
개인스터디
통계학 기초 5주차
피어슨 상관계수
가장 대표적으로 많이 사용하는 상관계수!
- 두 연속형 변수 간 선형 관계의 강도 측정
- 값의 범위:
+1→ 완전한 양의 선형 관계-1→ 완전한 음의 선형 관계0→ 선형 관계 없음
- 언제 사용?
- 변수 간 선형적인 관계가 예상될때
- 비선형 관계 ❌
- 라이브러리
from scipy.stats import pearsonr
비모수 상관계수
데이터가 정규분포를 따르지 않을 때 사용하는 상관계수!
- 언제 사용?
- 변수 간 비선형적인 관계가 예상될때
- 데이터의 분포에 대한 가정을 하지 않을때
- 순서형 데이터일 때
스피어만 상관계수
-
두 변수의 순위 간 일관성 측정
-
피어슨보다 이상치에 강함
-
라이브러리
from scipy.stats import spearmanr
켄달의 타우
-
순위 일치/불일치 쌍의 비율 기반
-
순위 간 일관성 정도 측정
-
라이브러리
from scipy.stats import kendalltau
상호정보 상관계수
상호정보를 이용한 변수끼리의 상관계수 계산!
-
두 변수 간 상호 정보량 측정
→ 하나의 변수를 알면 다른 변수의 불확실성이 얼마나 줄어드는지를 측정 -
언제 사용?
- 변수 간 관계가 비선형적이고 복잡할 때
-
라이브러리
from sklearn.metrics import mutual_info_score
통계야 놀자 4회차
회귀분석
독립변수(x)를 통해 종속변수(y)를 예측
- 예) 게임시간(x)이 늘어나면 전기세(y)는 어떻게 변할까?
- 독립변수 : 원인이 되는 변수
- 종속변수 : 결과가 되는 변수
➡️ 추세선(회귀선)
데이터를 가장 잘 설명하는 선 찾기
y = a + bx
- a : 절편 (x = 0일때 값)
- b : 기울기 (x가 변할때 y의 변화량)
프로세스
1. 변수 설정 & 가설 수립
- 귀무가설: 게임시간은 전기세에 영향 없다
- 대립가설: 게임시간은 전기세에 영향 있다
2. 경향성 확인
- 산점도, 상관계수 등 활용 > 변수 관계 시각적으로 파악
3. 정합성 검증 & 결과 해석
- 설명력 (R²)
- 모델 유의성 검정 (F검정)
- 독립변수 유의성 확인 (t검정)
등등
☑️ 종류
| 종류 | 구분 | 독립변수 | 종속변수 | 목적 | 예시 |
|---|---|---|---|---|---|
| 선형 회귀 | 🔹단순 | 1개 (연속형) | 연속형 | 예측 | 공부시간 → 시험점수 |
| 🔸다중 | 2개 이상 (연속형) | 연속형 | 예측 | 면적, 방수 → 집값 | |
| 로지스틱 회귀 | 🔹이진 | 연속형 / 범주형 | 이진 범주형 (0/1) | 분류 | 공부시간 → 합격 여부 |
| 🔸다중 | 연속형 / 범주형 | 다중 범주형 (3개 이상) | 분류 | 응답시간 → 고객만족도 |
🤷♀️두 강의에서 분류 방법이 왜 차이가 나는 것일까?
정욱튜터님한테 여쭤봤는데 [과정(통계학적 측면)을 함께 보느냐 / 결과(머신러닝적 측면)만 보느냐] 에서 차이가 난다고 하셨다
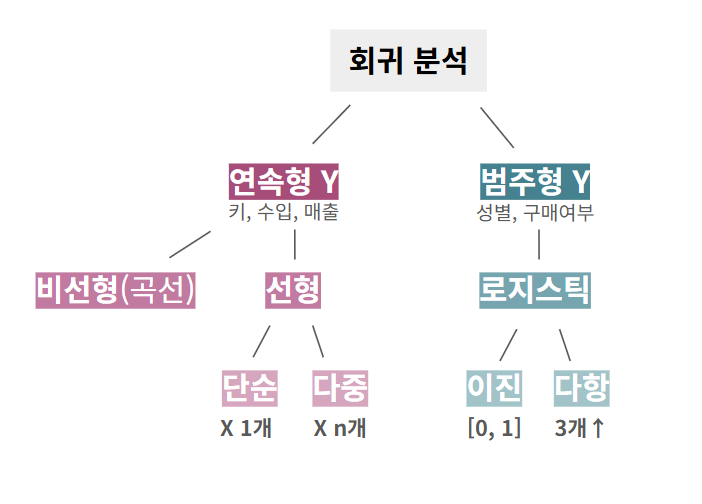
이런 흐름으로 이해하면 될듯
결과 해석
1. R² (결정계수): 설명력
→ 종속변수의 전체 변동 중에서 회귀선이 설명해주는 비율
| 기호 | 의미 |
|---|---|
| T (Total) | 전체 변동 (y값들이 평균에서 얼마나 흩어져 있는지) |
| R (Regression) | 회귀선이 설명해준 변동 (설명 가능한 부분) |
| E (Error) | 잔차 = 회귀선이 설명하지 못한 변동 (오차) |
⚠️ R ≠ R²
설명력 R² = R / T = 1 - (E / T)
- R²가 1에 가까울수록 회귀선이 데이터를 잘 설명함
- 예: R² = 0.8 → 전체 변동의 80%를 회귀선이 설명함
2. F-검정: 통계적 유의성
- 귀무가설: 모든 회귀계수는 0이다 → 모델 의미 없다
- 대립가설: 적어도 하나의 회귀계수는 0이 아니다
- p-value < 0.05 → 유의미한 모델
3. t-검정: 상관관계
- 귀무가설: 해당 독립변수는 y와 관계 없다
- 대립가설: 해당 독립변수는 y에 영향을 준다
- p-value < 0.05 → 해당 변수는 유의미
4. OLS(최소제곱법) 결과 요약
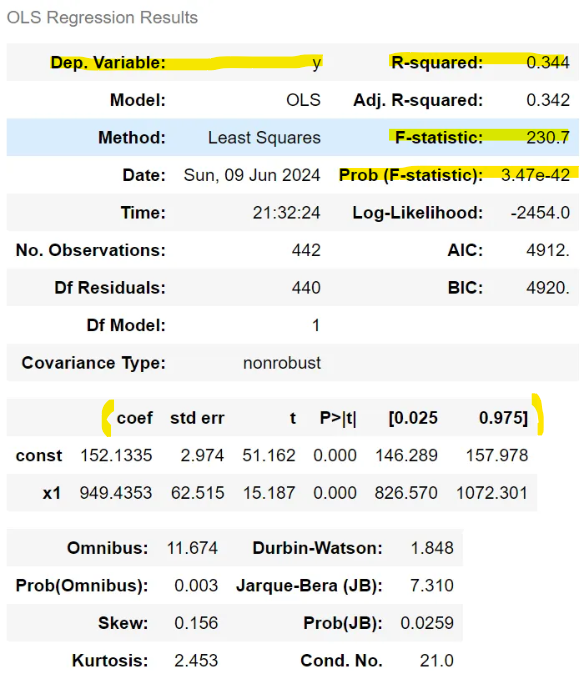
Dep. Variable: 종속변수R-suared: 결정계수 (R²)
0.344 → 모델이 종속변수의 약 34.4%를 설명F-statistic: F 통계량
230.7로 매우 큼 → 모델 유의미할 가능성 높음Prob (F-statistic): F 통계량의 p-value
3.47e-42 (≈ 0) → 귀무가설 기각, 모델 유의미함coef: 회귀계수const: 절편
x가 0일때 152.1335x1: 설명변수
x가 1 증가할때 y는 평균 949.4353 증가
→ 회귀식 : y = 152.13 + 949.44 * x1
std err: 표준오차P>|t|: 각 계수에 대한 p-value
x1과 상수항 모두 0 → 매우 유의미[0.025 0.975]: 95% 신뢰구간
x1의 계수는 826.570 ~ 1072.301 범위 내에 있을 가능성이 95%
☑️ 요약
-
독립변수: 원인 / 종속변수: 결과
-
회귀분석 > 예측과 설명이 목적
- 독립변수, 종속변수 설정
- 데이터 경향성 확인(산점도, 상관관계)
- 정합성 검증 & 결과 해석
- 회귀식의 설명력 (R²)
- 모델 유의성 (F-검정)
- 독립변수 유의성 (t-검정)
-
신뢰할 수 있는지 = p-value 기준으로 판단
Standard 7회차
머신러닝 파이프라인
-
데이터를 준비하고, 모델을 학습시켜서, 예측을 만들기까지의 일련의 단계들을 체계적으로 정리한 것
-
효과
- 자동화
- 협업 용이, 코드 재사용 가능
- 실수 줄이기
-
전체 흐름
- 데이터 수집 → 전처리 → 모델 학습 → 평가 → 예측/배포
실습
1. import

2. 데이터 로드

3. 전처리

- ⚠️ 주의 "테스트 데이터의 어떤 정보도 알려고 하지 마라"
테스트셋은 최종 평가용으로만 사용해야 함
미리 학습 시킬 경우 평가 제대로 불가능 !
scaler = StandardScaler()
scaler.fit ❌
scaler.fit(X_train) ⭕ 훈련 데이터만 사용4. 모델 학습

5. 예측+정확도 평가

6. 파이프라인 ✅
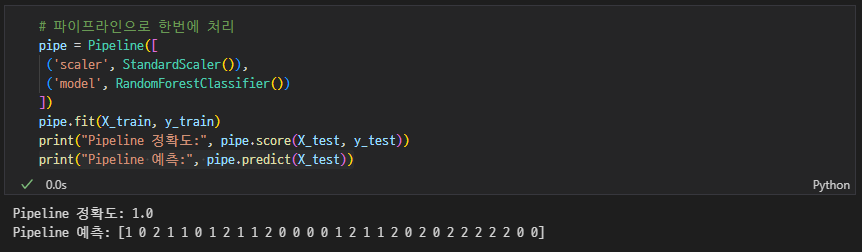
fit,transform,predict메서드를 가진 클래스만 사용 가능 (sklearn대부분 사용 가능)
모듈화
파이프라인 순서대로 각 파일 하나씩 작성해서
DIY 라이브러리 ... 를 만드는 것 정도로 이해함
나중에 프로젝트할때 써먹어보면 좋겠다
📂my_project/
├── 📂data/
│ └── load_data.py
├── 📂preprocess/
│ └── scaler.py
├── 📂model/
│ └── random_forest.py
├── 📂pipeline/
│ └── full_pipeline.py
└── main.py- 효과
- 코드 재사용 가능
- 유지보수 용이
- 협업 시 역할 분담 유리
과제
LogisticRegression,SVC같은 다른 모델로 파이프라인 바꿔보기
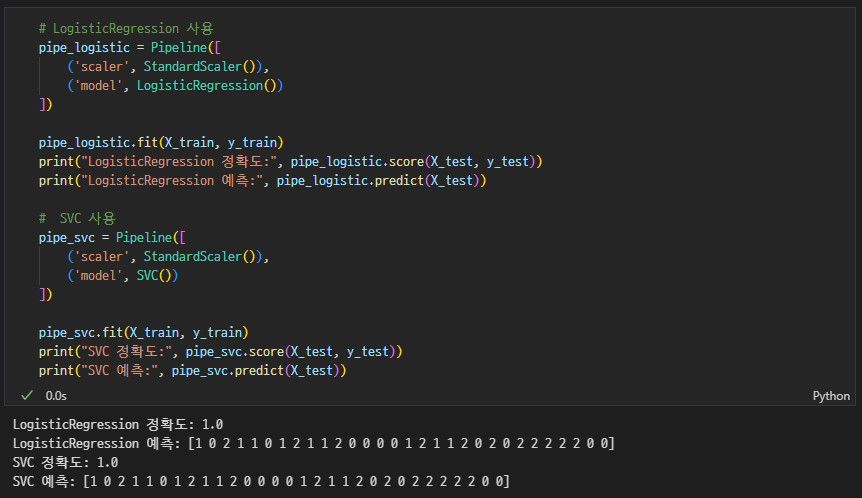
MinMaxScaler와StandardScaler비교해보기
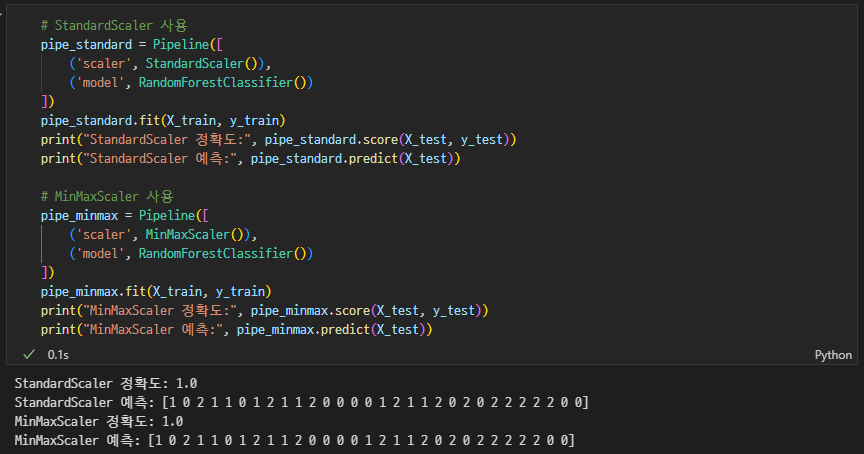
전부 다 같은 값으로 나와서 의문이었는데, 질문방에 이미 관련한 질문이 있어 답을 얻었다! (경민님 감사합니다)

결론은 데이터셋이 단순해서 그런 것🫡
다른 데이터셋으로 연습해보면 좋을 것 같다
코드카타
SQL - 입양 시각 구하기(2)
SQL -특정 기간동안 대여 가능한 자동차들의 대여비용 구하기
일기
- SQL
코드카타 73-74✅ - Python
코드카타 43-44❌ - 통계
세션 4회차✅기초강의 5-6주차✅ - 수준별학습
스탠다드 7회차✅ - 머신러닝
1강❌
오늘은 지각을 했다🥲 하하
코드카타도 다 못했고.. 머신러닝 강의도 들으려고 했는데 강의 세개 들으려니까 너무 힘들다
스탠다드반은 오늘 처음으로 머신러닝 들어갔는데 생각보다 재밌었다(아직 쉬워서 그렇겠지만) 내일 머신러닝 강의 들으면서 복습한다 생각하면 될듯 ! 고생했따 오늘도🍀
💿오늘의 추천곡 Official髭男dism - Pretender

히게단디즘 조 아 ~
