
😢 서버가 내려갔나봐요
어느 때와 다름없이 EC2에서 서버 배포를 진행하는 중이었다.
EC2 타입은 서버비를 아끼기 위해 늘 사용하던 프리티어 t2.micro로 설정했고, 이 인스턴스에 도커를 활용해서 Spring 컨테이너를 올려 사용 중이었다. 여기에 인스턴스의 사용량이나 로그 등을 시각화해서 사용하려고 Portainer, Prometheus, Grafana 이미지를 가져와 추가적으로 컨테이너로 띄워졌다.
이제 Grafana 대시보드를 어떻게 꾸밀까를 신나게 고민하던 중 Slack에 한 알림이 날아오게 된다.

서버가 터졌다고 한다...
그냥 Spring, Nginx 정도의 컨테이너들만 다룰 때에는 버티던 t2.micro가 드디어 한계에 봉착했나보다. 저정도로 컨테이너들을 띄워두기도 했고 심지어 로깅 툴이라 주기적으로 작업이 들어가는데, 프리티어 수준으로 버틸 수 없을 것 같다고 판단했다.
하긴 프리티어니까 그럴 수 있지
라고 막연히 인스턴스 재시작으로 해결했던 지난 날들을 뒤로 하고 진짜 이유를 한번 찾아보자.
👀 CloudWatch를 통해 확인해보자
우선, Grafana까지 같은 인스턴스에 집어넣었기 때문에 당연하게도 Grafana도 사용할 수 없었고, EC2 인스턴스로부터 자유로운 CloudWatch를 열어 인스턴스의 상태를 확인해보았다.
이로 인해 모니터링, 로깅 툴들은 메인 인스턴스와 분리해야 한다는 교훈을 얻을 수 있었다.
귀찮다고 분리하지 않았는데, 꼭 직접 당해봐야 정신을 차린다.
서버가 다운된 시점을 보니 CPU 이용률이 100%로 갑자기 스파이크 되었다. 뭔가 작업이 엄청나게 많아져서 CPU가 이를 감당하기 힘들었다면 저렇게 특정 시점에 스파이크 되는 것이 아니라 이미 컨테이너를 올려둔 시점부터 이용률이 올라갔어야 했을텐데, 컨테이너들을 올리는 시점으로부터 시간이 지나고 갑자기 100%를 찍어버리는 현상은 다른 이유가 있는 것 같다.
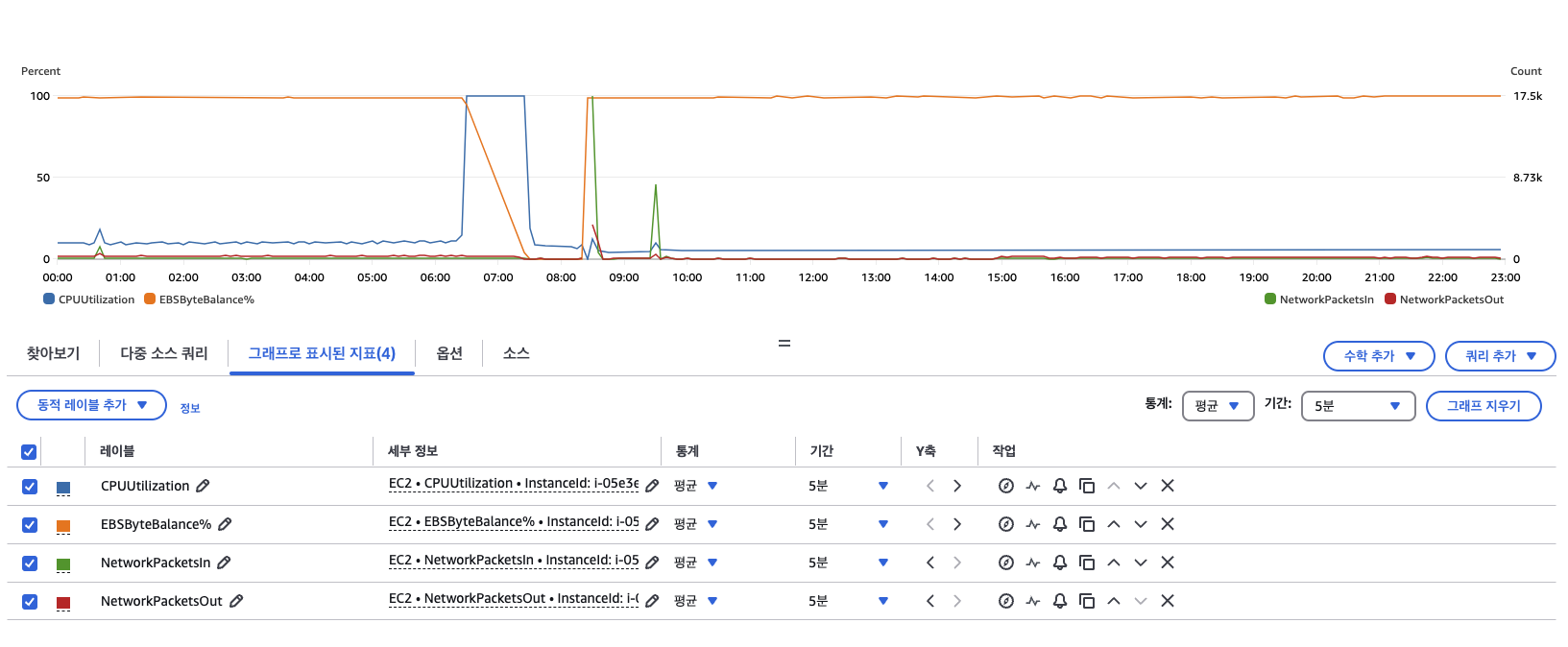
CPU Utilization이 100%에 도달한 시점에서의 몇 가지 지표들을 확인해보았다.
- EBS ReadOps
- EBS WriteOps
- NetworkPacketsIn
- NetworkPacketsOut
여기서는 포함하지 않았지만, 버스터블 인스턴스 기능을 제공하는 t시리즈를 사용했기 때문에 CPUCredit도 CPU Utilization이 100%를 찍은 시점에서 고갈되었다고 나온다.
Network 관련 지표들에서도 유효한 움직임이 보이지 않으므로 외부 요청 증가, 내부 응답 증가 등과 같은 네트워크 관련한 문제는 아닌 것 같다.
그러나, EBS ReadOps는 CPU 이용률이 올라가는 시점에서 유의미한 변화를 나타낸다.
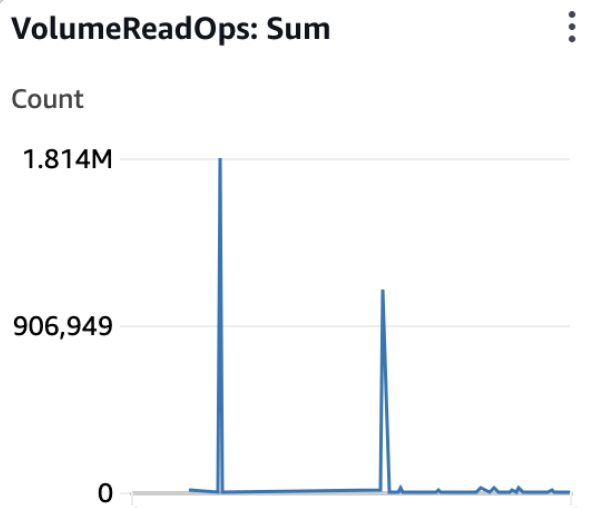 | 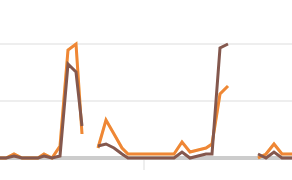 |
|---|
심지어 거의 똑같은 움직임을 보여준다. 이런 결과로 우린 이런 결과를 도출해낼 수 있다.
EBS, 즉 디스크에서 데이터를 읽어오는 작업으로 인해 CPU의 이용률이 높아지게 되었고, 결국 인스턴스가 중단되는 일이 벌어지고 만 것이다.
🔥 왜 이런 일이 일어난걸까?
디스크에서 데이터를 읽어오는 과정을 생각해보자.
일반적으로 애플리케이션은 RAM에서 데이터를 읽다가, 필요한 데이터가 메모리에 없을 경우 디스크에 있는 데이터를 불러온다.
이때 운영체제는 물리적 메모리가 부족하면 사용하지 않는 메모리 페이지를 스왑 영역(디스크)에 내보내고, 필요할 때 다시 불러오는(= Swap In) 과정을 거친다.
여기서 EBS ReadOps가 증가했다는 것은, 인스턴스가 메모리 부족으로 인해 스왑 영역에서 자주 데이터를 읽어오는 작업이 많아졌음을 의미한다.
특히 우리의 t2.micro와 같이 메모리와 CPU 자원이 제한된 인스턴스는, 이런 상황에서 Swap In 작업이 빈번하게 발생하여 디스크 I/O 부하가 커지고, 그 결과 CPU 사용률이 급증해 서버가 중단되는 현상이 발생할 수 있다.
이걸 해결하기 위해서는?
메모리 부족 문제를 해결하는 방법은 두 가지가 있다.
- 인스턴스의 스펙을 Scale Up하여 더 많은 메모리와 CPU를 제공하는 것이지만, 이는 추가 비용이 발생할 수 있다.
가장 단순하고 직관적이지만 아무래도 비용이 들어간다는 점에서 다른 대안을 찾고 싶다.
- Swap 메모리를 설정하여 물리적 메모리가 부족할 때 디스크의 일부를 임시 메모리로 활용하는 방법이다.
우린 이 방식을 사용해보자.
Swap 메모리는 디스크 공간을 일종의 보조 메모리로 활용하는 기술이다. 즉, 디스크의 일부 공간을 메모리처럼 활용하는 방식인데, 진짜 RAM 같은 메모리가 아니라 물리적으로는 디스크이기 때문에 아무래도 속도가 저하될 수 있다는 단점이 있다.
그래서 Swap 메모리의 크기와 설정이 적절하지 않으면 오히려 디스크 I/O 부하가 가중되고 속도가 느려질 수 있다.
📌 적절한 Swap 공간의 크기는?
Red Hat Documentation - 권장되는 시스템 스왑 공간
| 시스템의 RAM 크기 | 권장 스왑 공간 | 최대 절전 모드를 허용하는 경우 권장 스왑 공간 |
|---|---|---|
| ≤ 2GB (✓ 2GB) | RAM의 2배 | RAM의 3배 |
| > 2GB – 8GB | RAM의 양과 같음 | RAM의 2배 |
| > 8GB – 64GB | 최소 4GB | RAM의 1.5배 |
| > 64GB | 최소 4GB | 최대 절전 모드는 권장되지 않음 |
Red Hat에서 제공하는 문서를 확인해보니 다음과 같은 권장 스왑 공간 표를 제공하고 있었다. 우리의 t2.micro는 1GB라는 RAM 크기를 가지니 Swap 공간은 2GB로 설정하면 될 것이다.
✅ 이제 설정해보자
-
sudo dd if=/dev/zero of=/swapfile bs=128M count=16
스왑 파일을 생성해준다. 이 명령어는 128MB를 16개 만드는 것으로 2GB를 나타낸다. 1MB로 2048개를 만들 수도 있지만, I/O 작업이 많아지게 될 것이므로 큰 단위로 적게 생성해주었다. 그리고 너무 블록 단위로 설정할 시 성능에 영향을 줄 수 있기 때문에 적당한 크기인 128MB로 설정해주었다. -
$ sudo chmod 600 /swapfile
이 파일에 읽기, 쓰기 권한을 부여해주었다. -
$ sudo mkswap /swapfile
스왑 파일을 이제 스왑 영역으로 초기화해주고, -
$ sudo swapon /swapfile
스왑 공간에 새로 만든 스왑 파일을 추가하여 스왑 파일을 활성화했다. -
sudo swapon --showorfree -h
이제 결과를 확인해보자.
NAME TYPE SIZE USED PRIO
/swapfile file 2G 102.8M -2 -
echo '/swapfile swap swap defaults 0 0' | sudo tee -a /etc/fstab
이제는 재부팅 시 스왑 파일이 유지되도록 /etc/fstab에 항목을 추가해보자.
이러면 설정이 끝난다.
결론

EC2를 사용할 때도 여러 고려사항이 필요하다라는 것을 느낄 수 있었고, 나름의 장애 대응을 경험했다보니 Grafana, Prometheus는 다른 서버에서 띄우는 것이 좋겠다 라는 점과, CloudWatch를 다루는 방법 등을 알아갈 수 있었던 경험이었다.
또 다른 관점으로 이 결과를 바라보면 여러 의문점이 생길 수도 있다.
CPU 이용률이 100%가 되면 왜 인스턴스가 죽을까? 그냥 CPU를 Max로 사용하는 건데, 왜 인스턴스가 중단되는 걸까?
CPU 이용률은 왜 점진적으로 증가한 게 아니라 갑자기 폭증하는 형태로 나왔을까?
Appendix
초반에는 외부 네트워크에서 공격하여 CPU 이용률에 영향을 끼친 줄 알고 CloudWatch로 서버로 들어오는 요청들을 확인해보았는데, 외부 네트워크 문제로 CPU 이용률이 증가하지 않았다는 것은 이제 알았지만 이 과정에서 정체를 알 수 없는 여러 요청들이 들어오는 것을 확인했다.

어떤 요청들은 이렇게 젠틀하게 자신의 정체와 목적까지 설명해주는 반면,
어떤 요청들은 /src/main/resources/application.yml처럼 Spring에서의 크리덴셜 정보가 들어있는 경로로 엔드포인트로 설정해서 요청을 보내고 실패하는 로그도 확인할 수 있었다.
이런 요청들의 IP 주소들을 확인해보니 파리, 뉴욕, 러시아 등 다른 나라에서의 요청이 들어오는 경우가 많았다. 이런 경우는 어떻게 막아야 하고 이 요청들은 무슨 요청이었을까?
