이 포스트는 EventBridge와 이벤트 관련 아키텍처를 공부하던 중 AWS re:Invent 2021에서 나온 세미나를 요약하고 정리한 내용이 담겨있다.
AWS re:Invent 2021 - Building next-gen applications with event-driven architectures
📌 Event-driven architectures
이벤트 관련 아키텍처는 시스템에서 자원 간의 결합도를 낮추기 위해 고민하던 중 탄생하게 되었다. 결국, 이 이벤트를 사용하는 방식들은 모두 시스템 자원들의 결합도를 낮추기 위함이라는 사실을 알아야 한다.
📌 Event-driven architecture가 고안된 과정
Synchronous model

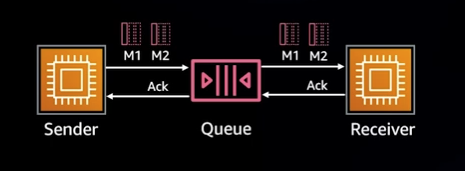
가장 단순한 구조의 Request-Response model이다.
먼저 동기적으로 요청과 응답이 이루어지는 경우, 저지연성의 장점을 가져갈 수 있고 구조가 단순하여 관리자가 인지하기 편할 뿐만 아니라 실패했을 때 바로 대처할 수 있다는 장점이 있다.

그러나, 다수의 Sender가 존재할 경우 Receiver가 견디지 못할 만큼의 요청이 들어오게 된다면 Receiver가 죽게 되고, 다량의 트래픽을 인한 병목현상도 발생할 수 있기 때문에 대규모 분산 시스템의 경우에는 복구가 매우 어려울 수 있다는 문제점이 있다.
Asynchronous model
이를 해결하기 위해 비동기적 통신의 Queue를 사용한 P2P 모델이 등장하게 되었다.

이 방식에서는 Sender는 대기열인 큐에 메시지를 보내두면 큐에서는 이 메시지를 확인하고 확인이 된다면, Receiver가 별도로 큐에 접근하여 메시지를 꺼내가는 방식이다. 이때, 큐에서 Receiver가 메시지를 반복해서 처리하지 못하거나 하는 등의 상황으로 인해 메시지가 사라질 것을 방지하여 DLQ 등의 별개의 큐에 따로 메시지를 담아 정상적으로 처리되지 못한 메시지들을 보관한다.
이 방식의 장점은 Send와 Receive가 동시에 일어나지 않아도 되며, Receiver에 장애가 생겨도 Sender는 직접적인 영향을 받지 않고 아무 문제 없이 계속해서 메시지를 큐에 보낼 수 있다.
또한, 이렇게 중간에 큐를 사용하게 되면 Sender가 많아져도 Queue로 인해 트래픽이 버퍼링되기 때문에 Receiver가 메시지를 소모하는 속도를 편하게 선택할 수 있다는 장점이 있다.
이렇게 되면 결국 복원력 있는 아키텍처를 만들 수 있게 되는 것이다.
다만, 이 방식도 문제가 있다.

한 Receiver가 다운되면 큐에 메시지가 계속 생기게 되고 이로 인한 Backlog가 생길 수 있다는 점과 하나의 큐에 여러 사용자가 요청을 보내고 있을 때, 특정 사용자가 너무 많은 메시지를 보내면 다른 사용자의 메시지가 지연될 수 있다는 문제점이 생기게 된다.
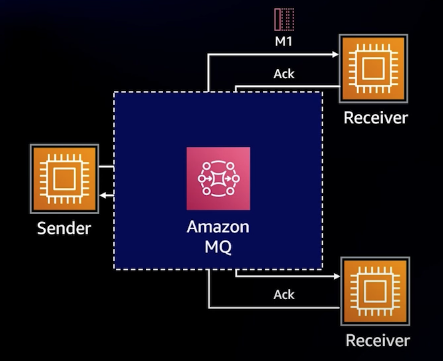
이를 해결하기 위해 AWS는 다양한 메시징 솔루션을 제공하며 이는 SQS나 Amazon MQ 등이 있다.
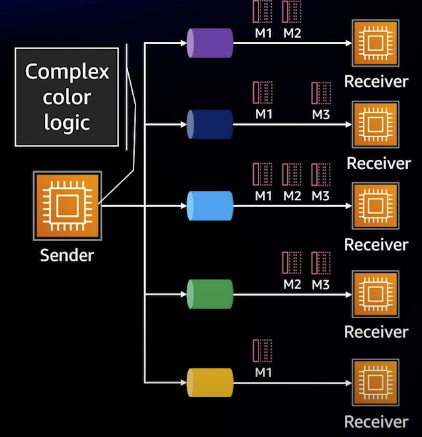
또한, 라우팅적인 관점에서 바라봤을 때, 여러 큐가 존재하는 상황이라면 Sender는 어느 메시지를 어느 큐에 넣어야 할 지에 대한 로직이 존재해야 하고 이는 곧 결합성이 강해진다는 것을 의미한다.
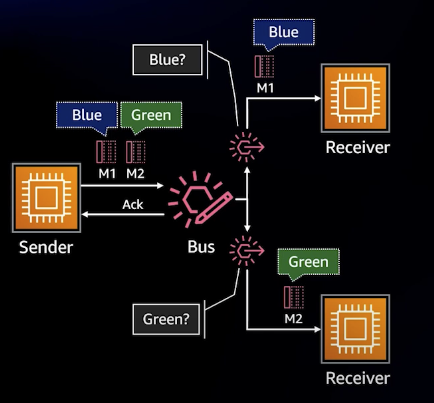
이럴 때, 중앙에 Bus System을 도입하여 이벤트와 함께 사용하면 결합도를 낮추면서도 Sender와 Receiver가 효과적으로 통신할 수 있다.
그래서, 이벤트 브릿지는 복잡한 라우팅 요구 사항이 많고 Subscriber에게 중요한 메시지가 무엇인지 설명하고 다른 중개자나 프록시 없이 AWS 서비스를 직접 타겟팅할 수 있는 Rule이 필요한 경우에 사용하기 매우 적합하다.
EventBridge 자세히 알아보기
Event 자세히 알아보기
일단 Event란 무엇일까? Event는 단순히 시스템 상태가 변경되었다는 신호이다. 우리 일상 생활에서 생각해본다면 빨간 신호가 켜져있던 신호등이 초록색 신호로 바뀌는 것도 Event라고 할 수 있는 것이다.
우리가 이 신호등의 신호가 바뀌는 Event를 보고 길을 건너갈 것인가 말 것인가를 선택하는 것처럼, 시스템의 상태가 변하는 Event를 감지하여 이 Event에 반응할 것인지를 결정하고 어떻게 행동할 것인지를 결정하는 과정이 될 것이다.
이때, 이벤트는 감지하는 시점보다 분명 과거에 발생했다는 것을 인지하는 것이 중요하다. 그래서 이벤트의 이름은 이벤트의 상태와 상태의 변화를 나타내는 과거형 동사를 사용하여 주로 네이밍한다.
여기서의 네이밍은 관례일 뿐 필수는 아니다. 또한, 이벤트가 과거에 발생했다는 사실을 아는 것이 중요한 이유는 이벤트는 과거에 일어난 사실이기 때문에 우리가 바꿀 수 없다는 사실을 인지해야 하기 때문이다.
JSON Event

우선 Event는 다음과 같이 JSON으로 정의할 수 있다.
이 JSON은 두 가지 필드로 나뉘게 된다.
- envelope field : source와 detail-type이 존재한다. 이 필드들은 이벤트의 스키마를 나타낸다고 생각하면 된다.
- detail field : 이벤트의 세부 정보가 담긴 필드로 실제 데이터가 들어간다. 여기서는 metadata와 data를 포함하고 있는데, metadata는 사용자 정의 envelope field, data는 사용자 정의 이벤트 데이터 무엇이든 포함할 수 있다.
여기서 이벤트를 정의할 때는 특정한 규칙이 있는게 아니라서 진짜 아무거나 정의할 수 있다.
또한, Rule 역시 JSON으로 표현이 가능하다. 여기서는 찾고 있는 값들을 담은 배열로 이벤트를 잡는 예시 그림이다. 물론 이 뿐만 아니라 이벤트 거부, 문자열 prefix 매칭, 숫자 범위 매칭, 값의 여부 매칭 등등 다양한 Rule 행동들을 쉽게 정의할 수 있다.
그런데, 이 이벤트를 정의할 때 주의해야 할 점이 있다.
이벤트에 넣기로 한 데이터는 결국 생산자와 소비자 간의 또 다른 형태의 결합이 될 수도 있다. 이벤트에 생산자의 상태에 대한 정보를 기입하고, 소비자는 rule에서 생산자의 상태 정보 변화를 입력해야 하기 때문이다.
그래서 결국 이벤트에 들어가는 데이터가 너무 많아지면 생산자와 소비자 사이에 의미적 결합이 더욱 강화되게 된다는 문제가 생긴다.
극단적인 예시를 들어보겠다.
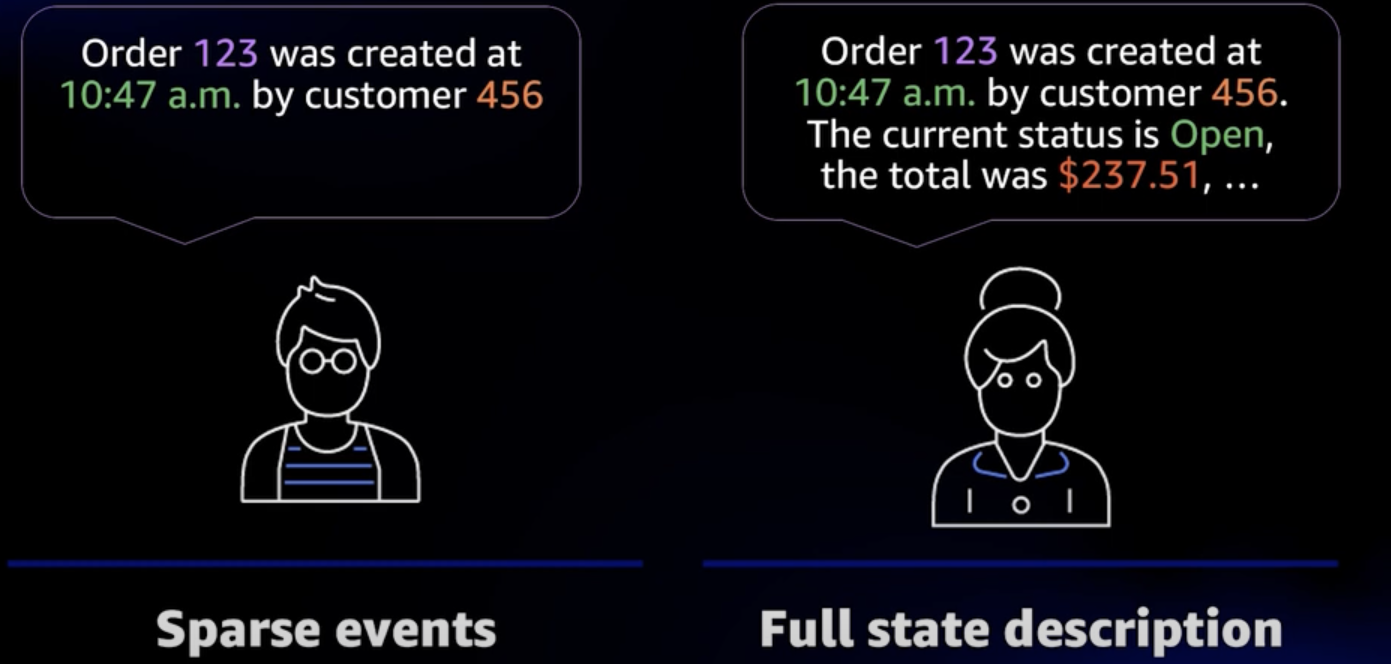
Sparse events처럼 변경된 상태의 세부 정보만 적는 것과 Full State description처럼 모든 상태를 적는 경우가 있을 수 있다.
먼저, Sparse Events처럼 이벤트에 포함된 정보가 부족한 경우, 이벤트를 구독하고 있는 구독자들은 이 ID스러운 정보들만으로는 원하는 작업을 수행할 수 없으니, 추가적인 정보를 얻기 위해 DB나 API로 추가적인 요청을 또 보내게 된다.
이런 현상이 대규모로 발생하면 DB나 서버에 과부하가 걸리게 되어 Reverse DDoS가 걸리게 되는 문제가 생길 수 있다.
그렇다고, Full State description처럼 이벤트에 데이터를 많이 넣는 것도 그다지 좋은 방법은 아니다.
한번 이벤트에 데이터를 넣으면 구독자들 중에서 이 데이터를 사용 중일 수 있으니, 나중에 이벤트에서 다시 이벤트를 삭제하기가 어려울 수 있다. 즉, 이전 버전과의 호환성을 유지해야 한다는 점에서 한번 넣은 데이터는 추후에 다시 삭제하기가 쉽지 않기 때문이다.
또한, 초반에는 단일 DB나 단일 MS에서 데이터가 나오다가 시간이 흘러 서비스가 확장되어 다중 DB나 다중 MSA가 도입된다면 이벤트를 위한 데이터들을 조인하고 계산하는 등에서 나오는 Cost도 점차 시간이 지날수록 무시하지 못하는 수준에 도달하게 될 것이라는 문제도 고려해야 한다.
그러면 이벤트에 들어가는 데이터는 어느 정도로 정해야 할까?
처음에는 Sparse하게 이벤트를 발행하다가 구독자들이 추가로 요청하는 공통적인 요구 데이터 속성을 분석하고, 이 속성은 정말 이벤트에 포함되어야 하는지, 추후에 리팩토링을 거쳤을 때의 영향은 어떠한 지 등등을 고려하여 점진적으로 필요한 데이터들을 신중하게 추가해나가는 것이 좋다.
Choreograph events between domains using subscriptions
갑자기 새로운 용어가 나왔다. 이 Choreography는 뭘까?
Choreography란 서로 다른 비즈니스 도메인들 간에 Event를 이용하여 통신하는 방식을 말한다. 즉, 각 도메인은 독립적으로 동작되고 특정 이벤트가 발생했을 때 다른 도메인이 이 이벤트가 필요하면 이를 구독하여 처리하는 방식이다.
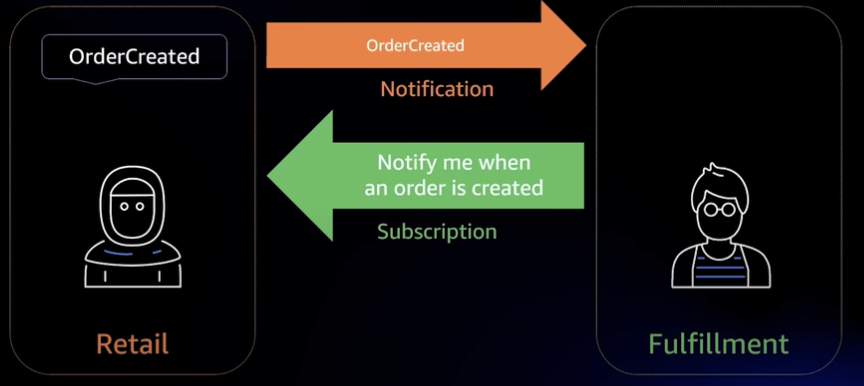
예를 들어, Retail 도메인과 Fulfilment(물류) 도메인이 있다고 할 때, 원래는 Retail 도메인에서 Fulfilment 도메인으로 API 요청을 보내는 방식이었다. 그러나, 이렇게 되면 Fulfilment 도메인이 변경되면 Retail도 변경되어야 한다는 문제가 생긴다. (새로운 물류 업체를 추가하면 Retail 코드도 수정되어야 한다.)
이를 해결하기 위해 Choreography를 도입하면 리테일 도메인에서 주문이 생성될 때 이벤트를 발생시킨다. 그러면 물류 도메인에서는 이 이벤트를 구독하여 배송을 처리하는 방식이다.
이렇게 Choreography하게 처리하면 느슨한 결합을 유지할 수 있다. 이벤트를 발행하는 도메인은 구독하는 도메인이 이 이벤트를 어떻게 처리할 것인지에 대해 전혀 신경쓰지 않아도 되고 알 필요도 없어진다. 이러면 Publisher는 이벤트만 보내면 끝이기 때문에 시스템 간의 결합도를 낮출 수 있고, 새로운 Subscriber가 추가되거나 제거되어도 기존 시스템에는 전혀 지장이 가지 않는다.
Publisher는 하위 호환성(Backwards Compatibility)를 유지하여 이벤트 구조가 바뀌어도 기존 Subscriber들이 정상적으로 작동할 수 있게 해야하고, 이벤트에 필요한 정보를 담아 중앙 이벤트 버스(Event Bus, Kafka, RabbitMQ 등)에 게시하는 것까지를 책임지면 된다.
이때, Publisher는 이 이벤트가 어떤 식으로 처리해야 한다는 기대를 가지는 순간 시스템이 강하게 결합되는 것이기 때문에 주의해야 한다.
Event Duplication
Choregraphy를 사용해서 MSA나 여러 비즈니스 도메인 간의 이벤트를 주고받는 환경을 구축할 수 있었다. 그러나, 이런 환경에서는 피할 수 없는 제한이 생기게 된다. 바로 CAP 이론의 제한이 생긴다는 것이다.
CAP?
일관성(Consistency)과 가용성(Availability)는 동시에 충족시킬 수 없기에 둘 중 하나를 택해야 함.
대부분의 분산 시스템에서는 가용성을 높이기 위해 이벤트를 중복으로 전송하는 경우가 많다.
네트워크 오류 혹은 분산 환경에서는 이벤트가 한번만 정확하게 전달된다는 보장이 없기에 많은 시스템에서는 이벤트가 손실되는 위험을 줄이기 위해 이벤트를 여러 번 중복해서 전송하는 방식을 택하곤 한다.
하지만, 동일한 이벤트가 여러 번 처리되면 중복 데이터 생성, 잘못된 상태 변경 등의 부작용들이 발생할 수 있다.
이를 해결하기 위한 것이 바로 Idempotency(멱등성)이다.
Idempotency(멱등성)
멱등성이란 같은 이벤트를 여러 번 처리하더라도, 최종 결과가 항상 동일하게 유지되는 성질을 의미한다. 즉, 중복된 이벤트를 여러 개 받았을 때 부작용 없이 처리할 수 있어야 한다는 것이다.
예를 들어, 동일한 송금 요청이 두 번 발생하더라도 실제 돈은 한 번만 빠져나가야 한다.
이를 보장하기 위해 Idempotency Key를 사용해서 해결할 수 있다. 이벤트마다 idempotency key를 추가하여 시스템이 중복된 이벤트를 인식할 수 있게 하는 것이다. 키를 생성할 때는 API 요청의 고유한 속성들(userid, orderid, timestamp 등)을 이용하여 해시값을 생성하거나 UUID기반 고유 식별자를 사용할 수 있다.
이 키는 Client에서 계산해서 이벤트에 포함시켜야 한다. Subscriber가 이벤트를 처리할 때, 이전에 처리한 키인지를 확인하고 이미 처리된 경우 이전의 결과를 재사용하는 것이다.
이런 처리는 Lambda와 같이 서버리스 형태를 사용하면 더 쉽게 할 수 있다. Event De-duplication 전략의 예시 플로우는 다음과 같다.
- Redis, DynamoDB 등 외부 DB에 중복 이벤트를 필터링하기 위해 idempotency key를 저장하고, TTL값을 적절히 설정함.
- 첫 번째 요청이 들어왔을 때의 결과를 저장소에 기록함.
- 이후 동일한 키로 요청이 다시 들어오면 기존 결과를 반환하여 재처리를 방지한다.
이러한 패턴으로 API Gateway, Message Queue 등과 함께 활용하면 더 다양한 시스템을 설계할 수 있다.
Orchestrate
Chorography 방식을 사용하면 느슨한 결합을 유지할 수 있어 시스템의 확장성이 좋아진다는 것이 장점이라고 했다. 그러나, 복잡한 비즈니스 로직들을 처리할 때는 이벤트의 흐름이 너무 분산되어 오히려 관리가 어려워질 수 있다.
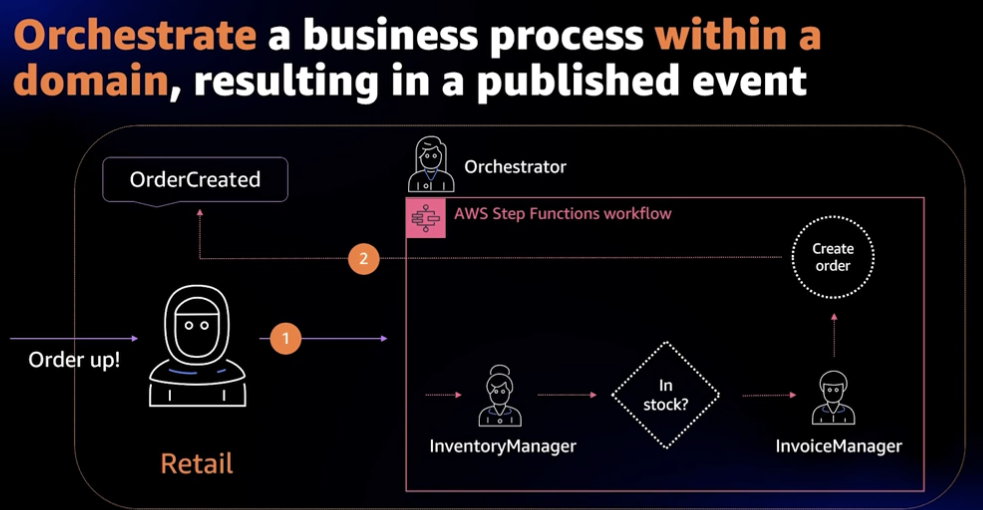
그래서 이벤트에 따른 전체적인 비즈니스 프로세스들을 순차적이고 명확하게 관리할 필요성이 생겼고, 이를 위해 도입된 개념이 바로 Orchestrate이다. 이는 중앙 컨트롤러라는 Orchestrator가 존재하여 전체 서비스 간 호출 순서, 오류 처리, 재시도 로직 등을 직접 제어한다.
이로 인해 복잡한 워크플로우를 구조적으로 설계할 수 있고, AWS Step functions과 같은 서버리스 서비스와 함께 사용하여 SPOF(단일 장애점) 문제도 벗어날 수 있다.
AWS Step Functions
Step Functions에 대해 조금 더 자세히 알아보자. 이 서비스는 서버리스 서비스로 인프라 운영 부담이 없이 관리가 가능하다. 또한, API 호출이나 Lambda 실행 등을 시각적으로 설계할 수 있고, 에러 처리 및 Retry도 지원하여 장애 발생 시 유연한 대처가 가능하다. 심지어, 로그 모니터링을 통해 문제 발생 시 분석도 가능하다.
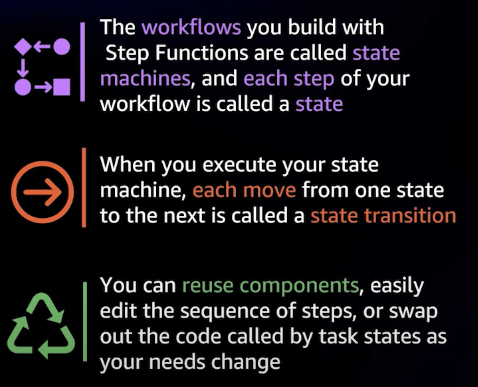
Step functions에서는 비즈니스 프로세스를 State, 즉 상태로 정의하고 각 단계에서 어떤 작업을 수행할 것인지를 결정한다. 이 상태는 JSON 기반의 ASL(Amazon States Language)을 사용하여 결정한다.
이후, 개별 실행 단위는 Task라고 하여 다양한 AWS 서비스와 통합이 가능하고, State Machine을 시작하면 workflow가 실행된다.
각 실행은 개별적으로 관리되기 때문에 병렬 실행이 가능하다.
{
"Comment": "Order Processing Workflow",
"StartAt": "Check Inventory",
"States": {
"Check Inventory": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:CheckInventory",
"Next": "Process Payment"
},
"Process Payment": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:ProcessPayment",
"Next": "Ship Order"
},
"Ship Order": {
"Type": "Task",
"Resource": "arn:aws:lambda:us-east-1:123456789012:function:ShipOrder",
"End": true
}
}
}다음과 같이 정의할 수 있고, 만약 특정 단계에서 오류가 발생하면 자동으로 재시도 및 오류 처리가 가능하다.
이 Step Funcions는 다양한 AWS 서비스와 통합하여 구현할 수 있다. 다음은 AWS Step Functions를 이용한 통합 서비스 패턴의 예시들이다.
Service Integration Pattern
Request Response
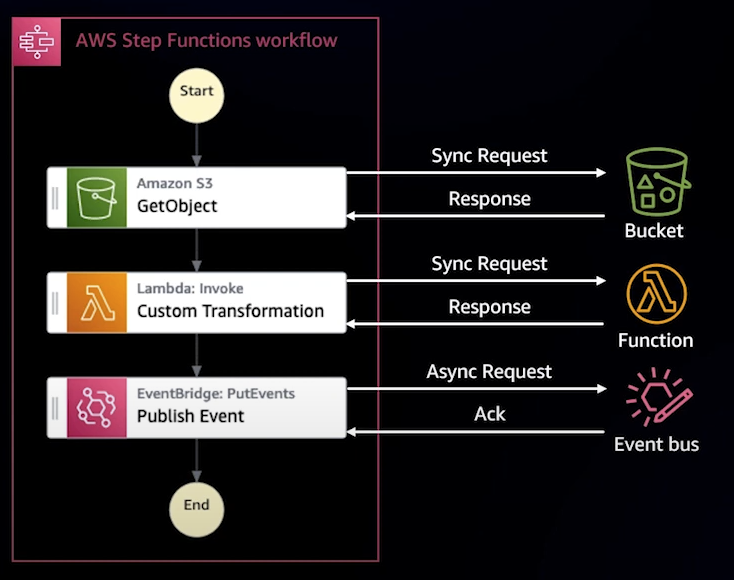
동기적으로 AWS 서비스와 통신하는 방식이다. 여기서는 S3에서 객체를 가져와 Lambda로 변환시킨 결과를 EventBridge에 게시한다.
Wait for a Callback
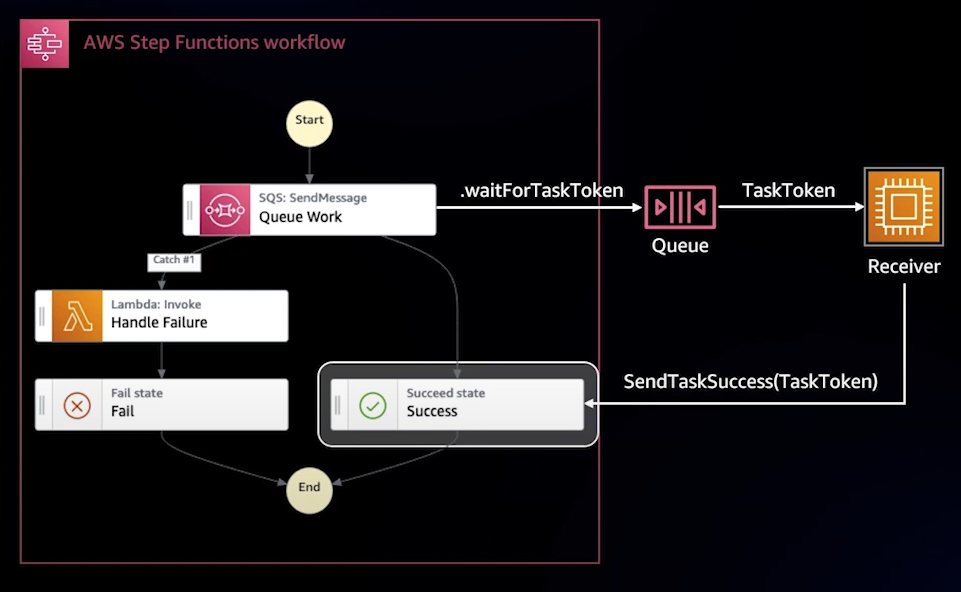
비동기적으로 외부 프로세스가 완료될 때까지 대기하는 방식이다. Step Functions이 SQS에 작업을 전송한 후, Worker가 SQS에서 메시지를 가져와서 처리한다. 이후, Worker가 처리한 결과를 다시 Step Funcions로 응답하면 그 응답에 맞춰 Success를 반환하거나, 결과가 실패라면 Lambda를 통해 재시도 혹은 오류 처리를 시행한다.
Run a Job(.sync)
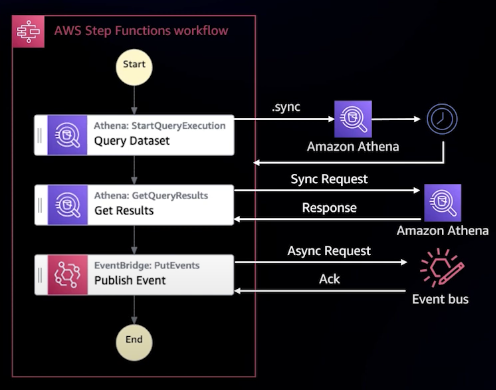
Athena, Glue 등의 비동기 작업을 실행한 후의 상태를 모니터링하는 예시이다. Step Functions는 작업의 진행 상태를 확인하며 완료될 때까지 기다렸다가 다음 단계로 넘어가는 작업 실행 형태의 예시이다.
Both of them
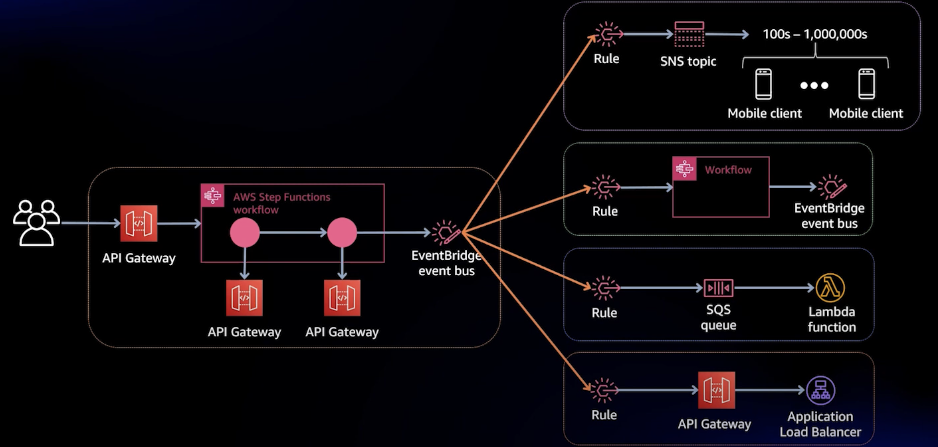
대부분의 시스템들에서는 Choreography와 Orchestration 방식을 함께 사용한다. 하나의 이벤트가 Kafka나 EventBridge로 발행되면 여러 Subscriber들이 이를 받아 독립적으로 이벤트를 처리한다.
이때, 특정한 순서로 진행되어야 하는 프로세스는 Step Functions를 사용하여 워크플로우를 관리할 수 있다. 예를 들어, OrderCreated라는 이벤트가 Publishing 되었을 때, 재고 확인, 결제 처리, 배송 요청의 과정은 Step Functions에서 오케스트레이션 하고 이후의 결과를 EventBridge로 발행하여 다른 도메인에서 이후의 비즈니스 로직을 수행하게 할 수 있다.
Taco Bell Architecture
TacoBell같이 대형 트래픽을 처리하는 기업에서는 어떻게 설계했을까?
TacoBell은 7,000점 이상의 점포를 전세계에 보유하고 있고, 매주 4,200만 명 이상의 고객들이 사용하며 이는 연간 10억 건의 고유한 주문 수를 처리하게 된다.
이에 TacoBell에서는 모바일 앱, 웹 그리고 키오스크와 배달 주문 등의 비중을 늘려 총 주문의 50%를 디지털로 확대할 계획을 세웠고 규모가 커짐에 따라 비용 절감 등의 이유로 처음에는 서버리스로 시작했다고 한다.
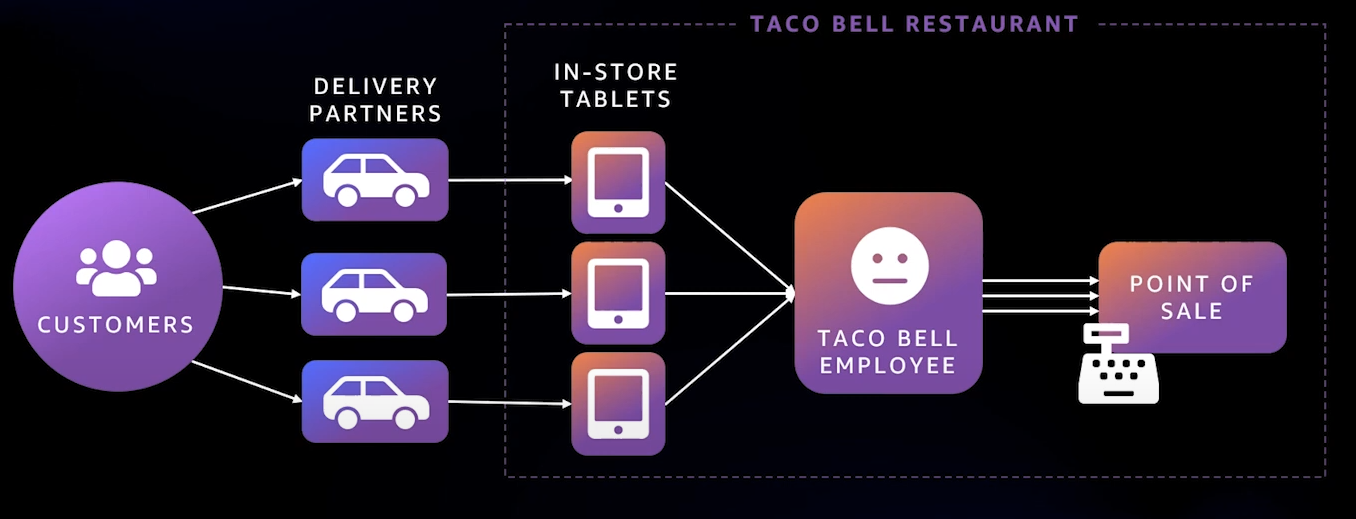
기존 방식은 위의 그림처럼 사용자가 앱에서 주문하여 매장의 태블릿에 주문이 전달되고 직원이 이 태블릿들을 확인하며 처리하는 방식이었지만, 이 방식은 불편하고 능률도 좋지 않기에
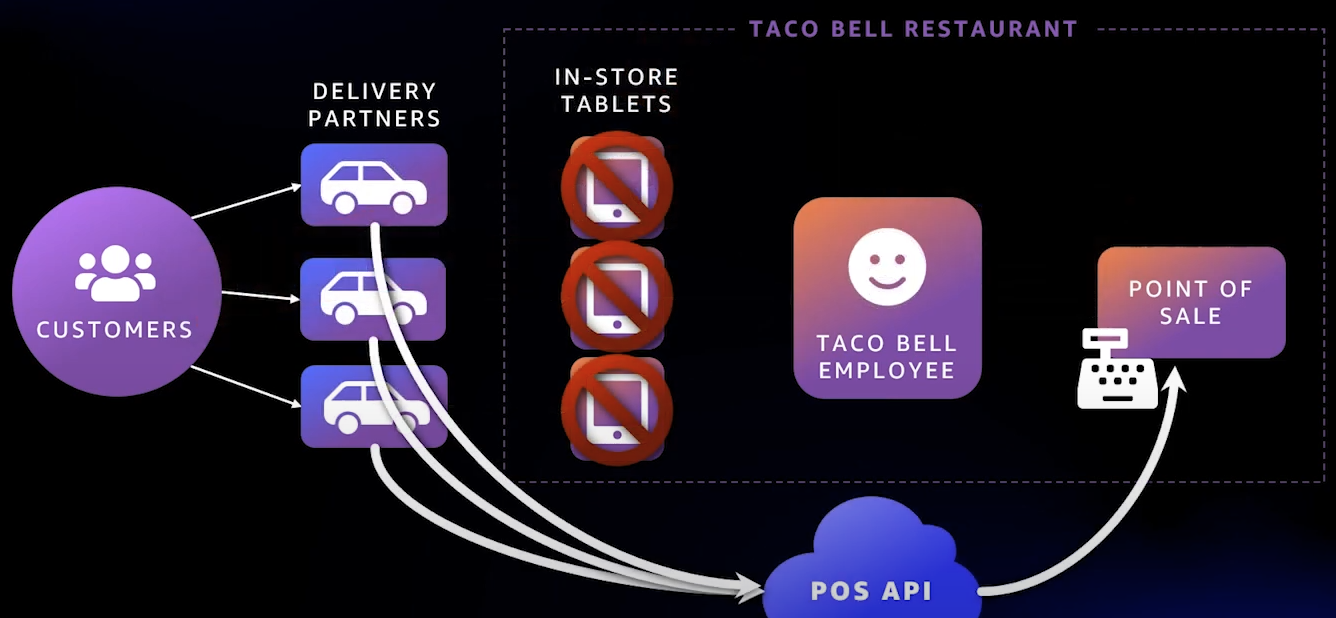
이렇게 주문 앱에서 바로 전달되도록 설계했다고 한다.
초기 Serverless 아키텍처
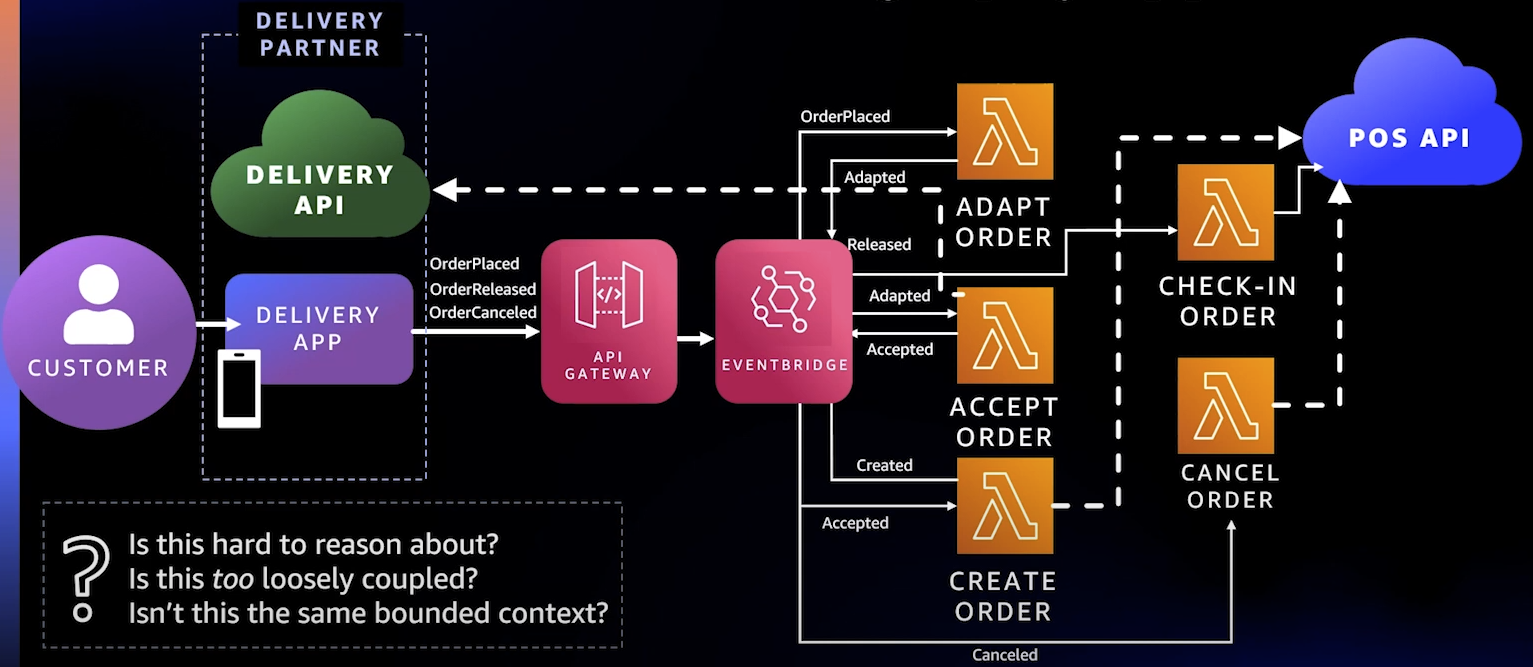
이를 위한 초기 서버리스 아키텍처는 다음과 같다. 사용자가 Delivery App에서 주문하면 관련 API Gateway로 요청이 전달되고 EventBridge로 이 요청이 전달된다.
그러면 Adapt Order를 처리하는 람다에서 이 이벤트를 받아 처리하고 Accept Order에 의해 주문이 수락되며 Delivery API로 수락 메시지가 전달된다.
또한, Order를 생성하여 POS API로 보내 주문을 만들어낸 후에 주문 취소나 조회 등이 가능하게 했다.
그러나, 위의 구조에 대해 이런 의문이 든다.
- 이 구조는 이해하기 쉬운가? -> X. 화살표도 복잡하고 설명하기도 쉽지 않다.
- 결합이 너무 느슨하진 않은가? -> 느슨한 결합은 좋은거라고 하지만 느슨한 결합을 관리할 때에는 Cost가 발생하며, 이 주문을 처리하는 과정은 별도의 프로세스라기보다는 동일한 프로세스의 단계처럼 보인다.
- 이것이 같은 도메인의 작업인가? -> 그렇다. 배송을 위한 주문 처리 도메인이라는 점에서 같은 도메인에서 이루어지는 작업이다. 2번과 연계하여 좀 더 긴밀한 결합을 유지해도 좋을 것 같다.
Orchestration 적용
위에서 내린 질문들에 대한 결론으로 좀 더 긴밀한 결합을 원했고, 이를 바탕으로 Workflow를 정의할 수 있는 Orchestration을 적용했다.
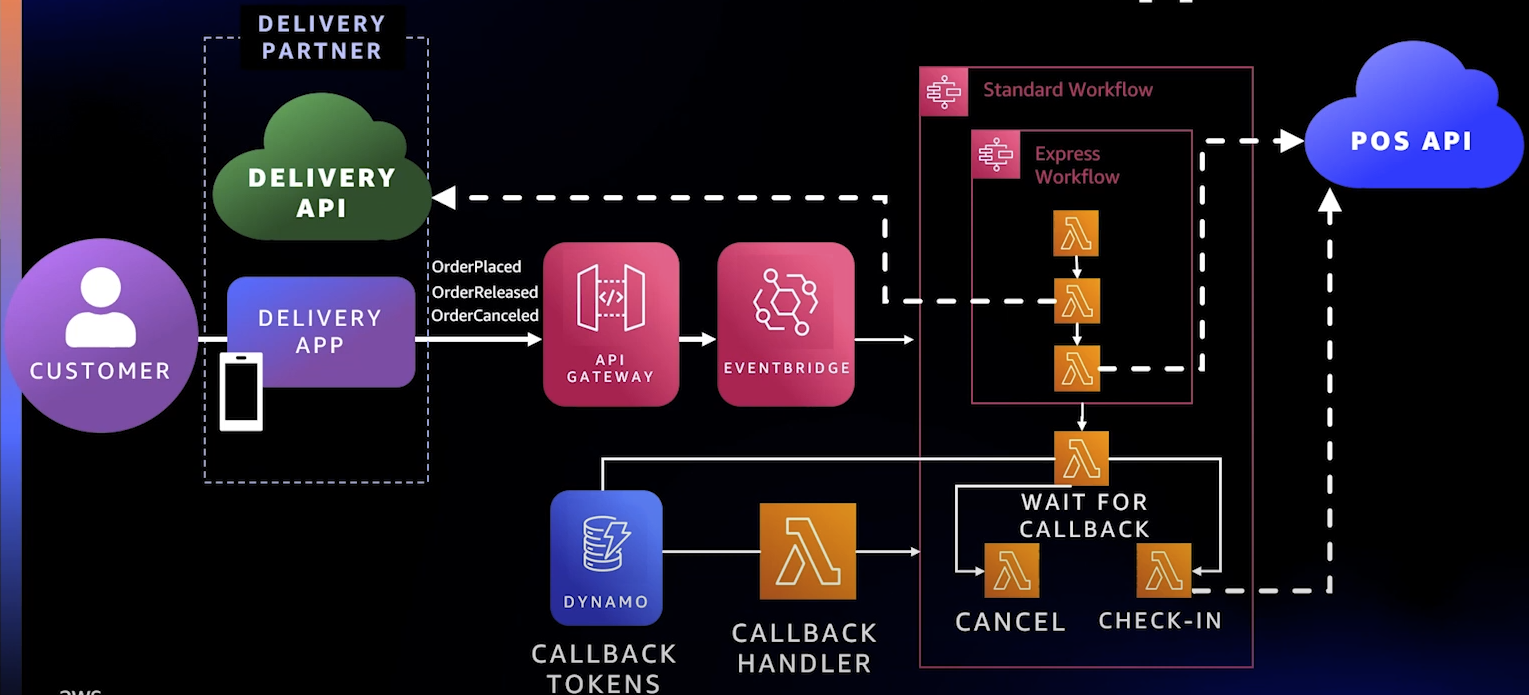
유연성을 위해 EventBridge까지 전달하는 것은 동일하나, EventBridge가 Workflow의 모든 단계를 조율하는 것이 아닌 Step Functions을 사용하여 명확한 플로우를 정의했다. 이렇게 하니 확실히 흐름을 쉽게 확인하고 설명할 수 있게 되었다.
또한, workflow 안에 또 다른 workflow를 넣을 수도 있으며, CallBack 패턴이 추가되었는데, 여기서는 너무 주문이 배달 기사에 비해 일찍 들어왔거나 시간이 예약된 주문들에 대해 잠시 Dynamo DB에 저장해두었다가 다시 Lambda로 발생시키는 (시간, 배달기사의 위치 등을 트리거로)방식으로도 발전시킬 수 있었다.
