팀스터디
아티클 스터디
선정 아티클
개인 요약
- 요약 : 파이썬 초보자가 저지르는 10가지 실수
from xyz import *사용- 비효율적
- 필요한 모듈만 가져오기
except절에 예외가 없음- 에러 상황 대비 예외상황 명시
- 연산 시
numpy사용을 하지 않음- 다른 방식으로도 풀 수 있으나, numpy가 빠름(벡터화)
- 이전에 열었던 파일을 다시 닫지 않음
with구문을 사용 → 예외 발생 시에도 파일 닫기 가능
- PEP8 가이드라인을 벗어남
- 스타일 가이드를 지켜 작성하기
- 딕셔너리 사용 시
.keys.values를 적절히 사용하지 않음- 반복문으로도 key 값 얻을 수 있음
.items()사용해 value 값 얻을 수 있음
- 컴프리헨션을 적절히 사용하지 않음
- 컴프리헨션 자체가 매우 효율적
- 과도하게 사용할 경우 복잡함
range(len())사용- 대신
enumeratezip사용 → 작업 단순화
- 대신
- 문자열 연결 시
+사용- 가독성 떨어짐 →
f-string방식 이용
- 가독성 떨어짐 →
mutable value를 디폴트 매개변수로 사용- 이전 호출 값 계속 저장됨 → 디폴트값을
[]대신None으로 설정
- 이전 호출 값 계속 저장됨 → 디폴트값을
인사이트
-
“파이썬스러운” 방식으로 코드를 짜는 것이 매우 중요하다는 것을 다시금 느낄 수 있었습니다. 가독성 + 효율성 두 가지를 다 잡은 코드를 짜는 것은 항상 어려운 것 같아요 🤣
-
특히 코드카타 문제를 풀고 나면 다른 사람 풀이를 항상 추가로 보는 편인데, 컴프리헨션을 써서 한줄로 표현하는 분들이 참 많더라고요.. 저는 컴프리헨션 쓰는 게 아직까지 어렵게 느껴지는데 (쓰는 것과 별개로 이해하는 것도 아직 어려움) 연습을 많이 해야겠다고 생각했습니다.
개인스터디
실무에 쓰는 머신러닝 기초 7강
* 머신러닝
├── 지도학습
│ ├── 분류 (Classification) → KNN, 로지스틱 회귀, SVM
│ └── 회귀 (Regression) → 선형회귀, Lasso, Ridge
│
├── 앙상블
│ ├── 배깅 (Bagging) → Random Forest
│ └── 부스팅 (Boosting) → XGBoost, LightGBM, CatBoost
│
├── 비지도학습
│ ├── 군집 (Clustering)✅ → K-means, DBSCAN
│ ├── 차원축소 (Dim. Reduction) → PCA, t-SNE
│ └── 이상탐지 (Anomaly Detection) → One-Class SVM, Isolation Forest
│
└── 강화학습 (Reinforcement) 🔷 군집
유사한 특성을 가진 데이터끼리 묶어 군집화
군집 내 유사성↑, 군집 간 차이↑
프로세스
1️⃣ 데이터 수집 & 전처리
: 결측치/이상치 처리, 정규화
2️⃣ 군집 수 설정 or 파라미터 지정
- K-Means → k
- DBSCAN → eps, minPts
3️⃣ 군집화 알고리즘 적용
4️⃣ 결과 해석 및 평가
실루엣 계수 등 군집 평가지표 활용
5️⃣ 활용
비즈니스 전략, 이상치 탐지 등
K-Means
k개의 군집으로 나누는 거리 기반 알고리즘
-
각 군집에 대해 중심 정의, 데이터를 가장 가까운 중심에 할당
-
중심 재계산 & 재할당 반복 → 군집 내 거리 최소화
-
장단점
-
장점
구현이 간단하고 속도 빠름
대용량 데이터에 잘 작동 -
단점
군집 수(k)를 미리 정해야 함
이상치 민감(평균 기반 중심 계산)
비구형 군집 구조를 파악하기 어려움
-
-
예시
- 고객 세분화(나이, 평균 지출액 등 수치형 변수 기반)
-
라이브러리
from sklearn.cluster import KMeans
DBSCAN
밀도 기반 군집화 알고리즘

-
특정 거리(ε) 내에 이웃 데이터가 minPts 이상이면 군집 생성
-
고밀도 영역 → 군집, 저밀도 영역 → 노이즈(이상치)
-
장단점
-
장점
군집 수 지정 불필요
이상치 자동 감지
복잡한 모양도 탐색 가능 -
단점
eps, minPts 설정에 민감
밀도가 다양한 데이터에 부적합
-
-
예시
- 지도에서 매장 밀집 지역 군집화
- 센서 데이터에서 이상 작동 감지
-
라이브러리
from sklearn.cluster import DBSCAN
계층적 클러스터링(Agglomerative Clustering)
데이터를 계층적으로 묶어나가는 방식

-
병합형 : 각 데이터를 군집으로 시작 → 유사도 높은 군집끼리 병합
-
분할형 : 하나의 군집에서 출발 → 점차 분할
-
장단점
-
장점
덴드로그램으로 군집 구조 파악 쉬움
유연한 군집 개수 설정 -
단점
계산 복잡도 ↑ → 대규모 데이터엔 느림
-
-
예시
- 유전자 데이터 분석
- 문서 클러스터링
-
라이브러리
from sklearn.cluster import AgglomerativeClustering
주요 군집 알고리즘 비교
| 알고리즘 | 특징 | 장점 |
|---|---|---|
| K-Means | 거리 기반 | 빠르고 간단 |
| DBSCAN | 밀도 기반 | 이상치 탐지, 복잡한 군집 처리 가능 |
| 계층적 클러스터링 | 유사도 기반 병합 | 덴드로그램 시각화 가능 |
🔷 군집모델 평가지표
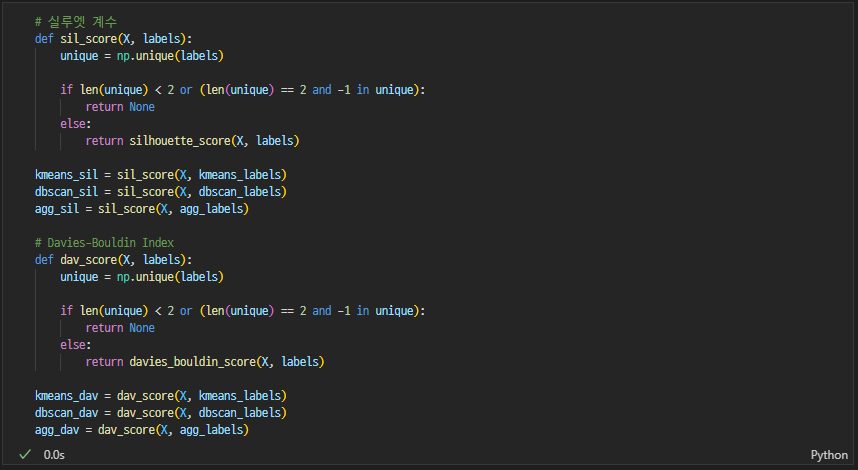
실루엣 계수
- (b - a) / max(a, b)
- 각 데이터 포인트의 응집도(a)와 분리도(b)를 이용해 계산
- 응집도(a) : 같은 군집 데이터와의 평균 거리
- 분리도(b) : 가장 가까운 다른 군집과의 평균 거리
- 라이브러리
from sklearn.metrics import silhouette_score - [-1, 1] 범위 → 1에 가까울수록 좋음
Davies-Bouldin Index
-
군집 간 분산과 거리의 비율
-
라이브러리
from sklearn.metrics import davies_bouldin_score -
0 이상 → 작을수록 좋음
내부 평가 vs 외부 평가
| 평가 방식 | 설명 |
|---|---|
| 내부 평가 | 데이터 자체의 특성(분산, 거리 등)을 이용해 클러스터 품질을 평가 |
| 외부 평가 | 정답 레이블(ground truth)이 존재할 때, 군집 결과와 실제 레이블을 비교 평가 |
☑️ 요약
- 비지도 학습은 레이블 없이 구조를 파악
- 클러스터링은 데이터 유사성 기반 그룹화
- K-Means, DBSCAN, 계층적 군집 - 상황에 맞춰 선택
- 실루엣 계수 & Davies-Bouldin 등으로 평가
- 분석 후에는 활용 방안까지 연결해야 진짜 가치 창출!
☑️ Q&A
| 질문 | 답변 요약 |
|---|---|
| 군집 수 k는 어떻게 정하나요? | 엘보우 기법, 실루엣 계수로 최적 k 탐색 |
| K-Means vs DBSCAN | K: 빠르고 간단 / D: 이상치 감지 탁월 |
| 성능 평가 | 내부 지표(Silhouette, DB) or 외부 레이블 기반 비교 |
| 결과 해석 | 각 군집의 특성(평균, 변수 분포) 분석 |
| 이상치/결측치 처리 | 결측값 처리 + 이상치 제거/보정 + 스케일링 필수 |
| 만족스럽지 않을 땐? | 다른 알고리즘 or 파라미터 조정 시도 |
| 실무 적용 방식 | 목적 설정 → 데이터 수집 → 전처리 → 군집화 → 평가 → 인사이트 도출 → 실행 전략 연결 |
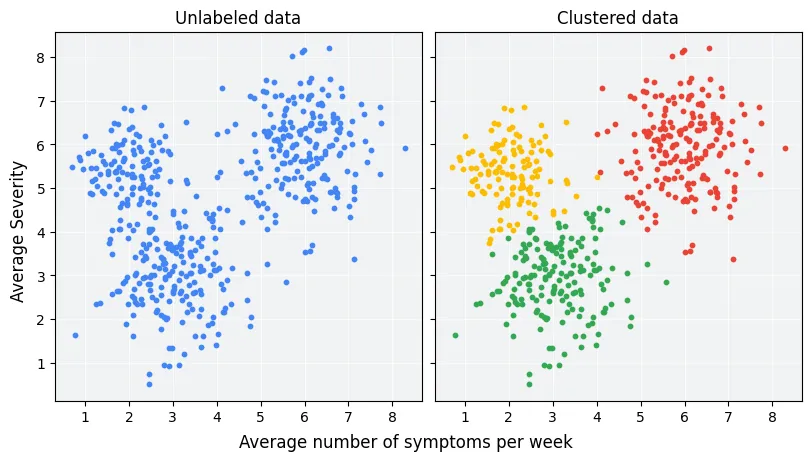
실습
- Wine 데이터셋 로드
load_wine()함수를 통해 와인 데이터를 가져옵니다.- 13개 연속형 특성과 3개의 와인 품종 레이블로 구성되어 있습니다.
- 군집 자체는 비지도학습이므로
y레이블은 직접 사용하지 않습니다(평가용으로 간단히 참고하거나 무시).- 3개의 군집 모델 모두 사용
- DBSCAN의 경우 eps, min_samples 값에 따라서 군집이 나오지 않을 수도 있습니다
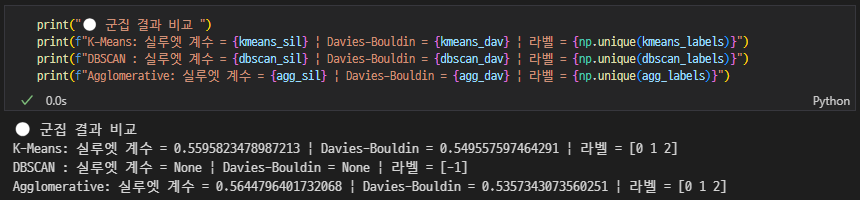
- 실루엣 지수와 Davies-Bouldin 지수 계산
- PCA 시각화 진행
-
데이터셋 로드
-
데이터프레임으로 만들기
-
필요 라이브러리 import

-
KMeans / DBSCAN / 계층적 클러스터링
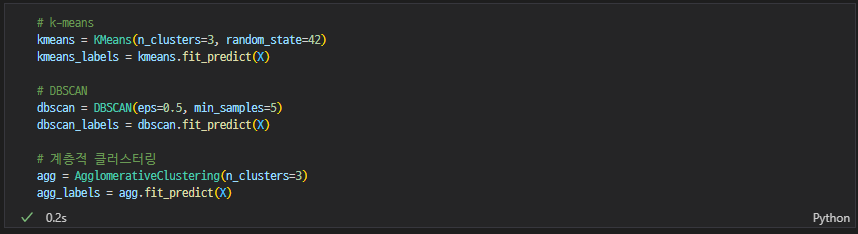
-
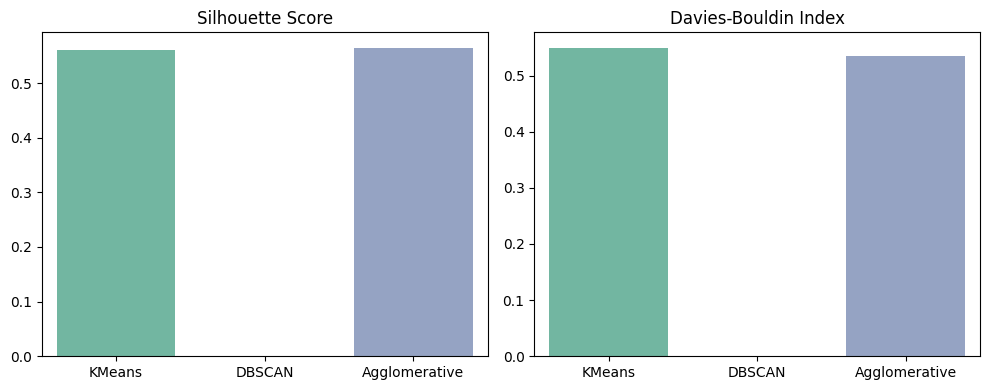
군집 결과 평가 (Silhouette, Davies-Bouldin) + 시각화
-
차원축소(PCA) → 시각화
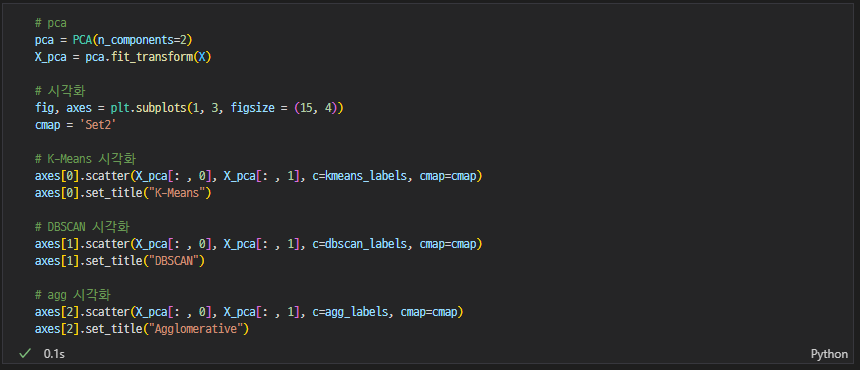
실무에 쓰는 머신러닝 기초 8강
* 머신러닝
├── 지도학습
│ ├── 분류 (Classification) → KNN, 로지스틱 회귀, SVM
│ └── 회귀 (Regression) → 선형회귀, Lasso, Ridge
│
├── 앙상블
│ ├── 배깅 (Bagging) → Random Forest
│ └── 부스팅 (Boosting) → XGBoost, LightGBM, CatBoost
│
├── 비지도학습
│ ├── 군집 (Clustering) → K-means, DBSCAN
│ ├── 차원축소 (Dim. Reduction)✅ → PCA, t-SNE
│ └── 이상탐지 (Anomaly Detection) → One-Class SVM, Isolation Forest
│
└── 강화학습 (Reinforcement) 🔷 차원축소
- 고차원 데이터
- 피처(변수) 가 매우 많은 상태
- 연산 복잡도 증가 → 오래 걸림
- 노이즈 존재
- 시각화 어려움 → 패턴 파악 어려움
- 차원 축소 시 장점
- 연산 효율 ↑
- 핵심 정보 유지
- 시각화 가능
- 노이즈 제거
선형 차원축소
선형 변환으로 투영하여 차원을 줄이는 기법
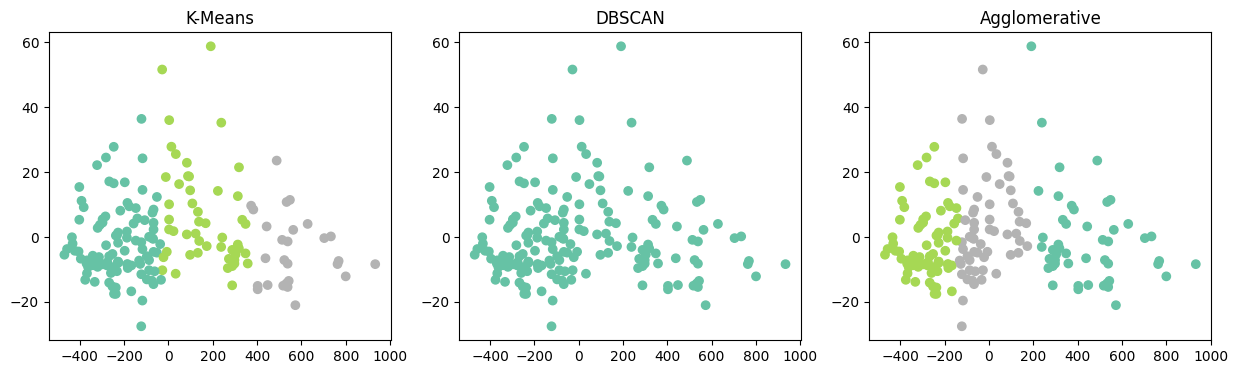
PCA
데이터의 분산이 가장 큰 방향으로 축소
- 주성분
- 가장 큰 분산을 갖는 방향 : 1주성분
- 그 다음 큰 분산을 갖는 서로 직교(90º)하는 방향 : 2주성분
- 설명 분산비율
- 몇 개의 주성분만으로 전체 분산의 몇 %를 설명할 수 있는지
- 장단점
- 장점
계산이 비교적 간단
결과 해석 용이
노이즈 제거 효과 - 단점
선형이 아닌 패턴일 경우 정보 손실 발생
복잡한 구조 반영 어려움
- 장점
- 라이브러리
from sklearn.decomposition import PCA
비선형 차원축소
선형 변환만으로 충분치 않아 비선형 매핑을 이용
t-SNE
‘가까운 포인트는 가깝게, 먼 포인트는 멀리’ → 지역적 구조 시각화
- 장단점
- 장점
데이터 군집이 자연스럽게 시각화
패턴 인지 쉬움 - 단점
계산 비용이 큰 편
하이퍼파라미터 튜닝 필요
거리 왜곡 가능성 O
- 장점
- 라이브러리
from sklearn.manifold import TSNE
UMAP
비선형적으로 휘어진 공간(매니폴드)을 펼쳐 매핑(t-SNE와 유사)
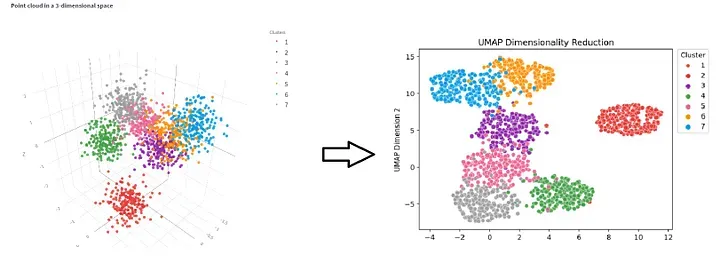
- 장단점
- 장점
t-SNE보다 빠름
지역적/글로벌 구조 함께 반영 - 단점
비교적 복잡
하이퍼파라미터 튜닝 필요
t-SNE 만큼은 아니나 거리 왜곡 가능성 O
- 장점
- 라이브러리
from umap import UMAP
📌 t-SNE / UMAP
시각화 목적에서 많이 쓰임
"서로 비슷한 포인트끼리 가까이 두는" 비슷한 방식
주요 차원축소 알고리즘 비교
| 기법 | 종류 | 장점 |
|---|---|---|
| PCA | 선형 | 계산 빠름, 해석 쉬움 |
| t-SNE | 비선형 | 지역적 구조 시각화 |
| UMAP | 비선형 | 지역적/글로벌 구조 시각화 |
실무 적용 시 고려사항
-
데이터 전처리
-
하이퍼파라미터 튜닝
- PCA : 주성분 개수를 얼마나 선택할지
- t-SNE : perplexity, learning rate, iteration 수
- UMAP : n_neighbors, min_dist 등
-
결과 해석
- PCA : 주성분 방향이 어떤 피처 조합과 관련이 있는지 해석
- t-SNE / UMAP : 시각화를 통해 군집 형태나 분포 확인하는 정도로만 사용
-
성능측정 및 검증
- 차원축소만의 별도 지표 X
☑️ 요약
- 고차원 데이터 = 시각화와 연산 복잡도 측면에서 어려움 → 차원 축소
- PCA: 선형 차원 축소 / 계산이 빠르고 해석이 직관적
- t-SNE, UMAP : 비선형 구조 반영 / 시각화에 효과적
☑️ Q&A
| 질문 | 답변 요약 |
|---|---|
| PCA vs t-SNE/UMAP | PCA는 선형 변환으로 분산이 가장 큰 축 기준 차원 축소. t-SNE/UMAP은 비선형 방식으로, 이웃 간 근접도를 보존해 2D/3D로 시각화함. |
| 주성분 개수 | 설명 분산 비율 를 확인 → 누적 설명력 80% 이상 되도록 선택 / 업무 목적에 맞춰 시각적으로 해석 가능한 범위로 선택 |
| t-SNE/UMAP 시각화를 분류 기준으로? | ❌ 거리 정보 왜곡 가능성 있음 추가 검증 필요 |
| PCA 결과 해석 | pca.components_ 가중치 확인 가능 → 주성분의 의미나 특징 해석 |
| 정보 손실? | ⭕ 일부 정보가 손실됨 / 다만, 중요한 정보(분산 큰 방향)는 보존되고, 노이즈 제거 효과도 있음 |
실무에 쓰는 머신러닝 기초 9강
* 머신러닝
├── 지도학습
│ ├── 분류 (Classification) → KNN, 로지스틱 회귀, SVM
│ └── 회귀 (Regression) → 선형회귀, Lasso, Ridge
│
├── 앙상블
│ ├── 배깅 (Bagging) → Random Forest
│ └── 부스팅 (Boosting) → XGBoost, LightGBM, CatBoost
│
├── 비지도학습
│ ├── 군집 (Clustering) → K-means, DBSCAN
│ ├── 차원축소 (Dim. Reduction) → PCA, t-SNE
│ └── 이상탐지 (Anomaly Detection)✅ → One-Class SVM, Isolation Forest
│
└── 강화학습 (Reinforcement) 🔷 이상 탐지
정상(Normal) 패턴에서 크게 벗어난 이상(anomaly) 패턴을 찾는 기법
비지도학습 기반으로 동작
대표 예시
- 카드 사기, 계좌 해킹 감지
- 기계 설비 고장 예측
- 네트워크 침입 시도, 데이터 탈취 감지
이상치 탐지 vs 이상 탐지
| 구분 | 이상치 탐지 (Outlier Detection) | 이상 탐지 (Anomaly Detection) |
|---|---|---|
| 초점 | 통계적 극단값 | 맥락 기반 이상 행동 |
| 방식 | 평균/분산 등 수치 기준 | 시계열, 상관관계 고려 |
| 예시 | 평균보다 3배 이상 높은 값 | 평소에는 적절한 값이나, 특정 시간대엔 비정상 |
One-Class SVM
하나의 클래스(정상)만 학습 → 경계(boundary) 형성
경계 밖 데이터 = 이상으로 분류
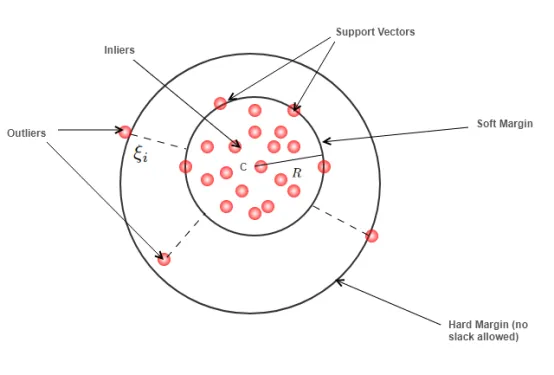
- 1 정상 / -1 이상치
- 특징
- 커널(필터) 사용 가능 → 고차원 공간에서도 잘 동작
- 데이터 스케일링, 커널 파라미터 선택 중요
- 라이브러리
sklearn.svm import OneClassSVM
Isolation Forest
무작위로 특성과 분할값을 골라 데이터를 계속 나눔
쉽게 분리(격리)되는 데이터 = 이상으로 분류
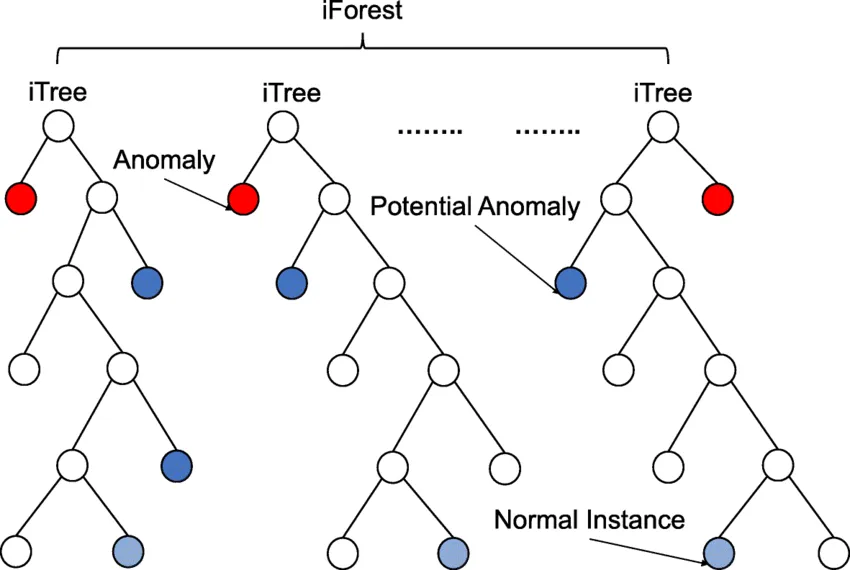
- 1 정상 / -1 이상치
- 특징
- 깊이(depth)를 측정하여 이상 점수 부여
- 간단, 직관적 / 대규모 데이터셋에서 빠르게 동작
- 라이브러리
from sklearn.ensemble import IsolationForest
☑️ 요약
- 이상탐지
- 정상 패턴과 다른 데이터를 찾아내는 기법
- 이상치탐지와 유사, 맥락과 패턴 학습 측면에서 조금 더 넓은 범위
- One-Class SVM: 정상 데이터 기준 경계 형성
- Isolation Forest: 무작위 분할 → 이상 감지
- 산업 전반에서 활용 가능
☑️ Q&A
| 질문 | 요약 답변 |
|---|---|
| 라벨 없이 학습 가능? | ⭕ 비지도학습 기반 |
| Isolation Forest에서 contamination 값? | 이상치 비율 사전 추정 or 도메인 지식 활용 |
| 임계값(threshold) ? | 정상 데이터 분포 기준으로 결정 |
| 혼합 가능여부 | ⭕ 앙상블 (ex) One-class SVM + Isolation Forest |
실습
- Wine 데이터셋을 로드하세요.
- 변수(특성) 2개만 간단히 선택하세요. (예: 첫 번째와 두 번째 컬럼)
- One-Class SVM과 Isolation Forest를 각각 적용하여, 이상치(Outlier)를 찾아보세요.
- One-Class SVM의
nu파라미터를 적절히 설정하세요.- Isolation Forest의
contamination을 적절히 설정하세요.- 두 모델에서 도출된 이상치 샘플들을 그래프에서 빨간색으로 표시한 2차원 산점도를 시각화하세요.
-
데이터셋 로드
-
데이터프레임으로 만들기
-
EDA
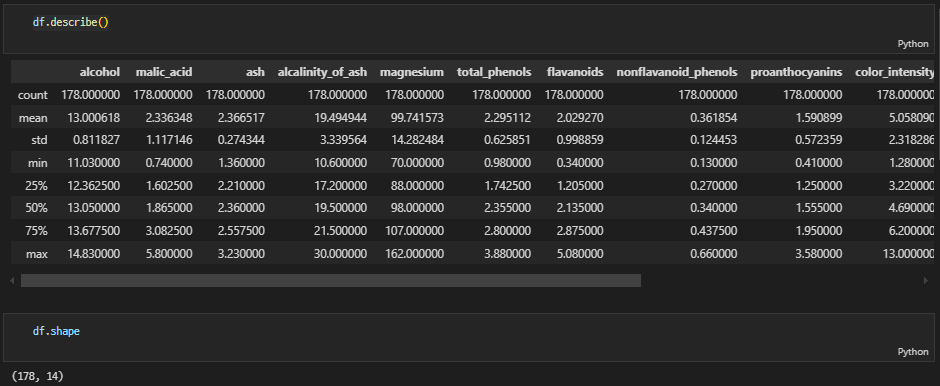
-
2개 특성

-
One-class SVM

-
Isolation Forest

-
인덱스 추출 / 샘플 개수, 이상치 인덱스
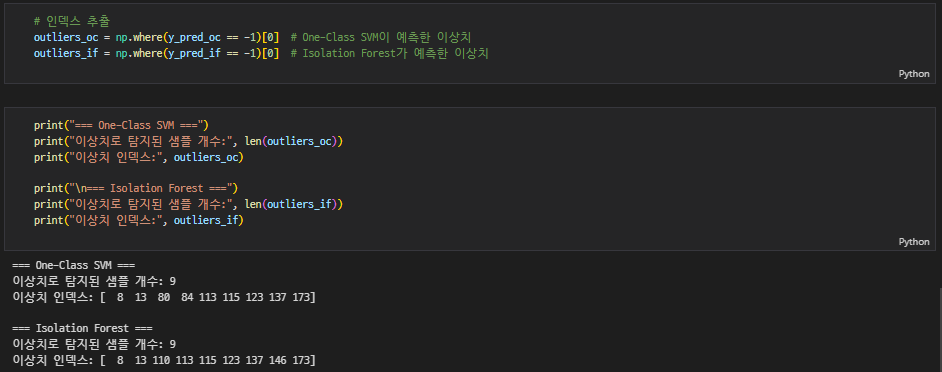
-
시각화
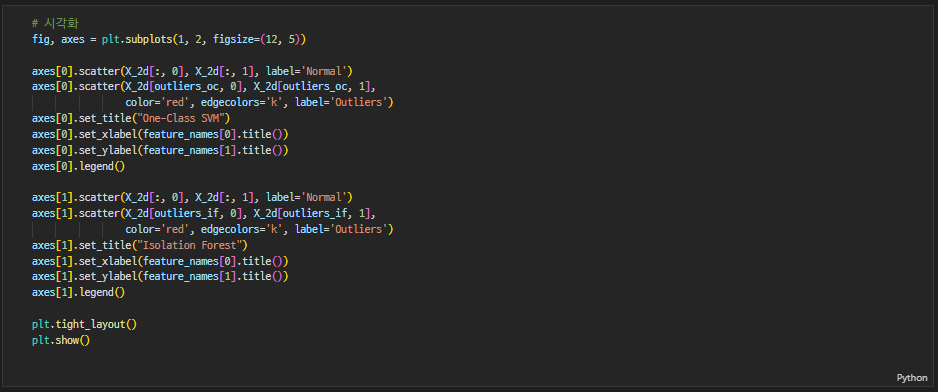
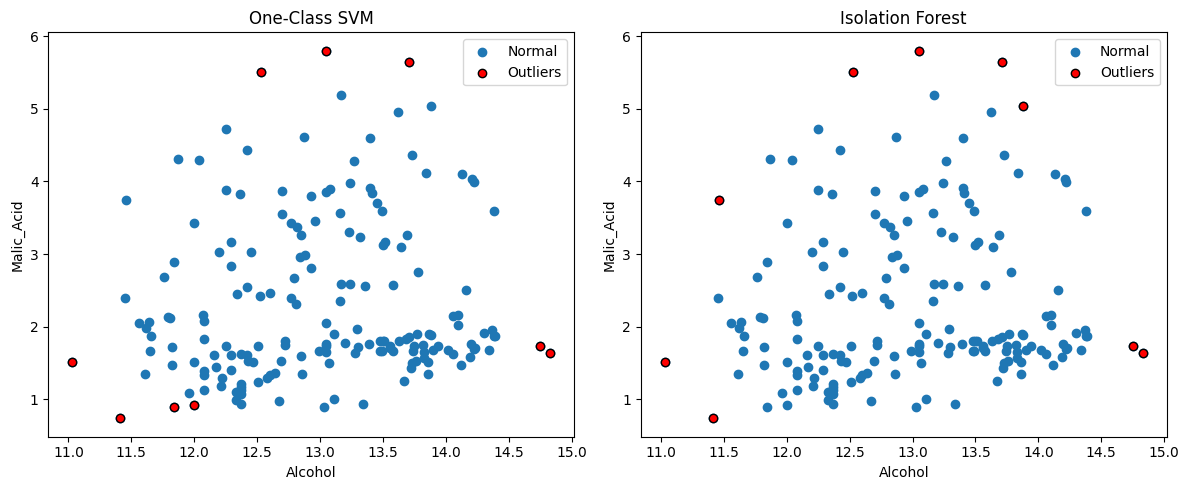
❓ 궁금한 점
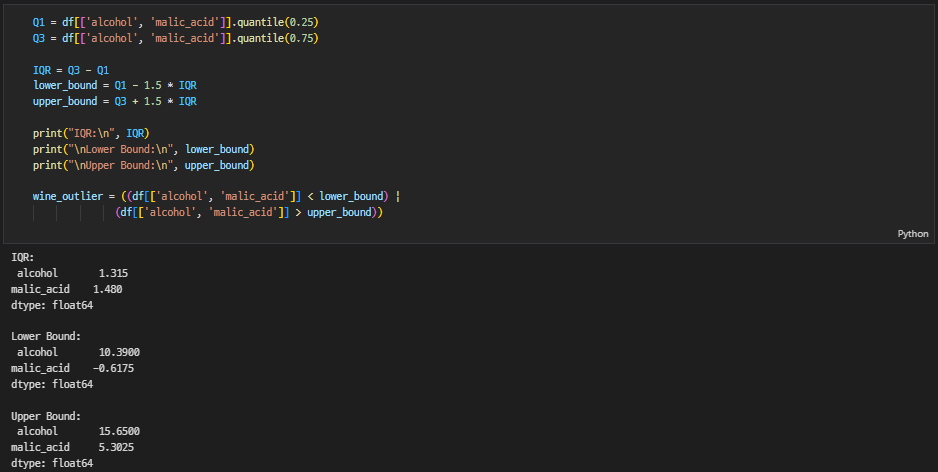
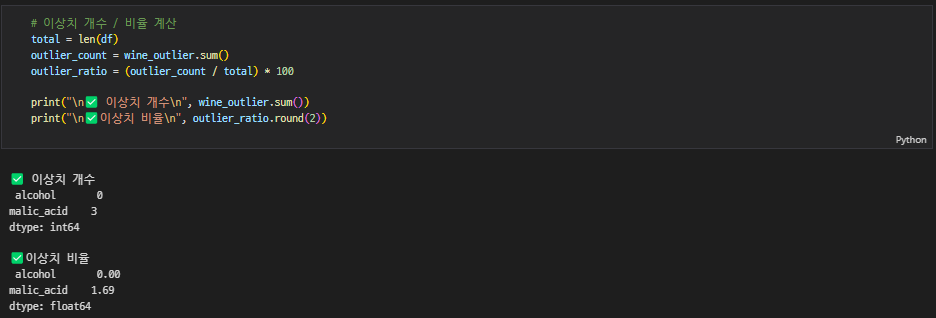
IQR 비율을 활용해서 nu값이랑 contamination 값을 조절해도 되는 걸까?
일기
- SQL
코드카타 85-86✅ - Python
코드카타 47-48✅ - 머신러닝
기초강의 7-10강✅
오늘은 왕짱뿌듯한 하루 머신러닝 강의 다 들었다💦💦
내일은 복습할 겸 머신러닝 특강 정리 한번 쫙 해야지😵💫
10강은 딥러닝이라서 따로 정리는 안했다! 가벼운 마음으로 들음
프로젝트 시작이라 그럴 시간이 있을진 잘 모르겠긴 한데. . 내일 현지튜터님한테 모르는 거 물어보러 바로 가야한당 파이팅하자자
💿오늘의 추천곡 Teddy Swims - lose control

