NoSQL
NoSQL의 개념
- 관계형 데이터베이스 이외의 형식으로(비관계형 모델) 데이터를 저장하는 데이터베이스로, NoSQL에서는 데이터를 행과 열이 아닌, 체계적인 방식으로 저장한다.
NoSQL의 종류
1. Key-Value 데이터베이스
- Key-Value 쌍으로 나타나는 데이터를 배열 형태로 저장
- key는 속성이름, value는 데이터 값 (Redis, DynamoDB...)
2. 문서형 데이터베이스
- 데이터를 문서형태로 저장한다.
- 사용이 번거롭고 쿼리가 SQL과는 다르다.
- JSON, XML과 같은 Collection 데이터 모델 구조를 채택함 (MongoDB...)
3. Wide-Column 스토어
- 각 열에는 key-value 형식으로 데이터 저장되고, column family라고 하는 열의 집합체단위로 데이터를 처리할 수 있음
- 각 행이 동일한 열을 가질 필요 없으므로 RBD에 비해 뛰어난 유연성 제공 (Cassandra,HBase...)
4. 그래프 데이터베이스
- 그래프와 비슷한 형식으로 데이터 관계를 구성
- node와 edge 와 함께 그래프 구조를 사용하여 데이터를 저장함. (Neo4J, InfiniteGraph...)
RDB VS NoSQL
RDBMS
- 장점
• RDBMS는 위에서 설명을 하였듯이 정해진 스키마에 따라 데이터를 저장하여야 하므로 명확한 데이터 구조를 보장하고 있습니다.
• 또한 관계는 각 데이터를 중복없이 한 번만 저장할 수 있습니다. - 단점
• 테이블간테이블 간 관계를 맺고 있어 시스템이 커질 경우 JOIN문이 많은 복잡한 쿼리가 만들어질 수 있습니다.
• 성능 향상을 위해서는 서버의 성능을 향상 시켜야하는 Scale-up만을 지원합니다. 이로 인해 비용이 기하급수적으로 늘어날 수 있습니다.
• 스키마로 인해 데이터가 유연하지 못합니다. 나중에 스키마가 변경 될 경우 번거롭고 어렵습니다.
NoSQL
- 장점
• NoSQL에서는 스키마가 없기 때문에 유연하며 자유로운 데이터 구조를 가질 수 있습니다. 언제든 저장된 데이터를 조정하고 새로운 필드를 추가할 수 있습니다.
• 데이터 분산이 용이하며 성능 향상을 위한 Saclue-up 뿐만이 아닌 Scale-out 또한 가능합니다. - 단점
• 데이터 중복이 발생할 수 있으며 중복된 데이터가 변경 될 경우 수정을 모든 컬렉션에서 수행을 해야 합니다.
• 스키마가 존재하지 않기에 명확한 데이터 구조를 보장하지 않으며 데이터 구조 결정가 어려울 수 있습니다.
사용처
- RDBMS
데이터 구조가 명확하며 변경 될 여지가 없으며 명확한 스키마가 중요한 경우 사용하는 것이 좋습니다. 또한 중복된 데이터가 없어(데이터 무결성) 변경이 용이하기 때문에 관계를 맺고 있는 데이터가 자주 변경이 이루어지는 시스템에 적합합니다.
- NoSQL
정확한 데이터 구조를 알 수 없고 데이터가 변경/확장이 될 수 있는 경우에 사용하는 것이 좋습니다. 또한 단점에서도 명확하듯이 데이터 중복이 발생할 수 있으며 중복된 데이터가 변경될 시에는 모든 컬렉션에서 수정을 해야 합니다. 이러한 특징들을 기반으로 Update가 많이 이루어지지 않는 시스템이 좋으며 또한 Scale-out이 가능하다는 장점을 활용해 막대한 데이터를 저장해야 해서 Database를 Scale-Out를 해야 되는 시스템에 적합합니다.
Redis
개념
- Redis : REmote DIctionary Server
- Key-Value 구조의 비정형 데이터를 저장하고 관리하기 위한 오픈소스 기반의 NoSQL DBMS
- 사용에 따라 데이터베이스로 사용될 수도 있고, Message Queue, Shared Memory 용도로 사용될 수 있음. 주로 Cache Server로 사용.
특징과 장점
- Key, Value 구조이기 때문에 쿼리를 사용할 필요가 없음
• 고정되지 않은 스키마를 가지므로 키마다 원하는 내용만 저장 가능 - In-Memory 데이터베이스
• 매우 빠름
• 서버 재시작 시 모든 데이터 유실
• 복제 기능이 있지만 사람의 실수에는 복원 불가
• 백업이 필요할 수 있음 (persist option 지원) - 다양한 자료구조를 제공
• String, List, Hash, Set, Sorted Set, Stream 등
• 사용 용이, 개발 편의성 증대
• application 단에서 필요한 로직을 DB 단에서 줄일 수 있음
• list형 데이터 입력/삭제가 MySQL에 비해 10배 빠름 - Single Thread로 동작
• 한 번에 여러 클라이언트의 요청을 수행할 수 없음
• 때문에 여러 요청이 동시에 돌아가지는 않지만 빠르게 처리해 동시성을 보장하려고 노력하고 경쟁상태를 방지(원자적 연산 수행)
• 한 클라이언트가 오래 걸리는 작업을 요청하면 장애가 발생할 수 있음 - 여러 대의 서버 구성 가능 (Master-Slave)
- Database, Cache, Message broker로 사용됨
• Cache로 사용 시 무조건 TTL로 사용. 시간 중요 - 읽기 성능 증대를 위한 서버 측 리플리케이션을 지원
- 쓰기 성능 증대를 위한 클라이언트 측 샤딩 지원
데이터베이스를 두고 Redis를 사용하는 이유는 데이터베이스는 물리디스크에 직접 write 작업이 이루어지기 때문에 데이터가 손실되지 않는 장점이 있지만, 사용자가 많아질 수록 디스크의 부하가 발생하게 된다. 이에 따라 한번 읽어온 데이터를 인 메모리 DB인 Redis에 캐싱하여 데이터 조회 작업을 빠르게 하여 서비스의 속도를 향상시켜줄 수 있다.
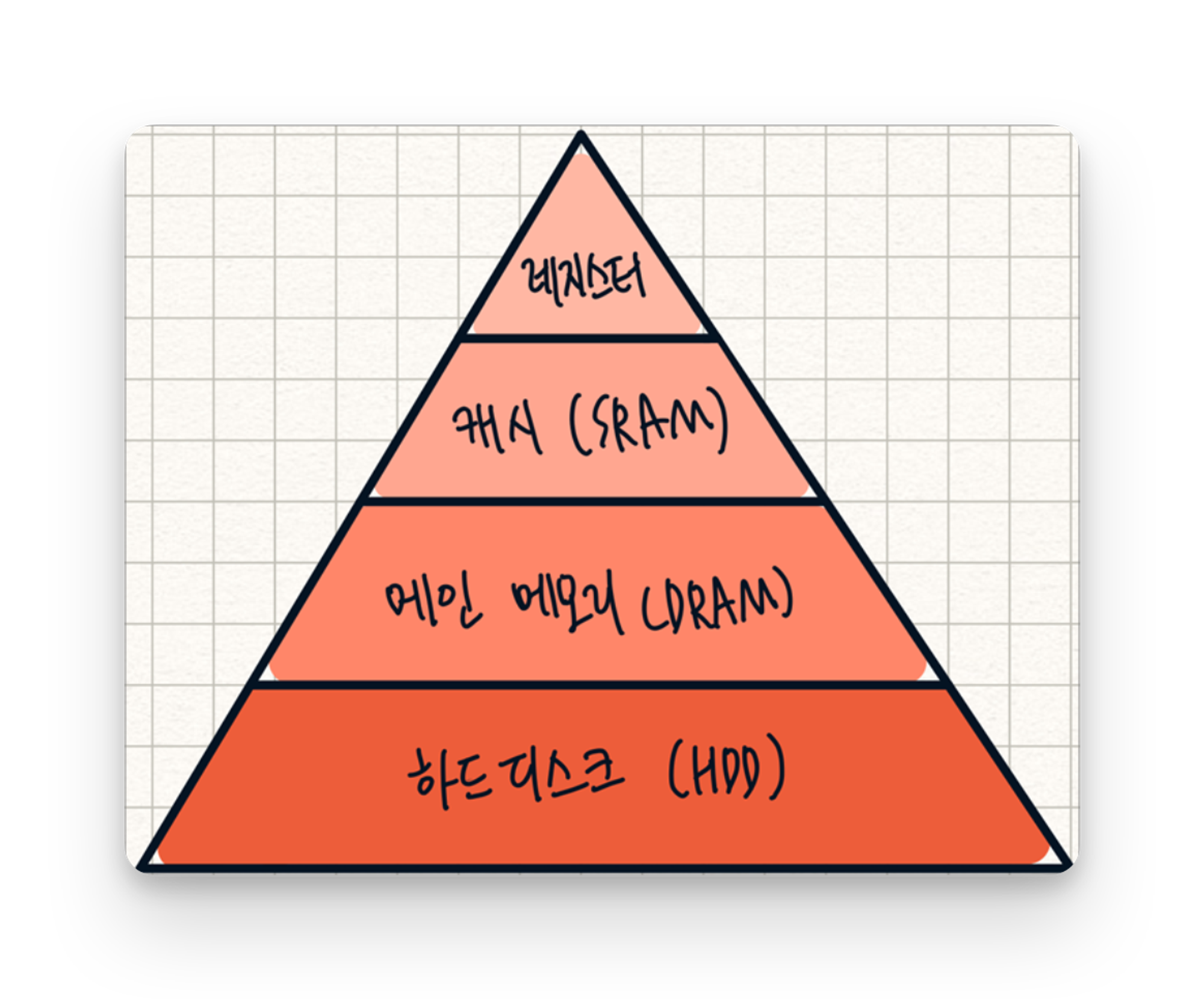
※ 인메모리
- 컴퓨터의 주 기억장치(메인메모리)인 RAM에 데이터를 올려서 사용하는 방법.
하드디스크(SSD, HDD)보다 수백배 이상 빠름. but, 휘발성 메모리
주 활용 방식
- 여러 서버에서 같은 데이터를 공유가 필요할 때
• 한대에서만 필요하면 전역변수 쓰면 되지 않나? → X
• Redis 자체가 Atomic하기때문에 Thread safe 하고 Single Thread 이기 때문에 Race Condition 발생 가능성이 낮음 - 인증 토큰 등을 저장 (Strings or hash)
- Ranking 보드로 사용 ( Sorted Set )
- 유저 API Limit
- Job QUeue

기록 블로그