
팀스터디
1차회의
개인 의견
-
분류
-
금융
신용등급이 진짜로 유의미한 등급인지 분석해보면 재밌겠다는 생각을 했읍니다 근데 lending club이 아무래도 은행이 아니라 개인 투자자들이 개인에게 대출을 해주는 형태라 여기만의 신용등급을 매기고 뭐 그런..걸 할 수 있을까요? -
제조
이것도 도메인지식이.. 어느정도 필요한 데이터가 아닌가..ㅎ
-
-
군집
- 마케팅
제일 만만해보임 답이 어느 정도 정해져있는 것 같음 재미없어보여서 안 하고 싶어요ㅎㅎ;; - 금융
기본적으로 금융 도메인에서 고객 클러스터링을 하는 이유가 뭘까요..?
토스를 생각해보면 고객 군집을 나눠서 맞춤형으로 알람을 보내준다든지, 어플 이용자수를 늘리기 위해 재밌는 요소들을 넣는다든지 하는 게 떠오르네용 막 소비태그같은 거 붙여서……..하는거…….?근데 이걸 어케 연결할지는 잘 모르겠어요
- 마케팅
-
회귀
- 제일 재밌어 보이긴 하는데 이상치 제거에서 굉장히 힘들 것 같다는 생각이 들어요 💦
- 그냥 예측을 해서 어떤 인사이트를 낼 수 있을지 생각해보면..
호스트를 기준으로 한다면 가격이 비싼 날을 예측해서 가격 추천 시스템을 개발할 수 있을 거고, 방문자를 위한다면 스카이스캐너마냥 가격이 비교적 저렴하게 갈 수 있도록 하는 …어플??을 개발??한다 머 이런 인사이트가 나올 수 있지 않을까요
-
이상탐지
비지도학습이기도 하고 도메인지식이 필요할 것 같습니다
결론
-
일단 공통적으로 이상탐지 x / 분류 - 제조 x
-
흥미로운 걸 두 개를 꼽아보면
- 에어비앤비 → 전처리, 인사이트 나오는 시간은 짧은데 분석 시간은 길듯
- 군집 - 금융 → 전처리, 인사이트 나오는 시간은 긴데 분석 시간은 짧을듯
-
군집 - 금융데이터로 결정
튜터 질의응답
-
Q1) mcc codes.json 파일 안 써도 되나요?
visa로 대체? → 더 세분화 되어 있어서 그런건가?- A1) 둘 다 활용하는 게 좋을듯 → 변수 조합을 다양하게 고려 / normalize 필요
-
Q2) 피처 선택 시 중요도에 나의 생각을 투영해도 되나요?
- A2) 상관없음 / 비지도학습이라 정답은 없음
-
기획을 세분화하는 것은 좋은 전략
대주제 : 고객을 세분화해서 맞춤전략을 제공하겠다 -
실험 시 모든 컬럼을 다 넣어주는 게 좋음
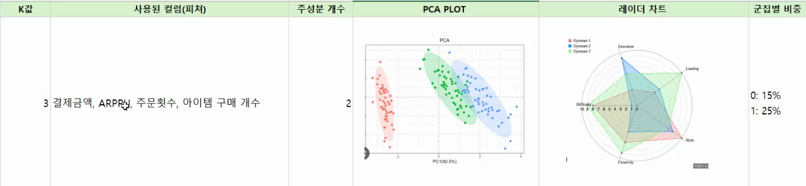
→ scree plot → range 나눠서 보기 (ex. k = 4, 3…)*이때 실험 결과 기록해야 함
-
다른 기법도 충분히 쓸 수 있음
(클러스터링을 하기 위한 중간 과정의 하나로) -
- EDA에서도 중요한 것만 보여주기
- 반드시 EDA 기법을 사용해야 하는 것 아님 / 도메인 지식 충분히 활용
- EDA에서도 중요한 것만 보여주기
-
파생변수 설정 중요
-
라인차트(평균), 레이더차트 유의미
-
생키차트(시간에 따라 고객이 어떻게 흘러갔는지)
전체 분석흐름
- 시장 현황
- 문제 제기(또는 흥미)
- 프로젝트 목적
분석
-
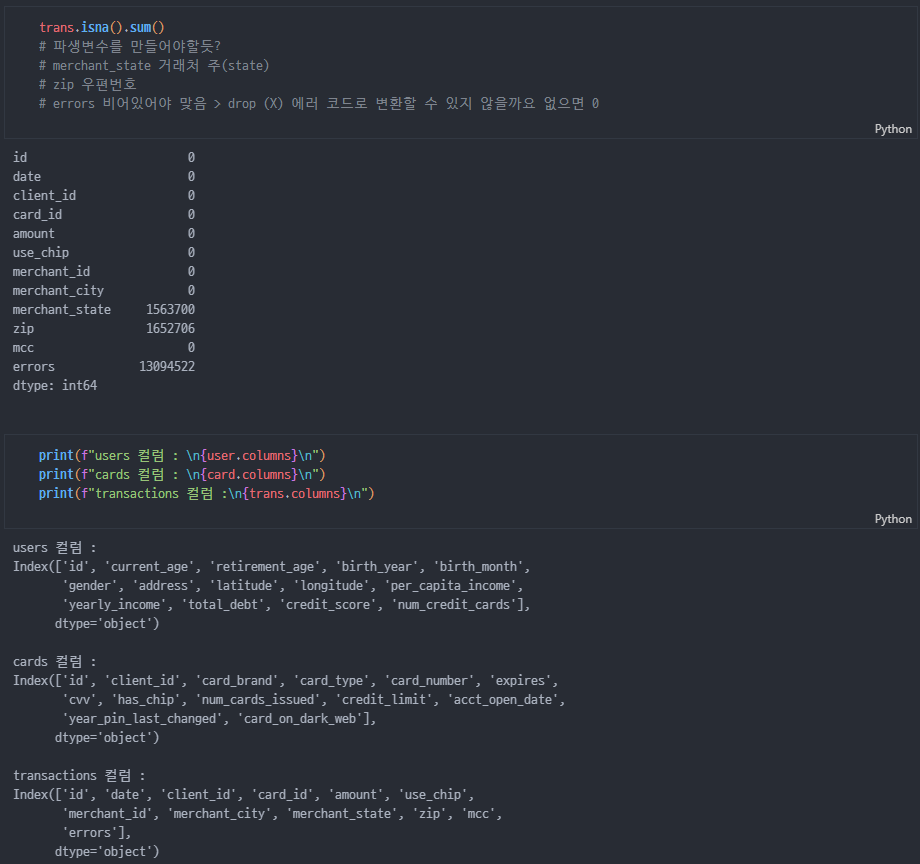
전체 데이터셋 EDA
- 결측
- 이상
- 시각화(분포)
- 고객/제품/판매자/대출상품
-
상세분석(상관관계 및 통계적 가설검정이 사용될 수 있습니다.또한 시장 동향자료가 배치되어도 좋습니다. )
- 가설 1
- 가설 1 결과 해석
- 가설 2
- 가설 2 결과 해석
-
ML
- 실험 반복.
- 인원을 나눠 K값 분배. 피쳐변경하시면서 실험 결과값 기록 후 취합.
- 클러스터 요약(1번군집은 OOO 이다)
-
분석 결과
- 클러스터별 인사이트 및 기대효과
- 회고
2차회의
목표
- 각자 EDA 진행 → 17:50 중간보고/ 20:00 최종보고
- 세부 주제 정하기
- 역할 분담
EDA
- import
일단 쓰는 것만

-
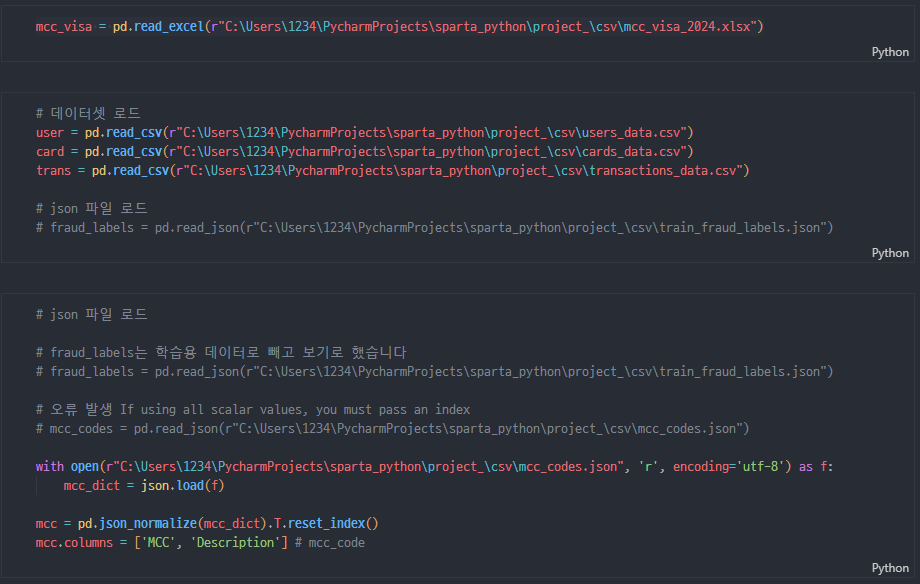
데이터셋 로드
-
mcc codes, mcc_codes_visa
-
display

-
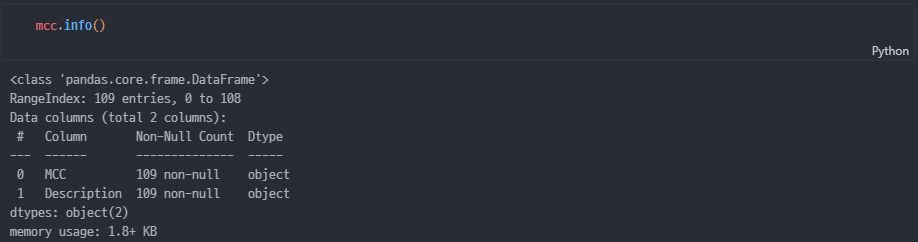
info
-
mcc object로 확인됨
-
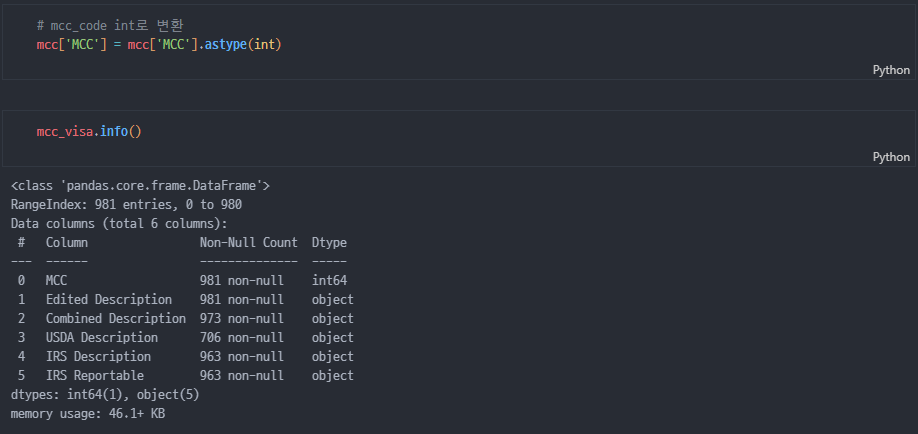
int로 변형하고 다시 확인
-
-
json mcc랑 visa mcc랑 비교해보기
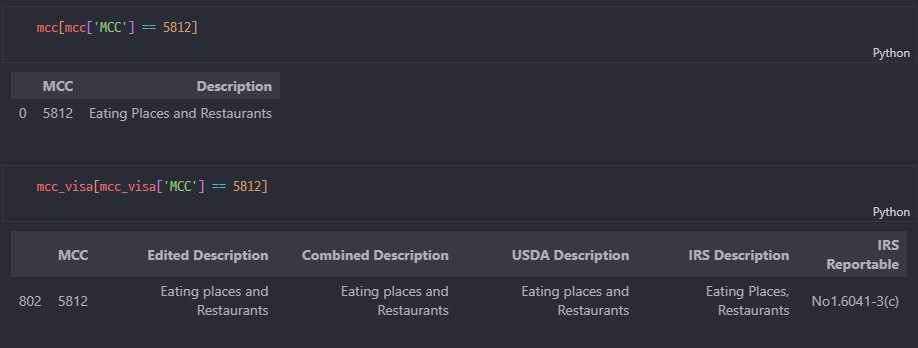
-
merge하고 확인
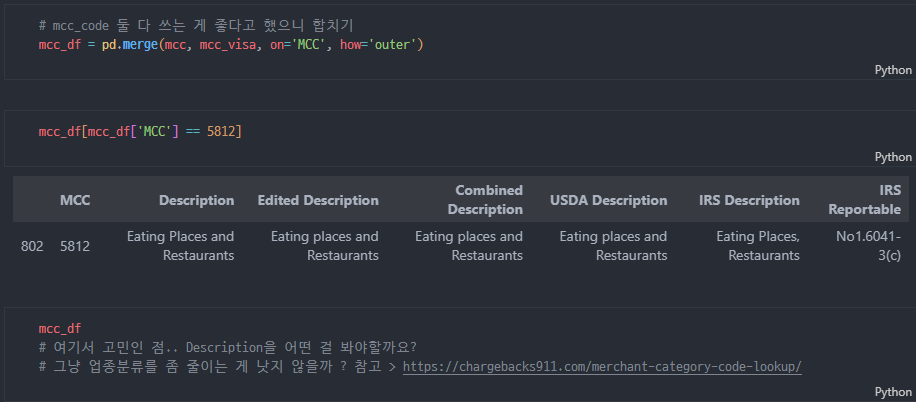
- Description들이 너무 많은데 category화 해서 나누는 게 좋지 않을까 생각함
🔗 mcc range 참고자료
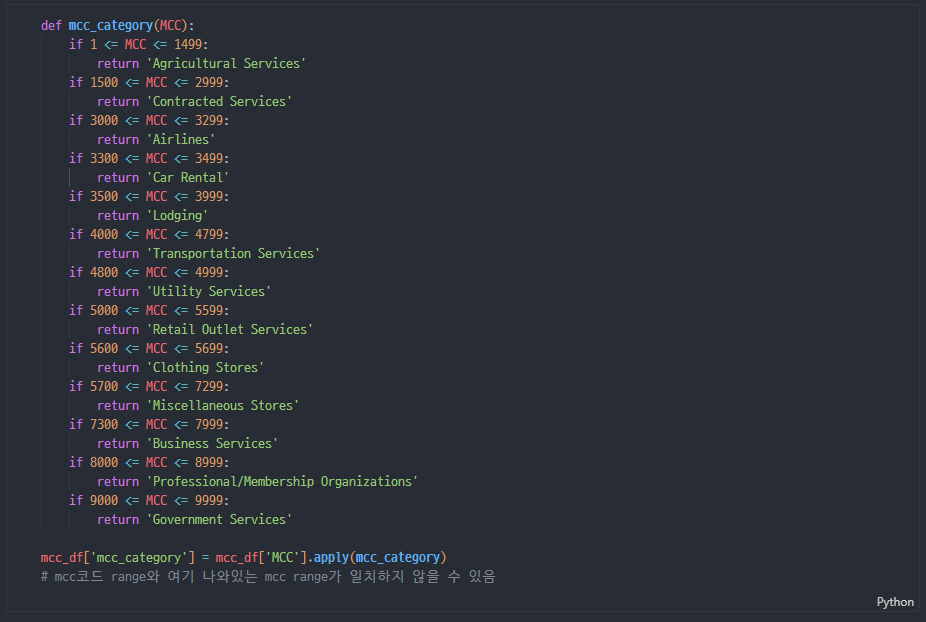
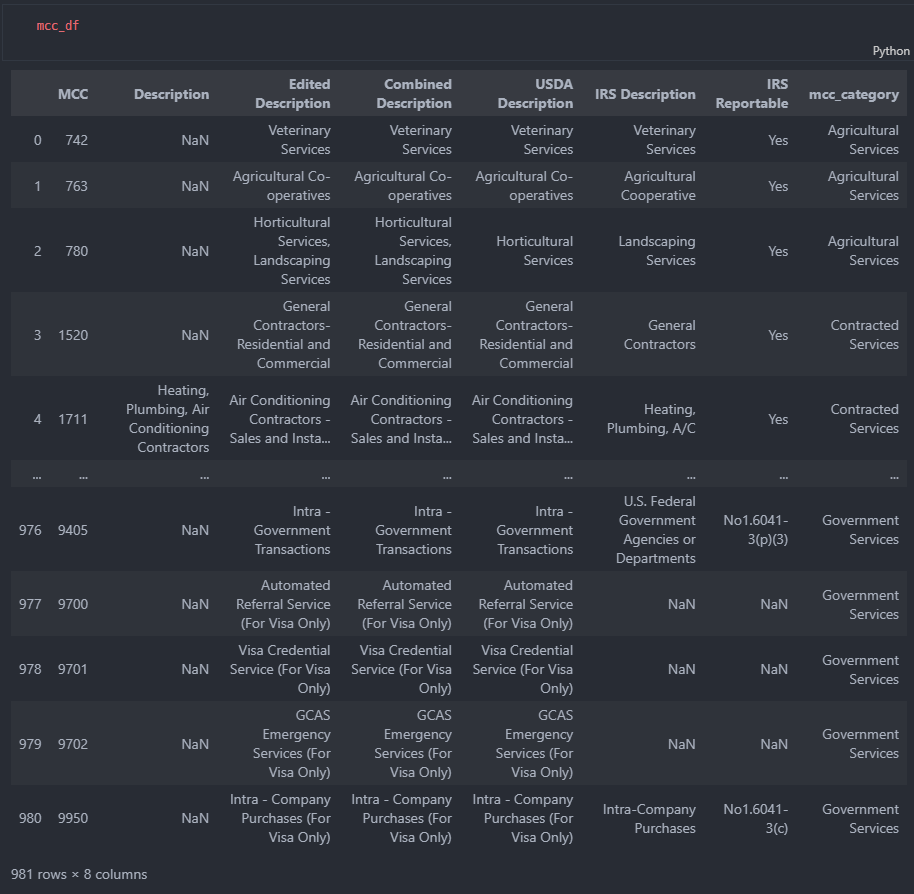
- Description들이 너무 많은데 category화 해서 나누는 게 좋지 않을까 생각함
-
이상치 확인

-
필요없는 컬럼 버리기
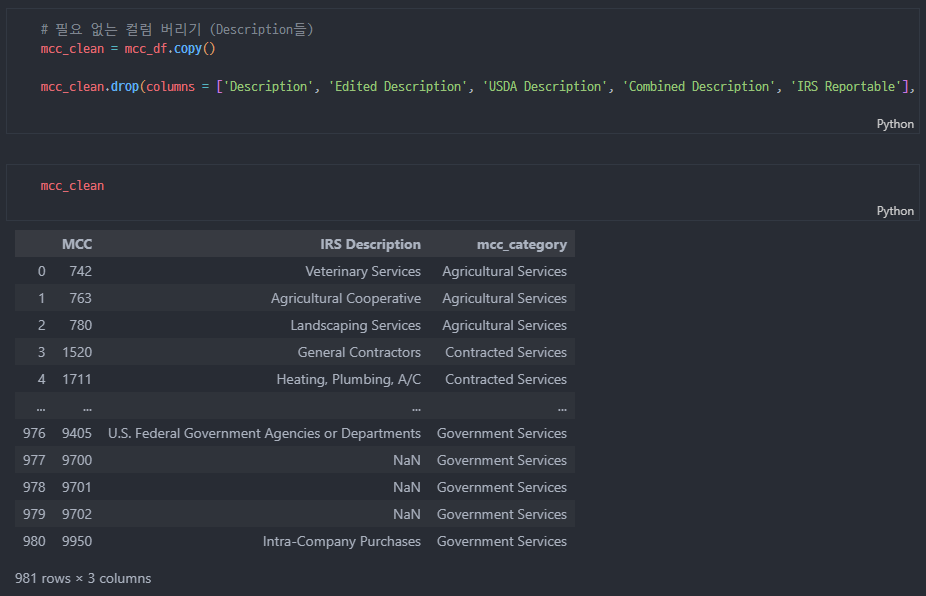
- users / cards / transaction
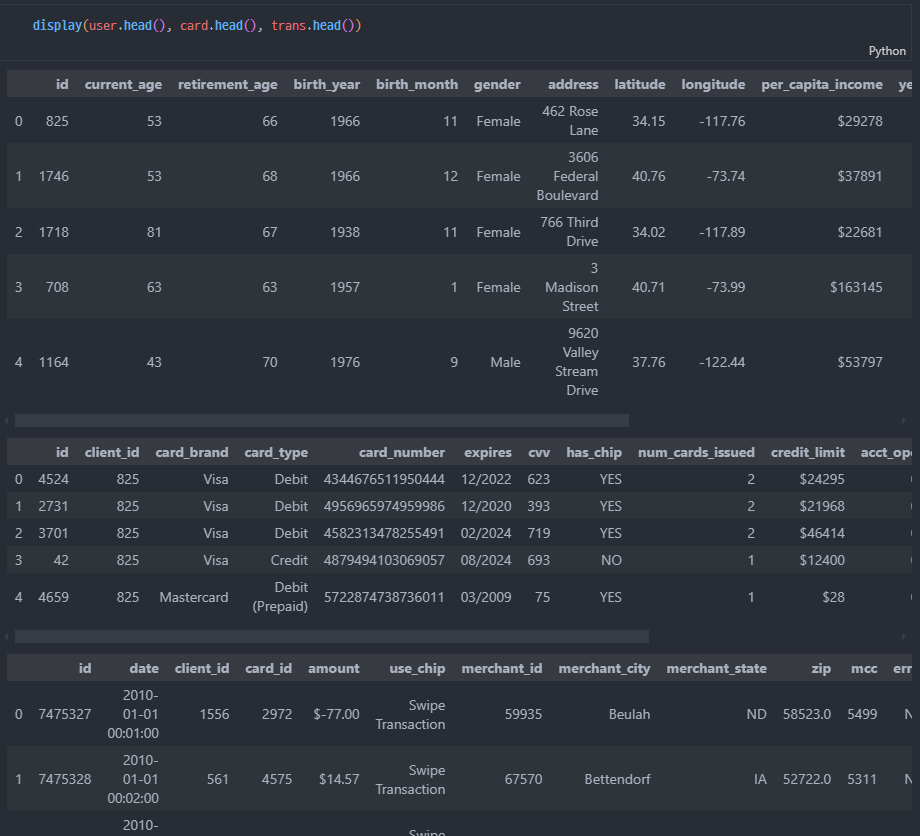
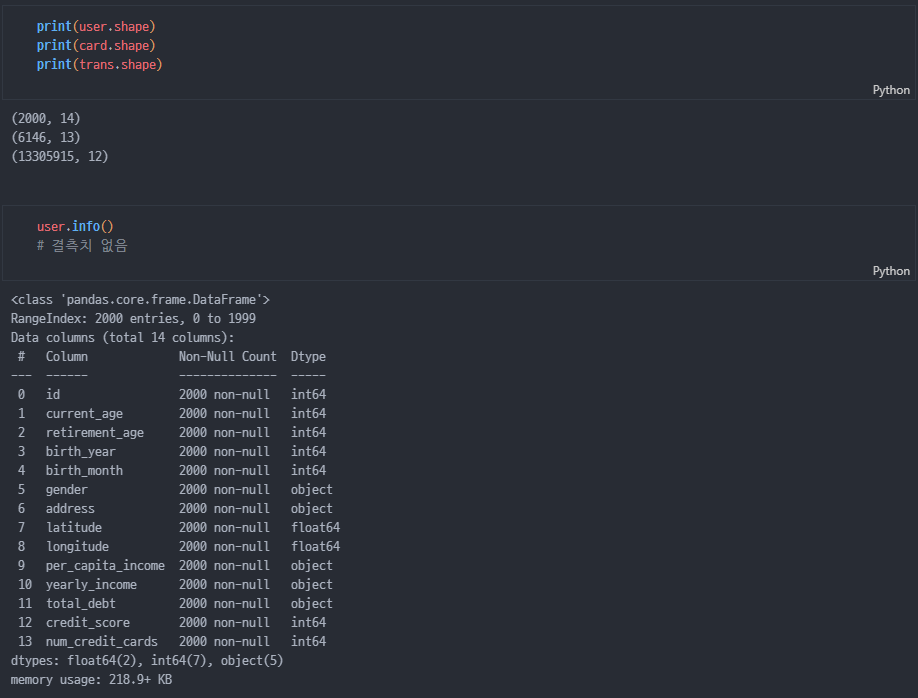
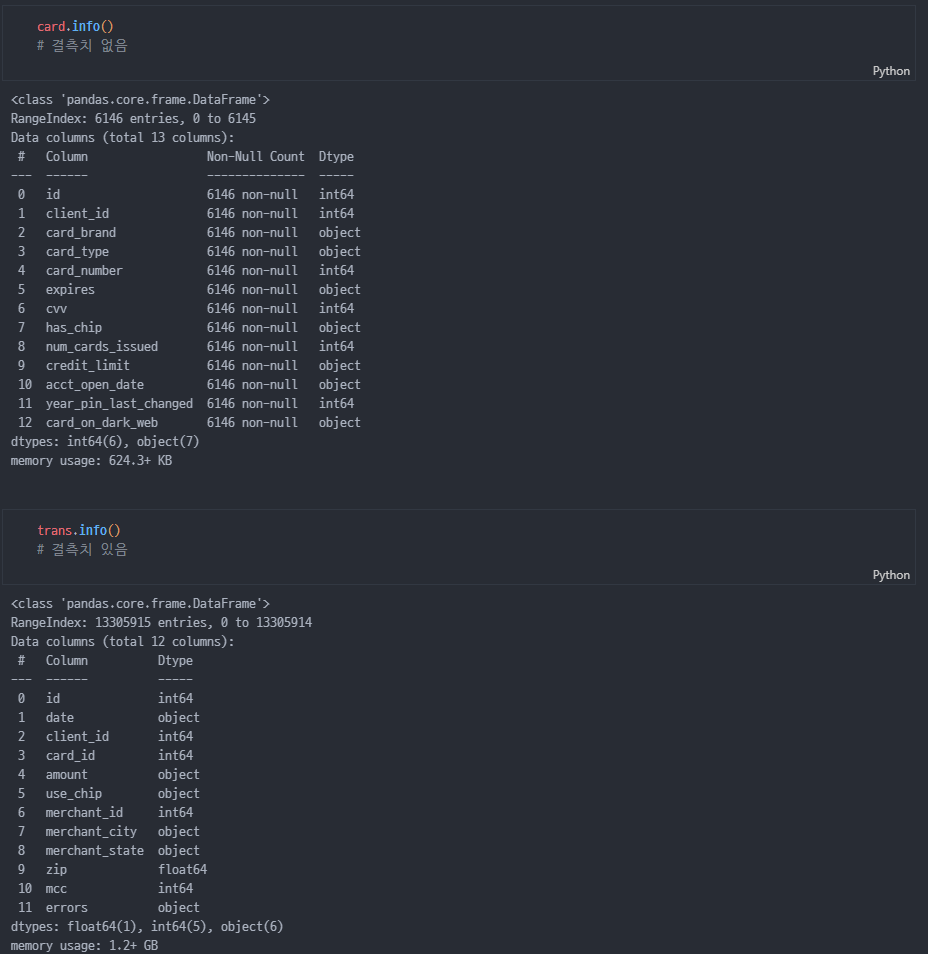
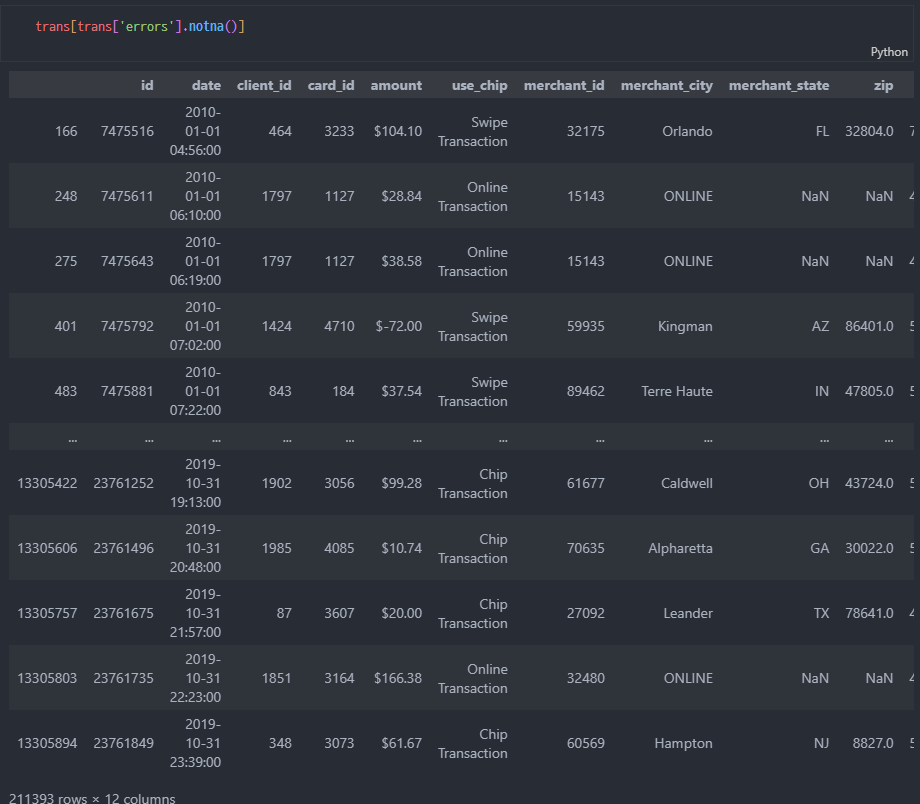
3차회의
- 날짜를 언제부터로 볼건지? => 논의
- 주황님은 이상치를 보는중
- 사기라벨? > 이건 train 데이터 셋이어서 그건 아닌 것같음 > 튜터님 확인 ㅇ
ㄴ 이거 데이터셋 보면 Perfect for analyzing spending patterns and building fraud detection models 라고 되어있어서 원래 이상탐지까지 같이보는 셋인것 같아요
ㄴ 시간이 남으면 이상탐지를 하겠지만 아마 .. 안되겠지요?
결과
-
확실히 이상한 데이터
-
users > 희린
- 나이 0살 이하
- total_debt 부채 음수
- per_capita_income, yearly_income 1인당소득, 연간소득 음수
- credit_score 음수
- num_credit_cards 보유 신용카드 수 0 >> 형진님 확인 / 없음
- birth_date > expire_date
- 상관관계도 보기 + 시각화
-
cards > 동윤, 주황
- credit_limit 카드 한도 0 > 그럴수있나요? > ???
-- prepaid_card (선불카드)에 돈이 없으면 in ~ balance라고 오류가나옴
-- 신용카드 전략 / 체크카드 전략이랑 나누기
-- 확인을 해보세요 ㅋㅋ - has_chip = 0 인데 transaction에서 use_chip 인 사람
- card_number 카드 자리수가 비정상적인사람(길, 짧)
- 상관관계도 보기 + 시각화
- credit_limit 카드 한도 0 > 그럴수있나요? > ???
-
transactions > 수희, 형진
-
zip 우편번호 비정상(길,짧)
-
merchant_state 미국 주 코드 비정상(길,짧)
-
mcc가 1 ~ 9999 범위가 아닌것
-
amount가 음수인 것 (환불금액인지, 아닌지)
-
기간 2017/1/1 ~ 2019/10/31
-
상관관계도 보기 + 시각화
카드정보로 뭐 할 거 아니니까 빼도됨(민감정보 - 카드정보, 위도, 경도)
ㄴ고객의 기준으로 삼는 거면 괜찮지않나?
-
-
시각화
-
- 처리해야할 것
- transactions
- amount $표시 떼고 int로 바꾸기
- mcc df랑 결합해서 해당하지 않는 데이터 > 이상
- transactions
데이터를 결합했을때 서로 잘 맞는 데이터인 것 같다 ?
확실한 이상치 먼저 제거하고 파생변수
상관분석할 거 정리
-
소득대비 지출 많다/적다
ㄴ할부가 많이되는 카드? -
지역에 따른 소비패턴
ㄴ가맹점 위치에 따라서 활동반경을 볼 수 있다 (집밖으로 안나가는사람 -> 온라인쇼핑) *
ㄴgeocode > 시각화 추가
ㄴgeopandas -
연령/성별별 소비패턴
-
신용점수 * > 유의미한 차이가 있을지는 모르겟음
ㄴ할부가 많아지면 점수가 떨어지고
ㄴ연체가 점수가 떨어지고
ㄴ카드대금을 밀리지 않고 냈을때
ㄴ등급별로 나누는것도 괜찮지않냐
(POOR/FAIR ~어쩌고저쩌고) -
계좌개설일자 *
ㄴ나이 대비 금융활동일? > 파생변수 ? 이 긴사람은 ...머 어쩌고다
ㄴ계좌를 만든지 오래됐는데 돈을 안써 ???? > 휴면계좌 (금융 활동성?)
ㄴlast_pin_change랑 연관지을수도있을듯 -
소득 대비 카드한도
-
자주 쓴 가맹점(가게) + 한번 갔는데 돈을 많이 쓰는곳
-
카드 타입(debit vs credit vs pre-paid)
ㄴ나이랑 상관관계가 있지않을까
ㄴ신용이 있어야 신용카드를 쓰니까
일정
-
21 점심까지 각자 확실한 이상치/결측치 전처리를 > 월요일 밤까지 전처리
ㄴeda(분포 확인) 먼저 제거할때도 증명이 필요 (시각화 근거 제시)
ㄴ그대로 써도 성능이 좋을 경우 새로운 인사이트임 ! -
25 분석을 끝낸다
-
28~29 자료준비
-
29일 밤까지는 발표자료, ppt, 인사이트 / 30일 오전 10시까지 최종제출
역할 분담
-
PPT : 희린
-
발표 : 수희
-
영상발표 : 동윤
-
코드 (다같이^^~)
ㄴ전처리
ㄴ머신러닝 k값 ? -> 추가로 나눠야할 사항
일기
- 프로젝트
주제선정✅EDA✅계획✅
오늘은 뭐 한 건 없고 프로젝트 주제선정하고 머 이런저런거 했다
힘들다 그만써야지 !
💿오늘의 추천곡 Frank Ocean - White Ferrari

