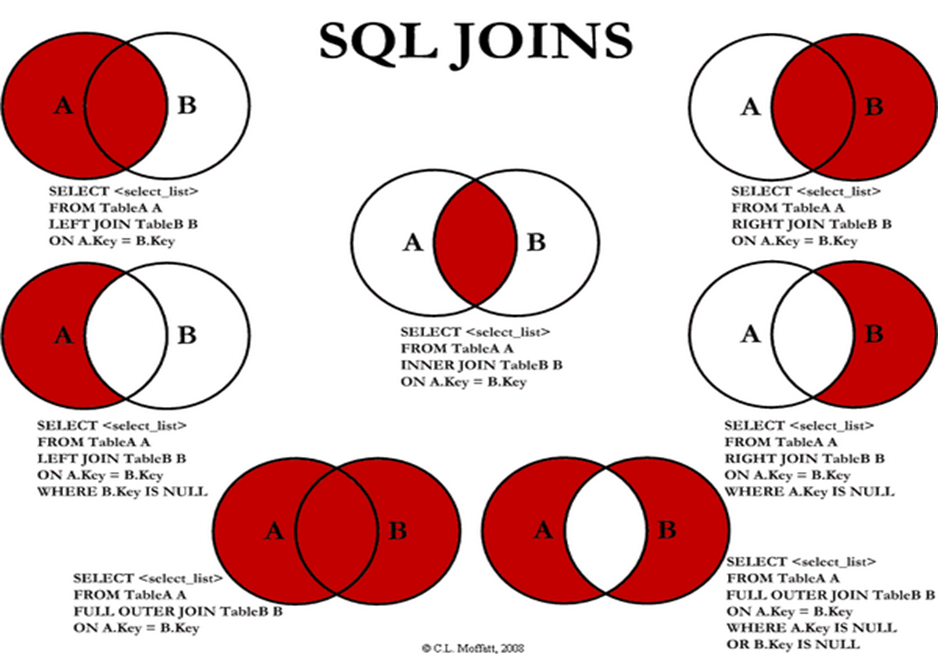
Join
- 한 데이터베이스 내의 여러 테이블의 레코드를 조합하여 하나의 열로 표현한 것이다.
- 따라서 조인은 테이블로서 저장되거나, 그 자체로 이용할 수 있는 결과 셋(set)을 만들어 낸다.
Sharding
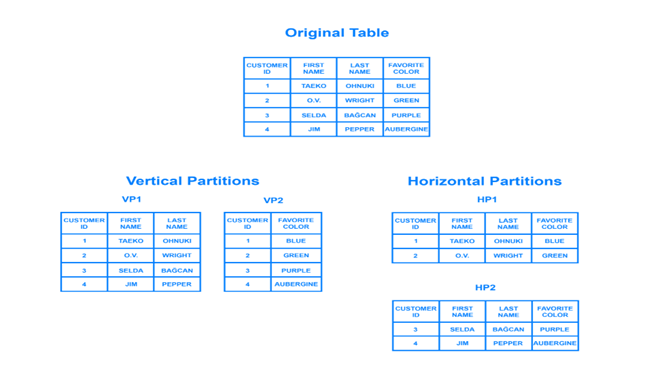
- 같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법
장점
• Scale-Out이 가능
• 스캔 범위를 줄여서 쿼리 반응 속도를 빠르게 함
• 장애가 샤드 단위로 발생함
단점
• 프로그래밍 복잡도가 증가
• 데이터가 한 쪽 샤드로 몰릴 경우(Hotspot), 샤딩이 무의미 해짐
• 잘 못 사용할 경우 risk가 큼
• 한번 샤딩 사용시 샤딩 이전의 구조로 돌아가기 힘듬
샤딩은 위와 같이 프로그래밍, 운영적 복잡도가 높아지는 단점이 있다. 따라서 가능하다면 샤딩을 피하는 방법을 사용하는 것이 좋다. 대표적인 방법으로는 데이터베이스 서버의 Scale-Up, Read의 부하가 클 경우 Cache 사용 및 Database Replication, 테이블의 일부 컬럼만 주로 사용할 경우 Vertical Partitioning 등의 방법이 있다.
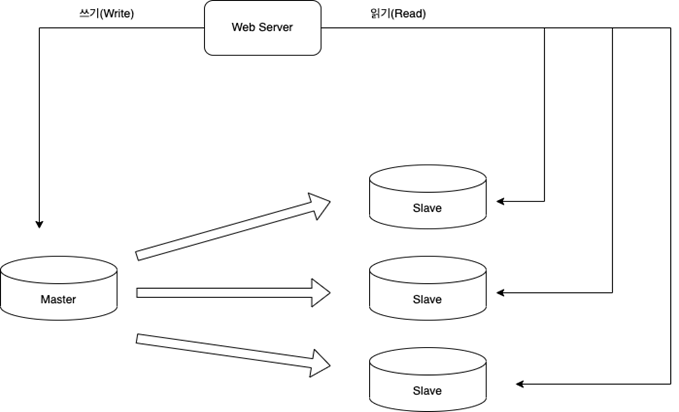
Master/Slave
- Replication(복제)은 말 그대로 DB인 데이터를 갖다가 물리적으로 복사해 다른곳에 넣어두는 기술을 의미
쓰기(Write)는 마스터에서만 지원하고, 부(Slave)서버는 DB사본을 갱신하면서, 읽기만을 지원합니다. 통상 애플리케이션은 읽기 연산 비중이 훨씬 크기 때문에 아래와 같은 구성으로 많이 사용
장단점
• 주 연산에 해당하는 읽기(Write) 연산을 병렬로 처리가 가능함
• 일부가 손상, 파괴되어도 데이터가 보존됨
• slave가 갱신되기 전에 조회 시 데이터 불일치 발생 가능
이상 현상과 정규화
정규화
- 정규화란 이상 현상을 제거하기 위해서, 릴레이션을 의미 있는 속성들로만 구성하기 위해 릴레이션을 분해하는 과정과정/ 이때 함수적 종속성을 판단하여 정규화를 진행
정규화 3가지 원칙 :
- 정보의 무손실 : 분해된 릴레이션이 표현하는 정보는 분해되기 전의 정보를 모두 포함해야 한다.
- 최소 데이터 중복 : 이상 현상을 제거, 데이터 중복을 최소화
- 분리의 원칙 : 하나의 독립된 관계성은 하나의 독립된 릴레이션으로 분리해서 표현
이상현상
- 불필요한 데이터 중복으로 인해 릴레이션에 대한 데이터 삽입, 수정, 삭제 연산을 할 때 발생할 수 있는 부작용
이상 현상의 종류
- 삽입 이상
데이터를 삽입하기 위해 불필요한 데이터도 함께 삽입해야 하는 문제
- 갱신 이상
중복 튜플 중 일부만 변경하여 데이터가 불일치하게 되는 문제
- 삭제 이상
튜플을 삭제하면 꼭 필요한 데이터까지 같이 삭제되는 데이터 손실 문제
함수 종속
- X -> Y 일 때
"X가 Y를 함수적으로 결정한다" = "Y가 X에 함수적으로 종속되어 있다"
릴레이션 내의 모든 튜플을 대상으로 하나의 X값에 대한 Y값이 항상 하나인 경우를 의미한다.
- 함수 종속 관계를 판단할 때 현재의 속성 값을 기준으로 판단하면 안 되고 속성에 들어올 수 있는 값들을 고려하여 판단해야 한다. 일반적으로 기본키와 후보 키는 릴레이션의 다른 모든 속성들을 함수적으로 결정한다.
완전 함수 종속 (Full Functional Dependency)
- 일반적으로 함수 종속은 완전 함수 종속을 의미하는데 X -> Y 일 때 속성 집합 X의 일부분에는 Y가 종속되어 있지 않는다.
부분 함수 종속 (Partial Functional Dependency)
- X -> Y 일 때 속성 집합 X의 부분집합에도 Y가 함수적으로 종속되어 있을 때 부분 함수 종속이라고 한다.
이행적 함수 종속 (Transitive Functional Dependency)
- 함수 종속 관계 X -> Y, Y -> Z 가 있으면 논리적으로 X -> Z 가 성립된다. 이것을 Z가 X에 이행적으로 함수 종속되었다고 한다.
트랜잭션
- 데이터베이스의 상태를 변경시키기 위해 수행하는 작업 단위( SELECT, UPDATE, INSERT, DELETE 와 같은 행동)
ACID
원자성 (Atomicity)
- 원자성은 트랜잭션이 DB에 모두 반영되거나, 전혀 반영되지 않거나를 뜻한다.
All or Nothing을 생각하면 된다.
일관성 (Consistency)
- 일관성은 트랜잭션 작업 처리의 결과가 항상 일관되어야 한다를 뜻한다.
즉, 데이터 타입이 반환 후와 전이 항상 동일해야 한다.
독립성 (Isolation)
- 독립성은 하나의 트랜잭션은 다른 트랜잭션에 끼어들 수 없고 마찬가지로 독립적임을 의미한다.
즉, 각각의 트랜잭션은 독립적이라 서로 간섭이 불가능하다.
지속성 (Durability)
- 지속성은 트랜잭션이 성공적으로 완료되면 영구적으로 결과에 반영되어야 함을 뜻한다.
보통 commit 이 된다면 지속성은 만족할 수 있다.
Lock
• Lock이란 트랜잭션 처리의 순차성을 보장하기 위한 방법
• DBMS마다 Lock을 구현하는 방식과 세부적인 방법이 다름
• DBMS를 효과적으로 이용하기 위해서는 해당 DB의 Lock에 대한 이해가 필요
Lock 종류
• Lock의 종류로는 공유(Shared) Lock과 베타(Exclusive) Lock이 있음
• 공유락은 다른 말로 Read Lock이라고 불리며 베타락은 Write Lock이라고도 불림
공유(Shared) Lock
• 공유 Lock은 데이터를 읽을 때 사용되어지는 Lock
• 공유 Lock은 공유 Lock 끼리는 동시에 접근이 가능
• 하나의 데이터를 읽는 것은 여러 사용자가 동시에 할 수 있다라는 의미
• 공유 Lock이 설정된 데이터에 베타 Lock을 사용할 수는 없음
베타(Exclusive) Lock
• 베타 Lock은 데이터를 변경하고자 할 때 사용되며, 트랜잭션이 완료될 때까지 유지
• 베타락은 Lock이 해제될 때까지 다른 트랜잭션(읽기 포함)은 해당 리소스에 접근할 수 없음
• 베타 Lock은 다른 트랜잭션이 수행되고 있는 데이터에 대해서는 접근하여 함께 Lock을 설정할 수 없음
Lock 설정 범위
- 데이터베이스
o 데이터베이스 범위의 lock은 전체 데이터베이스를 기준으로 lock
o 1개의 세션만이 DB의 데이터에 접근이 가능
o 일반적으로는 사용하지 않음. DB의 소프트웨어 버전을 올린다던지 주요한 DB의 업데이트에 사용 - 파일
o 데이터베이스 파일을 기준으로 lock을 설정
o 테이블, row 등과 같은 실제 데이터가 쓰여지는 물리적인 저장소
o 파일 범위의 Lock은 잘 사용되지는 않음 - 테이블
o 테이블 수준의 Lock은 테이블을 기준으로 Lock을 설정
o 테이블의 모든 행을 업데이트 하는 전체 테이블에 영향을 주는 변경을 수행할 때 유용
o DDL(create, alter, drop 등) 구문과 함께 사용되며 DDL Lock이라고도 불림. - 페이지와 블럭
o 파일의 일부인 페이지와 블록을 기준으로 Lock을 설정
o 잘 사용되지는 않음 - 컬럼
o 컬럼 기준의 Lock은 컬럼을 기준으로 Lock을 설정할 수 있음
o 해당 형식은 Lock 설정 및 해제의 리소스가 많이 들기 때문에 일반적으로 사용되지는 않음
o 지원하는 DBMS도 많지 않음 - 행(Row)
o 행 수준의 Lock은 1개의 행(Row)를 기준으로 Lock 설정
o DML에 대한 Lock으로 가장 일반적으로 사용하는 Lock
