 하여금 설정할 수 있게 한다. 각 채널들은 서로 다른 목적으로 사용된다. 예를 들어 원격 로그인, 파일 전송 등이다. - 응용프로그램들
원격 로그인을 위해 몇몇의 상업적인 응용프로그램들이 SSH를 사용한다. 예를 들면 PuTTy, Tsctia 등이다. - 파일 전송을 위한 SSH
SSH 위에서 생성되어 파일전송을 수행하는 응용프로그램 중 하나는 SFTP이다. SFTP 응용프로그램은 파일을 전송하기 위해 SSH에 의해 제공되는 여러 채널 중의 하나를 사용한다. 또 다른 하나는 SCP(Secure Copy)이다.
포트 전달
SSH 프로토콜이 제공하는 흥미로운 서비스 중의 하나는 포트 전달(port forwarding)이다. 보안 서비스를 제공하지 않는 응용프로그램에 접속하기 위해서 SSH에서 이용 가능한 안전한 채널을 사용할 수 있다. TELNET 및 SMTP와 같은 응용에서 SSH의 포트 전달 서비스를 사용할 수 있다. SSH 포트 전달 방법은 다른 프로토콜에 속한 메시지가 지나가는 터널을 생성하는 것이다. 이런 이유로 이 방법을 때때로 SSH 터널링이라 부른다.
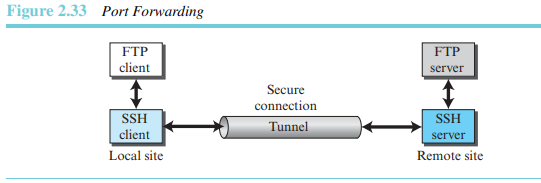
로컬상의 FTP 클라이언트는 원격상에 위치한 SSH 서버와 안전한 연결을 맺기 위해 SSH 클라이언트는 사용할 수 있다. FTP 클라이언트에서 FTP 서버로의 어떠한 요청도 SSH 클라이언트와 서버가 제공하는 터널을 통해 전달된다. 그 반대도 마찬가지다.
SSH 패킷의 형식
그림 2.34는 SSH 프로토콜에 의해 사용되는 패킷의 형식을 보여 준다.
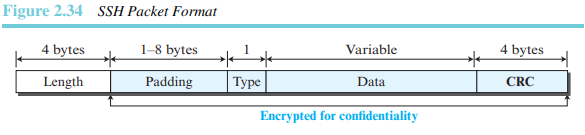
필드의 길이는 패딩을 포함하지 않는 패킷의 길이를 나타낸다. 1에서 8바이트의 패딩을 패킷에 추가하여 공격을 더 어렵게 만든다. CRC(cyclic redundancy check) 필드는 오류 점검을 위해 사용된다. 유형은 SSH 프로토콜에 의해 사용되는 패킷의 유형을 정의한다. 데이터 필드는 다른 프로토콜의 데이터에 의해 전송되는 데이터이다.
2.3.6 DNS
TCP/IP 프로토콜은 개체를 구분하기 위해 호스트에서 인터넷으로의 연결을 유일하게 식별하는 IP 주소를 사용한다. 그러나 사람들은 숫자로 된 주소보다는 이름 사용을 선호한다. 그러므로 인터넷은 이름과 주소를 매핑할 수 있는 디렉터리 시스템이 필요하다.
오늘날 인터넷은 매우 광범위하므로 하나의 중앙 디렉터리 시스템은 모든 매핑을 수행할 수 없다. 게다가 만약 중앙 컴퓨터가 무너질 경우, 전체 통신 네트워크는 무너질 것이다. 더 나은 해결책은 정보를 전세계의 많은 컴퓨터에 분산하는 것이다. 이 방법에서 각 호스트들은 매핑이 필요할 경우 필요한 정보를 가진 가장 가까운 컴퓨터와 통신할 수 있다. 이 방법은 DNS에 의해 사용된다.
그림 2.35는 TCP/IP에서 어떻게 DNS 클라이언트와 DNS 서버를 사용하여 이름을 주소로 매핑하는지를 보인다. 사용자는 원격 호스트에서 동작하는 파일 전송 서버에 접근하기 위하여 파일 전송 클라이언트를 사용하고자 한다. 사용자는 afileresource.com 과 같은 파일 전송 서버 이름만 알고 있다. 그러나 TCP/IP 집합은 연결을 설정하기 위해 파일 전송 서버의 IP 주소를 알아야만 한다. 다음의 여섯 절차가 호스트 이름을 IP 주소로 매핑하도록 한다.
1. 사용자는 호스트 이름을 파일 전송 클라이언트에 전달한다.
2. 파일 전송 클라이언트는 호스트 이름을 DNS 클라이언트에 전달한다.
3. 각 컴퓨터는 부팅된 후 하나의 DNS 서버 주소를 안다. DNS 클라이언트는 알려진 DNS 서버의 IP 주소를 사용하여 DNS 서버에게 메시지와 파일 전송 서버의 이름을 쿼리로 전송한다.
4. DNS 서버는 원하는 파일 전송 서버의 IP 주소를 응답한다.
5. DNS 클라이언트는 IP 주소를 파일 전송 클라이언트에 전달한다.
6. 파일 전송 클라이언트는 수신한 IP 주소를 사용하여 파일 전송 서버에 접속한다.
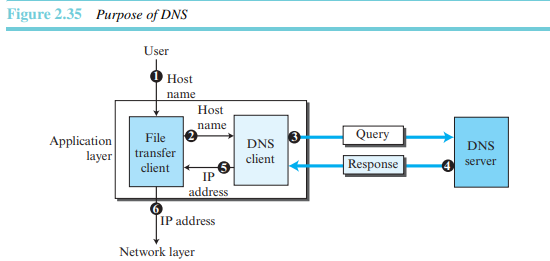
인터넷 접속의 목적이 파일 전송 클라이언트와 서버 간에 연결을 맺는 것이지만, 그 전에 일어나야 할 것이 DSN 클라이언트와 DNS 서버 간의 연결이라는 점을 주의할 필요가 있다. 즉 두 가지 연결이 필요한 것이다.
2.4 피어-대-피어 패러다임
2.4.1 피어-대-피어 네트워크
자신들의 자원을 공유하려는 인터넷 유저들은 피어가 되어 네트워크를 이룬다. 네트워크 내의 한 피어가 공유할 어떠한 파일을 갖고 있을 때, 나머지 피어들도 그것을 이용할 수 있다. 관심이 있는 피어는 직접 그 파일이 있는 컴퓨터에 접속하여 다운로드할 수 있다. 피어가 파일을 다운로드한 후, 다른 피어들도 그 파일을 다운로드가 가능하다. 더 많은 피어들이 접속하여 파일을 다운로드함에 따라 더 많은 파일의 복사본이 그 그룹에 의해 이용될 수 있다. 피어들의 숫자가 증가 또는 감소할 수 있으므로 파일의 위치정보와 피어들의 기록을 어떻게 유지할지가 문제이다. 이 문제를 해결하기 위해, 피어-대-피어 네트워크를 두 개의 범주인 중앙집중화된 네트워크와 분산화된 네트워크로 나눈다.
중앙집중형 네트워크
중앙집중형 피어-대-피어 네트워크에서 디렉터리 시스템은 (피어들과 그들이 제공하는 것들을 열거하는)클라이언트-서버 개념을 사용한다. 그러나 파일들의 저장과 다운로딩은 피어-대-피어 개념을 사용하여 처리한다. 이러한 이유로 중앙집중형 피어-투-피어 네트워크는 하이브리드 피어-투-피어 네트워크로 불린다. Napster는 이 형식의 예이다. 이 유형의 네트워크에서 하나의 피어는 처음에 중앙서버에 자신을 등록한다. 그 다음 자신의 IP 주소들과, 공유해야만 하는 파일들의 리스트를 제공한다.
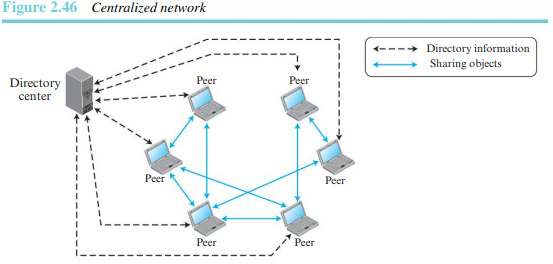
하나의 특정한 파일을 찾는 피어는 하나의 질의를 중앙 서버에 보낸다. 그 서버는 그것의 디렉터리를 검색하고 그 파일의 복사본을 소유하고 있는 노드들의 주소들을 가지고 응답한다. 피어는 그 노드들 중 하나에 접속하여 그 파일을 다운로드한다. 디렉터리는 노느들이 참여하거나 그 피어를 떠남에 따라서 지속적으로 업데이트된다.
중앙집중형 네트워크들은 디렉터리의 유지를 쉽게 하는 반면에 몇 가지 장애를 가진다. 디렉터리에서의 접근은 거대한 트래픽을 생성할 수 있으며 시스템을 느리게 할 수 있다. 중앙 서버들은 공격에 약하며, 만약 그들 모두가 실패한다면 전체 시스템이 중단될 것이다.
분산형 네트워크
분산적 피어-대-피어 네트워크는 중앙집중형 디렉터리 시스템에 의존하지 않는다. 이 모델에서 피어들은 그들 스스로를 오버레이 네트워크에 할당한다. 이것은 물리 네트워크의 최상위 부분에 만들어진 논리적 네트워크이며, 해시함수를 사용한다. 오버레이 네트워크에서 노드들이 링크되는 방법에 따라 분산된 피어-대-피어 네트워크는 비구조적 또는 구조적으로 구분된다.
- 비구조적 네트워크
비구조적 피어-대-피어 네트워크에서 노드들은 랜덤하게 링크되어진다. 비구조적 피어-대-피어 네트워크에서 검색은 매우 효율적이지 못하다. 그 이유는 하나의 파일을 찾기 위한 질의는 네트워크를 통해 플러딩(flooding)되어야 하기 때문이다. 이것은 상당한 트래픽을 생성함에도 불구하고 그 질의는 처리되지 않을 수 있다. - 구조적 네트워크
구조적 네트워크는 질의가 효과적이고 효율적으로 처리될 수 있도록 노드들을 링크하기 위해 미리 정의된 룰들을 사용한다. 이 목적을 위해 사용되는 가장 공통적인 테크닉은 분산 해시 테이블(DHT)이다. DHT는 분산 데이터 구조, 컨텐츠 분산시스템들, DNS를 포함한 많은 응용들에서 사용된다.
2.4.2 분산 해시 테이블
몇 개의 미리 정의된 규칙들에 따라 노드들의 세트 사이에서 데이터를 분배(또는 참조)한다. DHT 기반의 네트워크에서의 각 피어는 데이터 아이템들의 범위에 대한 책임을 가지게 된다. 비구조적 피어-대-피어 네트워크들에서 논의했던 플러딩 오버헤드 문제를 피하기 위해서 DHT 기반의 네트워크들은 각 피어의 전체 네트워크에 대한 부분적 지식을 가지게 한다. 이 지식은 데이터 아이템들에 관한 질의를 효과적이고 확장성 있는 절차들을 사용하여 대응하는 노드들에게 라우팅하기 위한 용도로 사용되어진다.
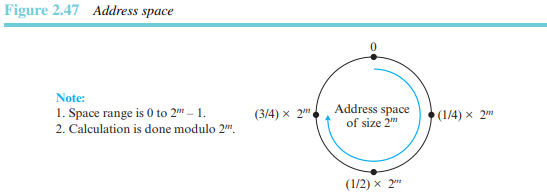
주소 공간
DHT 기반의 네트워크에서 각 데이터 아이템과 피어는 크기의 큰 주소 중 하나의 포인트에 매핑된다. 이 주소 공간은 모듈로 계산법을 사용하여 디자인되었다. 이것은 그림 2.47에서 보이는 바와 같이 시계방향으로 도는 개수의 포인트(0에서 -1)를 가지는 하나의 원 위에서 공평하게 분산된 주소 공간 안의 포인트들을 의미한다. DHT를 구현할 때는 대부분 =160을 사용한다.
-
해싱 피어 식별자
DHT 시스템을 만드는 첫 번째는 모든 피어들을 주소 공간 링에 두는 것이다. 이것은 보통 피어 식별자를 -bit 정수로 해시하는 해시함수를 사용하여 처리한다. 피어 식별자는 주로 IP 주소가 사용되며 해시된 -bit 정수는 노드 ID로 불린다.DHT는 충돌에 강한 안전한 해시 알고리즘(SHA, Secure Hash Algorithm)과 같은 몇몇의 암호학적 해시함수들을 사용한다. 이것은 2개의 입력이 같은 출력으로 매핑될 확률이 매우 낮다는 것을 의미한다.
-
해싱 객체 식별자
공유되는 객체(예: 하나의 파일)의 이름은 또한 같은 주소 공간에서 하나의 -bit 정수로 해시되어진다. 이 결과는 DHT 용어 키로 불린다.DHT에서 하나의 객체는 보통 키와 값의 쌍과 연관되어 있으며 키는 객체이름의 해시이며 값은 객체 또는 객체의 참조값이다.
-
객체 저장
객체를 저장하기 위한 두 가지 전략으로 직접적 방식과 간접적 방식이 존재한다. 직접적 방식에서 객체는 노드ID가 링 안의 키값과 최대한 '가까운' 노드에 저장된다. '가까운'이라는 용어는 각 프로토콜마다 다르게 정의되어진다. 그러나 대부분의 DHT 시스템들은 효울성 때문에 간접적 방식을 사용한다. 객체를 소유하는 그 피어는 그 객체를 계속 가지고 있지만 객체에의 참조는 키포인트에 '가까운' ID를 가진 노드에서 만들어지고 저장된다. 다시 말해서 객체의 물리 객체와 참조는 두 개의 서로 다른 장소들에 저장된다. 직접적 방식에서는 객체를 저장하는 노드ID와 객체의 키값 사이에서의 관계를 생성한다. 반면에 간접적 방식에서는 객체의 참조와 참조를 저장하는 노드 사이에서의 관계를 형성한다. 이들 중 하나의 상황에서 만약 객체의 이름이 주어진다면 그 관계는 객체를 찾기 위해 필요했던 것이다. 남은 절에서는 간접적 방식을 사용한다.
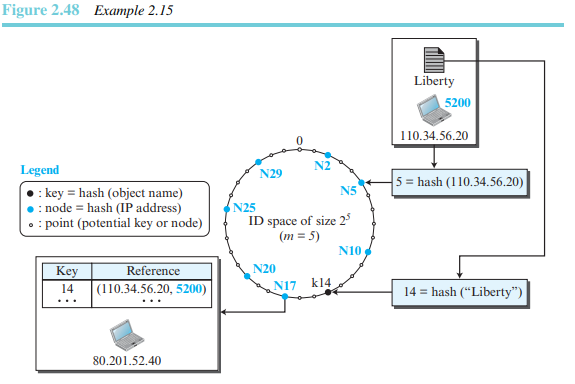
예제 2.15
통상적인 의 값이 160이긴 하지만 여기선 =5를 사용한다. 그림 2.48에서 우리는 여러 개의 피어들이 이미 그룹에 참여한 상태임을 가정한다. IP 주소 110.35.56.20을 가진 노드 N5는 그것의 피어들과 공유하기 원하는 Liberty라는 이름의 파일을 가진다. 그 노드는 key=14를 얻기 위해 파일 이름 'Libety'를 해시한다. key 14에 가까운 노드는 N17이기 때문에 N5는 파일 이름(key), IP 주소, 포트번호에 대한 참조를 생성한다. 그리고 노드 N17에 저장될 이 참조를 전송한다. 다시 말해서 그 파일은 N5에 저장되고 그 파일의 key는 14인 것이다. 그러나 그 파일의 참조는 N17에 저장된다. 어떻게 다른 노드들이 먼저 N17을 찾고 그 참조를 추출한 다음에 파일 Liberty에 접속하기 위해 참조를 사용하는지를 뒤에서 보게 될 것이다. 이 예제는 링 위에서 오직 한 개의 키만을 사용하지만 실제 상황에서는 링 안에 수천만 개의 키들과 노드들이 존재한다.
Liberty 파일을 N5에서 공유, Liberty의 해쉬값은 14,가까운 노드는 N17 , N17에 파일 참조 포인트 저장, 다른 노드에서는 Liberty 해쉬값 14 추출, 가까운 N17에 접속해서 파일 포인트를 가져옴 ,N5에 접속해서 실제 파일 접근
-
라우팅
DHT의 주요한 기능은 객체의 참조를 저장하는 책임을 가지는 노드에게 질의를 라우팅하는 것이다. 각 DHT 구현은 라우팅을 위해 각기 다른 방식을 사용하지만, 모두 '각 노드는 하나의 질의를 대응하는 노드와 가까운 노드에 라우팅하기 위해 링에 대한 부분적 지식을 가져야 한다' 라는 아이디어를 따른다. -
노드들의 출현과 이탈
피어-대-피어 네트워크에서 각 피어는 켜지거나 꺼질 수 있는 데스크탑이나 컴퓨터가 될 수 있다. 하나의 컴퓨터 피어가 DHT 소프트웨어를 시작할 때 그것은 네트워크에 참여된다. 마찬가지로 컴퓨터가 꺼지거나 SW를 종료시킬 경우 네트워크와 끊긴다. DHT 구현은 노드들의 출현과 이탈 그리고 남은 피어들에 미칠 영향을 다루기 위한 명확하고 효율적인 전략을 가질 필요가 있다. 대부분의 DHT 구현들은 노드의 실패를 이탈로 간주한다.
3. 전송계층
3.1 개요
전송계층은 네트워크 계층과 응용 계층 사이에 위치한다. 전송계층은 두 응용계층 사이에서의 프로세스-대-프로세스 통신을 제공하는데, 하나는 로컬 호스트이고 다른 하나는 원격 호스트이다.
3.1.1 전송 계층 서비스
전송 계층에서 제공하는 서비스에 대해 알아본다.
프로세스-대-프로세스 통신
전송계층 프로토콜의 첫 번째 임무는 프로세스-대-프로세스 통신을 제공하는 것이다. 프로세스는 전송계층의 서비스를 이용하는 응용계층 객체이다. 프로세스-대-프로세스 통신이 어떻게 제공되는지를 살펴보기 전에 먼저 호스트 대 호스트 통신과 프로세스-대-프로세스 통신의 차이에 대해 이해할 필요가 있다.
네트워크 계층은 컴퓨터 레벨에서의 통신에만 책임이 있다. 네트워크 계층 프로토콜은 목적지 컴퓨터에서만 메시지를 전송한다. 그렇지만 이것만으로 전송이 완료되었다고는 할 수 없다. 메시지는 올바른 프로세스에서 처리되어야 한다. 이것이 전송계층 프로토콜이 수행해야 할 임무이다. 전송계층 프로토콜은 메시지를 적절한 프로세스로 전송할 책임이 있다.
주소체계: 포트번호
전송계층에서 프로세스를 식별하기 위해서는 포트번호가 필요하다. 클라이언트 프로세스는 임시 포트번호(ephemeral port number)라고 하는 임의의 포트번호로 자신을 지정한다. 임시(ephemeral)라는 단어는 단명한다는 것을 의미하며 이것은 클라이언트의 수명이 일반적으로 짧기 때문이다. 클라이언트/서버 프로그램이 원활히 동작하기 위해서 임시 포트번호는 1,023보다 크게 지정하도록 한다.
서버 프로세스도 포트번호로 자신을 지정해야 한다. 그렇지만 서버 포트번호를 임의로 지정할 수는 없다. 만일 서버가 임의의 번호를 포트번호로 지정한다면, 클라이언트 프로세스는 서버의 포트번호를 알 수가 없기 때문이다. 따라서 TCP/IP는 서버를 위해 범용 포트번호를 사용하기로 결정하였고, 이를 잘 알려진 포트번호(well-known port number)라 한다. 여기에는 몇가지 예외가 있다. 예를 들어 잘 알려진 포트번호가 할당된 클라이언트도 있다. 모든 클라이언트 프로세스는 대응되는 서버 프로세스의 잘 알려지니 포트번호를 알고 있다. 예를 들어 daytime 클라이언트 프로세스는 임시 포트번호 52,000을 사용할 수 있지만 daytime 프로세스는 잘 알려진 포트번호 13을 사용해야 한다.
ICANN 범위
ICANN은 그림 3.5처럼 포트번호를 잘 알려진, 등록된, 동적(또는 개인)의 세 범위로 나누었다.

- 잘 알려진 포트: 0과 1,023 범위 내의 포트는 ICANN에 의해 배정되고 제어된다.
- 등록된 포트: 1,024에서 49,151 사이의 포트는 ICANN에 의해 배정되거나 제어되지 않는다. 그러나 중복을 피하기 위해 ICANN에 등록될 수는 있다.
- 나머지 번호의 포트는 제어되거나 등록되지 않는다. 이들은 임시 또는 개인 포트번호로서 사용될 수 있다.
캡슐화와 역캡슐화
다중화와 역다중화
흐름 제어
하나의 개체가 정보를 생성하고 다른 개체가 정보를 소비할 때마다 생성률과 소비율 간에 균형이 이루어져야 한다. 만일 정보가 소비되는 속도보다 더 빨리 생성된다면, 소비 측에서는 데이터가 과도하게 수신되어 정보의 일부가 손실될 수 있다. 반면 정보가 소비되는 속도보다 더 늦게 생성되면, 소비 측에서는 정보의 수신을 기다리게 되어 시스템이 덜 효율적으로 작동할 것이다. 흐름 제어는 첫 번째 문제와 연관된다. 즉 소비차 측에서의 정보 손실을 방지할 필요가 있다.
-
밀기와 끌기
정보를 생산자로부터 소비자로 배달하는 방법은 밀기와 끌기의 두 방법 중의 하나로 이루어질 수 있다. 소비자로부터 선요구 없이 정보가 생성될 때마다 전송측에서 정보를 전달하는 경우의 배달을 밀기라고 한다. 반면 소비자가 요구한 경우에만 생산자가 정보를 배달하는 경우를 끌기라고 한다.
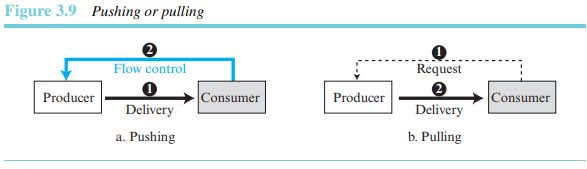
생산자가 밀기 방식으로 정보를 전달하면, 소비자는 정보의 과도한 수신에 직면할 수 있다. 따라서 정보의 손실을 방지하기 위하여 반대 방향으로의 흐름 제어가 필요하다. 끌기 방식에서는 소비자가 수신할 준비가 되면 생산자에게 정보를 요청한다. 이 경우 흐름 제어는 필요 없다. -
전송 계층에서의 흐름 제어
전송 계층에서의 통신을 위하여 송신 프로세스, 송신 전송 계층, 수신 전송 계층, 그리고 수신 프로세스 등 네 개의 개체가 필요하다. 응용 계층에서의 송신 프로세스는 단순한 생산자이다. 송신 프로세스는 메시지를 생산하고 밀기 방식을 이용하여 전송 계층으로 전송한다. 송신 전송 계층은 소비자와 생산자의 두 가지 임무를 수행한다. 수신 전송 계층 또한 두 가지 임무를 수행한다. 수신 전송 계층은 송신측으로부터 전송된 계층을 소비하고, 메시지를 역캡슐화하고 응용 계층으로 전달한다. 마지막 전송 방법은 끌기 방식으로 이루어진다.
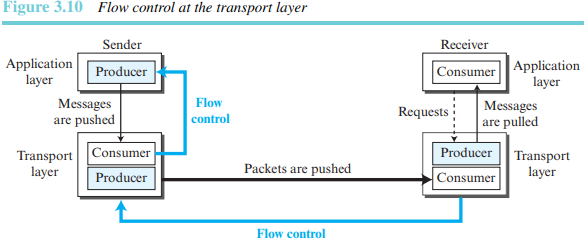
-
버퍼
흐름 제어를 구현하는 방법으로 버퍼가 있다. 송신측과 수신측에서의 패킷을 저장할 수 있는 일련의 메모리 영역으로, 송신 전송 계층에 하나, 수신 전송 계층에 또 하나가 있다.
송신 전송 계층의 버퍼가 가득 차면, 송신 전송 계층은 메시지 청크 전달을 멈추도록 송신 응용 계층에게 알린다.
수신 전송 계층의 버퍼가 가득 차면, 수신 전송 계층은 패킷의 전송을 멈추도록 송신 전송 계층에게 알린다.
오류 제어
네트워크 계층은 신뢰성을 제공하지 않으므로 전송 계층이 신뢰성을 제공할 수 있어야 하는데, 이는 전송 계층에 오류 제어 서비스를 추가하므로써 제공할 수 있다. 전송 계층의 오류 제어에서 제공하는 기능은 다음과 같다.
1) 훼손된 패킷의 감지 및 폐기
2) 손실되거나 제거된 패킷을 추적하고 재전송
3) 중복 수신 패킷을 확인하고 폐기
4) 손실된 패킷이 도착할 때까지 순서에 어긋나게 들어온 패킷을 버퍼에 저장
흐름 제어와는 다르게 오류 제어에는 송신 전송계층과 수신 전송계층만이 관여한다. 그림 3.11은 송신과 수신 전송계층간의 오류 제어를 보여준다. 흐름 제어와 마찬가지로 수신 전송계층은 문제점에 대해서 송신 전송 계층에 알림으로써 오류 제어를 수행한다.

- 순서 번호
오류 제어가 수행되기 위해서 송신 전송계층은 어떤 패킷이 재전송되어야 하는지를 알아야 한다. 또한 수신 전송계층은 어떤 패킷이 중복되었는지 또는 어떤 패킷이 순서에 어긋나게 도착했는지를 알아야 한다. 이는 패킷이 번호를 가지면 된다. 패킷의 순서 번호를 저장할 수 있도록 전송 계층 패킷에 한 필드를 추가하는 것이다.
패킷에는 일련번호가 매겨진다. 그렇지만 헤더 안에 각 패킷의 순서 번호를 포함하기 위해서는 최대값이 설정되어야 한다. 만일 패킷의 헤더에 순서 번호를 위해서 비트가 설정된다면, 순서 번호는 0에서 값의 범위를 가진다. 예를 들어 = 4인 경우에는 순서 번호는 0부터 15 사이의 값이 된다. 다시 말하면 순서 번호는 modulo 이다.오류 제어에서 순서 번호는 modulo 이며, 여기서 은 순서 번호 필드의 크기이다.
- 확인응답
응답 신호는 긍정이거나 부정일 수 있다. 수신자는 패킷이 잘 수신된 경우 ACK를, 잘못 수신되거나 타임아웃이 일어난 경우엔 NACK를 송신자에게 전송한다. 수신측에서는 중복 수신된 패킷은 폐기하고, 순서에 어긋나게 들어온 패킷은 폐기하거나 버퍼에 저장한다.
흐름과 오류 제어의 결합
송신측에 하나 그리고 수신측에 하나가 있는 두 개의 버퍼에 번호가 매겨지면 위의 두 제어 기능이 결합될 수 있다.
전송할 패킷이 있는 송신측은 패킷의 순서 번호로서 버퍼 내의 비어있는 영역의 제일 앞 부분의 번호인 를 사용한다. 패킷이 전송되면 패킷의 복사본은 메모리 영역 에 저장되며 상대방으로부터 확인응답을 기다린다. 전송된 패킷에 대한 확인응답이 도착하면, 패킷의 복사본은 제거되고 메모리 영역은 비워진다.
수신측에 순서 번호 를 갖는 패킷이 도착하면, 수신측은 응용계층에서 수신할 준비가 되기 전까지는 수신된 패킷을 메모리 영역 에 저장한다. 그리고 패킷 의 도착을 알리기 위해 확인응답이 전송된다.
- 슬라이딩 윈도우
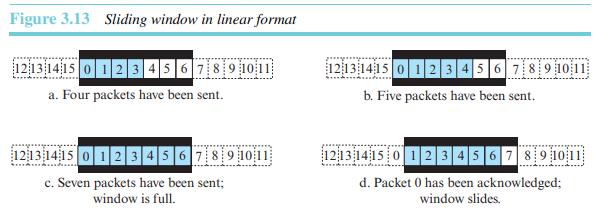
순서 번호가 modulo 을 사용하기 때문에 0부터 까지의순서 번호를 원형으로 표현할 수 있다.(그림 3.12) 버퍼는 슬라이딩 윈도라고 하는 일련의 조각으로 표현되며, 각 조각들은 언제나 원형의 일부분을 점유한다. 송신측에서 패킷이 전송되면 관련 조각이 마크된다. 모든 조각이 마크된다는 것은 버퍼가 다 차서 더 이상의 메시지를 응용 계층으로부터 수신할 수 없다는 것을 의미한다. 확인응답이 수신되면 해당 조각의 마크는 해제된다. 윈도의 시작부터 몇 개의 연속적인 조각의 마크가 해제되면, 윈도의 끝에서 좀 더 많은 빈 조각을 허용하기 위해 윈도를 관련 순서 번호 범위로 미끄러지듯이 돌린다. 그림 3.12는 송신측의 윈도다. 순서 번호는 modulo 16이며 윈도 크기는 7이다.
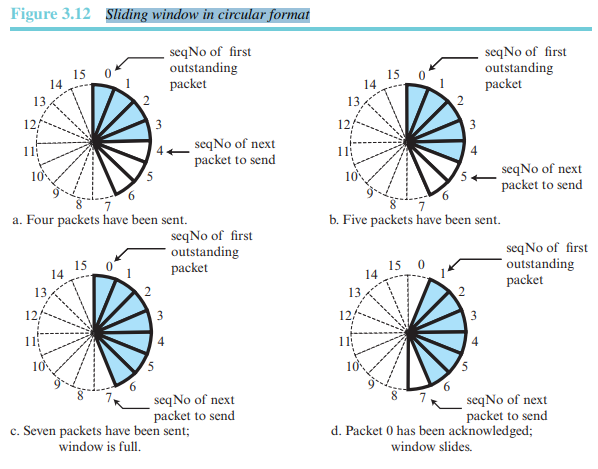
대부분의 프로토콜에서는 선형으로 윈도를 표현한다.
- 혼잡 제어
혼잡(congestion)은 인터넷과 같은 패킷 교환 네트워크에서 중요한 문제이다. 네트워크로 전송되는 패킷의 수를 나타내는 네트워크의 부하 가 네트워크에서 처리할 수 있는 패킷의 수를 나타내는 네트워크의 용량 을 초과하는 경우에 혼잡이 발생한다. 혼잡 제어(congestion control)는 혼잡을 제어하고 로드가 용량보다 작도록 하기 위한 메커니즘과 기술들이다.
혼잡은 왜 발생하는가? 혼잡은 대기(waiting)을 포함하는 어떠한 시스템에서도 발생한다. 예를 들어 혼잡 시간 동안에 사고와 같은 비정상적인 상황으로 인하여 정체가 발생하는 고속도로가 있다.
네트워크나 인터넷에서의 혼잡은 라우터나 스위치가 패킷을 저장하기 위한 버퍼인 큐를 가지고 있기 때문에 발생한다. 예를 들어, 라우터는 각각의 인터페이스에 입출력 큐를 가지고 있다. 만약 라우터에 도착하는 패킷들을 처리할 수 없으면 큐는 과부하가 되며 혼잡이 발생한다. 전송 계층의 혼잡은 사실 네트워크 계층에서 발생한 혼잡이 전송 계층에서 나타나는 것이다.
비연결형과 연결 지향 서비스
네트워크 계층 프로토콜과 마찬가지로 전송 계층 프로토콜도 비연결형(connectionless)과 연결형(connection-oriented)의 두 가지 형태의 서비스를 제공한다. 그렇지만 전송 계층에서의 이러한 서비스는 네트워크 계층의 것과는 본질적으로 다르다. 네트워크 계층에서의 비연결형 서비스는 동일한 메시지에 속하는 서로 다른 데이터그램이 서로 다른 경로를 거칠 수 있다는 것을 의미한다. 전송계층에서는 패킷의 물리 경로에 대해서는 관여하지 않는다. 전송 계층에서의 비연결형 서비스는 패킷 간의 독립성을 의미하며, 연결 지향은 종속성을 의미한다.
- 비연결형 서비스
논리적 연결을 만들지 않으며, 일정한 경로를 통해 패킷이 전송되지 않는다. 또한 패킷의 도착 순서가 보장되지 않는다. - 연결 지향 서비스
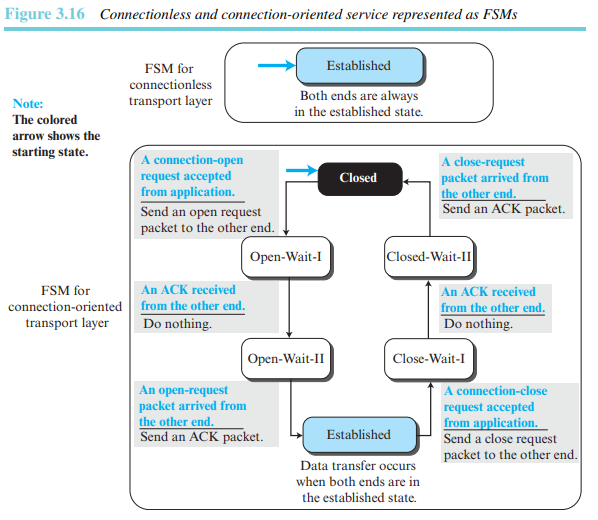
네트워크에서의 연결 지향 서비스는 두 개의 종단 호스트와 그 사이에 있는 모든 라우터들 간의 협력을 의미한다. 전송 계층에서의 연결 지향 서비스는 단지 두 개의 종단 호스트만을 포함하며, 서비스는 종단에서만 이루어진다(즉 네트워크상의 경로가 일정하다는 보장이 없다). 즉 이것은 비연결형 또는 연결 지향 서비스 위에서 연결 지향 프로토콜을 구현할 수 있어야 한다는 것을 의미한다. - 유한상태기계
- 안전 전송을 위한 기능
- 시퀀스번호
- 수신응답(ACK)
- 버퍼 크기
- 타이머
- 재전송
- 흐름제어, 오류제어
- 슬라이딩 윈도우
3.2 전송 계층 프로토콜
앞의 전송 계층 서비스들을 결합하여 전송 계층 프로토콜이 어떻게 만들어지는지 보자.
3.2.1 단순 프로토콜
첫 번째 프로토콜은 흐름 제어나 오류 제어가 없는 단순 비연결형 프로토콜이다. 이 프로토콜에서 수신측은 수신한 패킷을 즉시 처리할 수 있다고 가정한다. 다시 말하면 수신측에서는 과도한 패킷의 수신으로 인한 버퍼 초과가 발생하지 않는다.
FSM은 다음과 같다. ready 상태만을 가진다.
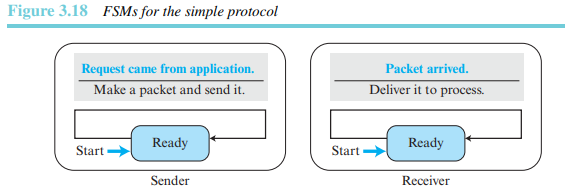
송신측에서는 수신측을 고려하지 않고 하나씩 패킷을 전송한다.
3.2.2 Stop-and-Wait 프로토콜
흐름 제어와 오류 제어를 모두 사용하는 연결 지향 프로토콜이다. 송신측과 수신측은 모두 크기가 1인 슬라이딩 윈도를 사용한다. 송신측은 한 번에 하나의 패킷을 전송하고 확인응답이 들어오기 전까지는 다음 패킷을 전송하지 않는다. 패킷이 훼손되었는지를 검사하기 위하여 각각의 패킷에 체크섬을 추가한다. 수신측은 패킷의 검사합이 틀리면 조용히 패킷을 버린다. '조용'이라는 것은 송신측에게 패킷이 훼손되었거나 손실되었다는 신호이다. 송신측은 패킷을 전송할 때마다 타이머를 구동하며, 타이머가 만료되면 패킷을 재전송한다. 이를 위해서 송신측은 확인응답이 도착하기 전까지는 전송한 패킷의 사본을 가지고 있어야 한다. 그림 3.20은 전송 대기 프로토콜의 개괄적 동작이다. 채널에는 한 번에 하나의 패킷과 하나의 확인응답만이 전송될 수 있다.
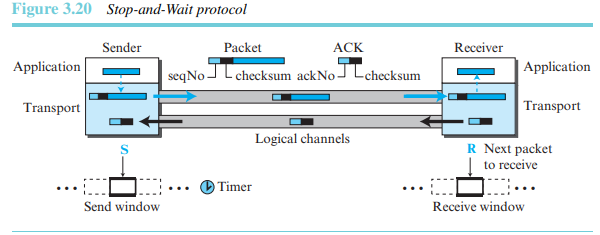
Stop-and-Wait 프로토콜은 흐름 제어와 오류 제어를 제공하는 연결 지향 프로토콜이다.
순서 번호
패킷을 중복 수신하지 않도록 하기 위하여 프로토콜은 순서 번호와 확인응답 번호를 사용한다. 여기서 고려해야 할 사항은 순서 번호의 범위이다. 패킷의 크기를 최소화하기 위해서는 최소 범위를 찾아야 한다. 만약 를 순서 번호로 사용한다면, 그 다음 번호로는 만이 필요하고 는 필요없다. 즉 모듈로 2 연산을 따른다.
확인응답 번호
확인응답 번호는 항상 수신측에서 다음에 받기를 기대하는 패킷의 순서 번호를 나타낸다.
Stop-and-Wait 프로토콜에서, 확인 응답 번호는 모듈로-2 연산을 사용하여 다음에 기대되는 패킷의 시퀀스 번호를 항상 알린다.
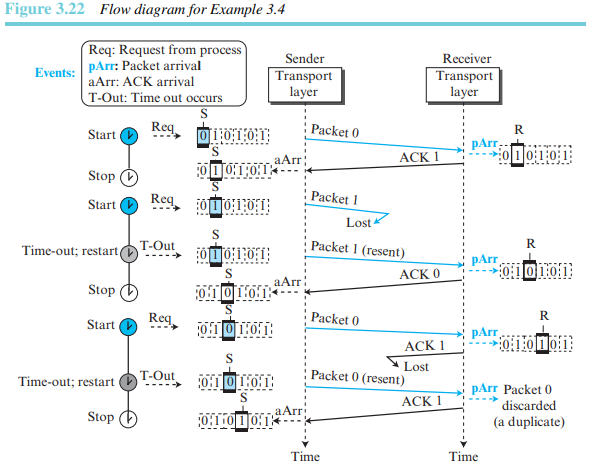
예제 3.4
그림 3.22는 Stop-and-Wait 프로토콜의 예를 보여준다. 패킷 0이 전송되고 확인응답되었다. 패킷 1은 손실되고 타임아웃 후에 재전송되었다. 재전송된 패킷 1은 확인응답되고 타이머는 중단되었다. 패킷 0은 전송되고 확인응답되었으나 ACK가 손실되었다. 송신측은 패킷 또는 ACK가 손실되었는지를 알 수 없기 때문에 타임아웃 후에 패킷 0을 재전송하고, 이 패킷은 확인응답되었다.
효율
Stop-and-Wait 프로토콜은 채널이 두껍고 긴 경우에는 매우 비효율적이다. 여기서 '두껍다'는 단어는 채널이 큰 대역폭(높은 전송률)을 의미하고, '길다'라는 단어는 왕복 지연시간이 길다는 것을 의미한다. 이 두 항목을 곱한 것을 대역폭-지연-곱(bandwidth-delay-product)이라고 한다. 채널을 파이프라고 생각해 보자. 대역폭-지연 곱은 비트로 표현된 파이프의 용량이라고 할 수 있으며, 수신측으로부터 확인응답을 기다리면서 송신측에 파이프를 통하여 전송할 수 있는 비트의 수이다.
예제 3.5
전송 대기 시스템에서 선로의 대역폭이 1Mbps이고 1비트가 왕복하는 데 20msec이 걸린다고 가정하자. 대역폭-지연 곱은 얼마인가? 시스템의 데이터 패킷 길이가 1000비트이면, 선로의 이용률은 얼마인가?
-해답
대역폭-지연 곱은 비트이다. 즉 시스템은 송신측에서 수신측으로 전송되고 그 반대의 방향으로 확인응답이 돌아오는 시간 동안 20,000비트를 전송할 수 있다. 그런데 실제로 이 시간동안 시스템은 1,000비트만 전송할 수 있다. 따라서 선로의 이용률은 1000/20000 또는 라고 할 수 있다. 이러한 이유로 인하여 높은 전송률 또는 긴 지연을 갖는 선로에서 Stop-and-Wait 프로토콜을 사용하는 것은 선로의 용량을 낭비하는 것이다.
파이프라인
네트워크와 다른 분야에서 이전 업무가 완료되기 전에 새로운 업무가 시작되는 경우가 있는데 이것을 파이프라인이라 한다.
3.2.3 Go-Back-N 프로토콜
확인응답을 수신하기 전에 여러 개의 패킷을 전송할 수 있다. 그렇지만 수신측은 단지 하나의 패킷을 버퍼에 저장할 수 있다.
순서 번호
순서 번호는 modulo 이며, 은 순서 번호 필드의 비트 수이다.
확인응답 번호
이 프로토콜에서 확인응답 번호는 누적 값이며 수신하기를 기대하는 값은 다음 패킷의 순서 번호를 나타낸다. 예를 들어, 확인응답 번호(ackNo)가 7이라는 것은 1번부터 6번까지의 순서 번호를 갖는 패킷 모두가 안전하게 도착했고 수신측은 순서번호 7을 갖는 패킷의 수신을 기다리고 있다는 뜻이다.
GBN에서 모든 수신된 패킷에 대해 개별적인 ACK가 생성되지 않는다.
송신 윈도
전송 중이거나 전송될 데이터 패킷의 순서번호를 포함하는 가상의 상자이다. 각 윈도의 위치에서 어떤 순서번호들은 이미 전송된 패킷을, 또 다른 순서번호들은 전송되고자 하는 패킷을 나타낸다. 윈도의 최대 크기는 이다. 그림 3.24는 GBN 프로토콜에서 크기 7의 슬라이딩 윈도를 보여준다.
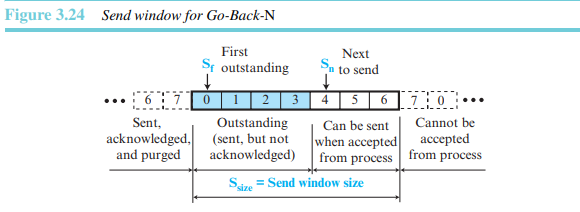
윈도 자체는 추상적 개념이다. 세 개의 변수가 윈도의 크기와 위치를 정의한다. 이 변수들은 각각 (송신 윈도, 첫 번째 미해결 패킷), (송신 윈도, 전송할 다음 패킷), (송신 윈도, 크기)를 나타낸다.
송신 윈도는 , 그리고 세 개의 변수를 가지고 최대값이 인 가상 상자를 나타내는 추상적 개념이다.
그림 3.25는 상대방으로부터 확인응답을 수신하는 경우에 어떻게 송신 윈도가 오른쪽으로 하나 이상의 슬롯을 이동하는지 보여준다. 이 그림에서 ackNo=6인 확인응답이 도착하였다.
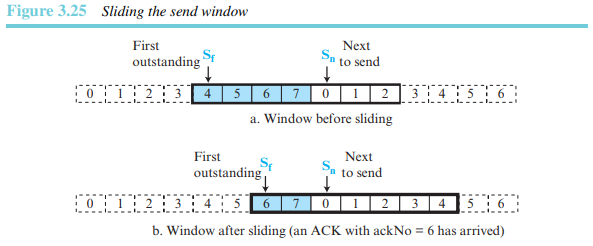
송신 윈도
수신 윈도는 촐바른 데이터 패킷을 수신하고 또한 올바른 확인응답이 전송될 수 있도록 한다. GBN에서 수신 윈도의 크기는 항상 1이다. 수신측은 항상 특정한 패킷을 기다린다. 순서에 어긋나게 도착한 패킷은 폐기되며 재전송될 것이다. 그림 3.26은 수신 윈도를 보여준다. 수신 윈도라는 추상적 개념을 표현하기 위해서는 하나의 변수 (수신 윈도, 다음에 수신할 패킷)만이 필요하다. 윈도의 왼쪽 부분은 이미 수신하였고 확인응답된 순서번호들이다. 오른쪽 부분은 수신될 수 없는 패킷을 나타낸다. 이 두 영역에 속하는 순서 번호를 가진 어떠한 패킷도 폐기된다. 단지 순서번호가 으로 설정된 패킷만이 수신되며 확인응답된다. 수신 윈도도 역시 이동하지만 한 번에 한 슬롯만큼만 이동한다. 올바른 패킷이 수신되면, 윈도는 = () 으로 이동한다.
타이머
전송된 각각의 패킷에 대한 타이머가 있지만, 여기에서는 단지 하나의 타이머만 사용한다고 가정한다. 그 이유는 첫 번째 미해결 패킷을 위한 타이머는 항상 먼저 만료되기 때문이다. 이 타이머가 만료되면 모든 미해결 패킷은 재전송된다.
패킷 재전송
타이머가 만료되면 송신측은 모든 미해결 패킷들을 재전송한다. 예를 들어 송신측에서 이미 패킷 6(=7)을 전송했지만 타이머가 만료되었다고 가정해 보자. 만일 = 3이면, 패킷 3, 패킷 4, 패킷 5, 패킷 6, 네 개의 패킷이 확인응답되지 않았다. 타이머가 만료되면 송신측은 패킷 3부터 패킷 6까지 네 개의 패킷을 재전송한다. 이것이 프로토콜을 Go-Back-N이라고 하는 이유이다. 타임아웃이 발생하면 윈도는 N 위치만큼 후퇴하며 모든 패킷을 재전송한다. 즉, N은 패킷들을 재전송할 때 확인응답을 받지 못한 패킷들의 개수다.
송신 윈도 크기
송신 윈도의 크기가 보다 작아야 하는 이유를 설명하려고 한다. 예를 들어 =2라고 하면, 윈도의 크기는 3이 된다. 그림 3.28은 윈도의 크기가 3인 경우와 4인 경우를 비교하여 보여준다.
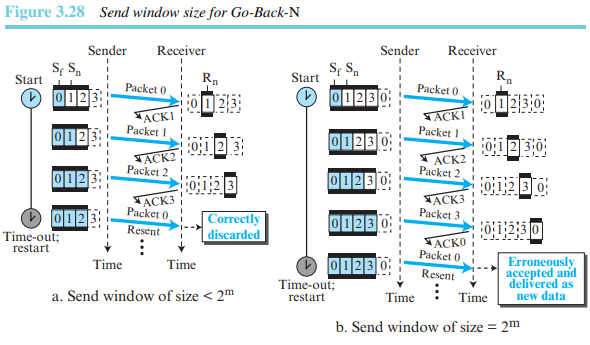
윈도 크기가 3이고 세 개의 ACK이 모두 손실된다면, 타이머가 만료된 후에 세 개의 패킷 모두는 재전송된다. 여기서 수신측은 패킷 0이 아닌 패킷 3의 수신을 기대하며, 따라서 중복되어 수신된 패킷들은 올바르게 폐기된다. 반면에 윈도의 크기가 4이고 확인응답이 모두 손실된다면, 송신측은 패킷 0의 복사본을 전송할 것이다. 그런데 수신측은 다음 사이클에 패킷 0을 받아야 하므로, 수신측은 패킷 0이 복사본이 아닌 다음 사이클의 첫 번째 패킷으로 간주하고 받아들인다. 이것은 명백한 오류를 유발한다.
GBN 프로토콜에서 송신 윈도의 크기는 보다 작아야 한다.
반면 수신 윈도의 크기는 항상 1이다.
예제 3.7
그림 3.29는 GBN의 예를 보여준다. 여기서 포워드 채널은 신뢰성이 있지만 백워드 채널은 그렇지 않다고 가정한다. 즉 데이터 패킷은 손상되지 않지만, ACK의 일부는 지연되거나 손실된다. 또한 이 그림은 누적 확인응답이 지연되거나 손실되는 경우에 어떻게 해결하는지 보여준다.
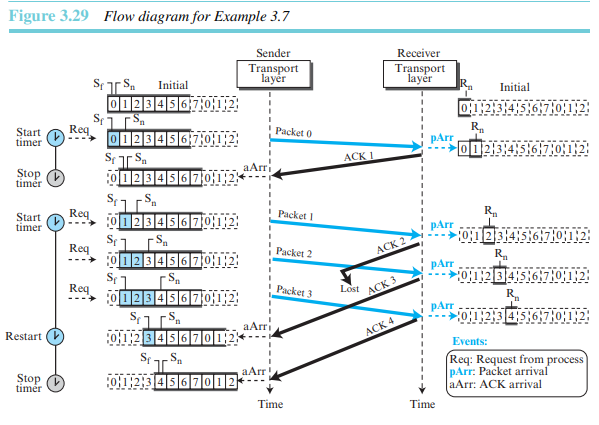
초기화 이후에 송신측 이벤트가 발생하였다. Request 이벤트는 응용 계층으로부터 메시지 전송 요청에 의해 발생하며, arrival 이벤트는 네트워크 계층으로부터 수신된 ACK에 의해서 발생한다. 여기에서는 타이머가 만료되기 전에 미해결 패킷이 모두 확인응답되었기 때문에 타임아웃 이벤트는 발생하지 않는다. 비록 ACK2는 손실되었지만, ACK3는 누적이며 따라서 ACK2와 ACK3를 모두 포함한다. 수신측에는 네 개의 이벤트가 있다.
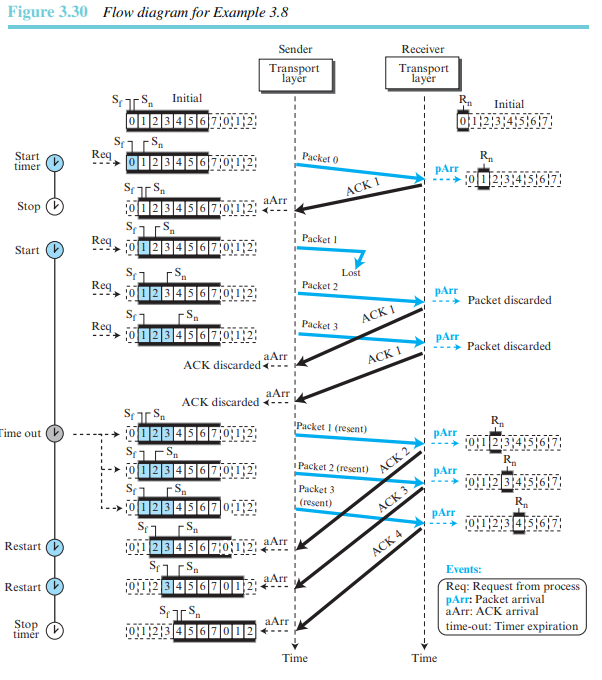
예제 3.8
그림 3.30은 패킷이 손실된 경우를 보여준다. 패킷 0, 1, 2, 그리고 3이 전송된다. 그런데 패킷 1이 손실되었다. 수신측에서는 패킷 2와 3을 수신했지만, 수신된 패킷이 모두 순서에 어긋나게 들어왔기 때문에 수신한 패킷을 모두 폐기한다. 수신측에서 패킷 2, 3을 수신하면, 수신측은 자신이 패킷 1을 기다린다는 것을 알리기 위하여 ACK 1을 전송한다. 그렇지만 이러한 ACK는 송신측에서 쓸모가 없다. 왜냐하면 ackNo이 보다 크지 않고 같기 때문이다. 즉 송신측은 수신한 ACK를 폐기한다. 타임아웃이 발생하면, 송신측은 패킷 1, 2, 3을 재전송하고, 이 패킷들은 확인응답된다.
GBN과 Stop-and-Wait 비교
Stop-and-Wait 프로토콜은 순서번호가 0과 1 단지 두 번호만 가지고, 송신 윈도의 크기가 1인 GBN 프로토콜이다.
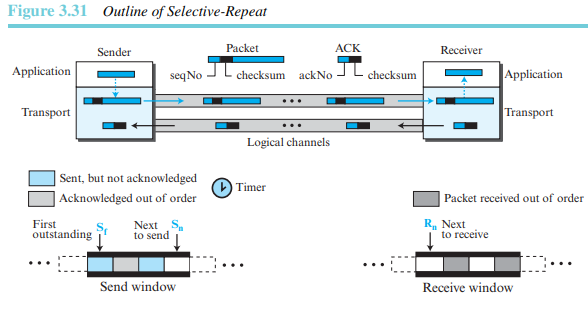
3.2.4 Selective-Repeat 프로토콜
GBN 프로토콜은 수신측 프로세스를 간단히 한다. 그러나 GBN은 하나의 패킷이 손실되거나 손상될때마다 송신측은 모든 패킷을 재전송해야 한다.
SR 프로토콜에서는 실제로 손실된 패킷만 선택적으로 재전송한다. 그림 3.31은 이 프로토콜의 동작을 간략히 보여준다.
윈도
SR 프로토콜의 윈도는 GBN 윈도와 여러 가지 면에서 다르다. 첫째, 송신 윈도의 최대 크기는 로 상당히 작다. 둘째, 수신 윈도는 송신 윈도와 같은 크기를 갖는다.
송신 윈도의 최대값은 이다. 예를 들어 =4이면, 순서번호는 0부터 15까지이지만, 윈도의 최대 크기는 8이다(GBN의 경우 최대 윈도 크기는 15). 그림 3.32는 SR 프로토콜의 송신 윈도 크기를 보여준다.
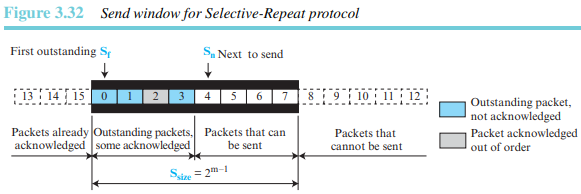
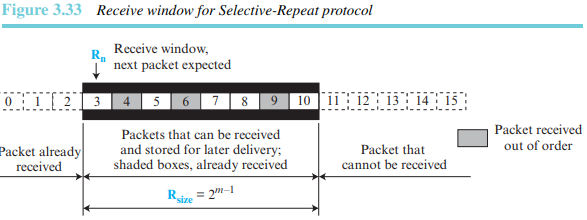
SR에서 수신 윈도는 GBN과는 완전히 다르다. 수신 윈도의 크기는 송신 윈도의 크기(최대 )와 같다. SR 프로토콜에서는 수신 윈도의 크기만큼 많은 패킷들이 순서에 맞지 않게 도착한다면 이런 패킷들은 버퍼에 저장되며, 올바른 패킷이 도착하면 응용 계층으로 전달한다. 그림 3.33은 SR에서의 수신 윈도를 간략히 보여준다.
타이머
이론적으로 SR 프로토콜에서는 아직 처리되지 않은 각각의 패킷마다 하나의 타이머를 사용한다. 타이머가 만료되면 해당 패킷이 재전송된다.
확인응답
두 프로토콜 사이의 또 다른 차이점은 다음과 같다. GBN 프로토콜에서 ackNo는 누적을 나타낸다. 즉 ackNo는 다음에 수신하기를 기다리는 패킷의 순서번호를 나타내며, 이 번호 이전의 패킷들은 이상없이 도착했음을 의미한다. SR에서는 다르다. SR에서 ackNo는 오류 없이 수신된 하나의 패킷 순서 번호를 나타내며, 다른 패킷들에 대한 어떤 피드백도 제공하지 않는다.
예제 3.9
송신측에서 패킷 0, 1, 2, 3, 4, 5의 6개 패킷을 전송한다고 가정해 보자. 송신측이 ackNo=3의 ACK를 수신했다. 시스템이 GBN 또는 SR을 사용하는 경우에 ACK 수신은 각각 무엇을 의미하는가?
-해답
GBN을 이용하는 시스템에서는 패킷 0, 1, 2가 훼손되지 않고 잘 수신되었다는 것과 수신측에서 패킷 3의 수신을 기다리고 있다는 것을 의미한다. SR을 이용하는 시스템에서는 패킷 3이 훼손되지 않고 잘 도착했다는 것을 의미하며, 다른 패킷에 대한 정보는 없다.
예제 3.10
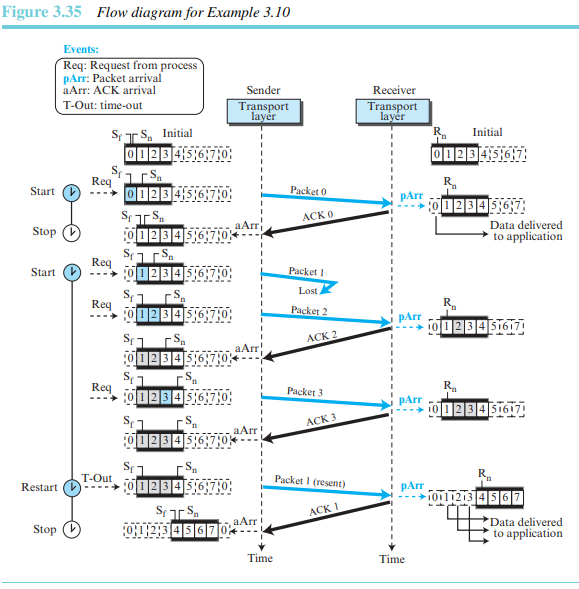
그림 3.35는 다음의 상황을 보여준다.
송신측에서 패킷 0이 수신측에게 전송되고 확인응답되었다. 패킷 1은 손실되었다. 패킷 2와 3은 순서에 맞지 않게 도착하였고 확인응답되었다. 타미어가 만료되면, 패킷 1은 재전송되고 또한 확인응답되었다. 이제 송신 윈도는 이동한다.
수신측에서는 패킷의 수신과 패킷의 응용 계층으로의 전달을 구분해야 한다. 두 번째 도착에서 패킷 2는 도착한 후 저장되고 확인(음영 슬롯으로)되었지만 응용계층으로 전달될 수 없다. 다음 도착에서 패킷 3이 도착한 후 저장되고 확인(음영 슬롯으로)되었지만, 여전히 어떤 패킷도 응용계층으로 전달될 수 없다. 패킷 1에 대한 사본이 도착했을 때 비로소 패킷 1, 2, 3이 응용계층으로 전달될 수 있다.
응용계층으로 패킷을 전달하는 데는 두 가지 조건이 있다. 첫 번째는 연속적인 패킷이 도착해야 하고, 두 번째는 수신한 패킷 집합이 윈도의 처음 부분부터 시작해야 한다는 것이다. 처음 도착 후에는 하나의 패킷만이 있으며, 이 패킷은 윈도의 처음 부분부터 시작된다. 마지막 도착 이후에는 세 개의 패킷이 있으며, 처음 패킷은 윈도의 처읍 부분부터 시작된다. 신뢰성 있는 전송 계층에서는 순서에 맞는 패킷 전송을 약속하는 것이 중요하다.
윈도 크기
송신 윈도와 수신 윈도의 크기가 의 반밖에 되지 않는 이유를 살펴보자. 예를 들어 = 2라면 윈도의 크기는 /2 = 2가 된다. 그림 3.36에서는 윈도 크기 2와 윈도 크기 3을 비교한다.
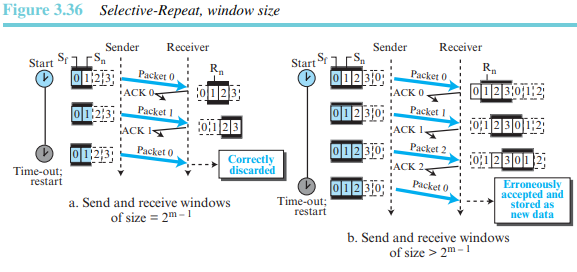
윈도의 크기가 2이고 모든 확인응답이 손실되면, 패킷 0에 대한 타이머는 만료되어 패킷 0이 재전송된다. 그렇지만 수신측 윈도는 패킷 0이 아닌 2를 수신하기를 기대하고 중복수신한 패킷은 폐기한다(순서번호 0은 윈도 내의 번호가 아니다). 윈도의 크기가 3이고 모든 확인응답이 손실되면, 송신측은 패킷 0의 복사본을 전송한다. 그렇지만 수신측 윈도는 패킷 0의 수신을 기대하고 있으며, 따라서 수신측은 패킷 0을 복사본이 아닌 다음 사이클에 속하는 패킷으로 간주하고 받아들인다. 이것은 분명한 오류이다.
Selectiv-Repeat에서 송신 윈도와 수신 윈도의 크기는 의 반이다.
3.2.5 양방향 프로토콜: 피기배킹
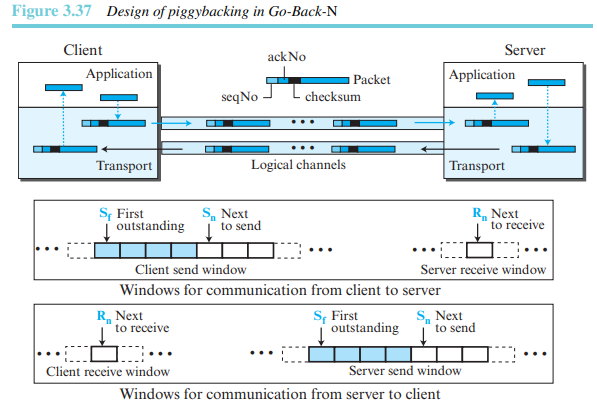
앞서 설명한 네 개의 프로토콜은 모두 단방향이다. 실제 환경에서 데이터 패킷은 양방향으로 전송된다. 이것은 확인응답 역시 양방향으로 전송될 필요가 있다는 것을 의미한다. 피기배킹(piggybacking) 기술은 양방향통신의 효율을 향상시키기 위해 사용된다. 패킷이 A부터 B까지 전송될 때, B가 수신한 패킷에 대한 확인응답 피드백도 같이 전달할 수 있다. 그 반대도 마찬가지다.
그림 3.37은 피기배킹을 이용하여 양방향통신이 가능한 GBN의 개략적 동작을 보여준다.
3.3 UDP
비연결형, 비신뢰성 프로토콜이다. 호스트 대 호스트의 통신 대신 프로세스-대-프로세스 통신을 제공하는 것 이외에는 IP 서비스에 추가되는 기능이 아무 것도 없다. 대신 최소한의 오버헤드만 사용한다. 프로세스가 작은 메시지를 보내거나 신뢰성을 크게 고려하지 않을 때 사용될 수 있다.
3.3.1 사용자 데이터그램
사용자 데이터그램으로 불리는 UDP 패킷은 각각 2바이트 크기를 갖는 4개의 필드로 만들어진 8바이트의 고정된 헤더를 갖는다. 그림 3.39는 사용자 데이터그램의 형식을 보여준다.
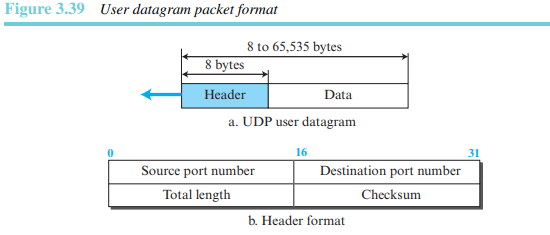
처음 두 필드는 발신지와 목적지의 포트번호를 정의한다. 세 번째 필드는 헤더 길이와 데이터 길이를 합한 사용자 데이터그램의 총 필드 길이를 정의한다. 16비트는 0에서 65,535 사이의 길이를 정의할 수 있다. 그러나 유저 데이터그램은 총 길이가 65,535바이트인 IP 데이터그램에 저장되므로 실제 총 길이는 훨씬 작다. 마지막 필드는 검사합과 같은 추가적인 옵션이 포함될 수 있다.
예제 3.11
다음은 16진수 형식으로 UDP 헤더를 나타낸 것이다.

A. 발신지 포트번호는?
B. 목적지 포트번호는?
C. 유저 데이터그램의 총 길이는?
D. 데이터의 길이는?
E. 데이터의 전송 방향이 클라이언트로부터 서버 쪽인가 아니면 반대의 방향인가?
F. 클라이언트 프로세스는 무엇인가?
-해답
A. 발신지 포트번호는 처음 네 개의 16진수()이며, 십진수로 표현하면 52,100이다.
B. 목적지 포트번호는 두 번째 네 개의 16진수()이며, 십진수로 표현하면 13이다.
C. 세 번째 네 개의 16진수()는 UDP 패킷의 전체 길이를 나타내며, 28바이트이다.
D. 데이터의 길이는 패킷의 전체 길이에서 헤더의 길이를 뺀 것으로 20바이트이다.
E. 목적지 포트번호가 13(잘 알려진 포트)이므로, 클라이언트로부터 서버로 패킷이 전송되었다.
F. 클라이언트 프로세스는 데이타임이다.
3.3.2 UDP 서비스
프로세스-대-프로세스 통신
UDP는 IP 주소와 포트번호로 구성된 소켓을 이용하여 프로세스-대-프로세스 통신을 지원한다.
비연결형 서비스
UDP에 의해 전송되는 각각의 유저 데이터그램은 서로 독립적이다. 여러 개의 데이터그램이 동일한 발신지 프로세서로부터 동일한 목적지 프로그램으로 전송되어도 서로 다른 유저 데이터그램 사이에는 아무런 연관관계가 없다. 유저 데이터그램에는 번호가 붙지 않고, TCP 프로토콜과 다르게 연결 설정과 연결 종료가 없다. 이것은 각 사용자 데이터그램이 다른 경로를 통하여 전달될 수 있다는 것을 의미한다.
65,507바이트(65,535UDP 헤더의 8바이트IP 헤더의 20바이트)보다 작은 메시지를 보내는 프로세스만이 UDP를 사용할 수 있다.
흐름 제어
없다. 따라서 수신측에서는 받는 메시지로 인한 오버플로우가 발생할 수 있다.
오류 제어
검사합을 제외한 오류 제어가 없다. 이것은 메시지 손실 및 중복을 송신자가 알 수 없다는 것이다. 검사합을 사용하여 오류를 감지하면 유저 데이터그램을 폐기한다.
검사합
UDP 검사합 계산은 의사헤더, UDP 헤더, 응용계층으로부터 온 데이터의 세 부분을 포함한다. 의사헤더는 유저 데이터그램이 캡슐화되는 IP 패킷 헤더의 일부분이며, 몇 개 필드의 값은 0으로 설정한다.
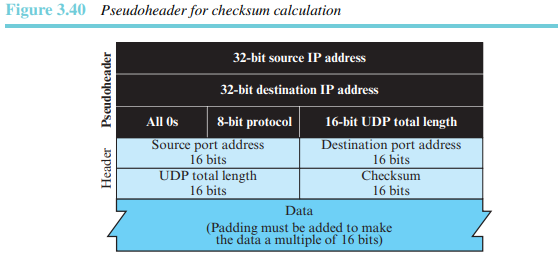
만약 검사합이 의사헤더를 포함하지 않으면, 유저 데이터그램은 안전하고 정상적으로 도착할 수도 있다. 그러나 IP 헤더에 오류가 발생하면 잘못된 호스트로 전달될 수 있다.
- 검사합의 옵션 포함 사항
UDP 패킷의 송신자는 검사합 계산을 선택하지 않을 수도 있다. 이 경우에 전송 전 검사합 필드는 0이 된다. 송신자가 검사합을 계산하기로 결정한 경우에는 검사합의 결과값이 모두 0이면 검사합 필드 값은 모두 1로 변경된 후 전송된다.
혼잡 제어
혼잡 제어를 제공하지 않는다.
캡슐화와 역캡슐화
수행한다.
큐잉
UDP에서 큐는 포트와 관련이 있다. 클라이언트 측에서 프로세스가 시작되면 클라이언트는 OS에게 포트번호를 요청한다. 각 프로세스에 연계된 입력 큐와 출력 큐가 생성된다.
다중화와 역다중화
사용한다.
UDP와 일반 단순 프로토콜과의 비교
비연결형 단순 프로토콜과 UDP의 차이점은 UDP는 수신측에서 훼손된 패킷을 감지하기 위해 부가적인 검사합을 사용한다는 점이다. 검사합이 패킷에 포함되면, 수신 UDP는 패킷을 검사하고 패킷이 훼손되었다면 폐기한다. 그렇지만 어떠한 피드백도 송신측으로 전송되지 않는다.
UDP는 비연결형 단순 프로토콜의 예이며, 검사합 이외에는 차이가 없다.
3.3.3 UDP 응용
UDP 특징
-
비연결형 서비스
UDP 패킷은 동일한 응용프로그램으로부터 전송되는 다른 패킷들과는 독립적이다. 예를 들어 클라이언트 응용이 서버에게 짧은 요청을 전송하고 짧은 응답을 수신하고자 하는 경우는 도움이 된다. 연결 지향 서비스에서는 연결을 설정하고 종료하기 위한 오버헤드가 클 수 있다. -
오류 제어의 결함
UDP는 오류 제어를 제공하지 않아 비신뢰성 서비스를 제공한다. 신뢰성 서비스를 제공하는 전송 계층은 손실되거나 훼손된 메시지를 재전송해야 하고, 이것은 수신측 전송계층이 손실되거나 훼손된 메시지를 즉시 응용계층에 전송하지 못함을 의미한다. -
혼잡 제어의 결함
UDP는 혼잡 제어를 제공하지 않는다. 하지만 UDP는 오류가 발생할 수 있는 네트워크에서의 추가적인 트래픽을 생성하지 않는다. TCP는 패킷을 여러 번 재전송하여 혼잡을 유발하거나 혼잡 상태를 더 악화시킨다. 따라서 혼잡이 큰 문제인 경우 UDP에서 오류 제어를 제공하지 않는 것은 장점이 된다.
대표적인 응용
- UDP는 단순한 요청-응답 통신을 필요로 하고 흐름 제어와 오류 제어에 큰 관련이 없는 프로세스에 적절하다. FTP와 같이 대량의 데이터를 보내야 하는 프로세스에서는 일반적으로 사용되지 않는다.
- UDP는 내부에 흐름 제어와 오류 제어 메커니즘을 가지고 있는 프로세스에 적절하다. 예를 들어 TFTP 프로세스는 흐름 제어와 오류 제어를 포함한다.
- UDP는 멀티캐스팅에 적합하다.
- UDP는 SNMP와 같은 관리 프로세스에 사용된다.
- UDP는 라우팅 정보 프로토콜과 같은 경로 갱신 프로토콜에 사용된다.
- UDP는 수신된 메시지 조각들 간의 지연이 동일해야 하는 실시간 응용들에 의해 일반적으로 사용된다.
3.4 TCP
GBN과 SR 프로토콜 조합을 사용한다.
3.4.1 TCP 서비스
프로세스-대-프로세스 통신
제공한다.
스트림 배달 서비스
UDP와는 다르게 TCP는 스트림 기반의 프로토콜이다. TCP에서 송수신 프로세스는 바이트 스트림의 형태로 데이터를 전송 및 수신할 수 있다.
송신 버퍼와 수신 버퍼
송신 및 수신 프로세스가 동일한 속도로 데이터를 생산하거나 소비하지 않을 수 있으므로 TCP의 경우 버퍼가 필요하다. 송수신 모두에게 있으며, 이는 흐름 및 오류 제어에도 사용된다.
그림 3.42는 한방향으로의 데이터 이동을 보여준다. 송신측 버퍼는 세 유형으로 이루어져 있다. 하얀 부분은 빈 공간이며 송신 프로세스에 의해 채워질 수 있다. 컬러 부분은 전송되었지만 아직 확인응답이 되지 않은 바이트를 나타낸다. 회색 부분은 송신 TCP가 전송할 데이터를 나타낸다.
수신측에서의 버퍼 동작은 간단하다. 하얀 부분은 빈 공간이며, 망으로부터 수신되는 바이트에 의해 채워진다. 컬러 부분은 수신은 되었지만, 아직 수신 프로세스가 읽지 않은 바이트를 나타낸다.
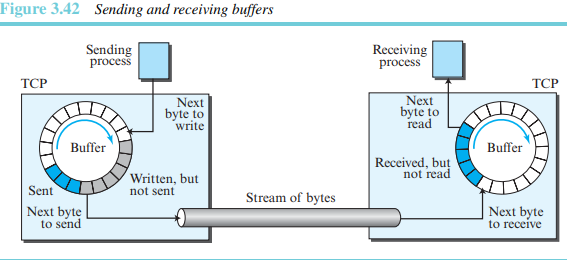
- 세그먼트
TCP 제공자로서의 IP는 바이트 스트림의 형태가 아닌 패킷의 형태로 데이터를 전달한다. TCP는 일련의 바이트를 세그먼트라고 하는 패킷으로 그룹화한다. TCP는 각각의 세그먼트들에게 헤더를 붙이고, 전송을 위하여 IP 계층에 세그먼트를 전송한다. 이 세그먼트는 IP 데이터그램으로 캡슐화되어 전송된다.
전이중 통신
지원한다.
다중화와 역다중화
수행한다. 프로세스들 간에 연결이 설정되어 있어야 한다.
연결 지향 서비스
TCP 연결에서 실제로 물리적인 연결은 없다. 그렇지만 TCP는 스트림 기반의 환경을 제공하여 상대방에게 순서에 맞게 바이트를 전달할 책임이 있다.
신뢰성 있는 서비스
확인응답 메커니즘을 사용한다.
3.4.2 TCP의 특징
번호화 시스템
TCP SW는 어떤 세그먼트를 전송 또는 수신했는지를 기억하지만, 세그먼트 헤더에는 세그먼트 번호 값을 위한 필드가 없다. 대신에 순서 번호와 확인응답 번호 두 개의 필드가 존재한다. 이 두 개의 필드는 세그먼트 번호가 아닌 바이트의 번호와 관련이 있다.
-
바이트 번호
TCP는 한 연결에서 전송되는 모든 데이터 바이트에 번호를 매긴다. 이러한 번호는 각 방향에서 서로 독립적으로 매겨진다. TCP가 프로세스로부터 데이터 바이트를 수신하여 송신 버퍼에 보관하면, TCP는 각 바이트마다 번호를 매긴다. 0부터 번호를 매길 필요는 없다. 대신에 TCP는 에서 사잉의 임의값을 선택하여 이를 처음 바이트 번호로 설정한다. 예를 들어, 임의의 값이 1,057이고 전송하고자 하는 총 데이터가 6,000바이트라면, 각각 전송되는 바이트에 1,057부터 7,056까지의 번호가 매겨진다. 바이트 순서화는 흐름 및 오류 제어에 사용된다.각 방향으로 전송되는 데이터 바이트는 TCP에 의해 번호가 매겨진다. 번호는 임의로 생성된 값에서부터 시작한다.
-
순서 번호
바이트 번호가 매겨지면, TCP는 전송하고자 하는 세그먼트에 하나의 순서 번호를 할당한다. 각 방향에서 순서 번호는 아래와 같이 정의된다.
1. 첫 번째 세그먼트의 순서 번호는 임의의 숫자인 ISN(Initial Sequence Number)이다.
2. 다른 세그먼트의 순서 번호는 이전 세그먼트의 순서 번호에 이전 세그먼트가 운반한 바이트를 더한 것이다.
예제 3.17
TCP 연결이 5,000바이트의 파일을 전송한다고 가정하자. 첫 번째 바이트는 10,001의 번호를 가지고 있다. 만일 각각이 1,000바이트를 가지는 5개의 세그먼트에 데이터가 전달된다면, 각 세그먼트의 순서 번호는 어떻게 되는가?
-해답
다음은 각 세그먼트의 순서 번호를 보여준다.

세그먼트 내의 순서 번호 필드의 값은 그 세그먼트에 포함되는 첫 번째 데이터 바이트의 번호를 나타낸다.
데이터와 제어 정보(피기배킹) 조합을 운반하는 세그먼트는 순서 번호를 용한다. 사용자 데이터를 전달하지 않는다면 세그먼트는 논리적으로는 순서 번호를 가질 필요는 없다. 필드는 있지만 값은 유효하지 않다. 그렇지만 단지 제어 정보만을 포함하는 특별한 세그먼트는 순서 번호를 필요로 하며 수신측으로부터 확인응답된다. 이러한 세그먼트는 연결, 설정, 해지, 또는 중단을 위해 사용된다. 각각의 세그먼트는 실제의 데이터가 없지만, 마치 하나의 바이트를 전달하는 것과 같이 하나의 순서 번호를 소비한다.
- 확인응답 번호
송/수신 각각의 TCP는 서로 다른 시작 번호를 이용하여 바이트에 순서를 매긴다. 각 방향으로 전송되는 세그먼트에 있는 순서 번호는 그 세그먼트에 의해 운반되는 첫 번째 바이트의 번호를 보여준다. 또한 각 TCP는 자신이 바이트를 수신하였다는 것을 확인하기 위해 확인응답 번호를 이용한다. 확인응답 번호는 자신이 수신하기를 기대하는 다음 바이트의 번호를 나타낸다. 또한 확인응답 번호는 누적이다. 즉 한쪽 편에서는 수신 성공한 마지막 바이트의 번호에 1을 더한 값을 확인응답 번호로 전송한다.세그먼트 내의 확인응답 번호의 값은 다음에 수신하기를 기다리는 바이트의 번호를 나타낸다. 확인응답 번호는 누적이다.
3.4.3 세그먼트
TCP에서 패킷은 세그먼트라 한다.
형식
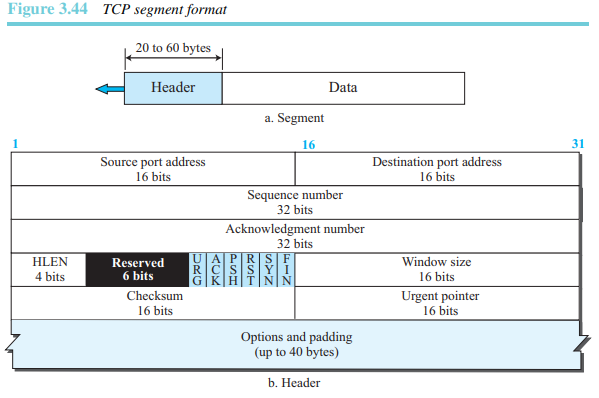
세그먼트는 20에서 60바이트의 헤더와 응용프로그램으로부터 생성되는 데이터로 구성되어 있다. 헤더는 옵션이 없는 경우에 20바이트이고, 옵션을 포함하는 경우 최대 60바이트로 구성된다.
-
발신지 포트 주소
-
목적지 포트 주소
-
순서 번호: TCP에서는 난수 발생기를 이용하여 초기 순서 번호(ISN)를 만들며, 이때 사용되는 ISN은 일반적으로 각 방향에 따라 다른 번호가 사용된다.
-
확인응답 번호
-
헤더 길이
-
제어: 이 필드는 그림 3.45에 나타나 있는 것과 같이 6개의 서로 다른 제어 비트 또는 플래그를 나타낸다. 동시에 여러 개의 비트가 1로 설정될 수 있다. 이 비트들은 흐름 제어, 연결 설정 및 종료, 연결 리셋, 그리고 TCP에서의 데이터 전송 모드를 위해 사용된다.
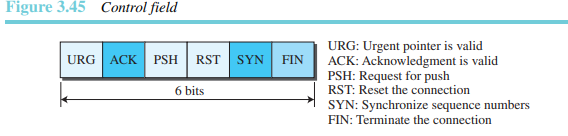
-
윈도 크기: 이 필드의 길이가 16비트이므로 윈도의 최대 크기는 65.535바이트이다. 윈도 크기는 수신 윈도(rwnd)라고 하며, 수신측에 의해 결정된다. 이 경우 송신측은 수신측의 지시에 따라야 한다.
-
검사합: 이 16비트 필드는 검사합을 포함한다. TCP에서의 검사합은 UDP 부분에서 언급한 것과 같이 동일한 절차를 따른다. 그러나 TCP에서의 검사합 포함은 필수이다. TCP 의사헤더의 프로토콜 필드의 값은 6이다.
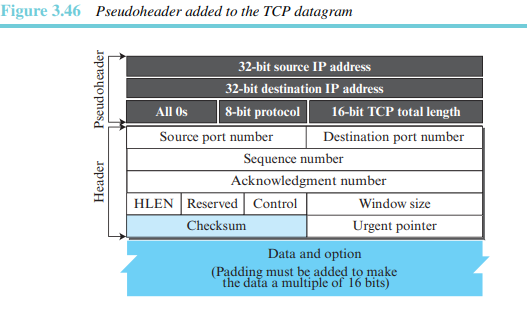
TCP에서의 검사합의 포함은 필수 사항이다.
-
긴급 포인터
-
옵션
캡슐화
3.4.4 TCP 연결
연결 설정
TCP는 전이중 방식으로 데이터를 전송한다.
-
3단계 핸드셰이킹
3단계 핸드셰이킹 절차는 서버에서부터 시작한다. 서버 프로그램은 자신의 TCP에게 연결을 수락할 ready가 되었다는 것을 알린다. 이러한 요청을 수동 개방(passive open)이라고 한다. 서버 TCP가 다른 시스템으로부터 연결을 수락할 수 있지만, 자신이 먼저 연결을 개설할 수는 없다.
클라이언트 프로그램은 능동 개방(active open)을 위한 요청을 실행한다. 개방되어 있는 서버와 연결을 설정하고자 하는 클라이언트는 자신의 TCP에게 특정한 서버와 연결을 설정할 것을 알린다. TCP는 이제 그림 3.47에 나와 있는 것과 같은 3단계 핸드셰이킹 절차를 시작한다.
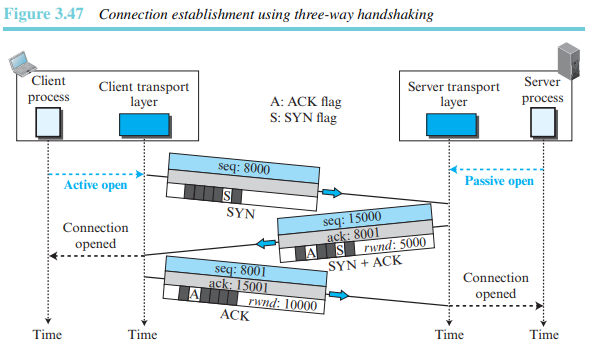
1. 클라이언트는 첫 번째 세그먼트로서 SYN 플래그가 1로 설정된 SYN 세그먼트를 전송한다. 이 세그먼트는 순서 번호의 동기화가 목적이다. 예제에서 클라이언트는 임의의 값을 첫 번째 순서 번호로 선택한 후 이 번호를 서버로 전송한다. 이 번호를 초기 순서 번호(ISN)라고 한다. 이 세그먼트에는 확인응답 번호가 포함되지 않는다. 또한 이 세그먼트에는 윈도 크기도 정의되지 않는다. 윈도 크기 필드에 있는 값은 세그먼트가 확인응답 번호를 포함하는 경우에만 의미가 있다. 세그먼트에는 몇 가지 옵션들이 포함될 수 있다. SYN 세그먼트는 단지 하나의 제어 세그먼트이며 어떠한 데이터도 전달하지 않는다. 그렇지만 이 세그먼트는 하나의 순서 번호를 소비한다. 데이터 전송이 시작되면 순서 번호는 1만큼 증가한다. 즉 SYN 세그먼트는 실제 데이터를 전달하지 않지만 하나의 가상 바이트를 포함하고 있다고 생각할 수 있다.SYN 세그먼트는 데이터를 전달하지는 않지만 하나의 순서 번호를 소비한다.
2. 서버는 두 번째 세그먼트로서 SYN과 ACK 플래그 비트가 각각 1로 설정된 SYN+ACK 세그먼트를 전송한다. 이 세그먼트는 두 가지 목적을 갖고 있다. 첫 번째로, 이 세그먼트는 반대 방향으로의 통신을 위한 SYN 세그먼트이다. 서버는 서버로부터 클라이언트로 전송되는 바이트의 순서화를 위한 순서 번호를 초기화하기 위해 이 세그먼트를 사용한다. 서버는 또한 ACK 플래그를 1로 설정하고 클라이언트로부터 다음에 수신하기를 기대하는 순서 번호를 표시함으로써 클라이언트로부터의 SYN 세그먼트 수신을 확인응답한다. 이 세그먼트는 확인응답 번호를 포함하고 있으며, 윈도 크기인 rwnd(클라이언트에 의해 사용될)를 포함한다. 이 세그먼트는 SYN 세그먼트의 역할을 수행하기 때문에 응답을 필요로 한다. 따라서 하나의 순서 번호를 소비한다.
SYN+ACK 세그먼트는 데이터를 전달하지는 않지만 하나의 순서 번호를 소비한다.
3. 클라이언트는 세 번째 세그먼트를 전송한다. 이것은 단순히 ACK 세그먼트이다. 이 세그먼트는 ACK 플래그와 확인응답 번호 필드를 이용하여 두 번째 세그먼트의 수신을 확인한다. 이 세그먼트에 있는 순서 번호는 SYN 세그먼트에 있는 것과 동일한 값으로 설정된다. 왜냐하면 ACK 세그먼트는 어떤 순서 번호도 소비하지 않기 때문이다. 또한 클라이언트는 서버의 윈도 크기를 결정해야 한다. 어떤 구현에서는 연결 단계에 있는 세 번째 세그먼트에 클라이언트로부터 들어온 데이터들을 포함하여 전달할 수 있다. 이 경우, 세 번째 세그먼트는 데이터 첫 번째 바이트의 바이트 번호를 나타내는 새로운 순서 번호를 가지고 있어야 한다.
ACK 세그먼트는 데이터를 전달하지 않는 경우에 순서 번호를 소비하지 않는다.
-
SYN 플러딩 공격
TCP의 연결 과정은 SYN 플러딩 공격이라는 중요한 보안 문제에 노출되어 있다. 이 공격은 악의에 찬 공격자가 데이터그램의 발신지 IP주소를 위조함으로써 서로 다른 클라이언트로 가장한 후에 많은 수의 SYN 세그먼트를 하나에 서버에 전송하는 경우에 발생한다.
데이터 전송
연결이 설정된 후에는 양방향으로 데이터가 전송될 수 있다. 클라이언트와 서버는 양방향으로 데이터와 확인응답을 전송할 수 있다. 동일한 방향으로 전송되는 데이터와 확인응답은 하나의 세그먼트로 전송될 수 있다. 즉 확인응답에 데이터가 피기백된다.
- 푸싱 데이터
송신 TCP는 송신 응용프로그램으로부터 들어오는 데이터 스트림을 저장하기 위하여 버퍼를 이용한다. 송신 TCP는 세그먼트의 크기를 선택할 수 있다. 수신 TCP 역시 수신한 데이터를 저장하기 위한 버퍼를 갖고 있으며, 응용프로그램이 ready가 되어 있을 때 데이터를 응용프로그램으로 전달한다. 이러한 종류의 유연성이 TCP의 효율을 향상시킨다.
그러나 모든 응용에서 편리한 것은 아니다. 다른 편에 있는 응용프로그램과 대화형으로 통신하는 경우, 키보드를 통하여 입력된 문자를 전송하고, 전송된 문자에 대한 확인응답을 즉시 수신하고자 할 때, 데이터의 전송을 지연하는 것은 문제가 된다.
이러한 문제에 대한 TCP에서의 해결 방법이 푸시 동작을 이용하는 것이다. 송신 TCP는 푸시 비트(제어필드의 PSH 비트 필드)를 1로 설정하여 수신 TCP에게 세그먼트가 가능한 한 빨리 수신 응용프로그램으로 전달되어야 하는 데이터를 포함하고 있다는 것을 알려준다. 따라서 수신 TCP가 더 이상의 데이터가 오기를 기다리지 않고 바로 수신 응용프로그램으로 전달할 수 있도록 한다. 이것은 바이트 지향적인 TCP에서 청크 기반의 TCP로 변경하기 위한 것을 의미한다.
연결 종료
데이터를 교환하는 어느 쪽도 연결을 종료할 수 있지만, 일반적으로는 클라이언트에서 종료를 시작한다. 현재 대부분의 구현에서는 연결 종료를 위하여 3단계 핸드셰이킹과 Half-close 옵션을 갖는 4단계 핸스셰이킹의 2가지 옵션이 사용된다.
-
3단계 핸드셰이킹
오늘날의 대부분의 구현에서는 그림 3.49처럼 연결 종료를 위해 3단계 핸드셰이킹 방법을 사용한다.
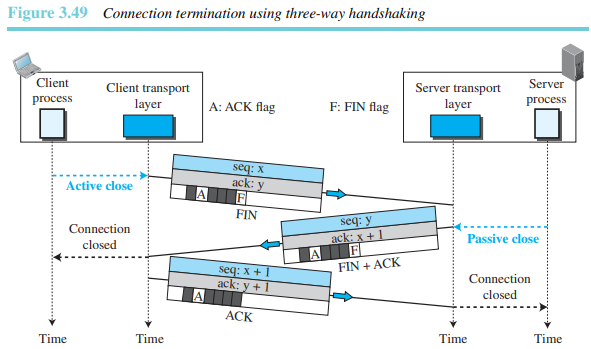
1. 클라이언트 프로세스로부터 close 명령어를 수신한 클라이언트 TCP는 첫 번째 세그먼트의 FIN 플래그를 1로 설정한 후 세그먼트를 전송한다. 이러한 FIN 세그먼트는 클라이언트로부터 전송되는 데이터의 마지막 청크를 포함할 수 있으며, 위 그림과 같이 제어 세그먼트일 수도 있다. FIN 세그먼트가 제어 세그먼트로 동작하는 경우에는 확인응답이 필요하기 때문에 하나의 순서 번호를 소비한다.데이터를 포함하지 않는 FIN 세그먼트는 하나의 순서 번호를 소비한다.
2. FIN 세그먼트를 수신한 서버 TCP는 서버 프로세스에게 연결 종료 상황을 알려준다. 그리고 서버 TCP는 클라이언트 TCP로부터의 수신을 확인하고 동시에 다른 방향으로의 연결 종료를 알려주기 위하여 두 번째 세그먼트인 FIN+ACK 세그먼트를 전송한다. 이 세그먼트는 서버로부터 수신한 데이터를 포함할 수 있다. 이 세그먼트가 데이터를 포함하지 않는 경우에는 이 세그먼트는 하나의 순서 번호를 소비한다.
데이터를 포함하지 않는 FIN+ACK 세그먼트는 하나의 순서 번호를 포함한다.
3. 클라이언트 TCP는 서버 TCP로부터의 FIN 세그먼트 수신을 확인하기 위하여 마지막 세그먼트인 ACK 세그먼트를 전송한다. 이 세그먼트에는 서버로부터 수신한 FIN 세그먼트에 있는 순서 번호에 1을 더한 값으로 설정되는 확인응답 번호가 포함된다. 이 세그먼트는 데이터를 전달하지 않으며 순서 번호를 소비하지도 않는다.
-
Half-close
TCP에서는 한쪽에서 데이터를 수신하면서 데이터 전송을 종료할 수 있다.
연결 리셋
한쪽 편에 있는 TCP는 연결 요청을 거절하거나, 연결 중단 그리고 휴지 상태에 있는 연결을 종료할 수 있다. 이것은 모두 RST 플래그에 의해 수행된다.
3.4.5 상태 천이 다이어그램
3.4.6 TCP 윈도
TCP에서의 데이터 전송과 흐름 제어, 그리고 혼잡 제어와 같은 문제를 다루기 전에 우선 TCP에서 사용되는 윈도의 대해 살펴보자. TCP는 데이터 전송을 위한 각 방향에 대해서 두 개의 윈도(송수신)를 사용하며 따라서 양방향통신을 위하여 네 개의 윈도가 필요하다. 여기서는 통신이 단방향이라 가정한다.
송신 윈도
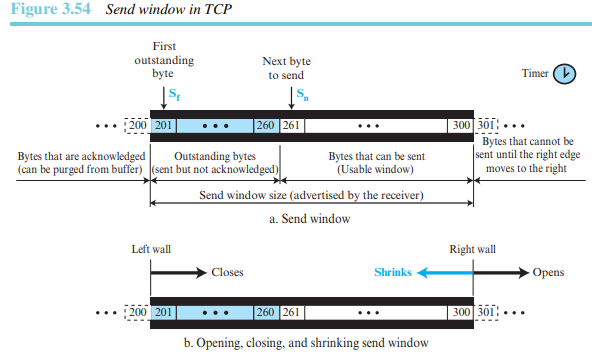
그림 3.54는 송신 윈도의 예를 보여준다. 여기서 사용하는 윈도의 크기는 100바이트이지만 송신 윈도의 크기는 수신자(흐름 제어)와 하부 네트워크의 혼잡(혼잡 제어)에 의해 조절되는 것을 볼 수 있다. 그림에서는 어떻게 송신 윈도가 열리고, 닫히고, 축소되는지 보여준다.
TCP의 송신 윈도는 SR 프로토콜에서 사용하는 것과 유사하지만 다음과 같은 차이점이 있다.
1. 첫 번째 차이점은 윈도와 관련된 객체 자체의 차이이다. SR에서 윈도는 패킷의 번호를 나타내지만, TCP의 윈도는 바이트 번호를 나타낸다. 비록 TCP에서는 세그먼트 단위의 전송이 이뤄지지만, 윈도를 제어하는 변수는 바이트로 표현된다.
2. 두 번째 차이점은 어떤 구현에서는 TCP는 프로세스로부터 데이터를 수신하고 추후에 그것들을 구현하지만, 여기서는 송신 TCP가 프로세스로부터 데이터를 수신하자마다 데이터에 대한 세그먼트를 전송할 수 있다고 가정했다.
3. 또 다른 차이점은 타이머의 개수이다. 이론적으로 SR 프로토콜은 전송되는 패킷마다 각각의 타이머를 사용하지만, TCP 프로토콜은 오직 하나의 타이머만 사용한다.
수신 윈도
그림 3.55는 수신 윈도의 예를 보여준다. 여기서 사용하는 윈도의 크기는 100바이트이다. 이 그림에서는 수신 윈도가 어떻게 열리고 닫히는지를 보여준다. 수신 윈도는 축소되지 않는다.
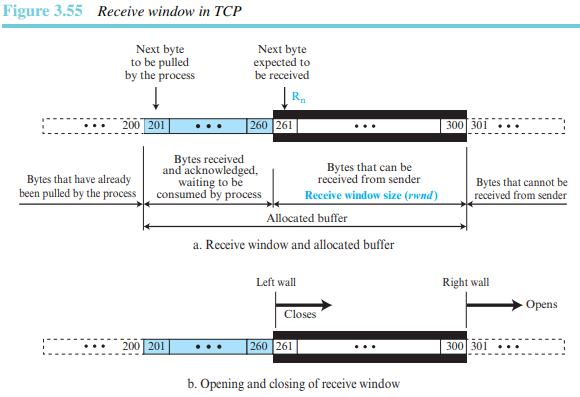
TCP의 수신 윈도와 SR에서 사용되는 윈도는 다음 두 가지의 차이점이 있다.
1. 첫 번째 차이점은 TCP에서 응용 프로세스가 자신의 속도로 데이터를 읽어갈 수 있다. 즉 수신측에 할당된 버퍼의 일부분은 확인응답된 데이터로 채워져 있지만 수신 프로세스에서 읽기 전까지 이러한 데이터는 버퍼에 저장되어 있어야 한다. 그림 3.55와 같이 수신 윈도의 크기는 항상 버퍼보다 크거나 같다. 수신 윈도의 크기는 수신 윈도가 송신측으로부터 넘치치 않고(흐름 제어) 수신할 수 있는 바이트의 개수를 결정한다. 수신 윈도 크기인 rwnd는 다음과 같이 결정될 수 있다.
rwnd = 버퍼크기 - 가져오기를 대기하는 바이트 수
2. 두 번째 차이점은 TCP 프로토콜에서 사용되는 확인응답 방법이다. SR에서의 확인응답은 선택적이며, 따라서 훼손되지 않고 수신된 패킷만을 정의함을 기억하라. TCP에서 주된 확인응답 메커니즘은 수신받기를 기대하는 다음 바이트를 알려주는 누적 확인응답 방법이다(즉 TCP는 GBN 방법과 비슷하다).
3.4.7 흐름 제어
흐름 제어는 생산자가 데이터를 만드는 속도와 소비자가 데이터를 사용하는 속도의 균형을 맞추는 것이다. TCP는 흐름 제어와 오류 제어를 구분한다. 송신과 수신 TCP 사이에 설정된 논리 채널은 오류가 없다고 가정한다.
그림 3.56은 송신측과 수신측 사이의 단방향 데이터 전송의 경우를 보여주며, 양방향 데이터 전송은 단방향의 경우로부터 유추할 수 있다.
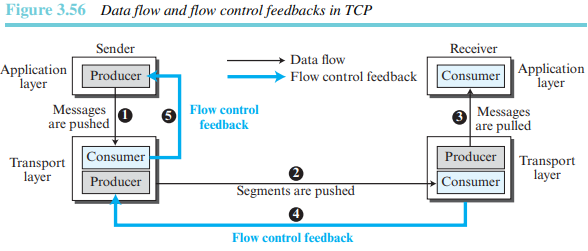
송신 TCP로부터 송신 프로세스로의 흐름 제어 피드백은 송신 TCP 윈도가 다 차면 송신 TCP에 의한 데이터의 간단한 거부로 획득된다. 단순히 데이터의 수신을 거부함으로써 이루어질 수 있다. 즉 여기에서 흐름 제어에 대한 설명은 수신 TCP로부터 송신 TCP로 전송되는 피드백에 대해서만 집중하면 된다는 것을 의미한다.
윈도 열기와 닫기
윈도가 꽉 차기 전에 흐름 제어가 발생되어야 한다.
어리석은 윈도 신드롬
슬라이딩 윈도 동작에서는 전송 응용프로그램이 데이터를 천천히 발생하거나, 또는 수신 응용프로그램이 데이터를 천천히 소비하는 경우에 심각한 문제가 발생한다. 이 경우에는 아주 적은 수의 데이터를 포함하는 세그먼트의 전송으로 인하여 동작의 효율은 감소한다. 예를 들어 TCP가 1바이터의 데이터를 포함하는 세그먼트를 전송하는 경우에는 단지 1바이트를 전달하기 위해서 41바이트의 데이터그램(20바이트의 TCP 헤더와 20바이트의 IP 헤더)이 전송되어야 한다. 즉 오버헤드는 41/1이 되고, 네트워크의 용량은 상당히 비효율적으로 사용된다. 이러한 문제를 어리석은 윈도 신드롬(silly window syndrome)이라 한다.
-
송신측에서 발생하는 신드롬
송신 TCP가 한 번에 한 바이트씩 데이터를 천천히 발생하는 응용프로그램을 다루는 경우에 어리석은 윈도 신드롬이 발생한다. 응용프로그램이 송신 TCP의 버퍼에 한 번에 한 바이트씩 쓰는 경우를 생각해 보자. 송신 TCP에 어떤 특별한 지시사항이 없을 경우, 송신 TCP는 한 바이트의 데이터를 포함하는 세그먼트를 만들게 되고, 41바이트 크기의 세그먼트가 인터넷을 통해 전달된다.
이러한 문제를 해결하는 한 가지 방법은 송신 TCP가 한 바이트 단위의 데이터 전송을 예방하는 것이다. 전송 TCP는 데이터를 취합하여 가능한 큰 블록으로 데이터를 전송해야 한다. 이 경우에는 충분한 데이터가 버퍼에 쌓이도록 전송 TCP가 일정 시간 기다려야 하는데, 얼마의 기간을 전송 TCP가 기다려야 하는가? 이러한 문제를 해결하는 것이 Nagle 알고리즘이다.
1. 송신 TCP는 단지 한 바이트일지라도 송신 응용프로그램으로부터 수신하는 첫 데이터를 세그먼트로 만든 후 전송한다.
2. 첫 번째 세그먼트를 전송한 후에 송신 TCP는 수신 TCP로부터 확인응답을 수신하거나 또는 최대 크기의 세그먼트를 구성할 수 있을 정도로 충분한 데이터가 출력 버퍼에 저장되기 전까지 기다린다. 위의 두 가지 경우 중 하나가 발생되면, 송신 TCP는 세그먼트를 전송한다.
3. 나머지 전송 기간 동안 2번째 단계를 반복한다. 즉 세그먼트 2에 대한 수신응답이 수신되거나 최대 크기의 세그먼트를 채울 수 있을 정도로 충분한 데이터가 저장되었을 경우에는 세그먼트 3이 전송된다.
Nagel 알고리즘의 장점은 매우 간단하다는 것과 데이터를 발생하는 응용프로그램의 속도와 네트워크의 데이터 전달 속도를 고려했다는 것이다. 만일 응용프로그램이 네트워크보다 빠르면 세그먼트는 (최대 크기의 세그먼트로) 커지게 된다. 만일 응용프로그램이 네트워크보다 느리면 (최대 크기의 세그먼트보다 작은 크기로) 작아지게 된다. -
수신측에 의한 신드롬 발생
수신 TCP가 한 번에 한 바이트와 같이 천천히 데이터를 소비하는 응용프로그램에 서비스를 제공하는 경우 수신 TCP에 어리석은 윈도 신드롬이 발생한다. 도착하는 속도보다 천천히 데이터를 소비하는 응용프로그램에 의해 발생되며, 이를 예방하기 위해 2가지 방법이 제시된다.
Clark의 해결 방안(Clark's solution)은 데이터가 도착하자마자 확인응답을 전송하지만, 수신 버퍼에 최대 크기의 세그먼트를 수용할 수 있는 충분한 공간이 있거나 적어도 수신 버퍼가 반 이상 비어있기 전까지는 윈도 크기를 0으로 통보하는 것이다. 두 번째 방법은 확인응답의 전송을 지연하는 것이다. 즉 세그먼트가 도착하더라도 확인응답하지 않는다. 그 대신 수신 버퍼에 충분한 공간이 있을 때까지 도착한 세그먼트의 확인응답을 보류한다. 지연된 확인응답은 송신 TCP로 하여금 자신의 윈도를 진행하지 못하도록 한다. 즉 송신 TCP는 윈도만큼의 데이터 전송 후에는 전송을 멈춘다.
3.4.8 오류 제어
TCP는 신뢰성 있는 전송 계층 프로토콜이다. 즉 데이터 스트림을 TCP로 전달하는 응용프로그램은 TCP가 전체 스트림을 순서에 맞고 오류 없이, 또한 부분적인 손실이나 중복 없이 상대편에 있는 응용프로그램에게 전달함을 확신하는 것을 의미한다.
TCP는 오류 제어를 이용하여 신뢰성을 제공한다. 오류 제어는 훼손된 세그먼트의 감지 및 재전송, 손실 세그먼트의 재전송, 분실된 세그먼트가 도착하기 전까지 순서가 맞지 않는 세그먼트를 저장하고 중복 세그먼트의 감지 및 폐기를 위한 메커니즘을 포함한다. TCP에서의 오류 제어는 간단한 세 가지 도구인 검사합, 확인응답 그리고 타임아웃을 통해 수행된다.
검사합
각 세그먼트에는 검사합 필드가 있으며, 이 필드는 세그먼트가 훼손되었는지를 검사하기 위해 사용된다. 만일 세그먼트가 무효한 검사합으로 인해 훼손되면, 목적지 TCP는 손상되었다고 판명된 세그먼트를 폐기하고 손실로 간주한다.
확인응답
TCP에서 데이터 세그먼트의 수신을 확인해 주기 위하여 확인응답을 사용한다. 데이터를 포함하지는 않지만 하나의 순서 번호를 소비하는 제어 세그먼트도 역시 확인응답된다. ACK 세그먼트는 결코 확인응답되지 않는다.
ACK 세그먼트는 순서 번호를 소비하지 않으며 확인응답되지도 않는다.
- 확인응답 유형
과거의 TCP는 확인응답의 한 가지 유형인 누적 확인응답만을 사용했다. 현재에 구현되는 TCP에선 선택적 확인응답도 같이 사용한다.누적 확인응답(ACK):
본래 TCP는 세그먼트의 수신을 누적하여 확인응답할 수 있도록 설계되었다. 수신측은 순서에 맞지 않게 도착하고 저장된 모든 세그먼트들을 무시하고 수신하고자 하는 다음 바이트를 광고한다. 일반적으로 긍정 누적 확인응답 또는 ACK라고 한다. ""긍정""이라는 단어는 수신측에서 세그먼트가 폐기되거나, 손실 혹은 중복 수신되었을 때 이에 대한 어떠한 피드백도 제공하지 않는다는 것을 의미한다. TCP 헤더에 있는 32비트의 ACK 필드가 누적 확인응답을 위하여 사용되며, 이 필드는 ACK 플래그 필드 비트가 1로 설정된 경우에만 유효하다.
선택 확인응답(SACK):
새 유형의 확인응답이 점차적으로 많은 구현에 추가되고 있다. SACK은 ACK를 대체하는 것이 아니라 송신측에게 부가 정보를 알려주기 위해 사용된다. SACK는 순서에 맞지 않에 들어온 데이터 블록과 중복 세그먼트 블록을 알려준다. 하지만 TCP 헤더에는 이러한 유형의 정보를 추가할 수 있는 여분의 공간이 없으므로 SACK은 TCP 헤더 끝에 옵션의 형태로 구현된다.
재전송
오류 제어 메커니즘의 핵심은 세그먼트의 재전송이다. 전송된 세그먼트는 확인응답되기 전까지 버퍼에 저장된다. 재전송 타이머가 만료되거나 송신측 버퍼에 있는 첫 번째 세그먼트에 대한 3개의 중복 ACK를 수신하는 경우에는 세그먼트가 재전송된다.
-
RTO 이후의 재전송
송신 TCP는 각각의 연결을 위해 하나의 재전송 타임-아웃(Retransmission Time-Out, RTO)을 유지한다. 타이머가 만료되어 타임아웃이 발생하면, TCP는 버퍼 앞에 있는 세그먼트(즉 가장 작은 순서 번호를 갖는 세그먼트)를 전송하고 타이머를 재구동한다. 여기에서는 을 가정한다. TCP에서 RTO의 값은 가변적이며 세그먼트의 왕복시간 RTT를 기반으로 업데이트된다. -
세 개의 중복 ACK 세그먼트 이후에 재전송
RTO 값이 크지 않은 경우에는 앞에서 언급한 규칙을 이용하여 세그먼트를 재전송해도 충분하다. 송신측에서 타임아웃을 기다리는 것보다 좀 더 빨리 재전송하여 인터넷에서의 처리율 향상을 위해 근래에 구현된 대부분의 TCP들은 세 개의 중복 ACK 규칙을 따르며 손실로 간주된 세그먼트를 즉시 재전송한다. 이러한 특징을 빠른 재전송(fast retransmission)이라고 한다. 이러한 TCP에서 만일 하나의 세그먼트에 대한 세 개의 확인응답이 수신되면, 타임아웃을 기다리지 않고 즉시 재전송된다.
순서에 맞지 않는 세그먼트
현재의 TCP에는 순서에 맞지 않는 세그먼트를 버리지 않고, 그 세그먼트를 일시적으로 저장하며, 손실된 세그먼트가 도착하기 전까지는 이 세그먼트를 순서에 맞지 않는 세그먼트로 표시한다. 그렇지만 순서에 맞지 않는 세그먼트를 프로세스로 전달하지는 않는다. TCP는 데이터가 순서에 맞게 프로세스에 전달되도록 한다.
데이터는 순서에 맞지 않게 도착할 수 있고 또한 수신 TCP에서 일시적으로 보관할 수 있다. 그렇지만 TCP는 세그먼트가 순서에 맞지 않게 프로세스로 전달되지 않게 한다.
4. 네트워크 계층
4.1 개요
인터넷은 많은 네트워크들이 연결 장치를 통해 서로 연결되어 구성되어 있다. 인터넷은 LAN과 WAN의 조합인 네트워크 간(internetwork)의 여결이다. 네트워크 계층의 역할을 보다 쉽게 이해하기 위해 WAN과 LAN을 연결해주는 연결 장치(라우터나 스위치)를 알아야 한다.
4.1.1 네트워크 계층 서비스
최근 인터넷의 네트워크 계층을 살펴보기 전에, 네트워크 프로토콜에서 제공하는 네트워크 서비스를 알아보기로 하자.
패킷화
발신지에서는 상위 계층에서 받은 데이터인 페이로드를 네트워크 계층의 패킷으로 캡슐화하고 목적지에서는 네트워크 계층의 패킷을 역캡슐화한다. 즉 네트워크의 주요 역할은 발신지에서 목적지까지 페이로드를 사용하거나 변경하지 않고 전달하는 것이다.
라우팅
네트워크 계층은 패킷이 발신지에서 목적지까지 갈 수 있도록 경로를 라우팅해야 한다. 물리적인 네트워크는 네트워크(LAN과 WAN)와 네트워크를 연결하는 라우터의 조합이다. 이는 발신지에서 목적지까지 적어도 하나 이상의 라우터가 있다는 의미이다. 네트워크 계층은 가능한 모든 경로 중에서 가장 좋은 경로를 찾는 역할도 수행한다. 따라서 네트워크 계층은 가장 좋은 경로를 정의하는 구체적인 규칙이 필요하다. 요즘 인터넷에서는 라우팅 프로토콜을 통해 라우터가 이웃에 관한 정보를 일관된 테이블에 유지하여 패킷이 도착했을 때 사용할 수 있어야 한다. 라우팅 프로토콜은 통신이 이루어지기 전 수행해야 한다.
라우팅 프로토콜:
네트워크 상태 및 경로 등에 대한 라우팅 정보를 라우터들 상호 간에 동적으로 교신하기 위해 약속된 하나의 언어
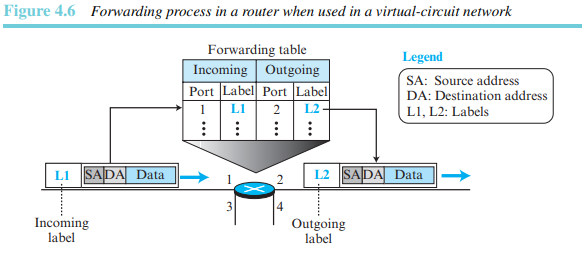
포워딩
각 라우터의 의사결정 테이블을 만들기 위해 라우팅에 규칙을 적용하고 라우팅 프로토콜을 실행할 때 포워딩은 라우터 상에 하나의 인터페이스로 패킷이 도착했을 때 라우터가 취하는 행동으로 정의할 수 있다. 이런 행동을 취하기 위해 라우터가 일반적으로 사용하는 의사결정 테이블은 포워딩 테이블이나 라우팅 테이블이라 불리기도 한다. 라우터가 하나의 네트워크로부터 패킷을 수신하면 해당 패킷을 다른 하나의 네트워크로 포워딩하거나 여러 네트워크로 포워딩한다. 이런 결정을 위해 라우터는 패킷 헤더에 있는 목적지 주소나 레이블 정보를 사용하여 포워딩 테이블에서 상응하는 출력 인터페이스 번호를 찾는다. 그림 4.2는 라우터 상에서 포워딩 과정을 보여준다.
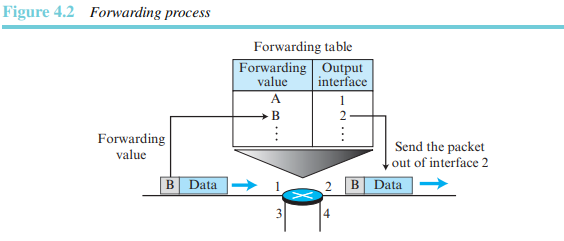
오류 제어
오류 제어는 네트워크 계층에서 구현될 수 있지만 인터넷 네트워크 계층을 설계할 때 네트워크 계층이 전달하는 데이터를 보호하기 위한 오류 제어를 고려하지 않았다. 이는 각 라우터에서 패킷이 단편화될 때마다 네트워크 계층에서 오류를 검사하는 것이 비효율적이라 여겨졌기 때문이다.
그러나 네트워크 계층을 설계할 때 데이터그램이 아닌 헤더의 훼손을 방지하기 위한 검사합 필드를 추가하였다. 이 검사합은 두 홉간 및 단대단 간의 데이터 전송 시 데이터그램의 헤더가 변경되거나 훼손되는 것을 방지해 준다.
인터넷 상의 네트워크 계층이 직접적으로 오류 제어 서비스를 제공해주지는 않지만, 데이터그램이 폐기되거나 헤더 상에 알 수 없는 정보가 있을 때 오류 제어를 할 수 있는 보조 프로토콜인 ICMP를 제공한다.
흐름 제어
흐름 제어는 송신자가 수신자가 허용할 수 있을 만큼의 데이터만 보내도록 조절해준다. 데이터의 흐름을 제어하기 위해 수신자는 데이터를 감당할 수 없다는 것을 알리기 위한 피드백을 전송해야 한다.
그러나 인터넷의 네트워크 계층은 직접적으로 흐름 제어를 제공하지 않는다. 수신측의 준비와는 상관없이 송신측에서 데이터그램이 준비되면 바로 전송한다.
네트워크 계층에 흐름 제어가 포함되지 않은 것은 몇 가지 이유가 있다. 첫째, 네트워크 계층에 오류 제어가 없기 때문에 수신측의 네트워크 계층 역할이 간단해지고 이는 곧 네트워크 계층이 더 많은 데이터를 처리할 수 있도록 해주기 때문이다. 둘째, 네트워크 계층에서 전달되는 데이터를 보관할 수 있기 때문이다. 셋째, 흐름 제어는 네트워크 계층을 사용하는 대부분의 상위 계층에서 제공되므로 네트워크 계층에서의 추가적인 흐름 제어를 수행하는 것은 네트워크 계층을 더욱 복잡하게 만들고 전체 시스템을 비효율적으로 만들기 때문이다.
혼잡 제어
네트워크 계층에서의 혼잡은 인터넷의 공간에 너무 많은 데이터그램이 존재하는 경우이다. 송신자가 보낸 데이터그램이 네트워크나 라우터의 처리 성능을 넘어설 경우 혼잡이 발생한다. 이 경우 몇몇 라우터는 데이터그램 중 일부를 놓칠 수도 있다. 그러나 데이터그램을 처리하지 못할수록 상위 계층의 오류 제어 때문에 송신자는 손실된 패킷의 복사본을 계속 보내게 되어 상황을 더욱 악화시키게 된다. 혼잡이 지속되면 때때로 시스템이 다운되고 데이터그램이 하나도 전달되지 못하는 지경에 이를 수 있다. 혼잡 제어는 현재 인터넷에 구현되어 있지는 않다.
서비스 품질
인터넷에서 멀티미디어 통신과 같은 새로운 어플리케이션을 사용 가능하기 때문에 서비스 품질이 더욱 중요하게 되었다. 인터넷은 이런 어플리케이션을 지원하기 위해 보다 나은 서비스 품질을 제공하며 발전하였다. 그러나 네트워크 계층을 그대로 두기 위해, 이런 기능의 대부분은 상위 계층에 구현되어야 한다.
보안
인터넷을 설계하던 당시 적은 수의 대학 측 사용자들이 연구 목적으로 사용할 용도로 설계하였기에 보안은 고려대상이 아니었다. 그러나 보안은 커다란 관심사이다. 비연결형 네트워크 계층에 보안성을 제공하기 위해, 비연결형 서비스를 연결 지향형 서비스로 변경할 수 있는 다른 가상의 단계(IPSec)가 필요하다.
4.1.2 패킷 교환
라우터는 전기 스위치가 입력단의 전기를 출력단의 전기로 연결하는 것과 같이 입력 포트와 출력 포트 사이의 연결을 만드는 교환기이다.
비록 데이터 통신의 기법이 회선 교환과 패킷 교환방식으로 구분되지만, 네트워크 계층에서 사용되는 데이터는 패킷이므로 패킷 교환만 사용된다.
패킷 교환 네트워크의 연결 장치는 패킷을 최종 목적지로 어떻게 보낼지 결정해야 한다. 오늘날 패킷 교환 네트워크에서 패킷의 경로를 찾기 위해 데이터그램 방식과 가상 회선 방식의 두 가지 방식을 사용한다.
데이터그램 방식: 비연결형 서비스
인터넷이 처음 만들어질 때 네트워크 계층의 간소화를 위해 모든 패킷을 독립적으로 처리하는 비연결형 서비스를 제공하도록 설계되었다. 네트워크 계층의 기본 개념은 발신지에서 목적지로 패킷을 전달하는 것이었다. 이 방식에서는 메시지의 패킷들이 목적지까지 같은 경로나 혹은 다른 경로로 전달될 수 있다. 그림 4.3은 이런 경우를 보여준다.
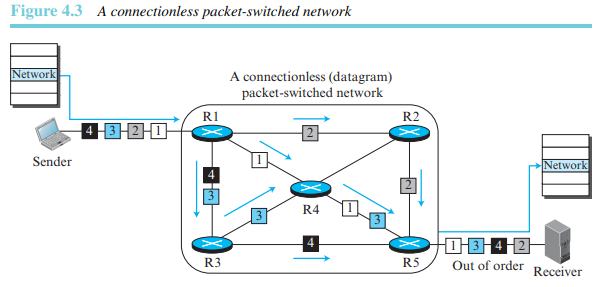
네트워크 계층에서 비연결형 서비스를 제공할 때 인터넷 상의 모든 패킷은 각각 독립적인 개체였다. 같은 메시지에 속한 것이라 할지라도 서로 연관성이 없었다. 이런 네트워크 형태의 교환기를 라우터라 하였다. 한 메시지에 속한 패킷은 같은 메시지에 속한 패킷 다음에 갈 수도, 다른 발신지에서 전송된 다른 메시지에 속한 패킷 다음에 갈 수도 있다.
각 패킷은 패킷의 헤더에 포함된 발신지 주소와 목적지 주소 정보를 기반으로 라우팅된다. 라우터는 목적지 주소만 참조하여 경로를 라우팅한다. 발신지 주소는 패킷이 폐기될 때 오류 메시지를 전송하기 위해 사용된다. 그림 4.4에서 이런 경우의 포워딩 과정을 볼 수 있다.
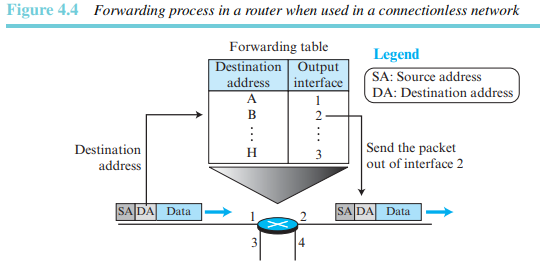
데이터그램 방식에서 포워딩 결정은 패킷의 목적지 주소에 의해 결정된다.
가상 회선 방식: 연결 지향형 서비스
연결 지향형 서비스(또는 가상 회선 방식)에서는 한 메세지에 속한 모든 패킷은 연관성이 있다. 메시지의 모든 데이터그램이 전송되기 전에 데이터그램을 위한 가상의 경로가 설정된다. 연결이 설정된 뒤, 데이터그램을 모두 같은 경로로 전송할 수 있다. 이런 종류의 서비스에서는 패킷은 발신지와 목적지 주소뿐만 아니라 패킷이 지나가야 하는 가상 경로를 정의하는 가상 회선 인식자와 같은 흐름 레이블을 포함해야 한다. 패킷이 흐름 레이블을 포함하는 것으로 가정하고 흐름 레이블이 어떻게 정해지는지 설명한다. 이런 레이블의 사용으로 전송단계 중에 발신지와 목적지의 주소가 불필요하다고 생각할 수 있지만, 네트워크 계층에서 여전히 이 주소들이 필요하다. 이는 경로 중의 일부분이 여전히 비연결형 서비스를 사용하고 있을 수도 있기 때문이다. 그림 4.5는 연결 지향형 서비스의 개념을 보여준다.
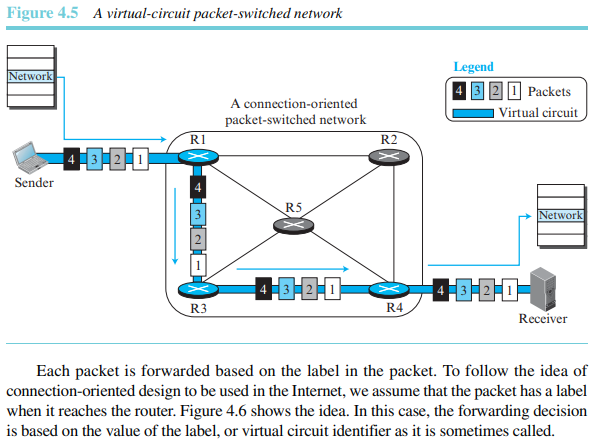
각 패킷은 패킷의 레이블에 따라 전달된다. 인터넷에서 연결 지향형 설계의 방식을 따르기 위해 라우터에 도착하는 패킷에 레이블이 있다고 가정한다. 그림 4.6은 이런 개념을 보여준다. 이 경우, 포워딩 결정은 레이블의 값 혹은 가상 회선 확인자로 불리는 것에 의해 결정된다.
연결 지향형 서비스를 만들기 위해 설정, 데이터 전송, 연결 해제의 3단계 과정이 사용된다. 설정 단계에서는 연결 지향형 서비스를 위해 송신자와 수신자의 발신지와 목적지 주소로 테이블 항목을 생성한다. 연결 해제 단계에서는 라우터 상의 해당 테이블 항목을 삭제한다.
가상 회선 방식에서 포워딩은 패킷의 레이블에 의해 결정된다.
-
설정 단계
설정 단계에서는 가상 회선을 위한 항목을 라우터가 생성한다. 예를 들어, 발신지 A가 목적지 B로 가상 회선을 생성한다고 하자. 송신측과 수신측은 요청 패킷과 확인응답 패킷의 두 개 보조 패킷을 교환한다.
(1) 요청 패킷
발신지가 목적지로 전송한다. 이 보조 패킷은 발신지와 목적지 주소 정보를 가지고 있다. 그림 4.7은 이 과정을 보여준다.
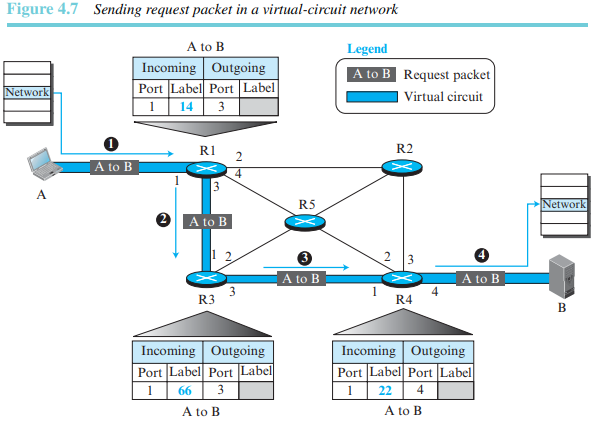
(2) 확인응답 패킷
교환 테이블 내의 항목을 완성시킨다. 그림 4.8은 이 과정을 보여준다. -
데이터 전송 단계
모든 라우터가 특정 가상 회선을 위한 포워딩 테이블을 완성하면 하나의 메시지에 속한 네트워크 계층 패킷들을 순서대로 전송할 수 있다. -
연결 해제 단계
발신지 A가 목적지 B로 모든 패킷을 보내고 난 뒤, 연결 해제 패킷으로 보내는 특수 패킷을 전송한다. 목적지 B는 확인 패킷으로 회신한다. 모든 라우터는 테이블 내에 상응하는 항목을 삭제한다.
4.1.3 네트워크 계층 성능
네트워크 계층을 사용하는 상위 계층 프로토콜은 이상적인 서비스를 원하지만 네트워크 계층은 완벽하지 않다. 네트워크의 성능은 지연, 처리량, 패킷 손실률로 측정 가능하다.
지연
패킷이 발신지에서 목적지까지 전송될 때 필연적ㅇ로 지연이 발생한다. 네트워크 상의 지연은 전송 지연, 전파 지연, 처리 지연, 큐 내부의 지연이 있다.
-
전송 지연
발신지 호스트나 라우터는 패킷을 즉시 보낼 수 없다. 송신자는 전송해야 할 패킷에 하나하나 비트 정보들을 추가해야 한다.
-
전파 지연
전송 매체를 통해 A지점부터 B지점까지 1비트가 전달되는 데 걸리는 시간이다.
-
처리 지연
라우터나 목적지 호스트가 입력 포트로 패킷을 받고, 헤더를 제거하고, 오류 탐지를 수행한 뒤, 출력 포트로 패킷을 보내거나(라우터의 경우) 상위 계층 프로토콜로 패킷을 전달(목적지 호스트의 경우)하는 데 걸리는 시간이다.
-
큐 내부의 지연
일반적으로 라우터에서 발생한다. 라우터는 각 입력 포트에 처리할 패킷을 보관할 큐와 출력 포트에 전송할 패킷을 보관할 큐를 각각 가지고 있다. 큐 내부의 지연은 라우터의 입력 큐와 출력 큐에서 패킷이 대기하는 시간을 측정하여 구한다.
-
전체 지연
전체 경로상의 라우터의 개수 을 알고 송신자, 라우터, 수신측이 각각 같은 지역을 가지고 있다고 가정할 때 패킷에 발생할 전체 지연은 다음과 같다.
처리량
처리량(througput)은 초당 한 지점을 지나는 비트의 수로 정의되는 것으로, 해당 지점의 실질적인 전송률이다. 발신지에서 목적지까지의 경로에서 패킷은 서로 다른 전송률을 가진 다수의 링크(네트워크)를 통과할 수 있다. 이 경우 전체 처리량을 어떻게 정의할 수 있는가? 그림 4.10과 같이 각기 다른 전송률을 가진 세 개의 링크가 있다고 가정해 보자.
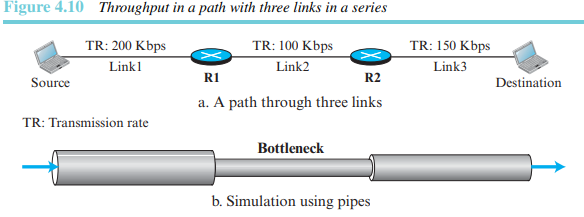
평균 전송량은 가장 작은 반경을 가진 병목지점의 파이프에 의해 결정된다. 일반적으로 연속된 경로에서
인터넷 상에서 일반적으로 데이터가 통과하는 실제 경우는 그림 4.11과 같이 두 개의 다른 액세스 네트워크과 인터넷 백본을 지나는 경우이다.

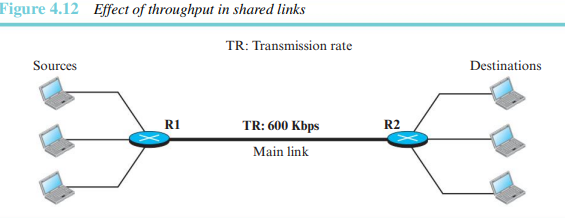
처리량을 고려하기 위해서는 다른 상황도 생각해 봐야 한다. 두 라우터 사이의 링크가 항상 플로우 A에 할당된 것이 아니다. 라우터는 여러 발신지로부터 플로우를 수신받을 수도 있고 여러 발신지로 플로우를 전송할 수 있다. 이 경우, 두 라우터 사이의 링크의 전송률이 플로우 간 공유되기 때문에 처리량을 계산할 때 이 점을 고려해야 한다. 그림 4.12에서 링크가 세 경로에 의해 공유되므로 실제 경우 주경로의 처리량은 200Kbps밖에 되지 않는다.
패킷 손실
통신의 성능에 큰 영향을 미치는 다른 요소 중 하나는 전송 중 손실되는 패킷의 수이다. 라우터가 다른 패킷을 처리하는 동안 패킷은 자신의 순서가 될 때까지 입력 버퍼에서 대기해야 한다. 그러나 라우터는 한정된 버퍼를 가지고 있다. 따라서 버퍼가 가득 찰 경우 패킷을 수신하지 못하고 폐기하게 된다. 인터넷의 네트워크 계층에서 패킷 손실이 발생하면 해당 패킷을 재전송하는데, 이 경우 더 많은 오버플로우와 패킷 손실을 일으킬 수 있다.
4.1.4 네트워크 계층의 혼잡
인터넷 모델에서 네트워크 계층의 혼잡을 명시적으로 다루지는 않지만, 네트워크 계층의 혼잡을 공부하는 것이 전송 계층의 혼잡이 발생하는 이유와 네트워크 계층에 사용 가능한 해결책을 찾는 데 도움이 될 수 있다. 네트워크 계층의 혼잡은 앞서 언급된 처리량과 지연의 두 가지 사항과 관련이 있다. 그림 4.13은 부하에 따른 지연과 처리량의 성능을 보여주고 있다.
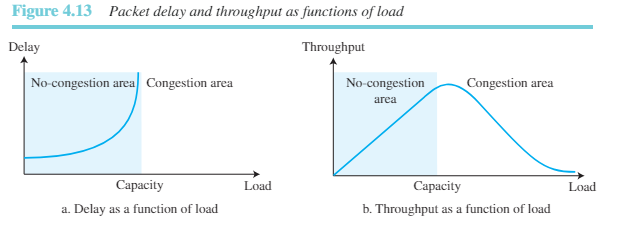
부하가 네트워크의 용량보다 훨씬 적을 경우 지연(delay)은 최소화된다. 이 최소 지연은 무시해도 좋은 전파 지연과 처리 지연으로 이루어져 있다. 그러나 부하가 네트워크 용량에 도달하면 전체 지연에 큐 내부의 지연이 더해지기 때문에 지연이 급격하게 높아진다. 부하가 네트워크 용량을 넘어서게 되면 지연은 무한대가 된다.
부하가 네트워크 용량보다 낮을 경우에 처리량은 부하에 비례하여 증가한다. 부하가 네트워크 용량에 도달하면 처리량이 일정하게 유지될 것 같지만 실제로 처리량은 급속하게 감소한다. 이는 라우터에서 패킷을 폐기하기 때문이다. 부하가 용량을 넘어서면 큐는 가득 차게 되고 라우터는 몇몇 패킷을 폐기해야 한다. 패킷이 목적지에 도달하지 못하면 타임아웃 기법을 사용하여 패킷을 재전송하기 때문에 패킷을 폐기하여도 네트워크 상의 수는 줄지 않는다.
혼잡 제어
혼잡 제어는 혼잡이 발생하기 전에 그것을 방지하거나 혼잡이 발생한 후 그것을 없애주는 역할을 하는 기술이다. 일반적으로 혼잡 제어는 혼잡을 방지하기 위한 open-loop 혼잡 제어와 혼잡을 제거하기 위한 closed-loop 혼잡 제어로 나누어진다.
-
open-loop 혼잡 제어
open-loop 혼잡 제어는 혼잡이 발생하기 전 그것을 방지하기 위한 정책을 수행한다. 이 기술에서 혼잡 제어는 발신지나 목적지에서 수행된다. 다음은 혼잡을 방지할 수 있는 정책의 간단한 예시이다. open-loop 혼잡 제어는 혼잡을 감지하고, 수동적이며, 방어적이다.
1) 재전송 정책: 때때로 재전송은 불가피하다. 송신자가 송신한 패킷이 손실되거나 훼손된 것을 인식하면 패킷은 재전송되어야 한다. 일반적으로 재전송은 네트워크 내의 혼잡을 증가시킨다. 그러나 좋은 재전송 정책은 혼잡을 방지할 수 있다. 재전송 정책과 재전송 타이머는 혼잡을 방지하면서 가장 효율적이도록 설계되어야 한다.
2) 윈도 정책: 송신측의 윈도 종류는 혼잡에 영향을 미친다. 혼잡 제어에서 SR 윈도는 GBN 윈도보다 나은 성능을 보인다. GBN 윈도에서 패킷의 타이머가 만료되면 수신측에 잘 도착한 패킷을 포함한 여러 패킷이 재전송될 수 있다. 이런 중복이 혼잡한 상황을 더욱 악화시킨다.
3) 확인응답 정책:
수신자에 의한 확인응답 정책도 혼잡에 영향을 미친다. 수신자가 수신한 모든 패킷을 확인응답하지 않으면 송신자가 천천히 패킷을 보내도록 만들고 이는 혼잡을 줄이게 된다. 여기에는 많은 방식이 있다. 수신자는 수신할 패킷이 있거나 특정 타이머가 만료되면 확인응답을 보내는 것이다. 혹은 수신자는 한 번에 N개의 패킷만 확인응답할 수 있다. 여기서 중요한 것은 확인응답도 네트워크 부하의 일종이라는 것이다. 더 작은 확인응답을 보내면 네트워크의 부하를 줄일 수도 있다.
4) 폐기 정책: 라우터에서 좋은 폐기 정책은 혼잡을 방지하면서 전송되는 것에 영향을 주지 않는다. 예를 들어 오디오 전송 시, 혼잡이 발생하려고 할 때 덜 민감한 패킷을 폐기하도록 정책이 수행되면 오디오의 질은 유지되면서 혼잡을 방지하거나 낮출 수 있다.
5) 수락 정책: 서비스 품질 기술인 수락 정책은 가상 회선 네트워크에서 혼잡을 방지할 수 있다. 교환기는 플로우를 네트워크고 허가하기 전에 플로우가 요구하는 서비스 품질을 검사한다. 네트워크 상에 혼잡이 있거나 혼잡 발생이 예상되는 경우, 라우터는 가상 회선 연결 설정을 거부할 수 있다. -
closed-loop 혼잡 제어
closed-loop는 혼잡이 발생한 뒤 혼잡을 줄이기 위한 적극적인 방법을 쓰는 기술이다.
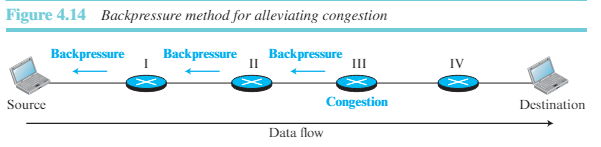
1) Backpressure: Backpressure 기법은 수신 노드가 데이터를 전송하는 발신 노드로부터 수신을 중단하는 것이다. 이는 발신 노드를 혼잡에 빠지게 할 수 있으며, 발신 노드들도 차례로 데이터의 상위 발신노드로부터 데이터 수신을 거부하게 한다. Backpressure 기법은 노드 간 혼잡 제어 기술로 발신지를 향해 데이터의 흐름과 역방향으로 전파된다. Backpressure 기법은 노드가 데이터의 플로우를 전송하는 노드를 알고 있는 가상 회선 네트워크에만 적용이 가능하다. 그림 4.14는 Backpressure의 원리를 보여준다.
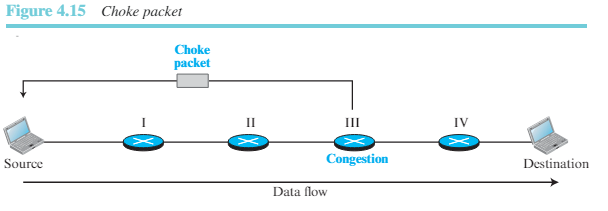
2) 초크 패킷: 초크 패킷은 혼잡을 알리기 위해 노드에서 발신지로 전송되는 패킷이다. 이때 초크 패킷 방식과 Backpressure 방식의 차이점을 알아야 한다. Backpressure에서는 경고 메시지가 자신의 상위 라우터로 전달되어 결국 발신지 노드로 도착하게 된다. 그러나 초크 패킷 방식은 혼잡이 발생한 라우터에서 발신지로 직접 전송된다. 패킷이 거쳐가는 중간 노드는 경고를 받지 않는다. ICMP에서 이러한 제어 방식의 예를 볼 수 있다. 인터넷 상의 라우터가 IP 데이터그램을 처리하지 못할 경우, 패킷 중 일부분을 폐기하고 발신지 호스트에게 ICMP quench 메시지를 전송하여 혼잡을 알린다. 이 메시지는 중간 노드에서 아무런 처리를 거치지 않고 발신지 노드로 직접 전달된다. 그림 4.15는 초크 패킷의 원리를 보여준다.
3) 암묵적인 신호: 암묵적인 신호 방식에서는 혼잡 노드와 발신지 간에 신호를 주고받지 않는다. 발신지 노드는 다른 증상으로부터 네트워크 상에 혼잡이 있을 것으로 추측한다. 예를 들어, 발신지가 여러 패킷을 보내고 일정시간동안 아무런 확인응답을 수신하지 못하면, 네트워크가 혼잡한 것으로 간주할 수 있다. 수신한 확인응답의 지연도 네트워크 혼잡을 나타낼 수 있으므로 발신지는 전송을 늦추어야 한다.
4) 명시적인 신호 방식: 혼잡을 경험하는 노드는 발신지 또는 목적지 노드에 신호를 명시적으로 보낼 수 있다. 명시적 신호 방식은 초크 패킷 방식과 다르다. 초크 패킷 방식은 개별 패킷 혼잡 제어를 위해 사용된다. 그러나 명시적인 신호 방식은 데이터를 전송하는 패킷 내에 신호를 포함한다. 명시적인 신호 방식은 순방향 또는 역방향에서 발생한다.
4.1.5 라우터의 구조
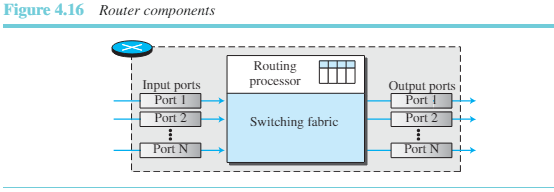
컴포넌트
라우터는 그림 4.16과 같이 입력 포트, 출력 포트, 라우팅 프로세서, 스위칭 패브릭의 네 가지로 구성되어 있다.
- 입력 포트
그림 4.17은 입력 포트의 다이어그램 기본동작을 보여준다.
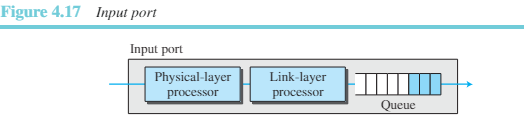
입력 포트는 라우터의 물리 계층과 링크 계층의 기능을 담당한다. 수신된 신호로부터 비트가 생성된다. 프레임을 역캡슐화하여 패킷을 추출하고 오류를 검사하며 훼손된 경우 이를 폐기한다. 이 과정을 마치면 패킷은 네트워크 계층에서 처리된다. 물리 계층 프로세서와 링크 계층 프로세서 외에 입력포트는 스위칭 패브릭에 직접 전달되기 전 패킷을 보관하기 위한 버퍼(큐)를 갖고 있다. - 출력 포트
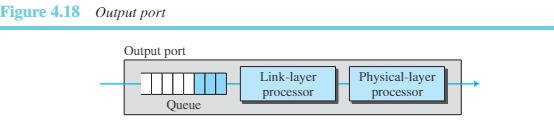
출력 포트는 입력 포트와 같은 기능을 수행하지만 이를 역순으로 수행한다. 출력될 패킷이 큐에 들어오면 각 패킷은 프레임으로 캡슐화가 되고 최종적으로 물리 계층에서 프레임을 전기적 신호로 생성하여 재전송한다. 그림 4.18은 출력 포트의 다이어그램 개략을 보여준다.
- 라우팅 프로세서
네트워크 계층의 기능을 수행한다. 패킷을 전송할 출력 포트번호와 다음 홉 주소를 찾기 위해 패킷의 목적지 주소를 참조한다. 라우팅 프로세서가 포워딩 테이블에서 검색하기 때문에 이런 동작은 테이블 검색으로도 알려져 있다. 최신 라우터에는 라우팅 프로세서의 이런 기능을 입력 포트에서 작동하도록 하여 더 신속하게 처리하도록 하고 있다. - 스위칭 패브릭
라우터에서 가장 어려운 일은 패킷을 입력 큐에서 출력 큐로 전달하는 것이다. 이 작업의 수행 속도가 입출력 큐의 크기와 패킷 전달의 전체 지연에 영향을 준다. 과거 라우터가 고정된 컴퓨터였을 때, 컴퓨터의 메모리나 버스가 스위칭 패브릭으로 사용되었다. 입력 큐가 패킷을 메모리에 저장하고 출력 큐가 메모리로부터 패킷을 읽어오는 방식이었다. 요즘에는 라우터에서 다양한 방식으로 스위칭 패브릭을 사용한다.
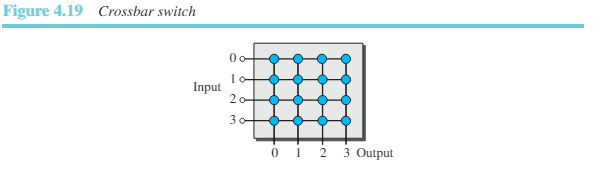
1) 크로스바 스위치: 가장 단순한 형태의 패브릭은 그림 4.19와 같은 크로스바 스위치이다. 크로스바 스위치는 각 교환점(crosspoint)에서 전기적인 마이크로스위치를 사용하여 그리드 형태로 n개의 입력과 n개의 출력을 연결한다.
2) 반얀 스위치:
크로스바 스위치보다 현실적인 것은 그림 4.20과 같은 반얀 스위치이다.
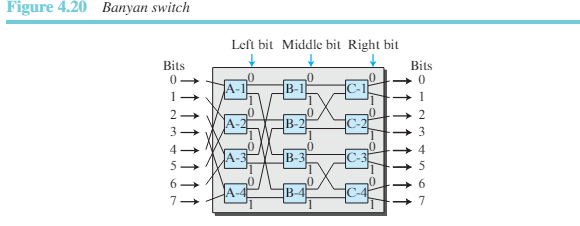
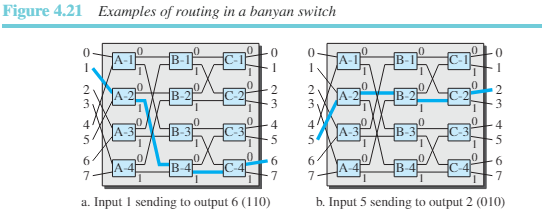
반얀 스위치는 마이크로스위치를 사용한 다단식 스위치로 출력 포트를 기반으로 패킷을 라우팅하는 각 단은 이진 문자열로 표시된다. n개의 입력과 n개의 출력에 대하여 여기서는 개의 단과 각 단에 개의 마이크로스위치를 가지고 있다. 첫 번째 단에서는 비트 문자열 중 가장 높은 순서의 비트에 따라 패킷을 라우팅한다. 두 번째 단에서는 비트 문자열에서 두 번째로 높은 비트에 따라 패킷을 라우팅한다. 그림 4.21은 8개의 입력과 8개의 출력이 있는 반얀 스위치를 보여준다. 단의 총수는 로 3개이다. 1번 입력 포트에 도착한 패킷이 6번 출력 포트()로 전달되어야 한다고 가정해보자. 첫 번째 마이크로스위치(A-2)는 패킷의 첫 번째 비트(1)로 라우팅한다. 두 번재 마이크로스위치(B-4)는 패킷의 두 번째 비트(1)로 라우팅한다. 세 번째 마이크로스위치(C-4)는 패킷의 세 번째 비트(0)로 라우팅한다.
3) 배처-반얀 스위치: 반얀 스위치의 문제점은 두 개의 패킷이 같은 출력 포트로 전달되지 않을 때마저도 내부 충돌이 발생할 수 있다는 것이다. 이 문제는 도착한 패킷을 목적지 포트별로 정렬하여 해결할 수 있다. K.E.배처는 반얀 스위치 앞에 사용되는 스위치를 설계하여 들어오는 패킷을 최종 목적지별로 정렬하도록 하였다. 두 스위치의 조합을 배처-반얀 스위치라 한다.
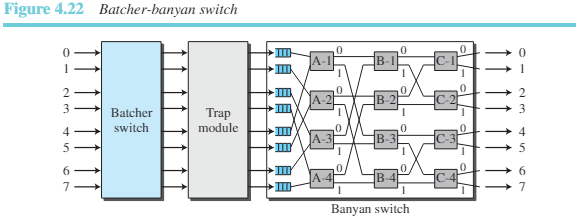
배처 스위치는 통합 하드웨어 기술을 사용하였다. 보통 트랩으로 불리는 하든 하드웨어 모듈이 반얀 스위치와 배처 스위치 사이에 추가된다. 트랩 모듈은 같은 목적지로 향하는 중복된 패킷이 연속적으로 반얀 스위치에 입력되는 것을 방지해 준다. 하나의 틱에는 각각 다른 목적지로 전송되는 패킷만 허용한다. 만약 같은 목적지로 향하는 패킷이 둘 이상이라면 다음 틱을 기다려야 한다.
4.2 네트워크 계층 프로토콜
TCP/IP에 네트워크 계층이 어떻게 구현되어 있는지 설명한다. 네트워크 계층의 프로토콜은 여러 버전을 거쳐왔으며 현재 사용되고 있는 버전 4에 대해 집중한다.
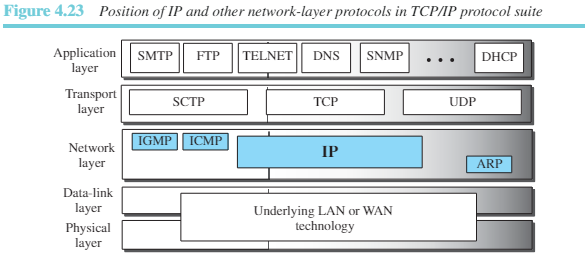
네트워크 계층에서 버전 4는 하나의 주 프로토콜과 3개의 보조 프로토콜로 생각할 수 있다. 주 프로토콜인 IPv4는 패킷화, 포워딩, 그리고 네트워크 계층에서 패킷 전달을 수행한다. ICMPv4는 IPv4를 도와 네트워크 계층의 전송 중 발생할 수 있는 오류를 제어한다. IGMP는 IPv4의 멀티캐스트를 보여준다. ARP는 네트워크 계층 주소와 링크 계층 주소를 매핑시킨다. 그림 4.23은 TCP/IP에서 위 4가지 프로토콜의 위치를 보여준다.
IPv4는 비신뢰적이고 비연결형의 데이터그램 프로토콜로 최선형 전송 서비스이다. 여기서 최선형 전송의 의미는 IPv4 패킷이 훼손되거나 손실, 순서에 맞지 않게 도착, 지연되어 네트워크에 혼잡을 발생시킬 수 있음을 뜻한다. 만약 신뢰성이 중요하다면 IPv4는 TCP처럼 신뢰성 있는 전송계층 프로토콜과 함께 사용되어야 한다.
또한 IPv4는 데이터그램 방식의 패킷 교환 네트워크에서 비연결형 프로토콜이다. 이는 각 데이터그램이 독립적으로 전송되며 각 데이터그램이 목적지로 갈 때 서로 다른 경로로 전달될 수 있음을 의미한다. 이로 인해 같은 발신지에서 목적지로 향하는 데이터그램이 순서에 맞지 않게 전송될 수 있다. 또한 몇몇 패킷은 전송 중 훼손되거나 분실될 수 있다. IPv4는 이러한 모든 문제를 상위 계층에서 책임지도록 하고 있다.
4.2.1 IPv4 데이터그램 형식
그림 4.24는 데이터그램 형식을 보여준다. 데이터그램은 가변 길이의 패킷으로 헤더와 페이로드(데이터)로 이루어져 있다. 헤더는 20에서 60바이트의 길이이며 라우팅과 전송에 필수적인 정보를 갖고 있다. TCP/IP에서는 헤더를 4바이트 섹션으로 보이는 것이 일반적이다.
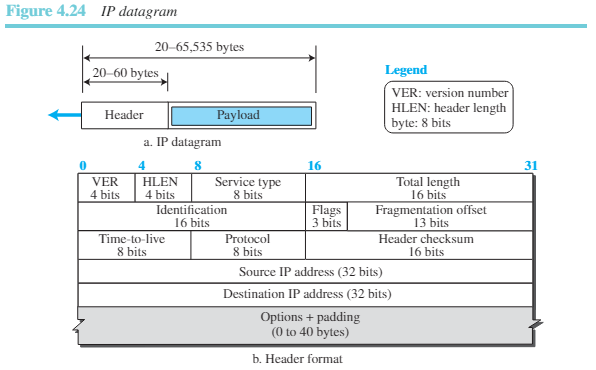
다음은 각 필드에 대한 간단한 설명이다.
- 버전 숫자: 4비트의 VER 필드는 IP 프로토콜의 버전을 정의한다.IPv4는 4의 값을 가진다.
- 헤더 길이: 4비트 길이의 HLEN 필드는 데이터그램 헤더의 전체 길이를 4바이트 워드로 표현한다. IPv4 데이터그램은 가변의 헤더를 가진다.
- 서비스 유형: IP 헤더의 원안에서 이 필드는 데이터그램을 어떻게 처리할지를 정의하는 서비스의 유형(TOS)를 나타냈다. 지금은 서비스 구분()을 위한 것으로 재정의되었다.
- 전체 길이: 이 16비트의 필드는 IP 데이터그램의 전체 바이트 수를 정의한다. 16비트의 숫자는 65,535까지의 길이를 나타낼 수 있다.
- 식별자, 플래그, 분할 오프셋: 이 세 필드는 데이터그램의 크기가 기반 네트워크가 처리할 수 있는 크기보다 클 경우 필요한 IP 데이터그램의 분할과 관련이 있다.
- TTL: 데이터그램이 방문할 수 있는 최대 라우터의 수를 정의한다. 발신지 호스트가 데이터그램을 전송할 때 이 필드에 값을 저장한다. 이 값은 보통 일반 호스트 사이의 라우터의 수의 약 두 배로 정의된다.
- 프로토콜: TCP/IP에서 페이로드는 다른 프로토콜의 전체 패킷을 전송한다.
- 헤더 검사합: 헤더에 대한 오류를 검사한다.
- 발신지와 목적지 주소
- 옵션
- 페이로드
단편화
데이터그램은 다른 네트워크를 통해 전달될 수 있다. 각 라우터는 수신한 프레임에서 데이터그램을 역캡술화하고 처리한 후 다른 프레임으로 캡슐화한다. 수신한 프레임의 형식과 크기는 프레임이 막 통과한 물리 네트워크에서 사용되는 프로토콜에 따라 다르다. 예를 들어, LAN에서 WAN으로 연결하는 라우터의 경우 LAN 형식의 프레임을 수신하여 WAN 형식의 프레임으로 전송한다.
-
최대 전송 단위(MTU)
각 링크 계층 프로토콜은 각각 프레임 형식을 가지고 있다. 각 형식마다 갖는 하나의 특징은 캡슐화 가능한 페이로드의 최대 크기이다. 즉 데이터그램이 프레임으로 캡슐화될 때 데이터그램의 전체 크기는 네트워크에서 사용되는 HW와 SW에서 지정한 이 최대 크기보다 작아야 한다.
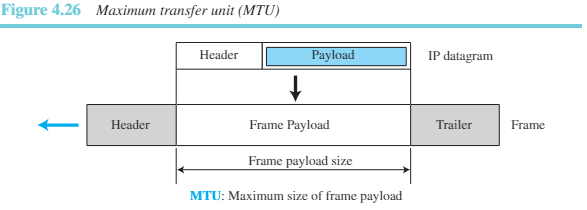
MTU의 크기는 각 물리적인 네트워크 프로토콜마다 다르다.
IP 프로토콜을 물리 네트워크와 독립적으로 만들기 위해 IP 데이터그램의 최대크기를 동일하게 65,536바이트로 하였다. 이는 언젠가 링크 계층 프로토콜에서 MTU로 이 크기를 사용할 때 전송을 보다 효율적으로 할 수 있게 해준다. 그러나 다른 물리 네트워크에서는 데이터그램을 전송하기 위해 분할해야 한다. 이를 단편화(fragmentaion)라 한다. -
단편화에 관련된 필드
IP 단편화에 관련된 식별자, 플래그, 단편화 오프셋의 세 개 필드가 있다.
16비트의 식별자 필드는 데이터그램이 전송된 발신지 호스트를 구분한다. 식별자와 IP 주소의 조합으로 발신지를 유일하게 구분할 수 있다. 유일함을 보장하기 위해 IP 프로토콜은 카운터를 사용한다. 카운터는 양수로 초기화되어 있다. IP 프로토콜이 데이터그램을 전송할 때 현재 카운터 값을 식별자 필드에 복사하고 카운터를 1 증가시킨다. 단편화될 때 식별자 필드의 값이 모든 단편에 동일하게 복사된다.
3비트의 플래그 필드는 세 가지 플래그를 정의한다. 가장 왼쪽 비트는 사용되지 않는다. 두 번째 비트는 단편화 금지 비트이다. 1이면 단편화 금지이다. 세 번째 비트는 추가 단편화 비트이다. 1이면 데이터그램이 마지막 단편이 아니고 다른 단편이 더 있음을 의미한다.
13비트의 단편화 오프셋 필드는 전체 데이터그램에서 해당 단편의 상대적인 위치를 나타낸다.
IPv4 데이터그램의 보안
IP 프로토콜에 적용 가능한 세 가지 보안 이슈는 패킷 도청, 패킷 변조 그리고 IP 스푸핑이다. -
IPSec
IPSec을 사용하여 세 가지 공격으로부터 IP 패킷을 보호할 수 있다. IPSec이 제공하는 네 가지 서비스는 다음과 같다.
1) 알고리즘과 키 정의
서로 안전한 채널을 생성하려는 두 개체는 보안의 목적으로 사용될 알고리즘과 키를 정의할 수 있다.
2) 패킷 암호화
첫 번째 단계에서 합의된 공유키와 알고리즘으로 두 개체가 교환하는 패킷은 암호화될 수 있다. 이는 패킷 도청 공격을 방지한다.
3) 데이터 무결성
데이터 무결성은 패킷이 전송 중 변조되지 않았음을 보장한다. 수신한 패킷이 데이터 무결성 검사를 통과하지 못하면 폐기된다. 이는 패킷 변조 공격을 방지한다.
4) 발신자 인증
IPSec은 패킷의 발신지를 인증하여 패킷이 다른 공격자에 의해 생성된 것이 아님을 보장해 준다. 이는 IP 스푸핑 공격을 방지한다.
