트랜잭션 격리 수준(Isolation level)
- 트랜잭션의 특징 ACID 중 Isolation에 따라, 트랜잭션간에 격리성(독립성)을 완전히 보장해야 한다. 하지만 그럴 경우를 완전히 보장하기 위해서는 모든 트랜잭션을 차례로 처리 해야 하며, 이는 성능의 하락으로 이어짐
- 트랜잭션 격리 수준은, 동시에 여러 트랜잭션이 처리될 때 특정 트랜잭션이 다른 트랜잭션에서 변경하거나 조회하는 데이터를 볼 수 있도록 허용할지 말지를 결정하는 것이다.
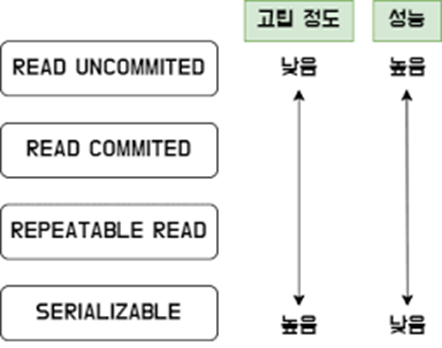
0 : READ UNCOMMITTED (커밋되지 않은 읽기)
• 각 트랜잭션에서의 변경 내용이 COMMIT이나 ROLLBACK 여부에 상관 없이 다른 트랜잭션에서 값을 읽을 수 있습니다.
• 정합성에 문제가 많은 격리 수준이기 때문에 사용하지 않는 것을 권장합니다.
• DIRTY READ(트랜잭션이 작업이 완료되지 않았는데도 다른 트랜잭션에서 볼 수 있게 되는 현상) 발생
1 : READ COMMITTED (커밋된 읽기)
• COMMIT 이 된 데이터만 읽습니다.
• RDB에서 대부분 기본적으로 사용되고 있는 격리 수준
• Dirty Read와 같은 현상은 발생하지 않지만 NON-REPEATABLE READ(하나의 트랜잭션 내에서 동일한 SELECT 쿼리를 실행했을 때 항상 같은 결과를 보장해야 한다는 REPEATABLE READ 정합성에 어긋나는 것) 발생
• 실제 테이블 값을 가져오는 것이 아니라 Undo 영역에 백업된 레코드에서 값을 가져온다.
2 : REPEATABLE READ (반복 가능한 읽기)
• 자신의 트랜잭션이 생성되기 이전의 트랜잭션에서 COMMIT 이 된 데이터만 읽습니다.
• MySQL과 MariaDB 가 기본으로 사용하는 격리 수준
• MySQL에서는 트랜잭션마다 트랜잭션 ID를 부여하여 트랜잭션 ID보다 작은 트랜잭션 번호에서 변경한 것만 읽게 된다.
• PHANTOM READ(다른 트랜잭션에서 수행한 변경 작업에 의해 레코드가 보였다가 안 보였다가 하는 현상)발생
3 : SERIALIZABLE (직렬화 가능)
• 가장 단순한 격리 수준이지만 가장 엄격한 격리 수준
• 데이터를 접근할 때, 항상 Lock을 걸고 데이터를 조회
• SERIALIZABLE에서는 PHANTOM READ가 발생하지 않는다.
• 성능 문제로 데이터베이스에서 거의 사용되지 않는다.

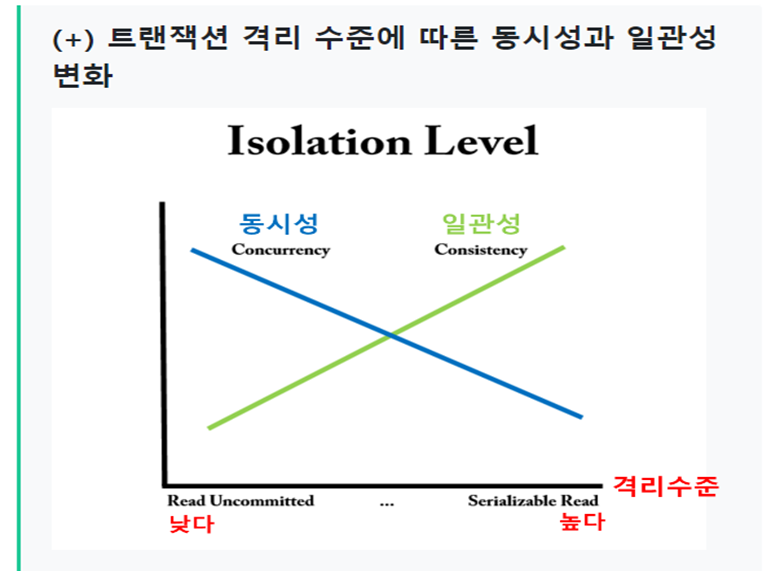
- 격리 수준이 높아지면서 데이터의 일관성이 유지될 수 있지만, 동시에 처리가능한 트랜잭션의 양은 떨어집니다. 격리수준이 낮아지면 일관성은 유지되기 어렵지만, 동시에 처리할 수 있는 트랜잭션의 양은 늘어나게 됩니다.
• 동시성 : 동시에 수행하는 트랜잭션 양
• 일관성 : 트랜잭션의 작업 처리 결과가 항상 일관성이 있어야 한다는 것
교착상태
※ Lock
- 대용량의 데이터를 처리하는 데이터베이스 애플리케이션의 경우 데이터의 정확성을 유지하면서 최대한 동시성을 높이는 것이 중요한 포인트이다. 그렇기 때문에 상황에 따른 여러가지 Lock을 통해 동시성을 제어하며 이를 통해 사용자가 설정한 대로 원하는 수준의 트랜잭션 격리 수준(Transaction Isolation Level)을 유지해준다.
Lock은 트랜잭션과 비슷한 개념같지만, Lock은 동시성을 제어하기 위한 기능이고, 트랜잭션은 정합성을 보장히기 위한 기능이다.
데이터의 일관성을 보장하기 위한 하나의 방법이다.
DeadLock(교착상태)
- 둘 이상의 프로세스가 다른 프로세스가 점유하고 있는 자원을 서로 기다릴 때 무한 대기에 빠지는 상황을 말한다.
데이터베이스 관점에서는 트랜젝션간 발생하는 것을 의미하며, 두 개의 트랜젝션이 각각의 트랜젝션이 가지고 있는 리소스의 Lock을 획득하려고 할 때 발생
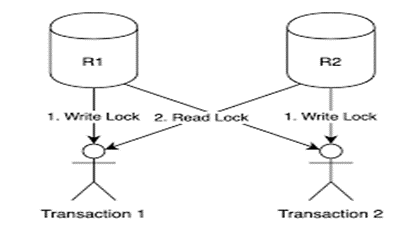
교착상태 발생의 필요 충분 조건
- 네가지의 조건이 모두 충족되어야 교착상태가 발생한다.
- 상호배제 (Mutual Exclusion)
한번에 한개의 프로세스만 자원을 사용할 수 있어야 한다. - 점유와 대기 (Hold and Wait)
프로세스가 한개의 자원을 점유하고 있고 추가적으로 다른 프로세스의 자원을 점유하기 위해서는 대기해야한다. - 비선점 (Non-preemption)
점유된 자원은 강제로 해제될 수 없고, 프로세스가 자원의 사용을 자발적을 해제하기 전까지 그 자원은 얻을 수 없다. - 환형 대기 (Circular Wait)
자원과 자원을 사용하기 위해 대기하는 프로세스들이 원형으로 구성되어 있어 자신에게 할당된 자원을 점유하면서 앞이나 뒤에 있는 프로세스의 자원을 요구해야 한다.
DeadLock의 해결방법
- 교착상태 예방 (Prevention)
필요충분 조건 중 한가지를 제거함으로써 교착상태가 발행하지 않도록 사전에 방지하는 방법. 이 방법은 자원 요청을 제한하여 교착상태를 예방한다. 자원낭비가 가장 심하다. - 교착상태 회피 (Avoidance)
교착상태 회피 기법은 교착상태가 발생할 가능성을 배제하지 않고 교착상태가 발생하면 적절히 피해나가는 방법으로, 주로 은행원 알고리즘(Banker’s Algorithm)이 사용된다. - 교착상태 탐지 (Detection)
교착상태가 발생했는지 점검하여 교착상태에 있는 프로세스와 자원을 발견하는 것이다.
인덱스
개념
A. 간단한 비유로 일반적으로 책 뒤쪽에 위치하는 ‘찾아보기’를 들 수 있다.
B. 일 예로, ‘홍길동전’에서 ‘율도국’이라는 단어를 찾는다고 가정해보자. 만일 이 책에 ‘찾아보기’가
없다면 책을 첫 장부터 훑어야 할 것이다. 그런데 찾아보기가 있다면 한번에 찾아 갈 수 있다.
이 것이 인덱스의 기본적인 개념이다.
인덱스 생성시 발생되는 특징
A. 검색 속도 향상.
i. 시스템의 부하를 줄여, 시스템 전체 성능향상에 기여 가능.
B. 인덱스를 위한 추가 공간이 필요.
C. 생성에 시간이 소요 될 수 있음.
D. INSERT, UPDATE, DELETE가 자주 발생한다면 성능이 많이 하락할 수 있다.
종류
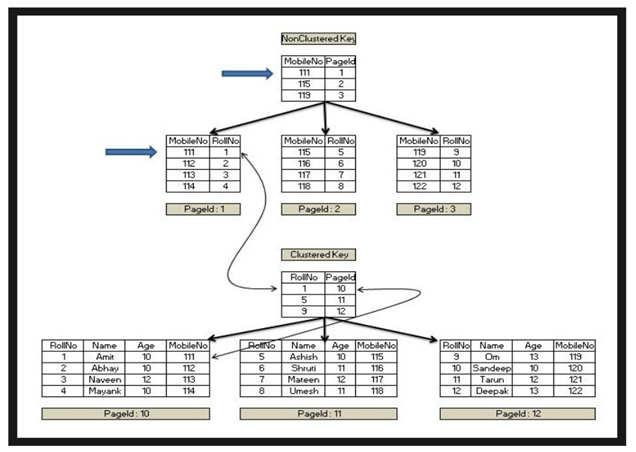
A. 클러스터형 인덱스(Clustered Index).
i. 테이블당 한 개만 생성이 가능하다.
ii. 행 데이터를 인덱스로 지정한 열에 맞춰서 자동 정렬한다.
iii.영어 사전처럼 책의 내용 자체가 순서대로 정렬이 되어 있어, 인덱스 자체가 책의 내용과 같음.
B. 비클러스터형 인덱스(Nonclustered Index)
i. 테이블당 여러 개를 생성할 수 있다.
ii. 비클러스터형 인덱스는 그냥 찾아보기가 있는 일반 책과 같다.