
CQRS란?
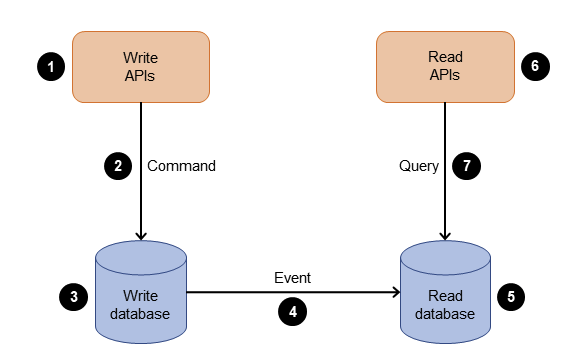
MSA에서 데이터 지속성을 지원하기 위한 패턴 중 하나이다. 즉, ACID 중 Durability를 지원할 수 있는 패턴이라는 의미가 된다. 이 CQRS 패턴은 CUD 작업과 R 작업을 분리하여 사용하는 패턴이다.
사용 이유?
대부분의 정책이나 제약은 데이터 변경(C, U, D)에서 처리되고, 데이터 조회(R) 작업은 단순 데이터 조회인데, 동일 Domain Model로 처리하면 필요하지 않은 Domain 속성들로 인해 복잡도가 증가해버린다.
이 문제를 해결하기 위해서 명령을 처리하는 책임과 조회를 처리하는 책임을 분리하는 것이 CQRS이다.
구현 종류
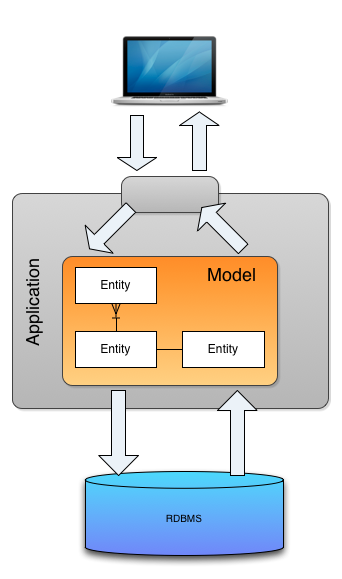
전통적인 CRUD 시스템
Simple CQRS 아키텍처
 |  |
|---|
이런 Simple CQRS 패턴은 다음과 같은 상황에 사용을 고려해볼 수 있다.
- ACID를 제공하는 트랜잭션을 통해 보다 안정적으로 일관성을 보장하고 싶을 때
- Data 계층의 구조를 갈아엎고 싶지 않을 때
- 하나의 DB만 사용하여 유지보수 및 운용을 가져가고 싶을 때
- 여러 마이크로 서비스들 간의 관계 등으로 인하여 DB의 개수를 늘리기 어려울 때
아무래도 DB를 하나만 사용하기 때문에 데이터의 일관성을 더욱 보장할 수 있고 관리하기 용이하다는 장점이 있지만, Application 단계에서 책임을 분리한 것이기 때문에 DB로 인한 성능 개선을 기대하긴 어렵다.
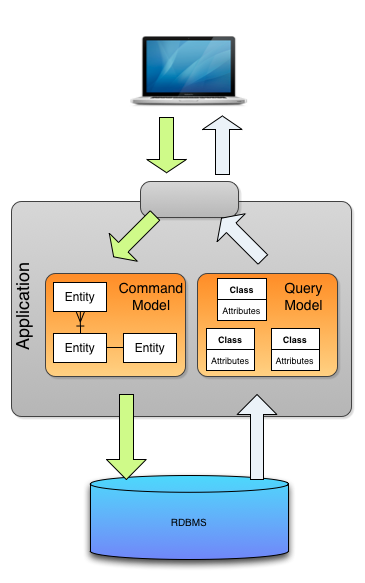
CQRS에서 Command 모델의 Entity랑 Query 모델의 Class는 뭐가 다를까?
목적과 책임
Command 모델의 Entity: 데이터의 생성, 수정, 삭제와 같은 상태 변경 작업을 처리
Query 모델의 Class: 데이터 조회 및 읽기 작업에 최적화구조와 설계
Command 모델의 Entity: 도메인 로직과 비즈니스 규칙을 포함하며, 객체 지향적 설계 지향
Query 모델의 Class: 주로 데이터 전송 객체(DTO) 형태로, 조회에 필요한 데이터만을 포함데이터베이스 상호작용
Command 모델의 Entity: 주로 ORM(Object-Relational Mapping)을 사용하여 데이터베이스와 상호작용
Query 모델의 Class: SQL 쿼리나 NoSQL 데이터베이스와 직접 상호작용성능 최적화
Command 모델의 Entity: 데이터 일관성과 트랜잭션 관리에 집중
Query 모델의 Class: 빠른 데이터 검색과 대량 데이터 처리에 최적화확장성
Command 모델의 Entity: 비즈니스 로직의 변경에 따라 확장
Query 모델의 Class: 조회 요구사항에 따라 독립적으로 확장 가능
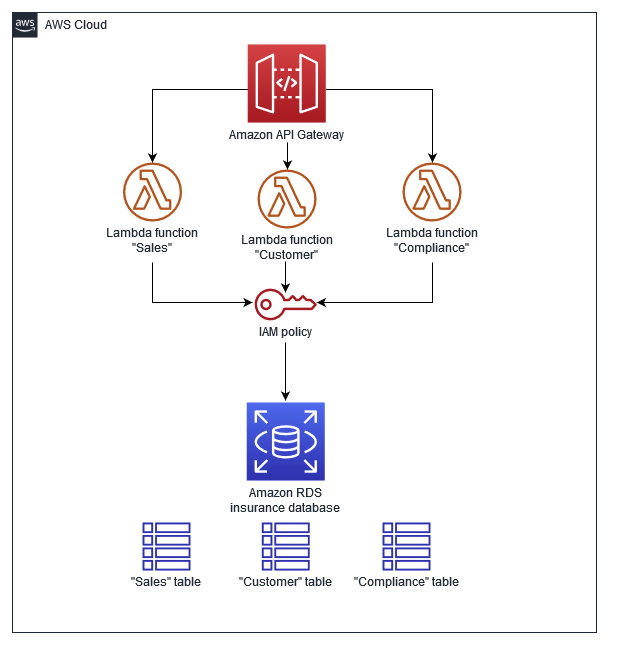
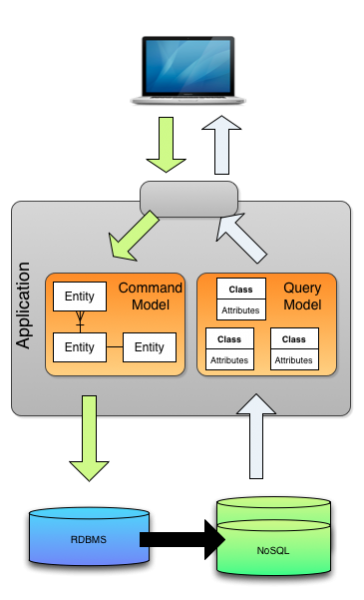
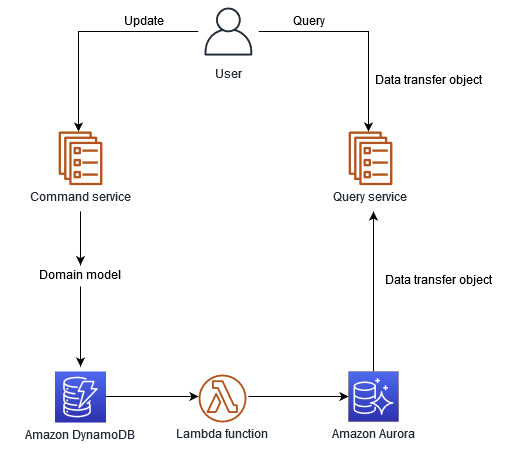
CQRS with Separated Persistance mechanisms
 |  |
|---|
이 경우는 모델에 따라 DB를 분리하고 별도의 Broker를 통해 이 둘 간의 Data를 동기화하는 방식이다. 여기서의 Broker가 DB에서의 일관성을 결정하는 핵심 요소가 되기 때문에 가용성과 신뢰도가 보장되어야 한다.
AWS 공식문서에서는 Lambda와 같은 서버리스 환경을 이용하여 이 브로커를 구성하는 모습도 보여주었다.
또한, 이런 polygot 구조에서는, 즉 다수의 DB를 혼용하여 사용하는 구조에서는 DB를 각 모델의 특성과 서비스 요구사항에 맞게 선택할 수 있다.
DB 선택
CQRS에서 Polyglot 구조를 사용할 때, Command 모델과 Query 모델에 적합한 데이터베이스를 선택하는 것이 중요하다.
RDB의 장점
- 트랜잭션 지원: ACID 속성을 보장하여 데이터 일관성을 유지
- 데이터 무결성: 스키마 제약 조건을 통해 데이터 정확성을 보장
- 복잡한 관계 처리: 테이블 간 관계를 효과적으로 관리 가능
NoSQL의 장점
- 높은 읽기 성능: 대량의 데이터를 빠르게 조회 가능
- 스키마 유연성: 다양한 형태의 데이터를 저장하고 조회하기 용이
- 수평적 확장성: 대규모 데이터 처리에 적합
앞선 예시들에서도 Model마다 매핑된 DB가 모두 달랐던 것처럼 어느 한 Model에 특정 DB를 선택해야 한다는 가이드가 존재하는 것이 아니다.
각 서비스의 특징과 요구사항을 파악하고 DB를 관리자의 의도에 맞게 선택하는 것이 중요하다.
예를 들어, Command의 작업의 빈도가 Query에 비해 압도적으로 많이 발생한다면 WRITE 연산 비용이 적게 드는 NoSQL을 Command 모델에 사용하여 쓰기 성능을 높이는 방향을 고려해볼 수 있다.
반대로 Command 시 데이터의 일관성을 보다 강하게 보장하고 싶다면 Command 모델에 RDB를 사용하여 데이터를 안정적으로 보장할 수 있도록 설계할 수도 있다.
CQRS의 이점
독립적인 크기 조정
CQRS를 통해 읽기 및 쓰기 작업 중 원하는 작업의 책임을 관리하는 리소스나 관리 사양을 높일 수 있다. 예를 들어, 읽기 작업이 쓰기 작업보다 훨씬 많이 발생한다면 읽기 작업에 관련된 DB 스펙을 높이거나 Query Model을 담당하는 서버, 코드 등을 집중 관리할 수 있다.
최적화된 데이터 스키마
읽기 쪽에서는 쿼리에 최적화된 스키마를 사용하고 쓰기에서는 업데이트에 최적화된 스키마를 사용하기에 각각의 용도에 맞는 설계를 주도적으로 가져갈 수 있다.
유연한 모델 생성
대부분의 복잡한 비즈니스 로직은 Command Model로 이동시키고 Query Model은 상대적으로 간단하게 정리하여 유연하고 유지 가능한 모델을 만들 수 있다.
단순한 쿼리
Query DB에서 구체화된 뷰를 저장하여 쿼리 시 복잡한 조인을 방지할 수 있다.
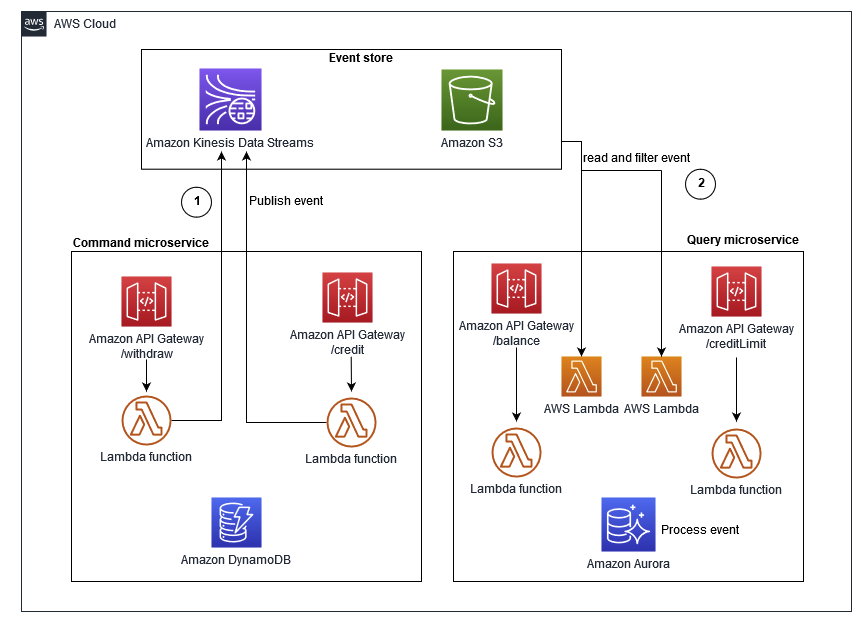
Event Sourcing Pattern
 |  |
|---|
CQRS는 Event Sourcing Pattern과 결합하면 더욱 효과를 볼 수 있다.
Event Sourcing Pattern이란 여기서는 DB의 변경된 상태를 이벤트의 형태로 브로커에 게시하여 Consumer들이 이벤트를 사용하는 형태를 말한다.
이 패턴을 사용하면 DB에 들어온 데이터를 이벤트의 형태로 게시하면서 "데이터"가 아닌 "상태 변화"를 따로 기록할 수 있게 된다. 이로 인해 시스템 복구 시 이벤트 로그를 재생하여 과거 상태를 복원할 수 있게 된다.
CQRS에서는 DB를 여러 개 사용하는 CQRS with Separated Persistance mechanisms의 사례에서 두 DB의 데이터를 일치시키기 위해 사용할 수 있다.
Command DB에서 데이터가 들어오면 데이터가 들어왔다는 Event를 Broker에 발행한다. 이때, Broker를 구독하고 있던 Query DB가 이 이벤트를 보고 자신의 DB에 해당 데이터를 업데이트 시키는 방식이다.
아무래도 DB가 여러 개 존재한다면 이 DB들간의 동기화가 가장 중요한 요소로 이루어질 수 있기 때문에 Event Sourcing Pattern과 함께 결합하면 DB 간 데이터 일관성을 보장할 수 있다. 특히 이벤트 로그가 따로 남아 시스템 복구가 가능하다는 점에서 금융 시스템에서는 트랜잭션 이력 관리방식으로 많이 사용한다고 한다.
또한, Event Sourcing Pattern은 하나의 브로커를 여러 리소스들이 구독하고 있는 상황에서 Publisher가 이벤트를 Publishing만 하면 알아서 돌아가는 구조이기 때문에 각 서비스나 리소스들 간의 결합도를 느슨하게 하는 것에 효과적이다.
따라서, DB를 여러 개 두거나 Lambda나 다른 서버로 이벤트를 보내는 등의 작업들을 쉽게 붙일 수 있어 확장성도 뛰어나진다.
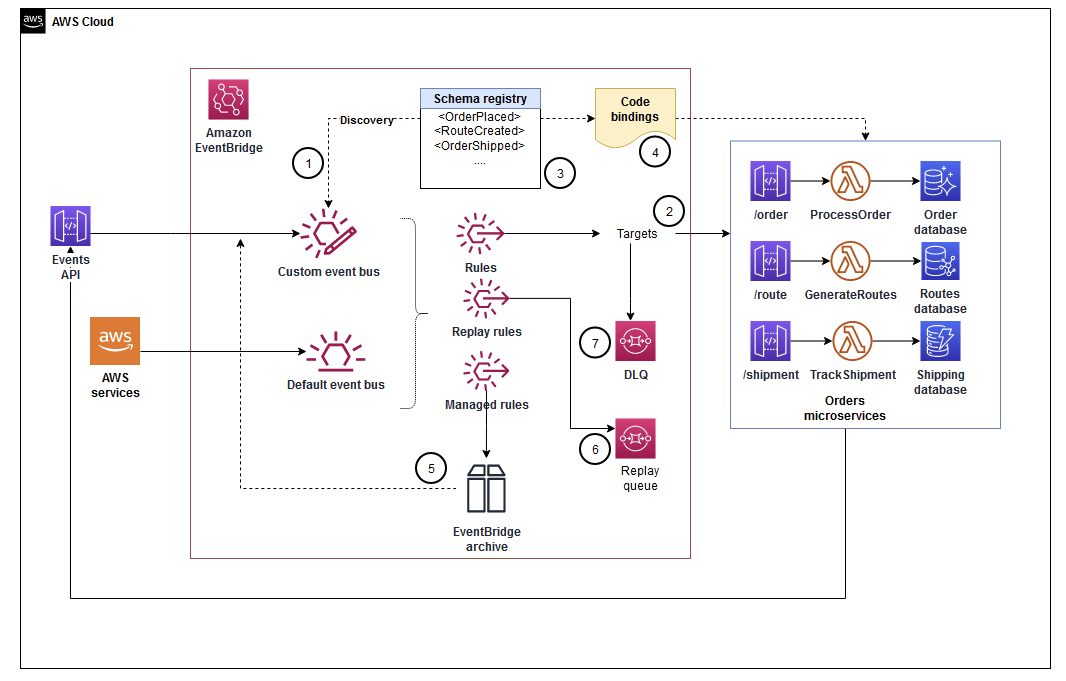
SAGA Pattern
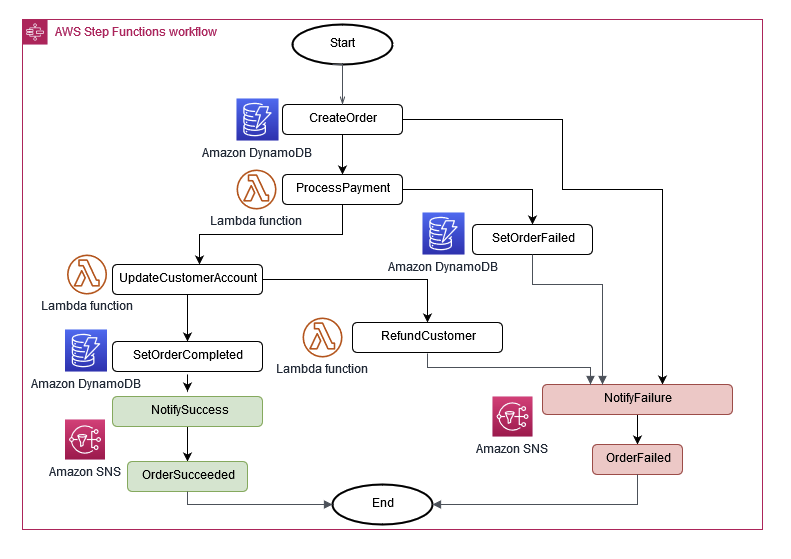
SAGA 패턴은 앞선 Event Sourcing Pattern을 조금 더 디벨롭한 패턴이라고 볼 수 있다. Event 기반 환경을 구축하고 사용할 때는 보통 MSA와 같이 분산 환경에 도입하는 경우가 많은데, 이런 환경에서는 데이터의 정합성을 유지하기가 어렵다.
Event를 활용하여 Broker를 두고 운용할 때는 시스템 구조가 복잡해지거나 Event 트랜잭션에 실패했을 경우에 대한 처리가 관리되지 않을 수 있기 때문이다.
특히, MSA 환경에서는 여러 마이크로 서비스들 간의 트랜잭션이 각기 존재하기 때문에 데이터 일관성을 유지하기가 쉽지 않을 수 있다.
SAGA 패턴은 이를 AWS Step Functions를 통해 하나의 Workflow로 시각화하여 관리하고 각각에 대한 에러 처리나 재실행도 보장할 수 있도록 설계하는 패턴이다.
위의 그림을 보면 각 트랜잭션들은 모두 이벤트의 형태로 Publishing 되고 이 트랜잭션 이벤트의 결과에 따라 다음 트랜잭션이 실행된다.
또한, 각 이벤트의 결과에 따라 성공, 실패 경우를 핸들링 할 수 있어지기 때문에 workflow가 실패했을 때 전체 workflow 혹은 특정 작업이 재실행되거나 다시 롤백시키는 등의 처리가 가능해진다.
SAGA 패턴에 등장하는 주요 개념은 Choreography와 Orchestration이 있다. 이 개념들은 EDA를 다룬 포스트에서 더 확인해보자.
➡ Amazon EventBridge를 활용한 이벤트 기반 아키텍처 설계 - 5hseok
DB 선택 관련 추가 정보
Reference : Relational DB VS NoSQL DB
Reference : 상세 설명
Reference : DB 선택 기준
