Sqoop
Hive는 Hadoop 클러스터를 관계형 데이터베이스처럼 사용하지만 실제로 데이터베이스를 갖는 것은 아니었다. 그러나 만약 MySQL과 같은 진짜 관계형 데이터베이스를 갖고 있고 Hadoop 클러스터에 데이터를 불러오거나 내보내고 싶을 수도 있을 때 Sqoop을 활용하여 할 수 있다.
MYSQL
- 거대한 하드 드라이브에 연결되는 하나의 서버에 설치.
- 클러스터에 분산되지 않고 모든 것이 로컬에 있으므로 온라인 처리 프로세싱(OLTP)에 적절.
- 데이터베이스에서 빠르게 결과를 구해야 한다면 MySQL 같은 도구가 적절
Sqoop
- SQL과 Hadoop을 합친 이름.
- 대용량 데이터 세트를 Hadoop 클러스터에 가져오거나 내보내고 관리한다.
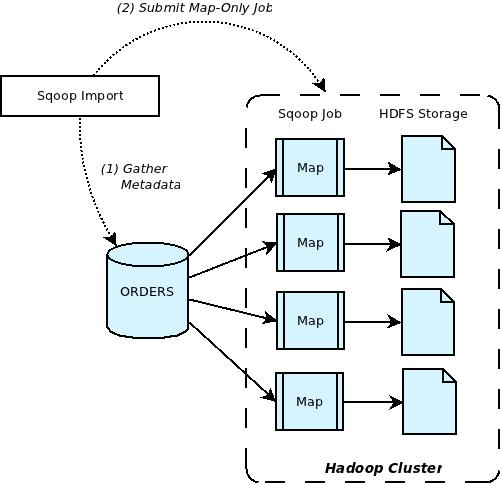
- MapReduce 작업을 통해 가능 함.- 데이터베이스를 Hadoop으로 내보내려고 하면 Sqoop은 내부적으로 여러 매퍼를 작동한다.(데이터를 한 곳에서 다른 곳으로 옮기는 일이니 매퍼만 사용)
- 매퍼들은 Hadoop 클러스터의 HDFS 클러스터와 소통하며 HDFS에 거대한 테이블 생성한다.
Apache OverView (https://blogs.apache.org/sqoop/entry/apache_sqoop_overview)
- Mapper에서 HDFS로 들어가는 과정은 병렬적으로 처리됨.
- 각 Mapper는 같은 호스트에 있는 HDFS의 블록들과 개별적으로 소통하고 있으니 병목현상이 일어나지 않음.
SQL to HDFS
sqoop import --connect jdbc:mysql://<hostname>/<databasename> -- driver com.mysql.jdbc.Driver --table <tablename>- sqoop은 명령창에서만 작동됨.
- {sqoop import}는 데이터를 클러스터로 가져온다는 뜻.- 'driver'를 명시해서 문제를 사전에 방지.
SQL to Hive
- 파일을 HDFS 클러스터로 옮기는 중간 단계를 건너 뛰고 Hive 테이블을 만드는 것.
sqoop import --connect jdbc:mysql://<hostname>/<databasename> -- driver com.mysql.jdbc.Driver --table <tablename> --hive-import- 끝에 '--hive-import'라는 매개 변수를 추가하기만 하면 된다.
Incremental import
- 데이터베이스를 불러올 때 순차 번호나 타임스탬프를 사용해 어디까지 가져왔는지 기억할 수 있음.
- '--check-column'이란 매개 변수는 타임스탬프나 순차 번호 등을 가진 열(column).
- '--last-value'는 열(column)의 값이 지정된 값보다 클 때만 데이터를 가져오겠다는 뜻
- 이걸 사용해 데이터베이스를 불러올 때 순차 번호나 타임스탬프를 사용해어디까지 가져왔는지 기억할 수 있다.
Hive to SQL
sqoop export --connect jdbc:mysql://<hostname>/<databasename> -- driver com.mysql.jdbc.Driver --table <tablename> --export-dir /<where>/<is>/<hive data> --input-fields-terminated-by '\0001'- 'import' 대신 {sqoop export}라고 입력하고 연결하려는 데이터베이스를 지정
- '-m 1'은 하나의 매퍼만 사용한다는 뜻.
- 데이터를 저장할 MySQL의 테이블을 지정한다 이때 Sqoop이 테이블을 따로 만들지 않도록 그 테이블이 존재하는지 확인해야 한다.
