zookeeper 클러스터 설정
version : zookeeper-3.4.6
conf/zoo.cfg
dataDir=/opt/data
server.1=test-nn0:2888:3888
server.2=test-nn1:2888:3888
server.3=test-jn0:2888:3888
server.x : zookeeper 연결(총 3개)
dataDir : zookeeper id 설정필요( /opt/data/myid -> 1~3(zookeeper 아이디))
zookeeper 실행
./zkServer.sh start
zookeeper 연결 상태 확인
./zkServer.sh status

follower 및 Leader 표시
hadoop 클러스터 설정
version : hadoop-3.3.1
hadoop 클러스터 구성
namenode 2, journalnode 3, datanode 2
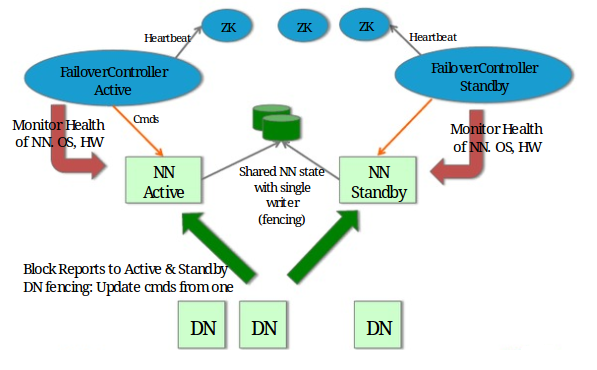
(https://hadoopabcd.wordpress.com/2015/02/19/hdfs-cluster-high-availability)
클러스터 설정
1. ubuntu 설정
아래 설정은 모든 node에 적용
-
ubuntu 그룹, 계정 생성 및 권한 추가
sudo addgroup hadoop
sudo adduser --ingroup hadoop hdusersudo visudo
hduser ALL=(ALL:ALL) ALL
-
각 호스트 네임 설정
sudo vi /etc/hostname
test-nn0, test-nn1, test-jn0, test-dn0, test-dn1(다른 PC)
-
SSH 설정
-비밀번호 없이 서로간에 공개키를 저장 하는 방식으로 통신
/etc/ssh/sshd_configPubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
-
키 발급
ssh-keygen -t rsa -P ""
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys-호스트별 키 저장
./ssh/authorized_keys
내부에 각 호스트네임 및 발급 된 공개키 입력
-
hosts 변경
vi /etc/hosts172.17.0.8 test-nn0
172.17.0.9 test-nn1
172.17.0.10 test-jn0
172.17.0.11 test-dn0
192.168.0.23 test-dn1
2. hadoop 설정
아래 설정은 각 역할마다 node에 적용
-
hadoop 환경 설정
ssh 기본 포트 변경
hadoop-3.3.1/etc/hadoop/hadoop-env.sh
export HADOOP_SSH_OPTS="-p 51022"환경 변수 등록
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
export HADOOP_HOME=/home/hduser/hadoop-3.3.1
export HADOOP_PID_DIR=$HADOOP_HOME/pids
-
core-site.xml 설정
hadoop-3.3.1/etc/hadoop/core-site.xml<!-- hadoop 기본 FS설정 및 zookeeper 연동(journalnode3) --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop-cluster:8020</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>test-nn0:2181,test-nn1:2181,test-jn0:2181</value> </property>
-
hdfs-site.xml 설정
hadoop-3.3.1/etc/hadoop/hdfs-site.xml<!--namenode 개수--> <property> <name>dfs.replication</name> <value>2</value> </property> <!--namenode, datanode, journalnode 폴더 설정, 각 서버마다 필요한 설정 세팅 및 폴더 생성--> <property> <name>dfs.namenode.name.dir</name> <value>/home/hduser/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/home/hduser/data/datanode</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/home/hduser/data/journalnode</value> </property> <!--datanode에만 추가.--> <property> <name>dfs.datanode.http.address</name> <value>0.0.0.0:59864</value> </property> <property> <name>dfs.datanode.address</name> <value>0.0.0.0:58864</value> </property> <!-- 네임서버 이름--> <property> <name>dfs.nameservices</name> <value>hadoop-cluster</value> </property> <!-- namenode 클러스터 이름--> <property> <name>dfs.ha.namenodes.hadoop-cluster</name> <value>nn1,nn2</value> </property> <!-- 각 namenode별 포트 설정--> <property> <name>dfs.namenode.rpc-address.hadoop-cluster.nn1</name> <value>test-nn0:58020</value> </property> <property> <name>dfs.namenode.rpc-address.hadoop-cluster.nn2</name> <value>test-nn1:58021</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster.nn1</name> <value>test-nn0:51070</value> </property> <property> <name>dfs.namenode.http-address.hadoop-cluster.nn2</name> <value>test-nn1:51071</value> </property> <!-- journalnode 설정 3개(nn에 포함된 jn1, jn2, j0)--> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://test-nn0:8485;test-nn1:8485;test-jn0:8485/hadoop-cluster</value> </property> <!-- 클러스터 동작을 위한 설정들--> <property> <name>dfs.client.failover.proxy.provider.hadoop-cluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>shell(/bin/true)</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> <!-- 웹 hdfs사용 설정--> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property>
-
yarn-site.xml 설정
hadoop-3.3.1/etc/hadoop/yarn-site.xml<property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <property> <name>yarn.resourcemanager.cluster-id</name> <value>rmcluster</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>test-nn0</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>test-nn1</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>test-nn0:8088</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>test-nn1:8088</value> </property> <property> <name>hadoop.zk.address</name> <value>test-nn0:2181,test-nn1:2181,test-jn0:2181</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> -
datanode 등록
workers에 datanode 기입
hadoop-3.3.1/etc/hadoop/workers
test-dn0
test-dn1
- docker 형태

명령어
zookeeper 초기화
hadoop-3.3.1/bin/hdfs zkfc -formatZK
journalnode 시작
hadoop-3.3.1/bin/hdfs --daemon start journalnode
namenode 초기화
hadoop-3.3.1/bin/hdfs namenode -format
namenode 실행(activate)
hadoop-3.3.1/bin/hdfs --daemon start namenode
second namenode 실행(standby)
standby 옵션을 설정후에 실행
hadoop-3.3.1/bin/hdfs namenode -bootstrapStandby
hadoop-3.3.1/bin/hdfs --daemon start namenode
datanode 실행
hadoop-3.3.1/bin/hdfs --daemon start datanode
전체 한번에 실행 및 종료
최초 standby 생성까지 진행 후에 명령어 사용
hadoop-3.3.1/sbin/start-dfs.sh
hadoop-3.3.1/sbin/stop-dfs.sh
safemode off
hadoop-3.3.1/bin/hadoop dfsadmin -safemode leave
파일 업로드 및 다운로드
다운로드
hadoop-3.3.1/bin/hdfs dfs -copyToLocal /file.text /home/hduser/tmp
업로드
hadoop-3.3.1/bin/hdfs dfs -copyFromLocal /home/hduser/file.text /
