
해당 글은 Transformers 기반의 Tokenizer를 Vue CLI에서 구현하는 방법을 소개한다.
참조 사이트
HuggingFace Transformers(Python)
@xenova/transformers(Javascript)
NLP support with Huggingface tokenizers(Java)
DJL NLP Utilities For Huggingface Tokenizers Maven
의존성 추가
// package.json의 dependencies에 다음 내용 추가
"@xenova/transformers": "^2.3.1",Tokenizer 파일 추가
@xenova/transformers라이브러리의 tokenizer.json 탐색 순서는 다음과 같다.location.host/models/인스턴스 생성 파라미터/tokenizer.jsonlocation.host/models/인스턴스 생성 파라미터/tokenizer_config.json- https://huggingface.co/
인스턴스 생성 파라미터/resolve/main/tokenizer.json - https://huggingface.co/
인스턴스 생성 파라미터/resolve/main/tokenizer_config.json
- 따라서 Vue에서 정적 파일을 Context Root로 제공하는
public폴더에models폴더 생성 후 tokenizer.json를 넣어둔다- 빌드 이후에도 자동으로 포함됨
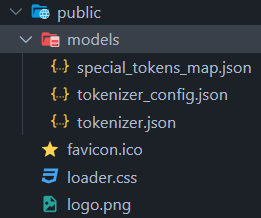
Tokenizer 인스턴스 생성
// 상단에서 인스턴스 생성 파라미터가 탐색 경로가 된다
// public/models/ 이하에 위치한다면 빈 string을 입력
// public/models/tokenizer/ 이하에 위치한다면 'tokenizer'를 입력
const tokenizer = await AutoTokenizer.from_pretrained('')Token 길이 계산
const tokens = await tokenizer('안녕하세요')
// tokens 구조
{
attention_maks: {
data: BigInt64Array,
dim: number[],
size: number,
type: string
},
input_ids: {
data: BigInt64Array,
dim: number[],
size: number,
type: string
}
}
// 토큰 길이는 아래 방법 중 택 1
tokens.attention_mask.size
tokens.attention_mask.data.length
tokens.input_ids.size
tokens.input_ids.data.length위 함수 이외에도 다양한 기능이 제공된다.

Java & Vue ...
좋은 정보 얻어갑니다, 감사합니다.