http://kimjmin.net/2022/07/2022-07-seoul-metro-v3-1/
위 링크의 개발자분이 하신 것을 그대로 하면서 기록한 것입니다.
따라하게 되신다면 위 링크가 더욱 자세하고 잘 적혀있으니 참고하시면 됩니다.
데이터다운
- 아래 링크에서 데이터를 다운 받아온다.
https://www.kaggle.com/datasets/kimjmin/seoul-metro-usage?resource=download
색인
seoul-metro-station-info.csv 색인
-
Machine Learning 메뉴에서 File 을 선택한다.
-
seoul-metro-station-info.csv파일을 업로드를 한다.
1) Data Visualizer 가 파일을 읽어들여 필드명과 매핑을 적절하게 설정 해 준다. 업로드를 한 다음에 import 버튼을 클릭한다.
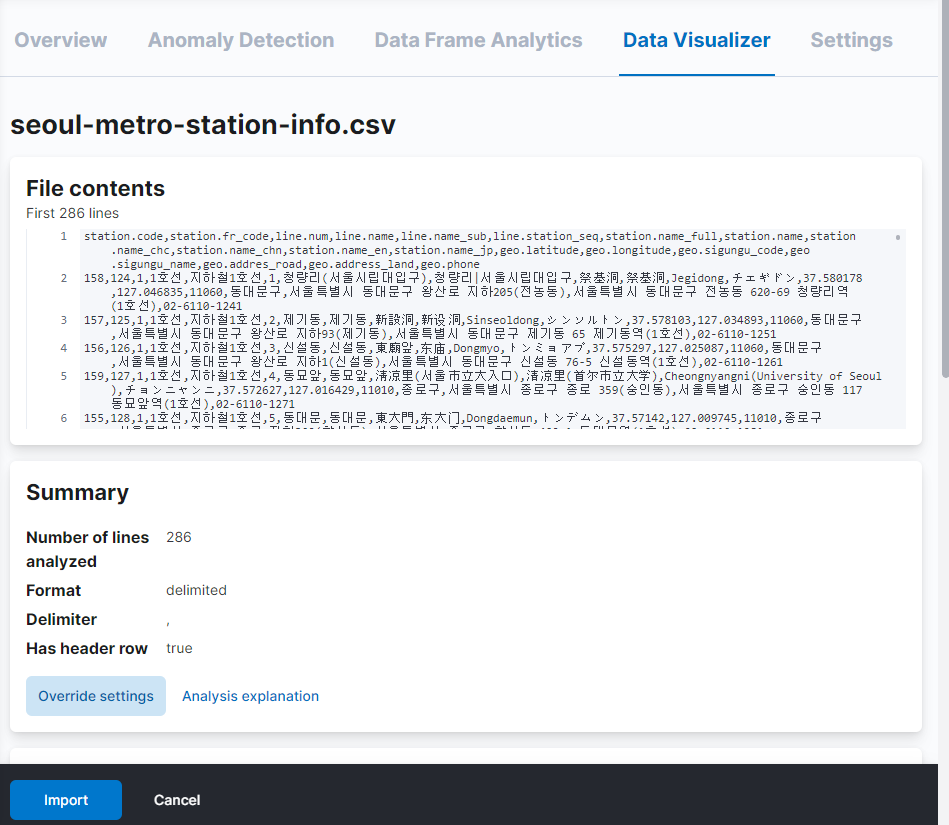
-
기본 설정으로 색인을 한 뒤 필요한 부분은 _reindex API 를 이용한다.
1) Data View 는 생성하지 않도록 create data view 는 체크를 해제 하고 색인할 인덱스 이름은seoul-metro-station-info-temp로 한다.
import 버튼을 눌러 업로드 한 파일의 색인을 시작하도록 한다.
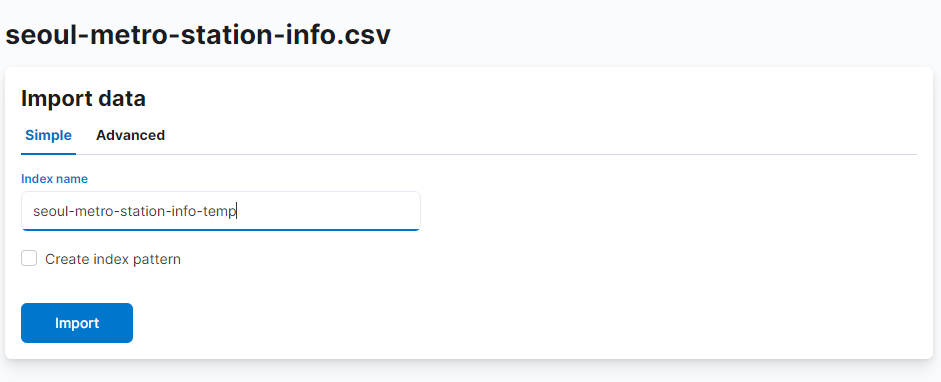
-
285개의 데이터가 색인이 끝났다.
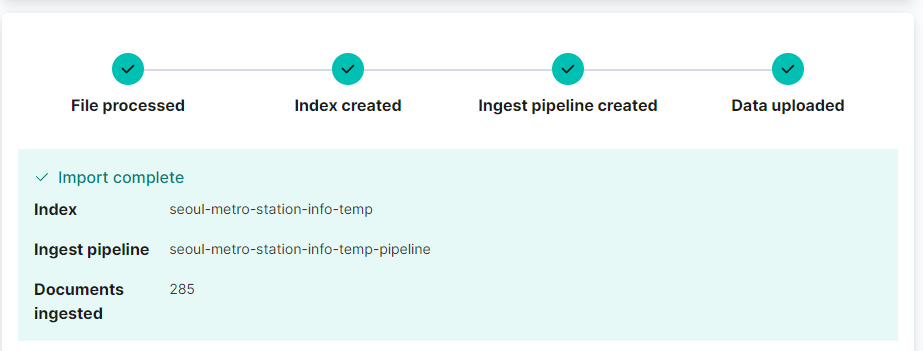
-
Dev Tools에서 확인한다.
Dev Tools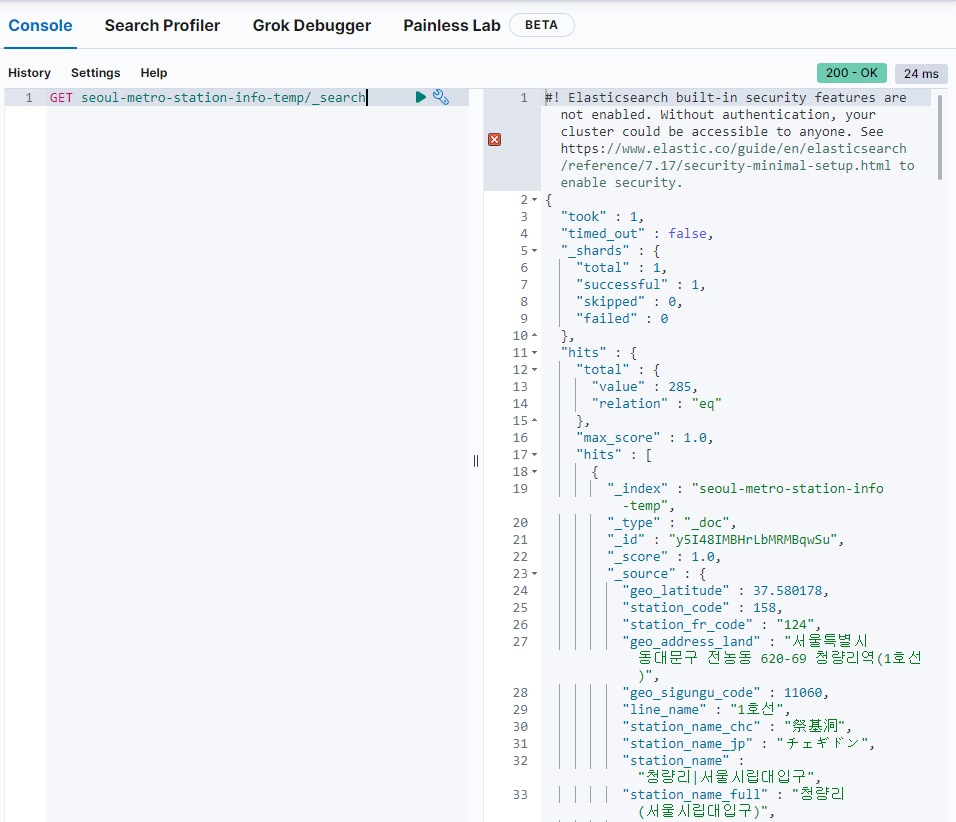
seoul-metro-station-info 매핑 설정
데이터는 잘 들어갔지만 매핑을 손보아야한다고 한다.
seoul-metro-station-info 인덱스를 만들면서 매핑을 아래와 같이 추가한다.
PUT seoul-metro-station-info
{
"mappings": {
"properties": {
"geo": {
"properties": {
"addres_road": { "type": "text" },
"address_land": { "type": "text" },
"latitude": { "type": "float" },
"longitude": { "type": "float" },
"phone": { "type": "text" },
"sigungu_code": { "type": "keyword" },
"sigungu_name": { "type": "keyword" },
"location": { "type": "geo_point" }
}
},
"line": {
"properties": {
"name": { "type": "keyword" },
"name_sub": { "type": "keyword" },
"num": { "type": "byte" },
"station_seq": { "type": "byte" }
}
},
"station": {
"properties": {
"code": { "type": "short" },
"fr_code": { "type": "keyword" },
"name": { "type": "keyword" },
"name_chc": { "type": "keyword" },
"name_chn": { "type": "keyword" },
"name_en": { "type": "text" },
"name_full": { "type": "keyword" },
"name_jp": { "type": "keyword" }
}
}
}
}
}필드 구조 정리를 위한 ingest pipeline
루트에 있는 필드들을 geo, line, station 필드의 하위 필드로 적절하게 나누어 저장을 할 것이다. seoul-metro-station-info-temp 인덱스의 도큐먼트들을 seoul-metro-station-info 로 재색인 할 때 사용할 ingest pipeline 을 다음과 같이 입력한다.
PUT _ingest/pipeline/seoul-metro-station-pipe
{
"processors": [
{ "set": { "field": "_id", "value": "{{station_code}}" } },
{ "set": { "field": "geo.location.lon", "value": "{{geo_longitude}}" } },
{ "set": { "field": "geo.location.lat", "value": "{{geo_latitude}}" } },
{ "convert": { "field": "geo.location.lon", "type": "float" } },
{ "convert": { "field": "geo.location.lat", "type": "float" } },
{ "split": { "field": "station_name", "separator": "\\|" } },
{ "split": { "field": "line_name_sub", "separator": "\\|" } },
{"rename": { "field": "geo_addres_road", "target_field": "geo.addres_road" } },
{"rename": { "field": "geo_address_land", "target_field": "geo.address_land" } },
{"rename": { "field": "geo_latitude", "target_field": "geo.latitude" } },
{"rename": { "field": "geo_longitude", "target_field": "geo.longitude" } },
{"rename": { "field": "geo_phone", "target_field": "geo.phone" } },
{"rename": { "field": "geo_sigungu_code", "target_field": "geo.sigungu_code" } },
{"rename": { "field": "geo_sigungu_name", "target_field": "geo.sigungu_name" } },
{"rename": { "field": "line_name", "target_field": "line.name" } },
{"rename": { "field": "line_name_sub", "target_field": "line.name_sub" } },
{"rename": { "field": "line_num", "target_field": "line.num" } },
{"rename": { "field": "line_station_seq", "target_field": "line.station_seq" } },
{"rename": { "field": "station_code", "target_field": "station.code" } },
{"rename": { "field": "station_fr_code", "target_field": "station.fr_code" } },
{"rename": { "field": "station_name", "target_field": "station.name" } },
{"rename": { "field": "station_name_chc", "target_field": "station.name_chc" } },
{"rename": { "field": "station_name_chn", "target_field": "station.name_chn" } },
{"rename": { "field": "station_name_en", "target_field": "station.name_en" } },
{"rename": { "field": "station_name_jp", "target_field": "station.name_jp" } },
{"rename": { "field": "station_name_full", "target_field": "station.name_full" } }
]
}1) seoul-metro-station-info-temp 인덱스의 도큐먼트들을 seoul-metro-station-info 로 재색인 한다.
POST _reindex
{
"source": {
"index": "seoul-metro-station-info-temp"
},
"dest": {
"index": "seoul-metro-station-info",
"pipeline": "seoul-metro-station-pipe"
}
}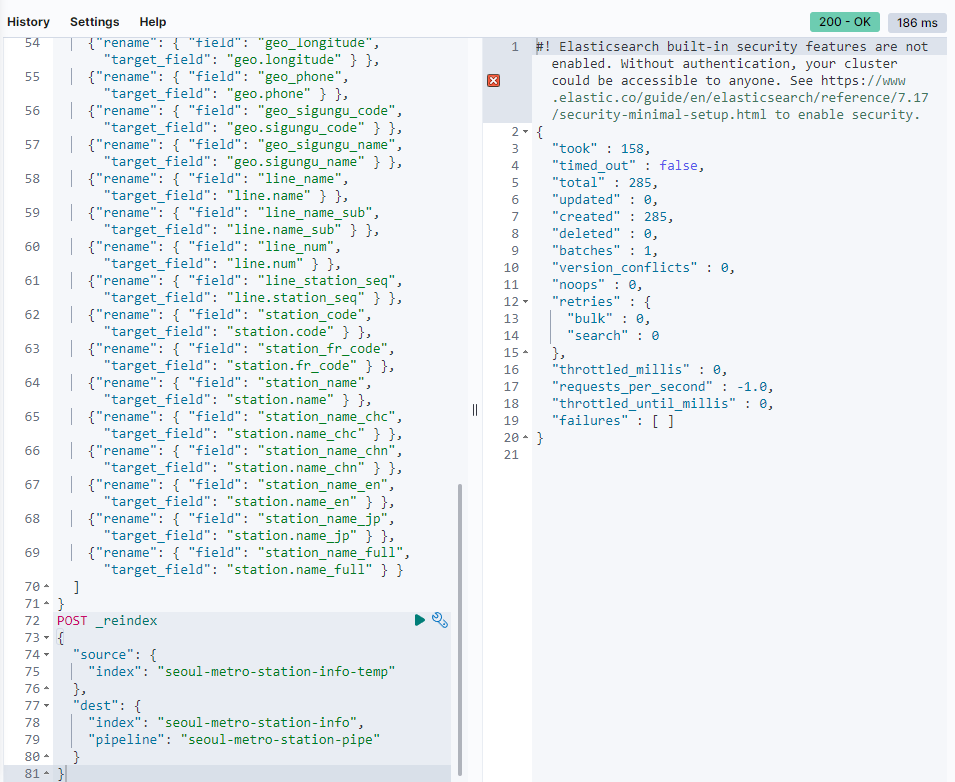
위와 같이 285 개의 도큐먼트가 created 되었다는 메시지가 나오면 성공이다. (난 성공이다)
- 재색인 작업이 끝났으면 seoul-metro-station-info-temp 인덱스와 seoul-metro-station-pipe ingest 파이프라인은 삭제해도 된다.
DELETE seoul-metro-station-info-temp
DELETE _ingest/pipeline/seoul-metro-station-pipe데이터 확장을 위한 스크립트 작업
승하차인원 집계 로그 데이터를 색인하면서 다양한 변환 작업을 해 줄 것이기 때문에 이를 위한 준비를 한다.
hour_and_week 스크립트
나중에 만들 대시보드에 아래와 같이 요일별, 시간대별 값을 보는 차트를 만들기 위해서 쿼리 시점에서 timestamp 필드값에서 요일과 시각 정보를 만드는 것 보다 별도의 시각값과 요일값 필드를 만들어 각 도큐먼트에 넣어 두는 것이 성능이나 자원 활용 면에서 여러가지로 유용하다.
timestamp 필드로부터 요일과 시각 정보를 추출해서 저장하는 스크립트를 만들고 _scripts 에 hour_and_week 라는 이름으로 미리 저장 하도록 한다.
PUT _scripts/hour_and_week
{
"script": {
"lang": "painless",
"source": """def ts=ctx[params['dateTimeField']];
def sdf=new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS");
def date=sdf.parse(ts);
def cal=Calendar.getInstance();
cal.setTime(date);
ctx[params['hourOfDayField']]=cal.get(Calendar.HOUR_OF_DAY);
def dowNum=cal.get(Calendar.DAY_OF_WEEK)-1;
def dowEn=["Sun","Mon","Tue","Wed","Thu","Fri","Sat"][dowNum];
def dowKr=["일","월","화","수","목","금","토"][dowNum];
ctx[params['dayOfWeekField']]=["num":dowNum, "en":dowEn, "kr":dowKr];"""
}
}이 스크립트에 사용되는 파라메터 3가지는 다음과 같다.
- dateTimeField : 시각과 요일 정보를 추출할 date 타입의 필드명
- hourOfDayField : 시각 값을 저장할 필드명
- dayOfWeekField : 날짜 값을 저장할 필드명
1) 스크립트를 테스트 하기 위해서 임시로 ingest pipeline 을 만들어보자. 이름은 temp_hourAndWeek 으로 했다.
PUT _ingest/pipeline/temp_hourAndWeek
{
"processors": [
{
"script": {
"id": "hour_and_week",
"params": {
"dateTimeField": "timestamp",
"hourOfDayField": "hour_of_day",
"dayOfWeekField": "day_of_week"
}
}
}
]
}2) timestamp 필드에 date 타입의 값이 있으면 hour_of_day 와 day_of_week 에 값을 넣도록 한다. ingest pipeline 을 _simulate 를 이용해서 테스트 해 보자.
POST _ingest/pipeline/temp_hourAndWeek/_simulate
{
"docs": [
{
"_source": {
"timestamp": "2022-07-01T12:00:00.000+0900"
}
}
]
}아래의 이미지와 같이 리턴된다.
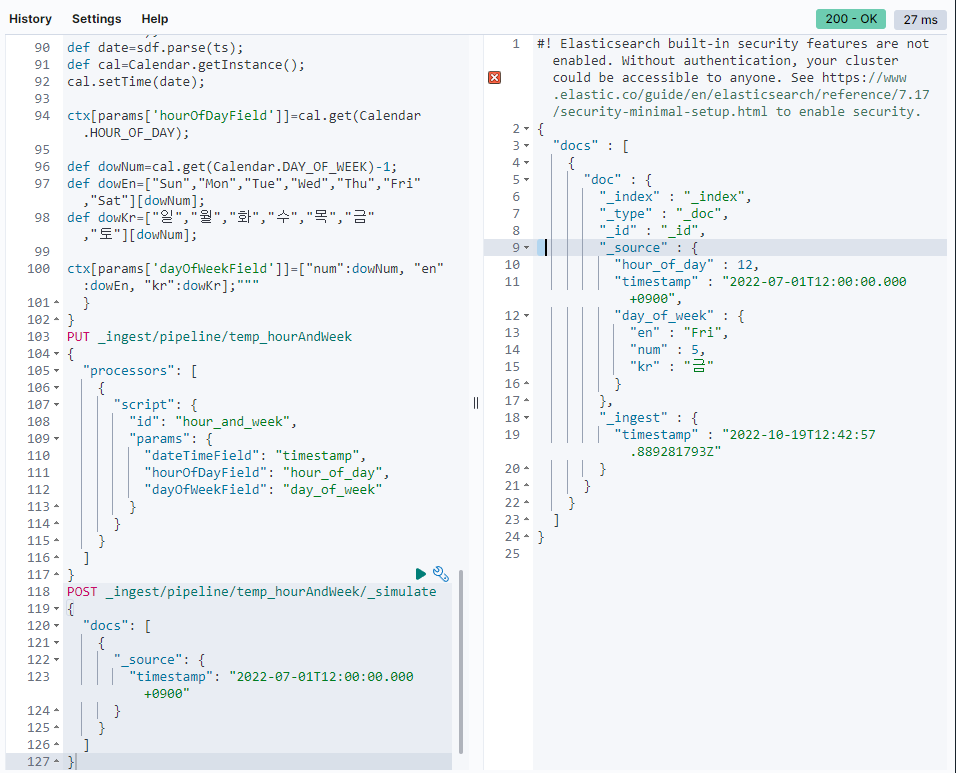
hour_of_day 필드에 시각 값인 12, day_of_week 필드에 하위 필드로 해당 날짜의 요일인 금요일이 영어, 한글 그리고 순번으로 입력 된 것을 확인할 수 있다. 순번을 넣은 이유는 나중에 시각화를 하고 정렬할 때 필요하다. 없으면 요일을 가나다 또는 알파벳 순으로 밖에 나열을 못한다. (예: 금목수월일토화)
enrich pipeline process
승하차인원 집계 로그 파일이 색인될 때 앞서 만든 seoul-metro-station-info 인덱스의 정보를 가져와 조인 할 수 있도록 enrich 프로세서를 포함하는 인제스트 파이프라인을 만들겠습니다. 자세한 사용 방법에 대한 설명은 공식 도큐먼트의 Enrich your data 페이지를 참고하여 확인하면 된다.
1) enrich policy 를 만들어야 한다. seoul-metro-station-info 인덱스에서 station.code 필드와 일치하는 도큐먼트를 가져와 병합하는 seoul-metro-info_policy 를 만들고 활성(_execute) 해 준다.
PUT /_enrich/policy/seoul-metro-info_policy
{
"match": {
"indices": "seoul-metro-station-info",
"match_field": "station.code",
"enrich_fields": [ "line", "station", "geo" ]
}
}
POST /_enrich/policy/seoul-metro-info_policy/_execute2)방금 만든 seoul-metro-info_policy 의 enrich 프로세서를 포함하는 인제스트 파이프라인을 만들고 문서를 테스트 해 봅니다.
PUT _ingest/pipeline/seoul-metro-logs-pipe
{
"processors": [
{
"enrich": {
"policy_name": "seoul-metro-info_policy",
"field": "station_code",
"target_field": "info"
}
}
]
}
POST _ingest/pipeline/seoul-metro-logs-pipe/_simulate
{
"docs": [
{
"_source": {
"@timestamp": "2015-01-01T05:00:00.000+09:00",
"station_code": 150,
"people_in": 441,
"people_out": 392
}
}
]
}성공이다.
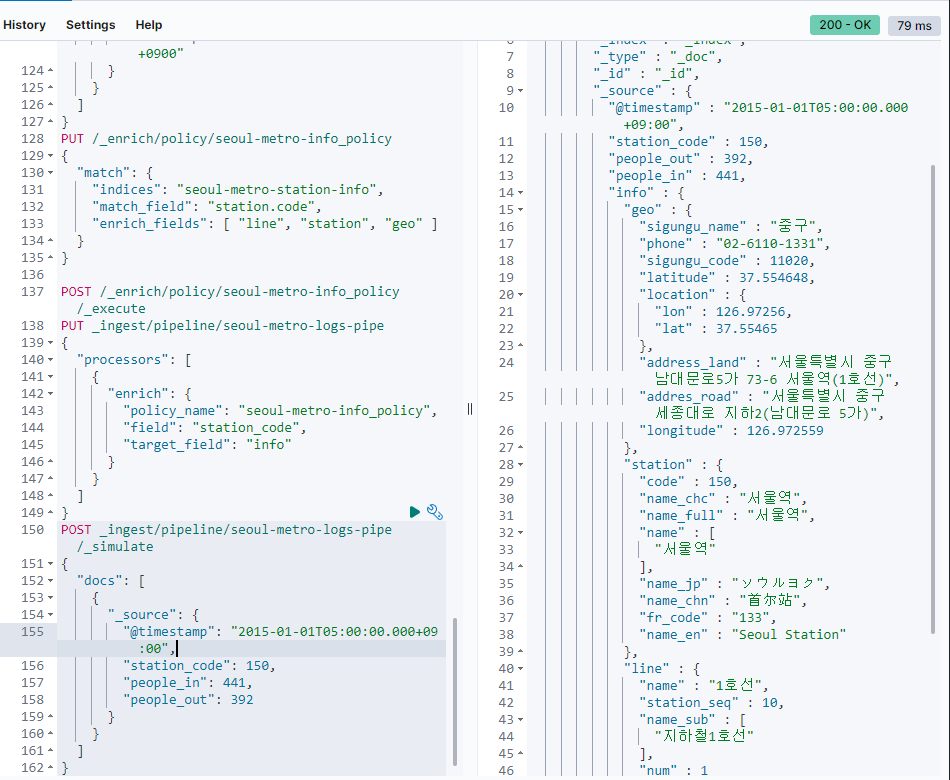
enrich, hour_and_week, date 파이프라인
앞에서 만든 enrich 프로세서와 hour_and_week 스크립트, 그리고 그 외 필요한 프로세서들을 포함하는 seoul-metro-logs-pipe 파이프라인을 만든다. 앞에 만든 파이프라인과 이름이 중복되어도 덧씌워지기 때문에 상관 없다.
PUT _ingest/pipeline/seoul-metro-logs-pipe
{
"description": "Ingest pipeline for seoul-metro-logs-%{+YYYY} index",
"processors": [
{
"enrich": {
"policy_name": "seoul-metro-info_policy",
"field": "station_code",
"target_field": "info"
}
},
{
"script": {
"id": "hour_and_week",
"params": {
"dateTimeField": "timestamp",
"hourOfDayField": "hour_of_day",
"dayOfWeekField": "day_of_week"
}
}
},
{ "rename": { "field": "info.geo.sigungu_name", "target_field": "geo.sigungu_name" } },
{ "rename": { "field": "info.geo.sigungu_code", "target_field": "geo.sigungu_code" } },
{ "rename": { "field": "info.geo.location", "target_field": "geo.location" } },
{ "rename": { "field": "info.station", "target_field": "station" } },
{ "rename": { "field": "info.line", "target_field": "line" } },
{ "date": { "field": "timestamp", "formats": [ "ISO8601" ], "timezone" : "Asia/Seoul" } },
{ "remove": { "field": [ "info", "station_code", "timestamp" ] } }
]
}seoul-metro-logs-pipe 파이프라인은 다음과 같은 작업들을 한다.
enrich: seoul-metro-info_policy 인덱스에서 가져온 정보들을 info 필드의 하위에 넣습니다.
script: @timestamp 필드로부터 hour_of_day, day_of_week 정보를 추출해서 입력합니다.
rename: enrich 에서 가져온 info.geo, info.line, info.station 필드들을 바깥으로 옮깁니다.
remove: 필요 없어진 info 필드와 중복 값을 가진 station_code 를 삭제합니다.
다시 도큐먼트를 넣고 테스트를 해 보자
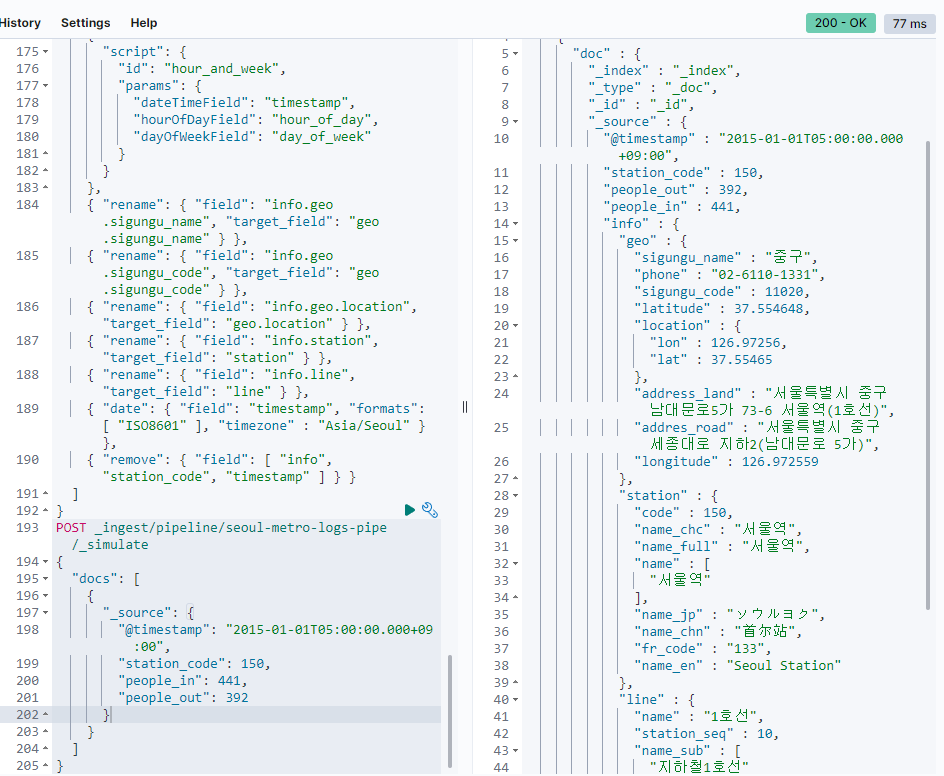
성공인가..?
seoul-metro-%{+YYYY}.logs.csv 색인
seoul-metro-station-info 매핑 설정
이제 seoul-metro-logs* 형식을 가진 인덱스가 색인될 때 자동으로 매핑을 적용할 인덱스 템플릿을 만들어본다.
PUT _index_template/seoul-metro-logs_template
{
"index_patterns": [ "seoul-metro-logs*" ],
"template": {
"mappings": {
"properties": {
"@timestamp": { "type": "date" },
"year": { "type": "integer" },
"people_in": { "type": "integer" },
"people_out": { "type": "integer" },
"hour_of_day": { "type": "byte" },
"day_of_week": {
"properties": {
"en": { "type": "keyword" },
"kr": { "type": "keyword" },
"num": { "type": "byte" }
}
},
"geo": {
"properties": {
"sigungu_code": { "type": "keyword" },
"sigungu_name": { "type": "keyword" },
"location": { "type": "geo_point" }
}
},
"line": {
"properties": {
"name": { "type": "keyword" },
"name_sub": { "type": "keyword" },
"num": { "type": "byte" },
"station_seq": { "type": "byte" }
}
},
"station": {
"properties": {
"code": { "type": "short" },
"fr_code": { "type": "keyword" },
"name": { "type": "keyword" },
"name_chc": { "type": "keyword" },
"name_chn": { "type": "keyword" },
"name_en": { "type": "keyword" },
"name_full": {
"type": "keyword",
"fields": {
"nori": { "type": "text", "analyzer": "nori" }
}
},
"name_jp": { "type": "keyword" }
}
}
}
}
}
}만약 위 코드에서 err가 뜬다면 nori가 설치 되어있는지 확인이 필요하다.
# 설치 명령어
cd /usr/share/elasticsearch
bin/elasticsearch-plugin install analysis-nori
#elasticsearch 재시작 필요
sudo systemctl restart elasticsearch
성공적으로 저장이 됨을 볼 수 있다.
logstash 필터 설정

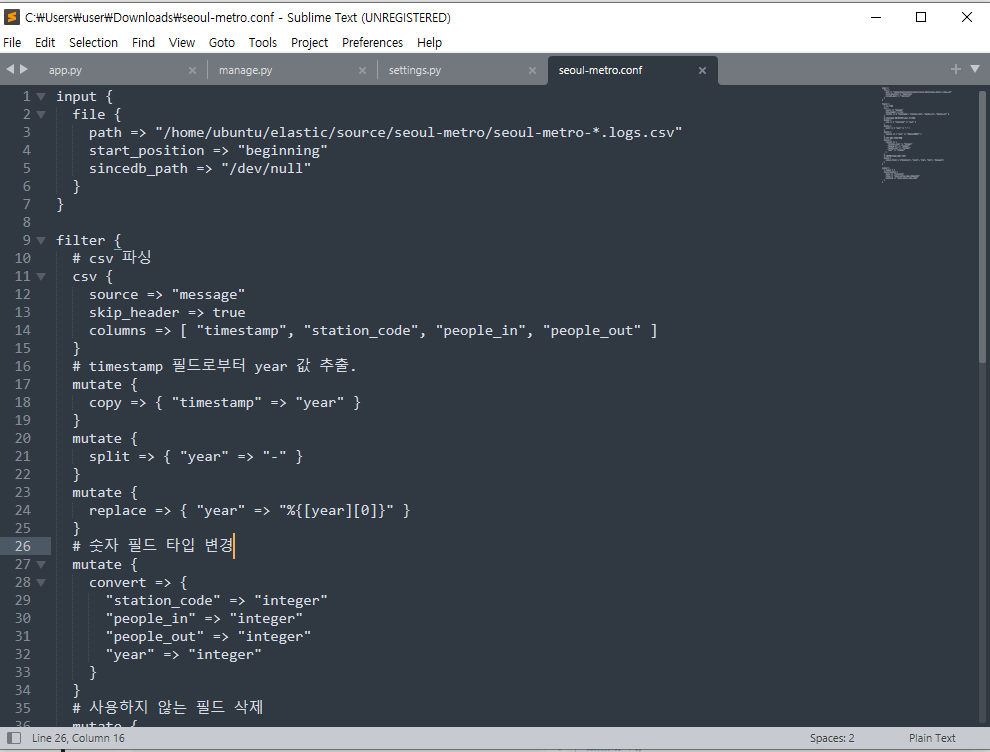
현재 파일 상태는 이러하다.
elastic 폴더 안에 source 폴더와 logstash를 설치한 폴더가 있다.
source 폴더 안에는 seoul-metro 폴더가 있고 그 안엔 kaggle에서 다운 받은 파일들이 들어 있다.
elasticsearch 버전을 7.x 버전으로 하였기 때문에 logstash도 7.16 버전으로 설치하였다.
https://www.elastic.co/kr/downloads/past-releases/logstash-7-16-2
파일 다운 받고 실행 하면 된다.
logstash와 source는 따로 ubuntu에 elastic 폴더를 만들어 넣었다.
-
seoul-metro.conf 파일 생성(xftp를 이용하여 파일을 넘겼다.)
-
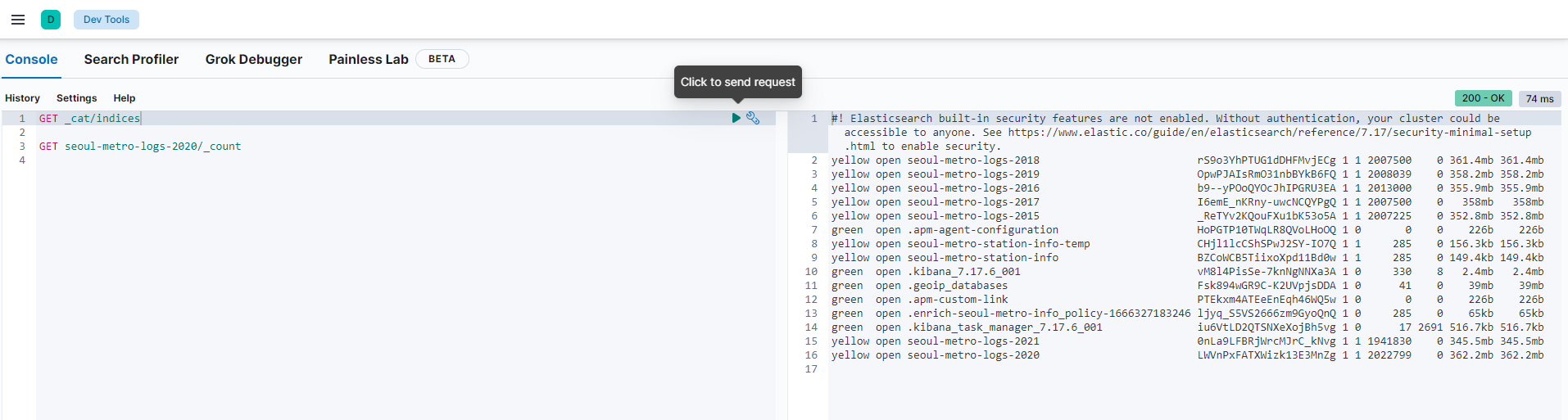
sutout으로 나타냈을 때 결과이다.
bin/logstash -f seoul-metro.conf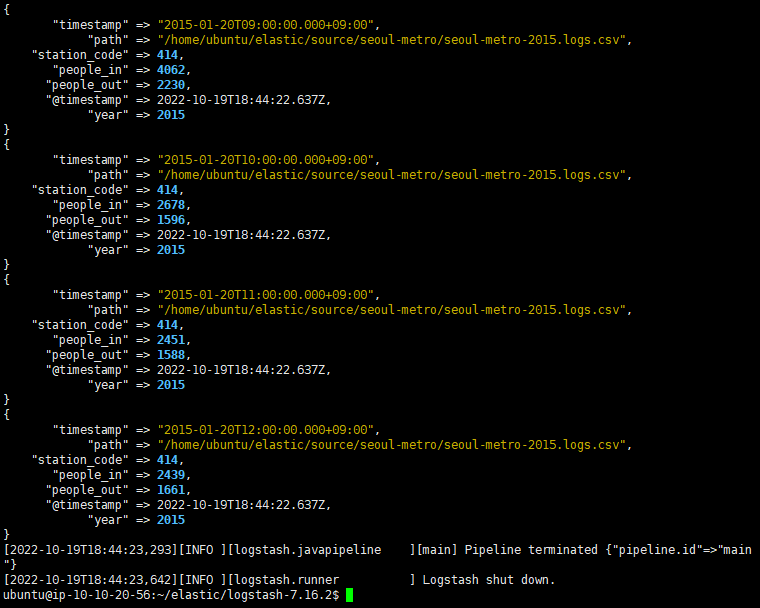
- 결과를 output하여 kibana에 출력하였다.
input {
file {
path => "/home/ubuntu/elastic/source/seoul-metro/seoul-metro-*.logs.csv"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
filter {
# csv 파싱
csv {
source => "message"
skip_header => true
columns => [ "timestamp", "station_code", "people_in", "people_out" ]
}
# timestamp 필드로부터 year 값 추출.
mutate {
copy => { "timestamp" => "year" }
}
mutate {
split => { "year" => "-" }
}
mutate {
replace => { "year" => "%{[year][0]}" }
}
# 숫자 필드 타입 변경
mutate {
convert => {
"station_code" => "integer"
"people_in" => "integer"
"people_out" => "integer"
"year" => "integer"
}
}
# 사용하지 않는 필드 삭제
mutate {
remove_field => ["@version", "event", "log", "host", "message"]
}
}
output {
# stdout { }
elasticsearch {
hosts => "localhost"
pipeline => "seoul-metro-logs-pipe"
}
}

버전 때문에 3일이 걸렸다...
밤새 했지만 계속 버전과 오류로 인해 힘들어서 이해를 많이 못하고 그저 따라한 부분이 많아 공부가 많이 필요하다.
