개인스터디
데이터 전처리 & 시각화 3주차
라이브러리 불러오기
import pandas as pd
import seaborn as sns
# 없으면 pip install seabornseaborn 오픈소스 데이터셋 사용
# 오픈소스 데이터
data = sns.load_dataset('tips')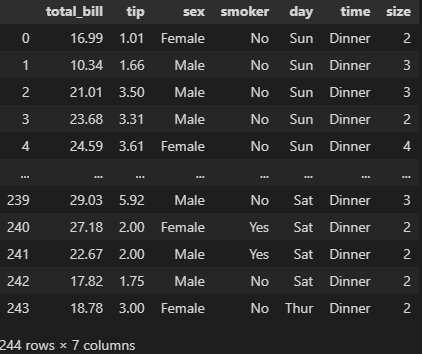
csv로 저장하기, 불러오기
# 데이터 csv로 저장하기 (현재 위치에 저장됨)
#data.to_csv("tips_data.csv")
# unnamed라는 컬럼이 생성됨 불러올때, 혹은 저장할때 인덱스에 대해 설정을 하지 않으면 컬럼에 들어오는 경우가 존재
# 저장할때 index = False로 저장하면 해결
data.to_csv("tips_data.csv", index = False)
#csv 파일 불러오기
df = pd.read_csv("tips_data.csv", index_col = 0) index
예시 데이터프레임 만들기
# 딕셔너리 형태로 작성
df = pd.DataFrame({
'A' : [1, 2, 3],
'B' : ['a', 'b', 'c']
}, index = ['idx3', 'idx2', 'idx1'])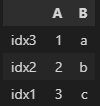
정보 가져오기
df.loc['idx2'] # index로 정보 가져오기
df.sort_index() #index 순서대로 정렬
df.set_index('A') # 인덱스 설정 (A가 가지고 있는 값이 넘어감)
df.index = ['ㄱ', 'ㄴ', 'ㄷ'] # 인덱스 변경
df.reset_index(drop = True) #원래 값으로 리셋 column
예시 데이터프레임 만들기
data = {
'name' : ['Alice', 'Bob', 'Charlie'],
'age' : [25, 30, 35],
'gender' : ['female', 'male', 'male']
}
df = pd.DataFrame(data)정보 가져오기
df['name'] # name이라는 컬럼명의 해당 시리즈를 불러옴
df.columns # 컬럼 이름 구성이 어떻게 되어있는지 확인하기
df.columns = ['이름', '나이', '성별'] # 컬럼 이름 변경
df.rename(columns= {'이름' : 'name'}) # 컬럼 이름 변경방법2
df.rename(columns= {'나이' : 'age', '성별' : '남/여'}) # 컬럼 이름 변경방법3 (여러개를 한번에)
df['스포츠'] = '축구' # 컬럼 추가
del df['스포츠'] # 컬럼 삭제데이터 확인
df.head() # 상단 5개 - 짤막하게 볼때
#df.head(n) 상단 n개만큼 가져옴
df.describe() # 숫자 타입을 가진 컬럼 값들에 대한 기초 통계량 확인 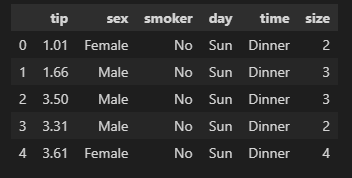
df.info() # 데이터들의 정보를 간략하게 표현해주는 메소드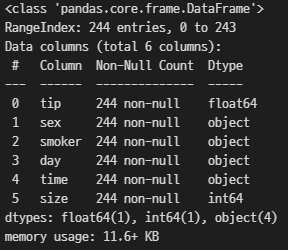
df.describe() # 숫자 타입을 가진 컬럼 값들에 대한 기초 통계량 확인 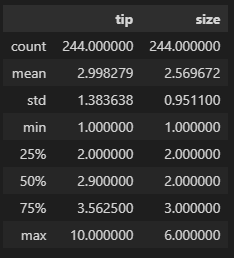
df.isna() # true = null값임
df[df['B'].isna()] # 일종의 조건식으로 B의 null값을 불러오는 거 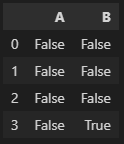
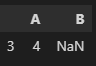
데이터 타입
df['size'].dtype #해당 컬럼이 무슨 타입인지
df['tip'] = df['tip'].astype(str) # 컬럼 타입 변경 (float -> str)
df['tip'].astype(float) # str > float > int로 변경
df['tip'] = df['tip'].astype(float)
df.dtypes # 다시 str -> float으로 돌려주고 타입들만 간결하게 보기
# info를 보통 많이 사용하지만 편한 방법으로 사용하면 됨 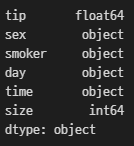
데이터 선택
iloc: 행 번호, 열 번호 - 번호를 통해서 데이터를 불러오는 거loc: 인덱스 이름으로 특정 문자를 통해서 각 데이터 불러오는 거
iloc
df.iloc[0] # n번째 인덱스에 해당하는 값
# 슬라이싱
df.iloc[0:5:2] # 0~2까지 인덱스에 해당하는 값 [start:stop:step]
df.iloc[0, 1] # 좌표로 데이터 출력하기
df.iloc[:, 0] # 첫번째 컬럼만 보기
# 헷갈리는 부분 정리 : 파이썬은 인덱스 슬라이싱 시 끝값의 이전값을 불러옴 (ex. [0:3] = 0, 1, 2값 불러오기)
# loc에서 인덱스명을 입력 시에는 해당 데이터를 포함하여 불러옴
df.loc[:, 'A'] # 첫번째 컬럼만 보기 loc ('A' 로 불러오기 )loc
# 인덱스로 컬럼 불러오기
df.loc['b':'e', 'A':'C'] # 인덱스 b부터 e까지, 컬럼 A부터 C까지
df.loc[:, 'A'] # ':' 모든 행 , 'A'컬럼 선택
df['A'] # 'A'컬럼 선택 (= `df.loc[:, 'A'])loc, iloc 없이 불러오기
# df['A', 'B'] = 에러 / 대괄호 중요
df[['A', 'B']]
# 순서변경 가능
df[['B', 'A']] # 순서만 다르게 적어주면 됨
# 슬라이싱
df.loc['a':'b', ['B', 'C']]
df.loc['a':'b', 'B':'C']
# 정답은 없고 원하는 형태로 불러오는 방법을 적재적소에 활용할 것 조건식(Boolean)
# 남성 데이터만 가져오기
# df에 조건을 넣으면 참인 조건만 가져옴(Boolean indexing)
df[df['sex'] == 'Male']
# 여러개의 조건 넣기
# 남성이면서 흡연자(AND)
df[(df['sex'] == 'Male') & (df['smoker'] == 'Yes')]
# 남성이거나 흡연자(OR)
df[(df['sex'] == 'Male') | (df['smoker'] == 'Yes')]
# loc로 필터링
# 사이즈가 3 초과, tip 부터 smoker까지 슬라이싱
df.loc[df['size'] > 3, 'tip':'smoker']
# 특정 컬럼에서 특정 값만 보고 싶다
# 사이즈 1,2 만 보고싶다
df[df['size'].isin([1,2])]
# 일요일, 목요일만 보고 싶다
df[df['day'].isin(['Sun','Thu'])]변수에 할당하기
# 변수에 할당하기
condition = df['tip'] < 2
# 변수로 조회
df[condition]
# 여러개의 조건 변수 할당
cond1 = df['size'] >= 3
cond2 = df['tip'] < 2
df[cond1 | cond2]
# 조건식이 많아 복잡할 경우 구분
# 줄바꿈 정렬 \
# 다른사람들과 협업하는 일이 많기 때문에 업무적인 능률을 올리기 위해 사용함
cond = (df['sex'] == 'Male') \
& (df['tip'] > 3) \
& (df['smoker'] == 'Yes') \
& (df['total_bill'] < 20) \
& (df['size'] == 4)
df[cond]데이터 추가하기
# created_at 이라는 시리즈 추가
df['created_at'] = '2024-01-01'
#str으로 추가한 컬럼을 datetime type으로 변경
df['created_at']= pd.to_datetime(df['created_at'])
df.info()데이터 연산
# 데이터 연산 + 새로운 컬럼에 할당 (행 기준 연산)
df['revenue'] = df['total_bill'] + df['tip']
# percent 계산
df['tip_percentage'] = round(df['tip'] / df['revenue'] * 100)데이터 병합
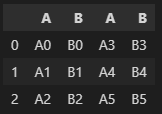
CONCAT
pd.concat([df1, df2])
# axis = 0 : 기본값(위아래)
# 인덱스가 원래 기존과 똑같이 유지됨 .reset_index(drop=True) 사용 시 인덱스 초기화
pd.concat([df1, df2], axis=0).reset_index(drop=True)
# axis = 1 : 양옆으로
pd.concat([df1, df2], axis=1).reset_index(drop=True)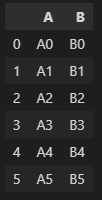
MERGE
# default 값은 inner join
# key라는 컬럼을 기준으로 묶어줌
pd.merge(df1, df2, on='key', how='inner')
# key값을 기준으로 모든 데이터를 가져오는 것
pd.merge(df1, df2, on='key', how='outer')
# left join
# df1을 기준으로 1에있는 데이터는 변하지 않으면서 df2에 속하는 데이터를 가져오는것
pd.merge(df1, df2, on='key', how='left')데이터 집계
# 각 카테고리별 value값 계산
df.groupby('Category').mean() # 평균 계산 > category 가 인덱스로 변함
df.groupby('Category').sum() # 합계 계산
df.groupby('Category').count() # 개수 세기
df.groupby('Category').max() # 최대값
df.groupby('Category').min() # 최소값
df.groupby('Category').first() # 처음 나오는 값
df.groupby('Category').agg(list) #리스트형태로 묶어서 Group By
# 요일에 따른 평균값 구하기
df[['day', 'total_bill', 'tip', 'size']].groupby('day').mean()
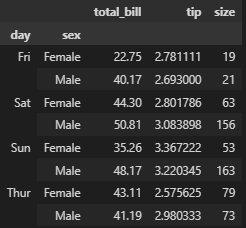
# 변형
# groupby 기준으로 묶으려면 앞에서 무조건 조회를 해야 함 SQL이랑 똑같음
df[['day', 'total_bill', 'tip', 'sex', 'size']].groupby(['day','sex']).mean()
# 문자형 + 숫자형 > 계산불가
# mean의 경우 앞에 계산할 컬럼들이 object면 안됨
# 각각 컬럼별 계산도 가능
df[['sex', 'day', 'total_bill', 'tip', 'size']].groupby(['day','sex']).agg({'total_bill' : 'max', 'tip' : 'mean', 'size' : 'sum'})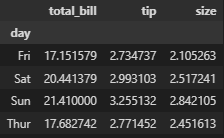
Pivot table
# 피봇 테이블 만들기
pivot = df.pivot_table(index = 'day', columns = 'sex', values = 'total_bill', aggfunc = 'sum')
pivot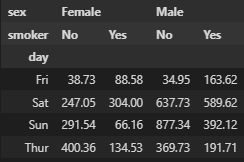
# 여러개 컬럼 기준
pivot = df.pivot_table(index = 'day', columns = ['sex', 'smoker'], values = 'total_bill', aggfunc = 'sum')
pivot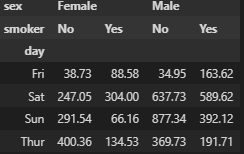
데이터 정렬
# tip 열 기준 오름차순 정렬
sorted_by_tip = df.sort_values('tip')
print(sorted_by_tip)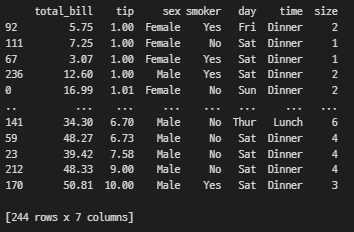
# 여러개 열 기준 정렬
# tip 기준 오름차순, total_bill 기준 내림차순
sorted_by_tip = df.sort_values(by = ['tip', 'total_bill'], ascending=[True, False])
print(sorted_by_tip)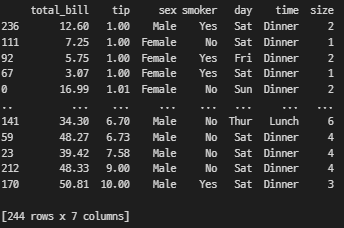
데일리퀘스트
SQL - 없어진 기록 찾기
SQL - 과일로 만든 아이스크림 고르기
Python - 핸드폰 번호 가리기
Python - 없는 숫자 더하기
Python - 코딩 기초 트레이닝 Day 4
일기
- SQL
코드카타 51-52✅ - Python
코드카타 27-28✅기초트레이닝 Day4✅기초트레이닝 Day5❌ - 전처리&시각화
3주차✅4주차❌ - 라이브세션
4회차 참석✅
세션이 이해가 안 돼서 전처리 강의부터 들었는데, 내용이 어마어마하다 코드 한줄 한줄 치는 것 자체가 오래 걸리는데 휙휙 지나가서 강의 끊어 보느라 엄청 오래 걸림
라이브세션 데이터도 얼른 이것저것 뜯어보려면 빨리 시각화 강의를 끝내야 해서 오늘 4주차까지 듣고싶었는데 시간이 모자랐다
파이썬 기초 트레이닝도 Day5까지 하기로 해놓고(어제 미뤄뒀음) Day4까지 밖에 못했음 미친세상아
오늘은 특히 계속 집중했는데도 시간이 모자라서 걍 광광 울고싶음🥲 아무튼 내일도 힘내보자..... 새로 나온 판다스 과제도 얼른 해보자...

이분량 MERGE? 완전 빠르자낫! 역시 수2뉨~