
팀스터디
늦었지만 이제서야 정리해보는 프로젝트 (그간 너무 힘들었음)
심화프로젝트
전처리 - 1차
import + 데이터 로드

xlsx는 with open으로 / json은 normalize를 해야한다는 걸 알게 됨
사실 이때부터 쉽지 않았는데 지금 보니 너무 .. 먼지잔아
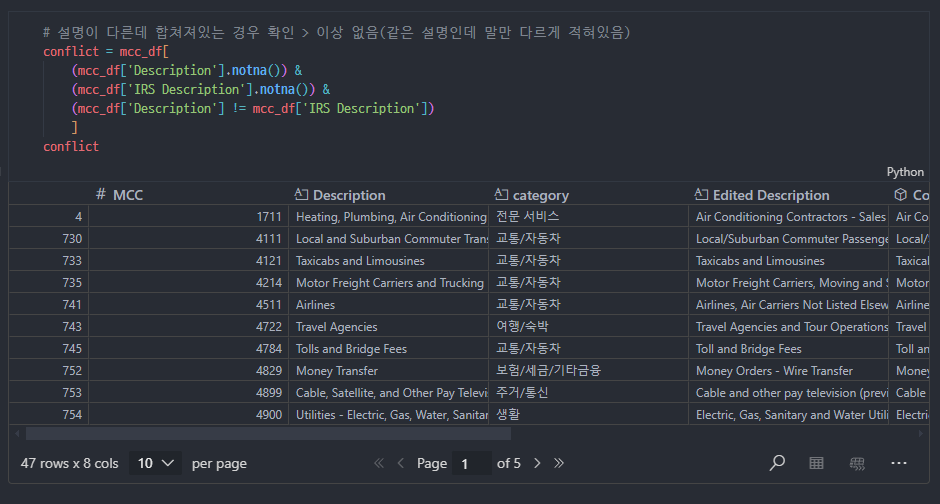
mcc clean
-
결측치 확인

IRS description 결측치 양이 적었기 때문에 IRS Description을 기준으로 삼아야겠다 생각했고, 부족한 설명은 json Description에서 당겨오기로 함 -
카테고리 분류
-
range로 분류
소비패턴에서의 차이는 아무래도 소비하는 업종 선호도에서 온다고 생각했기 때문에, 카테고리를 만들어주기로 했음 원래는 🔗mcc code range 보고 range로 분류를 해주려고 했는데..튜터님이 "저기 나와있는 범위랑 여기서 쓰는 mcc code가 다르다면요?" 라고 하셔서 방향을 틀었다 -
매핑
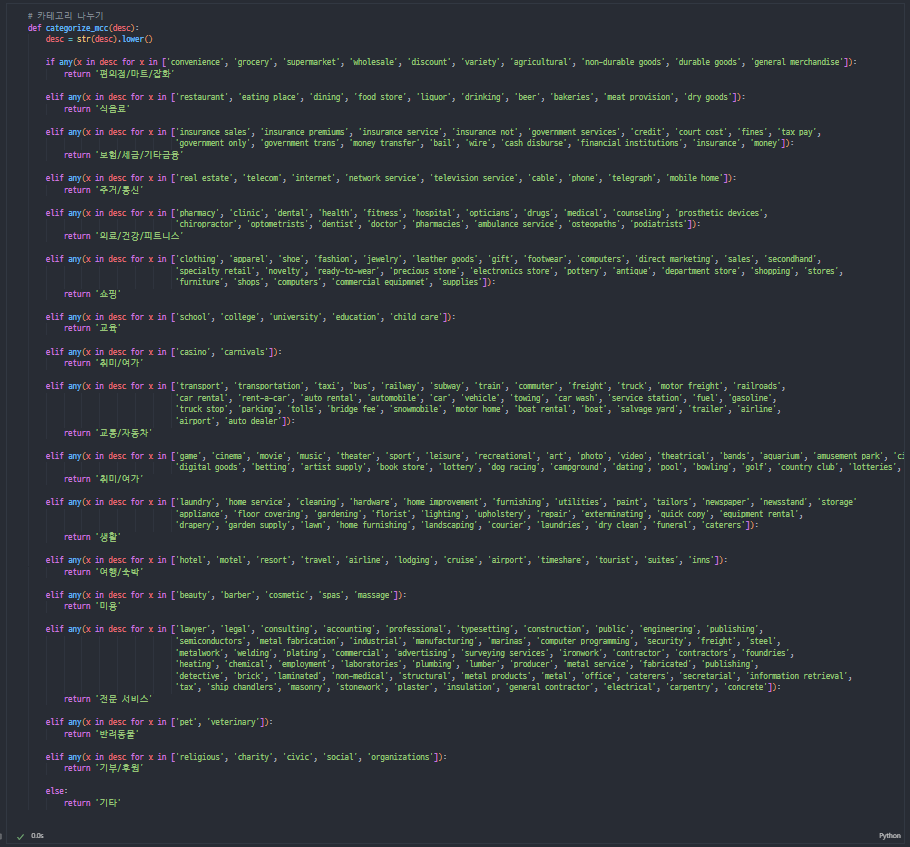
이런식으로 기타로 나오는 게 없을때까지 분류를 추가해줬다
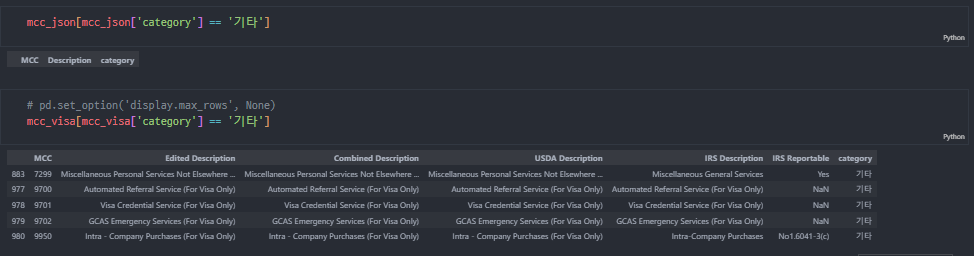
-
적용

-
json + visa


-
확인

-
필요없는 컬럼들 버려주고 중복 제거

-
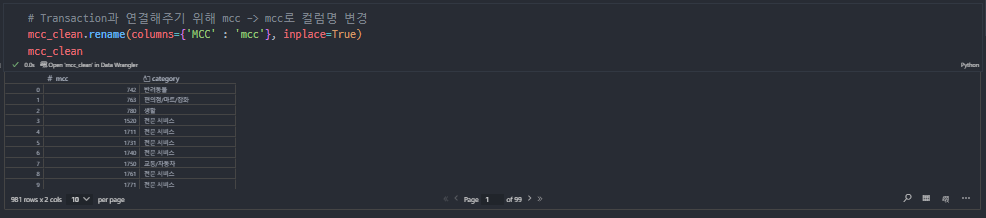
컬럼명 통일
-
trans + mcc clean
-
merge

-
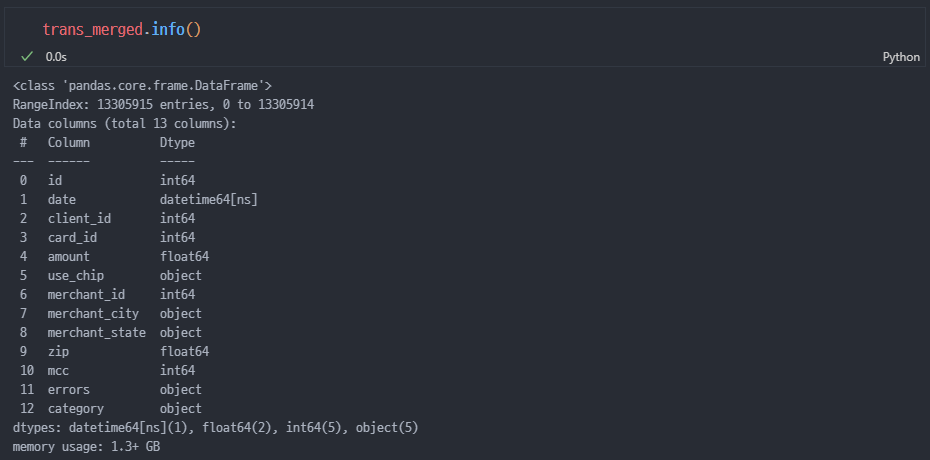
info 따기
-
datetime 형변환

-
$ 표시 떼기

-
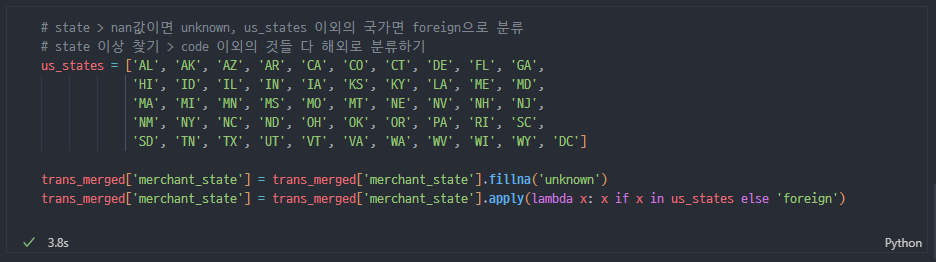
merchant_state 처리
-
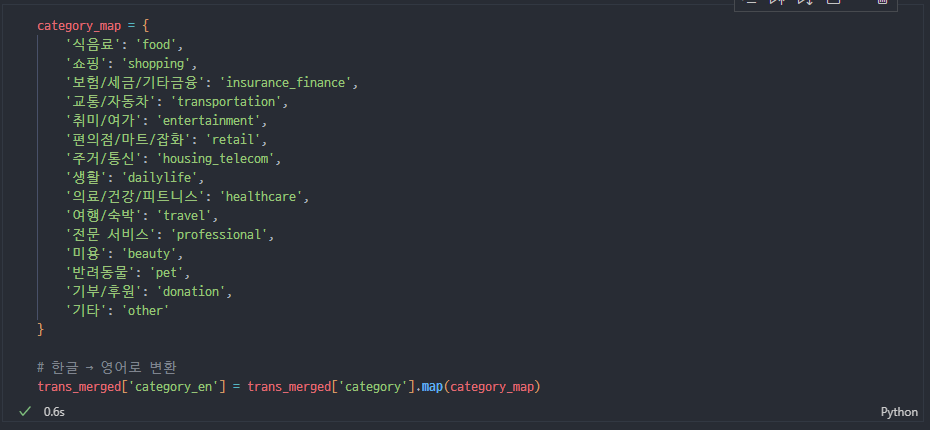
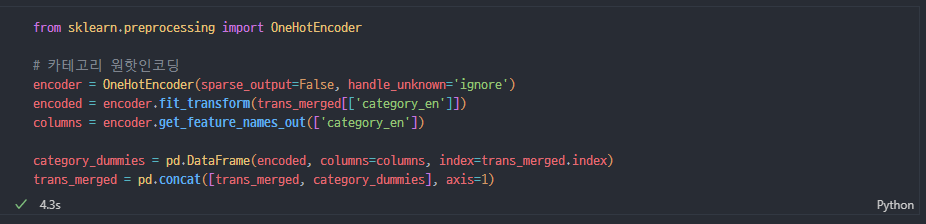
category 인코딩
- 한글 > 영어 매핑
사실 원래 그냥 영어로 매핑했으면 됐는데, 보기가 너무 힘들어서 한글로 매핑하고 추가로 매핑해줬다
- 원핫인코딩
- 한글 > 영어 매핑
-
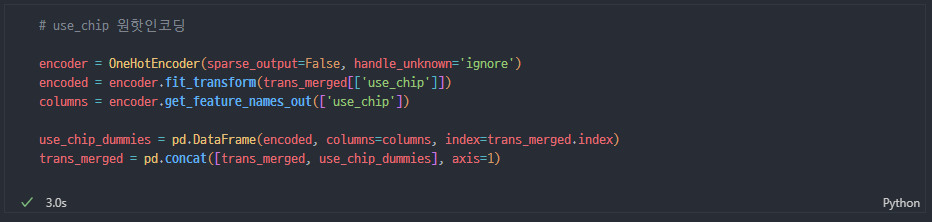
use_chip 인코딩
- unique 따기

swipe, chip 은 큰 의미 없고 온라인이 중요하다 생각함 - 원핫인코딩
- unique 따기
-
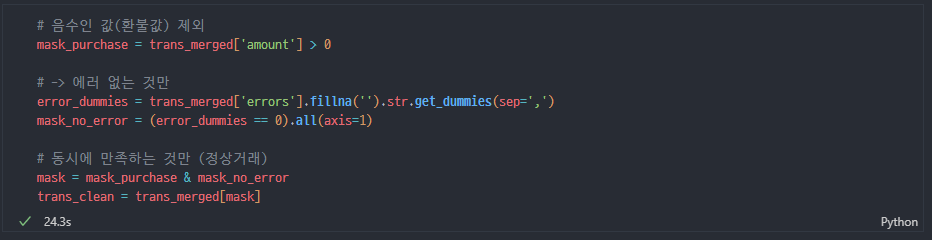
정상거래 필터링
- 음수인 값(환불값)
이게 환불이 맞는지에 대해서는 의문이 들었었는데 형진님이 확인해주셨다!
우리 조는 소비 패턴만 알면 되기 때문에, 환불값은 제하고 보기로 함 - 에러 없는 것만
에러도 뭔가 인코딩을 할까 말까 고민했는데, 목표가 그게 아니기 때문에 오류가 없는 값만 정상거래로 간주
- 음수인 값(환불값)
-
최종확인
card clean
-
$ 표시 떼기

-
날짜 변환
mm/yyyy > yyyy/mm/dd

-
레이블인코딩
지금 생각하면 이거 굳이 할 필요가 없긴 한데.. 순차적으로 드랍하면서 가는 방식이 나았을 것 같다

-
인코딩
- card_type

- card_brand
이것도 지금 생각하면 굳이.. 네 ^^

- card_type
-
한도 0인 신용카드 필터링

user clean
-
$ 표시 떼기

-
gender 인코딩

-
나이 계산 확인
current_age 가 있어서 제대로 계산된 게 맞는지 확인했다
-
은퇴 나이 이상치 확인
-
필터링 후 drop

mcc + transaction + card + user
-
merge

-
중복 컬럼 제거

-
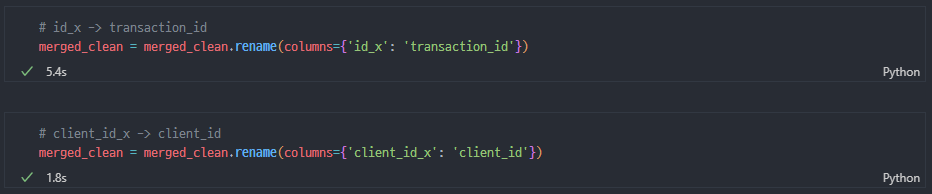
컬럼명 변경
-
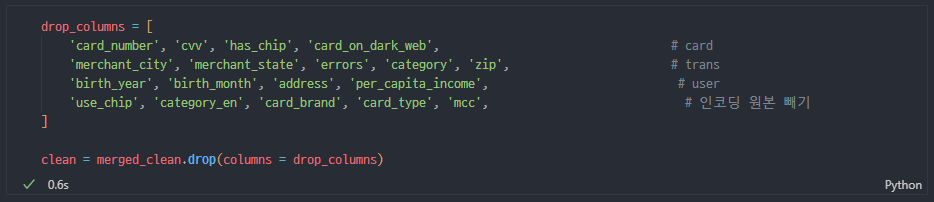
최종 drop
-
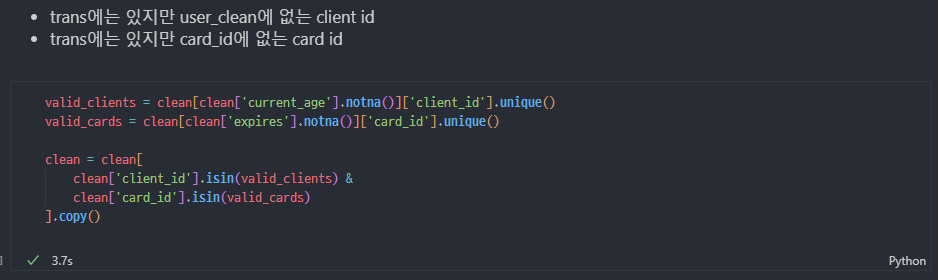
결측치 정리
전처리 - 2차
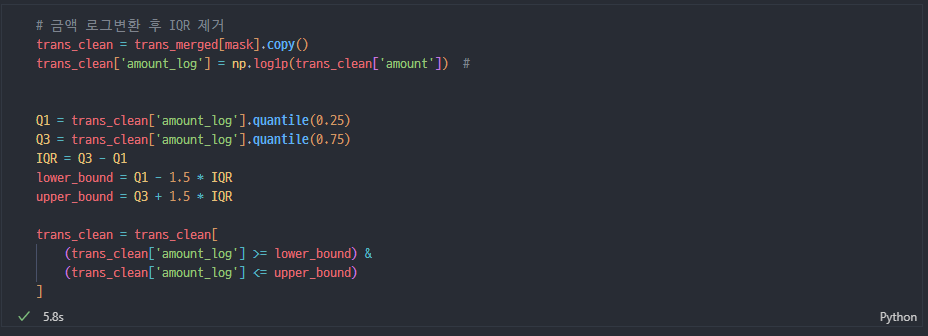
log변환 + IQR 제거O + zip코드
사실 원래는 eda+전처리랑 모델링 코드가 너무 엉켜있어서 정리하다가, 튀는 데이터들이 있는 것 같아서 로그변환 + IQR도 적용해봤음
변경사항
-
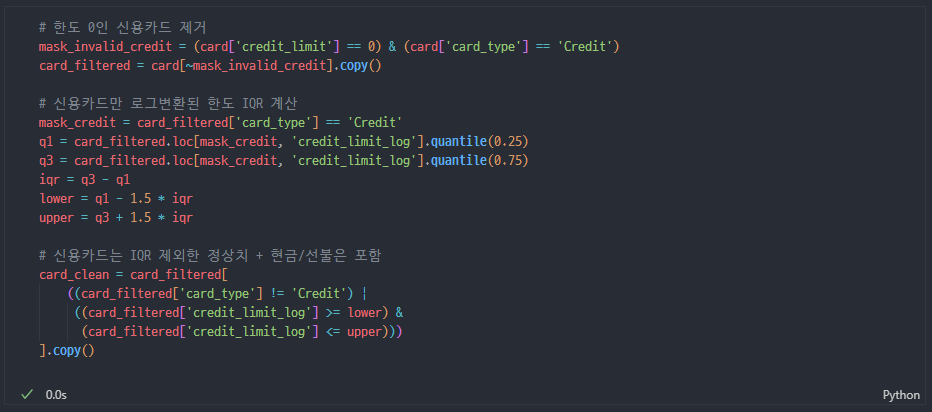
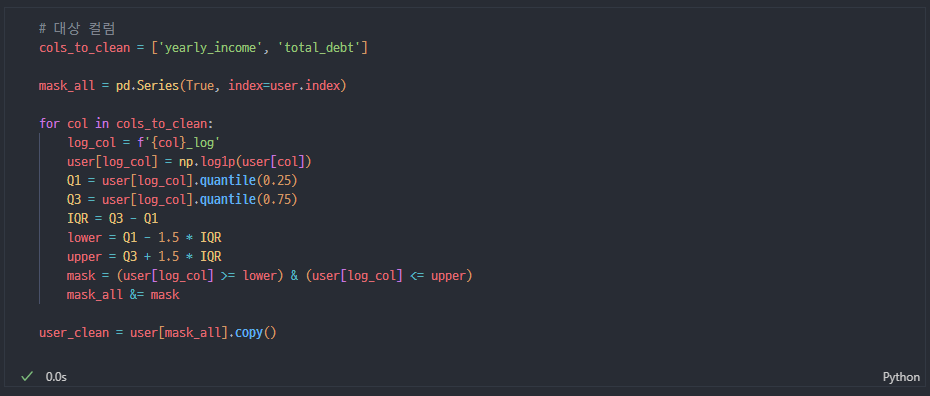
로그변환 + IQR 이상치 제거
- amount
- credit_limit 신용카드만(현금, 선불 그대로 0)
- total_debt
- yearly_income
-
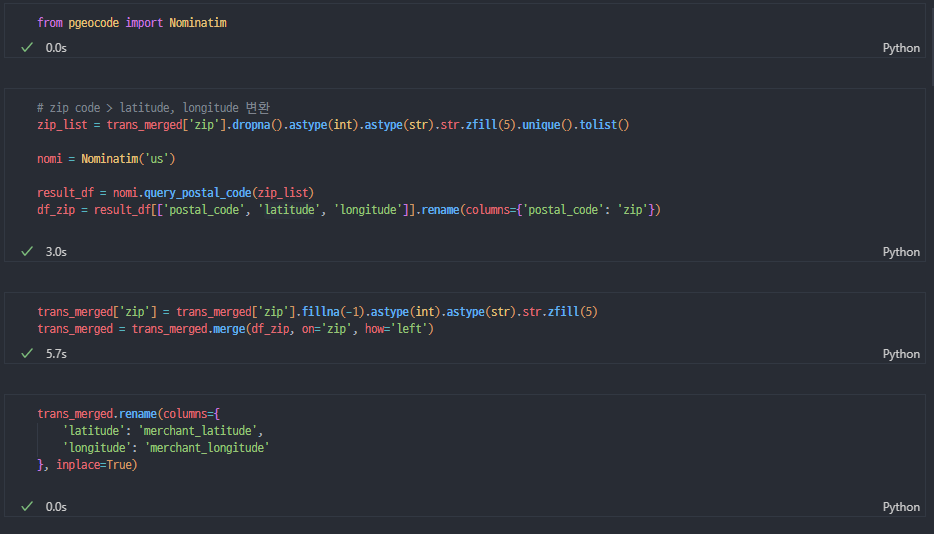
zip코드 변환
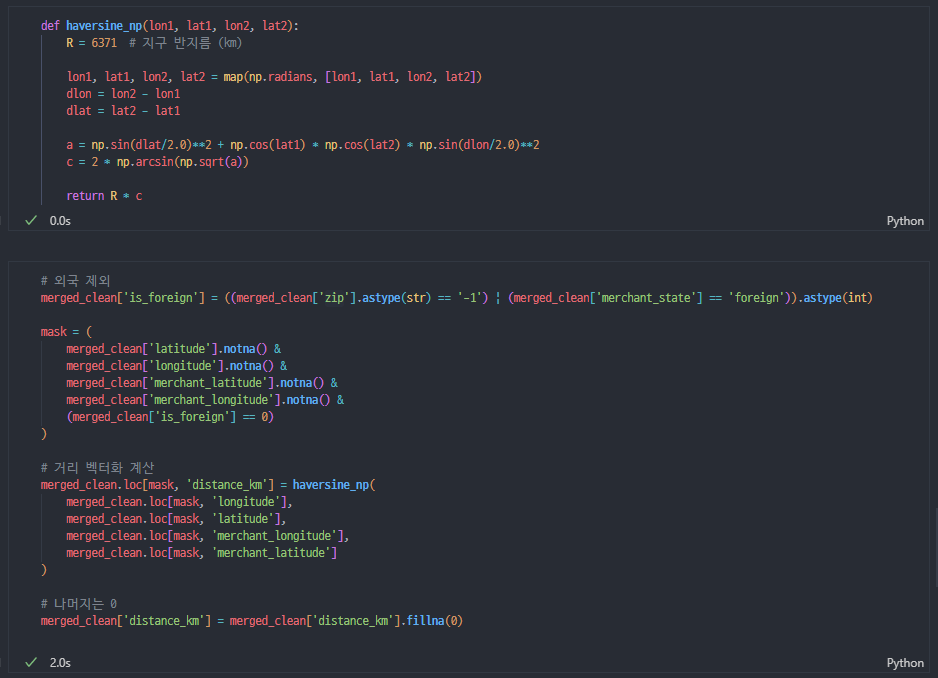
- 위도, 경도 기반 고객 - 상점 거리 계산(하버사인) + is_foreign 생성
머신러닝 - 1차
(fit_original ver.)
import + 데이터 로드

원본 데이터를 손상시키지 않기 위해 copy
인코딩 관련 파생변수
-
카테고리
-
카드타입
-
칩
집계함수 관련 파생변수
-
거래 관련
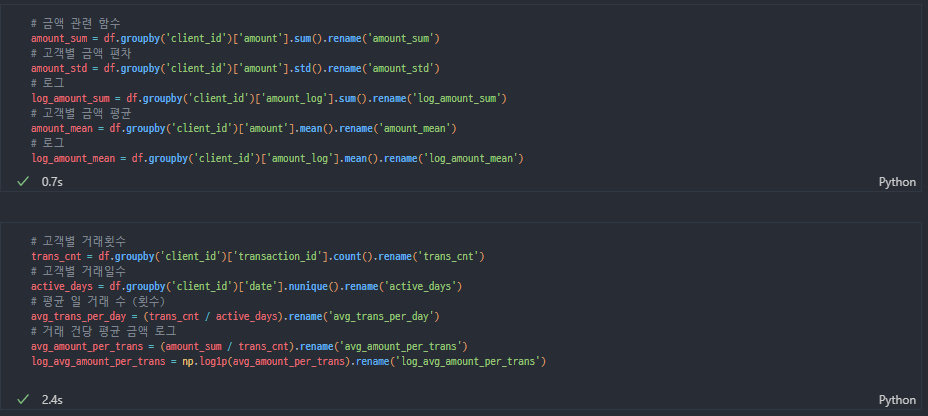
-
고객 재무건전성 / 정보 관련
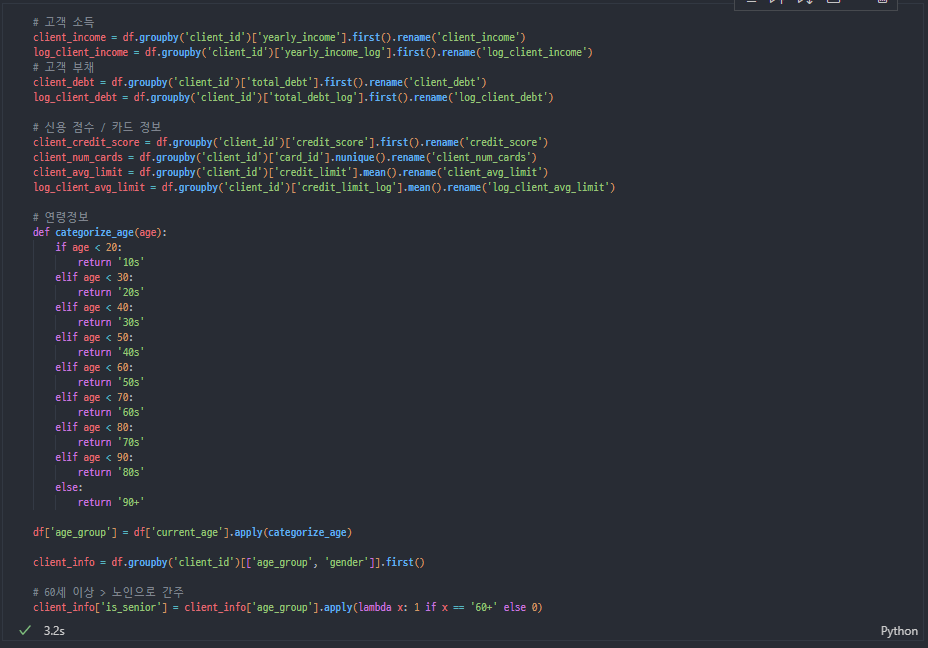
-
시간 관련
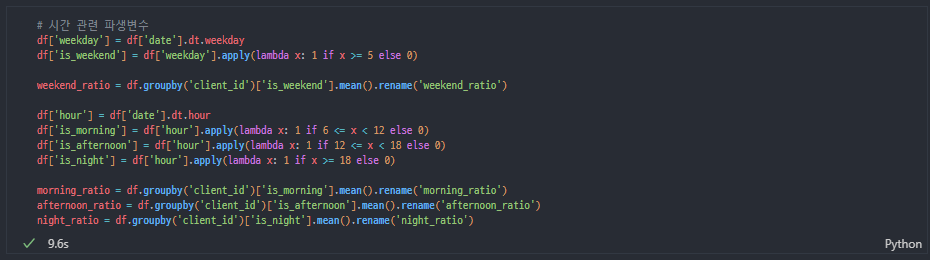
-
거리 관련
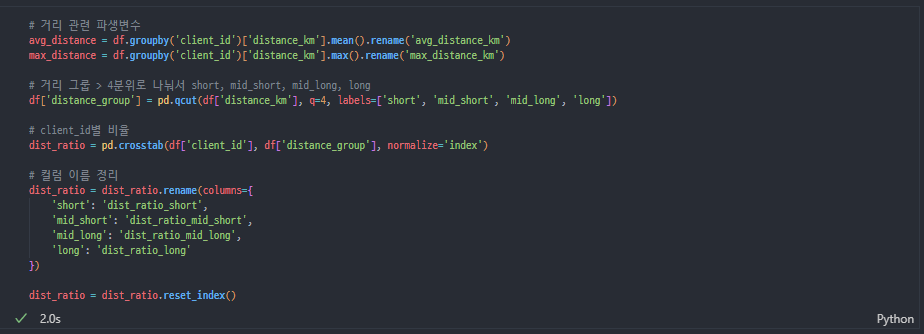
-
소비패턴 관련
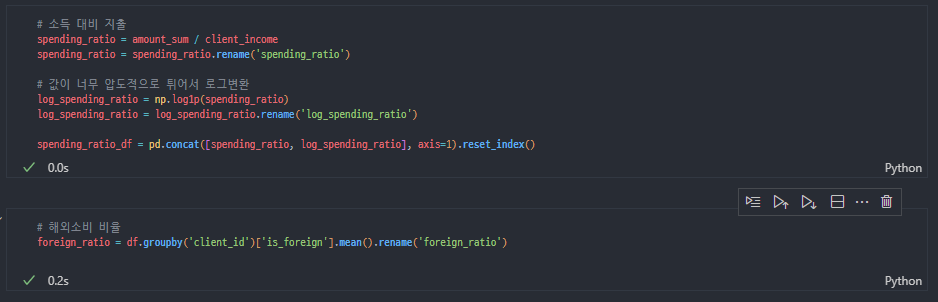
base_df 생성
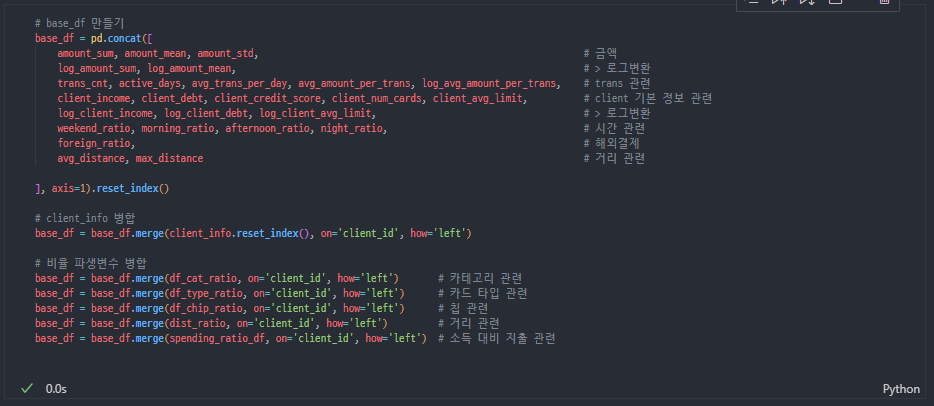
피처 선택 지표
-
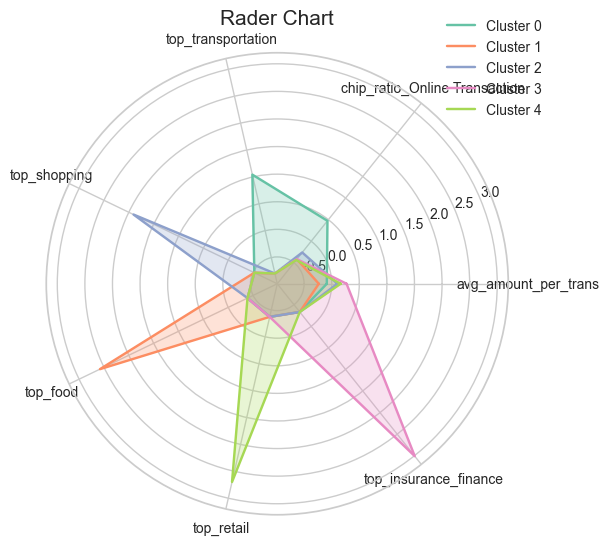
카테고리
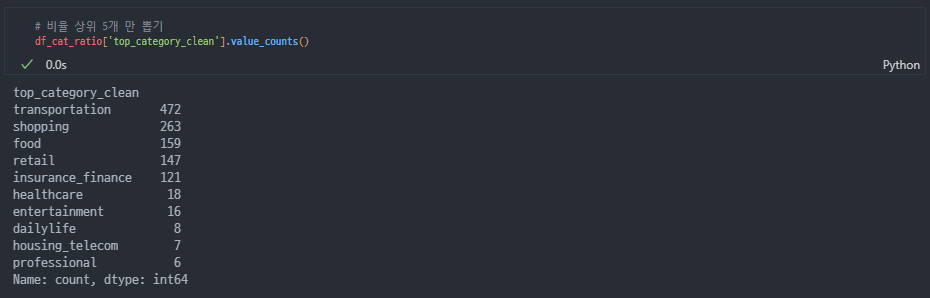
앞서 말했듯 소비패턴에서의 차이는 소비하는 업종 선호도에서 온다고 생각해서 카테고리는 꼭 필요했다
다 넣고 돌리는 건 비효율적이라 생각해서 TOP5만 뽑았다 -
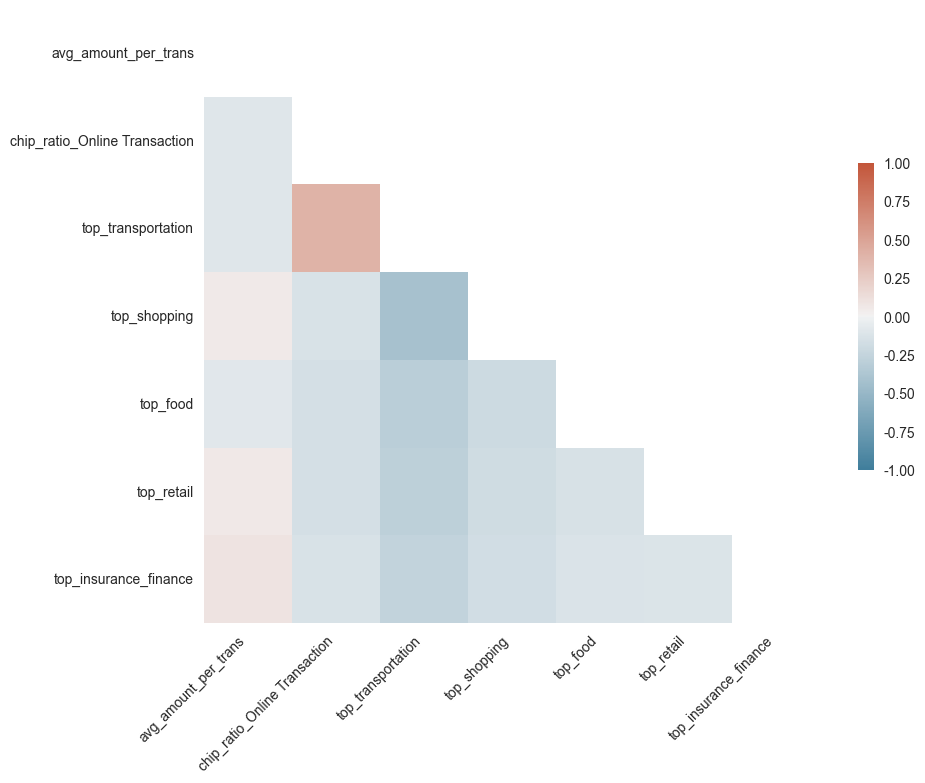
상관계수 > 다중공선성 제거
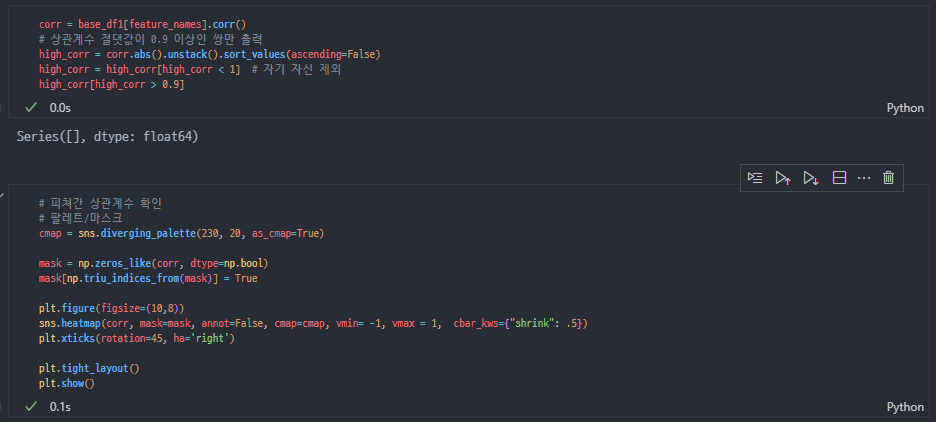
-
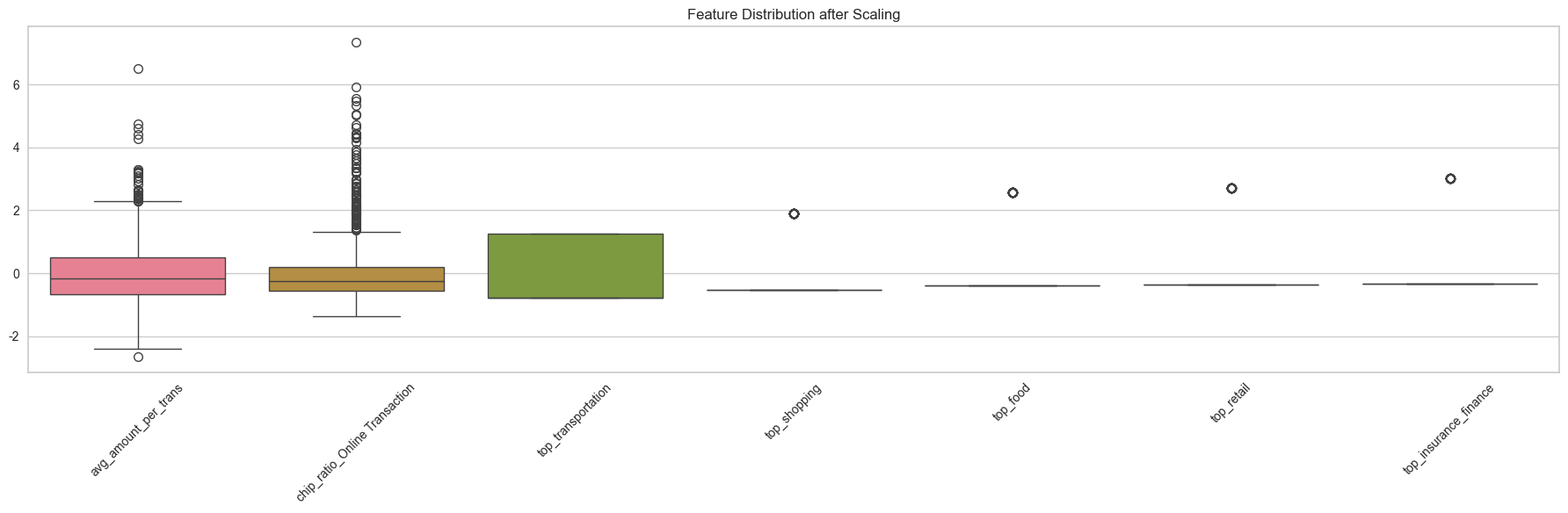
분산확인 > 왜곡 줄 수 있는 변수는 제거
최종피처 / 파라미터 결정
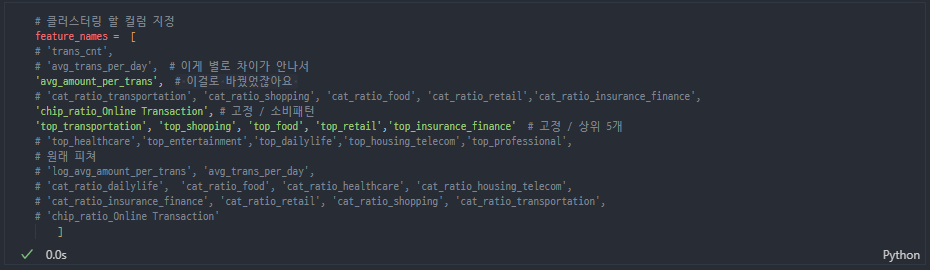
최종적으로 중요하다고 생각했던 [소비규모, 소비패턴(온라인), 카테고리]를 모두 반영해 최종 피처를 골랐다!
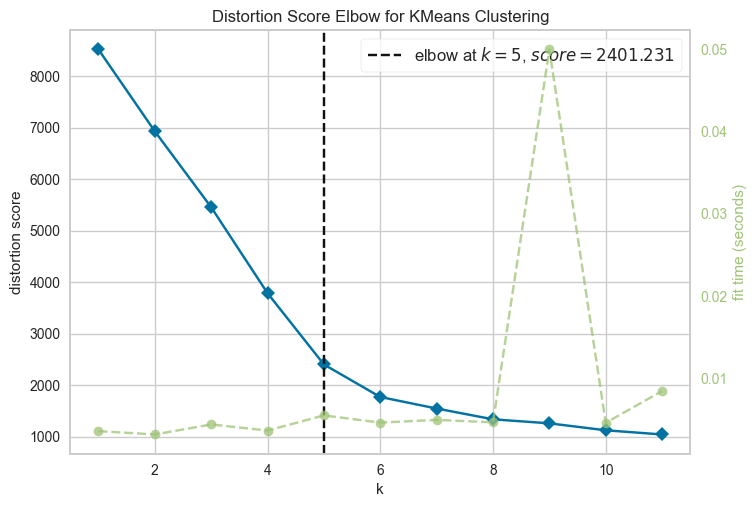
K=5
PCA + K-Means
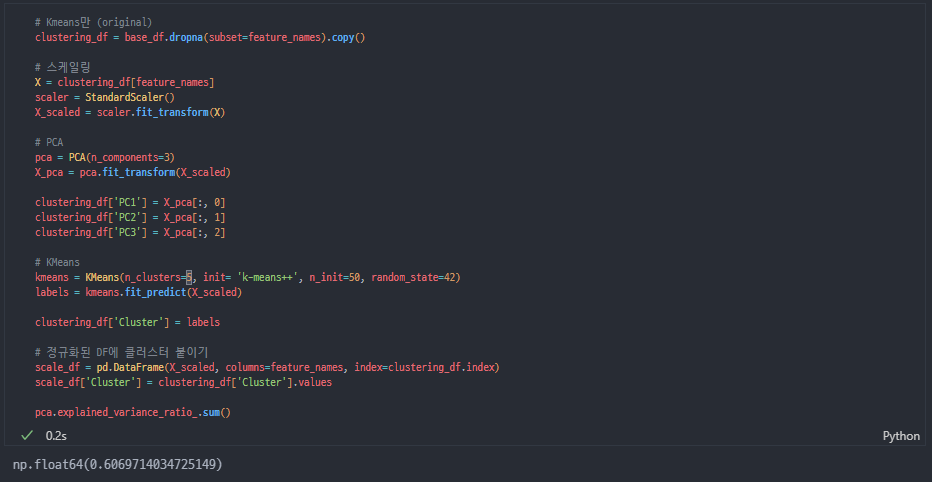
결과
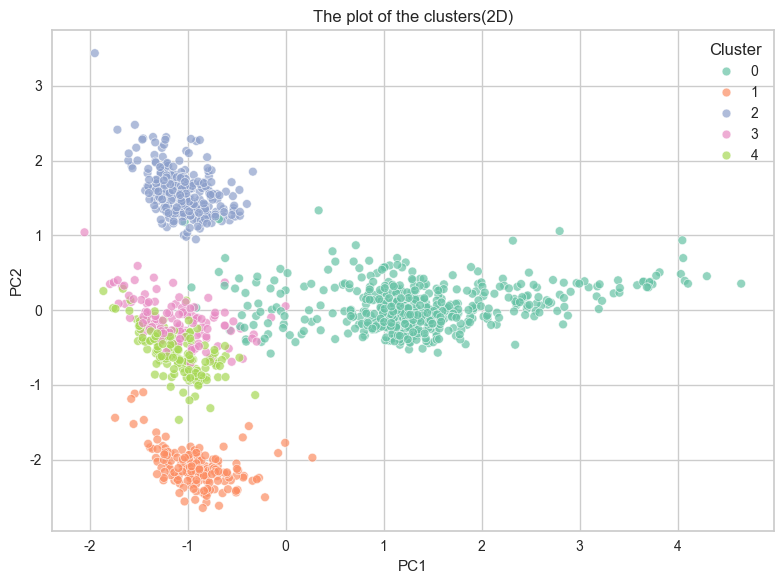
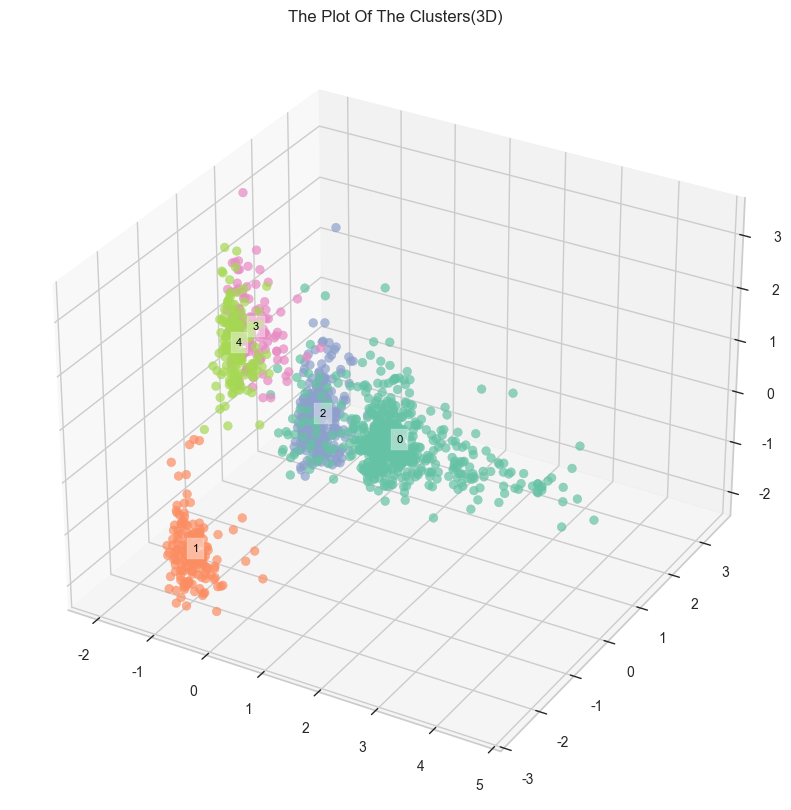
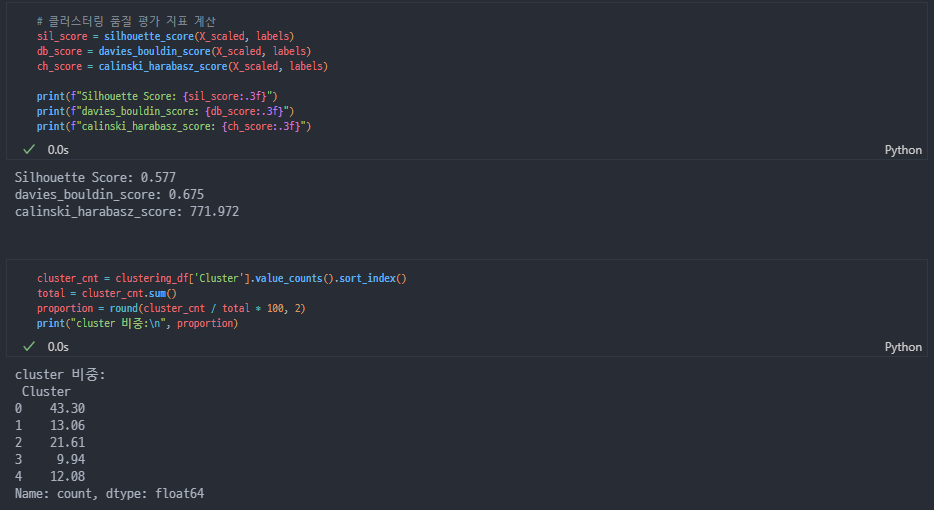
점수도 나쁘지 않았지만 아직 끝이 아니고요.. 다시 태초마을로 돌아감
전처리 - 3차
IQR 제거X
참 할 말이 많은데.. 일단 기존 코드가 나는 차원축소를 한 데이터로 학습을 시키는 건줄 알았다
그런데 사실은 스케일링 된 원본 데이터를 학습 시키는 거였고, 결론적으로는 로그 변환도, IQR 제거도 하지 않은 게 가장 품질이 좋았다
당시에는 자연스러운 분포를 그대로 두는 게 군집화에는 유리하다 정도로만 받아들였는데, 지피티한테 자세하게 물어봤다
✅ 각 처리 방식 비교
-
IQR
- 군집 내 중요한 분포 정보까지 제거
- 군집 간 경계가 흐려질 수 있음
- PCA만 할 경우 원래 분산 구조를 보존하면서 이를 요약 > 군집간 특성이 뚜렷하게 드러나는 효과
-
로그변환
- 편향된 분포를 잡는데는 좋음
- 다만 클러스터링에서는 절대 크기나 분산 자체가 군집 구분의 중요한 기준이 되기도 함
-
PCA
- 분산이 큰 방향 = 정보가 많은 방향이라 가정하고 주성분을 뽑아냄
- 원본 데이터를 유지할 경우 분산이 살아있고, 이상치도 특이한 방향성을 만드는 데 기여
→ 결론적으로 극단값까지 포함한 분산 구조와 전체 패턴이 중요했던 것
머신러닝
2차 (fit_pca ver.)
scale된 데이터가 아닌 pca된 데이터로 학습시키기 위한 코드로 바꾸는 김에, 아예 파이프라인처럼 함수로 묶어보는 게 좋겠다 싶어서 만들어봤다
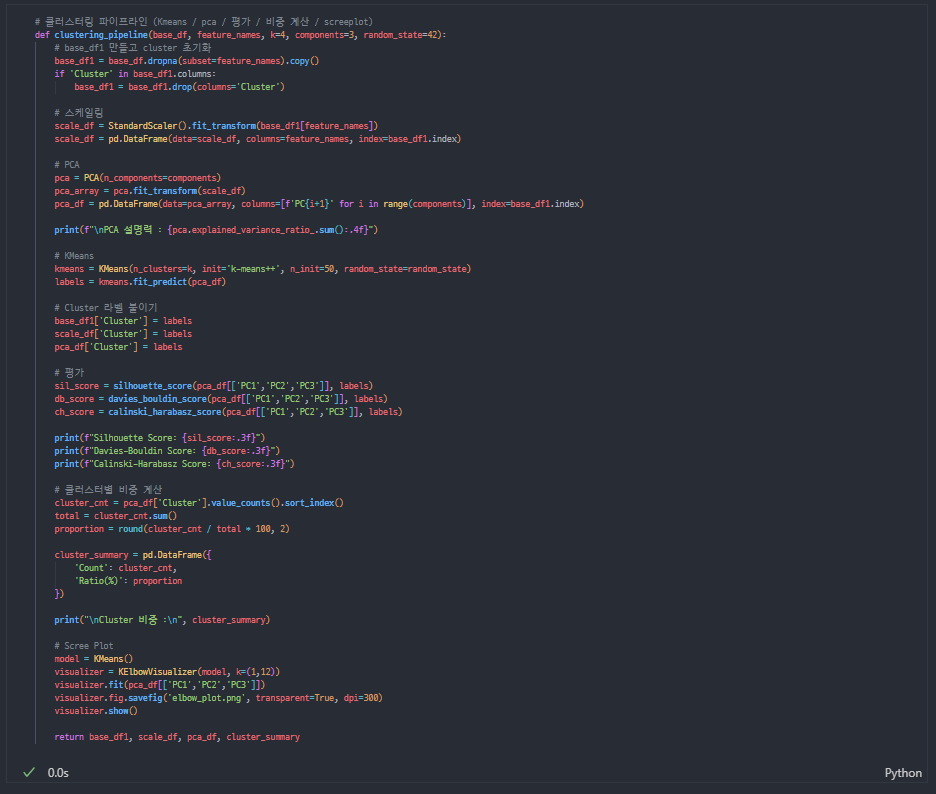
결과
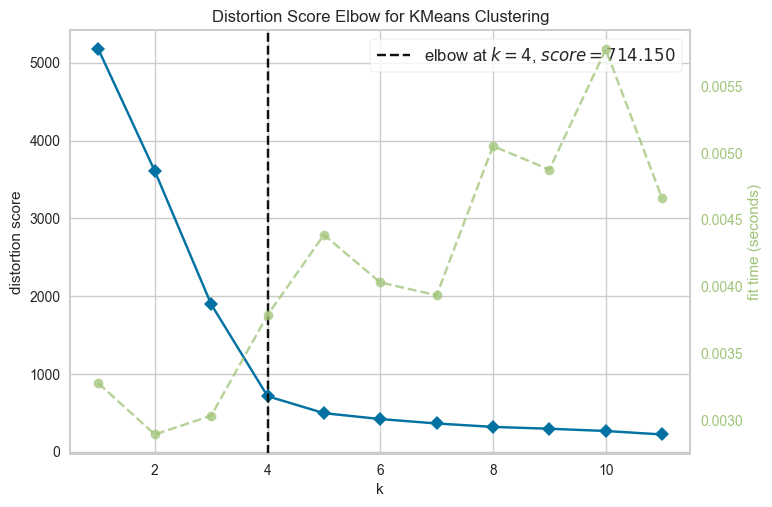
여기서는 K=4
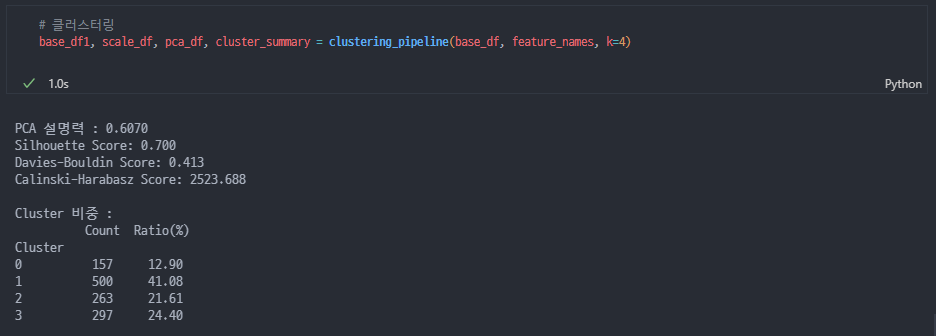
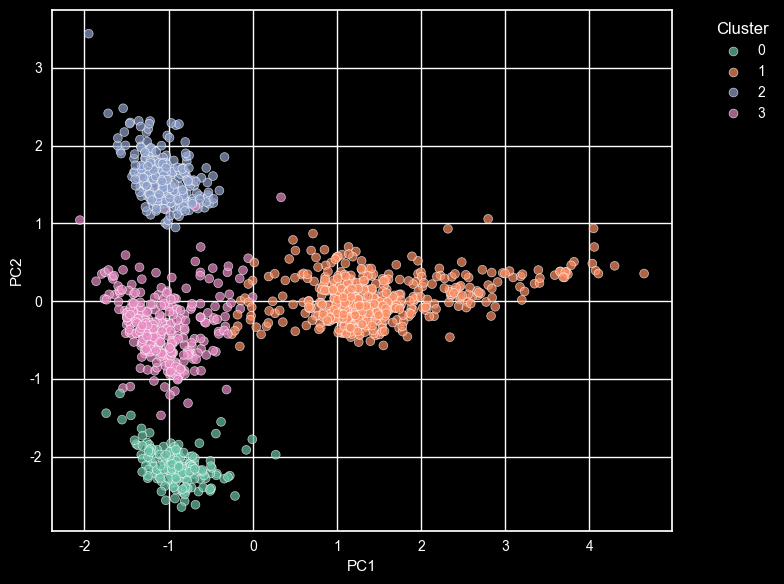
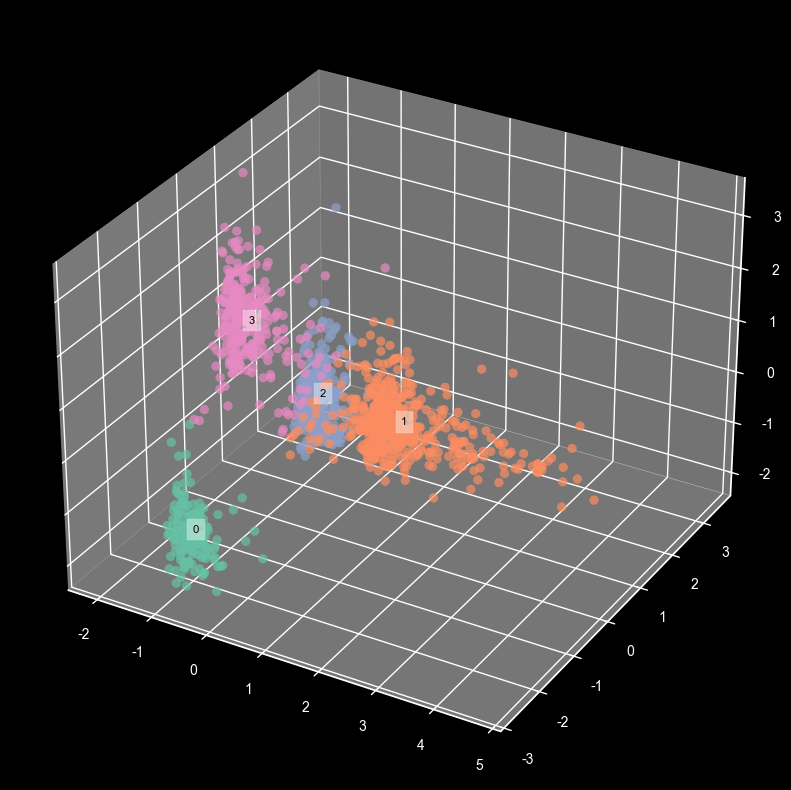
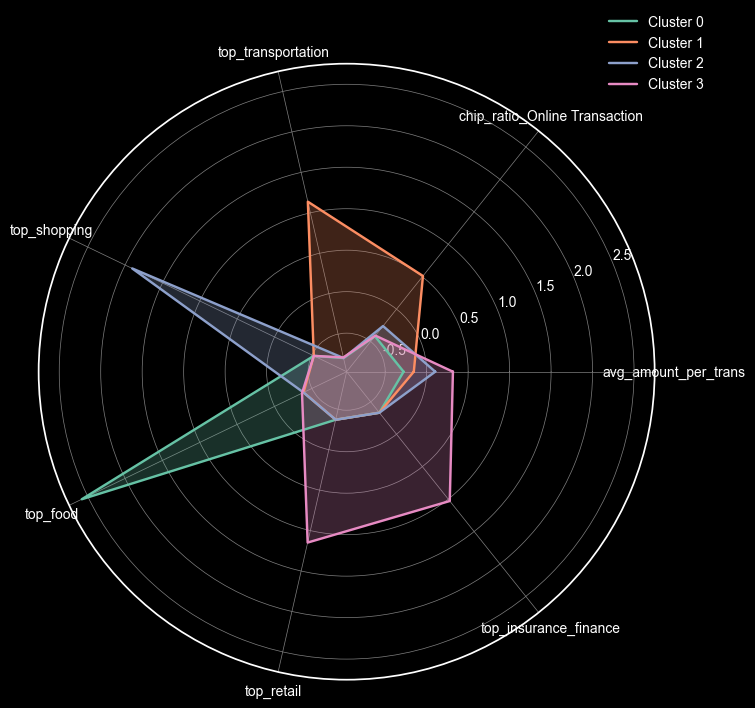
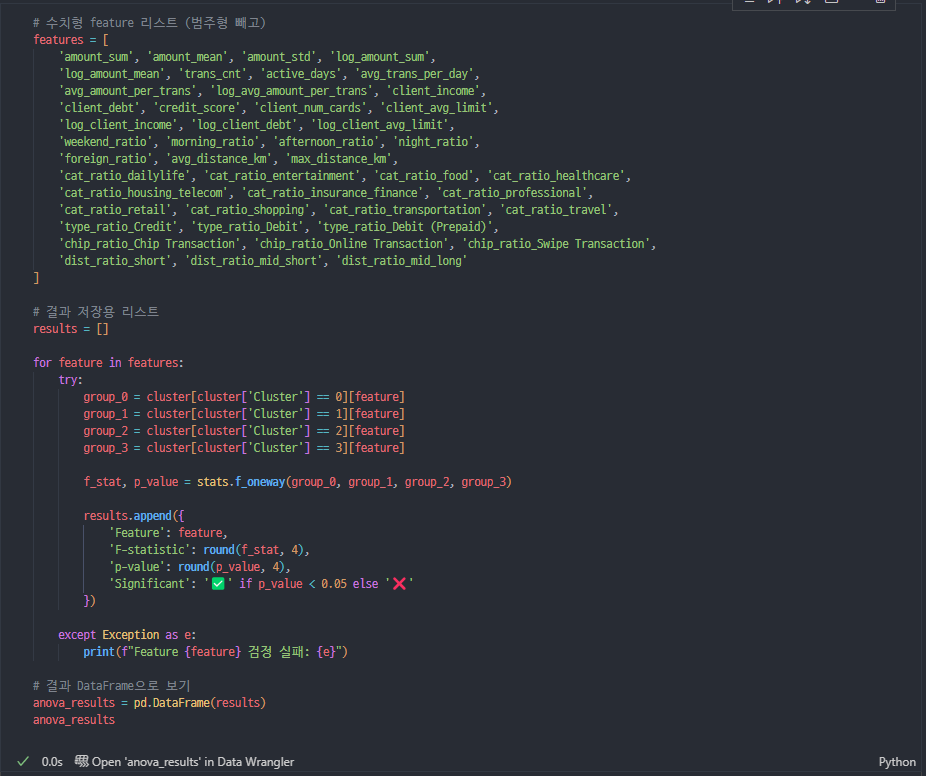
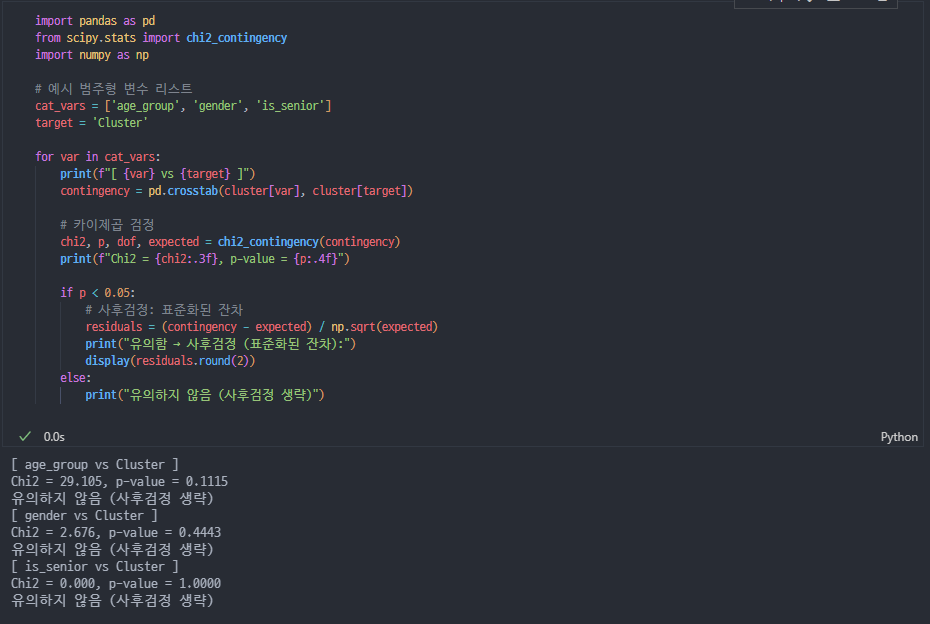
사후검정
-
수치형
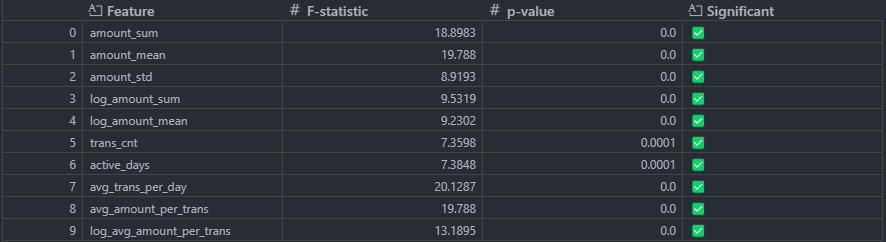
-
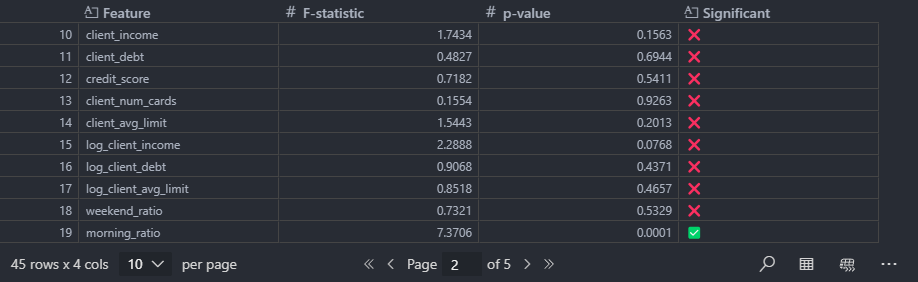
범주형
상세분석
기본 전처리

대부분 시각화 자료라 PPT로 대체..
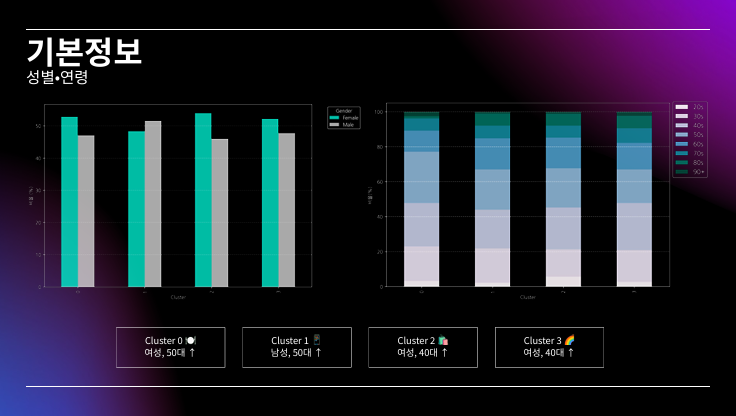
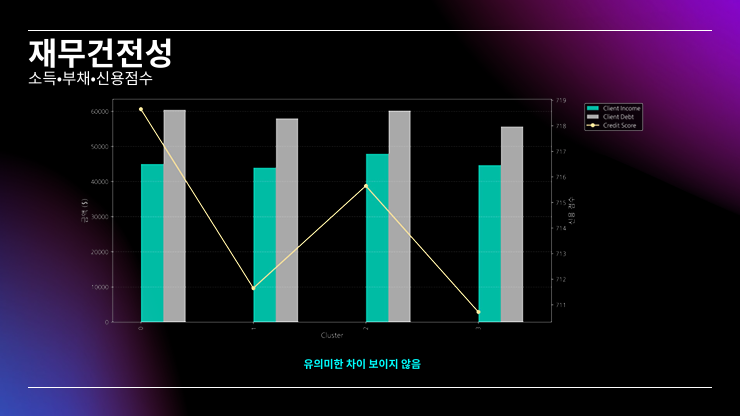
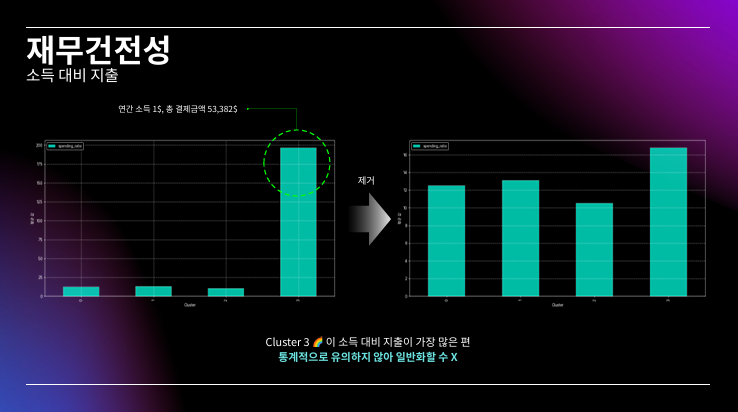
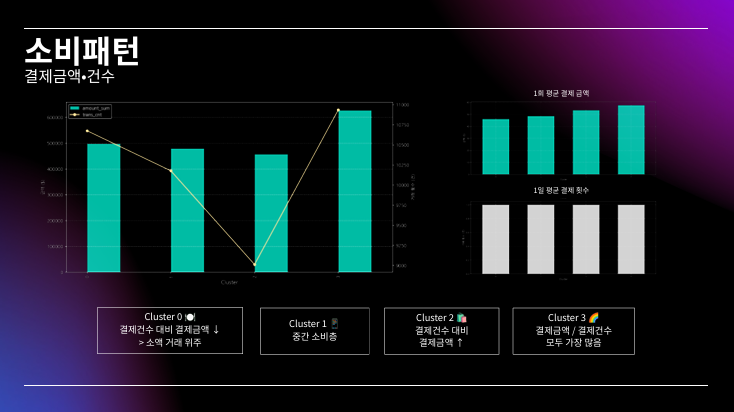
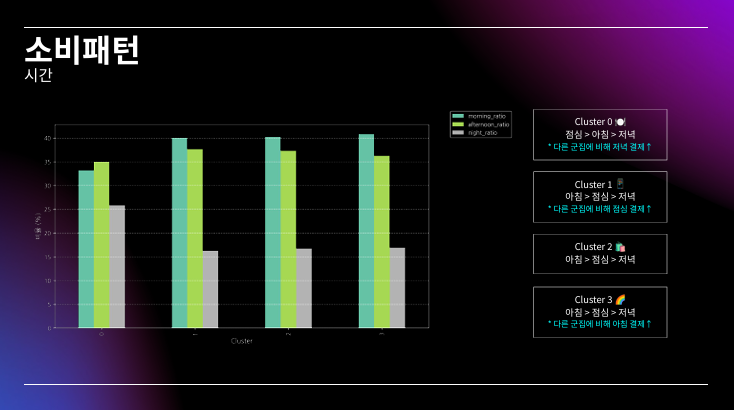
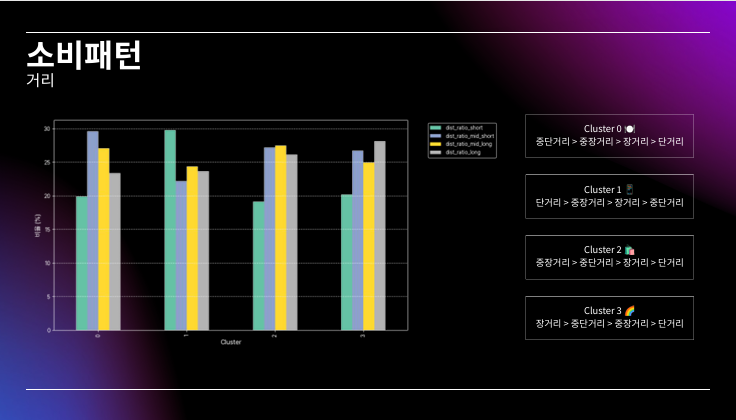
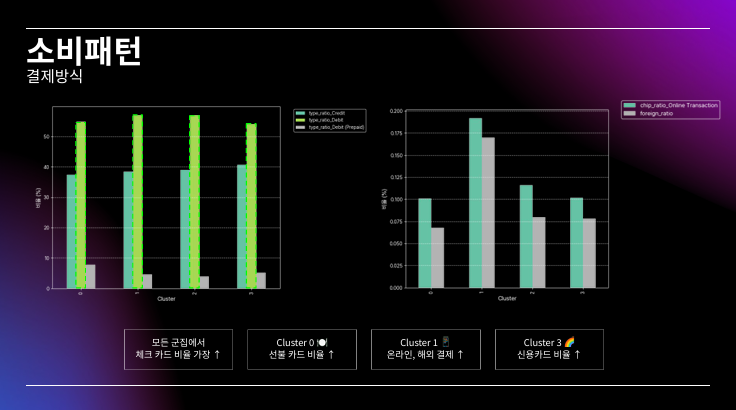
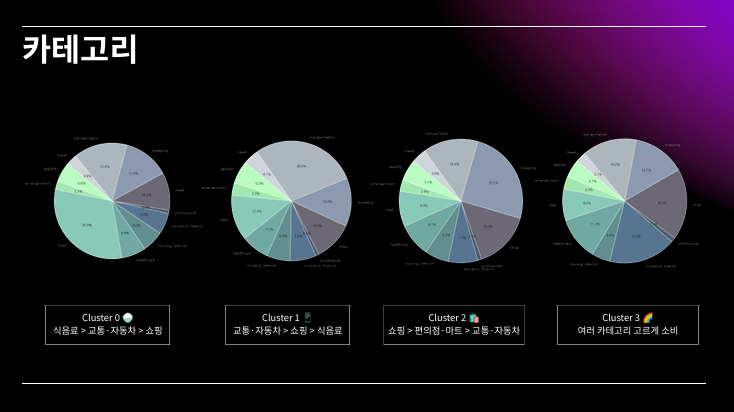
PPT
(희린님과 나의 피땀눈물... 감사합니다...)

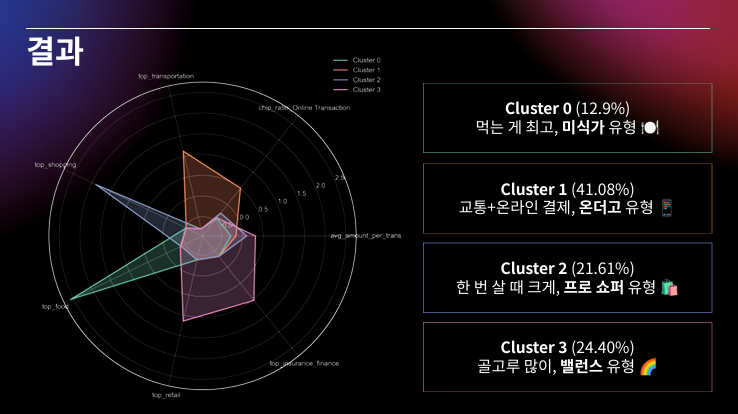
피드백
-
발표 잘했고, 전달력 좋다
시간이 딱 10분이라 그런지 속도가 좀 빨라서 아쉬웠지만 이해함 -
PPT 템플릿 좋았음 (고마워요 희린님)
-
단순 '최종 모델 선정했다', '평가 지표가 이렇다'로 끝나지 않고 상세 분석 + 군집별 서비스 추천까지 이어져서 좋았다
-
근거를 시각화를 통해 보여준 점이 좋다
-
질의응답
-
Q1) 예시로 든 카드는 실제 있는건가요?
실제로 존재하는 건 아니고, 자료조사를 통해 예시로 든 카드에서 적절한 혜택을 뽑아 만든 것 -
Q2) 이상치 제거를 어떻게 했는지? IQR이나 z-score 사용했는지? 안 했으면 이유가 뭔지?
IQR로 제거를 했었다가, 제거하지 않은 모델이 군집을 나누기엔 더 적합한 것 같아 그렇게 택했다
(지금 생각하면 스케일링 + 차원축소 얘기를 이때 같이했다면 좋았을 것 같다) -
Q3) 데이비스, 실루엣 계수 이외에 CH점수를 넣은 이유가 뭔가요?
사실 튜터님이 추천해주신 건데 여러 모델을 놓고 봤을때 CH점수 사용 시 비교하기가 용이한 것 같아 추가로 택했다
-
아름다운 나의 전조원들과 현조원들(이제는 구..가 되어버린)

팀장님 ....... 언제나 행복하기...