개인스터디
QCC 5회차
문제 1 ) 분류되지 않은 상담 비율 계산 🟢
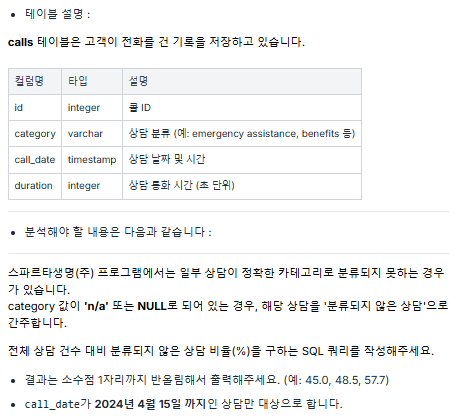
풀이
SELECT ROUND((SUM(CASE
WHEN category IS NULL OR category = 'n/a' THEN 1 ELSE 0
END ) / COUNT(*)) * 100 ,1)
FROM calls
WHERE call_date < '2024-04-16'1️⃣ 해설
SELECT ROUND(
(SUM(IF(category = 'n/a' OR category IS NULL, 1, 0)) / COUNT(*)) * 100, 1
)
FROM calls
WHERE call_date <= '2024-04-15'문제 2 ) 나이 구간별 전환율 계산 🟢
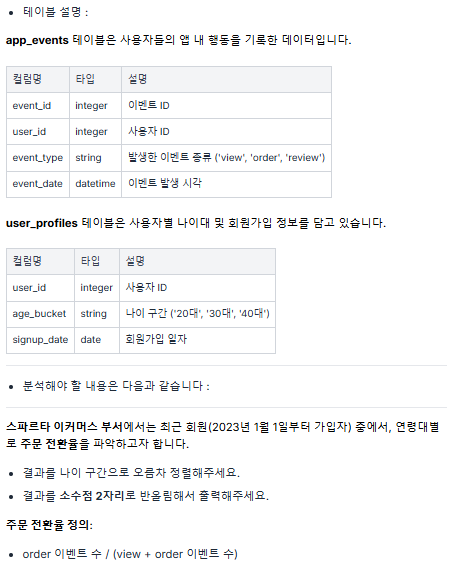
풀이
SELECT u.age_bucket,
ROUND(SUM(CASE WHEN a.event_type = 'order' THEN 1 ELSE 0 END) /
SUM(CASE WHEN a.event_type IN ('view', 'order') THEN 1 ELSE 0 END)*100, 2) AS conversion_rate
FROM app_events a
INNER JOIN user_profiles u
ON a.user_id = u.user_id
WHERE u.signup_date > '2022-12-31'
GROUP BY u.age_bucket
ORDER BY u.age_bucket2️⃣ 해설
SELECT
up.age_bucket,
ROUND(
SUM(IF(ap.event_type = 'order', 1, 0)) / COUNT(*) * 100, 2
) AS conversion_rate
FROM user_profiles up
JOIN app_events ap
ON up.user_id = ap.user_id
WHERE up.signup_date >= '2023-01-01'
AND ap.event_type IN ('order', 'view')
GROUP BY up.age_bucket
ORDER BY up.age_bucket;문제 3 ) 우수 고객 파악 🟢
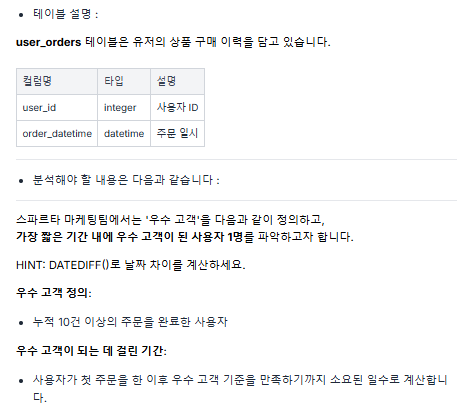
풀이
WITH order_rn AS(
SELECT user_id,
order_datetime,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY order_datetime) AS rn
FROM user_orders
),
ten_orders AS(
SELECT user_id,
MIN(CASE WHEN rn = 1 THEN order_datetime END)AS first_order,
MIN(CASE WHEN rn = 10 THEN order_datetime END)AS last_order
FROM order_rn
GROUP BY user_id
HAVING COUNT(*) >= 10
),
vip_days AS(
SELECT user_id,
DATEDIFF(last_order, first_order) AS days_to_power_user
FROM ten_orders)
SELECT *
FROM vip_days
ORDER BY days_to_power_user
LIMIT 13️⃣ 해설
SELECT user_id,
DATEDIFF(tenth_ordertime, order_datetime) AS days_to_power_user
FROM (
SELECT user_id,
order_datetime,
LEAD(order_datetime, 9) OVER (PARTITION BY user_id ORDER BY order_datetime) AS tenth_ordertime,
ROW_NUMBER() OVER (PARTITION BY user_id ORDER BY order_datetime) AS rn
FROM user_orders
) a
WHERE rn = 1
AND tenth_ordertime IS NOT NULL
ORDER BY days_to_power_user
LIMIT 1통계 + 머신러닝 개인과제
필수 1. pandas 응용
- statistics csv 파일을 읽고, Category 기준 Customer ID 컬럼은 Count, Purchase Amount(USD) 컬럼은 Sum 연산을 진행해주세요. 동시에 2가지 연산을 진행해주세요. (한번의 group by)
- 그리고 이를 df2 라는 변수에 저장해주세요.
- 결과 제출형태
풀이
import pandas as pd
df = pd.read_csv(r"C:\Users\1234\PycharmProjects\sparta_python\statistics\statistics.csv")
df2 = df.groupby('Category').agg({
'Customer ID' : 'count',
'Purchase Amount (USD)' : 'sum'
}).reset_index()
df2필수 2. pandas 응용
- Expanding 메서드를 이용하여, Purchase Amount (USD) 의 누적 합을 계산해주세요.
- 그리고 결과값을 df의 “Purchase Amount (USD)_누적” 컬럼으로 새롭게 지정해주세요. 그리고 Purchase Amount (USD) 과 함께 보여주세요. 결과값은 아래와 같아야 합니다.
풀이
import pandas as pd
df['Purchase Amount (USD)_누적']= df['Purchase Amount (USD)'].expanding().sum()
df[['Purchase Amount (USD)_누적', 'Purchase Amount (USD)']]필수 3. 기초통계
- 성별 Review Rating 에 대한 평균과 중앙값을 동시에 구해주세요. 결과는 소수점 둘째자리까지 표현해주세요.
- 그리고 이에 대한 해석을 간략하게 설명해주세요.
- 결과 제출형태
- 코드와 결과값
- 해석
풀이
import pandas as pd
df.groupby('Gender')['Review Rating'].agg(['mean','median']).round(2)
# 해석
# 여성 평균 3.74, 중앙값 3.7 / 남성 평균 3.75, 중앙값 3.8
# 두 성별은 유사한 평점 분포를 보임 필수 4. 통계적 가설검정
- 성별, Review Rating 컬럼에 대한 T-TEST 를 진행해주세요.
- 해당 데이터셋의 컬럼들은 정규성을 만족한다고 가정하겠습니다.
(T-TEST 진행시, equal_var=True 로 지정해주세요.)- 귀무가설과 대립가설을 작성해주세요.
- t-score, P-value 를 구해주세요. 단, t값의 부호는 어느 집단의 평균이 더 높은지에 대한 방향성에 대한 내용이므로, 아래와 같이 해석해주세요.
- t > 0: 첫 번째 그룹 평균이 더 큼
- t < 0: 두 번째 그룹 평균이 더 큼
- 그리고 이에 대한 귀무가설 채택/기각 여부와 그렇게 생각한 이유를 간략하게 설명해주세요.
- 결과 제출형태
- 귀무가설, 대립가설
- 코드와 결과값
- 해석(채택여부 및 이유)
풀이
import pandas as pd
import scipy.stats as stats
# 가설 설정
# 귀무가설 : 두 성별 간 평균 평점은 차이가 없다
# 대립가설 : 두 성별 간 평균 평점은 차이가 있다
# 데이터 분리
mask_m = (df['Gender'] == 'Male')
mask_f = (df['Gender'] == 'Female')
male = df[mask_m]
female = df[mask_f]
# 확인용 코드
display(male, female)
# 통계적 가설검정
t, p_value = stats.ttest_ind(female['Review Rating'], male['Review Rating'], equal_var=True)
print(f"t : {t:.4f}")
print(f"p-value : {p_value:.4f}")
# 해석
# t : -0.5097 , p-value : 0.6103
# t < 0 이므로 남성 평균 평점이 더 크다
# p-value > 0.05 이므로 통계적으로 유의미하지 않다
# 따라서 최종적으로 귀무가설 채택
# 귀무가설 : 두 성별 간 평균 평점은 차이가 없다 > 채택
# 대립가설 : 두 성별 간 평균 평점은 차이가 있다 > 기각 필수 5. 통계적 가설검정
- Color, Season 컬럼에 대한 카이제곱 검정을 진행해주세요.
- 귀무가설과 대립가설을 작성해주세요.
- 두 범주형 자료의 빈도표를 만들어주세요. 이를 코드로 작성하여 기재해주세요.
- 카이제곱통계량, P-value 를 구해주세요.
- 그리고 이에 대한 귀무가설 채택/기각 여부와 그렇게 생각한 이유를 간략하게 설명해주세요.
- 결과 제출형태
- 귀무가설, 대립가설
- 코드와 결과값
- 해석(채택여부 및 이유)
풀이
import pandas as pd
from scipy.stats import chi2_contingency
# 가설 설정
# 귀무가설 : Color, season은 관계가 없다
# 대립가설 : Color, season은 관계가 있다
# 데이터 확인
df.groupby(['Color', 'Season'])['Customer ID'].count().reset_index()
result = pd.crosstab(df['Color'], df['Season'])
# 확인용
result
# 카이제곱 독립성 검정
chi2, p, dof, expected = chi2_contingency(result)
print(f"카이제곱 통계량: {chi2:.3f}, p-value : {p:.3f}, 자유도: {dof}")
# 해석
# 카이제곱 통계량: 64.651, p-value : 0.719, 자유도: 72
# p-value > 0.05 이므로 통계적으로 유의미하지 않다
# 따라서 최종적으로 귀무가설 채택
# 귀무가설 : Color, season은 관계가 없다 > 채택
# 대립가설 : Color, season은 관계가 있다 > 기각
# 두 변수는 독립적임 필수 6. 머신러닝
- 아래와 같은 데이터가 있다고 가정하겠습니다.데이터를 바탕으로 선형 회귀 모델을 훈련시키고, 회귀식을 작성해주세요.
- 독립 변수(X): 광고예산 (단위: 만원)
- 종속 변수(Y): 일일 매출 (단위: 만원)
- X=[10, 20, 30, 40, 60, 100]
- Y=[50, 60, 70, 80, 90, 120]
- 회귀식을통해, 새로운 광고예산이 1,000만원일 경우의 매출을 예측(계산)해주세요. 그리고 이에 대한 해석을 간략하게 설명해주세요.
- 결과 제출형태
- 회귀식
- 코드와 결과값
- 해석
풀이
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
X = [10, 20, 30, 40, 60, 100] # 광고예산
Y = [50, 60, 70, 80, 90, 120] # 일일매출
# 어레이로 변환 (1차원 > 2차원)
X = np.array(X).reshape(-1, 1)
Y = np.array(Y)
# 모델 선언
model = LinearRegression()
# 모델 학습
model.fit(X,Y)
# 기울기, 절편
print(f"회귀식 : y = {model.coef_[0]:.3f}x + {model.intercept_:.3f}") # y = 0.756x + 45.562
# 광고예산이 1000만원일 경우 매출 예측
budget = 1000
coef = model.coef_[0] # 기울기
intercept = model.intercept_ # 절편
sales = coef * budget + intercept
print(f"매출 : {sales:.0f}만원") # 802만원
# 해석
# 광고 예산과 일일 매출은 양의 상관관계
# 광고 예산이 1만원 증가할때, 일일 매출은 약 0.756만원 증가
# 광고 예산이 1000만원일 경우 예상 매출은 약 802만원
# 따라서 광고 집행이 매출 증대에 도움이 됨 도전 1. 머신러닝
- Review Rating, Age, Previous Purchases 컬럼을 활용하여, 고객이 할인(Discount Applied)을 받을지 예측하는 RandomForest모델을 학습시켜 주세요. 그리고 모델 정확도를 계산해주세요.
- y(종속변수)는 Yes/No 로 기재된 이진형 데이터입니다. 따라서, 인코딩 작업이 필요합니다. 구현을 위해 LabelEncoder를 사용해주세요.
- 머신러닝시, 전체 데이터셋을 Train set과 Test set 으로 나눠주세요. 해당 문제에서는Test set비중을 30%로 설정해주세요. random_state는 42로 설정해주세요.
- Train Set: 모델을 학습하는데 사용하는 데이터셋
- Test Set: 적합된 모델의 성능을 평가하는데 사용하는 데이터셋
- RandomForestClassifier 를 활용하여 모델 학습을 진행해주세요. random_state는 42로 설정해주세요.
- 참고) https://www.ibm.com/kr-ko/topics/random-forest
- 그리고 이에 대한 해석을 간략하게 설명해주세요.
- 결과 제출형태
- 코드와 결과값(정확도)
- 해석
풀이
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 결측치 확인
df.isna().sum() # 없음
df.shape # (3900, 19)
# 변수선택
X = df[['Review Rating', 'Age', 'Previous Purchases']]
# 인코딩
encoder = LabelEncoder()
y = encoder.fit_transform(df['Discount Applied'])
# 데이터 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42, stratify = y)
# 확인
print(X_train.shape) # (2730, 3)
print(y_test.shape) # (1170,)
# Random Forest 학습
rf_model = RandomForestClassifier(random_state = 42)
rf_model.fit(X_train, y_train)
# 예측
y_pred_rf = rf_model.predict(X_test)
# 성능평가
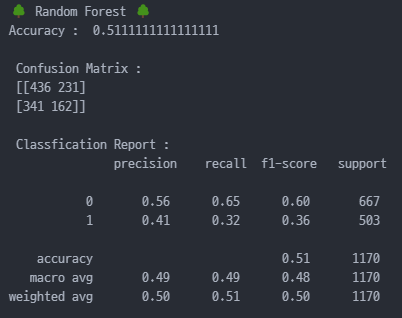
print("🌳 Random Forest 🌳")
print("Accuracy : ", accuracy_score(y_test, y_pred_rf))
print("\n Confusion Matrix : \n", confusion_matrix(y_test, y_pred_rf))
print("\n Classfication Report : \n", classification_report(y_test, y_pred_rf))
# 해석
# 정확도는 약 51.1% > 성능이 별로 좋지 않은 모델
# 0(No) 정밀도 0.56, 재현율 0.65 > No 클래스는 성능 양호
# 1(Yes) 정밀도 0.41, 재현율 0.32 > yes 클래스는 성능 별로
# 실제 할인 받은 고객을 제대로 분류하지 못함
도전 2. 머신러닝
- Subscription Status(구독여부) 컬럼을 종속변수로 두고 이를 예측하는 로지스틱 회귀 모델 학습을 진행해주세요. Age, Purchase Amount, Review Rating을 활용하여 모델을 훈련한 후, 연령 30세, 구매 금액 50 USD, 리뷰 평점 4.0인 고객의 구독취소 확률을 계산해주세요.
- y(종속변수)는 Yes/No 로 기재된 이진형 데이터입니다. 따라서, 인코딩 작업이 필요합니다. 구현을 위해 LabelEncoder를 사용해주세요. 아래와 같이 지정해주세요.
- 종속변수 Yes = 구독= 0
- 종속변수 No = 구독 취소 = 1
- 머신러닝시, 전체 데이터셋을 Train set과 Test set 으로 나눠주세요. 해당 문제에서는Test set비중을 30%로 설정해주세요. random_state는 42로 설정해주세요.
- Train Set: 모델을 학습하는데 사용하는 데이터셋
- Test Set: 적합된 모델의 성능을 평가하는데 사용하는 데이터셋
- 연령 30세, 구매 금액 50 USD, 리뷰 평점 4.0 인 고객을 new_customer 라는 변수에 지정해주세요. 1차원이 아닌 이중 대괄호
[[...]]로 지정해주세요. (모델 입력 형식은 2차원 배열이어야 합니다.)- model.predict_proba 를 사용하여 구독취소 확률을 구해주세요.
- predict_proba의 반환값: 로지스틱 회귀 모델의 예측 결과를 확률 값으로 제공해주며, ****모델이 각 클래스에 속할 확률을 계산합니다. 결과는 배열로 반환됩니다. 인코딩된 값을 기준으로 예측을 수행합니다. 즉, 예측 확률의 순서는 이 클래스 순서
[0, 1] = [구독(인코딩 값 0), 구독취소(인코딩 값 1)]으로 도출됩니다.- 참고: 클래스는 0과 1로 이루어질 필요는 없지만, 이진 분류 문제에서는 관례적으로 0과 1을 사용합니다.
예시) predict_proba(new_customer)가 아래와 같이 반환되었다면
[[0.27, 0.73]]
이 고객이 구독할 확률 약 27%
이 고객이 구독취소할 확률 약 73%
- 그리고 이에 대한 해석을 간략하게 설명해주세요.
- 결과 제출형태
- 코드와 결과값(구독취소확률)
- 해석
풀이
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
from sklearn.metrics import roc_curve, roc_auc_score
# 변수선택
X = df[['Age', 'Purchase Amount (USD)', 'Review Rating']]
# 인코딩
encoder = LabelEncoder()
y = encoder.fit_transform(df['Subscription Status'])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42, stratify = y)
# 확인
print(X_train.shape) # (2730, 3)
print(y_test.shape) # (1170,)
# Logistic 학습
logi_model = LogisticRegression()
logi_model.fit(X_train, y_train)
# 예측
y_pred_logi = logi_model.predict(X_test)
y_proba_logi = logi_model.predict_proba(X_test)
# 신규 고객
new_customer = [[30, 50, 4.0]]
# 구독 취소 확률 구하기
proba = logi_model.predict_proba(new_customer)
print(f"🧑🦲 고객정보 \n고객 나이 : {new_customer[0][0]} / 구매 금액 : {new_customer[0][1]} / 리뷰 평점 : {new_customer[0][2]}")
print(f"- 구독 확률 : {proba[0][0] * 100:.2f}%") #0.73, 0.270
print(f"- 구독취소 확률 : {proba[0][1] * 100:.2f}%")
# auc 계산
auc_score = roc_auc_score(y_test, y_proba_logi[:, -1])
# 성능평가
print("\n🌹 Logistic Regression 🌹")
print("Confusion Matrix :\n", confusion_matrix(y_test,y_pred_logi))
print("\n Accuracy : ", accuracy_score(y_test, y_pred_logi))
print("\n Classification Report :\n ", classification_report(y_test, y_pred_logi))
print("\n ROC - AUC score : ", auc_score)
# 해석
# 고객이 구독할 확률은 약 73%, 구독하지 않을 확률은 약 27%
# 정확도가 약 73%로 높게 나왔으나, 실제 구독 취소 고객을 하나도 맞추지 못한 것이라 좋은 모델이라 할 수 없음
# roc-auc score 약 0.5로 랜덤에 가까움 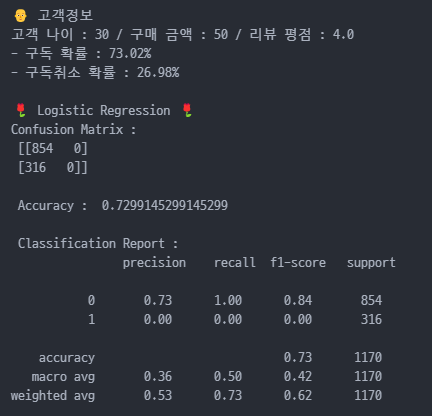
일기
- 머신러닝
개인과제 ✅ - SQL
QCC 5회차 ✅ - 태블로
강의 1주차✅
튜터님께 피드백 요청드렸는데 상세히 잘 알려주셔서 너무나 좋았다 😀 튜터님이 금요일이니까 좀 쉬엄쉬엄 해도 된다고 하셔서 하루종일 졸렸는데 그 말을 들은 기점으로 마음이 너무 편해졌나.. 7시반쯤인가 사우론 파업한다고 하고 잠깐 쉬고 있다가 잠들어버려서 (ㅋㅋ) 스크럼 참여 못함 팀원분들이 너무 너그럽게 양해해주셔서 감사.... ....

오늘 QCC 만점인데 심지어 당첨됐다! 영은매니저님이랑 무언의 제스처 주고받았는데 이거 나한테 하는 말 맞나? 긴가민가 하면서 나갔다 이따 여쭤보니까 맞다고 하심 ㅋㅋ 짱재밌다
아무튼 연휴 푹 쉬고 또 파이팅해야겠다~

튜터님 왤케 맑눈광같으시지.. QCC 스피드 만점 너무 축하해욧!!!!!!!!!!!