
팀스터디
아티클 스터디
선정 아티클
개인 요약
-
요약 : 시각 정보를 처리하는 과정을 고려한 시각화디자인은 독자들이 쉽게 이해할 수 있도록 돕는다.
- 뚜렷한 시각 요소 파악
색, 형태 추출
→ 전주의적 속성 활용
(ex. 지진 데이터, 백신의 효과)
- 패턴 인식
윤곽선, 동일한 색이나 질감, 방향성에 따라 분류
→ 게슈탈트 원리 활용
(ex. 미국 하원 의원 투표 경향, 오미크론 지도 등)
- 해석
시각 요소 및 패턴을 이용 → 의미 부여 및 해석
- 뚜렷한 시각 요소 파악
인사이트
게슈탈트 원리나 전주의적 속성과 같은 개념은 처음이라 흥미로웠고, 당연하다고 여겨왔던 것들의 원리를 알 수 있어서 좋았습니다. 예시로 나와있는 시각화 자료처럼 누가 봐도 이해하기 쉽게 만들려면 오늘 아티클에서 배운 것처럼 시각 정보 처리 과정을 잘 이해해야겠습니다.
팀원 공통 인사이트
데이터 시각화는 인간의 인지 특성을 활용해 정보를 빠르고 효과적으로 전달할 수 있지만, 동시에 왜곡의 도구가 될 수 있어 설계와 해석 모두에 비판적 사고가 필요하다.
개인스터디
통계학 기초 6주차
가설 검정에서 주의할 점
재현 가능성
-
정의: 같은 실험을 반복했을 때 일관된 결과가 나오는지 여부
-
문제점: 가설검정 오남용 → 재현성 위기 발생
-
원인:
- 실험 조건 동일하게 조성 어려움
- p값 조작(p해킹), 1종 오류 발생
- 유의수준 낮추면 검정력(1 - 베타) 약화
→ 데이터 수 늘려서 보완 필요
p-해킹
-
정의: 다양한 방식으로 분석을 반복해 인위적으로 p값을 낮추는 행위
-
문제점: 분석 결과 신뢰성 저하
-
주의 상황:
- 여러 가설 시도 후 유의한 결과만 채택
- 유리한 p값만 보고하거나 데이터 개수를 조작
- 마음에 드는 결과만 채택하고 가설을 나중에 설정하는 행위
→ 본페로니 보정, 사전 가설 수립 필요
선택적 보고
- 정의: 유의미한 결과만 보고, 그렇지 않은 것은 숨기는 행위
- 문제점: 분석 결과 왜곡, 신뢰도 하락
- 주의 상황:
- 유의미한 결과만 보고서에 실음
- 결과를 보고 가설을 변경하고 처음부터 그랬다고 주장함
자료수집 중단 시점 결정
- 정의: 사전에 중단 시점을 정하지 않고, 유리한 결과 나올 때까지 수집
- 문제점: 결과 왜곡
- 주의 상황:
- 계획보다 더 많은 데이터를 수집해서 원하는 결과 도출
→ 실험 전 자료 수집 종료 시점 사전 정의 필요
- 계획보다 더 많은 데이터를 수집해서 원하는 결과 도출
데이터 탐색과 검증 분리
- 정의: 가설 설정(탐색)과 검증에 서로 다른 데이터를 사용
- 이유: 과적합 방지 및 신뢰도 확보
- 방법: 데이터셋을 탐색용(train)과 검증용(test)으로 나누어 사용
실무에 쓰는 머신러닝 기초 1강
머신러닝?
사람 도움 최소화 → 컴퓨터가 스스로 데이터에서 패턴 학습 + 예측/분류
예) 스팸메일 분류, 이미지 인식, 음성 인식 등
핵심요소
- 데이터 : 학습할 재료
- 알고리즘 : 문제 푸는 방법
- 컴퓨팅 파워 : 계산할 힘
AI, 머신러닝, 딥러닝의 관계
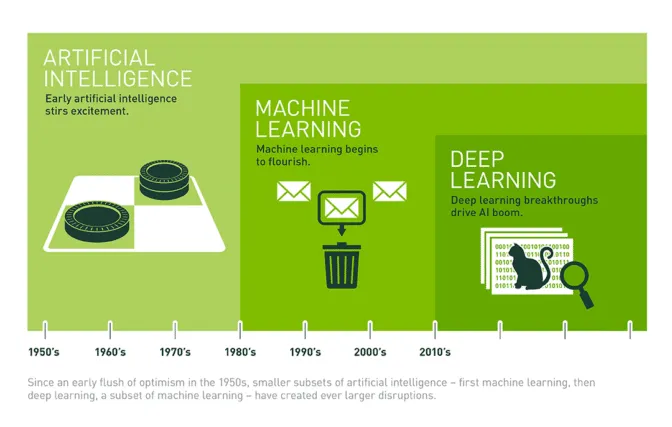
AI(인공지능)
└── 머신러닝 (ML): 데이터 기반 학습
└── 딥러닝 (DL): 인공신경망 기반 학습
-
AI: 사람의 지능적인 작업을 기계가 수행하도록 만드는 광범위한 개념
-
머신러닝: AI 안에서 데이터 기반으로 학습하는 방식
ex) 스팸 메일 패턴 학습 → 필터링 -
딥러닝: 머신러닝 중에서도 ‘신경망’을 여러 층 쌓아 학습하는 방식
ex) ChatGPT, 알파고
활용 예시
- 제조업
- 예측 유지보수
장비 고장시점 사전예측 - 공정 최적화
전체 공정 효율 최대화하도록 제어/설계
- 예측 유지보수
- 마케팅
- 고객 세분화 + 페르소나 도출
- 추천 시흐템
- 금융
- 신용 평가
대안데이터(SNS, 구매이력) 활용 - 자산운용 및 투자전략
알고리즘 트레이딩
로보어드바이저 - 보험 업무 고도화
언더라이팅
- 신용 평가
머신러닝 vs 기존 통계분석
| 항목 | 전통 통계 | 머신러닝 |
|---|---|---|
| 목적 | 가설 검증 ("왜?") | 예측 성능 ("얼마나 잘?") |
| 방식 | 사람이 가설 세움 | 데이터 학습 |
| 데이터 | 적어도 OK | 많을수록 Good |
종류
지도학습 (Supervised Learning)
정답(= 레이블)이 있는 데이터 학습
- 분류 : 어느 그룹에 속하는지 결정
ex) 이메일이 스팸인지 아닌지, 은행 대출 상환 가능 여부 - 회귀 : 숫자로 된 결과를 예측
ex) 주택 가격 예측, 주가 예측
비지도학습 (Unsupervised Learning)
정답 없이 데이터 패턴을 스스로 찾음
-
군집화 : 성향이 비슷한 사람이나 사물을 자동으로 묶어내는 기법
ex) 고객 군집 분석, 문서 토픽 분석 -
차원축소 : 데이터의 특징(변수)이 너무 많아서 복잡한 데이터를, 핵심 정보만 남기고 압축하는 기법
ex) 수백 가지 지표가 있는 데이터를 2~3개의 핵심 지표로 요약
강화학습 (Reinforcement Learning)
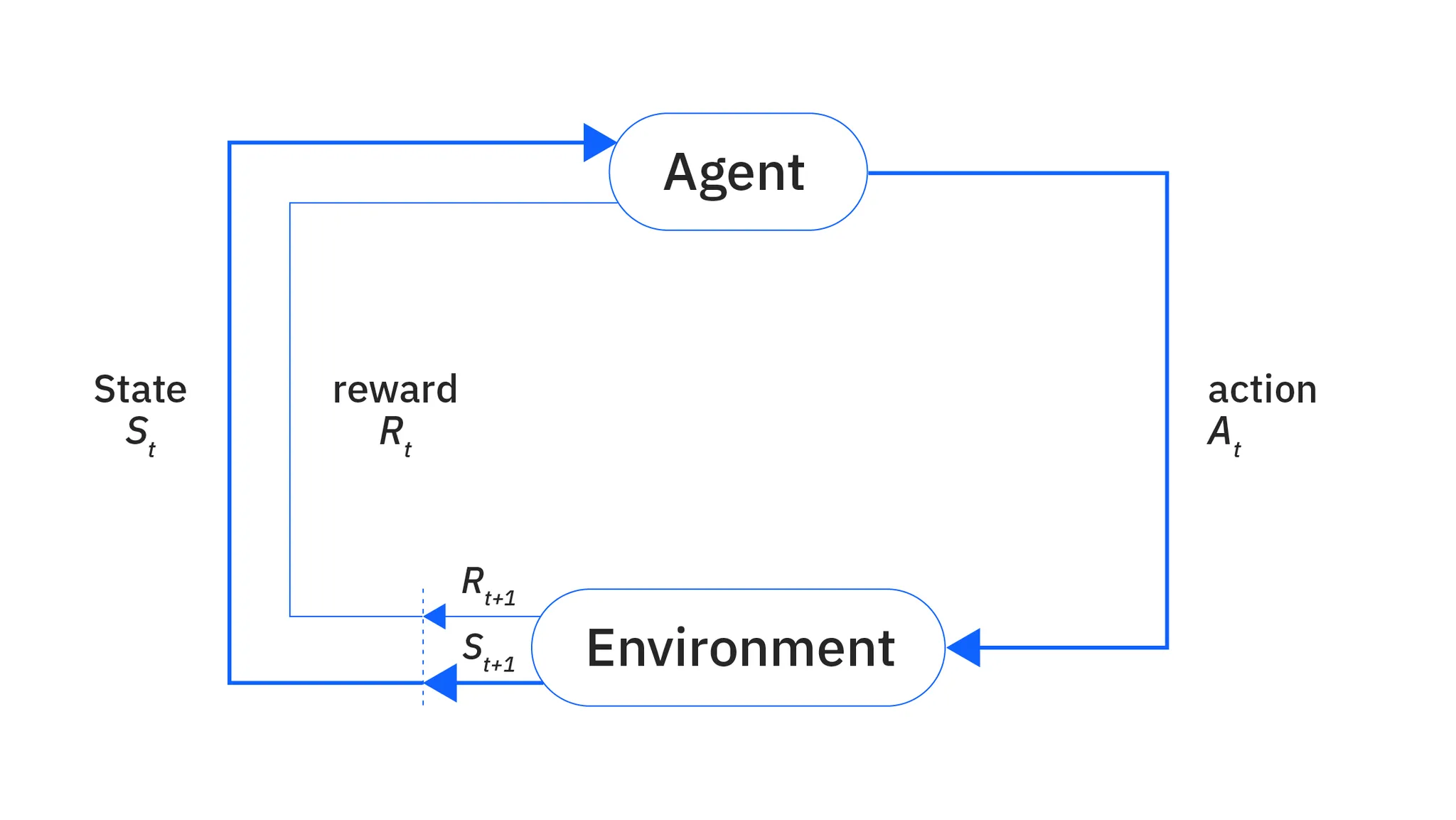
에이전트가 환경과 상호작용하며 보상을 최대화하도록 학습
ex) 알파고, 게임AI, 로봇 제어
- 용어
- 에이전트
학습을 수행하는 주인공 - 환경
에이전트가 움직이고 상호작용하는 무대 - 보상 / 벌점
잘했을때 얻는 점수, 잘못했을때 받는 벌점
- 에이전트
머신러닝 모델링 프로세스
데이터수집 → 전처리 → 모델링 → 성능평가 → 배포
1️⃣ 데이터 수집
- 웹크롤링, 센서측정, 설문조사, DB 추출
- 양질의 데이터 확보가 중요
2️⃣ 전처리
- 결측치 처리
- 평균이나 최빈값으로 대체
- 삭제
- 이상치 처리
대부분의 데이터 범위에서 심하게 벗어난 값 대체 or 삭제 - 스케일링
각각 다른 단위를 쓰는 데이터를 비슷한 수준으로 맞추기
ex) 키 150~180, 몸무게 50~100
→ 모두 0~1 범위로 변환
트리형 모델은 예외 - 범주형 변환
- 원-핫 인코딩 : 범주에 속하면 1, 아니면 0
ex) 빨강 = (1,0,0), 초록 = (0,1,0), 파랑 = (0,0,1) - 레이블 인코딩 : 순서대로 숫자 부여
ex) s사이즈 = 0, m사이즈 = 1, l사이즈 = 2
⚠️ 순위 생길 수 있어 주의
- 원-핫 인코딩 : 범주에 속하면 1, 아니면 0
3️⃣ 모델링
- 지도학습 : 분류/회귀 알고리즘 선택
ex) 로지스틱 회귀, 랜덤 포레스트, XGBoost 등 - 비지도학습 : 클러스터링/차원축소 알고리즘 선택
ex) K-Means, PCA 등
4️⃣ 성능평가 → 추후 자세히 살펴볼 예정
- 분류 : Accuracy, Precision, Recall, F1-score, ROC-AUC 등
- 회귀 : MAE, RMSE, R² 등
- 비지도(군집) : 실루엣 계수 등
5️⃣ 배포
- 사용할 수 있도록 서비스
윤리적 이슈 & 데이터 편향
-
데이터 편향: 편향된 샘플이 많으면, 모델도 그대로 학습함
ex) 인종·성별 분포가 편향된 데이터 → 차별적 의사결정 -
윤리적 책임
- 데이터 균형화
- 민감 정보 보호
개인정보 비식별화, GDPR 등 법적 규제 준수
☑️ 요약
- 머신러닝 = 데이터 기반 예측 기술
- AI > 머신러닝 > 딥러닝
- 머신러닝 vs 통계 = 예측 성능 vs 가설 검증
- 프로세스
- 데이터 수집 → 전처리 → 모델링 → 평가 → 최적화 → 배포
- 전처리가 중요!
- 실무는 항상 윤리도 고려해야 함
실무에 쓰는 머신러닝 기초 2강
전처리
원시(raw) 데이터 → 학습 가능한 데이터로 가공하는 작업
- 센서 오류, 수기 입력 누락, 이상한 숫자 → 처리 필요
- 모델 훈련 전에 반드시 해야 할 준비 작업
- 전처리 부족할 경우
- 성능 저하
- 학습 편향
- 예측 불안정
결측치 처리
◾ 원인
센서 미작동, 수기 누락, 특정 시간대 데이터 미수집 등
◾ 처리 방법
- 삭제 : 소수일 경우
- 대체
- 수치형 : 평균, 중앙값
- 범주형 : 최빈값
- ML 예측 모델로 채우기
➕ 실무 예시
- 야간 센서 누락 : 중앙값 대체 or 이동 평균 활용
- 고객 데이터 누락 : 클러스터 평균 활용
이상치 처리
◾ 정의
정상 범위에서 크게 벗어난 극단값
(ex. 갑자기 온도 센서가 300도 찍힘)
◾ 탐지 방법
- 3σ 룰: 평균 ± 3 * 표준편차
- IQR (박스플롯) : Q1 - 1.5IQR ~ Q3 + 1.5IQR
- 머신러닝 기반: Isolation Forest, DBSCAN 등
◾ 처리
제거, 클리핑, 별도 변수로 활용
➕ 실무 예시
- 제조업에서는 이상치가 이상 신호일 수도 있음
⚠️ 무조건 제거 금지
스케일링(정규화/표준화)
거리 기반 알고리즘, 딥러닝 등에서는 스케일 영향 큼
◾ 종류
| 방식 | 특징 | 사용처 |
|---|---|---|
| 정규화 (MinMaxScaler) | 0~1로 압축 | 딥러닝, 이미지 |
| 표준화 (StandardScaler) | 평균 0, 표준편차 1 | 선형모델, SVM |
불균형 데이터 변환
- 클래스 비율이 한쪽으로 몰린 데이터 (ex. 정상 99%, 불량 1%)
- 모델이 소수 클래스를 예측 못하고 다수 클래스만 예측
◾ 처리
-
Oversampling
- Random : 단순 복제하여 개수를 늘이는 방식
- SMOTE: 소수 클래스끼리 보간, 유사하지만 새로운 가상 데이터 생성
→ 단순 복제보다 데이터 다양성이 높아짐
-
Undersampling
- 다수 클래스 데이터를 줄이는 방식
-
혼합기법 : SMOTE + 언더샘플링
범주형 인코딩
원-핫 인코딩(One-Hot Encoding)
-
범주마다 열 생성 → 해당하면 1, 아니면 0
- ex) 색상(‘Red’, ‘Blue’, ‘Green’) → ‘Red=1,Blue=0,Green=0’ / ‘Red=0,Blue=1,Green=0’ / …
-
장점: 범주 간 서열 관계가 없을 때 사용하기 좋음
-
단점: 범주가 매우 많으면 차원이 커짐
레이블 인코딩(Label Encoding)
-
범주를 숫자로 매핑
- ex) ‘M’=0, ‘L’=1, ‘XL’=2, ...
-
장점: 단순
-
단점: 숫자의 크기가 서열 정보로 해석될 수 있음
피처 엔지니어링
기존 변수 → 새로운 변수 생성 또는 변환
-
예시
-
날짜 ‘2025-02-24 10:35:00’
→ 월(2)’, ‘요일(월=1)’, ‘시(10)’, ‘주말여부(0/1)’ 분해 -
'온도','습도' = '온도 × 습도' 상호작용 피처
-
로그 변환, 제곱근변환 : 비대칭 분포 보정
-
다중공선성 제거 : VIF 활용해 판단
-
☑️ 요약
- 결측치, 이상치는 무조건 삭제 X
- 스케일은 모델 특성에 맞게 선택
- 불균형 데이터는 SMOTE + 실제 분포 확인
- 인코딩은 원-핫 인코딩 vs 레이블 인코딩
- 모든 단계에서 EDA + 도메인 고려가 핵심
복습퀴즈
아래 중 '모수(parameter)'에 해당하는 것은?
A. 표본평균
B. 모집단의 표준편차 ✅
C. 표본의 분산
D. 표본 수 ❌
A. 표본평균 → 통계량
C. 표본의 분산 → 통계량
D. 표본 수 (n) → 단순한 개수
ex) "한국 전체 고등학생 수" → 모수
"내가 조사한 학교의 학생 수(n)" → 표본의 크기, 모수 아님
🔗 용어정리
정규분포가 중요한 이유
기준이 되는 분포이기 때문에 ✅
- 중심극한 정리에 의해 많은 통계량들이 정규분포에 가까워짐
- 확률 계산이 수학적으로 용이하고, 통계적 추론의 기반이 됨
신뢰구간 95%란, 모집단 평균이 해당 구간 안에 있을 확률이 95%라는 의미이다. (O/X)
정답 ❌
동일한 방법으로 표본을 여러 번 뽑아 신뢰구간을 계속 계산하면, 그 신뢰구간들 중 약 95%는 모집단의 모수를 포함하게 된다
- 예시
- 95% 신뢰수준으로 신뢰구간을 만들었을 때
평균을 포함할지 안 할지 이미 결정된 사실
- 95% 신뢰수준으로 신뢰구간을 만들었을 때
귀무가설이 기각되었다는 것은, 대립가설이 참이라는 것을 의미한다. (O/X)
정답 ❌
귀무가설이 기각됐다고 해서 대립가설이 반드시 참은 아님
데이터가 귀무가설을 지지하지 않는다고 판단한 것 뿐!
기각 or 기각하지 않음만 판단
회귀 결과에서 p-value가 0.0001이고, 𝛽1 = 2.5라면 이 회귀계수에 대해 어떤 해석을 할 수 있는가?
-
p-value = 0.0001(매우 작음)
→ 이 회귀계수가 통계적으로 유의하다 -
𝛽1 = 2.5
X가 1 단위 증가하면 Y는 2.5 증가하며, 이 관계는 유의수준 0.05보다 훨씬 작은 p-value를 가지므로 통계적으로 매우 유의미하다.
일기
- SQL
코드카타 75-76❌ - 통계
전체 복습✅기초강의 6주차 복습✅ - 수준별학습
전체 복습✅ - 머신러닝
기초강의 1-2강✅
머신러닝 강의 듣느라 코드카타 못하고 ..
일단 전체 복습 한번 쫙 했는데 아직 헷갈리는 개념이 몇 개 있다
지피티한테 퀴즈 내달라고 하는 거 좋은 것 같아서 잘 활용하는 중 🫡
내일은 QCC 하는 날이니까 파이썬은 유기하고 SQL 코드카타 조져야지🍀 만점 해보자 가보자 할 수 있따
💿오늘의 추천곡 Anderson Paak - Jet Black

조흔~ 노래~
